Amazon EMR en EKS es una opción de implementación en EMR de Amazon que le permite ejecutar trabajos de Spark en Servicio Amazon Elastic Kubernetes (Amazon EKS). Nube informática elástica de Amazon (Amazon EC2) Las instancias de spot le ahorran hasta un 90 % en comparación con las instancias bajo demanda, y es una excelente manera de optimizar los costos de las cargas de trabajo de Spark que se ejecutan en Amazon EMR en EKS. Debido a que Spot es un servicio interrumpible, si podemos mover o reutilizar los archivos aleatorios intermedios, mejora la estabilidad general y el SLA del trabajo. Las últimas versiones de Amazon EMR en EKS tienen características de Spark integradas para habilitar esta capacidad.
En esta publicación, analizamos estas funciones (Desmantelamiento de nodos y Reutilización de reclamo de volumen persistente (PVC)) y su impacto en el aumento de la tolerancia a fallas de los trabajos de Spark en Amazon EMR en EKS cuando se optimizan los costos con EC2 Spot Instances.
Amazon EMR en EKS y Spot
Las instancias de spot de EC2 son capacidad EC2 de repuesto que se proporciona con un gran descuento de hasta el 90 % sobre los precios bajo demanda. Las instancias de spot son una excelente opción para cargas de trabajo sin estado y flexibles. La advertencia con este descuento y capacidad adicional es que Amazon EC2 puede interrumpir una instancia con una advertencia proactiva o reactiva (2 minutos) cuando necesita recuperar la capacidad. Puede aprovisionar capacidad de cómputo en un clúster de EKS mediante instancias de spot mediante un grupo de nodos administrado o autoadministrado y proporcionar optimización de costos para sus cargas de trabajo.
Amazon EMR en EKS utiliza Amazon EKS para ejecutar trabajos con el Tiempo de ejecución de EMR para Apache Spark, que se puede optimizar en cuanto a costos ejecutando el Ejecutores de chispa en Spot. Proporciona hasta 61 % menos de costes y hasta un 68 % de mejora del rendimiento para cargas de trabajo de Spark en Amazon EKS. La aplicación Spark inicia un controlador y ejecutores para ejecutar el cálculo. Spark es un marco tolerante a fallas parciales que es resistente a la pérdida del ejecutor debido a una interrupción y, por lo tanto, puede ejecutarse en EC2 Spot. Por otro lado, cuando se interrumpe al conductor, el trabajo falla. Por lo tanto, recomendamos ejecutar controladores en instancias bajo demanda. Algunos de los y las mejores prácticas para ejecutar Spark en Amazon EKS son aplicables con Amazon EMR en EKS.
Las instancias EC2 Spot también ayudan en la optimización de costos al mejorar el rendimiento general del trabajo. Esto se puede lograr mediante el escalado automático del clúster mediante el escalador automático de clústeres (por grupos de nodos administrados) o carpintero.
Aunque los ejecutores de Spark son resistentes a las interrupciones de Spot, los archivos aleatorios y los datos RDD se pierden cuando el ejecutor muere. Los archivos aleatorios perdidos deben volver a calcularse, lo que aumenta el tiempo de ejecución general del trabajo. Apache Spark ha lanzado dos funciones (en las versiones 3.1 y 3.2) que solucionan este problema. Amazon EMR en EKS lanzó funciones como la desactivación de nodos (versión 6.3) y la reutilización de PVC (versión 6.8) para simplificar la recuperación y la reutilización de archivos aleatorios, lo que aumenta la resistencia general de su aplicación.
Desmantelamiento de nodos
La función de desmantelamiento de nodos funciona impidiendo la programación de nuevos trabajos en los nodos que se van a desmantelar. También mueve cualquier archivo aleatorio o caché presente en esos nodos a otros ejecutores (pares). Si no hay otros ejecutores disponibles, los archivos aleatorios y la memoria caché se mueven a un almacenamiento alternativo remoto.
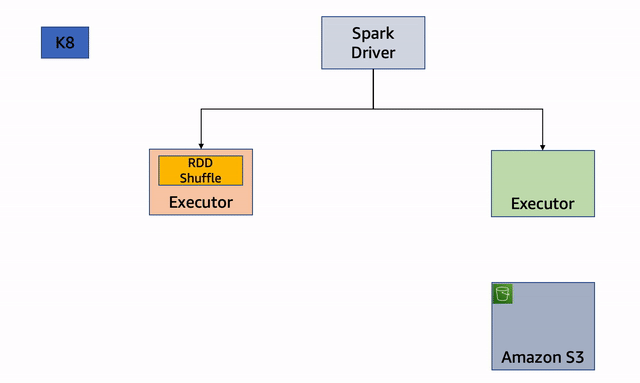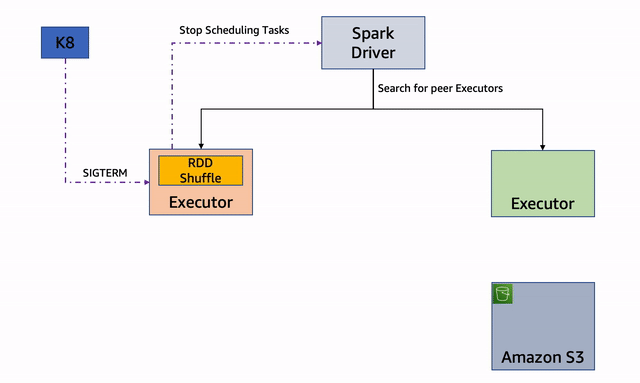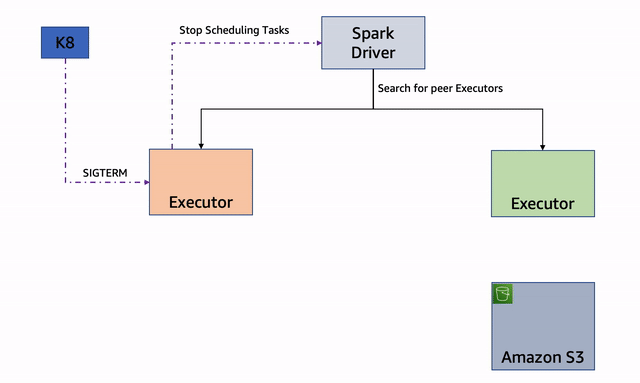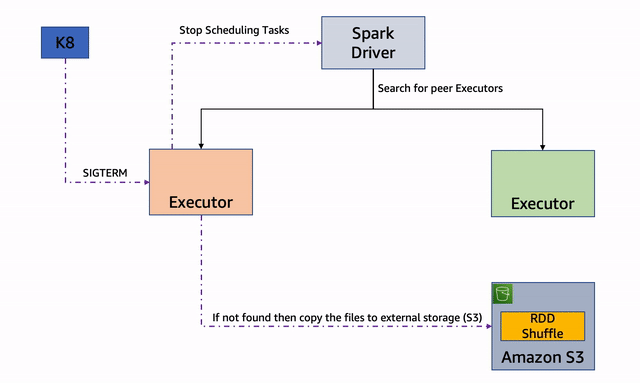
Fig. 1: Desmantelamiento de nodos
Veamos los pasos de desmantelamiento con más detalle.
Si uno de los nodos que está ejecutando ejecutores se interrumpe, el ejecutor inicia el proceso de desmantelamiento y envía el mensaje al controlador:
El ejecutor busca archivos RDD o shuffle e intenta replicar o migrar esos archivos. Primero intenta encontrar un ejecutor del mismo nivel. Si tiene éxito, moverá los archivos al ejecutor del mismo nivel:
Sin embargo, si no puede encontrar un ejecutor del mismo nivel, intentará mover los archivos a un almacenamiento alternativo si está disponible.
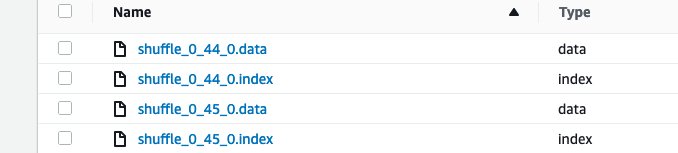
Fig. 2: Almacenamiento alternativo
El ejecutor es entonces dado de baja. Cuando aparece un nuevo ejecutor, los archivos aleatorios se reutilizan:
La ventaja clave de este proceso es que permite migrar bloques y mezclar datos, lo que reduce el recálculo, lo que aumenta la resistencia general del sistema y reduce el tiempo de ejecución. Este proceso puede desencadenarse mediante una señal de interrupción de Spot (Sigterm) y el drenaje del nodo. El drenaje de nodos puede ocurrir debido a la programación de tareas de alta prioridad o de forma independiente.
Cuando usa Amazon EMR en EKS con un nodo administrado groups/Karpenter, el manejo de la interrupción de Spot está automatizado, en el que Amazon EKS drena y reequilibra correctamente los nodos de Spot para minimizar la interrupción de la aplicación cuando un nodo de Spot tiene un riesgo elevado de interrupción. Si está utilizando un nodo administrado groups/Karpenter, la desactivación se activa cuando los nodos se vacían y, como es proactivo, le da más tiempo (al menos 2 minutos) para mover los archivos. En el caso de los grupos de nodos autoadministrados, recomendamos instalar el controlador de terminación de nodos de AWS para manejar la interrupción, y la desactivación se activa cuando se recibe la notificación reactiva (2 minutos). Recomendamos usar Karpenter con instancias de spot, ya que tiene una programación de nodos más rápida con vinculación temprana de pods y binpacking para optimizar la utilización de recursos.
El siguiente código habilita esta configuración; más detalles están disponibles en GitHub:
reutilización de PVC
Apache Spark habilitó PVC dinámico en la versión 3.1, lo cual es útil con la asignación dinámica porque no tenemos que crear previamente los reclamos o volúmenes para los ejecutores y eliminarlos después de completarlos. PVC permite un verdadero desacoplamiento de datos y procesamiento cuando ejecutamos trabajos de Spark en Kubernetes, porque también podemos usarlo como almacenamiento local para distribuir archivos en proceso. La última versión de Amazon EMR 6.8 ha integrado la función de reutilización de PVC de Spark, en la que si un ejecutor finaliza debido a una interrupción de EC2 Spot o por cualquier otro motivo (JVM), el PVC no se elimina, sino que persiste y se vuelve a conectar a otro ejecutor. Si hay archivos aleatorios en ese volumen, se reutilizan.
Al igual que con la desactivación de nodos, esto reduce el tiempo de ejecución general porque no tenemos que volver a calcular los archivos aleatorios. También ahorramos el tiempo requerido para solicitar un nuevo volumen para un ejecutor, y los archivos aleatorios se pueden reutilizar sin mover los archivos.
El siguiente diagrama ilustra este flujo de trabajo.
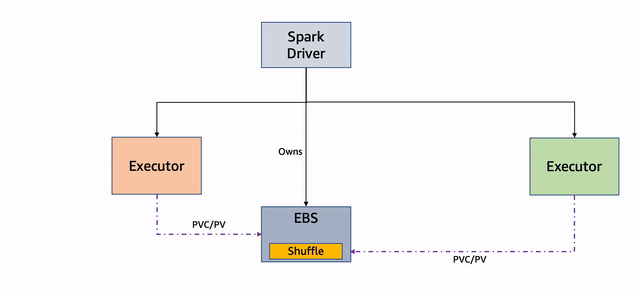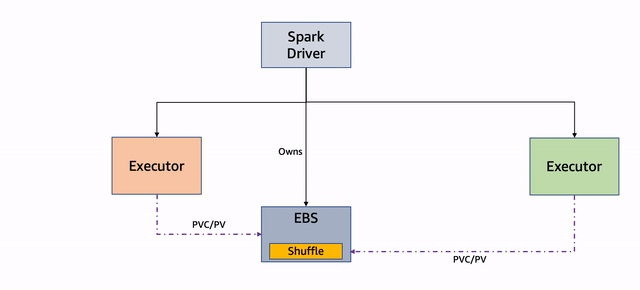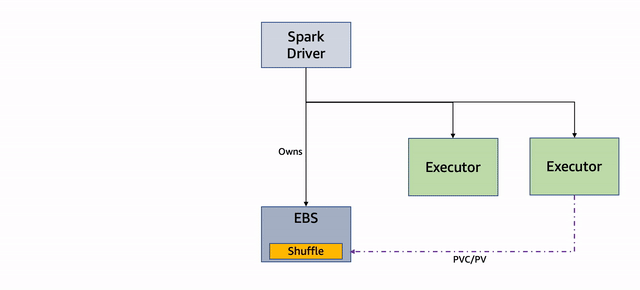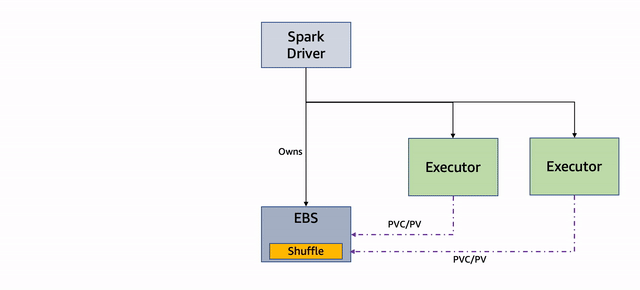
Figura 3: Reutilización de PVC
Veamos los pasos con más detalle.
Si uno o más de los nodos que ejecutan los ejecutores se interrumpen, los pods subyacentes se terminan y el controlador obtiene la actualización. Tenga en cuenta que el controlador es el propietario del PVC de los ejecutores y no están terminados. Ver el siguiente código:
El ExecutorPodsAllocator intenta asignar nuevos módulos de ejecución para reemplazar los terminados debido a una interrupción. Durante la asignación, calcula cuántos de los PVC existentes tienen archivos y se pueden reutilizar:
El ExecutorPodsAllocator solicita un pod y cuando lo lanza, el PVC se reutiliza. En el siguiente ejemplo, el PVC del ejecutor 6 se reutiliza para el nuevo módulo del ejecutor 11:
Los archivos aleatorios, si están presentes en el PVC, se reutilizan.
La ventaja clave de esta técnica es que nos permite reutilizar archivos aleatorios precalculados en su ubicación original, lo que reduce el tiempo de ejecución general del trabajo.
Esto funciona tanto para PVC estáticos como dinámicos. Amazon EKS ofrece tres ofertas de almacenamiento diferentes, que también se pueden cifrar: Tienda de bloques elásticos de Amazon (Amazon EBS), Sistema de archivos elástico de Amazon (Amazon EFS), y Amazon FSx para Lustre. Recomendamos el uso de PVC dinámicos con Amazon EBS porque con los PVC estáticos, necesitaría crear varios PVC.
El siguiente código habilita esta configuración; más detalles están disponibles en GitHub:
Para que esto funcione, debemos habilitar PVC con Amazon EKS y mencionar los detalles en la configuración del tiempo de ejecución de Spark. Para obtener instrucciones, consulte ¿Cómo uso el almacenamiento persistente en Amazon EKS? El siguiente código contiene los detalles de configuración de Spark para usar PVC como almacenamiento local; otros detalles están disponibles en GitHub:
Conclusión
Con Amazon EMR en EKS (6.9) y las características que se analizan en esta publicación, puede reducir aún más el tiempo de ejecución general de los trabajos de Spark cuando se ejecutan con instancias de spot. Esto también mejora la resiliencia y la flexibilidad generales del trabajo al mismo tiempo que optimiza los costos de la carga de trabajo en EC2 Spot.
Probar el Taller EMR sobre EKS para mejorar el rendimiento al ejecutar cargas de trabajo de Spark en Kubernetes y optimizar los costos con EC2 Spot Instances.
Sobre la autora
 Kinnar Kumar Sen es un Arquitecto de Soluciones Sr. en Amazon Web Services (AWS) que se enfoca en Computación Flexible. Como parte del equipo de computación flexible de EC2, trabaja con los clientes para guiarlos hacia las opciones de computación más elásticas y eficientes que sean adecuadas para su carga de trabajo que se ejecuta en AWS. Kinnar tiene más de 15 años de experiencia en la industria trabajando en investigación, consultoría, ingeniería y arquitectura.
Kinnar Kumar Sen es un Arquitecto de Soluciones Sr. en Amazon Web Services (AWS) que se enfoca en Computación Flexible. Como parte del equipo de computación flexible de EC2, trabaja con los clientes para guiarlos hacia las opciones de computación más elásticas y eficientes que sean adecuadas para su carga de trabajo que se ejecuta en AWS. Kinnar tiene más de 15 años de experiencia en la industria trabajando en investigación, consultoría, ingeniería y arquitectura.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/run-fault-tolerant-and-cost-optimized-spark-clusters-using-amazon-emr-on-eks-and-amazon-ec2-spot-instances/

