La IA generativa ha abierto un gran potencial en el campo de la IA. Estamos viendo numerosos usos, incluida la generación de texto, generación de código, resúmenes, traducción, chatbots y más. Una de esas áreas que está evolucionando es el uso del procesamiento del lenguaje natural (NLP) para desbloquear nuevas oportunidades de acceso a datos a través de consultas SQL intuitivas. En lugar de lidiar con códigos técnicos complejos, los usuarios comerciales y los analistas de datos pueden hacer preguntas relacionadas con los datos y los conocimientos en un lenguaje sencillo. El objetivo principal es generar automáticamente consultas SQL a partir de texto en lenguaje natural. Para ello, la entrada de texto se transforma en una representación estructurada y, a partir de esta representación, se crea una consulta SQL que puede utilizarse para acceder a una base de datos.
En esta publicación, brindamos una introducción al texto a SQL (Text2SQL) y exploramos casos de uso, desafíos, patrones de diseño y mejores prácticas. Específicamente, discutimos lo siguiente:
- ¿Por qué necesitamos Text2SQL?
- Componentes clave para Texto a SQL
- Consideraciones de ingeniería rápidas para lenguaje natural o texto a SQL
- Optimizaciones y mejores prácticas.
- Patrones de arquitectura
¿Por qué necesitamos Text2SQL?
Hoy en día, hay una gran cantidad de datos disponibles en análisis de datos, almacenamiento de datos y bases de datos tradicionales, que pueden no ser fáciles de consultar o comprender para la mayoría de los miembros de las organizaciones. El objetivo principal de Text2SQL es hacer que las consultas de bases de datos sean más accesibles para usuarios no técnicos, quienes pueden realizar sus consultas en lenguaje natural.
NLP SQL permite a los usuarios empresariales analizar datos y obtener respuestas escribiendo o pronunciando preguntas en lenguaje natural, como las siguientes:
- "Mostrar las ventas totales de cada producto el mes pasado"
- "¿Qué productos generaron más ingresos?"
- "¿Qué porcentaje de clientes son de cada región?"
lecho rocoso del amazonas es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento a través de una única API, lo que permite crear y escalar fácilmente aplicaciones Gen AI. Se puede aprovechar para generar consultas SQL basadas en preguntas similares a las enumeradas anteriormente y consultar datos estructurados organizacionales y generar respuestas en lenguaje natural a partir de los datos de respuesta de la consulta.
Componentes clave para texto a SQL
Los sistemas de texto a SQL implican varias etapas para convertir consultas en lenguaje natural en SQL ejecutable:
- Procesamiento natural del lenguaje:
- Analizar la consulta de entrada del usuario.
- Extraiga elementos clave e intención
- Convertir a un formato estructurado
- Generación de SQL:
- Mapa de detalles extraídos en sintaxis SQL
- Generar una consulta SQL válida
- Consulta de base de datos:
- Ejecute la consulta SQL generada por IA en la base de datos
- Recuperar resultados
- Devolver resultados al usuario
Una capacidad notable de los modelos de lenguajes grandes (LLM) es la generación de código, incluido el lenguaje de consulta estructurado (SQL) para bases de datos. Estos LLM se pueden aprovechar para comprender la pregunta en lenguaje natural y generar la consulta SQL correspondiente como resultado. Los LLM se beneficiarán al adoptar el aprendizaje en contexto y ajustar la configuración a medida que se proporcionen más datos.
El siguiente diagrama ilustra un flujo básico de Text2SQL.

Consideraciones de ingeniería rápidas para el lenguaje natural en SQL
El mensaje es crucial cuando se utilizan LLM para traducir el lenguaje natural a consultas SQL, y existen varias consideraciones importantes para la ingeniería rápida.
Eficaz pronta ingenieria es clave para desarrollar lenguaje natural para sistemas SQL. Las indicaciones claras y sencillas proporcionan mejores instrucciones para el modelo de lenguaje. Proporcionar el contexto de que el usuario solicita una consulta SQL junto con los detalles relevantes del esquema de la base de datos permite que el modelo traduzca la intención con precisión. Incluir algunos ejemplos anotados de indicaciones en lenguaje natural y las consultas SQL correspondientes ayuda a guiar el modelo para producir resultados compatibles con la sintaxis. Además, la incorporación de recuperación de generación aumentada (RAG), donde el modelo recupera ejemplos similares durante el procesamiento, mejora aún más la precisión del mapeo. Las indicaciones bien diseñadas que brindan al modelo suficiente instrucción, contexto, ejemplos y aumento de recuperación son cruciales para traducir de manera confiable el lenguaje natural a consultas SQL.
El siguiente es un ejemplo de un mensaje de referencia con representación de código de la base de datos del documento técnico. Mejora de las capacidades de texto a SQL de pocas oportunidades de modelos de lenguaje grandes: un estudio sobre estrategias de diseño rápido.
Como se ilustra en este ejemplo, el aprendizaje de pocas oportunidades basado en indicaciones proporciona al modelo un puñado de ejemplos anotados en la propia indicación. Esto demuestra el mapeo de destino entre el lenguaje natural y SQL para el modelo. Normalmente, el mensaje contendrá entre 2 y 3 pares que muestran una consulta en lenguaje natural y la declaración SQL equivalente. Estos pocos ejemplos guían al modelo para generar consultas SQL compatibles con la sintaxis a partir de lenguaje natural sin requerir datos de entrenamiento extensos.
Ajuste fino versus ingeniería rápida
Al crear lenguaje natural para sistemas SQL, a menudo entramos en la discusión sobre si ajustar el modelo es la técnica correcta o si la ingeniería rápida y efectiva es el camino a seguir. Ambos enfoques podrían considerarse y seleccionarse en función del conjunto adecuado de requisitos:
-
- Sintonia FINA – El modelo de referencia está previamente entrenado en un gran corpus de texto general y luego puede usarse ajuste fino basado en instrucciones, que utiliza ejemplos etiquetados para mejorar el rendimiento de un modelo básico previamente entrenado en texto-SQL. Esto adapta el modelo a la tarea objetivo. El ajuste fino entrena directamente el modelo en la tarea final, pero requiere muchos ejemplos de texto-SQL. Puede utilizar ajustes supervisados basados en su LLM para mejorar la efectividad de la conversión de texto a SQL. Para esto, puede utilizar varios conjuntos de datos como Spiders, WikiSQL, PERSECUCIÓN, PÁJARO-SQLo CoSQL.
- Ingeniería rápida – El modelo está entrenado para completar solicitudes diseñadas para solicitar la sintaxis SQL de destino. Al generar SQL a partir de lenguaje natural utilizando LLM, es importante proporcionar instrucciones claras en el mensaje para controlar la salida del modelo. En el mensaje, se deben anotar diferentes componentes, como señalar columnas, esquemas y luego indicar qué tipo de SQL crear. Estos actúan como instrucciones que le indican al modelo cómo formatear la salida SQL. El siguiente mensaje muestra un ejemplo en el que señala columnas de la tabla e indica que se cree una consulta MySQL:
Un enfoque eficaz para los modelos de texto a SQL es comenzar primero con un LLM básico sin ningún ajuste específico de la tarea. Luego se pueden utilizar indicaciones bien diseñadas para adaptar e impulsar el modelo base para manejar la asignación de texto a SQL. Esta ingeniería rápida le permite desarrollar la capacidad sin necesidad de realizar ajustes. Si la ingeniería rápida en el modelo base no logra suficiente precisión, se puede explorar el ajuste fino de un pequeño conjunto de ejemplos de texto-SQL junto con una ingeniería rápida adicional.
Es posible que se requiera la combinación de ajuste fino e ingeniería rápida si la ingeniería rápida solo en el modelo sin procesar previamente entrenado no cumple con los requisitos. Sin embargo, es mejor intentar inicialmente la ingeniería rápida sin realizar ajustes, porque esto permite una iteración rápida sin recopilación de datos. Si esto no logra proporcionar un rendimiento adecuado, el siguiente paso viable es realizar ajustes junto con una ingeniería rápida. Este enfoque general maximiza la eficiencia y al mismo tiempo permite la personalización si los métodos puramente basados en indicaciones son insuficientes.
Optimización y mejores prácticas.
La optimización y las mejores prácticas son esenciales para mejorar la eficacia y garantizar que los recursos se utilicen de manera óptima y se logren los resultados correctos de la mejor manera posible. Las técnicas ayudan a mejorar el rendimiento, controlar los costos y lograr un resultado de mejor calidad.
Al desarrollar sistemas de texto a SQL utilizando LLM, las técnicas de optimización pueden mejorar el rendimiento y la eficiencia. Las siguientes son algunas áreas clave a considerar:
- Almacenamiento en caché – Para mejorar la latencia, el control de costos y la estandarización, puede almacenar en caché el SQL analizado y las solicitudes de consulta reconocidas del LLM de texto a SQL. Esto evita reprocesar consultas repetidas.
- Monitoreo – Se deben recopilar registros y métricas sobre el análisis de consultas, el reconocimiento de solicitudes, la generación de SQL y los resultados de SQL para monitorear el sistema LLM de texto a SQL. Esto proporciona visibilidad para el ejemplo de optimización actualizando el mensaje o revisando el ajuste con un conjunto de datos actualizado.
- Vistas materializadas frente a tablas – Las vistas materializadas pueden simplificar la generación de SQL y mejorar el rendimiento de consultas comunes de texto a SQL. Consultar tablas directamente puede generar SQL complejo y también generar problemas de rendimiento, incluida la creación constante de técnicas de rendimiento como índices. Además, puede evitar problemas de rendimiento cuando se utiliza la misma tabla para otras áreas de aplicación al mismo tiempo.
- Actualizando datos – Las vistas materializadas deben actualizarse según una programación para mantener los datos actualizados para consultas de texto a SQL. Puede utilizar enfoques de actualización incremental o por lotes para equilibrar los gastos generales.
- Catálogo de datos centrales – La creación de un catálogo de datos centralizado proporciona una vista única de las fuentes de datos de una organización y ayudará a los LLM a seleccionar tablas y esquemas apropiados para brindar respuestas más precisas. Vector incrustaciones Los datos creados a partir de un catálogo de datos central se pueden suministrar a un LLM junto con la información solicitada para generar respuestas SQL relevantes y precisas.
Al aplicar las mejores prácticas de optimización, como almacenamiento en caché, monitoreo, vistas materializadas, actualización programada y un catálogo central, puede mejorar significativamente el rendimiento y la eficiencia de los sistemas de texto a SQL mediante LLM.
Patrones de arquitectura
Veamos algunos patrones de arquitectura que se pueden implementar para un flujo de trabajo de texto a SQL.
Ingeniería rápida
El siguiente diagrama ilustra la arquitectura para generar consultas con un LLM mediante ingeniería rápida.
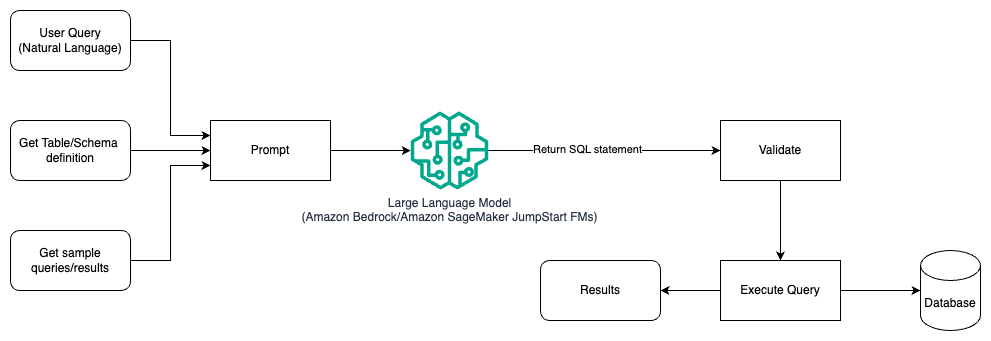
En este patrón, el usuario crea un aprendizaje de pocas oportunidades basado en solicitudes que proporciona al modelo ejemplos anotados en la solicitud misma, que incluye los detalles de la tabla y el esquema y algunas consultas de muestra con sus resultados. El LLM utiliza el mensaje proporcionado para devolver el SQL generado por IA, que se valida y luego se ejecuta en la base de datos para obtener los resultados. Este es el patrón más sencillo para comenzar a utilizar la ingeniería rápida. Para esto, puedes usar lecho rocoso del amazonas or modelos de cimientos in JumpStart de Amazon SageMaker.
En este patrón, el usuario crea un aprendizaje de pocas oportunidades basado en indicaciones que proporciona al modelo ejemplos anotados en la solicitud misma, que incluye los detalles de la tabla y el esquema y algunas consultas de muestra con sus resultados. El LLM utiliza el mensaje proporcionado para devolver el SQL generado por IA que se valida y se ejecuta en la base de datos para obtener los resultados. Este es el patrón más sencillo para comenzar a utilizar la ingeniería rápida. Para esto, puedes usar lecho rocoso del amazonas que es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en IA a través de una única API, junto con un amplio conjunto de capacidades que necesita para crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable. o Modelos de la Fundación JumpStart que ofrece modelos básicos de última generación para casos de uso como redacción de contenido, generación de código, respuesta a preguntas, redacción, resumen, clasificación, recuperación de información y más.
Ingeniería y puesta a punto rápidas
El siguiente diagrama ilustra la arquitectura para generar consultas con un LLM mediante ingeniería rápida y ajuste.
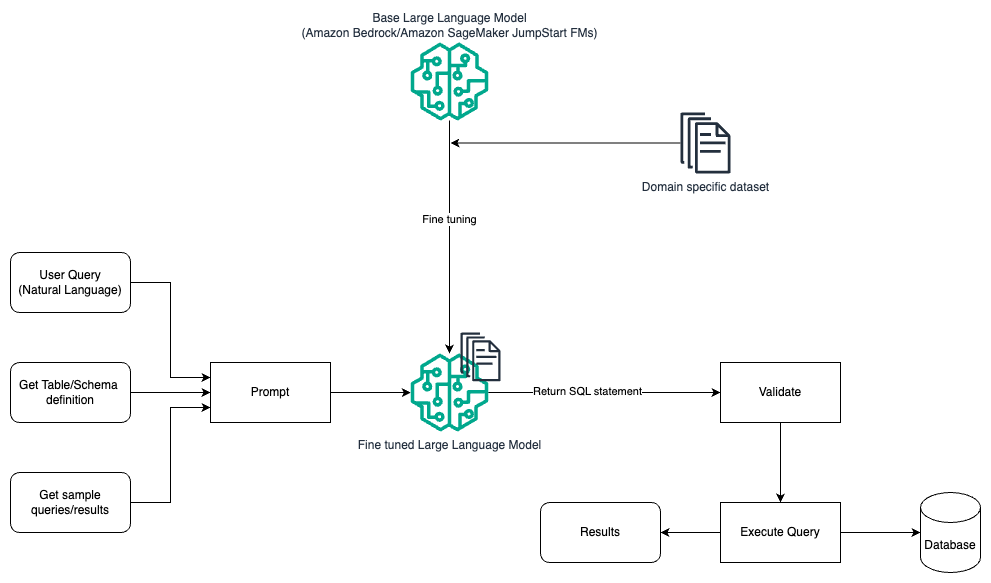
Este flujo es similar al patrón anterior, que se basa principalmente en ingeniería rápida, pero con un flujo adicional de ajuste fino en el conjunto de datos específico del dominio. El LLM ajustado se utiliza para generar consultas SQL con un valor mínimo en contexto para el mensaje. Para esto, puede usar SageMaker JumpStart para ajustar un LLM en un conjunto de datos específico de un dominio de la misma manera que entrenaría e implementaría cualquier modelo en Amazon SageMaker.
Ingeniería rápida y RAG.
El siguiente diagrama ilustra la arquitectura para generar consultas con un LLM utilizando ingeniería rápida y RAG.
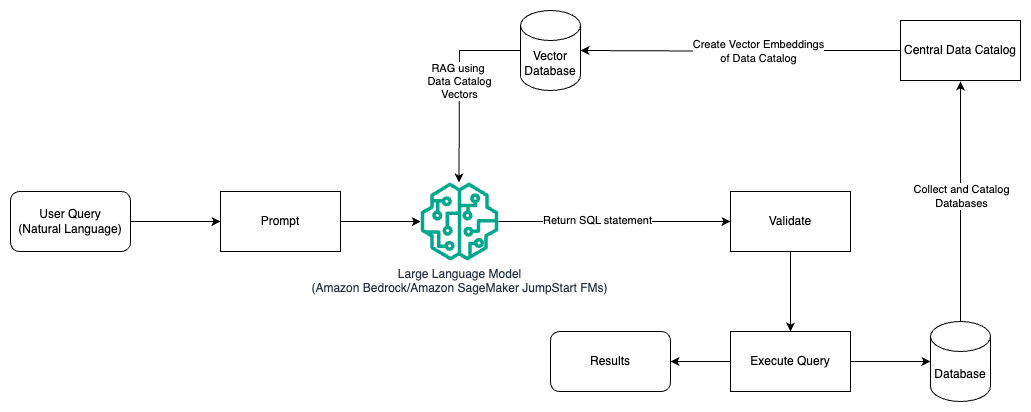
En este patrón utilizamos Recuperación Generación Aumentada usando tiendas de incrustaciones de vectores, como Incrustaciones de Amazon Titan or Cohere Insertar, El lecho rocoso del amazonas de un catálogo de datos central, como Pegamento AWS Catálogo de datos, de bases de datos dentro de una organización. Las incrustaciones de vectores se almacenan en bases de datos de vectores como Motor vectorial para Amazon OpenSearch sin servidor, Servicio de base de datos relacional de Amazon (Amazon RDS) para PostgreSQL con el pgvector extensión, o amazona kendra. Los LLM utilizan incrustaciones de vectores para seleccionar la base de datos, las tablas y las columnas correctas de las tablas más rápido al crear consultas SQL. El uso de RAG es útil cuando los datos y la información relevante que los LLM deben recuperar se almacenan en múltiples sistemas de bases de datos separados y el LLM necesita poder buscar o consultar datos de todos estos sistemas diferentes. Aquí es donde proporcionar incrustaciones de vectores de un catálogo de datos centralizado o unificado a los LLM da como resultado información más precisa y completa devuelta por los LLM.
Conclusión
En esta publicación, analizamos cómo podemos generar valor a partir de datos empresariales utilizando lenguaje natural para la generación de SQL. Analizamos los componentes clave, la optimización y las mejores prácticas. También aprendimos patrones de arquitectura, desde ingeniería básica hasta ajustes finos y RAG. Para obtener más información, consulte lecho rocoso del amazonas para construir y escalar fácilmente aplicaciones de IA generativa con modelos básicos
Acerca de los autores
 Randy DeFauw es un Arquitecto Principal Principal de Soluciones en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión artificial para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el espacio tecnológico, desde ingeniería de software hasta gestión de productos. En ingresó al espacio Big Data en 2013 y continúa explorando esa área. Está trabajando activamente en proyectos en el espacio ML y se ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
Randy DeFauw es un Arquitecto Principal Principal de Soluciones en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión artificial para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el espacio tecnológico, desde ingeniería de software hasta gestión de productos. En ingresó al espacio Big Data en 2013 y continúa explorando esa área. Está trabajando activamente en proyectos en el espacio ML y se ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
 Nitin Eusebio es un arquitecto sénior de soluciones empresariales en AWS, con experiencia en ingeniería de software, arquitectura empresarial e IA/ML. Le apasiona profundamente explorar las posibilidades de la IA generativa. Colabora con los clientes para ayudarlos a crear aplicaciones bien diseñadas en la plataforma AWS y se dedica a resolver desafíos tecnológicos y ayudarlos en su viaje a la nube.
Nitin Eusebio es un arquitecto sénior de soluciones empresariales en AWS, con experiencia en ingeniería de software, arquitectura empresarial e IA/ML. Le apasiona profundamente explorar las posibilidades de la IA generativa. Colabora con los clientes para ayudarlos a crear aplicaciones bien diseñadas en la plataforma AWS y se dedica a resolver desafíos tecnológicos y ayudarlos en su viaje a la nube.
 Arghya Banerjee es un arquitecto sénior de soluciones en AWS en el área de la Bahía de San Francisco y se centra en ayudar a los clientes a adoptar y utilizar la nube de AWS. Arghya se centra en servicios y tecnologías de Big Data, Data Lakes, Streaming, Batch Analytics y AI/ML.
Arghya Banerjee es un arquitecto sénior de soluciones en AWS en el área de la Bahía de San Francisco y se centra en ayudar a los clientes a adoptar y utilizar la nube de AWS. Arghya se centra en servicios y tecnologías de Big Data, Data Lakes, Streaming, Batch Analytics y AI/ML.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

