El auge de la búsqueda contextual y semántica ha hecho que las empresas de comercio electrónico y minoristas realicen búsquedas sencillas para sus consumidores. Los motores de búsqueda y los sistemas de recomendación impulsados por IA generativa pueden mejorar exponencialmente la experiencia de búsqueda de productos al comprender las consultas en lenguaje natural y arrojar resultados más precisos. Esto mejora la experiencia general del usuario y ayuda a los clientes a encontrar exactamente lo que buscan.
Servicio Amazon OpenSearch ahora soporta el similitud de coseno Métrica para índices k-NN. La similitud de coseno mide el coseno del ángulo entre dos vectores, donde un ángulo de coseno más pequeño denota una mayor similitud entre los vectores. Con la similitud del coseno, puede medir la orientación entre dos vectores, lo que lo convierte en una buena opción para algunas aplicaciones de búsqueda semántica específicas.
En esta publicación, mostramos cómo crear un motor de búsqueda contextual de texto e imágenes para recomendaciones de productos utilizando el Modelo de incrustaciones multimodales de Amazon Titan, Disponible en lecho rocoso del amazonas, con las Amazon OpenSearch sin servidor.
Un modelo de incrustaciones multimodal está diseñado para aprender representaciones conjuntas de diferentes modalidades como texto, imágenes y audio. Al entrenarse en conjuntos de datos a gran escala que contienen imágenes y sus correspondientes leyendas, un modelo de incrustaciones multimodal aprende a incrustar imágenes y textos en un espacio latente compartido. La siguiente es una descripción general de alto nivel de cómo funciona conceptualmente:
- Codificadores separados – Estos modelos tienen codificadores separados para cada modalidad: un codificador de texto para texto (por ejemplo, BERT o RoBERTa), un codificador de imágenes para imágenes (por ejemplo, CNN para imágenes) y codificadores de audio para audio (por ejemplo, modelos como Wav2Vec). . Cada codificador genera incrustaciones que capturan características semánticas de sus respectivas modalidades.
- Fusión de modalidades – Las incorporaciones de los codificadores unimodales se combinan mediante capas de red neuronal adicionales. El objetivo es aprender las interacciones y correlaciones entre las modalidades. Los enfoques de fusión comunes incluyen concatenación, operaciones por elementos, agrupación y mecanismos de atención.
- Espacio de representación compartido – Las capas de fusión ayudan a proyectar las modalidades individuales en un espacio de representación compartido. Al entrenar en conjuntos de datos multimodales, el modelo aprende un espacio de incrustación común donde las incrustaciones de cada modalidad que representan el mismo contenido semántico subyacente están más juntas.
- Tareas posteriores – Las incorporaciones multimodales conjuntas generadas se pueden utilizar para diversas tareas posteriores, como recuperación, clasificación o traducción multimodal. El modelo utiliza correlaciones entre modalidades para mejorar el rendimiento en estas tareas en comparación con las incorporaciones modales individuales. La ventaja clave es la capacidad de comprender las interacciones y la semántica entre modalidades como texto, imágenes y audio mediante modelado conjunto.
Resumen de la solución
La solución proporciona una implementación para construir un prototipo de motor de búsqueda impulsado por un modelo de lenguaje grande (LLM) para recuperar y recomendar productos basados en consultas de texto o imágenes. Te detallamos los pasos para utilizar un Incorporaciones multimodales de Amazon Titan modelo para codificar imágenes y texto en incrustaciones, ingerir incrustaciones en un índice del servicio OpenSearch y consultar el índice utilizando el servicio OpenSearch Funcionalidad k-vecinos más cercanos (k-NN).
Esta solución incluye los siguientes componentes:
- Modelo de incrustaciones multimodales de Amazon Titan – Este modelo básico (FM) genera incrustaciones de las imágenes del producto utilizadas en esta publicación. Con Amazon Titan Multimodal Embeddings, puede generar incrustaciones para su contenido y almacenarlas en una base de datos vectorial. Cuando un usuario final envía cualquier combinación de texto e imagen como consulta de búsqueda, el modelo genera incrustaciones para la consulta de búsqueda y las compara con las incrustaciones almacenadas para proporcionar resultados de búsqueda y recomendaciones relevantes a los usuarios finales. Puede personalizar aún más el modelo para mejorar la comprensión de su contenido único y proporcionar resultados más significativos utilizando pares de imagen y texto para realizar ajustes. De forma predeterminada, el modelo genera vectores (incrustaciones) de 1,024 dimensiones y se accede a él a través de Amazon Bedrock. También puede generar dimensiones más pequeñas para optimizar la velocidad y el rendimiento.
- Amazon OpenSearch sin servidor – Es una configuración sin servidor bajo demanda para OpenSearch Service. Utilizamos Amazon OpenSearch Serverless como base de datos vectorial para almacenar incrustaciones generadas por el modelo Amazon Titan Multimodal Embeddings. Un índice creado en la colección Serverless de Amazon OpenSearch sirve como almacén de vectores para nuestra solución de generación aumentada de recuperación (RAG).
- Estudio Amazon SageMaker – Es un entorno de desarrollo integrado (IDE) para aprendizaje automático (ML). Los profesionales de ML pueden realizar todos los pasos de desarrollo de ML, desde preparar sus datos hasta crear, entrenar e implementar modelos de ML.
El diseño de la solución consta de dos partes: indexación de datos y búsqueda contextual. Durante la indexación de datos, procesa las imágenes del producto para generar incrustaciones para estas imágenes y luego completa el almacén de datos vectoriales. Estos pasos se completan antes de los pasos de interacción del usuario.
En la fase de búsqueda contextual, una consulta de búsqueda (texto o imagen) del usuario se convierte en incrustaciones y se ejecuta una búsqueda de similitud en la base de datos de vectores para encontrar imágenes de productos similares según la búsqueda de similitud. Luego muestra los principales resultados similares. Todo el código de esta publicación está disponible en el Repositorio GitHub.
El siguiente diagrama ilustra la arquitectura de la solución.
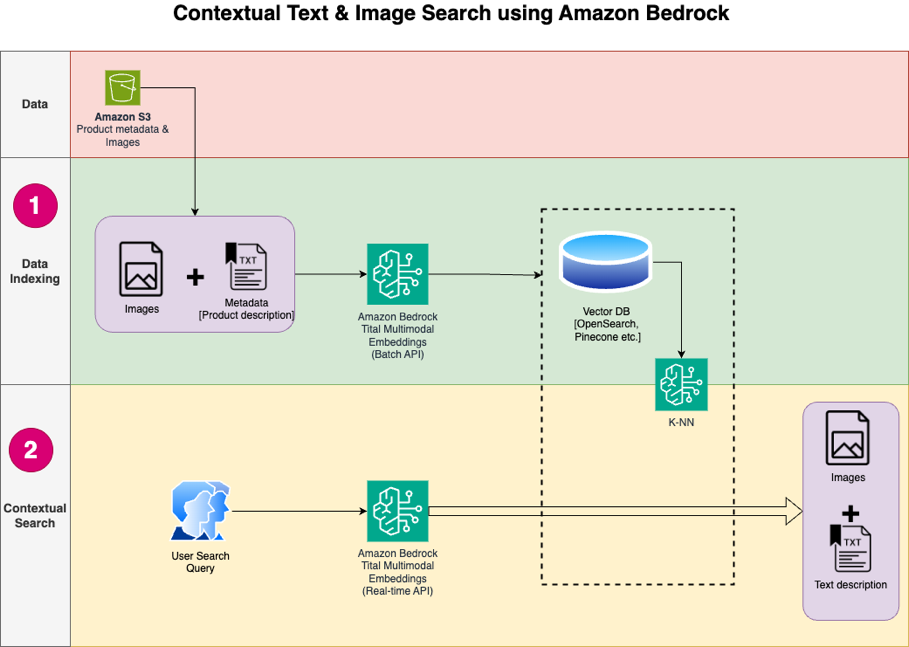
Los siguientes son los pasos del flujo de trabajo de la solución:
- Descargue el texto de descripción del producto y las imágenes del público. Servicio de almacenamiento simple de Amazon (Amazon S3) cubo.
- Revisar y preparar el conjunto de datos.
- Genere incrustaciones para las imágenes de productos utilizando el modelo Amazon Titan Multimodal Embeddings (amazon.titan-embed-image-v1). Si tiene una gran cantidad de imágenes y descripciones, opcionalmente puede utilizar el Inferencia por lotes para Amazon Bedrock.
- Guarde las incrustaciones en el Amazon OpenSearch sin servidor como motor de búsqueda.
- Finalmente, obtenga la consulta del usuario en lenguaje natural, conviértala en incrustaciones utilizando el modelo Amazon Titan Multimodal Embeddings y realice una búsqueda k-NN para obtener los resultados de búsqueda relevantes.
Usamos SageMaker Studio (no se muestra en el diagrama) como IDE para desarrollar la solución.
Estos pasos se analizan en detalle en las siguientes secciones. También incluimos capturas de pantalla y detalles del resultado.
Requisitos previos
Para implementar la solución proporcionada en esta publicación, debe tener lo siguiente:
- An Cuenta de AWS y familiaridad con FM, Amazon Bedrock, Amazon SageMakery el servicio OpenSearch.
- El modelo Amazon Titan Multimodal Embeddings habilitado en Amazon Bedrock. Puedes confirmar que está habilitado en el Modelo de acceso página de la consola Amazon Bedrock. Si Amazon Titan Multimodal Embeddings está habilitado, el estado de acceso se mostrará como Acceso permitido, como se muestra en la siguiente captura de pantalla.

Si el modelo no está disponible, habilite el acceso al modelo eligiendo Administrar el acceso al modelo, Seleccionando Incorporaciones multimodales de Amazon Titan G1y eligiendo Solicitar acceso al modelo. El modelo está habilitado para su uso inmediatamente.

Configurar la solución
Cuando se completen los pasos previos, estará listo para configurar la solución:
- En su cuenta de AWS, abra la consola de SageMaker y elija creativo en el panel de navegación.
- Elija su dominio y perfil de usuario, luego elija Open Studio.
Su dominio y nombre de perfil de usuario pueden ser diferentes.

- Elige terminal del sistema bajo Utilidades y archivos.
- Ejecute el siguiente comando para clonar el Repositorio GitHub a la instancia de SageMaker Studio:
- Navegue hasta la
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2ecarpeta. - Abra la
titan_mm_embed_search_blog.ipynbcuaderno.
Ejecute la solución
Abra el archivo titan_mm_embed_search_blog.ipynb y utilice el kernel Data Science Python 3. Sobre el Ejecutar menú, seleccione Ejecutar todas las celdas para ejecutar el código en este cuaderno.
Este cuaderno realiza los siguientes pasos:
- Instale los paquetes y bibliotecas necesarios para esta solución.
- Cargar el disponible públicamente Conjunto de datos de objetos de Amazon Berkeley y metadatos en un marco de datos de pandas.
El conjunto de datos es una colección de 147,702 listados de productos con metadatos multilingües y 398,212 imágenes de catálogo únicas. Para esta publicación, solo utiliza las imágenes y los nombres de los elementos en inglés de EE. UU. Utiliza aproximadamente 1,600 productos.

- Genere incrustaciones para las imágenes de elementos utilizando el modelo de incrustaciones multimodales de Amazon Titan utilizando el
get_titan_multomodal_embedding()función. En aras de la abstracción, hemos definido todas las funciones importantes utilizadas en este cuaderno en elutils.pyarchivo.

A continuación, creará y configurará un almacén de vectores sin servidor de Amazon OpenSearch (colección e índice).
- Antes de crear la nueva colección e índice de búsqueda de vectores, primero debe crear tres políticas de servicio OpenSearch asociadas: la política de seguridad de cifrado, la política de seguridad de red y la política de acceso a datos.

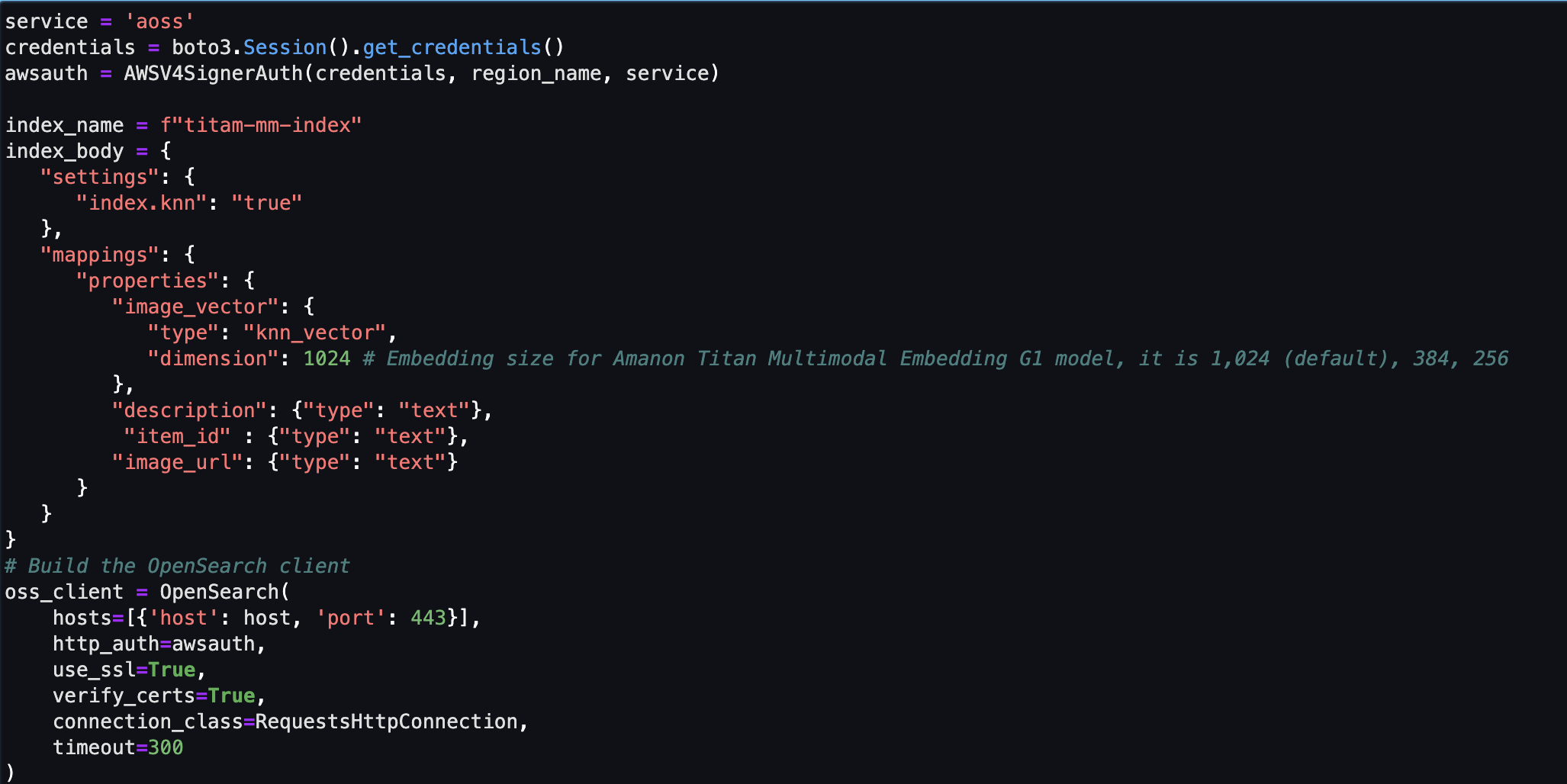
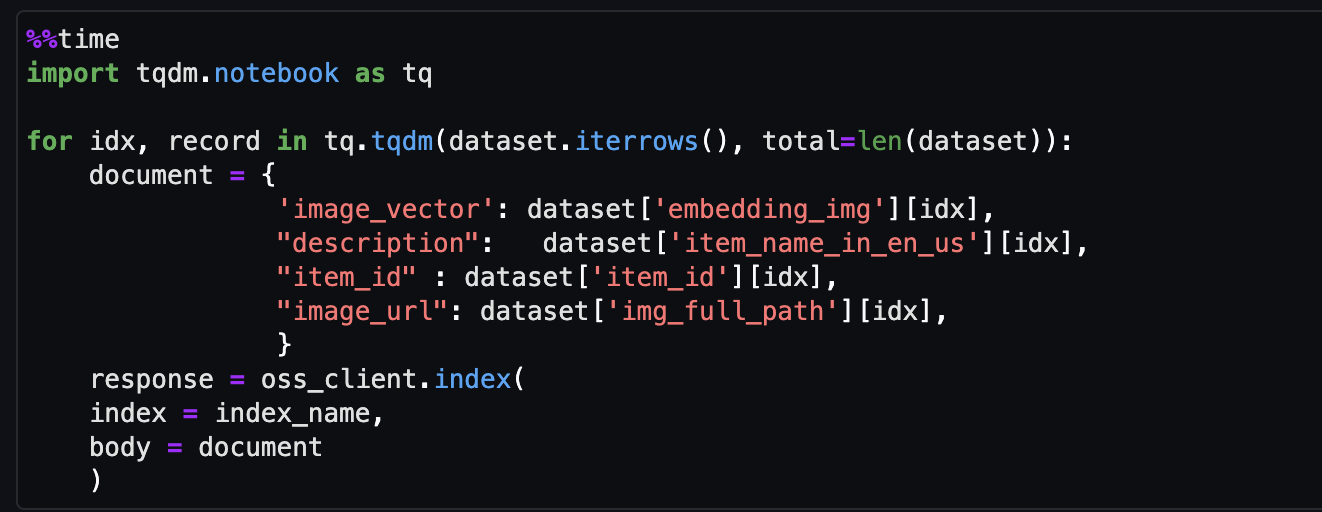
- Finalmente, ingiera la imagen incrustada en el índice vectorial.
Ahora puedes realizar una búsqueda multimodal en tiempo real.
Ejecute una búsqueda contextual
En esta sección mostramos los resultados de la búsqueda contextual basada en una consulta de texto o imagen.
Primero, realicemos una búsqueda de imágenes basada en la entrada de texto. En el siguiente ejemplo, utilizamos la entrada de texto "vaso" y la enviamos al motor de búsqueda para encontrar artículos similares.
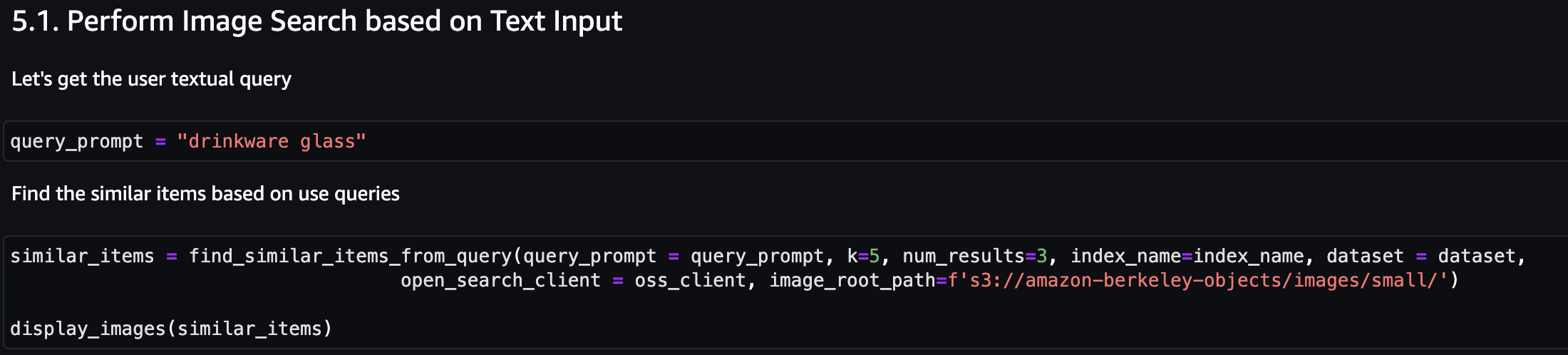
La siguiente captura de pantalla muestra los resultados.

Ahora veamos los resultados basados en una imagen simple. La imagen de entrada se convierte en incrustaciones de vectores y, según la búsqueda de similitud, el modelo devuelve el resultado.
Puede usar cualquier imagen, pero para el siguiente ejemplo, usamos una imagen aleatoria del conjunto de datos según el ID del artículo (por ejemplo, item_id = “B07JCDQWM6”), y luego envíe esta imagen al motor de búsqueda para encontrar artículos similares.

La siguiente captura de pantalla muestra los resultados.

Limpiar
Para evitar incurrir en cargos futuros, elimine los recursos utilizados en esta solución. Puede hacer esto ejecutando la sección de limpieza del cuaderno.

Conclusión
Esta publicación presentó un tutorial sobre el uso del modelo Amazon Titan Multimodal Embeddings en Amazon Bedrock para crear potentes aplicaciones de búsqueda contextual. En particular, demostramos un ejemplo de una aplicación de búsqueda de listado de productos. Vimos cómo el modelo de incrustaciones permite el descubrimiento eficiente y preciso de información a partir de imágenes y datos textuales, mejorando así la experiencia del usuario mientras busca los elementos relevantes.
Amazon Titan Multimodal Embeddings lo ayuda a impulsar experiencias de búsqueda, recomendación y personalización multimodal más precisas y contextualmente relevantes para los usuarios finales. Por ejemplo, una empresa de fotografía de archivo con cientos de millones de imágenes puede utilizar el modelo para potenciar su función de búsqueda, de modo que los usuarios puedan buscar imágenes mediante una frase, una imagen o una combinación de imagen y texto.
El modelo Amazon Titan Multimodal Embeddings en Amazon Bedrock ahora está disponible en las regiones de AWS Este de EE. UU. (Norte de Virginia) y Oeste de EE. UU. (Oregón). Para obtener más información, consulte Amazon Titan Image Generator, incrustaciones multimodales y modelos de texto ahora están disponibles en Amazon Bedrock, la Página del producto Amazon Titan, y la Guía del usuario de Amazon Bedrock. Para comenzar con las incrustaciones multimodales de Amazon Titan en Amazon Bedrock, visite el Consola Amazon Bedrock.
Comience a construir con el modelo Amazon Titan Multimodal Embeddings en lecho rocoso del amazonas .
Acerca de los autores
 Sandeep Singh es científico senior de datos de IA generativa en Amazon Web Services y ayuda a las empresas a innovar con IA generativa. Se especializa en IA generativa, inteligencia artificial, aprendizaje automático y diseño de sistemas. Le apasiona desarrollar soluciones basadas en IA/ML de última generación para resolver problemas comerciales complejos para diversas industrias, optimizando la eficiencia y la escalabilidad.
Sandeep Singh es científico senior de datos de IA generativa en Amazon Web Services y ayuda a las empresas a innovar con IA generativa. Se especializa en IA generativa, inteligencia artificial, aprendizaje automático y diseño de sistemas. Le apasiona desarrollar soluciones basadas en IA/ML de última generación para resolver problemas comerciales complejos para diversas industrias, optimizando la eficiencia y la escalabilidad.
 Mani Januja es líder tecnológica: especialistas en IA generativa, autora del libro Applied Machine Learning and High Performance Computing on AWS y miembro de la junta directiva de la Junta Directiva de la Women in Manufacturing Education Foundation. Lidera proyectos de aprendizaje automático en diversos ámbitos, como la visión por computadora, el procesamiento del lenguaje natural y la inteligencia artificial generativa. Habla en conferencias internas y externas como AWS re:Invent, Women in Manufacturing West, seminarios web de YouTube y GHC 23. En su tiempo libre, le gusta salir a correr largas distancias por la playa.
Mani Januja es líder tecnológica: especialistas en IA generativa, autora del libro Applied Machine Learning and High Performance Computing on AWS y miembro de la junta directiva de la Junta Directiva de la Women in Manufacturing Education Foundation. Lidera proyectos de aprendizaje automático en diversos ámbitos, como la visión por computadora, el procesamiento del lenguaje natural y la inteligencia artificial generativa. Habla en conferencias internas y externas como AWS re:Invent, Women in Manufacturing West, seminarios web de YouTube y GHC 23. En su tiempo libre, le gusta salir a correr largas distancias por la playa.
 Rupinder Grewal es un arquitecto senior de soluciones especializado en IA/ML en AWS. Actualmente se enfoca en servir modelos y MLOps en Amazon SageMaker. Antes de ocupar este puesto, trabajó como ingeniero de aprendizaje automático creando y alojando modelos. Fuera del trabajo, le gusta jugar tenis y andar en bicicleta por senderos de montaña.
Rupinder Grewal es un arquitecto senior de soluciones especializado en IA/ML en AWS. Actualmente se enfoca en servir modelos y MLOps en Amazon SageMaker. Antes de ocupar este puesto, trabajó como ingeniero de aprendizaje automático creando y alojando modelos. Fuera del trabajo, le gusta jugar tenis y andar en bicicleta por senderos de montaña.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

