Tabla de contenidos.
- Preguntas de entrevista de Python para estudiantes de primer año
- 1. ¿Qué es Python?
- 2. ¿Por qué Python?
- 3. ¿Cómo instalar Python?
- 4. ¿Cuáles son las aplicaciones de Python?
- 5. ¿Cuáles son las ventajas de Python?
- 6. ¿Cuáles son las características clave de Python?
- 7. ¿Qué quiere decir con literales de Python?
- 8. ¿Qué tipo de lenguaje es Python?
- 9. ¿Cómo es Python un lenguaje interpretado?
- 10. ¿Qué es pep 8?
- 11. ¿Qué es el espacio de nombres en Python?
- 12. ¿Qué es PYTHON PATH?
- 13. ¿Qué son los módulos de Python?
- 14. ¿Qué son las variables locales y las variables globales en Python?
- 15. Explique qué es Flask y sus beneficios.
- 16. ¿Django es mejor que Flask?
- 17. Mencione las diferencias entre Django, Pyramid y Flask.
- 18. Discutir la arquitectura Django
- 19. ¿Explicar el alcance en Python?
- 20. ¿Enumere los tipos de datos incorporados comunes en Python?
- 21. ¿Qué son los atributos globales, protegidos y privados en Python?
- 22. ¿Qué son las palabras clave en Python?
- 23. ¿Cuál es la diferencia entre listas y tuplas en Python?
- 24. ¿Cómo puedes concatenar dos tuplas?
- 25. ¿Qué son las funciones en Python?
- 26. ¿Cómo puede inicializar una matriz numpy de 5*5 con solo ceros?
- 27. ¿Qué son los pandas?
- 28. ¿Qué son los marcos de datos?
- 29. ¿Qué es una Serie Pandas?
- 30. ¿Qué entiendes por pandas groupby?
- 31. ¿Cómo crear un marco de datos a partir de listas?
- 32. ¿Cómo crear un marco de datos a partir de un diccionario?
- 33. ¿Cómo combinar marcos de datos en pandas?
- 34. ¿Qué tipo de uniones ofrece pandas?
- 35. ¿Cómo fusionar marcos de datos en pandas?
- 36. Proporcione el marco de datos a continuación y suelte todas las filas que tengan Nan.
- 37. ¿Cómo acceder a las primeras cinco entradas de un marco de datos?
- 38. ¿Cómo acceder a las últimas cinco entradas de un marco de datos?
- 39. ¿Cómo obtener una entrada de datos de un marco de datos de pandas usando un valor dado en el índice?
- 40. ¿Qué son los comentarios y cómo puedes agregar comentarios en Python?
- 41. ¿Qué es un diccionario en Python? Dar un ejemplo.
- 42. ¿Cuál es la diferencia entre una tupla y un diccionario?
- 43. Averigüe la media, la mediana y la desviación estándar de esta matriz numpy -> np.array([1,5,3,100,4,48])
- 44. ¿Qué es un clasificador?
- 45. En Python, ¿cómo se convierte una cadena en minúsculas?
- 46. ¿Cómo obtienes una lista de todas las claves en un diccionario?
- 47. ¿Cómo puedes poner en mayúscula la primera letra de una cadena?
- 48. ¿Cómo puedes insertar un elemento en un índice dado en Python?
- 49. ¿Cómo eliminará los elementos duplicados de una lista?
- 50. ¿Qué es la recursividad?
- 51. Explique la comprensión de listas de Python.
- 52. ¿Qué es la función bytes()?
- 53. ¿Cuáles son los diferentes tipos de operadores en Python?
- 54. ¿Qué es la declaración 'with'?
- 55. ¿Qué es una función map() en Python?
- 56. ¿Qué es __init__ en Python?
- 57. ¿Cuáles son las herramientas presentes para realizar el análisis estático?
- 58. ¿Qué es pasar en Python?
- 59. ¿Cómo se puede copiar un objeto en Python?
- 60. ¿Cómo se puede convertir un número en una cadena?
¿Eres un aspirante a desarrollador de Python? Una carrera en Python ha visto una tendencia ascendente en 2023, y puede ser parte de la comunidad en constante crecimiento. Entonces, si está listo para disfrutar del conjunto de conocimientos y estar preparado para la próxima entrevista de Python, entonces está en el lugar correcto.
Hemos compilado una lista completa de preguntas y respuestas de la entrevista de Python que serán útiles en el momento de la necesidad. Una vez que esté preparado con las preguntas que mencionamos en nuestra lista, estará listo para desempeñar numerosos roles de trabajo de Python, como desarrollador de Python, científico de datos, ingeniero de software, administrador de base de datos, probador de control de calidad y más.
La programación de Python puede lograr varias funciones con pocas líneas de código y admite cálculos potentes utilizando bibliotecas potentes. Debido a estos factores, existe un aumento en la demanda de profesionales con conocimientos de programación en Python. Echa un vistazo gratis curso de pitónpara aprender más
Este blog cubre las preguntas de entrevista de Python más frecuentes que lo ayudarán a obtener excelentes ofertas de trabajo.
Las preguntas se dividen en varias categorías, como se indica a continuación:
- Preguntas de entrevista de Python para estudiantes de primer año
- Preguntas de la entrevista de Python para experimentados
- Preguntas de la entrevista de programación de Python
- Preguntas frecuentes sobre las preguntas de la entrevista de Python
Preguntas de entrevista de Python para estudiantes de primer año
Esta sección sobre preguntas de la entrevista de Python para estudiantes de primer año cubre más de 70 preguntas que se hacen comúnmente durante el proceso de la entrevista. Como estudiante de primer año, puede ser nuevo en el proceso de entrevista; sin embargo, aprender estas preguntas lo ayudará a responder al entrevistador con confianza y a triunfar en su próxima entrevista.
1. ¿Qué es Python?
Python fue creado y lanzado por primera vez en 1991 por Guido van Rossum. Es un lenguaje de programación de propósito general y alto nivel que enfatiza la legibilidad del código y proporciona una sintaxis fácil de usar. Varios desarrolladores y programadores prefieren usar Python para sus necesidades de programación debido a su simplicidad. Después de 30 años, Van Rossum renunció como líder de la comunidad en 2018.
Los intérpretes de Python están disponibles para muchos sistemas operativos. CPython, la implementación de referencia de Python, es un software de código abierto y tiene un modelo de desarrollo basado en la comunidad, al igual que casi todas sus variantes de implementación. La Python Software Foundation sin fines de lucro administra Python y CPython.
2. ¿Por qué Python?
Python es un lenguaje de programación de propósito general y alto nivel. Python es un lenguaje de programación que puede usarse para crear aplicaciones GUI de escritorio, sitios web y aplicaciones en línea. Como lenguaje de programación de alto nivel, Python también le permite concentrarse en la funcionalidad esencial de la aplicación mientras maneja las tareas de programación de rutina. Las limitaciones gramaticales básicas del lenguaje de programación hacen que sea considerablemente más fácil mantener el código base inteligible y la aplicación manejable.
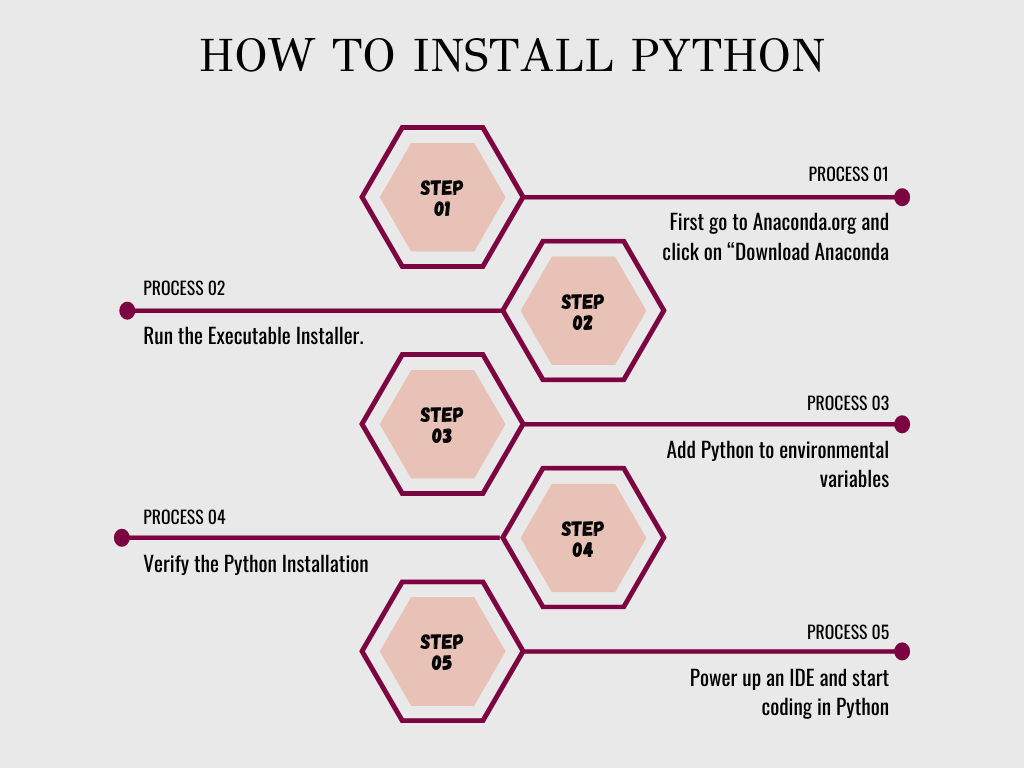
3. ¿Cómo instalar Python?
Para instalar Python, vaya a Anaconda.org y haga clic en "Descargar Anaconda". Aquí puede descargar la última versión de Python. Después de instalar Python, es un proceso bastante sencillo. El siguiente paso es encender un IDE y comenzar a codificar en Python. Si desea obtener más información sobre el proceso, consulte este Tutorial de Phyton. Check out Como instalar python.
Echa un vistazo a esta representación pictórica de la instalación de python.
4. ¿Cuáles son las aplicaciones de Python?
Python destaca por su carácter de propósito general, lo que le permite ser utilizado en prácticamente cualquier sector de desarrollo de software. Python se puede encontrar en casi todos los campos nuevos. Es el lenguaje de programación más popular y se puede utilizar para crear cualquier aplicación.
- Aplicaciones web
Podemos usar Python para desarrollar aplicaciones web. Contiene bibliotecas HTML y XML, bibliotecas JSON, bibliotecas de procesamiento de correo electrónico, bibliotecas de solicitud, hermosa sopa bibliotecas, bibliotecas Feedparser y otros protocolos de Internet. Instagram usa Django, un marco web de Python.
– Aplicaciones GUI de escritorio
La interfaz gráfica de usuario (GUI) es una interfaz de usuario que permite una fácil interacción con cualquier programa. Python contiene el marco Tk GUI para crear interfaces de usuario.
– Aplicación basada en consola
La línea de comandos o shell se utiliza para ejecutar programas basados en consola. Son programas informáticos que se utilizan para realizar pedidos. Este tipo de programa era más común en la generación anterior de computadoras. Es bien conocido por su REPL, o Read-Eval-Print Loop, que lo hace ideal para aplicaciones de línea de comandos.
Python tiene una serie de bibliotecas y módulos gratuitos que ayudan en la creación de aplicaciones de línea de comandos. Para leer y escribir, se utilizan las bibliotecas IO apropiadas. Tiene capacidades para procesar parámetros y generar texto de ayuda de la consola incorporado. Hay bibliotecas avanzadas adicionales que se pueden usar para crear aplicaciones de consola independientes.
- Desarrollo de software
Python es útil para el proceso de desarrollo de software. Es un lenguaje de soporte que se puede usar para establecer control y administración, pruebas y otras cosas.
- Los SCons se utilizan para generar control.
- La compilación y las pruebas continuas se automatizan mediante Buildbot y Apache Gumps.
– Científico y Numérico
Este es el momento de la inteligencia artificial, en el que una máquina puede ejecutar tareas tan bien como una persona. Python es un excelente lenguaje de programación para aplicaciones de inteligencia artificial y aprendizaje automático. Tiene una serie de bibliotecas científicas y matemáticas que simplifican los cálculos difíciles.
Poner en práctica los algoritmos de aprendizaje automático requiere mucha aritmética. Numpy, Pandas, Scipy, Scikit-learn y otros científicos y numéricos Bibliotecas de Python están disponibles. Si sabe cómo usar Python, podrá importar bibliotecas además del código. A continuación se enumeran algunos marcos de biblioteca de máquinas destacados.
- Aplicaciones de negocios
Las aplicaciones estándar no son lo mismo que las aplicaciones comerciales. Este tipo de programa requiere mucha escalabilidad y legibilidad, lo que proporciona Python.
Oddo es una aplicación todo en uno basada en Python que ofrece una amplia gama de aplicaciones comerciales. La aplicación comercial se basa en la plataforma Tryton, proporcionada por Python.
– Aplicaciones basadas en audio o video
Python es un lenguaje de programación versátil que se puede utilizar para construir aplicaciones multimedia. TimPlayer, cplay y otros programas multimedia escritos en Python son ejemplos.
– Aplicaciones CAD 3D
La arquitectura relacionada con la ingeniería se diseña utilizando CAD (diseño asistido por computadora). Se utiliza para crear una visualización tridimensional de un componente del sistema. Las siguientes funciones de Python se pueden utilizar para desarrollar una aplicación CAD 3D:
- Fandango (Popular)
- CAMVOX
- HeeksCNC
- Cualquier CAD
- RCAM
- Aplicaciones empresariales
Python se puede usar para desarrollar aplicaciones para su uso dentro de una empresa u organización. OpenERP, Tryton, Picalo, todas estas aplicaciones en tiempo real son ejemplos.
– Aplicación de procesamiento de imágenes
Python tiene muchas bibliotecas para trabajar con imágenes. La imagen se puede modificar según nuestras especificaciones. OpenCV, Pillow y SimpleITK son bibliotecas de procesamiento de imágenes presentes en python. En este tema, hemos cubierto una amplia gama de aplicaciones en las que Python juega un papel fundamental en su desarrollo. Estudiaremos más sobre los principios de Python en el próximo tutorial.
5. ¿Cuáles son las ventajas de Python?
Python es un lenguaje de programación dinámico de propósito general que es de alto nivel e interpretado. Su marco arquitectónico prioriza la legibilidad del código y utiliza ampliamente la sangría.
- Los módulos de terceros están presentes.
- Varias bibliotecas de soporte están disponibles (NumPy para cálculos numéricos, Pandas para análisis de datos, etc.)
- Desarrollo comunitario y código abierto
- Adaptable, fácil de leer, aprender y escribir
- Estructuras de datos en las que es bastante fácil trabajar
- Lenguaje de alto nivel
- El idioma que se escribe dinámicamente (no es necesario mencionar el tipo de datos según el valor asignado, se necesita el tipo de datos)
- Lenguaje de programación orientado a objetos
- Interactivo y transportable
- Ideal para prototipos ya que le permite agregar funciones adicionales con un código mínimo.
- Muy efectivo
- Posibilidades de Internet de las cosas (IoT)
- Lenguaje interpretado portátil en todos los sistemas operativos
- Dado que es un lenguaje interpretado, ejecuta cualquier código línea por línea y arroja un error si encuentra que falta algo.
- Python es de uso gratuito y tiene una gran comunidad de código abierto.
- Python tiene mucho soporte para bibliotecas que brindan numerosas funciones para realizar cualquier tarea en cuestión.
- Una de las mejores características de Python es su portabilidad: puede ejecutarse y se ejecuta en cualquier plataforma sin tener que cambiar los requisitos.
- Proporciona mucha funcionalidad en líneas de código menores en comparación con otros lenguajes de programación como Java, C++, etc.
Rompe tu entrevista de Python
6. ¿Cuáles son las características clave de Python?
Python es uno de los lenguajes de programación más populares utilizados por los científicos de datos y los profesionales de AIML. Esta popularidad se debe a las siguientes características clave de Python:
- Python es fácil de aprender debido a su clara sintaxis y legibilidad.
- Python es fácil de interpretar, lo que facilita la depuración
- Python es gratuito y de código abierto
- Se puede usar en diferentes idiomas.
- Es un lenguaje orientado a objetos que soporta conceptos de clases.
- Se puede integrar fácilmente con otros lenguajes como C++, Java y más
7. ¿Qué quiere decir con literales de Python?
Un literal es una forma simple y directa de expresar un valor. Los literales reflejan las opciones de tipos primitivos disponibles en ese idioma. Los números enteros, los números de punto flotante, los valores booleanos y las cadenas de caracteres son algunas de las formas más comunes de literales. Python admite los siguientes literales:
Los literales en Python se relacionan con los datos que se mantienen en una variable o constante. Hay varios tipos de literales presentes en Python
Literales de cadena: Es una secuencia de caracteres envueltos en un conjunto de códigos. Dependiendo del número de comillas utilizadas, puede haber cadenas simples, dobles o triples. Los caracteres individuales entre comillas simples o dobles se conocen como caracteres literales.
Literales numéricos: Estos son números inmutables que se pueden dividir en tres tipos: enteros, flotantes y complejos.
Literales booleanos: Se les puede asignar verdadero o falso, que significan '1' y '0', respectivamente.
Literales especiales: Se utiliza para categorizar campos que no han sido generados. 'Ninguno' es el valor que se utiliza para representarlo.
- Literales de cadena: "halo" , '12345'
- Literales enteros: 0,1,2,-1,-2
- Literales largos: 89675L
- Literales flotantes: 3.14
- Literales complejos: 12j
- Literales booleanos: verdadero o falso
- Literales especiales: Ninguno
- Literales Unicode: u"hola"
- Lista de literales: [], [5, 6, 7]
- Literales de tupla: (), (9,), (8, 9, 0)
- Dict literales: {}, {'x':1}
- Establecer literales: {8, 9, 10}
8. ¿Qué tipo de lenguaje es Python?
Python es un lenguaje de programación interpretado, interactivo y orientado a objetos. Están presentes clases, módulos, excepciones, tipos dinámicos y tipos de datos dinámicos de nivel extremadamente alto.
Python es un lenguaje interpretado con escritura dinámica. Debido a que el código no se convierte a un formato binario, estos lenguajes a veces se denominan lenguajes de "secuencias de comandos". Si bien digo tipado dinámicamente, me refiero al hecho de que los tipos no tienen que indicarse al codificar; el intérprete los descubre en tiempo de ejecución.
Se prioriza la legibilidad de la sintaxis concisa y fácil de aprender de Python, lo que reduce los costos de mantenimiento del software. Python proporciona módulos y paquetes, lo que permite la modularidad del programa y la reutilización del código. El intérprete de Python y su completa biblioteca estándar se pueden descargar y distribuir de forma gratuita en formato fuente o binario para todas las plataformas principales.
9. ¿Cómo es Python un lenguaje interpretado?
Un intérprete toma su código y ejecuta (hace) las acciones que proporciona, produce las variables que especifica y realiza una gran cantidad de trabajo detrás de escena para garantizar que funcione sin problemas o le advierte sobre problemas.
Python no es un lenguaje interpretado o compilado. El atributo de la implementación es si se interpreta o se compila. Python es un código de bytes (una colección de instrucciones legibles por un intérprete) que se puede interpretar de varias maneras.
El código fuente se guarda en un Archivo .py.
Python genera un conjunto de instrucciones para una máquina virtual a partir del código fuente. Este formato intermedio se conoce como "código de bytes" y se crea al compilar el código fuente de .py en .pyc, que es el código de bytes. Este código de bytes puede ser interpretado por el intérprete estándar de CPython o el compilador JIT (Just in Time) de PyPy.
Python se conoce como un lenguaje interpretado porque utiliza un intérprete para convertir el código que escribe en un lenguaje que el procesador de su computadora pueda entender. Más tarde descargará y utilizará el intérprete de Python para poder crear código de Python y ejecutarlo en su propia computadora cuando trabaje en un proyecto.
10. ¿Qué es pep 8?
PEP 8, a menudo conocido como PEP8 o PEP-8, es un documento que describe las mejores prácticas y recomendaciones para escribir código Python. Fue escrito en 2001 por Guido van Rossum, Barry Varsovia y Nick Coghlan. El objetivo principal de PEP 8 es hacer que el código de Python sea más legible y consistente.
Python Enhancement Proposal (PEP) es un acrónimo de Python Enhancement Proposal, y hay muchos de ellos. Una propuesta de mejora de Python (PEP) es un documento que explica las nuevas funciones sugeridas para Python y detalla los elementos de Python para la comunidad, como el diseño y el estilo.
11. ¿Qué es el espacio de nombres en Python?
En Python, un espacio de nombres es un sistema que asigna un nombre único a todos y cada uno de los objetos. Una variable o un método podría considerarse un objeto. Python tiene su propio espacio de nombres, que se mantiene en forma de diccionario de Python. Veamos una estructura de sistema de archivos de directorios en una computadora como ejemplo. No hace falta decir que un archivo con el mismo nombre puede encontrarse en numerosas carpetas. Sin embargo, al proporcionar la ruta absoluta del archivo, se puede enrutar a uno si lo desea.
Un espacio de nombres es esencialmente una técnica para garantizar que todos los nombres en un programa sean distintos y puedan usarse indistintamente. Es posible que ya sepa que todo en Python es un objeto, incluidas cadenas, listas, funciones, etc. Otra cosa notable es que Python usa diccionarios para implementar espacios de nombres. Existe un mapeo de nombre a objeto, con los nombres sirviendo como claves y los objetos sirviendo como valores. Muchos espacios de nombres pueden usar el mismo nombre, cada uno de los cuales lo asigna a un objeto distinto. Estos son algunos ejemplos de espacios de nombres:
Espacio de nombres local: Este espacio de nombres almacena los nombres locales de las funciones. Este espacio de nombres se crea cuando se invoca una función y solo vive hasta que la función regresa.
Espacio de nombres global: Los nombres de varios módulos importados que está utilizando en un proyecto se almacenan en este espacio de nombres. Se forma cuando se agrega el módulo al proyecto y dura hasta que se completa el script.
Espacio de nombres integrado: Este espacio de nombres contiene los nombres de funciones integradas y excepciones.
12. ¿Qué es PYTHON PATH?
PYTHONPATH es una variable de entorno que permite al usuario agregar carpetas adicionales a la lista de directorios sys.path para Python. En pocas palabras, es una variable de entorno que se establece antes del inicio del intérprete de Python.
13. ¿Qué son los módulos de Python?
Un módulo de Python es una colección de comandos y definiciones de Python en un solo archivo. En un módulo, puede especificar funciones, clases y variables. Un módulo también puede incluir código ejecutable. Cuando el código está organizado en módulos, es más fácil de entender y usar. También organiza lógicamente el código.
14. ¿Qué son las variables locales y las variables globales en Python?
Las variables locales se declaran dentro de una función y tienen un alcance que se limita solo a esa función, mientras que las variables globales se definen fuera de cualquier función y tienen un alcance global. Para decirlo de otra manera, las variables locales solo están disponibles dentro de la función en la que fueron creadas, pero las variables globales son accesibles a través del programa y de cada función.
Variables locales
Las variables locales son variables que se crean dentro de una función y son exclusivas de esa función. Fuera de la función, no se puede acceder.
Variables globales
Las variables globales son variables que se definen fuera de cualquier función y están disponibles en todo el programa, es decir, tanto dentro como fuera de cada función.
15. Explique qué es Flask y sus beneficios.
Flask es un marco web de código abierto. Frasco es un conjunto de herramientas, marcos y tecnologías para crear aplicaciones en línea. Se utiliza una página web, un wiki, un enorme software de calendario basado en la web o un sitio web comercial para crear esta aplicación web. Flask es un micro-framework, lo que significa que no depende demasiado de otras bibliotecas.
Beneficios:
Hay varias razones convincentes para utilizar Flask como marco de aplicación web. Me gusta-
- Soporte de pruebas unitarias que se incorpora
- Hay un servidor de desarrollo integrado, así como un depurador rápido.
- Envío de solicitudes tranquilas con base Unicode
- Se permite el uso de cookies.
- Plantillas compatibles con WSGI 1.0 jinja2
- Además, el matraz le brinda control total sobre el progreso de su proyecto.
- Función de procesamiento de solicitudes HTTP
- Flask es un marco web ligero y versátil que se puede integrar fácilmente con algunas extensiones.
- Puede usar su dispositivo favorito para conectarse. La API principal para ORM Basic está bien diseñada y organizada.
- Extremadamente adaptable
- En términos de fabricación, el matraz es fácil de usar.
16. ¿Django es mejor que Flask?
Django es más popular porque tiene muchas funciones listas para usar, lo que facilita la creación de aplicaciones complicadas. Django es más adecuado para proyectos más grandes con muchas características. Las características pueden ser excesivas para aplicaciones menores.
Si eres nuevo en la programación web, Flask es un lugar fantástico para comenzar. Muchos sitios web están construidos con Flask y reciben mucho tráfico, aunque no tanto como los sitios web basados en Django. Si desea un control preciso, debe usar el matraz, mientras que un desarrollador de Django se basa en una gran comunidad para producir sitios web únicos.
17. Mencione las diferencias entre Django, Pyramid y Flask.
Flask es un "micro framework" diseñado para aplicaciones más pequeñas con menos requisitos. Pyramid y Django están orientados a proyectos más grandes, pero abordan la extensión y la flexibilidad de diferentes maneras.
Una pirámide está diseñada para ser flexible, lo que permite al desarrollador utilizar las mejores herramientas para su proyecto. Esto significa que el desarrollador puede elegir la base de datos, la estructura de URL, el estilo de plantilla y otras opciones. Django aspira a incluir todas las baterías que requeriría una aplicación web, por lo que los programadores simplemente necesitan abrir la caja y comenzar a trabajar, incorporando los muchos componentes de Django a medida que avanzan.
Django incluye un ORM por defecto, pero Pyramid y Flask proporcionan al desarrollador control sobre cómo (y si) se almacenan sus datos. SQLAlchemy es el ORM más popular para aplicaciones web que no son de Django, pero hay muchas opciones alternativas, que van desde DynamoDB y MongoDB hasta persistencia local simple como LevelDB o SQLite normal. Pyramid está diseñado para trabajar con cualquier tipo de capa de persistencia, incluso aquellas que aún no se han concebido.
| Django | Pirámide | Frasco |
| Es un marco de Python. | Es lo mismo que Django. | Es un micro-marco. |
| Se utiliza para construir aplicaciones grandes. | Es lo mismo que Django. | Se utiliza para crear una pequeña aplicación. |
| Incluye un ORM. | Proporciona flexibilidad y las herramientas adecuadas. | No requiere bibliotecas externas. |
18. Discutir la arquitectura Django
Django tiene una arquitectura MVC (Model-View-Controller), que se divide en tres partes:
1. Modelo
El Modelo, que está representado por una base de datos, es la estructura de datos lógicos que sustenta todo el programa (generalmente bases de datos relacionales como MySql, Postgres).
2. vista
La Vista es la interfaz de usuario, o lo que ve cuando visita un sitio web en su navegador. Se utilizan archivos HTML/CSS/Javascript para representarlos.
3. Controlador
El Controlador es el vínculo entre la vista y el modelo, y es responsable de transferir datos del modelo a la vista.
Su aplicación girará en torno al modelo usando MVC, ya sea mostrándolo o modificándolo.
19. ¿Explicar el alcance en Python?
Piense en alcance como el padre de una familia; cada objeto funciona dentro de un ámbito. Una definición formal sería que este es un bloque de código bajo el cual, sin importar cuántos objetos declares, siguen siendo relevantes. A continuación se dan algunos ejemplos de lo mismo:
- Ámbito local: Cuando crea una variable dentro de una función que pertenece al alcance local de esa función y solo se usará dentro de esa función.
Ejemplo:
def harshit_fun():
y = 100
print (y) harshit_func()
100
- Alcance global: Cuando se crea una variable dentro del cuerpo principal del código Python, se denomina alcance global. La mejor parte del alcance global es que son accesibles dentro de cualquier parte del código Python desde cualquier alcance, ya sea global o local.
Ejemplo:
y = 100 def harshit_func():
print (y)
harshit_func()
print (y)
- Función anidada: Esto también se conoce como una función dentro de una función, como se indica en el ejemplo anterior en el ámbito local, la variable y no está disponible fuera de la función sino dentro de cualquier función dentro de otra función.
Ejemplo:
def first_func():
y = 100
def nested_func1():
print(y)
nested_func1()
first_func()
- Ámbito de nivel de módulo: Esto se refiere esencialmente a los objetos globales del módulo actual accesibles dentro del programa.
- Alcance más externo: Esta es una referencia a todos los nombres incorporados que puede llamar en el programa.
20. ¿Enumere los tipos de datos incorporados comunes en Python?
A continuación se muestran los tipos de datos integrados más utilizados:
Números: Consiste en números enteros, números de coma flotante y números complejos.
Lista: Ya hemos visto un poco sobre las listas, para poner una definición formal, una lista es una secuencia ordenada de elementos que son mutables, también los elementos dentro de las listas pueden pertenecer a diferentes tipos de datos.
Ejemplo:
list = [100, “Great Learning”, 30]Tuplas: Esta también es una secuencia ordenada de elementos, pero a diferencia de las listas, las tuplas son inmutables, lo que significa que no se pueden cambiar una vez declaradas.
Ejemplo:
tup_2 = (100, “Great Learning”, 20) Cuerda: Esto se llama la secuencia de caracteres declarada entre comillas simples o dobles.
Ejemplo:
“Hi, I work at great learning”
‘Hi, I work at great learning’Sets: Los conjuntos son básicamente colecciones de artículos únicos donde el orden no es uniforme.
Ejemplo:
set = {1,2,3}Diccionario: Un diccionario siempre almacena valores en pares de clave y valor donde se puede acceder a cada valor por su clave particular.
Ejemplo:
[12] harshit = {1:’video_games’, 2:’sports’, 3:’content’} Booleano: Solo hay dos valores booleanos: ¿Editas con tu equipo de forma remota? y Falso
21. ¿Qué son los atributos globales, protegidos y privados en Python?
Los atributos de una clase también se denominan variables. Hay tres modificadores de acceso en Python para variables, a saber
una. público - Las variables declaradas como públicas son accesibles desde cualquier lugar, dentro o fuera de la clase.
b. privado - Las variables declaradas como privadas son accesibles solo dentro de la clase actual.
C. protegido - Las variables declaradas como protegidas son accesibles solo dentro del paquete actual.
Los atributos también se clasifican en:
– Atributos locales se definen dentro de un bloque de código/método y solo se puede acceder a ellos dentro de ese bloque de código/método.
– Atributos globales se definen fuera del bloque de código/método y se puede acceder a ellos desde cualquier lugar.
class Mobile:
m1 = "Samsung Mobiles" //Global attributes
def price(self):
m2 = "Costly mobiles" //Local attributes
return m2
Sam_m = Mobile()
print(Sam_m.m1)22. ¿Qué son las palabras clave en Python?
Las palabras clave en Python son palabras reservadas que se utilizan como identificadores, nombres de funciones o nombres de variables. Ayudan a definir la estructura y la sintaxis del lenguaje.
Hay un total de 33 palabras clave en Python 3.7 que pueden cambiar en la próxima versión, es decir, Python 3.8. A continuación se proporciona una lista de todas las palabras clave:
Palabras clave en Python:
| Falso | clase | finalmente | is | volvemos |
| Ninguna | continue | para | lambda | try |
| ¿Editas con tu equipo de forma remota? | def | en | no local | mientras |
| y | de los | global | no | |
| as | elif | if | or | rendimiento |
| afirmar | más | importar | pass | |
| romper | excepto |
23. ¿Cuál es la diferencia entre listas y tuplas en Python?
Lista y tupla son estructuras de datos en Python que puede almacenar uno o más objetos o valores. Usando corchetes, puede crear una lista para contener numerosos objetos en una variable. Las tuplas, como las matrices, pueden contener numerosos elementos en una sola variable y se definen con paréntesis.
| Listas | Tuples |
| Las listas son mutables. | Las tuplas son inmutables. |
| Los impactos de las iteraciones consumen mucho tiempo. | Las iteraciones tienen el efecto de hacer que las cosas vayan más rápido. |
| La lista es más conveniente para acciones como inserción y eliminación. | Se puede acceder a los elementos utilizando el tipo de datos tupla. |
| Las listas ocupan más memoria. | Cuando se compara con una lista, una tupla usa menos memoria. |
| Existen numerosas técnicas integradas en las listas. | No hay muchos métodos integrados en Tuple. |
| Es más probable que ocurran cambios y fallas inesperados. | Es difícil que tenga lugar en una tupla. |
| Consumen mucha memoria dada la naturaleza de esta estructura de datos | Consumen menos memoria |
| Sintaxis: lista = [100, "Gran aprendizaje", 30] |
Sintaxis: tup_2 = (100, “Gran aprendizaje”, 20) |
24. ¿Cómo puedes concatenar dos tuplas?
Digamos que tenemos dos tuplas como esta ->
tup1 = (1,”a”,Verdadero)
tup2 = (4,5,6)
La concatenación de tuplas significa que estamos agregando los elementos de una tupla al final de otra tupla.
Ahora, sigamos adelante y concatenemos tuple2 con tuple1:
Código:
tup1=(1,"a",True)
tup2=(4,5,6)
tup1+tup2Todo lo que tiene que hacer es usar el operador '+' entre las dos tuplas y obtendrá el resultado concatenado.
De manera similar, concatenemos tupla1 con tupla2:
Código:
tup1=(1,"a",True)
tup2=(4,5,6)
tup2+tup1
25. ¿Qué son las funciones en Python?
Respuesta: Las funciones en Python se refieren a bloques que tienen códigos organizados y reutilizables para realizar eventos únicos y relacionados. Las funciones son importantes para crear una mejor modularidad para las aplicaciones que reutilizan un alto grado de codificación. Python tiene una serie de funciones integradas como print(). Sin embargo, también le permite crear funciones definidas por el usuario.
26. ¿Cómo puede inicializar una matriz numpy de 5*5 con solo ceros?
Usaremos el .ceros() método.
import numpy as np
n1=np.zeros((5,5))
n1
Use np.zeros() y pase las dimensiones dentro de él. Como queremos una matriz de 5*5, pasaremos (5,5) dentro del método .zeros().
27. ¿Qué son los pandas?
Pandas es una biblioteca de Python de código abierto que tiene un conjunto muy rico de estructuras de datos para operaciones basadas en datos. Los pandas con sus geniales funciones se adaptan a todos los roles de la operación de datos, ya sea en el ámbito académico o en la resolución de problemas comerciales complejos. Pandas puede manejar una gran variedad de archivos y es una de las herramientas más importantes para controlar.
Obtenga más información sobre los pandas de Python
28. ¿Qué son los marcos de datos?
Un marco de datos de pandas es una estructura de datos en pandas que es mutable. Pandas tiene soporte para datos heterogéneos que se organizan en dos ejes. ( filas y columnas).
Lectura de archivos en pandas: -
| 12 | Importar pandas como pddf=p.read_csv(“mydata.csv”) |
Aquí, df es un marco de datos de pandas. read_csv() se usa para leer un archivo delimitado por comas como un marco de datos en pandas.
29. ¿Qué es una Serie Pandas?
La serie es una estructura de datos de panda unidimensional que puede contener datos de casi cualquier tipo. Se asemeja a una columna de Excel. Admite múltiples operaciones y se utiliza para operaciones de datos unidimensionales.
Crear una serie a partir de datos:
Código:
import pandas as pd
data=["1",2,"three",4.0]
series=pd.Series(data)
print(series)
print(type(series))
30. ¿Qué entiendes por pandas groupby?
Un grupo de pandas es una función compatible con pandas que se utiliza para dividir y agrupar un objeto. Al igual que sql/mysql/oracle groupby, se usa para agrupar datos por clases y entidades que se pueden usar para la agregación. Un marco de datos se puede agrupar por una o más columnas.
Código:
df = pd.DataFrame({'Vehicle':['Etios','Lamborghini','Apache200','Pulsar200'], 'Type':["car","car","motorcycle","motorcycle"]})
df
Para realizar groupby escriba el siguiente código:
df.groupby('Type').count()31. ¿Cómo crear un marco de datos a partir de listas?
Para crear un marco de datos a partir de listas,
1) crear un marco de datos vacío
2) agregar listas como columnas individuales a la lista
Código:
df=pd.DataFrame()
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
df["cars"]=cars
df["bikes"]=bikes
df
32. ¿Cómo crear un marco de datos a partir de un diccionario?
Se puede pasar directamente un diccionario como argumento a la función DataFrame() para crear el marco de datos.
Código:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
df
33. ¿Cómo combinar marcos de datos en pandas?
Las funciones concat(), append() y join() en pandas pueden apilar dos marcos de datos diferentes, ya sea horizontal o verticalmente.
Concat funciona mejor cuando los marcos de datos tienen las mismas columnas y se pueden usar para la concatenación de datos que tienen campos similares y es básicamente un apilamiento vertical de marcos de datos en un solo marco de datos.
Append() se utiliza para el apilamiento horizontal de marcos de datos. Si se van a fusionar dos tablas (marcos de datos), esta es la mejor función de concatenación.
Join se usa cuando necesitamos extraer datos de diferentes marcos de datos que tienen una o más columnas comunes. El apilamiento es horizontal en este caso.
Antes de pasar por las preguntas, aquí hay un video rápido para ayudarlo a refrescar su memoria en Python.
34. ¿Qué tipo de uniones ofrece pandas?
Los pandas tienen una combinación izquierda, una combinación interna, una combinación derecha y una combinación externa.
35. ¿Cómo fusionar marcos de datos en pandas?
La fusión depende del tipo y los campos de los diferentes marcos de datos que se fusionan. Si los datos tienen campos similares, los datos se fusionan a lo largo del eje 0; de lo contrario, se fusionan a lo largo del eje 1.
36. Proporcione el marco de datos a continuación y suelte todas las filas que tengan Nan.
La función dropna se puede usar para hacer eso.
df.dropna(inplace=True)
df37. ¿Cómo acceder a las primeras cinco entradas de un marco de datos?
Al usar la función head(5), podemos obtener las cinco entradas principales de un marco de datos. Por defecto, df.head() devuelve las 5 primeras filas. Para obtener las primeras n filas, se usará df.head(n).
38. ¿Cómo acceder a las últimas cinco entradas de un marco de datos?
Al usar la función tail(5), podemos obtener las cinco entradas principales de un marco de datos. Por defecto, df.tail() devuelve las 5 primeras filas. Para obtener las últimas n filas, se utilizará df.tail(n).
39. ¿Cómo obtener una entrada de datos de un marco de datos de pandas usando un valor dado en el índice?
Para obtener una fila de un marco de datos dado el índice x, podemos usar loc.
Df.loc[10] donde 10 es el valor del índice.
Código:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
a=[10,20,30,40,50]
df.index=a
df.loc[10]
40. ¿Qué son los comentarios y cómo puedes agregar comentarios en Python?
Los comentarios en Python se refieren a un fragmento de texto destinado a la información. Es especialmente relevante cuando más de una persona trabaja en un conjunto de códigos. Se puede usar para analizar código, dejar comentarios y depurarlo. Hay dos tipos de comentarios que incluyen:
- Comentario de una sola línea
- comentario de varias líneas
Códigos necesarios para agregar un comentario
#Nota: comentario de una sola línea
"""Nota
Note
Nota”””—–comentario de varias líneas
41. ¿Qué es un diccionario en Python? Dar un ejemplo.
Un diccionario de Python es una colección de elementos sin ningún orden en particular. Los diccionarios de Python se escriben entre corchetes con claves y valores. Los diccionarios están optimizados para recuperar valores de claves conocidas.
Ejemplo
d={“a”:1,”b”:2}42. ¿Cuál es la diferencia entre un tupla y una ¿diccionario?
Una diferencia importante entre una tupla y un diccionario es que un diccionario es mutable mientras que una tupla no lo es. Lo que significa que el contenido de un diccionario se puede cambiar sin cambiar su identidad, pero en una tupla, eso no es posible.
43. Averigüe la media, la mediana y la desviación estándar de esta matriz numpy -> np.array([1,5,3,100,4,48])
import numpy as np
n1=np.array([10,20,30,40,50,60])
print(np.mean(n1))
print(np.median(n1))
print(np.std(n1))
44. ¿Qué es un clasificador?
Un clasificador se utiliza para predecir la clase de cualquier punto de datos. Los clasificadores son hipótesis especiales que se utilizan para asignar etiquetas de clase a cualquier punto de datos en particular. Un clasificador a menudo usa datos de entrenamiento para comprender la relación entre las variables de entrada y la clase. La clasificación es un método utilizado en el aprendizaje supervisado en Machine Learning.
45. En Python, ¿cómo se convierte una cadena en minúsculas?
Todas las mayúsculas de una cadena se pueden convertir a minúsculas mediante el método: string.lower()
ex:
string = ‘GREATLEARNING’ print(string.lower())o/p: gran aprendizaje
46. ¿Cómo obtienes una lista de todas las claves en un diccionario?
Una de las formas en que podemos obtener una lista de claves es usando: dict.keys()
Este método devuelve todas las claves disponibles en el diccionario.
dict = {1:a, 2:b, 3:c} dict.keys()o/p: [1, 2, 3]
47. ¿Cómo puedes poner en mayúscula la primera letra de una cadena?
Podemos usar el capitalizar() función para poner en mayúscula el primer carácter de una cadena. Si el primer carácter ya está en mayúscula, devuelve la cadena original.
Sintaxis:
string_name.capitalize()
ex:
n = “greatlearning” print(n.capitalize())o/p: Gran aprendizaje
48. ¿Cómo puedes insertar un elemento en un índice dado en Python?
Python tiene una función incorporada llamada función insert().
Se puede usar para insertar un elemento en un índice dado.
Sintaxis:
list_name.insert(index, element)
ex:
list = [ 0,1, 2, 3, 4, 5, 6, 7 ]
#insert 10 at 6th index
list.insert(6, 10)o/p: [0,1,2,3,4,5,10,6,7]
49. ¿Cómo eliminará los elementos duplicados de una lista?
Existen varios métodos para eliminar elementos duplicados de una lista. Pero, el más común es convertir la lista en un conjunto usando la función set() y usando la función list() para volver a convertirla en una lista si es necesario.
ex:
list0 = [2, 6, 4, 7, 4, 6, 7, 2]
list1 = list(set(list0)) print (“The list without duplicates : ” + str(list1))
o/p: La lista sin duplicados: [2, 4, 6, 7]
50. ¿Qué es la recursividad?
La recursividad es una función que se llama a sí misma una o más veces en su cuerpo. Una condición muy importante que debe tener una función recursiva para usarse en un programa es que debe terminar, de lo contrario habría un problema de bucle infinito.
51. Explique la comprensión de listas de Python.
Las listas por comprensión se utilizan para transformar una lista en otra lista. Los elementos se pueden incluir condicionalmente en la nueva lista y cada elemento se puede transformar según sea necesario. Consiste en una expresión que conduce a una cláusula for, encerrada entre paréntesis.
Por ejemplo:
list = [i for i in range(1000)]
print list52. ¿Qué es la función bytes()?
La función bytes() devuelve un objeto de bytes. Se utiliza para convertir objetos en objetos de bytes o crear objetos de bytes vacíos del tamaño especificado.
53. ¿Cuáles son los diferentes tipos de operadores en Python?
Python tiene los siguientes operadores básicos:
Aritmética (Suma (+), Resta (-), Multiplicación (*), División (/), Módulo (%) ), Relacional (<, >, <=, >=, ==, !=, ),
Asignación (=. +=, -=, /=, *=, %=),
lógico (y, o no), Membresía, Identidad y Operadores bit a bit
54. ¿Qué es la declaración 'with'?
La declaración "with" en python se usa en el manejo de excepciones. Un archivo se puede abrir y cerrar mientras se ejecuta un bloque de código, que contiene la instrucción "with", sin utilizar la función close(). Básicamente, hace que el código sea mucho más fácil de leer.
55. ¿Qué es una función map() en Python?
La función map() en Python se usa para aplicar una función en todos los elementos de un iterable especificado. Consta de dos parámetros, función e iterable. La función se toma como argumento y luego se aplica a todos los elementos de un iterable (se pasa como el segundo argumento). Como resultado, se devuelve una lista de objetos.
def add(n):
return n + n number= (15, 25, 35, 45)
res= map(add, num)
print(list(res))
sobre: 30,50,70,90
56. ¿Qué es __init__ en Python?
La metodología _init_ es un método reservado en Python, también conocido como constructor en OOP. Cuando se crea un objeto a partir de una clase y se llama a la metodología _init_ para acceder a los atributos de la clase.
Lea también Python __init__- Una visión general
57. ¿Cuáles son las herramientas presentes para realizar el análisis estático?
Las dos herramientas de análisis estático utilizadas para encontrar errores en Python son Pychecker y Pylint. Pychecker detecta errores del código fuente y advierte sobre su estilo y complejidad. Mientras que Pylint verifica si el módulo coincide con un estándar de codificación.
58. ¿Qué es pasar en Python?
Pass es una declaración que no hace nada cuando se ejecuta. En otras palabras, es una sentencia nula. El intérprete no ignora esta declaración, pero la declaración no da como resultado ninguna operación. Se usa cuando no desea que se ejecute ningún comando pero se requiere una declaración.
59. ¿Cómo se puede copiar un objeto en Python?
No todos los objetos se pueden copiar en Python, pero la mayoría sí. Podemos usar el operador "=" para copiar un objeto a una variable.
ex:
var=copy.copy(obj)60. ¿Cómo se puede convertir un número en una cadena?
La función incorporada str() se puede usar para convertir un número en una cadena.
61. ¿Qué son los módulos y paquetes en Python?
Los módulos son la forma de estructurar un programa. Cada archivo de programa de Python es un módulo que importa otros atributos y objetos. La carpeta de un programa es un paquete de módulos. Un paquete puede tener módulos o subcarpetas.
62. ¿Qué es la función object() en Python?
En Python, la función object() devuelve un objeto vacío. No se pueden agregar nuevas propiedades o métodos a este objeto.
63. ¿Cuál es la diferencia entre NumPy y SciPy?
NumPy significa Numerical Python mientras que SciPy significa Scientific Python. NumPy es la biblioteca básica para definir matrices y problemas matemáticos simples, mientras que SciPy se usa para problemas más complejos como integración y optimización numérica y aprendizaje automático, etc.
64. ¿Qué hace len()?
len() se usa para determinar la longitud de una cadena, una lista, una matriz, etc.
ex:
str = “greatlearning”
print(len(str))
sobre: 13
65. ¿Define la encapsulación en Python?
La encapsulación significa unir el código y los datos. Una clase de Python por ejemplo.
66. ¿Qué es el tipo () en Python?
type() es un método incorporado que devuelve el tipo del objeto o devuelve un nuevo tipo de objeto basado en los argumentos pasados.
ex:
a = 100
type(a)operación: int
67. ¿Para qué se usa la función split()?
La función de división se usa para dividir una cadena en cadenas más cortas usando separadores definidos.
letters= ('' A, B, C”)
n = text.split(“,”)
print(n)o/p: ['A', 'B', 'C' ]
68. ¿Cuáles son los tipos integrados que proporciona Python?
Python tiene los siguientes tipos de datos integrados:
Números: Python identifica tres tipos de números:
- Entero: Todos los números positivos y negativos sin una parte fraccionaria
- Flotante: cualquier número real con representación de punto flotante
- Números complejos: Un número con un componente real e imaginario representado como x+yj. x e y son flotantes y j es -1 (la raíz cuadrada de -1 se llama un número imaginario)
Boolean: El tipo de datos booleano es un tipo de datos que tiene uno de dos valores posibles, es decir, verdadero o falso. Tenga en cuenta que 'T' y 'F' son letras mayúsculas.
Cuerda: Un valor de cadena es una colección de uno o más caracteres entre comillas simples, dobles o triples.
Lista: Un objeto de lista es una colección ordenada de uno o más elementos de datos que pueden ser de diferentes tipos, puestos entre corchetes. Una lista es mutable y, por lo tanto, se puede modificar, podemos agregar, editar o eliminar elementos individuales en una lista.
Conjunto: Una colección desordenada de objetos únicos encerrados entre corchetes
Conjunto congelado: Son como un conjunto pero inmutables, lo que significa que no podemos modificar sus valores una vez creados.
Diccionario: Es un objeto de diccionario desordenado en el que hay una clave asociada a cada valor y podemos acceder a cada valor a través de su clave. Una colección de tales pares está encerrada entre corchetes. Por ejemplo {'First Name': 'Tom', 'last name': 'Hardy'} Tenga en cuenta que los valores numéricos, las cadenas y las tuplas son inmutables, mientras que los objetos List o Dictionary son mutables.
69. ¿Qué es la cadena de documentación en Python?
Las cadenas de documentación de Python son cadenas literales encerradas entre comillas triples que aparecen justo después de la definición de una función, método, clase o módulo. Estos se utilizan generalmente para describir la funcionalidad de una función, método, clase o módulo en particular. Podemos acceder a estas cadenas de documentos usando el atributo __doc__.
Aquí hay un ejemplo:
def square(n): '''Takes in a number n, returns the square of n''' return n**2
print(square.__doc__)
Salida: Toma un número n, devuelve el cuadrado de n.
70. ¿Cómo invertir una cadena en Python?
En Python, no hay funciones integradas que nos ayuden a invertir una cadena. Necesitamos hacer uso de una operación de corte de matriz para lo mismo.
| 1 | str_reverse = cadena[::-1] |
Aprende más: Cómo invertir una cadena en Python
71. ¿Cómo comprobar la versión de Python en CMD?
Para verificar la versión de Python en CMD, presione CMD + Espacio. Esto abre Spotlight. Aquí, escriba "terminal" y presione enter. Para ejecutar el comando, escriba python –version o python -V y presione enter. Esto devolverá la versión de python en la siguiente línea debajo del comando.
72. ¿Python distingue entre mayúsculas y minúsculas cuando se trata de identificadores?
Sí. Python distingue entre mayúsculas y minúsculas cuando se trata de identificadores. Es un lenguaje que distingue entre mayúsculas y minúsculas. Así, variable y Variable no serían lo mismo.
Preguntas de la entrevista de Python para experimentados
Esta sección sobre Preguntas de entrevista de Python para experimentados cubre más de 20 preguntas que se hacen comúnmente durante el proceso de entrevista para conseguir un trabajo como profesional con experiencia en Python. Estas preguntas frecuentes pueden ayudarlo a mejorar sus habilidades y saber qué esperar en sus próximas entrevistas.
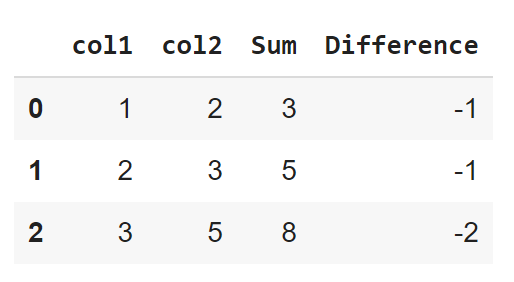
73. ¿Cómo crear una nueva columna en pandas usando valores de otras columnas?
Podemos realizar operaciones matemáticas basadas en columnas en un marco de datos de pandas. Los operadores pueden operar sobre las columnas de Pandas que contienen valores numéricos.
Código:
import pandas as pd
a=[1,2,3]
b=[2,3,5]
d={"col1":a,"col2":b}
df=pd.DataFrame(d)
df["Sum"]=df["col1"]+df["col2"]
df["Difference"]=df["col1"]-df["col2"]
dfSalida:
74. ¿Cuáles son las diferentes funciones que puede usar grouby en pandas?
gruby() en pandas se puede usar con múltiples funciones agregadas. Algunos de los cuales son sum(), mean(), count(), std().
Los datos se dividen en grupos basados en categorías y luego los datos en estos grupos individuales pueden ser agregados por las funciones antes mencionadas.
75. ¿Cómo eliminar una columna o grupo de columnas en pandas? Dada la siguiente columna desplegable del marco de datos "col1".
La función drop() se puede usar para eliminar las columnas de un marco de datos.
d={"col1":[1,2,3],"col2":["A","B","C"]}
df=pd.DataFrame(d)
df=df.drop(["col1"],axis=1)
df
76. Dado el siguiente marco de datos, suelte filas que tengan valores de columna como A.
Código:
d={"col1":[1,2,3],"col2":["A","B","C"]}
df=pd.DataFrame(d)
df.dropna(inplace=True)
df=df[df.col1!=1]
df
77. ¿Qué es la reindexación en pandas?
La reindexación es el proceso de reasignación del índice de un marco de datos de pandas.
Código:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
a=[10,20,30,40,50]
df.index=a
df
78. ¿Qué entiendes sobre la función lambda? Cree una función lambda que imprimirá la suma de todos los elementos en esta lista -> [5, 8, 10, 20, 50, 100]
Las funciones Lambda son funciones anónimas en Python. Se definen utilizando la palabra clave lambda. Las funciones Lambda pueden tomar cualquier cantidad de argumentos, pero solo pueden tener una expresión.
from functools import reduce
sequences = [5, 8, 10, 20, 50, 100]
sum = reduce (lambda x, y: x+y, sequences)
print(sum)
79. ¿Qué es vstack() en numpy? Dar un ejemplo.
vstack() es una función para alinear filas verticalmente. Todas las filas deben tener el mismo número de elementos.
Código:
import numpy as np
n1=np.array([10,20,30,40,50])
n2=np.array([50,60,70,80,90])
print(np.vstack((n1,n2)))
80. ¿Cómo eliminar espacios de una cadena en Python?
Los espacios se pueden eliminar de una cadena en python usando las funciones strip() o replace(). La función Strip() se usa para eliminar los espacios en blanco iniciales y finales, mientras que la función replace() se usa para eliminar todos los espacios en blanco de la cadena:
string.replace(” “,””) ex1: str1= “great learning”
print (str.strip())
o/p: great learning
ex2: str2=”great learning”
print (str.replace(” “,””))
o/p: gran aprendizaje
81. Explique los modos de procesamiento de archivos que admite Python.
Hay tres modos de procesamiento de archivos en Python: solo lectura (r), solo escritura (w), lectura y escritura (rw) y agregar (a). Entonces, si está abriendo un archivo de texto, por ejemplo, en modo de lectura. Los modos anteriores se convierten en "rt" para solo lectura, "wt" para escritura, etc. De manera similar, un archivo binario se puede abrir especificando "b" junto con los indicadores de acceso al archivo ("r", "w", "rw" y "a") que lo preceden.
82. ¿Qué es el decapado y decapado?
El decapado es el proceso de convertir una jerarquía de objetos de Python en un flujo de bytes para almacenarlo en una base de datos. También se conoce como serialización. El decapado es lo contrario del decapado. El flujo de bytes se vuelve a convertir en una jerarquía de objetos.
83. ¿Cómo se gestiona la memoria en Python?
Esta es una de las preguntas de entrevista de Python más frecuentes.
La administración de memoria en Python comprende un montón privado que contiene todos los objetos y la estructura de datos. El montón es administrado por el intérprete y el programador no tiene acceso a él en absoluto. El administrador de memoria de Python hace toda la asignación de memoria. Además, hay un recolector de basura incorporado que recicla y libera memoria para el espacio de almacenamiento dinámico.
84. ¿Qué es unittest en Python?
Unittest es un marco de pruebas unitarias en Python. Admite el uso compartido del código de configuración y apagado para las pruebas, la agregación de pruebas en colecciones, la automatización de pruebas y la independencia de las pruebas del marco de informes.
85. ¿Cómo se elimina un archivo en Python?
Los archivos se pueden eliminar en Python usando el comando os.remove (nombre de archivo) o os.unlink (nombre de archivo)
86. ¿Cómo se crea una clase vacía en Python?
Para crear una clase vacía podemos usar el comando pasar después de la definición del objeto de la clase. Un pase es una declaración en Python que no hace nada.
87. ¿Qué son los decoradores Python?
Los decoradores son funciones que toman otra función como argumento para modificar su comportamiento sin cambiar la función misma. Estos son útiles cuando queremos aumentar dinámicamente la funcionalidad de una función sin cambiarla.
Aquí hay un ejemplo:
def smart_divide(func): def inner(a, b): print("Dividing", a, "by", b) if b == 0: print("Make sure Denominator is not zero") return
return func(a, b) return inner
@smart_divide
def divide(a, b): print(a/b)
divide(1,0)
Aquí smart_divide es una función de decorador que se usa para agregar funcionalidad a la función de división simple.
88. ¿Qué es un lenguaje tipado dinámicamente?
La verificación de tipos es una parte importante de cualquier lenguaje de programación que se trata de garantizar errores de tipo mínimos. El tipo definido para las variables se verifica en tiempo de compilación o en tiempo de ejecución. Cuando la verificación de tipo se realiza en tiempo de compilación, se denomina lenguaje de tipo estático y cuando la verificación de tipo se realiza en tiempo de ejecución, se denomina lenguaje de tipo dinámico.
- En el lenguaje tipado dinámico, los objetos están vinculados con el tipo mediante asignaciones en tiempo de ejecución.
- Los lenguajes de programación tipificados dinámicamente producen código menos optimizado comparativamente
- En los lenguajes tipificados dinámicamente, no es necesario definir los tipos de variables antes de usarlos. Por lo tanto, se puede asignar dinámicamente.
89. ¿Qué es cortar en Python?
Cortar en Python se refiere a acceder a partes de una secuencia. La secuencia puede ser cualquier objeto mutable e iterable. slice() es una función utilizada en Python para dividir la secuencia dada en los segmentos requeridos.
Hay dos variaciones del uso de la función de división. Sintaxis para cortar en python:
- rebanada (inicio, parada)
- sílice (inicio, parada, paso)
por ejemplo:
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
substr1 = slice(3, 5)
print(Str1[substr1])
//same code can be written in the following way also Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
print(Str1[3,5])
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
substr1 = slice(0, 14, 2)
print(Str1[substr1]) //same code can be written in the following way also
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
print(Str1[0,14, 2])
90. ¿Cuál es la diferencia entre Python Arrays y listas?
Python Arrays y List son colecciones ordenadas de elementos y son mutables, pero la diferencia radica en trabajar con ellos.
Los arreglos almacenan datos heterogéneos cuando se importan desde el módulo de arreglos, pero los arreglos pueden almacenar datos homogéneos importados desde el módulo numpy. Pero las listas pueden almacenar datos heterogéneos y, para usar listas, no es necesario importarlas desde ningún módulo.
import array as a1
array1 = a1.array('i', [1 , 2 ,5] )
print (array1)
O,
import numpy as a2
array2 = a2.array([5, 6, 9, 2]) print(array2) - Las matrices deben declararse antes de usarlas, pero no es necesario declarar las listas.
- Las operaciones numéricas son más fáciles de realizar en matrices que en listas.
91. ¿Qué es la resolución de alcance en Python?
La accesibilidad de la variable se define en python de acuerdo con la ubicación de la declaración de la variable, denominada alcance de las variables en python. La resolución de alcance se refiere al orden en que se buscan estas variables para encontrar un nombre para la coincidencia de variables. El siguiente es el alcance definido en python para la declaración de variables.
una. Ámbito local: la variable declarada dentro de un ciclo, el cuerpo de la función es accesible solo dentro de esa función o ciclo.
b. Ámbito global: la variable se declara fuera de cualquier otro código en el nivel superior y se puede acceder a ella desde cualquier lugar.
C. Ámbito envolvente: la variable se declara dentro de una función envolvente, accesible solo dentro de esa función envolvente.
d. Alcance integrado: la variable declarada dentro de las funciones integradas de varios módulos de python tiene el alcance integrado y solo es accesible dentro de ese módulo en particular.
La resolución de alcance para cualquier variable se realiza en java en un orden particular, y ese orden es
Ámbito local -> ámbito adjunto -> ámbito global -> ámbito integrado
92. ¿Qué son las comprensiones de dictados y listas?
Las listas por comprensión proporcionan una forma más compacta y elegante de crear listas que los bucles for, y también se puede crear una nueva lista a partir de listas existentes.
La sintaxis utilizada es la siguiente:
a for a in iterator
O,
a for a in iterator if condition
por ejemplo:
list1 = [a for a in range(5)]
print(list1)
list2 = [a for a in range(5) if a < 3]
print(list2)
Las comprensiones de diccionario proporcionan una forma más compacta y elegante de crear un diccionario y, además, se puede crear un nuevo diccionario a partir de diccionarios existentes.
La sintaxis utilizada es:
{key: expression for an item in iterator}
por ejemplo:
dict([(i, i*2) for i in range(5)])
93. ¿Cuál es la diferencia entre xrange y range en Python?
range() y xrange() son funciones incorporadas en python que se utilizan para generar números enteros en el rango especificado. La diferencia entre los dos se puede entender si se usa la versión 2.0 de python porque la función xrange() de la versión 3.0 de python se vuelve a implementar como la propia función range().
Con respecto a Python 2.0, la diferencia entre la función range y xrange es la siguiente:
- range () toma más memoria comparativamente
- xrange(), la velocidad de ejecución es más rápida comparativamente
- range () devuelve una lista de enteros y xrange() devuelve un objeto generador.
Examplio:
for i in range(1,10,2): print(i) 94. ¿Cuál es la diferencia entre los archivos .py y .pyc?
.py son los archivos de código fuente en python que interpreta el intérprete de python.
.pyc son los archivos compilados que son códigos de bytes generados por el compilador de python, pero los archivos .pyc solo se crean para módulos/archivos incorporados.
Preguntas de la entrevista de programación de Python
Además de tener conocimientos teóricos, tener experiencia práctica y saber programar las preguntas de la entrevista es una parte crucial del proceso de la entrevista. Ayuda a los reclutadores a comprender su experiencia práctica. Estas son más de 45 de las preguntas de entrevista de programación de Python más frecuentes.
Aquí hay una representación pictórica de cómo generar la salida de programación de python.

95. Tienes este conjunto de datos de covid-19 a continuación:
Esta es una de las preguntas de entrevista de Python más frecuentes.
A partir de este conjunto de datos, ¿cómo hará un gráfico de barras para los 5 estados principales que tienen el máximo de casos confirmados al 17=07-2020?
Sol:
#keeping only required columns df = df[[‘Date’, ‘State/UnionTerritory’,’Cured’,’Deaths’,’Confirmed’]] #renaming column names df.columns = [‘date’, ‘state’,’cured’,’deaths’,’confirmed’] #current date today = df[df.date == ‘2020-07-17’] #Sorting data w.r.t number of confirmed cases max_confirmed_cases=today.sort_values(by=”confirmed”,ascending=False) max_confirmed_cases #Getting states with maximum number of confirmed cases top_states_confirmed=max_confirmed_cases[0:5] #Making bar-plot for states with top confirmed cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”confirmed”,data=top_states_confirmed,hue=”state”) plt.show()
Explicación del código:
Comenzamos tomando solo las columnas requeridas con este comando:
df = df[[‘Date’, ‘State/UnionTerritory’,’Cured’,’Deaths’,’Confirmed’]]
Luego, seguimos adelante y renombramos las columnas:
df.columns = [‘date’, ‘state’,’cured’,’deaths’,’confirmed’]
Después de eso, extraemos solo aquellos registros, donde la fecha es igual al 17 de julio:
today = df[df.date == ‘2020-07-17’]
Luego, seguimos adelante y seleccionamos los 5 estados principales con el número máximo. de casos de covid:
max_confirmed_cases=today.sort_values(by=”confirmed”,ascending=False)
max_confirmed_cases
top_states_confirmed=max_confirmed_cases[0:5]
Finalmente, seguimos adelante y hacemos un gráfico de barras con esto:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.barplot(x=”state”,y=”confirmed”,data=top_states_confirmed,hue=”state”)
plt.show()
Aquí, estamos usando la biblioteca seaborn para hacer el diagrama de barras. La columna "Estado" se asigna al eje x y la columna "confirmado" se asigna al eje y. El color de las barras está determinado por la columna "estado".
96. De este conjunto de datos de covid-19:
¿Cómo puedes hacer un gráfico de barras para los 5 estados principales con la mayor cantidad de muertes?
max_death_cases=today.sort_values(by=”deaths”,ascending=False) max_death_cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”deaths”,data=top_states_death,hue=”state”) plt.show()
Explicación del código:
Comenzamos clasificando nuestro marco de datos en orden descendente con la columna "muertes":
max_death_cases=today.sort_values(by=”deaths”,ascending=False)
Max_death_cases
Luego, seguimos adelante y hacemos el gráfico de barras con la ayuda de la biblioteca marina:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.barplot(x=”state”,y=”deaths”,data=top_states_death,hue=”state”)
plt.show()
Aquí, estamos mapeando la columna "estado" en el eje x y la columna "muertes" en el eje y.
97. De este conjunto de datos de covid-19:
¿Cómo se puede hacer un diagrama de líneas que indique los casos confirmados con respecto a la fecha?
Suelo:
maha = df[df.state == ‘Maharashtra’] sns.set(rc={‘figure.figsize’:(15,10)}) sns.lineplot(x=”date”,y=”confirmed”,data=maha,color=”g”) plt.show()
Explicación del código:
Comenzamos extrayendo todos los registros donde el estado es igual a "Maharashtra":
maha = df[df.state == ‘Maharashtra’]
Luego, continuamos y hacemos un gráfico de líneas usando la biblioteca seaborn:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.lineplot(x=”date”,y=”confirmed”,data=maha,color=”g”)
plt.show()
Aquí, mapeamos la columna "fecha" en el eje x y la columna "confirmado" en el eje y.
98. Sobre este conjunto de datos de “Maharashtra”:
¿Cómo implementará un algoritmo de regresión lineal con "fecha" como variable independiente y "confirmado" como variable dependiente? Es decir, debe predecir la cantidad de casos confirmados en la fecha.
from sklearn.model_selection import train_test_split maha[‘date’]=maha[‘date’].map(dt.datetime.toordinal) maha.head() x=maha[‘date’] y=maha[‘confirmed’] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(np.array(x_train).reshape(-1,1),np.array(y_train).reshape(-1,1)) lr.predict(np.array([[737630]]))
Solución de código:
Comenzaremos convirtiendo la fecha a tipo ordinal:
from sklearn.model_selection import train_test_split
maha[‘date’]=maha[‘date’].map(dt.datetime.toordinal)
Esto se hace porque no podemos construir el algoritmo de regresión lineal encima de la columna de fecha.
Luego, continuamos y dividimos el conjunto de datos en conjuntos de entrenamiento y prueba:
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
Finalmente, seguimos adelante y construimos el modelo:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(np.array(x_train).reshape(-1,1),np.array(y_train).reshape(-1,1))
lr.predict(np.array([[737630]]))
99. En este conjunto de datos customer_churn:
Esta es una de las preguntas de entrevista de Python más frecuentes.
¿Cree un modelo secuencial de Keras para averiguar cuántos clientes abandonarán en función de la permanencia del cliente?
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(12, input_dim=1, activation=’relu’)) model.add(Dense(8, activation=’relu’)) model.add(Dense(1, activation=’sigmoid’)) model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) model.fit(x_train, y_train, epochs=150,validation_data=(x_test,y_test)) y_pred = model.predict_classes(x_test) from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_pred)
Explicación del código:
Comenzaremos importando las bibliotecas requeridas:
from Keras.models import Sequential
from Keras.layers import Dense
Luego, seguimos adelante y construimos la estructura del modelo secuencial:
model = Sequential()
model.add(Dense(12, input_dim=1, activation=’relu’))
model.add(Dense(8, activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
Finalmente, seguiremos adelante y predeciremos los valores:
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
model.fit(x_train, y_train, epochs=150,validation_data=(x_test,y_test))
y_pred = model.predict_classes(x_test)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_pred)
100. En este conjunto de datos de iris:
Construya un modelo de clasificación de árboles de decisión, donde la variable dependiente sea "Especie" y la variable independiente sea "Sepal.Length".
y = iris[[‘Species’]] x = iris[[‘Sepal.Length’]] from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.4) from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier() dtc.fit(x_train,y_train) y_pred=dtc.predict(x_test) from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_pred)
(22+7+9)/(22+2+0+7+7+11+1+1+9)
Explicación del código:
Empezamos extrayendo la variable independiente y la variable dependiente:
y = iris[[‘Species’]]
x = iris[[‘Sepal.Length’]]
Luego, continuamos y dividimos los datos en tren y conjunto de prueba:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.4)
Después de eso, seguimos adelante y construimos el modelo:
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(x_train,y_train)
y_pred=dtc.predict(x_test)
Finalmente, construimos la matriz de confusión:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_pred)
(22+7+9)/(22+2+0+7+7+11+1+1+9)
101. En este conjunto de datos de iris:
Construya un modelo de regresión de árbol de decisión donde la variable independiente sea "longitud de pétalo" y la variable dependiente sea "longitud de sépalo".
x= iris[[‘Petal.Length’]] y = iris[[‘Sepal.Length’]] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25) from sklearn.tree import DecisionTreeRegressor dtr = DecisionTreeRegressor() dtr.fit(x_train,y_train) y_pred=dtr.predict(x_test) y_pred[0:5] from sklearn.metrics import mean_squared_error mean_squared_error(y_test,y_pred)
102. ¿Cómo extraerá datos del sitio web "cricbuzz"?
import sys import time from bs4 import BeautifulSoup import requests import pandas as pd try: #use the browser to get the url. This is suspicious command that might blow up. page=requests.get(‘cricbuzz.com’) # this might throw an exception if something goes wrong. except Exception as e: # this describes what to do if an exception is thrown error_type, error_obj, error_info = sys.exc_info() # get the exception information print (‘ERROR FOR LINK:’,url) #print the link that cause the problem print (error_type, ‘Line:’, error_info.tb_lineno) #print error info and line that threw the exception #ignore this page. Abandon this and go back. time.sleep(2) soup=BeautifulSoup(page.text,’html.parser’) links=soup.find_all(‘span’,attrs={‘class’:’w_tle’}) links for i in links: print(i.text) print(“n”)
103. Escriba una función definida por el usuario para implementar el teorema del límite central. Debe implementar el teorema del límite central en este conjunto de datos de "seguro":
También debe construir dos parcelas en "Distribución de muestreo de IMC" y "Distribución de población de IMC".
df = pd.read_csv(‘insurance.csv’) series1 = df.charges series1.dtype def central_limit_theorem(data,n_samples = 1000, sample_size = 500, min_value = 0, max_value = 1338): “”” Use this function to demonstrate Central Limit Theorem. data = 1D array, or a pd.Series n_samples = number of samples to be created sample_size = size of the individual sample min_value = minimum index of the data max_value = maximum index value of the data “”” %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns b = {} for i in range(n_samples): x = np.unique(np.random.randint(min_value, max_value, size = sample_size)) # set of random numbers with a specific size b[i] = data[x].mean() # Mean of each sample c = pd.DataFrame() c[‘sample’] = b.keys() # Sample number c[‘Mean’] = b.values() # mean of that particular sample plt.figure(figsize= (15,5)) plt.subplot(1,2,1) sns.distplot(c.Mean) plt.title(f”Sampling Distribution of bmi. n u03bc = {round(c.Mean.mean(), 3)} & SE = {round(c.Mean.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.subplot(1,2,2) sns.distplot(data) plt.title(f”population Distribution of bmi. n u03bc = {round(data.mean(), 3)} & u03C3 = {round(data.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.show() central_limit_theorem(series1,n_samples = 5000, sample_size = 500)
Explicación del código:
Comenzamos importando el archivo insurance.csv con este comando:
df = pd.read_csv(‘insurance.csv’)
Luego continuamos y definimos el método del teorema del límite central:
def central_limit_theorem(data,n_samples = 1000, sample_size = 500, min_value = 0, max_value = 1338):
Este método consta de estos parámetros:
- Datos
- N_muestras
- Tamaño de la muestra
- Valor_mínimo
- Valor máximo
Dentro de este método, importamos todas las bibliotecas requeridas:
mport pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Luego, continuamos y creamos la primera subparcela para "Distribución de muestreo de bmi":
plt.subplot(1,2,1) sns.distplot(c.Mean) plt.title(f”Sampling Distribution of bmi. n u03bc = {round(c.Mean.mean(), 3)} & SE = {round(c.Mean.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’)
Finalmente, creamos la subparcela para "Distribución de la población del IMC":
plt.subplot(1,2,2) sns.distplot(data) plt.title(f”population Distribution of bmi. n u03bc = {round(data.mean(), 3)} & u03C3 = {round(data.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.show()
104. Escriba código para realizar un análisis de sentimiento en las reseñas de Amazon:
Esta es una de las preguntas de entrevista de Python más frecuentes.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from tensorflow.python.keras import models, layers, optimizers import tensorflow from tensorflow.keras.preprocessing.text import Tokenizer, text_to_word_sequence from tensorflow.keras.preprocessing.sequence import pad_sequences import bz2 from sklearn.metrics import f1_score, roc_auc_score, accuracy_score import re %matplotlib inline def get_labels_and_texts(file): labels = [] texts = [] for line in bz2.BZ2File(file): x = line.decode(“utf-8”) labels.append(int(x[9]) – 1) texts.append(x[10:].strip()) return np.array(labels), texts train_labels, train_texts = get_labels_and_texts(‘train.ft.txt.bz2’) test_labels, test_texts = get_labels_and_texts(‘test.ft.txt.bz2’) Train_labels[0] Train_texts[0] train_labels=train_labels[0:500] train_texts=train_texts[0:500] import re NON_ALPHANUM = re.compile(r'[W]’) NON_ASCII = re.compile(r'[^a-z0-1s]’) def normalize_texts(texts): normalized_texts = [] for text in texts: lower = text.lower() no_punctuation = NON_ALPHANUM.sub(r’ ‘, lower) no_non_ascii = NON_ASCII.sub(r”, no_punctuation) normalized_texts.append(no_non_ascii) return normalized_texts train_texts = normalize_texts(train_texts) test_texts = normalize_texts(test_texts) from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(binary=True) cv.fit(train_texts) X = cv.transform(train_texts) X_test = cv.transform(test_texts) from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split X_train, X_val, y_train, y_val = train_test_split( X, train_labels, train_size = 0.75) for c in [0.01, 0.05, 0.25, 0.5, 1]: lr = LogisticRegression(C=c) lr.fit(X_train, y_train) print (“Accuracy for C=%s: %s” % (c, accuracy_score(y_val, lr.predict(X_val)))) lr.predict(X_test[29])
105. Implemente una gráfica de probabilidad usando numpy y matplotlib:
Sol:
import numpy as np import pylab import scipy.stats as stats from matplotlib import pyplot as plt n1=np.random.normal(loc=0,scale=1,size=1000) np.percentile(n1,100) n1=np.random.normal(loc=20,scale=3,size=100) stats.probplot(n1,dist=”norm”,plot=pylab) plt.show()
106. Implemente una regresión lineal múltiple en este conjunto de datos de iris:
Las variables independientes deben ser "Sepal.Width", "Petal.Length", "Petal.Width", mientras que la variable dependiente debe ser "Sepal.Length".
Suelo:
import pandas as pd iris = pd.read_csv(“iris.csv”) iris.head() x = iris[[‘Sepal.Width’,’Petal.Length’,’Petal.Width’]] y = iris[[‘Sepal.Length’]] from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.35) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(x_train, y_train) y_pred = lr.predict(x_test) from sklearn.metrics import mean_squared_error mean_squared_error(y_test, y_pred)
Solución de código:
Comenzamos importando las bibliotecas requeridas:
import pandas as pd
iris = pd.read_csv(“iris.csv”)
iris.head()
Luego, seguiremos adelante y extraeremos las variables independientes y la variable dependiente:
x = iris[[‘Sepal.Width’,’Petal.Length’,’Petal.Width’]]
y = iris[[‘Sepal.Length’]]
Después de lo cual, dividimos los datos en conjuntos de entrenamiento y prueba:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.35)
Luego, seguimos adelante y construimos el modelo:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x_train, y_train)
y_pred = lr.predict(x_test)
Finalmente, encontraremos el error cuadrático medio:
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_pred)
107. De este conjunto de datos de fraude crediticio:
Encuentre el porcentaje de transacciones que son fraudulentas y no fraudulentas. También construya un modelo de regresión logística, para saber si la transacción es fraudulenta o no.
Suelo:
nfcount=0 notFraud=data_df[‘Class’] for i in range(len(notFraud)): if notFraud[i]==0: nfcount=nfcount+1 nfcount per_nf=(nfcount/len(notFraud))*100 print(‘percentage of total not fraud transaction in the dataset: ‘,per_nf) fcount=0 Fraud=data_df[‘Class’] for i in range(len(Fraud)): if Fraud[i]==1: fcount=fcount+1 fcount per_f=(fcount/len(Fraud))*100 print(‘percentage of total fraud transaction in the dataset: ‘,per_f) x=data_df.drop([‘Class’], axis = 1)#drop the target variable y=data_df[‘Class’] xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size = 0.2, random_state = 42) logisticreg = LogisticRegression() logisticreg.fit(xtrain, ytrain) y_pred = logisticreg.predict(xtest) accuracy= logisticreg.score(xtest,ytest) cm = metrics.confusion_matrix(ytest, y_pred) print(cm)
108. Implemente una CNN simple en el conjunto de datos MNIST usando Keras. Siguiendo esto, también agregue abandono capas.
Suelo:
from __future__ import absolute_import, division, print_function import numpy as np # import keras from tensorflow.keras.datasets import cifar10, mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten, Reshape from tensorflow.keras.layers import Convolution2D, MaxPooling2D from tensorflow.keras import utils import pickle from matplotlib import pyplot as plt import seaborn as sns plt.rcParams[‘figure.figsize’] = (15, 8) %matplotlib inline # Load/Prep the Data (x_train, y_train_num), (x_test, y_test_num) = mnist.load_data() x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype(‘float32’) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype(‘float32’) x_train /= 255 x_test /= 255 y_train = utils.to_categorical(y_train_num, 10) y_test = utils.to_categorical(y_test_num, 10) print(‘— THE DATA —‘) print(‘x_train shape:’, x_train.shape) print(x_train.shape[0], ‘train samples’) print(x_test.shape[0], ‘test samples’) TRAIN = False BATCH_SIZE = 32 EPOCHS = 1 # Define the Type of Model model1 = tf.keras.Sequential() # Flatten Imgaes to Vector model1.add(Reshape((784,), input_shape=(28, 28, 1))) # Layer 1 model1.add(Dense(128, kernel_initializer=’he_normal’, use_bias=True)) model1.add(Activation(“relu”)) # Layer 2 model1.add(Dense(10, kernel_initializer=’he_normal’, use_bias=True)) model1.add(Activation(“softmax”)) # Loss and Optimizer model1.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) # Store Training Results early_stopping = keras.callbacks.EarlyStopping(monitor=’val_acc’, patience=10, verbose=1, mode=’auto’) callback_list = [early_stopping]# [stats, early_stopping] # Train the model model1.fit(x_train, y_train, nb_epoch=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), callbacks=callback_list, verbose=True) #drop-out layers: # Define Model model3 = tf.keras.Sequential() # 1st Conv Layer model3.add(Convolution2D(32, (3, 3), input_shape=(28, 28, 1))) model3.add(Activation(‘relu’)) # 2nd Conv Layer model3.add(Convolution2D(32, (3, 3))) model3.add(Activation(‘relu’)) # Max Pooling model3.add(MaxPooling2D(pool_size=(2,2))) # Dropout model3.add(Dropout(0.25)) # Fully Connected Layer model3.add(Flatten()) model3.add(Dense(128)) model3.add(Activation(‘relu’)) # More Dropout model3.add(Dropout(0.5)) # Prediction Layer model3.add(Dense(10)) model3.add(Activation(‘softmax’)) # Loss and Optimizer model3.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) # Store Training Results early_stopping = tf.keras.callbacks.EarlyStopping(monitor=’val_acc’, patience=7, verbose=1, mode=’auto’) callback_list = [early_stopping] # Train the model model3.fit(x_train, y_train, batch_size=BATCH_SIZE, nb_epoch=EPOCHS, validation_data=(x_test, y_test), callbacks=callback_list)
109. Implemente un sistema de recomendación basado en la popularidad en este conjunto de datos de lentes de películas:
import os import numpy as np import pandas as pd ratings_data = pd.read_csv(“ratings.csv”) ratings_data.head() movie_names = pd.read_csv(“movies.csv”) movie_names.head() movie_data = pd.merge(ratings_data, movie_names, on=’movieId’) movie_data.groupby(‘title’)[‘rating’].mean().head() movie_data.groupby(‘title’)[‘rating’].mean().sort_values(ascending=False).head() movie_data.groupby(‘title’)[‘rating’].count().sort_values(ascending=False).head() ratings_mean_count = pd.DataFrame(movie_data.groupby(‘title’)[‘rating’].mean()) ratings_mean_count.head() ratings_mean_count[‘rating_counts’] = pd.DataFrame(movie_data.groupby(‘title’)[‘rating’].count()) ratings_mean_count.head() 110. Implemente el algoritmo ingenuo de Bayes sobre el conjunto de datos de diabetes:
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) import matplotlib.pyplot as plt # matplotlib.pyplot plots data %matplotlib inline import seaborn as sns pdata = pd.read_csv(“pima-indians-diabetes.csv”) columns = list(pdata)[0:-1] # Excluding Outcome column which has only pdata[columns].hist(stacked=False, bins=100, figsize=(12,30), layout=(14,2)); # Histogram of first 8 columns
Sin embargo, queremos ver una correlación en la representación gráfica, por lo que a continuación se muestra la función para eso:
def plot_corr(df, size=11): corr = df.corr() fig, ax = plt.subplots(figsize=(size, size)) ax.matshow(corr) plt.xticks(range(len(corr.columns)), corr.columns) plt.yticks(range(len(corr.columns)), corr.columns) plot_corr(pdata)
from sklearn.model_selection import train_test_split X = pdata.drop(‘class’,axis=1) # Predictor feature columns (8 X m) Y = pdata[‘class’] # Predicted class (1=True, 0=False) (1 X m) x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=1) # 1 is just any random seed number x_train.head() from sklearn.naive_bayes import GaussianNB # using Gaussian algorithm from Naive Bayes # creatw the model diab_model = GaussianNB() diab_model.fit(x_train, y_train.ravel()) diab_train_predict = diab_model.predict(x_train) from sklearn import metrics print(“Model Accuracy: {0:.4f}”.format(metrics.accuracy_score(y_train, diab_train_predict))) print() diab_test_predict = diab_model.predict(x_test) from sklearn import metrics print(“Model Accuracy: {0:.4f}”.format(metrics.accuracy_score(y_test, diab_test_predict))) print() print(“Confusion Matrix”) cm=metrics.confusion_matrix(y_test, diab_test_predict, labels=[1, 0]) df_cm = pd.DataFrame(cm, index = [i for i in [“1″,”0”]], columns = [i for i in [“Predict 1″,”Predict 0”]]) plt.figure(figsize = (7,5)) sns.heatmap(df_cm, annot=True)
111. ¿Cómo puedes encontrar los valores mínimo y máximo presentes en una tupla?
Solución ->
Podemos usar la función min() encima de la tupla para averiguar el valor mínimo presente en la tupla:
tup1=(1,2,3,4,5)
min(tup1)
Salida
1
Vemos que el valor mínimo presente en la tupla es 1.
Análoga a la función min() es la función max(), que nos ayudará a encontrar el valor máximo presente en la tupla:
tup1=(1,2,3,4,5)
max(tup1)
Salida
5
Vemos que el valor máximo presente en la tupla es 5.
112. Si tiene una lista como esta -> [1,”a”,2,”b”,3,”c”]. ¿Cómo puede acceder a los elementos 2, 4 y 5 de esta lista?
Solución ->
Comenzaremos creando una tupla que comprenderá los índices de los elementos a los que queremos acceder.
Luego, usaremos un bucle for para recorrer los valores del índice e imprimirlos.
A continuación se muestra el código completo para el proceso:
indices = (1,3,4)
for i in indices: print(a[i])
113. Si tienes una lista como esta -> [“sparta”,Verdadero,3+4j,Falso]. ¿Cómo invertirías los elementos de esta lista?
Solución ->
Podemos usar la función reverse() en la lista:
a.reverse()
a
114. Si tiene un diccionario como este – > fruit={“Apple”:10,”Orange”:20,”Banana”:30,”Guava”:40}. ¿Cómo actualizaría el valor de 'Apple' de 10 a 100?
Solución ->
Así es como puedes hacerlo:
fruit["Apple"]=100
fruit
Ingrese el nombre de la clave dentro del paréntesis y asígnele un nuevo valor.
115. Si tienes dos conjuntos como este -> s1 = {1,2,3,4,5,6}, s2 = {5,6,7,8,9}. ¿Cómo encontrarías los elementos comunes en estos conjuntos?
Solución ->
Puede usar la función de intersección () para encontrar los elementos comunes entre los dos conjuntos:
s1 = {1,2,3,4,5,6}
s2 = {5,6,7,8,9}
s1.intersection(s2)
Vemos que los elementos comunes entre los dos conjuntos son 5 y 6.
116. Escriba un programa para imprimir la tabla de 2 utilizando el bucle while.
Solución ->
A continuación se muestra el código para imprimir la tabla de 2:
Código
i=1
n=2
while i<=10: print(n,"*", i, "=", n*i) i=i+1
Salida
Comenzamos inicializando dos variables 'i' y 'n'. 'i' se inicializa en 1 y 'n' se inicializa en '2'.
Dentro del ciclo while, dado que el valor 'i' va de 1 a 10, el ciclo itera 10 veces.
Inicialmente, n*i es igual a 2*1 e imprimimos el valor.
Luego, el valor 'i' se incrementa y n*i se convierte en 2*2. Seguimos adelante y lo imprimimos.
Este proceso continúa hasta que el valor i se convierte en 10.
117. Escribe una función que tome un valor e imprima si es par o impar.
Solución ->
El siguiente código hará el trabajo:
def even_odd(x): if x%2==0: print(x," is even") else: print(x, " is odd")
Aquí, comenzamos creando un método, con el nombre 'even_odd()'. Esta función toma un solo parámetro e imprime si el número tomado es par o impar.
Ahora, invoquemos la función:
even_odd(5)
Vemos que, cuando se pasa 5 como parámetro a la función, obtenemos el resultado -> '5 es impar'.
118. Escriba un programa en Python para imprimir el factorial de un número.
Esta es una de las preguntas de entrevista de Python más frecuentes.
Solución ->
A continuación se muestra el código para imprimir el factorial de un número:
factorial = 1
#check if the number is negative, positive or zero
if num<0: print("Sorry, factorial does not exist for negative numbers")
elif num==0: print("The factorial of 0 is 1")
else for i in range(1,num+1): factorial = factorial*i print("The factorial of",num,"is",factorial)
Comenzamos tomando una entrada que se almacena en 'num'. Luego, verificamos si 'num' es menor que cero y si en realidad es menor que 0, imprimimos 'Lo siento, el factorial no existe para números negativos'.
Después de eso, verificamos si 'num' es igual a cero, y si ese es el caso, imprimimos 'El factorial de 0 es 1'.
Por otro lado, si 'num' es mayor que 1, ingresamos al ciclo for y calculamos el factorial del número.
119. Escribe un programa en python para verificar si el número dado es un palíndromo o no
Solución ->
A continuación se muestra el código para verificar si el número dado es palíndromo o no:
n=int(input("Enter number:"))
temp=n
rev=0
while(n>0) dig=n%10 rev=rev*10+dig n=n//10
if(temp==rev): print("The number is a palindrome!")
else: print("The number isn't a palindrome!")
Comenzaremos tomando una entrada y almacenándola en 'n' y haremos un duplicado de ella en 'temp'. También inicializaremos otra variable 'rev' a 0.
Luego, ingresaremos a un ciclo while que continuará hasta que 'n' se convierta en 0.
Dentro del ciclo, comenzaremos dividiendo 'n' entre 10 y luego almacenaremos el resto en 'dig'.
Luego, multiplicaremos 'rev' por 10 y luego le agregaremos 'dig'. Este resultado se almacenará en 'rev'.
De ahora en adelante, dividiremos 'n' entre 10 y almacenaremos el resultado nuevamente en 'n'
Una vez que termine el bucle for, compararemos los valores de 'rev' y 'temp'. Si son iguales, imprimiremos 'El número es un palíndromo', de lo contrario imprimiremos 'El número no es un palíndromo'.
120. Escriba un programa en python para imprimir el siguiente patrón ->
Esta es una de las preguntas de entrevista de Python más frecuentes:
1
2 2
3 3 3
4 4 4 4
5 5 5 5 5
Solución ->
A continuación se muestra el código para imprimir este patrón:
#10 is the total number to print
for num in range(6): for i in range(num): print(num,end=" ")#print number #new line after each row to display pattern correctly print("n")
Estamos resolviendo el problema con la ayuda del bucle for anidado. Tendremos un bucle for externo, que va del 1 al 5. Luego, tenemos un bucle for interno, que imprimiría los números respectivos.
121. Preguntas de patrones. Imprime el siguiente patrón
#
# #
# # #
# # # #
# # # # #
Solución –>
def pattern_1(num): # outer loop handles the number of rows # inner loop handles the number of columns # n is the number of rows. for i in range(0, n): # value of j depends on i for j in range(0, i+1): # printing hashes print("#",end="") # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_1(num)
122. Imprime el siguiente patrón.
#
# #
# # #
# # # #
# # # # #
Solución –>
Código:
def pattern_2(num): # define the number of spaces k = 2*num - 2 # outer loop always handles the number of rows # let us use the inner loop to control the number of spaces # we need the number of spaces as maximum initially and then decrement it after every iteration for i in range(0, num): for j in range(0, k): print(end=" ") # decrementing k after each loop k = k - 2 # reinitializing the inner loop to keep a track of the number of columns # similar to pattern_1 function for j in range(0, i+1): print("# ", end="") # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_2(num)
123. Imprime el siguiente patrón:
0
0 1
0 1 2
0 1 2 3
0 1 2 3 4
Solución –>
Código:
def pattern_3(num): # initialising starting number number = 1 # outer loop always handles the number of rows # let us use the inner loop to control the number for i in range(0, num): # re assigning number after every iteration # ensure the column starts from 0 number = 0 # inner loop to handle number of columns for j in range(0, i+1): # printing number print(number, end=" ") # increment number column wise number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_3(num)
124. Imprime el siguiente patrón:
1
2 3
4 5 6
7 8 9 10
11 12 13 14 15
Solución –>
Código:
def pattern_4(num): # initialising starting number number = 1 # outer loop always handles the number of rows # let us use the inner loop to control the number for i in range(0, num): # commenting the reinitialization part ensure that numbers are printed continuously # ensure the column starts from 0 number = 0 # inner loop to handle number of columns for j in range(0, i+1): # printing number print(number, end=" ") # increment number column wise number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_4(num)
125. Imprime el siguiente patrón:
A
cama y desayuno
CCC
DDDD
Solución –>
def pattern_5(num): # initializing value of A as 65 # ASCII value equivalent number = 65 # outer loop always handles the number of rows for i in range(0, num): # inner loop handles the number of columns for j in range(0, i+1): # finding the ascii equivalent of the number char = chr(number) # printing char value print(char, end=" ") # incrementing number number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_5(num)
126. Imprime el siguiente patrón:
A
antes de Cristo
DEF
GHIJ
KLMNO
PQRSTU
Solución –>
def pattern_6(num): # initializing value equivalent to 'A' in ASCII # ASCII value number = 65 # outer loop always handles the number of rows for i in range(0, num): # inner loop to handle number of columns # values changing acc. to outer loop for j in range(0, i+1): # explicit conversion of int to char
# returns character equivalent to ASCII. char = chr(number) # printing char value print(char, end=" ") # printing the next character by incrementing number = number +1 # ending line after each row print("r") num = int(input("enter the number of rows in the pattern: "))
pattern_6(num)
127. Imprime el siguiente patrón
#
# #
# # #
# # # #
# # # # #
Solución –>
Código:
def pattern_7(num): # number of spaces is a function of the input num k = 2*num - 2 # outer loop always handle the number of rows for i in range(0, num): # inner loop used to handle the number of spaces for j in range(0, k): print(end=" ") # the variable holding information about number of spaces # is decremented after every iteration k = k - 1 # inner loop reinitialized to handle the number of columns for j in range(0, i+1): # printing hash print("# ", end="") # ending line after each row print("r") num = int(input("Enter the number of rows: "))
pattern_7(n)
128. Si tiene un diccionario como este -> d1={“k1″:10,”k2″:20,”k3”:30}. ¿Cómo incrementaría los valores de todas las claves?
d1={"k1":10,"k2":20,"k3":30} for i in d1.keys(): d1[i]=d1[i]+1
129. ¿Cómo se puede obtener un número aleatorio en python?
Ans. Para generar un aleatorio, usamos un módulo aleatorio de python. Aquí hay algunos ejemplos Para generar un número de coma flotante de 0-1
import random
n = random.random()
print(n)
To generate a integer between a certain range (say from a to b):
import random
n = random.randint(a,b)
print(n)
130. Explique cómo puede configurar la base de datos en Django.
Toda la configuración del proyecto, así como la información de conexión de la base de datos, se encuentran en el archivo settings.py. Django funciona con la base de datos SQLite de manera predeterminada, pero también puede configurarse para operar con otras bases de datos.
La conectividad de la base de datos requiere información de conexión completa, incluido el nombre de la base de datos, las credenciales del usuario, el nombre del host y el nombre de la unidad, entre otras cosas.
Para conectarse a MySQL y establecer una conexión entre la aplicación y la base de datos, use el controlador django.db.backends.mysql.
Toda la información de conexión debe incluirse en el archivo de configuración. El archivo settings.py de nuestro proyecto tiene el siguiente código para la base de datos.
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'djangoApp', 'USER':'root', 'PASSWORD':'mysql', 'HOST':'localhost', 'PORT':'3306' } } Este comando creará tablas para administración, autenticación, tipos de contenido y sesiones. Ahora puede conectarse a la base de datos MySQL seleccionándola del menú desplegable de la base de datos.
131. Dé un ejemplo de cómo puede escribir una VISTA en Django.
La estructura MVT de Django está incompleta sin las vistas de Django. Una función de vista es una función de Python que recibe una solicitud web y entrega una respuesta web, según el manual de Django. Esta respuesta puede ser el contenido HTML de una página web, una redirección, un error 404, un documento XML, una imagen o cualquier otra cosa que pueda mostrar un navegador web.
El HTML/CSS/JavaScript en sus archivos de plantilla se convierte en lo que ve en su navegador cuando muestra una página web usando las vistas de Django, que son parte de la interfaz de usuario. (No combine vistas Django con vistas MVC si ha usado otros marcos MVC (Model-View-Controller).) En Django, las vistas son similares.
# import Http Response from django
from django.http import HttpResponse
# get datetime
import datetime
# create a function
def geeks_view(request): # fetch date and time now = datetime.datetime.now() # convert to string html = "Time is {}".format(now) # return response return HttpResponse(html)
132. ¿Explicar el uso de sesiones en el framework Django?
Django (y gran parte de Internet) usa sesiones para rastrear el "estado" de un sitio y navegador en particular. Las sesiones le permiten guardar cualquier cantidad de datos por navegador y ponerlos a disposición en el sitio cada vez que se conecta el navegador. Los elementos de datos de la sesión se indican mediante una "clave", que se puede utilizar para guardar y recuperar los datos.
Django usa una cookie con una identificación de un solo carácter para identificar cualquier navegador y su sitio web asociado con el sitio web. Los datos de la sesión se almacenan en la base de datos del sitio de forma predeterminada (esto es más seguro que almacenar los datos en una cookie, donde es más vulnerable a los atacantes).
Django le permite almacenar datos de sesión en una variedad de ubicaciones (caché, archivos, cookies "seguras"), pero la ubicación predeterminada es una opción sólida y segura.
Habilitación de sesiones
Cuando creamos el sitio web básico, las sesiones estaban habilitadas de forma predeterminada.
La configuración se establece en el archivo del proyecto (locallibrary/locallibrary/settings.py) en las secciones INSTALLED_APPS y MIDDLEWARE, como se muestra a continuación:
INSTALLED_APPS = [ ... 'django.contrib.sessions', ....
MIDDLEWARE = [ ... 'django.contrib.sessions.middleware.SessionMiddleware', …
Usar sesiones
El parámetro de solicitud le da acceso a la propiedad de sesión de la vista (un HttpRequest pasado como el primer argumento de la vista). La identificación de sesión en la cookie del navegador para este sitio identifica la conexión particular con el usuario actual (o, para ser más exactos, la conexión con el navegador actual).
Los activos de la sesión son un elemento similar a un diccionario que puede examinar y escribir con la frecuencia que necesite en su vista, actualizándolo a medida que avanza. Puede realizar todas las acciones estándar del diccionario, como borrar todos los datos, probar la presencia de una clave, recorrer los datos, etc. Sin embargo, la mayoría de las veces, simplemente obtendrá y establecerá valores utilizando la API de "diccionario" habitual.
Los segmentos de código a continuación muestran cómo obtener, cambiar y eliminar datos vinculados con la sesión actual usando la tecla "mi bicicleta" (navegador).
Nota: una de las mejores cosas de Django es que no tiene que preocuparse por los mecanismos que cree que conectan la sesión con la solicitud actual. Si usáramos los fragmentos a continuación en nuestra vista, sabríamos que la información sobre my_bike está asociada solo con el navegador que envió la solicitud actual.
# Get a session value via its key (for example ‘my_bike’), raising a KeyError if the key is not present my_bike= request.session[‘my_bike’]
# Get a session value, setting a default value if it is not present ( ‘mini’)
my_bike= request.session.get(‘my_bike’, ‘mini’)
# Set a session value
request.session[‘my_bike’] = ‘mini’
# Delete a session value
del request.session[‘my_bike’]
Hay una variedad de métodos diferentes disponibles en la API, la mayoría de los cuales se utilizan para controlar la cookie de sesión vinculada. Hay formas de verificar si el navegador del cliente admite cookies, establecer y verificar las fechas de caducidad de las cookies y eliminar las sesiones caducadas del almacén de datos, por ejemplo. Cómo utilizar las sesiones tiene más información sobre toda la API (documentos de Django).
133. Enumere los estilos de herencia en Django.
Clases base abstractas: los desarrolladores utilizan este patrón de herencia cuando desean que la clase principal conserve los datos que no desean escribir para cada modelo secundario.
models.py
from django.db import models # Create your models here. class ContactInfo(models.Model): name=models.CharField(max_length=20) email=models.EmailField(max_length=20) address=models.TextField(max_length=20) class Meta: abstract=True class Customer(ContactInfo): phone=models.IntegerField(max_length=15) class Staff(ContactInfo): position=models.CharField(max_length=10) admin.py
admin.site.register(Customer)
admin.site.register(Staff)
Se forman dos tablas en la base de datos cuando transferimos estas modificaciones. Tenemos campos para nombre, correo electrónico, dirección y teléfono en la tabla de clientes. Tenemos campos para nombre, correo electrónico, dirección y puesto en Staff Table. La tabla no es una clase base que se crea en esta herencia.
Herencia de tablas múltiples: se utiliza cuando desea subclasificar un modelo existente y hacer que cada una de las subclases tenga su propia tabla de base de datos.
model.py
from django.db import models # Create your models here. class Place(models.Model): name=models.CharField(max_length=20) address=models.TextField(max_length=20) def __str__(self): return self.name class Restaurants(Place): serves_pizza=models.BooleanField(default=False) serves_pasta=models.BooleanField(default=False) def __str__(self): return self.serves_pasta admin.py from django.contrib import admin
from .models import Place,Restaurants
# Register your models here. admin.site.register(Place)
admin.site.register(Restaurants)
Modelos proxy: este enfoque de herencia permite al usuario cambiar el comportamiento en el nivel básico sin cambiar el campo del modelo.
Esta técnica se usa si solo desea cambiar el comportamiento del nivel de Python del modelo y no los campos del modelo. Con la excepción de los campos, hereda de la clase base y puede agregar sus propias propiedades.
- Las clases abstractas no deben usarse como clases base.
- La herencia múltiple no es posible en modelos proxy.
El objetivo principal de esto es reemplazar las funciones clave del modelo anterior. Siempre utiliza métodos anulados para consultar el modelo original.
134. ¿Cómo se puede obtener la antigüedad de caché de Google de cualquier URL o página web?
Usa la URL
https://webcache.googleusercontent.com/search?q=cache:<your url without “http://”>
Ejemplo:
Contiene un encabezado como este:
Este es el caché de Google de https://stackoverflow.com/. Es una captura de pantalla de la página a las 11:33:38 GMT del 21 de agosto de 2012. Mientras tanto, es posible que la página actual haya cambiado.
Sugerencia: use la barra de búsqueda y presione Ctrl+F o ⌘+F (Mac) para encontrar rápidamente su palabra de búsqueda en esta página.
Tendrá que raspar la página resultante, sin embargo, la página de caché más actual se puede encontrar en esta URL:
http://webcache.googleusercontent.com/search?q=cache:www.something.com/path
El primer div en la etiqueta del cuerpo contiene información de Google.
puede usar el sitio web CachedPages
Las grandes empresas con servidores web sofisticados normalmente conservan y conservan las páginas en caché. Debido a que dichos servidores suelen ser bastante rápidos, una página almacenada en caché con frecuencia se puede recuperar más rápido que el sitio web en vivo:
- Google generalmente conserva una copia actual de la página (de 1 a 15 días).
- Coral también conserva una copia actual, aunque no tan actualizada como la de Google.
- Puede acceder a varias versiones de una página web conservada a lo largo del tiempo utilizando Archive.org.
Entonces, la próxima vez que no pueda acceder a un sitio web pero aún quiera verlo, la versión de caché de Google podría ser una buena opción. Primero, determine si la edad es importante o no.
135. ¿Explicar brevemente sobre los espacios de nombres de Python?
Un espacio de nombres en python habla sobre el nombre que se asigna a cada objeto en Python. Los espacios de nombres se conservan en python como un diccionario donde la clave del diccionario es el espacio de nombres y el valor es la dirección de ese objeto.
Los diferentes tipos son los siguientes:
- Espacio de nombres integrado: espacios de nombres que contienen todos los objetos integrados en python.
- Espacio de nombres global: espacios de nombres que consisten en todos los objetos creados cuando llama a su programa principal.
- Espacio de nombres adjunto: espacios de nombres en la palanca superior.
- Espacio de nombres local: espacios de nombres dentro de las funciones locales.
136. Explique brevemente las declaraciones Break, Pass y Continue en Python.
Interrupción: cuando usamos una instrucción de interrupción en un código/programa de Python, inmediatamente interrumpe/termina el ciclo y el flujo de control se devuelve a la instrucción después del cuerpo del ciclo.
Continuar: cuando usamos una declaración de continuación en un código/programa de python, inmediatamente interrumpe/termina la iteración actual de la declaración y también omite el resto del programa en la iteración actual y controla los flujos a la siguiente iteración del bucle.
Pase: cuando usamos una declaración de pase en un código/programa de python, llena los espacios vacíos en el programa.
Ejemplo:
GL = [10, 30, 20, 100, 212, 33, 13, 50, 60, 70]
for g in GL:
pass
if (g == 0):
current = g
break
elif(g%2==0):
continue
print(g) # output => 1 3 1 3 1 print(current)
137. Dame un ejemplo de cómo puedes convertir una lista en una cadena.
El siguiente ejemplo muestra cómo convertir una lista en una cadena. Cuando convertimos una lista en una cadena, podemos hacer uso de la función ".join" para hacer lo mismo.
fruits = [ ‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
listAsString = ‘ ‘.join(fruits)
print(listAsString)
manzana naranja mango papaya guayaba
138. Dame un ejemplo en el que puedas convertir una lista en una tupla.
El siguiente ejemplo muestra cómo convertir una lista en una tupla. Cuando convertimos una lista en una tupla podemos hacer uso de la función, pero recuerde que, dado que las tuplas son inmutables, no podemos volver a convertirlo en una lista.
fruits = [‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
listAsTuple = tuple(fruits)
print(listAsTuple)
('manzana', 'naranja', 'mango', 'papaya', 'guayaba')
139. ¿Cómo se cuentan las ocurrencias de un elemento particular en la lista?
En la estructura de datos de la lista de python contamos el número de ocurrencias de un elemento usando la función count().
fruits = [‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
print(fruits.count(‘apple’))
Salida: 1
140. ¿Cómo se depura un programa de python?
Hay varias formas de depurar un programa de Python:
- Usando el
printdeclaración para imprimir variables y resultados intermedios a la consola - Usando un depurador como
pdboripdb - Adición
assertdeclaraciones al código para verificar ciertas condiciones
141. ¿Cuál es la diferencia entre una lista y una tupla en Python?
Una lista es un tipo de datos mutable, lo que significa que se puede modificar después de crearla. Una tupla es inmutable, lo que significa que no se puede modificar después de crearla. Esto hace que las tuplas sean más rápidas y seguras que las listas, ya que otras partes del código no pueden modificarlas accidentalmente.
142. ¿Cómo maneja las excepciones en Python?
Las excepciones en Python se pueden manejar usando un try–except cuadra. Por ejemplo:
Copiar códigotry: # code that may raise an exception
except SomeExceptionType: # code to handle the exception
143. ¿Cómo se invierte una cadena en Python?
Hay varias formas de invertir una cadena en Python:
- Usando una rebanada con un paso de -1:
Copiar códigostring = "abcdefg"
reversed_string = string[::-1]
- Usando el
reversedfunción:
Copiar códigostring = "abcdefg"
reversed_string = "".join(reversed(string))
- Usando un bucle for:
Copiar códigostring = "abcdefg"
reversed_string = ""
for char in string: reversed_string = char + reversed_string
144. ¿Cómo se ordena una lista en Python?
Hay varias formas de ordenar una lista en Python:
- Usando el
sortmétodo:
Copiar códigomy_list = [3, 4, 1, 2]
my_list.sort()
- Usando el
sortedfunción:
Copiar códigomy_list = [3, 4, 1, 2]
sorted_list = sorted(my_list)
- Usando el
sortfuncionar desde eloperatormódulo:
Copiar códigofrom operator import itemgetter my_list = [{"a": 3}, {"a": 1}, {"a": 2}]
sorted_list = sorted(my_list, key=itemgetter("a"))
145. ¿Cómo se crea un diccionario en Python?
Hay varias formas de crear un diccionario en Python:
- Uso de llaves y dos puntos para separar claves y valores:
Copiar códigomy_dict = {"key1": "value1", "key2": "value2"}
- Usando el
dictfunción:
Copiar códigomy_dict = dict(key1="value1", key2="value2")
- Usando el
dictconstructor:
Copiar códigomy_dict = dict({"key1": "value1", "key2": "value2"})
Pregunta 1. ¿Cómo se destaca en una entrevista de codificación de Python?
Ahora que está listo para una entrevista de Python en términos de habilidades técnicas, debe preguntarse cómo sobresalir entre la multitud para ser el candidato seleccionado. Debe poder demostrar que puede escribir códigos de producción limpios y tener conocimiento sobre las bibliotecas y las herramientas necesarias. Si ha trabajado en proyectos anteriores, mostrar estos proyectos en su entrevista también lo ayudará a destacarse del resto de la multitud.
Lea también Principales preguntas comunes de la entrevista
Pregunta 2. ¿Cómo me preparo para una entrevista de Python?
Para prepararse para una entrevista de Python, debe conocer la sintaxis, las palabras clave, las funciones y clases, los tipos de datos, la codificación básica y el manejo de excepciones. Tener un conocimiento básico de todas las bibliotecas e IDE utilizados y leer blogs relacionados con Python Tutorial lo ayudará. Muestre sus proyectos de ejemplo, repase sus habilidades básicas sobre algoritmos y tal vez tome un curso gratuito sobre tutorial de estructuras de datos de python. Esto le ayudará a mantenerse preparado.
Pregunta 3. ¿Son muy difíciles las entrevistas de codificación Python?
El nivel de dificultad de una entrevista de Python variará según el puesto que esté solicitando, la empresa, sus requisitos y su habilidad y conocimiento/experiencia laboral. Si es un principiante en el campo y aún no está seguro de su capacidad de codificación, puede sentir que la entrevista es difícil. Estar preparado y saber qué tipo de preguntas de entrevista de Python esperar lo ayudará a prepararse bien y dominar la entrevista.
Pregunta 4. ¿Cómo paso la entrevista de codificación de Python?
Tener un conocimiento adecuado sobre las bibliotecas Object Relational Mapper (ORM), Django o Flask, habilidades de prueba y depuración de unidades, principios de diseño fundamentales detrás de una aplicación escalable, paquetes de Python como NumPy, Scikit learn son extremadamente importantes para que pueda completar una entrevista de codificación. Puede mostrar su experiencia laboral previa o su capacidad de codificación a través de proyectos, esto actúa como una ventaja adicional.
Lea también Cómo construir un currículum de desarrolladores de Python
Pregunta 5. ¿Cómo se depura un programa de Python?
Al usar este comando, podemos depurar el programa en la terminal de python.
$ python -m pdb python-script.py
Pregunta 6. ¿Qué cursos o certificaciones pueden ayudar a impulsar el conocimiento en Python?
Con esto, hemos llegado al final del blog en la parte superior Preguntas de la entrevista de Python. Si desea mejorar sus habilidades, tomar un curso certificado lo ayudará a obtener los conocimientos necesarios. Puedes tomar un curso de programacion en python e inicie su carrera en Python.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.mygreatlearning.com/blog/python-interview-questions/

