Tabla de contenidos.
Una entrevista de Machine Learning exige una preparación rigurosa, ya que los candidatos son evaluados en varios aspectos, como habilidades técnicas y de programación, conocimiento profundo de los conceptos de ML y más. Si usted es un aspirante a profesional de Machine Learning, es crucial saber qué tipo de preguntas de entrevista de Machine Learning pueden hacer los gerentes de contratación. Para ayudarlo a agilizar este viaje de aprendizaje, hemos reducido estas preguntas esenciales de ML para usted. Con estas preguntas, podrá conseguir trabajos como ingeniero de aprendizaje automático, científico de datos, lingüista computacional, desarrollador de software, desarrollador de inteligencia comercial (BI), científico de procesamiento de lenguaje natural (NLP) y más.
Entonces, ¿estás listo para tener la carrera de tus sueños en ML?
Aquí está la lista de las 10 preguntas más frecuentes de la entrevista de aprendizaje automático
Una entrevista de Machine Learning requiere un riguroso proceso de entrevista en el que los candidatos son evaluados en varios aspectos, como habilidades técnicas y de programación, conocimiento de métodos y claridad de conceptos básicos. Si aspira a postularse para trabajos de aprendizaje automático, es crucial saber qué tipo de preguntas de entrevista de aprendizaje automático pueden hacer generalmente los reclutadores y gerentes de contratación.
Preguntas de entrevista de aprendizaje automático para estudiantes de primer año
Si es un principiante en Machine Learning y desea establecerse en este campo, ahora es el momento ya que los profesionales de ML tienen una gran demanda. Las preguntas de esta sección lo prepararán para lo que viene.
Aquí, hemos compilado una lista de las principales preguntas frecuentes de entrevistas de aprendizaje automático (preguntas de entrevistas de ml) que podría enfrentar durante una entrevista.
1. Explique los términos Inteligencia artificial (IA), Aprendizaje automático (ML) y Aprendizaje profundo.
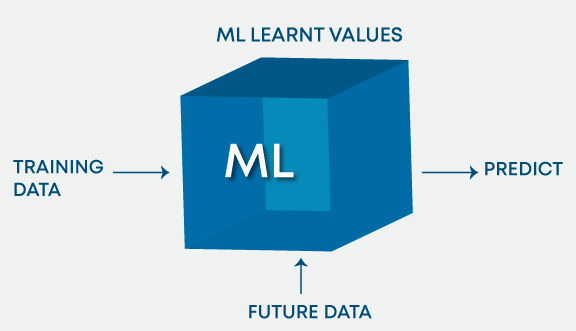
Inteligencia artificial (AI) es el dominio de producir máquinas inteligentes. ML se refiere a los sistemas que pueden asimilar la experiencia (datos de entrenamiento) y los estados de Deep Learning (DL) a los sistemas que aprenden de la experiencia en grandes conjuntos de datos. ML se puede considerar como un subconjunto de AI. Aprendizaje profundo (DL) es ML pero útil para grandes conjuntos de datos. La siguiente figura resume aproximadamente la relación entre AI, ML y DL:
En resumen, DL es un subconjunto de ML y ambos eran subconjuntos de AI.
Información adicional: ASR (Reconocimiento automático de voz) Y PNL (Procesamiento del lenguaje natural) se incluyen en la IA y se superponen con ML y DL, ya que ML se utiliza a menudo para tareas de NLP y ASR.
2. ¿Cuáles son los diferentes tipos de modelos de aprendizaje/entrenamiento en ML?
Los algoritmos de ML se pueden clasificar principalmente según la presencia/ausencia de variables de destino.
A. Aprendizaje supervisado: [El objetivo está presente]
La máquina aprende usando datos etiquetados. El modelo se entrena en un conjunto de datos existente antes de comenzar a tomar decisiones con los nuevos datos.
La variable objetivo es continua: Regresión lineal, regresión polinomial y regresión cuadrática.
La variable objetivo es categórica: Regresión logística, Naive Bayes, knn, SVM, árbol de decisión, Aumento de gradiente, refuerzo de ADA, embolsado, Bosque al azar etc.
B. Aprendizaje no supervisado: [El objetivo está ausente]
La máquina está entrenada con datos no etiquetados y sin ninguna guía adecuada. Infiere automáticamente patrones y relaciones en los datos mediante la creación de grupos. El modelo aprende a través de observaciones y estructuras deducidas en los datos.
Análisis de componentes principales, análisis factorial, descomposición de valores singulares, etc.
C. Aprendizaje por refuerzo:
El modelo aprende a través de un método de prueba y error. Este tipo de aprendizaje involucra a un agente que interactuará con el entorno para crear acciones y luego descubrir errores o recompensas de esa acción.
3. ¿Cuál es la diferencia entre el aprendizaje profundo y el aprendizaje automático?
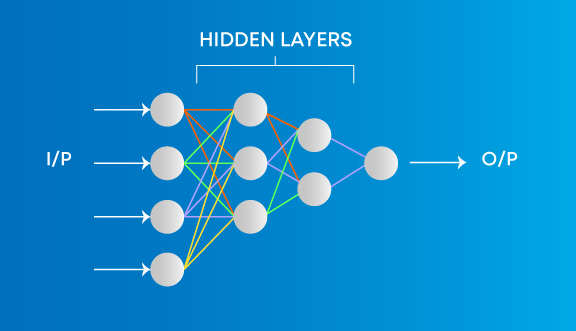
El aprendizaje automático involucra algoritmos que aprenden de patrones de datos y luego los aplican a la toma de decisiones. Deep Learning, por otro lado, es capaz de aprender a través del procesamiento de datos por sí mismo y es bastante similar al cerebro humano donde identifica algo, lo analiza y toma una decisión.
Las diferencias clave son las siguientes:
- La forma en que se presentan los datos al sistema.
- Los algoritmos de aprendizaje automático siempre requieren datos estructurados y las redes de aprendizaje profundo se basan en capas de redes neuronales artificiales.
Aprenda diferentes conceptos de AIML
4. ¿Cuál es la principal diferencia clave entre el aprendizaje automático supervisado y no supervisado?
| Aprendizaje supervisado | Aprendizaje sin supervisión |
| La técnica de aprendizaje supervisado necesita datos etiquetados para entrenar el modelo. Por ejemplo, para resolver un problema de clasificación (una tarea de aprendizaje supervisado), debe tener datos de etiquetas para entrenar el modelo y clasificar los datos en sus grupos etiquetados. | El aprendizaje no supervisado no necesita ningún conjunto de datos etiquetado. Esta es la principal diferencia clave entre el aprendizaje supervisado y el aprendizaje no supervisado. |
5. ¿Cómo selecciona variables importantes mientras trabaja en un conjunto de datos?
Hay varios medios para seleccionar variables importantes de un conjunto de datos que incluyen lo siguiente:
- Identificar y descartar variables correlacionadas antes de finalizar con variables importantes
- Las variables podrían seleccionarse en función de los valores 'p' de la regresión lineal
- Selección hacia adelante, hacia atrás y paso a paso
- Regresión de lazo
- Bosque aleatorio y gráfico de variables de parcela
- Las funciones principales se pueden seleccionar en función de la información obtenida para el conjunto de funciones disponible.
6. Hay muchos algoritmos de aprendizaje automático hasta ahora. Si se da un conjunto de datos, ¿cómo se puede determinar qué algoritmo se utilizará para eso?
El algoritmo de aprendizaje automático que se utilizará depende únicamente del tipo de datos en un conjunto de datos determinado. Si los datos son lineales, usamos regresión lineal. Si los datos muestran no linealidad, el algoritmo de embolsado funcionaría mejor. Si los datos se van a analizar/interpretar para algunos fines comerciales, entonces podemos usar árboles de decisión o SVM. Si el conjunto de datos consiste en imágenes, videos, audios, las redes neuronales serían útiles para obtener la solución con precisión.
Por lo tanto, no existe una métrica determinada para decidir qué algoritmo se utilizará para una situación determinada o un conjunto de datos. Necesitamos explorar los datos usando EDA (Análisis exploratorio de datos) y comprender el propósito de usar el conjunto de datos para generar el algoritmo de mejor ajuste. Por lo tanto, es importante estudiar todos los algoritmos en detalle.
7. ¿En qué se diferencian la covarianza y la correlación?
| Covarianza | La correlación |
| La covarianza mide cómo se relacionan dos variables entre sí y cómo variaría una con respecto a los cambios en la otra variable. Si el valor es positivo significa que existe una relación directa entre las variables y se aumentaría o disminuiría con un aumento o disminución de la variable base respectivamente, dado que todas las demás condiciones se mantienen constantes. | La correlación cuantifica la relación entre dos variables aleatorias y tiene solo tres valores específicos, es decir, 1, 0 y -1. |
1 denota una relación positiva, -1 denota una relación negativa y 0 denota que las dos variables son independientes entre sí.
8. ¿Enunciar las diferencias entre causalidad y correlación?
La causalidad se aplica a situaciones en las que una acción, digamos X, causa un resultado, digamos Y, mientras que la correlación es solo relacionar una acción (X) con otra acción (Y), pero X no necesariamente causa Y.
9. Observamos el software de aprendizaje automático casi todo el tiempo. ¿Cómo aplicamos Machine Learning al hardware?
Tenemos que construir algoritmos ML en System Verilog, que es un lenguaje de desarrollo de hardware y luego programarlo en un FPGA para aplicar Machine Learning al hardware.
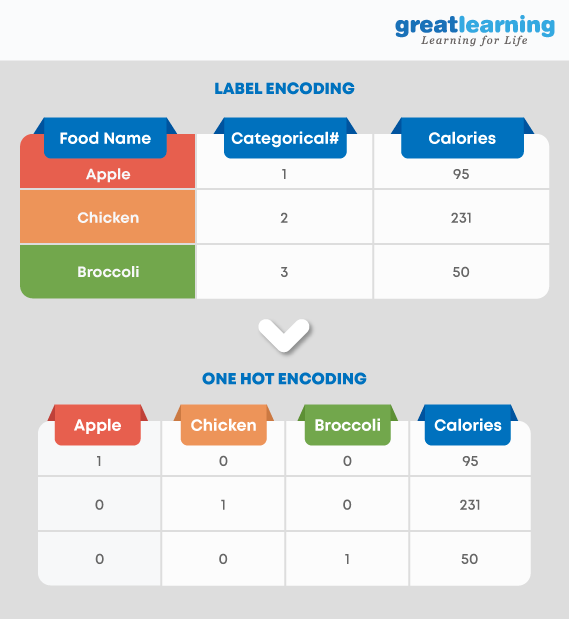
10. Explique la codificación One-hot y la codificación de etiquetas. ¿Cómo afectan la dimensionalidad del conjunto de datos dado?
La codificación one-hot es la representación de variables categóricas como vectores binarios. La codificación de etiquetas está convirtiendo etiquetas/palabras en formato numérico. El uso de la codificación one-hot aumenta la dimensionalidad del conjunto de datos. La codificación de etiquetas no afecta la dimensionalidad del conjunto de datos. La codificación one-hot crea una nueva variable para cada nivel de la variable mientras que, en la codificación de etiquetas, los niveles de una variable se codifican como 1 y 0.
Preguntas de la entrevista de aprendizaje profundo
Deep Learning es una parte del aprendizaje automático que funciona con redes neuronales. Se trata de una estructura jerárquica de redes que establecen un proceso para ayudar a las máquinas a aprender la lógica humana detrás de cualquier acción. Hemos recopilado una lista de las preguntas más frecuentes preguntas de la entrevista de aprendizaje profundo para ayudarte a prepararte.
11. ¿Cuándo entra en juego la regularización en Machine Learning?
A veces, cuando el modelo comienza a ajustarse demasiado o por debajo de lo normal, se hace necesaria la regularización. Es una regresión que desvía o regulariza las estimaciones de los coeficientes hacia cero. Reduce la flexibilidad y desalienta el aprendizaje en un modelo para evitar el riesgo de sobreajuste. La complejidad del modelo se reduce y se vuelve mejor en la predicción.
12. ¿Qué es el sesgo, la varianza y qué quiere decir con compensación entre sesgo y varianza?
Ambos son errores en Algoritmos de aprendizaje automático. Cuando el algoritmo tiene una flexibilidad limitada para deducir la observación correcta del conjunto de datos, se produce un sesgo. Por otro lado, la varianza ocurre cuando el modelo es extremadamente sensible a pequeñas fluctuaciones.
Si se agregan más funciones al construir un modelo, se agregará más complejidad y perderemos sesgo pero ganaremos algo de varianza. Para mantener la cantidad óptima de error, realizamos una compensación entre el sesgo y la varianza en función de las necesidades de una empresa.
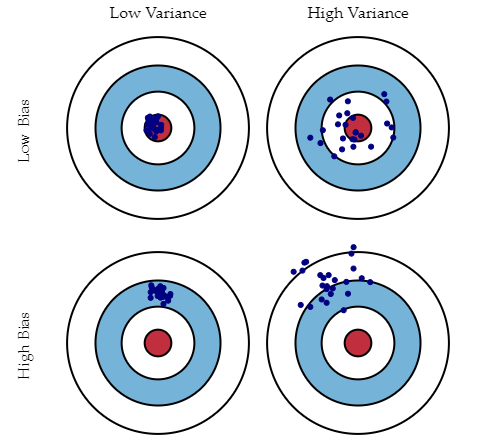
El sesgo representa el error debido a suposiciones erróneas o demasiado simplistas en el algoritmo de aprendizaje. Esta suposición puede llevar a que el modelo no se ajuste bien a los datos, lo que dificulta que tenga una alta precisión predictiva y que usted generalice su conocimiento del conjunto de entrenamiento al conjunto de prueba.
La varianza también es un error debido a demasiada complejidad en el algoritmo de aprendizaje. Esta puede ser la razón por la que el algoritmo es muy sensible a los altos grados de variación en los datos de entrenamiento, lo que puede hacer que su modelo se ajuste en exceso a los datos. Llevar demasiado ruido de los datos de entrenamiento para que su modelo sea muy útil para sus datos de prueba.
La descomposición de sesgo-varianza esencialmente descompone el error de aprendizaje de cualquier algoritmo al agregar el sesgo, la varianza y un poco de error irreducible debido al ruido en el conjunto de datos subyacente. Esencialmente, si hace que el modelo sea más complejo y agrega más variables, perderá el sesgo pero ganará algo de varianza: para obtener la cantidad de error óptimamente reducida, tendrá que compensar el sesgo y la varianza. No desea un alto sesgo o una gran variación en su modelo.
13. ¿Cómo podemos relacionar la desviación estándar y la varianza?
Desviación estándar se refiere a la dispersión de sus datos desde la media. Diferencia es el grado promedio en el que cada punto difiere de la media, es decir, el promedio de todos los puntos de datos. Podemos relacionar la desviación estándar y la varianza porque es la raíz cuadrada de la varianza.
14. Se le proporciona un conjunto de datos y tiene valores faltantes que se extienden a lo largo de 1 desviación estándar de la media. ¿Cuánto de los datos permanecería intacto?
Se da que los datos se distribuyen a lo largo de la media, es decir, los datos se distribuyen a lo largo de un promedio. Entonces, podemos suponer que es una distribución normal. En una distribución normal, alrededor del 68 % de los datos se encuentran en 1 desviación estándar de promedios como la media, la moda o la mediana. Eso significa que alrededor del 32% de los datos no se ven afectados por los valores faltantes.
15. ¿Una alta variación en los datos es buena o mala?
Una varianza más alta significa directamente que la distribución de datos es grande y la característica tiene una variedad de datos. Por lo general, la alta variación en una característica se considera de no tan buena calidad.
16. Si su conjunto de datos sufre una gran variación, ¿cómo lo manejaría?
Para conjuntos de datos con alta varianza, podríamos usar el algoritmo de embolsado para manejarlo. El algoritmo de embolsado divide los datos en subgrupos con muestreo replicado a partir de datos aleatorios. Después de dividir los datos, se utilizan datos aleatorios para crear reglas mediante un algoritmo de entrenamiento. Luego usamos la técnica de sondeo para combinar todos los resultados previstos del modelo.
17. Se le proporciona un conjunto de datos sobre la detección de fraudes de servicios públicos. Ha creado un modelo de clasificador y ha obtenido una puntuación de rendimiento del 98.5 %. ¿Es este un buen modelo? En caso afirmativo, justifique. Si no, ¿qué puedes hacer al respecto?
Conjunto de datos sobre detección de fraude de servicios públicos no está lo suficientemente equilibrado, es decir, desequilibrado. En un conjunto de datos de este tipo, la puntuación de precisión no puede ser la medida del rendimiento, ya que solo puede predecir correctamente la etiqueta de la clase mayoritaria, pero en este caso nuestro punto de interés es predecir la etiqueta de la minoría. Pero a menudo las minorías son tratadas como ruido e ignoradas. Por lo tanto, existe una alta probabilidad de clasificación errónea de la etiqueta minoritaria en comparación con la etiqueta mayoritaria. Para evaluar el rendimiento del modelo en el caso de conjuntos de datos desequilibrados, debemos utilizar la sensibilidad (tasa de verdaderos positivos) o la especificidad (tasa de verdaderos negativos) para determinar el rendimiento inteligente de la etiqueta de clase del modelo de clasificación. Si el desempeño de la etiqueta de clase minoritaria no es tan bueno, podríamos hacer lo siguiente:
- Podemos usar submuestreo o sobremuestreo para equilibrar los datos.
- Podemos cambiar el valor del umbral de predicción.
- Podemos asignar pesos a las etiquetas de modo que las etiquetas de las clases minoritarias obtengan pesos mayores.
- Podríamos detectar anomalías.
18. Explique el manejo de valores faltantes o dañados en el conjunto de datos dado.
Una manera fácil de manejar los valores perdidos o dañados es eliminar las filas o columnas correspondientes. Si hay demasiadas filas o columnas para descartar, consideramos reemplazar los valores faltantes o corruptos con algún valor nuevo.
La identificación de valores faltantes y la eliminación de filas o columnas se pueden realizar utilizando las funciones IsNull() y dropna() en Pandas. Además, la función Fillna() en Pandas reemplaza los valores incorrectos con el valor del marcador de posición.
19. ¿Qué es la serie temporal?
A Series de tiempo es una secuencia de puntos de datos numéricos en orden sucesivo. Realiza un seguimiento del movimiento de los puntos de datos elegidos, durante un período de tiempo específico y registra los puntos de datos a intervalos regulares. Las series de tiempo no requieren ninguna entrada de tiempo mínimo o máximo. Los analistas suelen utilizar series temporales para examinar los datos según sus requisitos específicos.
20. ¿Qué es una transformación de Box-Cox?
La transformación de Box-Cox es una transformación de potencia que transforma las variables dependientes no normales en variables normales, ya que la normalidad es la suposición más común que se hace al usar muchas técnicas estadísticas. Tiene un parámetro lambda que, cuando se establece en 0, implica que esta transformación es equivalente a la transformación logarítmica. Se utiliza para la estabilización de la varianza y también para normalizar la distribución.
21. ¿Cuál es la diferencia entre el descenso de gradiente estocástico (SGD) y el descenso de gradiente (GD)?
Descenso de gradiente y Stochastic Gradient Descent son los algoritmos que encuentran el conjunto de parámetros que minimizarán una función de pérdida.
La diferencia es que en Gradient Descend, todas las muestras de entrenamiento se evalúan para cada conjunto de parámetros. Mientras en Descenso de gradiente estocástico solo se evalúa una muestra de entrenamiento para el conjunto de parámetros identificados.
22. ¿Cuál es el problema del gradiente explosivo cuando se usa la técnica de retropropagación?
Cuando se acumulan grandes gradientes de error y dan como resultado grandes cambios en los pesos de la red neuronal durante el entrenamiento, se denomina problema de gradiente explosivo. Los valores de los pesos pueden volverse tan grandes como para desbordarse y dar como resultado valores de NaN. Esto hace que el modelo sea inestable y que el aprendizaje del modelo se detenga al igual que el problema de gradiente de fuga. Esta es una de las preguntas de entrevista más frecuentes sobre el aprendizaje automático.
23. ¿Puede mencionar algunas ventajas y desventajas de los árboles de decisión?
Las ventajas de los árboles de decisión son que son más fáciles de interpretar, no son paramétricos y, por lo tanto, resistentes a los valores atípicos, y tienen relativamente pocos parámetros para ajustar.
Por otro lado, la desventaja es que son propensos al sobreajuste.
24. Explique las diferencias entre las máquinas Random Forest y Gradient Boost.
| Bosques al azar | Aumento de gradiente |
| Los bosques aleatorios son un número significativo de árboles de decisión agrupados utilizando promedios o reglas de mayoría al final. | Las máquinas de aumento de gradiente también combinan árboles de decisión pero al comienzo del proceso, a diferencia de los bosques aleatorios. |
| El bosque aleatorio crea cada árbol independientemente de los demás, mientras que el aumento de gradiente desarrolla un árbol a la vez. | El aumento de gradiente produce mejores resultados que los bosques aleatorios si los parámetros se ajustan cuidadosamente, pero no es una buena opción si el conjunto de datos contiene muchos valores atípicos/anomalías/ruido, ya que puede resultar en un ajuste excesivo del modelo. |
| Los bosques aleatorios funcionan bien para la detección de objetos multiclase. | Gradient Boosting funciona bien cuando hay datos que no están equilibrados, como en la evaluación de riesgos en tiempo real. |
25. ¿Qué es una matriz de confusión y por qué la necesita?
La matriz de confusión (también llamada matriz de error) es una tabla que se utiliza con frecuencia para ilustrar el rendimiento de un modelo de clasificación, es decir, un clasificador en un conjunto de datos de prueba cuyos valores reales son bien conocidos.
Nos permite visualizar el rendimiento de un algoritmo/modelo. Nos permite identificar fácilmente la confusión entre diferentes clases. Se utiliza como una medida de rendimiento de un modelo/algoritmo.
Una matriz de confusión se conoce como un resumen de predicciones en un modelo de clasificación. El número de predicciones correctas e incorrectas se resumió con valores de conteo y se desglosó por cada etiqueta de clase. Nos da información sobre los errores cometidos a través del clasificador y también los tipos de errores cometidos por un clasificador.
Cree el mejor currículum de aprendizaje automático y destaque entre la multitud
26. ¿Qué es una transformada de Fourier?
La Transformada de Fourier es una técnica matemática que transforma cualquier función de tiempo en una función de frecuencia. La transformada de Fourier está estrechamente relacionada con la serie de Fourier. Toma cualquier patrón basado en el tiempo como entrada y calcula la compensación del ciclo general, la velocidad de rotación y la fuerza para todos los ciclos posibles. La transformada de Fourier se aplica mejor a las formas de onda ya que tiene funciones de tiempo y espacio. Una vez que se aplica una transformada de Fourier a una forma de onda, se descompone en una sinusoide.
27. ¿Qué quiere decir Minería de Reglas Asociativas (ARM)?
La minería de reglas asociativa es una de las técnicas para descubrir patrones en datos como características (dimensiones) que ocurren juntas y características (dimensiones) que están correlacionadas. Se utiliza principalmente en el análisis basado en el mercado para encontrar la frecuencia con la que se produce un conjunto de elementos en una transacción. Las reglas de asociación tienen que satisfacer un apoyo mínimo y una confianza mínima al mismo tiempo. La generación de reglas de asociación generalmente consta de dos pasos diferentes:
- "Se proporciona un umbral de soporte mínimo para obtener todos los conjuntos de elementos frecuentes en una base de datos".
- "Se otorga una restricción de confianza mínima a estos conjuntos de elementos frecuentes para formar las reglas de asociación".
El apoyo es una medida de la frecuencia con la que aparece el "conjunto de elementos" en el conjunto de datos y la confianza es una medida de la frecuencia con la que se ha determinado que una regla en particular es cierta.
28. ¿Qué es la Marginación? Explique el proceso.
La marginación es la suma de la probabilidad de una variable aleatoria X dada la distribución de probabilidad conjunta de X con otras variables. Es una aplicación de la ley de probabilidad total.
P(X=x) = ∑YP(X=x,Y)
Dada la probabilidad conjunta P(X=x,Y), podemos usar la marginación para encontrar P(X=x). Entonces, es encontrar la distribución de una variable aleatoria agotando los casos en otras variables aleatorias.
29. Explique la frase “La maldición de la dimensionalidad”.
El proyecto Maldición de dimensionalidad se refiere a la situación en la que sus datos tienen demasiadas funciones.
La frase se usa para expresar la dificultad de usar la fuerza bruta o la búsqueda en cuadrícula para optimizar una función con demasiadas entradas.
También puede referirse a varios otros problemas como:
- Si tenemos más características que observaciones, corremos el riesgo de sobreajustar el modelo.
- Cuando tenemos demasiadas características, las observaciones se vuelven más difíciles de agrupar. Demasiadas dimensiones hacen que cada observación en el conjunto de datos parezca equidistante de todas las demás y no se pueden formar grupos significativos.
Las técnicas de reducción de dimensionalidad como PCA vienen al rescate en estos casos.
30. ¿Qué es el Análisis de Componentes Principales?
La idea aquí es reducir la dimensionalidad del conjunto de datos al reducir el número de variables que están correlacionadas entre sí. Aunque la variación debe conservarse al máximo.
Las variables se transforman en un nuevo conjunto de variables que se conocen como componentes principales. Estos PC son los vectores propios de una matriz de covarianza y, por lo tanto, son ortogonales.
31. ¿Por qué es tan importante la rotación de componentes en el análisis de componentes principales (PCA)?
La rotación en PCA es muy importante ya que maximiza la separación dentro de la varianza obtenida por todos los componentes por lo que la interpretación de los componentes sería más fácil. Si los componentes no están rotados, entonces necesitamos componentes extendidos para describir la varianza de los componentes.
32. ¿Qué son los valores atípicos? Mencione tres métodos para tratar con valores atípicos.

Un punto de datos que está considerablemente distante de otros puntos de datos similares se conoce como un valor atípico. Pueden ocurrir debido a errores experimentales o variabilidad en la medición. Son problemáticos y pueden inducir a error en un proceso de capacitación, lo que eventualmente resulta en un tiempo de capacitación más prolongado, modelos inexactos y resultados deficientes.
Los tres métodos para tratar con valores atípicos son:
Método univariante – busca puntos de datos que tengan valores extremos en una sola variable
Método multivariante – busca combinaciones inusuales en todas las variables
error minkowski – reduce la contribución de posibles valores atípicos en el proceso de entrenamiento
Leer también - Ventajas de seguir una carrera en Machine Learning
33. ¿Cuál es la diferencia entre regularización y normalización?
| normalización | regularización |
| La normalización ajusta los datos; . Si sus datos están en escalas muy diferentes (especialmente de baja a alta), querrá normalizar los datos. Modifique cada columna para tener estadísticas básicas compatibles. Esto puede ser útil para asegurarse de que no haya pérdida de precisión. Uno de los objetivos del entrenamiento del modelo es identificar la señal e ignorar el ruido. Si se le da rienda suelta al modelo para minimizar el error, existe la posibilidad de sufrir un sobreajuste. | La regularización ajusta la función de predicción. La regularización impone cierto control sobre esto al proporcionar funciones de ajuste más simples sobre las complejas. |
34. Explique la diferencia entre Normalización y Estandarización.
La normalización y la estandarización son los dos métodos muy populares que se utilizan para el escalado de funciones.
| normalización | Normalización |
| La normalización se refiere a volver a escalar los valores para que se ajusten a un rango de [0,1]. La normalización es útil cuando todos los parámetros deben tener una escala positiva idéntica; sin embargo, se pierden los valores atípicos del conjunto de datos. |
La estandarización se refiere a volver a escalar los datos para que tengan una media de 0 y una desviación estándar de 1 (varianza unitaria) |
35. Enumere las curvas de distribución más populares junto con los escenarios en los que las usará en un algoritmo.
Las curvas de distribución más populares son las siguientes: Distribución de Bernoulli, Distribución uniforme, Distribución binomial, Distribución normal, Distribución de venenoy distribución exponencial. Echa un vistazo gratis Probabilidad para el aprendizaje automático curso para mejorar su conocimiento sobre distribuciones de probabilidad para aprendizaje automático.
Cada una de estas curvas de distribución se utiliza en varios escenarios.
Bernoulli Distribution se puede utilizar para comprobar si un equipo ganará un campeonato o no, un recién nacido el niño es hombre o mujer, pasas un examen o no, etc.
Distribución uniforme es una distribución de probabilidad que tiene una probabilidad constante. Tirar un solo dado es un ejemplo porque tiene un número fijo de resultados.
Distribución binomial es una probabilidad con solo dos resultados posibles, el prefijo 'bi' significa dos o dos veces. Un ejemplo de esto sería el lanzamiento de una moneda. El resultado será cara o cruz.
Distribución normal describe cómo se distribuyen los valores de una variable. Por lo general, es una distribución simétrica donde la mayoría de las observaciones se agrupan alrededor del pico central. Los valores más alejados de la media disminuyen igualmente en ambas direcciones. Un ejemplo sería la altura de los estudiantes en un salón de clases.
distribución de veneno ayuda a predecir la probabilidad de que ocurran ciertos eventos cuando sabe con qué frecuencia ha ocurrido ese evento. Puede ser utilizado por empresarios para hacer previsiones sobre el número de clientes en determinados días y les permite ajustar la oferta en función de la demanda.
Distribución exponencial se refiere a la cantidad de tiempo hasta que ocurre un evento específico. Por ejemplo, cuánto duraría la batería de un coche, en meses.
36. ¿Cómo verificamos la normalidad de un conjunto de datos o una característica?
Visualmente, podemos comprobarlo mediante gráficos. Hay una lista de controles de normalidad, son los siguientes:
- Prueba Shapiro-Wilk W
- Prueba de Anderson-Darling
- Prueba Martínez-Iglewicz
- Prueba de Kolmogorov-Smirnov
- Prueba de asimetría de D'Agostino
37. ¿Qué es la regresión lineal?
La función lineal se puede definir como una función matemática en un plano 2D como, Y =Mx +C, donde Y es una variable dependiente y X es una variable independiente, C es intersección y M es pendiente y lo mismo se puede expresar como Y es una función de X o Y = F(x).
En cualquier valor dado de X, uno puede calcular el valor de Y, usando la ecuación de Línea. Esta relación entre Y y X, con grado del polinomio 1, se llama Regresión lineal.
En el modelado predictivo, LR se representa como Y = Bo + B1x1 + B2x2
El valor de B1 y B2 determina la fuerza de la correlación entre las características y la variable dependiente.
Ejemplo: Valor de las acciones en $ = Intercepción + (+/-B1)*(Valor de apertura de las acciones) + (+/-B2)*(Valor más alto de las acciones del día anterior)
38. Diferenciar entre regresión y clasificación.
La regresión y la clasificación se clasifican bajo el mismo paraguas de aprendizaje automático supervisado. La principal diferencia entre ellos es que la variable de salida en la regresión es numérica (o continua) mientras que la de clasificación es categórica (o discreta).
Ejemplo: Predecir la temperatura definitiva de un lugar es un problema de regresión, mientras que predecir si el día estará soleado, nublado o lloverá es un caso de clasificación.
39. ¿Qué es el desequilibrio objetivo? ¿Cómo lo arreglamos? Un escenario en el que ha realizado un desequilibrio objetivo en los datos. ¿Qué métricas y algoritmos considera adecuados para ingresar estos datos?
Si tiene variables categóricas como objetivo cuando las agrupa o realiza una frecuencia, cuente sobre ellas si hay ciertas categorías que son más numerosas en comparación con otras en un número muy significativo. Esto se conoce como desequilibrio objetivo.
Ejemplo: columna de destino: 0,0,0,1,0,2,0,0,1,1 [0s: 60 %, 1: 30 %, 2:10 %] 0 son la mayoría. Para solucionar esto, podemos realizar un muestreo ascendente o descendente. Antes de solucionar este problema, supongamos que las métricas de rendimiento utilizadas fueron métricas de confusión. Después de solucionar este problema, podemos cambiar el sistema métrico a AUC: ROC. Dado que agregamos/eliminamos datos [muestreo ascendente o muestreo descendente], podemos continuar con un algoritmo más estricto como SVM, aumento de gradiente o aumento de ADA.
40. Enumere todas las suposiciones para que los datos se cumplan antes de comenzar con la regresión lineal.
Antes de iniciar la regresión lineal, los supuestos a cumplir son los siguientes:
- Relación lineal
- Normalidad multivariante
- No o poca multicolinealidad
- Sin autocorrelación
- Homocedasticidad
41. ¿Cuándo deja de girar la línea de regresión lineal o encuentra un punto óptimo donde se ajusta a los datos?
Un lugar donde se encuentra el valor RS cuadrado más alto es el lugar donde la línea se detiene. RSquared representa la cantidad de varianza capturada por la línea de regresión lineal virtual con respecto a la varianza total capturada por el conjunto de datos.
42. ¿Por qué la regresión logística es un tipo de técnica de clasificación y no una regresión? Nombre la función de la que se deriva?
Dado que la columna de destino es categórica, utiliza la regresión lineal para crear una función impar que se envuelve con una función de registro para utilizar la regresión como clasificador. Por lo tanto, es un tipo de técnica de clasificación y no una regresión. Se deriva de la función de costo.
43. ¿Cuál podría ser el problema cuando el valor beta de una determinada variable varía demasiado en cada subconjunto cuando se ejecuta la regresión en diferentes subconjuntos del conjunto de datos dado?
Las variaciones en los valores beta en cada subconjunto implican que el conjunto de datos es heterogéneo. Para superar este problema, podemos usar un modelo diferente para cada uno de los subconjuntos agrupados del conjunto de datos o un modelo no paramétrico, como árboles de decisión.
44. ¿Qué significa el término factor de inflación de la varianza?
El factor de inflación de variación (VIF) es la relación entre la varianza del modelo y la varianza del modelo con una sola variable independiente. VIF da la estimación del volumen de multicolinealidad en un conjunto de muchas variables de regresión.
VIF = Varianza del modelo con una variable independiente
45. ¿Qué algoritmo de aprendizaje automático se conoce como el aprendiz perezoso y por qué se llama así?
KNN es un algoritmo de aprendizaje automático conocido como aprendiz perezoso. K-NN es un aprendiz perezoso porque no aprende ningún valor o variable aprendido por máquina de los datos de entrenamiento, sino que calcula dinámicamente la distancia cada vez que quiere clasificar, por lo tanto, memoriza el conjunto de datos de entrenamiento.
Preguntas de entrevista de aprendizaje automático para experimentados
Sabemos lo que buscan las empresas, y con eso en mente, hemos preparado el conjunto de preguntas de entrevista de aprendizaje automático que se le puede hacer a un profesional experimentado. Por lo tanto, prepárese en consecuencia si desea superar la entrevista de una sola vez.
46. ¿Es posible utilizar KNN para el procesamiento de imágenes?
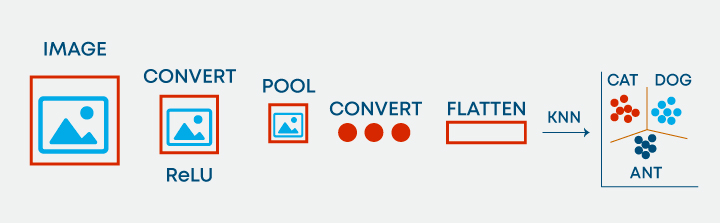
Sí, es posible utilizar KNN para el procesamiento de imágenes. Se puede hacer convirtiendo la imagen tridimensional en un vector unidimensional y usándolo como entrada a KNN.
47. ¿Diferenciar entre algoritmos K-Means y KNN?
| Algoritmos KNN | K-medias |
| Algoritmos KNN es aprendizaje supervisado donde, como K-Means, es aprendizaje no supervisado. Con KNN, predecimos la etiqueta del elemento no identificado en función de su vecino más cercano y ampliamos aún más este enfoque para resolver problemas basados en clasificación/regresión. | K-Means es aprendizaje no supervisado, donde no tenemos ninguna etiqueta presente, en otras palabras, no hay variables de destino y, por lo tanto, tratamos de agrupar los datos en función de su coord. |
Preguntas de la entrevista de PNL
NLP o Natural Language Processing ayuda a las máquinas a analizar los lenguajes naturales con la intención de aprenderlos. Extrae información de los datos aplicando algoritmos de aprendizaje automático. Aparte de aprender los conceptos básicos de la PNL, es importante prepararse específicamente para las entrevistas. mira la parte superior Preguntas de la entrevista de PNL
48. ¿Cómo trata el algoritmo SVM el autoaprendizaje?
SVM tiene una tasa de aprendizaje y una tasa de expansión que se encarga de esto. los tasa de aprendizaje compensa o penaliza a los hiperplanos por hacer todos los movimientos incorrectos y la tasa de expansión trata de encontrar el área de separación máxima entre clases.
49. ¿Qué son los Kernels en SVM? Enumere los núcleos populares utilizados en SVM junto con un escenario de sus aplicaciones.
La función del kernel es tomar datos como entrada y transformarlos en la forma requerida. Algunos núcleos populares utilizados en SVM son los siguientes: RBF, Linear, Sigmoid, Polynomial, Hyperbolic, Laplace, etc.
50. ¿Qué es Kernel Trick en un algoritmo SVM?
Kernel Trick es una función matemática que, cuando se aplica en puntos de datos, puede encontrar la región de clasificación entre dos clases diferentes. Según la elección de la función, ya sea lineal o radial, que depende puramente de la distribución de datos, se puede construir un clasificador.
51. ¿Qué son los modelos de conjuntos? Explicar cómo las técnicas de conjunto producen un mejor aprendizaje en comparación con los algoritmos ML de clasificación tradicionales.
un conjunto es un grupo de modelos que se utilizan juntos para la predicción tanto en clases de clasificación como de regresión. El aprendizaje conjunto ayuda a mejorar los resultados de ML porque combina varios modelos. Al hacerlo, permite un mejor rendimiento predictivo en comparación con un solo modelo.
Son superiores a los modelos individuales ya que reducen la varianza, promedian los sesgos y tienen menos posibilidades de sobreajuste.
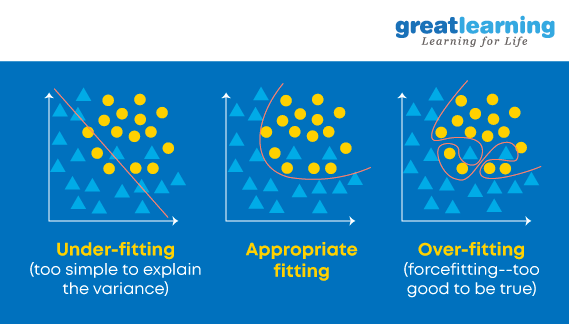
52. ¿Qué son el overfitting y el underfitting? ¿Por qué el algoritmo del árbol de decisión sufre a menudo problemas de sobreajuste?
El sobreajuste es un modelo estadístico o algoritmo de aprendizaje automático que captura el ruido de los datos. El ajuste insuficiente es un modelo o algoritmo de aprendizaje automático que no se ajusta lo suficientemente bien a los datos y ocurre si el modelo o algoritmo muestra una varianza baja pero un sesgo alto.
En los árboles de decisión, el sobreajuste ocurre cuando el árbol está diseñado para ajustarse perfectamente a todas las muestras en el conjunto de datos de entrenamiento. Esto da como resultado bifurcaciones con reglas estrictas o datos escasos y afecta la precisión al predecir muestras que no forman parte del conjunto de entrenamiento.
Lea también Sobreajuste y desajuste en el aprendizaje automático
53. ¿Qué es el error OOB y cómo ocurre?
Para cada muestra de arranque, hay un tercio de la datos que no se utilizó en la creación del árbol, es decir, estaba fuera de la muestra. Estos datos se conocen como datos fuera de bolsa. Para obtener una medida imparcial de la precisión del modelo sobre los datos de prueba, se utiliza el error fuera de bolsa. Los datos fuera de la bolsa se pasan para cada árbol que se pasa a través de ese árbol y las salidas se agregan para dar error de bolsa. Este porcentaje de error es bastante efectivo para estimar el error en el conjunto de prueba y no requiere más validación cruzada.
54. ¿Por qué boosting es un algoritmo más estable en comparación con otros algoritmos de conjunto?
El impulso se centra en los errores encontrados en iteraciones anteriores hasta que se vuelven obsoletos. Mientras que en el embolsado no existe un bucle corrector. Esta es la razón por la cual el impulso es un algoritmo más estable en comparación con otros algoritmos de conjunto.
55. ¿Cómo maneja los valores atípicos en los datos?
Un valor atípico es una observación en el conjunto de datos que está muy lejos de otras observaciones en el conjunto de datos. Podemos descubrir valores atípicos usando herramientas y funciones como diagrama de caja, diagrama de dispersión, puntaje Z, puntaje IQR, etc. y luego manejarlos según la visualización que tenemos. Para manejar los valores atípicos, podemos limitarlos a algún umbral, usar transformaciones para reducir la asimetría de los datos y eliminar los valores atípicos si son anomalías o errores.
56. Enumere las técnicas populares de validación cruzada.
Existen principalmente seis tipos de técnicas de validación cruzada. Son los siguientes:
- pliegue k
- Pliegue estratificado k
- dejar uno fuera
- Bootstrapping
- búsqueda aleatoria de cv
- currículum de búsqueda de cuadrícula
57. ¿Es posible probar la probabilidad de mejorar la precisión del modelo sin técnicas de validación cruzada? En caso afirmativo, explíquelo porfavor.
Sí, es posible probar la probabilidad de mejorar la precisión del modelo sin técnicas de validación cruzada. Podemos hacerlo ejecutando el modelo ML para decir n número de iteraciones, registrando la precisión. Trace todas las precisiones y elimine el 5% de los valores de baja probabilidad. Mida el corte izquierdo [bajo] y el corte derecho [alto]. Con el 95 % de confianza restante, podemos decir que el modelo puede ir tan bajo o tan alto [como se menciona dentro de los puntos de corte].
58. Nombre un algoritmo popular de reducción de dimensionalidad.
Los algoritmos populares de reducción de dimensionalidad son Análisis de componentes principales y Análisis Factorial.
El análisis de componentes principales crea una o más variables de índice a partir de un conjunto más grande de variables medidas. El Análisis Factorial es un modelo de la medida de una variable latente. Esta variable latente no se puede medir con una sola variable y se ve a través de una relación que provoca en un conjunto de y variables.
59. ¿Cómo podemos usar un conjunto de datos sin la variable objetivo en algoritmos de aprendizaje supervisado?
Introduzca el conjunto de datos en un algoritmo de agrupamiento, genere conglomerados óptimos, etiquete los números de conglomerados como la nueva variable de destino. Ahora, el conjunto de datos tiene variables objetivo e independientes presentes. Esto garantiza que el conjunto de datos esté listo para usarse en algoritmos de aprendizaje supervisado.
60. ¿Enumere todos los tipos de sistemas de recomendación populares? Nombre y explique dos sistemas de recomendación personalizados junto con su facilidad de implementación.
La recomendación basada en la popularidad, la recomendación basada en el contenido, el filtro colaborativo basado en el usuario y la recomendación basada en elementos son los tipos populares de sistemas de recomendación.
Personalizado Sistemas de recomendación son: recomendaciones basadas en el contenido, filtro colaborativo basado en el usuario y recomendaciones basadas en elementos. El filtro colaborativo basado en el usuario y las recomendaciones basadas en elementos son más personalizadas. Fácil de mantener: la matriz de similitud se puede mantener fácilmente con recomendaciones basadas en artículos.
61. ¿Cómo tratamos los problemas de escasez en los sistemas de recomendación? ¿Cómo medimos su eficacia? Explique.
La descomposición de valores singulares se puede utilizar para generar la matriz de predicción. RMSE es la medida que nos ayuda a comprender qué tan cerca está la matriz de predicción de la matriz original.
62. Nombrar y definir técnicas utilizadas para encontrar similitudes en el sistema de recomendación.
La correlación de Pearson y la correlación de coseno son técnicas utilizadas para encontrar similitudes en los sistemas de recomendación.
63. Indique las limitaciones de la función de base fija.
La separabilidad lineal en el espacio de características no implica la separabilidad lineal en el espacio de entrada. Entonces, las entradas se transforman de forma no lineal utilizando vectores de funciones básicas con mayor dimensionalidad. Las limitaciones de las funciones de base fija son:
- Las transformaciones no lineales no pueden eliminar la superposición entre dos clases, pero pueden aumentar la superposición.
- A menudo, no está claro qué funciones básicas son las más adecuadas para una tarea determinada. Por lo tanto, aprender las funciones básicas puede ser útil sobre el uso de funciones de base fija.
- Si queremos usar solo los fijos, podemos usar muchos de ellos y dejar que el modelo descubra el mejor ajuste, pero eso llevaría a sobreajustar el modelo, lo que lo haría inestable.
64. Defina y explique el concepto de sesgo inductivo con algunos ejemplos.
El sesgo inductivo es un conjunto de suposiciones que los humanos usan para predecir salidas dadas entradas que el algoritmo de aprendizaje aún no ha encontrado. Cuando intentamos aprender Y de X y el espacio de hipótesis para Y es infinito, necesitamos reducir el alcance de nuestras creencias/suposiciones sobre el espacio de hipótesis, que también se denomina sesgo inductivo. A través de estas suposiciones, restringimos nuestro espacio de hipótesis y también obtenemos la capacidad de probar y mejorar de forma incremental los datos utilizando hiperparámetros. Ejemplos:
- Suponemos que Y varía linealmente con X al aplicar la regresión lineal.
- Suponemos que existe un hiperplano que separa ejemplos negativos y positivos.
65. Explique el término aprendizaje basado en instancias.
El aprendizaje basado en instancias es un conjunto de procedimientos de regresión y clasificación que produce una predicción de etiqueta de clase basada en el parecido con sus vecinos más cercanos en el conjunto de datos de entrenamiento. Estos algoritmos solo recopilan todos los datos y obtienen una respuesta cuando se requiere o se consulta. En palabras simples, son un conjunto de procedimientos para resolver nuevos problemas basados en las soluciones de problemas ya resueltos en el pasado que son similares al problema actual.
66. Teniendo en cuenta los criterios de división del tren y de la prueba, ¿es bueno realizar el escalado antes o después de la división?
Idealmente, el escalado debe realizarse después del entrenamiento y la división de prueba. Si los datos están muy juntos, escalar la post o la división previa no debería hacer mucha diferencia.
67. ¿Defina precisión, recuperación y F1 Score?
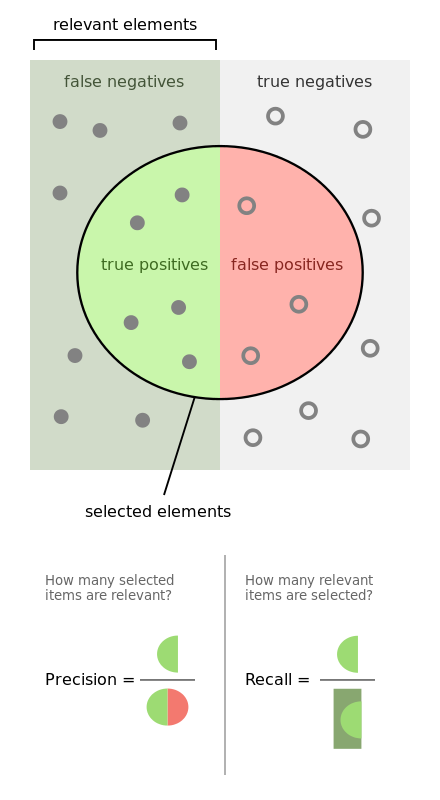
La métrica utilizada para acceder al rendimiento del modelo de clasificación es Confusion Metric. La métrica de confusión se puede interpretar con los siguientes términos:
Verdaderos positivos (TP) – Estos son los valores positivos pronosticados correctamente. Implica que el valor de la clase real es sí y el valor de la clase predicha también es sí.
Verdaderos negativos (TN) – Estos son los valores negativos predichos correctamente. Implica que el valor de la clase real es no y el valor de la clase predicha también es no.
Falsos positivos y falsos negativos, estos valores ocurren cuando su clase real contradice la clase predicha.
Ahora,
Recordar, también conocida como Sensibilidad es la relación entre la tasa de verdaderos positivos (TP) y todas las observaciones en la clase real: sí
Recuperar = TP/(TP+FN)
Precisión es la relación del valor predictivo positivo, que mide la cantidad de positivos precisos que predice el modelo, es decir, el número de positivos que reclama.
Precisión = TP/(TP+FP)
Exactitud es la medida de rendimiento más intuitiva y es simplemente una relación entre la observación predicha correctamente y el total de observaciones.
Precisión = (TP+TN)/(TP+FP+FN+TN)
Puntuación F1 es el promedio ponderado de precisión y recuperación. Por lo tanto, esta puntuación tiene en cuenta tanto los falsos positivos como los falsos negativos. Intuitivamente, no es tan fácil de entender como la precisión, pero F1 suele ser más útil que la precisión, especialmente si tiene una distribución de clases desigual. La precisión funciona mejor si los falsos positivos y los falsos negativos tienen un costo similar. Si el costo de los falsos positivos y los falsos negativos es muy diferente, es mejor considerar tanto la precisión como la recuperación.
68. Grafique el puntaje de validación y el puntaje de entrenamiento con el tamaño del conjunto de datos en el eje x y otro gráfico con la complejidad del modelo en el eje x.
Para un alto sesgo en los modelos, el rendimiento del modelo en el conjunto de datos de validación es similar al rendimiento en el conjunto de datos de entrenamiento. Para una alta varianza en los modelos, el desempeño del modelo en el conjunto de validación es peor que el desempeño en el conjunto de entrenamiento.
69. ¿Qué es el teorema de Bayes? Indique al menos 1 caso de uso con respecto al contexto de aprendizaje automático.
El teorema de Bayes describe la probabilidad de un evento, con base en el conocimiento previo de las condiciones que podrían estar relacionadas con el evento. Por ejemplo, si el cáncer está relacionado con la edad, entonces, usando el teorema de Bayes, la edad de una persona puede usarse para evaluar con mayor precisión la probabilidad de que tenga cáncer que sin conocer la edad de la persona.
La regla de la cadena para la probabilidad bayesiana se puede usar para predecir la probabilidad de la siguiente palabra en la oración.
70. ¿Qué es Naïve Bayes? ¿Por qué es ingenuo?
Los clasificadores Naive Bayes son una serie de algoritmos de clasificación que se basan en el teorema de Bayes. Esta familia de algoritmos comparte un principio común que trata cada par de características de forma independiente mientras se clasifican.
Naive Bayes se considera Naive porque los atributos que contiene (para la clase) son independientes de otros en la misma clase. Esta falta de dependencia entre dos atributos de la misma clase crea la cualidad de la ingenuidad.
Lea más sobre Bayes ingenuos.
71. Explique cómo funciona un clasificador Naive Bayes.
Los clasificadores Naive Bayes son una familia de algoritmos que se derivan del teorema de probabilidad de Bayes. Funciona con el supuesto fundamental de que cada conjunto de dos características que se clasifican son independientes entre sí y cada característica hace una contribución igual e independiente al resultado.
72. ¿Qué significan los términos probabilidad previa y probabilidad marginal en el contexto del teorema de Naive Bayes?
La probabilidad previa es el porcentaje de variables binarias dependientes en el conjunto de datos. Si le dan un conjunto de datos y la variable dependiente es 1 o 0 y el porcentaje de 1 es 65% y el porcentaje de 0 es 35%. Entonces, la probabilidad de que cualquier entrada nueva para esa variable sea 1 sería del 65%.
La verosimilitud marginal es el denominador de la ecuación de Bayes y asegura que la probabilidad posterior sea válida haciendo su área 1.
73. Explique la diferencia entre Lasso y Ridge.
Lasso(L1) y Ridge(L2) son las técnicas de regularización donde penalizamos los coeficientes para encontrar la solución óptima. En ridge, la función de penalización se define por la suma de los cuadrados de los coeficientes y para Lasso, penalizamos la suma de los valores absolutos de los coeficientes. Otro tipo de método de regularización es ElasticNet, es una función de penalización híbrida de lasso y ridge.
74. ¿Cuál es la diferencia entre probabilidad y verosimilitud?
La probabilidad es la medida de la probabilidad de que ocurra un evento, es decir, ¿cuál es la certeza de que ocurrirá un evento específico? Donde-as una función de verosimilitud es una función de parámetros dentro del espacio de parámetros que describe la probabilidad de obtener los datos observados.
Entonces, la diferencia fundamental es que la probabilidad se asocia a los posibles resultados; la probabilidad se une a las hipótesis.
[Contenido incrustado]
75. ¿Por qué podarías tu árbol?
En el contexto de la ciencia de datos o AIML, la poda se refiere al proceso de reducir las ramas redundantes de un árbol de decisión. Los árboles de decisión son propensos al sobreajuste, la poda del árbol ayuda a reducir el tamaño y minimiza las posibilidades de sobreajuste. La poda consiste en convertir las ramas de un árbol de decisión en nodos hoja y eliminar los nodos hoja de la rama original. Sirve como una herramienta para realizar el intercambio.
76. ¿Exactitud del modelo o rendimiento del modelo? ¿Cuál preferirás y por qué?
Esta es una pregunta capciosa, primero se debe tener una idea clara, ¿qué es Model Performance? Si Rendimiento significa velocidad, entonces depende de la naturaleza de la aplicación, cualquier aplicación relacionada con el escenario en tiempo real necesitará alta velocidad como característica importante. Ejemplo: El mejor de los Resultados de la Búsqueda perderá su virtud si los resultados de la Consulta no aparecen rápido.
Si se insinúa el rendimiento por qué la precisión no es la virtud más importante: para cualquier conjunto de datos desequilibrados, más que la precisión, será una puntuación F1 que explicará el caso comercial y, en caso de que los datos estén desequilibrados, entonces la precisión y la recuperación serán más importante que descansar.
77. Enumere las ventajas y limitaciones del método de aprendizaje de diferencias temporales.
El método de aprendizaje de diferencia temporal es una combinación del método de Monte Carlo y el método de programación dinámica. Algunas de las ventajas de este método incluyen:
- Puede aprender en cada paso en línea o fuera de línea.
- También puede aprender de una secuencia que no está completa.
- Puede trabajar en ambientes continuos.
- Tiene una varianza más baja en comparación con el método MC y es más eficiente que el método MC.
Las limitaciones del método TD son:
- Es una estimación sesgada.
- Es más sensible a la inicialización.
78. ¿Cómo manejaría un conjunto de datos desequilibrado?
Las técnicas de muestreo pueden ayudar con un conjunto de datos desequilibrado. Hay dos formas de realizar el muestreo, Under Sample o Over Sampling.
En Under Sampling, reducimos el tamaño de la clase mayoritaria para que coincida con la clase minoritaria, lo que ayuda a mejorar el rendimiento del almacenamiento y la ejecución en tiempo de ejecución, pero potencialmente descarta información útil.
Para Over Sampling, aumentamos la muestra de la clase Minority y, por lo tanto, resolvemos el problema de la pérdida de información, sin embargo, nos metemos en el problema de tener Overfitting.
También hay otras técnicas:
Sobremuestreo basado en conglomerados – En este caso, el algoritmo de agrupamiento de K-means se aplica de forma independiente a las instancias de clase mayoritaria y minoritaria. Esto es para identificar grupos en el conjunto de datos. Posteriormente, cada clúster se sobremuestrea de modo que todos los clústeres de la misma clase tengan el mismo número de instancias y todas las clases tengan el mismo tamaño.
Técnica de sobremuestreo minoritario sintético (SMOTE) – Se toma un subconjunto de datos de la clase minoritaria como ejemplo y luego se crean nuevas instancias similares sintéticas que luego se agregan al conjunto de datos original. Esta técnica es buena para puntos de datos numéricos.
79. ¿Mencione algunas de las Técnicas EDA?
El análisis exploratorio de datos (EDA) ayuda a los analistas a comprender mejor los datos y constituye la base de mejores modelos.
Visualización
- Visualización univariante
- Visualización bivariada
- Visualización multivariante
Tratamiento de valor perdido – Reemplace los valores faltantes con la media/mediana
Detección de valores atípicos – Use Boxplot para identificar la distribución de valores atípicos, luego aplique IQR para establecer el límite para IQR
– Basado en la distribución, aplicar una transformación en las características
Escalar el conjunto de datos – Aplique el mecanismo MinMax, Standard Scaler o Z Score Scaling para escalar los datos.
Ingeniería de características – La necesidad del dominio y el conocimiento de SME ayudan al analista a encontrar campos derivados que pueden obtener más información sobre la naturaleza de los datos.
Reducción de dimensionalidad — Ayuda a reducir el volumen de datos sin perder mucha información
80. Mencione por qué la ingeniería de características es importante en la construcción de modelos y enumere algunas de las técnicas utilizadas para la ingeniería de características.
Los algoritmos necesitan funciones con algunas características específicas para funcionar correctamente. Los datos están inicialmente en forma cruda. Debe extraer características de estos datos antes de proporcionarlos al algoritmo. Este proceso se llama ingeniería de características. Cuando tiene características relevantes, la complejidad de los algoritmos se reduce. Entonces, incluso si se usa un algoritmo no ideal, los resultados son precisos.
La ingeniería de funciones tiene principalmente dos objetivos:
- Prepare el conjunto de datos de entrada adecuado para que sea compatible con las restricciones del algoritmo de aprendizaje automático.
- Mejore el rendimiento de los modelos de aprendizaje automático.
Algunas de las técnicas utilizadas para la ingeniería de características incluyen la imputación, el binning, el manejo de valores atípicos, la transformación de registros, las operaciones de agrupación, la codificación One-Hot, la división de características, el escalado y la extracción de fechas.
81. ¿Diferenciar entre modelado estadístico y aprendizaje automático?
Los modelos de aprendizaje automático consisten en hacer predicciones precisas sobre las situaciones, como Foot Fall en restaurantes, precio de acciones, etc., mientras que los modelos estadísticos están diseñados para inferir sobre las relaciones entre variables, como lo que impulsa las ventas en un restaurante, es es comida o ambiente.
82. ¿Diferenciar entre Boosting y Bagging?
Embolsado y refuerzo son variantes de las técnicas de conjunto.
Bootstrap Agregación o embolsado es un método que se utiliza para reducir la varianza de algoritmos que tienen una varianza muy alta. Los árboles de decisión son una familia particular de clasificadores que son susceptibles de tener un alto sesgo.
Los árboles de decisión son muy sensibles al tipo de datos en los que se entrenan. Por lo tanto, la generalización de los resultados suele ser mucho más compleja de lograr en ellos a pesar de un ajuste muy fino. Los resultados varían mucho si los datos de entrenamiento se modifican en los árboles de decisión.
Por lo tanto, se utiliza el embolsado donde se realizan múltiples árboles de decisión que se entrenan en muestras de los datos originales y el resultado final es el promedio de todos estos modelos individuales.
Impulso es el proceso de utilizar un sistema de clasificación n-débil para la predicción, de modo que cada clasificador débil compense las debilidades de sus clasificadores. Por clasificador débil, implicamos un clasificador que funciona mal en un conjunto de datos dado.
Es evidente que impulsar no es un algoritmo sino un proceso. Los clasificadores débiles utilizados son generalmente regresión logística, árboles de decisión poco profundos, etc.
Hay muchos algoritmos que hacen uso de procesos de impulso, pero dos de ellos se utilizan principalmente: Adaboost y Gradient Boosting y XGBoost.
83. ¿Cuál es el significado de Gamma y Regularización en SVM?
El gamma define la influencia. Valores bajos significan 'lejos' y valores altos significan 'cerca'. Si gamma es demasiado grande, el radio del área de influencia de los vectores de soporte solo incluye el propio vector de soporte y ninguna cantidad de regularización con C podrá evitar el sobreajuste. Si gamma es muy pequeño, el modelo está demasiado restringido y no puede capturar la complejidad de los datos.
El parámetro de regularización (lambda) sirve como un grado de importancia que se le da a las clasificaciones erróneas. Esto se puede usar para dibujar la compensación con OverFitting.
84. Defina el trabajo de la curva ROC
La representación gráfica del contraste entre las tasas de verdaderos positivos y la tasa de falsos positivos en varios umbrales se conoce como curva ROC. Se utiliza como un proxy para el equilibrio entre verdaderos positivos y falsos positivos.
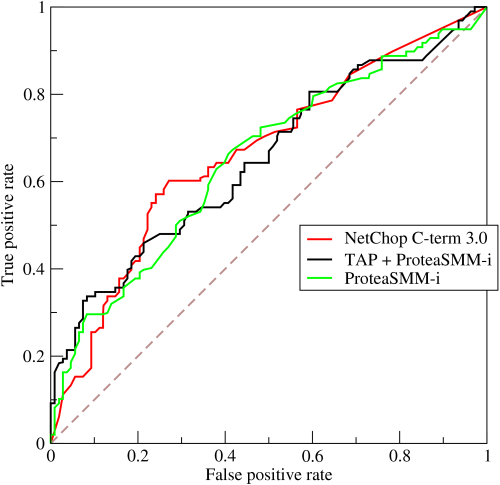
85. ¿Cuál es la diferencia entre un modelo generativo y discriminativo?
Un modelo generativo aprende las diferentes categorías de datos. Por otro lado, un modelo discriminativo solo aprenderá las distinciones entre diferentes categorías de datos. Los modelos discriminativos funcionan mucho mejor que los modelos generativos cuando se trata de tareas de clasificación.
86. ¿Qué son los hiperparámetros y en qué se diferencian de los parámetros?
Un parámetro es una variable que es interna al modelo y cuyo valor se estima a partir de los datos de entrenamiento. A menudo se guardan como parte del modelo aprendido. Los ejemplos incluyen ponderaciones, sesgos, etc.
Un hiperparámetro es una variable externa al modelo cuyo valor no se puede estimar a partir de los datos. A menudo se utilizan para estimar los parámetros del modelo. La elección de los parámetros es sensible a la implementación. Los ejemplos incluyen tasa de aprendizaje, capas ocultas, etc.
87. ¿Qué es romper un conjunto de puntos? Explique la dimensión de VC.
Para romper una configuración dada de puntos, un clasificador debe poder, para todas las posibles asignaciones de puntos positivos y negativos, dividir perfectamente el plano de manera que los puntos positivos estén separados de los puntos negativos. Para una configuración de n puntos, hay 2n asignaciones posibles de positivo o negativo.
Al elegir un clasificador, debemos considerar el tipo de datos que se clasificarán y esto se puede conocer por la dimensión VC de un clasificador. Se define como la cardinalidad del mayor conjunto de puntos que el algoritmo de clasificación, es decir, el clasificador, puede romper. Para tener una dimensión VC de at menos n, un clasificador debe ser capaz de romper una única configuración dada de n puntos.
88. ¿Cuáles son algunas de las diferencias entre una lista enlazada y una matriz?
Matrices y Listas enlazadas ambos se utilizan para almacenar datos lineales de tipos similares. Sin embargo, hay algunas diferencias entre ellos.
| Formación | Lista enlazada |
| Los elementos están bien indexados, lo que facilita el acceso a elementos específicos | Es necesario acceder a los elementos de forma acumulativa |
| Las operaciones (inserción, eliminación) son más rápidas en matriz | La lista vinculada toma un tiempo lineal, lo que hace que las operaciones sean un poco más lentas |
| Las matrices son de tamaño fijo. | Las listas enlazadas son dinámicas y flexibles |
| La memoria se asigna durante el tiempo de compilación en una matriz | La memoria se asigna durante la ejecución o el tiempo de ejecución en la lista Vinculada. |
| Los elementos se almacenan consecutivamente en matrices. | Los elementos se almacenan aleatoriamente en la lista Vinculada |
| La utilización de la memoria es ineficiente en la matriz | La utilización de la memoria es eficiente en la lista enlazada. |
89. ¿Qué es el método meshgrid() y el método contourf()? Indique algunos usos de ambos.
La función meshgrid() en numpy toma dos argumentos como entrada: rango de valores x en la cuadrícula, rango de valores y en la cuadrícula, mientras que meshgrid debe construirse antes de que se use la función contourf() en matplotlib, que toma muchos Entradas: valores x, valores y, curva de ajuste (línea de contorno) que se trazará en la cuadrícula, colores, etc.
La función Meshgrid () se usa para crear una cuadrícula usando matrices 1-D de entradas del eje x y entradas del eje y para representar la indexación de la matriz. Contourf () se usa para dibujar contornos rellenos usando las entradas del eje x dadas, las entradas del eje y, la línea de contorno, los colores, etc.
90. Describa una tabla hash.
Hashing es una técnica para identificar objetos únicos de un grupo de objetos similares. Las funciones hash son claves grandes convertidas en claves pequeñas en técnicas de hash. Los valores de las funciones hash se almacenan en estructuras de datos que se conocen como tablas hash.
91. Enumera las ventajas y desventajas del uso de redes neuronales.
Ventajas:
Podemos almacenar información en toda la red en lugar de almacenarla en una base de datos. Tiene la capacidad de trabajar y dar una buena precisión incluso con información inadecuada. A red neural Tiene capacidad de procesamiento paralelo y memoria distribuida.
Desventajas:
Las redes neuronales requieren procesadores que sean capaces de realizar procesamiento en paralelo. El funcionamiento inexplicable de la red también es un gran problema, ya que reduce la confianza en la red en algunas situaciones, como cuando tenemos que mostrar el problema que notamos a la red. La duración de la red es mayormente desconocida. Solo podemos saber que el entrenamiento ha terminado mirando el valor de error pero no nos da resultados óptimos.
92. Debe entrenar un conjunto de datos de 12 GB utilizando una red neuronal con una máquina que tiene solo 3 GB de RAM. ¿Cómo lo harías?
Podemos usar matrices NumPy para resolver este problema. Cargue todos los datos en una matriz. En NumPy, las matrices tienen una propiedad para mapear el conjunto de datos completo sin cargarlo completamente en la memoria. Podemos pasar el índice de la matriz, dividiendo los datos en lotes, para obtener los datos necesarios y luego pasar los datos a las redes neuronales. Pero tenga cuidado de mantener el tamaño del lote normal.
Preguntas de la entrevista de codificación de aprendizaje automático
93. Escriba un código simple para binarizar datos.
La conversión de datos en valores binarios sobre la base de cierto umbral se conoce como binarización de datos. Los valores por debajo del umbral se establecen en 0 y los que están por encima del umbral se establecen en 1, lo que es útil para la ingeniería de características.
Código:
from sklearn.preprocessing import Binarizer
import pandas
import numpy
names_list = ['Alaska', 'Pratyush', 'Pierce', 'Sandra', 'Soundarya', 'Meredith', 'Richard', 'Jackson', 'Tom',’Joe’]
data_frame = pandas.read_csv(url, names=names_list)
array = dataframe.values
# Splitting the array into input and output A = array [: 0:7]
B = array [:7]
binarizer = Binarizer(threshold=0.0). fit(X)
binaryA = binarizer.transform(A)
numpy.set_printoptions(precision=5)
print (binaryA [0:7:])
Aprendizaje automático con preguntas de entrevista de Python
94. ¿Qué es una matriz?
El proyecto matriz se define como una colección de artículos similares, almacenados de manera contigua. Arrays es un concepto intuitivo, ya que la necesidad de agrupar objetos similares surge en nuestra vida cotidiana. Los arreglos satisfacen la misma necesidad. ¿Cómo se almacenan en la memoria? Las matrices consumen bloques de datos, donde cada elemento de la matriz consume una unidad de memoria. El tamaño de la unidad depende del tipo de datos que se utilicen. Por ejemplo, si el tipo de datos de los elementos de la matriz es int, se utilizarán 4 bytes de datos para almacenar cada elemento. Para el tipo de datos de carácter, se utilizará 1 byte. Esto es específico de la implementación y las unidades anteriores pueden cambiar de una computadora a otra.
Ejemplo:
frutas = ['manzana', plátano', piña']
En el caso anterior, frutas es una lista que consta de tres frutas. Para acceder a ellos individualmente, utilizamos sus índices. Python y C son lenguajes indexados en 0, es decir, el primer índice es 0. MATLAB, por el contrario, comienza en 1 y, por lo tanto, es un lenguaje indexado en 1.
95. ¿Cuáles son las ventajas y desventajas de usar un Array?
- Ventajas:
- El acceso aleatorio está habilitado
- ahorra memoria
- Caché amigable
- Tiempo de compilación predecible
- Ayuda en la reutilización del código.
- Desventajas:
- La adición y eliminación de registros requiere mucho tiempo, aunque obtenemos el elemento de interés de inmediato a través del acceso aleatorio. Esto se debe al hecho de que los elementos deben reordenarse después de la inserción o eliminación.
- Si los bloques de memoria contiguos no están disponibles en la memoria, entonces hay una sobrecarga en la CPU para buscar la ubicación contigua más óptima disponible para el requisito.
Ahora que sabemos qué son los arreglos, los entenderemos en detalle resolviendo algunas preguntas de la entrevista. Antes de eso, veamos las funciones que Python como lenguaje proporciona para matrices, también conocidas como listas.
append() – Agrega un elemento al final de la lista
copy(): devuelve una copia de una lista.
reverse() – invierte los elementos de la lista
sort(): ordena los elementos en orden ascendente de forma predeterminada.
96. ¿Qué son las listas en Python?
Lists es una estructura de datos efectiva provista en python. Hay varias funcionalidades asociadas al mismo. Consideremos el escenario en el que queremos copiar una lista a otra lista. Si se tuviera que hacer la misma operación en el lenguaje de programación C, tendríamos que escribir nuestra propia función para implementarla.
Por el contrario, Python nos proporciona una función llamada copiar. Podemos copiar una lista a otra simplemente llamando a la función de copia.
new_list = old_list.copy()Debemos tener cuidado al usar la función. copy() es una función de copia superficial, es decir, solo almacena las referencias de la lista original en la nueva lista. Si el argumento dado es una estructura de datos compuesta como una lista, Python crea otro objeto del mismo tipo (en este caso, una nueva lista), pero para todo lo que está dentro de la lista anterior, solo se copia su referencia. Esencialmente, la nueva lista consta de referencias a los elementos de la lista anterior.
Por lo tanto, al cambiar la lista original, los valores de la nueva lista también cambian. Esto puede ser peligroso en muchas aplicaciones. Por lo tanto, Python nos proporciona otra funcionalidad llamada copia profunda. Intuitivamente, podemos considerar que deepcopy() seguiría el mismo paradigma, y la única diferencia sería que para cada elemento llamaremos recursivamente a deepcopy. En la práctica, este no es el caso.
deepcopy() conserva la estructura gráfica de los datos compuestos originales. Entendamos esto mejor con la ayuda de un ejemplo:
import copy.deepcopy
a = [1,2]
b = [a,a] # there's only 1 object a
c = deepcopy(b) # check the result by executing these lines
c[0] is a # return False, a new object a' is created
c[0] is c[1] # return True, c is [a',a'] not [a',a'']Esta es la parte complicada, durante el proceso de deepcopy() se usa una tabla hash implementada como un diccionario en python para mapear: la referencia old_object a la referencia new_object.
Por lo tanto, esto evita duplicados innecesarios y, por lo tanto, conserva la estructura de la estructura de datos compuesta copiada. Así, en este caso, c[0] no es igual a a, ya que internamente sus direcciones son diferentes.
Normal copy
>>> a = [[1, 2, 3], [4, 5, 6]]
>>> b = list(a)
>>> a
[[1, 2, 3], [4, 5, 6]]
>>> b
[[1, 2, 3], [4, 5, 6]]
>>> a[0][1] = 10
>>> a
[[1, 10, 3], [4, 5, 6]]
>>> b # b changes too -> Not a deepcopy.
[[1, 10, 3], [4, 5, 6]] Deep copy >>> import copy
>>> b = copy.deepcopy(a)
>>> a
[[1, 10, 3], [4, 5, 6]]
>>> b
[[1, 10, 3], [4, 5, 6]]
>>> a[0][1] = 9
>>> a
[[1, 9, 3], [4, 5, 6]]
>>> b # b doesn't change -> Deep Copy
[[1, 10, 3], [4, 5, 6]]Ahora que hemos entendido el concepto de listas, resolvamos las preguntas de la entrevista para obtener una mejor exposición sobre las mismas.
97. Dada una matriz de enteros donde cada elemento representa el número máximo de pasos que se pueden realizar desde ese elemento. La tarea es encontrar el número mínimo de saltos para llegar al final de la matriz (a partir del primer elemento). Si un elemento es 0, entonces no puede moverse a través de ese elemento.
Solución: este problema se conoce como el problema del final de la matriz. Queremos determinar el número mínimo de saltos necesarios para llegar al final. El elemento en la matriz representa el número máximo de saltos que puede tomar ese elemento en particular.
Entendamos cómo abordar el problema inicialmente.
Tenemos que llegar al final. Por lo tanto, tengamos una cuenta que nos diga qué tan cerca estamos del final. Considere la matriz A=[1,2,3,1,1]
In the above example we can go from > 2 - >3 - > 1 - > 1 - 4 jumps
1 - > 2 - > 1 - > 1 - 3 jumps
1 - > 2 - > 3 - > 1 - 3 jumpsPor lo tanto, tenemos una idea clara del problema. Propongamos una lógica para lo mismo.
Comencemos desde el final y retrocedamos, ya que eso tiene más sentido intuitivamente. Usaremos las variables right y prev_r que denotan el derecho anterior para realizar un seguimiento de los saltos.
Inicialmente, right = prev_r = penúltimo elemento. Consideramos la distancia de un elemento al final, y el número de saltos posibles por ese elemento. Por lo tanto, si la suma del número de saltos posibles y la distancia es mayor que el elemento anterior, descartaremos el elemento anterior y usaremos el valor del segundo elemento para saltar. Pruébelo usando un lápiz y papel primero. La lógica parecerá muy sencilla de implementar. Luego, impleméntelo por su cuenta y luego verifique con el resultado.
def min_jmp(arr): n = len(arr) right = prev_r = n-1 count = 0 # We start from rightmost index and travesre array to find the leftmost index # from which we can reach index 'right' while True: for j in (range(prev_r-1,-1,-1)): if j + arr[j] >= prev_r: right = j if prev_r != right: prev_r = right else: break count += 1 return count if right == 0 else -1 # Enter the elements separated by a space
arr = list(map(int, input().split()))
print(min_jmp(n, arr)) 98. Dada una cadena S que consta solo de 'a's y 'b's, imprima el último índice de la 'b' presente en ella.
Cuando tenemos una cadena de a y b, podemos encontrar inmediatamente la primera ubicación de un carácter que aparece. Por lo tanto, para encontrar la última aparición de un carácter, invertimos la cadena y buscamos la primera aparición, que es equivalente a la última aparición en la cadena original.
Aquí, se nos da la entrada como una cadena. Por lo tanto, comenzamos dividiendo los elementos de los caracteres usando la función split. Más tarde, invertimos la matriz, buscamos el valor de la posición de la primera aparición y obtenemos el índice encontrando el valor len – position -1, donde position es el valor del índice.
def split(word): return [(char) for char in word] a = input()
a= split(a)
a_rev = a[::-1]
pos = -1
for i in range(len(a_rev)): if a_rev[i] == ‘b’: pos = len(a_rev)- i -1 print(pos) break else: continue
if pos==-1: print(-1)99. Gira los elementos de una matriz d posiciones a la izquierda. Veamos inicialmente un ejemplo.
A = [1,2,3,4,5]
A <<2
[3,4,5,1,2]
A<<3
[4,5,1,2,3]Aquí existe un patrón, es decir, los primeros d elementos se intercambian con los últimos nd +1 elementos. Por lo tanto, podemos simplemente intercambiar los elementos. ¿Correcto? ¿Qué pasa si el tamaño de la matriz es enorme, digamos 10000 elementos? Hay posibilidades de error de memoria, error de tiempo de ejecución, etc. Por lo tanto, lo hacemos con más cuidado. Rotamos los elementos uno por uno para evitar los errores anteriores, en caso de matrices grandes.
# Rotate all the elements left by 1 position
def rot_left_once ( arr):
n = len( arr) tmp = arr [0] for i in range ( n-1): #[0,n-2] arr[i] = arr[i + 1]
arr[n-1] = tmp # Use the above function to repeat the process for d times.
def rot_left (arr, d): n = len (arr) for i in range (d): rot_left_once ( arr, n) arr = list( map( int, input().split()))
rot =int( input())
leftRotate ( arr, rot) for i in range( len(arr)): print( arr[i], end=' ')100. Problema de atrapamiento de agua
Dada una matriz arr[] de N enteros no negativos que representa la altura de los bloques en el índice I, donde el ancho de cada bloque es 1. Calcule cuánta agua puede quedar atrapada entre los bloques después de la lluvia.
# La estructura es como la siguiente:
# | |
# |_|
# la respuesta es que podemos atrapar dos unidades de agua.
Solución: Nos dan una matriz, donde cada elemento denota la altura del bloque. Una unidad de altura es igual a una unidad de agua, dado que existe espacio entre los 2 elementos para almacenarla. Por lo tanto, necesitamos averiguar todos los pares que existen que pueden almacenar agua. Tenemos que cuidar los posibles casos:
- No debe haber superposición de agua ahorrada
- El agua no debe desbordarse
Por lo tanto, busquemos comenzar con los elementos extremos y avanzar hacia el centro.
n = int(input())
arr = [int(i) for i in input().split()]
left, right = [arr[0]], [0] * n # left =[arr[0]]
#right = [ 0 0 0 0…0] n terms
right[n-1] = arr[-1] # right most element# usamos dos matrices izquierda[ ] y derecha[ ], que realizan un seguimiento de los elementos mayores que todos
# elementos el orden de recorrido respectivamente.
for elem in arr[1 : ]: left.append(max(left[-1], elem) )
for i in range( len( arr)-2, -1, -1): right[i] = max( arr[i] , right[i+1] )
water = 0
# once we have the arrays left, and right, we can find the water capacity between these arrays. for i in range( 1, n - 1): add_water = min( left[i - 1], right[i]) - arr[i] if add_water > 0: water += add_water
print(water)101. Explique los vectores propios y los valores propios.
Ans. Las transformaciones lineales son útiles para comprender el uso de vectores propios. Encuentran su principal uso en la creación de covarianza y correlación Matrices en ciencia de datos.
En pocas palabras, los vectores propios son entidades direccionales a lo largo de las cuales se pueden aplicar características de transformación lineal como compresión, volteo, etc.
Los valores propios son la magnitud de las características de transformación lineal a lo largo de cada dirección de un vector propio.
102. ¿Cómo definiría el número de clústeres en un algoritmo de agrupamiento?
Ans. El número de grupos se puede determinar encontrando la puntuación de la silueta. A menudo, nuestro objetivo es obtener algunas inferencias de los datos utilizando técnicas de agrupación para que podamos tener una imagen más amplia de una serie de clases representadas por los datos. En este caso, la puntuación de la silueta nos ayuda a determinar el número de centros de conglomerados para agrupar nuestros datos.
Otra técnica que se puede utilizar es el método del codo.
103. ¿Cuáles son las métricas de rendimiento que se pueden usar para estimar la eficiencia de un modelo de regresión lineal?
Ans. La métrica de rendimiento que se utiliza en este caso es:
- Error medio cuadrado
- R2 Puntuación
- R ajustado2 Puntuación
- Puntuación absoluta media
104. ¿Cuál es el método predeterminado de división en árboles de decisión?
El método predeterminado de división en árboles de decisión es el índice de Gini. El índice de Gini es la medida de la impureza de un nodo en particular.
Esto se puede cambiar haciendo cambios en los parámetros del clasificador.
105. ¿Cómo es útil el valor p?
Ans. El valor p da la probabilidad de que la hipótesis nula sea verdadera. Nos da la significación estadística de nuestros resultados. En otras palabras, el valor p determina la confianza de un modelo en un resultado particular.
106. ¿Se puede usar la regresión logística para clases de más de 2?
Ans. No, la regresión logística no se puede usar para clases de más de 2, ya que es un clasificador binario. Para los algoritmos de clasificación de clases múltiples como los árboles de decisión, los clasificadores de Naïve Bayes son más adecuados.
107. ¿Qué son los hiperparámetros de un modelo de regresión logística?
Ans. La penalización del clasificador, el solucionador del clasificador y el clasificador C son los hiperparámetros entrenables de un clasificador de regresión logística. Estos se pueden especificar exclusivamente con valores en Grid Search para hiperafinar un clasificador logístico.
108. ¿Nombre algunos hiperparámetros de árboles de decisión?
Ans. Las características más importantes que se pueden sintonizar en los árboles de decisión son:
- Criterios de división
- Min_hojas
- Min_muestras
- Máxima profundidad
109. ¿Cómo lidiar con la multicolinealidad?
Ans. La colinealidad múltiple se puede tratar mediante los siguientes pasos:
- Elimine predictores altamente correlacionados del modelo.
- Utilice la regresión de mínimos cuadrados parciales (PLS) o el análisis de componentes principales
110. Que es ¿Heterocedasticidad?
Ans. Es una situación en la que la varianza de una variable es desigual en el rango de valores de la variable predictora.
Debe evitarse en la regresión, ya que introduce una varianza innecesaria.
111. ¿Es el modelo ARIMA una buena opción para todos los problemas de series de tiempo?
Ans. No, el modelo ARIMA no es adecuado para todos los tipos de problemas de series temporales. Hay situaciones en las que el modelo ARMA y otros también vienen bien.
ARIMA es mejor cuando es necesario capturar diferentes estructuras temporales estándar para datos de series temporales.
112. ¿Cómo maneja el desequilibrio de clases en un problema de clasificación?
Ans. El desequilibrio de clases se puede tratar de las siguientes maneras:
- Uso de pesos de clase
- Uso de muestreo
- Usando SMOTE
- Elegir funciones de pérdida como Focal Loss
113. ¿Cuál es el papel de la validación cruzada?
Ans. La validación cruzada es una técnica que se utiliza para aumentar el rendimiento de un algoritmo de aprendizaje automático, donde la máquina recibe datos de muestra de los mismos datos varias veces. El muestreo se realiza para que el conjunto de datos se divida en partes pequeñas del mismo número de filas, y se elige una parte aleatoria como conjunto de prueba, mientras que todas las demás partes se eligen como conjuntos de trenes.
114. ¿Qué es un modelo de votación?
Ans. Un modelo de votación es un modelo de conjunto que combina varios clasificadores pero para producir el resultado final, en el caso de un modelo basado en clasificación, tiene en cuenta la clasificación de un cierto punto de datos de todos los modelos y elige el más avalado/votado/ opción generada de todas las clases dadas en la columna de destino.
115. ¿Cómo lidiar con muy pocas muestras de datos? ¿Es posible hacer un modelo con él?
Ans. Si hay muy pocas muestras de datos, podemos utilizar el sobremuestreo para producir nuevos puntos de datos. De esta manera, podemos tener nuevos puntos de datos.
116. ¿Qué son los hiperparámetros de una SVM?
Ans. El valor gamma, el valor c y el tipo de kernel son los hiperparámetros de un modelo SVM.
117. ¿Qué es la elaboración de perfiles de Pandas?
Ans. La creación de perfiles de Pandas es un paso para encontrar la cantidad efectiva de datos utilizables. Nos brinda las estadísticas de los valores NULL y los valores utilizables y, por lo tanto, hace que la selección de variables y la selección de datos para construir modelos en la fase de preprocesamiento sean muy efectivas.
118. ¿Qué impacto tiene la correlación en PCA?
Ans. Si los datos están correlacionados, PCA no funciona bien. Debido a la correlación de variables, la varianza efectiva de las variables disminuye. Por lo tanto, los datos correlacionados cuando se usan para PCA no funcionan bien.
119. ¿En qué se diferencia PCA de LDA?
Ans. PCA no está supervisado. LDA no está supervisado.
PCA tiene en cuenta la varianza. LDA tiene en cuenta la distribución de clases.
120. ¿Qué métricas de distancia se pueden usar en KNN?
Ans. Las siguientes métricas de distancia se pueden usar en KNN.
- Manhattan
- minkowski
- tanimoto
- jaccard
- mahalanobis
121. ¿Qué métricas se pueden usar para medir la correlación de datos categóricos?
Ans. La prueba de chi cuadrado se puede utilizar para hacerlo. Da la medida de correlación entre predictores categóricos.
122. ¿Qué algoritmo se puede usar en la imputación de valores en categorías de datos tanto categóricos como continuos?
Ans. KNN es el único algoritmo que se puede utilizar para la imputación de variables categóricas y continuas.
123. ¿Cuándo se debe preferir la regresión de cresta a lazo?
Ans. Deberíamos usar la regresión de cresta cuando queremos usar todos los predictores y no eliminar ninguno, ya que reduce los valores de los coeficientes pero no los anula.
124. ¿Qué algoritmos se pueden usar para la selección de variables importantes?
Ans. Random Forest, Xgboost y plot gráficos de importancia de variables se pueden utilizar para la selección de variables.
125. ¿Qué técnica de conjunto utilizan los bosques aleatorios?
Ans. El embolsado es la técnica utilizada por Random Forests. Los bosques aleatorios son una colección de árboles que funcionan con datos de muestra del conjunto de datos original y la predicción final es un promedio votado de todos los árboles.
126. ¿Qué técnica de conjunto utilizan los árboles potenciadores de gradiente?
Ans. Boosting es la técnica utilizada por GBM.
127. Si tenemos un error de sesgo alto, ¿qué significa? ¿Cómo tratarlo?
Ans. Un alto error de sesgo significa que el modelo que estamos usando está ignorando todas las tendencias importantes en el modelo y el modelo no se ajusta.
Para reducir el desajuste:
- Necesitamos aumentar la complejidad del modelo.
- Es necesario aumentar el número de funciones.
A veces también da la impresión de que los datos son ruidosos. Por lo tanto, el ruido de los datos debe eliminarse para que el modelo encuentre las señales más importantes para hacer predicciones efectivas.
Aumentar el número de épocas da como resultado aumentar la duración del entrenamiento del modelo. Es útil para reducir el error.
128. ¿Qué tipo de muestreo es mejor para un modelo de clasificación y por qué?
Ans. El muestreo estratificado es mejor en caso de problemas de clasificación porque tiene en cuenta el equilibrio de las clases en el tren y los conjuntos de prueba. La proporción de clases se mantiene y, por lo tanto, el modelo funciona mejor. En caso de muestreo aleatorio de datos, los datos se dividen en dos partes sin tener en cuenta las clases de equilibrio en el tren y los conjuntos de prueba. Por lo tanto, algunas clases pueden estar presentes solo en conjuntos tarin o conjuntos de validación. Por lo tanto, los resultados del modelo resultante son pobres en este caso.
129. ¿Cuál es una buena métrica para medir el nivel de multicolinealidad?
Ans. VIF o 1/tolerancia es una buena medida para medir la multicolinealidad en los modelos. VIF es el porcentaje de la varianza de un predictor que no se ve afectado por otros predictores. Cuanto mayor sea el valor de VIF, mayor será la multicolinealidad entre los predictores.
A regla de oro para interpretar el factor de inflación de la varianza:
- 1 = no correlacionado.
- Entre 1 y 5 = moderadamente correlacionado.
- Mayor que 5 = altamente correlacionado.
130. ¿Cuándo se puede tratar un valor categórico como una variable continua y qué efecto tiene cuando se hace así?
Ans. Un predictor categórico puede tratarse como continuo cuando la naturaleza de los puntos de datos que representa es ordinal. Si la variable predictora tiene datos ordinales, puede tratarse como continua y su inclusión en el modelo aumenta el rendimiento del modelo.
131. ¿Cuál es el papel de la máxima verosimilitud en la regresión logística?
Ans. La ecuación de máxima verosimilitud ayuda a estimar los valores más probables de los coeficientes de la variable predictora del estimador, lo que produce resultados que son los más probables o los más probables y están bastante cerca de los valores de verdad.
132. ¿Qué distancia medimos en el caso de KNN?
Ans. La distancia de hamming se mide en el caso de KNN para la determinación de los vecinos más cercanos. Kmeans utiliza la distancia euclidiana.
133. ¿Qué es un gasoducto?
Ans. Una canalización es una forma sofisticada de escribir software de modo que cada acción prevista durante la construcción de un modelo se pueda serializar y el proceso llame a las funciones individuales para las tareas individuales. Las tareas se llevan a cabo en secuencia para una secuencia determinada de puntos de datos y todo el proceso se puede ejecutar en n subprocesos mediante el uso de estimadores compuestos en scikit learn.
134. ¿Qué técnica de muestreo es la más adecuada cuando se trabaja con datos de series de tiempo?
Ans. Podemos usar un muestreo iterativo personalizado de modo que agreguemos continuamente muestras al conjunto de trenes. Solo debemos tener en cuenta que la muestra utilizada para la validación debe agregarse a los siguientes conjuntos de trenes y se usa una nueva muestra para la validación.
135. ¿Cuáles son los beneficios de la poda?
Ans. La poda ayuda en lo siguiente:
- Reduce el sobreajuste
- Acorta el tamaño del árbol.
- Reduce la complejidad del modelo.
- Aumenta el sesgo
136. ¿Qué es la distribución normal?
Ans. La distribución que tiene las siguientes propiedades se llama distribución normal.
- La media, la moda y la mediana son todas iguales.
- La curva es simétrica en el centro (es decir, alrededor de la media, μ).
- Exactamente la mitad de los valores están a la izquierda del centro y exactamente la mitad de los valores están a la derecha.
- El área total bajo la curva es 1.
137. ¿Qué es la regla del 68 por ciento en la distribución normal?
Ans. La distribución normal es una curva en forma de campana. La mayoría de los puntos de datos están alrededor de la mediana. Por lo tanto, aproximadamente el 68 por ciento de los datos están alrededor de la mediana. Dado que no hay sesgo y tiene forma de campana.
138. ¿Qué es una prueba de chi-cuadrado?
Ans. Un chi-cuadrado determina si los datos de una muestra coinciden con una población.
A prueba de chi-cuadrado para la independencia compara dos variables en una tabla de contingencia para ver si están relacionadas.
Una estadística de prueba de chi-cuadrado muy pequeña implica que los datos observados se ajustan extremadamente bien a los datos esperados.
139. ¿Qué es una variable aleatoria??
Ans. Una variable aleatoria es un conjunto de posibles valores de un experimento aleatorio. Ejemplo: Lanzar una moneda: podemos obtener cara o cruz. Lanzamiento de un dado: obtenemos 6 valores
140. ¿Qué es el grado de libertad?
Ans. Es el número de valores o cantidades independientes que se pueden asignar a una distribución estadística. Se utiliza en la prueba de hipótesis y la prueba de chi-cuadrado.
141. ¿Qué tipo de sistema de recomendación utiliza Amazon para recomendar artículos similares?
Ans. Amazon utiliza un algoritmo de filtrado colaborativo para la recomendación de artículos similares. Es un mapeo basado en la similitud de usuario a usuario de la semejanza del usuario y la susceptibilidad a comprar.
142. ¿Qué es un falso positivo?
Ans. Es un resultado de prueba que indica erróneamente que está presente una condición o atributo en particular.
Ejemplo: "La prueba de esfuerzo, una herramienta de diagnóstico de rutina utilizada para detectar enfermedades cardíacas, da como resultado una cantidad significativa de falsos positivos en mujeres"
143. ¿Qué es un falso negativo?
Ans. Un resultado de prueba que indica erróneamente que una condición o atributo en particular está ausente.
Ejemplo: "es posible obtener un falso negativo: la prueba dice que no está embarazada cuando lo está"
144. ¿De qué está compuesto el término de error en la regresión?
Ans. El error es la suma del error de sesgo+error de varianza+error irreducible en la regresión. El error de sesgo y de varianza se puede reducir, pero no el error irreducible.
145. ¿Qué métrica de rendimiento es mejor R2 o R2 ajustada?
Ans. R2 ajustado porque el rendimiento de los predictores lo afecta. R2 es independiente de los predictores y muestra una mejora del rendimiento a través del aumento si aumenta el número de predictores.
146. ¿Cuál es la diferencia entre el error Tipo I y Tipo II?
El error tipo I y tipo II en el aprendizaje automático se refiere a valores falsos. El tipo I es equivalente a un falso positivo, mientras que el tipo II es equivalente a un falso negativo. En el error tipo I, una hipótesis que debería aceptarse no se acepta. De manera similar, para el error de tipo II, se rechaza la hipótesis que debería haberse aceptado en primer lugar.
147. ¿Qué entiendes por regularización de L1 y L2?
Regularización L2: Intenta repartir el error entre todos los términos. L2 corresponde a una previa gaussiana.
Regularización L1: es más binario/disperso, con muchas variables a las que se les asigna un 1 o un 0 en la ponderación. L1 corresponde a la fijación de un prior laplaceano en los términos.
148. ¿Cuál es mejor, el algoritmo Naive Bayes o los árboles de decisión?
Aunque depende del problema que esté resolviendo, algunas ventajas generales son las siguientes:
Bayesiano ingenuo:
- Funciona bien con conjuntos de datos pequeños en comparación con DT que necesitan más datos
- menor sobreajuste
- Más pequeño en tamaño y más rápido en el procesamiento
Árboles de decisión:
- Los árboles de decisión son muy flexibles, fáciles de entender y fáciles de depurar.
- No se requiere preprocesamiento o transformación de características
- Propenso al sobreajuste, pero puede usar la poda o los bosques aleatorios para evitar eso.
149. ¿Qué quiere decir con la curva ROC?
Características operativas del receptor (curva ROC): la curva ROC ilustra la capacidad de diagnóstico de un clasificador binario. Se calcula/crea trazando el Positivo Verdadero contra el Positivo Falso en varias configuraciones de umbral. La métrica de rendimiento de la curva ROC es AUC (área bajo la curva). Cuanto mayor sea el área bajo la curva, mejor será el poder de predicción del modelo.
150. ¿Qué quiere decir con curva AUC?
AUC (área bajo la curva). Cuanto mayor sea el área bajo la curva, mejor será el poder de predicción del modelo.
151. ¿Qué es la verosimilitud logarítmica en la regresión logística?
Es la suma de los residuos de verosimilitud. A nivel de registro, se calcula el logaritmo natural del error (residual) para cada registro, se multiplica por menos uno y se suman esos valores. Luego, ese total se usa como base para la desviación (2 x ll) y la probabilidad (exp(ll)).
El mismo cálculo se puede aplicar a un modelo ingenuo que asume absolutamente ningún poder predictivo y un modelo saturado que asume predicciones perfectas.
Los valores de probabilidad se usan para comparar diferentes modelos, mientras que las desviaciones (prueba, ingenua y saturada) se pueden usar para determinar el poder predictivo y la precisión. La precisión de la regresión logística del modelo siempre será del 100 por ciento para el conjunto de datos de desarrollo, pero ese no es el caso una vez que se aplica un modelo a otro conjunto de datos.
152. ¿Cómo evaluaría un modelo de regresión logística?
La evaluación del modelo es una parte muy importante en cualquier análisis para responder a las siguientes preguntas,
¿Qué tan bien se ajusta el modelo a los datos?, ¿Qué predictores son los más importantes?, ¿Son precisas las predicciones?
Entonces, los siguientes son los criterios para acceder al rendimiento del modelo,
- Criterios de información de Akaike (AIC): En términos simples, AIC estima la cantidad relativa de información perdida por un modelo dado. Por lo tanto, cuanto menos información se pierda, mayor será la calidad del modelo. Por eso, siempre preferimos modelos con mínimo AIC.
- Características de funcionamiento del receptor (curva ROC): La curva ROC ilustra la capacidad de diagnóstico de un clasificador binario. Se calcula/crea trazando el Positivo Verdadero contra el Positivo Falso en varias configuraciones de umbral. La métrica de rendimiento de la curva ROC es AUC (área bajo la curva). Cuanto mayor sea el área bajo la curva, mejor será el poder de predicción del modelo.
- Matriz de confusión: Para averiguar qué tan bien funciona el modelo en la predicción de la variable objetivo, usamos una matriz de confusión/tasa de clasificación. No es más que una representación tabular de los valores reales Vs predichos que nos ayuda a encontrar la precisión del modelo.
153. ¿Cuáles son las ventajas de los algoritmos SVM?
Los algoritmos SVM tienen básicamente ventajas en términos de complejidad. Primero, me gustaría aclarar que tanto la regresión logística como la SVM pueden formar superficies de decisión no lineales y pueden combinarse con el truco del kernel. Si la regresión logística se puede combinar con el kernel, ¿por qué usar SVM?
● Se encuentra que SVM tiene un mejor rendimiento prácticamente en la mayoría de los casos.
● SVM es computacionalmente más barato O(N^2*K) donde K no es ningún vector de soporte (los vectores de soporte son aquellos puntos que se encuentran en el margen de la clase) donde la regresión logística es O(N^3)
● Clasificador en SVM depende sólo de un subconjunto de puntos. Dado que necesitamos maximizar la distancia entre los puntos más cercanos de dos clases (también conocido como margen), debemos preocuparnos solo por un subconjunto de puntos a diferencia de la regresión logística.
154. ¿Por qué XGBoost funciona mejor que SVM?
La primera razón es que XGBoos es un método de conjunto que usa muchos árboles para tomar una decisión, por lo que gana poder al repetirse.
SVM es un separador lineal, cuando los datos no son separables linealmente, SVM necesita un Kernel para proyectar los datos en un espacio donde pueda separarlos, ahí radica su mayor fortaleza y debilidad, al poder proyectar datos en un espacio dimensional alto SVM puede encuentre una separación lineal para casi todos los datos, pero al mismo tiempo necesita usar un kernel y podemos argumentar que no hay un kernel perfecto para cada conjunto de datos.
155. ¿Cuál es la diferencia entre SVM Rank y SVR (Regresión de vector de soporte)?
Uno se usa para clasificar y el otro para regresión.
Hay una diferencia crucial entre regresión y clasificación. En la regresión, el valor absoluto es crucial. Se predice un número real.
En la clasificación, lo único que importa es el orden de un conjunto de ejemplos. Solo queremos saber qué ejemplo tiene el rango más alto, cuál tiene el segundo más alto, y así sucesivamente. A partir de los datos, solo sabemos que el ejemplo 1 debería tener una clasificación más alta que el ejemplo 2, que a su vez debería tener una clasificación más alta que el ejemplo 3, y así sucesivamente. no sabemos por cuánto el ejemplo 1 está clasificado más alto que el ejemplo 2, o si esta diferencia es mayor que la diferencia entre los ejemplos 2 y 3.
156. ¿Cuál es la diferencia entre el SVM de margen suave normal y el SVM con kernel lineal?
Margen duro
Tiene el SVM básico: margen duro. Esto supone que los datos se comportan muy bien y puede encontrar un clasificador perfecto, que tendrá 0 errores en los datos del tren.
margen suave
Los datos generalmente no se comportan bien, por lo que los márgenes duros de SVM pueden no tener una solución en absoluto. Así que permitimos un poco de error en algunos puntos. Entonces, el error de entrenamiento no será 0, pero se minimiza el error promedio sobre todos los puntos.
Núcleos
Lo anterior asume que el mejor clasificador es una línea recta. Pero lo que es no es una línea recta. (por ejemplo, es un círculo, dentro de un círculo hay una clase, afuera hay otra clase). Si podemos mapear los datos en dimensiones más altas, la dimensión más alta puede darnos una línea recta.
157. ¿Cómo es relevante el clasificador lineal para SVM?
Un svm es un tipo de clasificador lineal. Si no te metes con los kernels, podría decirse que es el tipo de clasificador lineal más simple.
Los clasificadores lineales (¿todos?) aprenden ficciones lineales de sus datos que asignan su entrada a puntajes como este: puntajes = Wx + b. Donde W es una matriz de pesos aprendidos, b es un vector de sesgo aprendido que cambia sus puntajes y x son sus datos de entrada. Este tipo de función puede parecerte familiar si recuerdas y = mx + b de la escuela secundaria.
Una función típica de pérdida de svm (la función que le dice qué tan buenos son sus puntajes calculados en relación con las etiquetas correctas) sería la pérdida de bisagra. Toma la forma: Pérdida = suma de todos los puntajes excepto el puntaje correcto de max(0, puntajes – puntajes (clase correcta) + 1).
158. ¿Cuáles son las ventajas de usar un Bayes ingenuo para la clasificación?
- Muy simple, fácil de implementar y rápido.
- Si se cumple el supuesto de independencia condicional de NB, convergerá más rápido que los modelos discriminativos como la regresión logística.
- Incluso si la suposición de NB no se cumple, funciona muy bien en la práctica.
- Necesita menos datos de entrenamiento.
- Altamente escalable. Se escala linealmente con el número de predictores y puntos de datos.
- Se puede utilizar para problemas de clasificación tanto binarios como multiclase.
- Puede hacer predicciones probabilísticas.
- Maneja datos continuos y discretos.
- No es sensible a características irrelevantes.
159. ¿Son los Naive Bayes gaussianos lo mismo que los Naive Bayes binomiales?
Binomial Naive Bayes: asume que todas nuestras características son binarias, de modo que toman solo dos valores. Significa que los 0 pueden representar "la palabra no aparece en el documento" y los 1 como "la palabra aparece en el documento".
Gaussian Naive Bayes: debido a la suposición de la distribución normal, Gaussian Naive Bayes se utiliza en los casos en que todas nuestras funciones son continuas. Por ejemplo, en el conjunto de datos de Iris, las características son el ancho del sépalo, el ancho del pétalo, la longitud del sépalo y la longitud del pétalo. Por lo tanto, sus características pueden tener diferentes valores en el conjunto de datos, ya que el ancho y el largo pueden variar. No podemos representar características en términos de sus ocurrencias. Esto significa que los datos son continuos. Por lo tanto, aquí usamos Gaussian Naive Bayes.
160. ¿Cuál es la diferencia entre el clasificador Naive Bayes y el clasificador Bayes?
Naive Bayes asume independencia condicional, P(X|Y, Z)=P(X|Z)
P(X|Y,Z)=P(X|Z)
P(X|Y,Z)=P(X|Z), mientras que las Redes Bayesianas más generales (a veces llamadas Redes de Creencias Bayesianas), permitirán al usuario especificar qué atributos son, de hecho, condicionalmente independientes.
Para la red bayesiana como clasificador, las características se seleccionan en función de algunas funciones de puntuación, como la función de puntuación bayesiana y la longitud mínima de descripción (las dos son equivalentes en teoría, dado que hay suficientes datos de entrenamiento). Las funciones de puntuación restringen principalmente la estructura (conexiones y direcciones) y los parámetros (probabilidad) utilizando los datos. Una vez que se ha aprendido la estructura, la clase solo está determinada por los nodos en la manta de Markov (sus padres, sus hijos y los padres de sus hijos), y todas las variables dadas por la manta de Markov se descartan.
161. ¿En qué aplicaciones del mundo real se usa el clasificador Naive Bayes?
Algunos de los ejemplos del mundo real son los siguientes
- ¿Marcar un correo electrónico como spam o no spam?
- ¿Clasificar un artículo de noticias sobre tecnología, política o deportes?
- ¿Revisar un fragmento de texto que exprese emociones positivas o emociones negativas?
- También se utiliza para Reconocimiento facial software
162. ¿Naive Bayes es supervisado o no supervisado?
Primero, Naive Bayes no es un algoritmo sino una familia de algoritmos que hereda los siguientes atributos:
- Funciones Discriminantes
- Modelos generativos probabilísticos
- Teorema bayesiano
- Supuestos ingenuos de independencia e igual importancia de los vectores de características.
Además, es un tipo especial de algoritmo de aprendizaje supervisado que podría hacer predicciones simultáneas de varias clases (como se muestra en los temas permanentes en muchas aplicaciones de noticias).
Dado que estos son modelos generativos, en base a las suposiciones del mapeo de variables aleatorias de cada vector de características, estos pueden incluso clasificarse como Gaussian Naive Bayes, Bayes ingenuos multinomiales, Bernoulli Bayes ingenuo, etc.
163. ¿Qué entiendes por sesgo de selección en Machine Learning?
El sesgo de selección se refiere al sesgo introducido por la selección de individuos, grupos o datos para realizar el análisis de manera que no se logra la aleatorización adecuada. Asegura que la muestra obtenida no sea representativa de la población que se pretende analizar y en ocasiones se denomina efecto de selección. Esta es la parte de distorsión de un análisis estadístico que resulta del método de recolección de muestras. Si no tiene en cuenta el sesgo de selección, es posible que algunas conclusiones del estudio no sean precisas.
Los tipos de sesgo de selección incluyen:
- Sesgo de muestreo: Es un error sistemático debido a que una muestra no aleatoria de una población hace que sea menos probable que algunos miembros de la población sean incluidos que otros, lo que da como resultado una muestra sesgada.
- Intervalo de tiempo: Un ensayo puede terminar antes de tiempo en un valor extremo (a menudo por razones éticas), pero es probable que la variable con la varianza más grande alcance el valor extremo, incluso si todas las variables tienen una media similar.
- Datos: cuando se eligen subconjuntos específicos de datos para respaldar una conclusión o el rechazo de datos erróneos por motivos arbitrarios, en lugar de hacerlo de acuerdo con criterios previamente establecidos o generalmente acordados.
- Desgaste: El sesgo de deserción es un tipo de sesgo de selección causado por la deserción (pérdida de participantes) al descartar sujetos/pruebas del ensayo que no se completaron.
164. ¿Qué entiendes por Precisión y Recall?
In reconocimiento de patrones, La recuperación y clasificación de información en el aprendizaje automático son parte de precisión. También se denomina valor predictivo positivo, que es la fracción de instancias relevantes entre las instancias recuperadas.
Recordar también se conoce como sensibilidad y la fracción de la cantidad total de instancias relevantes que realmente se recuperaron.
Tanto la precisión como el recuerdo se basan, por lo tanto, en una comprensión y una medida de la relevancia.
165. ¿Cuáles son las tres etapas de la construcción de un modelo en el aprendizaje automático?
Para construir un modelo en aprendizaje automático, debe seguir algunos pasos:
- Entender el modelo de negocio
- Adquisiciones de datos
- Limpieza de datos
- Análisis exploratorio de datos
- Usar algoritmos de aprendizaje automático para hacer un modelo
- Use un conjunto de datos desconocido para verificar la precisión del modelo
166. ¿Cómo se diseña un filtro de correo no deseado en el aprendizaje automático?
- Comprender el modelo de negocio: tratar de comprender los atributos relacionados con el correo no deseado
- Adquisiciones de datos: recopile el correo no deseado para leer el patrón oculto de ellos
- Limpieza de datos: limpia los datos no estructurados o semiestructurados
- Análisis exploratorio de datos: use conceptos estadísticos para comprender los datos como dispersión, valores atípicos, etc.
- Usar algoritmos de aprendizaje automático para hacer un modelo: puede usar bayes ingenuos o algunos otros algoritmos también
- Use un conjunto de datos desconocido para verificar la precisión del modelo
167. ¿Cuál es la diferencia entre entropía y ganancia de información?
El proyecto ganancia de información se basa en la disminución de entropía después de que un conjunto de datos se divide en un atributo. La construcción de un árbol de decisión se trata de encontrar el atributo que devuelve el valor más alto. ganancia de información (es decir, las ramas más homogéneas). Paso 1: Calcular entropía del objetivo.
168. ¿Qué son la colinealidad y la multicolinealidad?
Colinealidad es una asociación lineal entre dos predictores. Multicolinealidad es una situación en la que dos o más predictores tienen una relación muy lineal.
169. ¿Qué es Kernel SVM?
Los algoritmos SVM tienen básicamente ventajas en términos de complejidad. Primero, me gustaría aclarar que tanto la regresión logística como la SVM pueden formar superficies de decisión no lineales y pueden combinarse con el truco del kernel. Si la regresión logística se puede combinar con el kernel, ¿por qué usar SVM?
● Se encuentra que SVM tiene un mejor rendimiento prácticamente en la mayoría de los casos.
● SVM es computacionalmente más barato O(N^2*K) donde K no es ningún vector de soporte (los vectores de soporte son aquellos puntos que se encuentran en el margen de la clase) donde la regresión logística es O(N^3)
● Clasificador en SVM depende sólo de un subconjunto de puntos. Dado que necesitamos maximizar la distancia entre los puntos más cercanos de dos clases (también conocido como margen), debemos preocuparnos solo por un subconjunto de puntos a diferencia de la regresión logística.
170. ¿Cuál es el proceso de realizar una regresión lineal?
Regresión lineal El análisis consiste en algo más que ajustar un lineal línea a través de una nube de puntos de datos. Consta de 3 etapas-
- analizar la correlación y la direccionalidad de los datos,
- estimando el modelo, es decir, ajustando la línea,
- evaluar la validez y utilidad de los modelo.
"Inicie su viaje de inteligencia artificial con gran aprendizaje que ofrece alta calificación cursos de inteligencia artificial con capacitación de clase mundial por parte de líderes de la industria. Ya sea que esté interesado en el aprendizaje automático, la minería de datos, o análisis de datos, ¡Great Learning tiene un curso para ti!”
Leer también Principales preguntas comunes de la entrevista
Preguntas frecuentes sobre entrevistas de aprendizaje automático
1. ¿Cómo empiezo una carrera en aprendizaje automático?
No existe una guía fija o definitiva a través de la cual pueda comenzar su carrera de aprendizaje automático. El primer paso es comprender los principios básicos del tema y aprender algunos conceptos clave, como algoritmos y estructuras de datos, capacidades de codificación, cálculo, álgebra lineal, estadística. Para un mejor análisis de datos, debe tener una comprensión clara de estadísticas para el aprendizaje automático. El siguiente paso sería retomar un curso de aprendizaje automático o leer los mejores libros para el autoaprendizaje. También puede trabajar en proyectos para obtener una experiencia práctica.
2. ¿Cuál es la mejor manera de aprender aprendizaje automático?
Cualquier forma que se adapte a su estilo de aprendizaje puede considerarse como la mejor manera de aprender. Diferentes personas pueden disfrutar de diferentes métodos. Algunas de las formas comunes serían tomando curso basico de aprendizaje automatico gratis, ver videos de YouTube, leer blogs con temas relevantes, leer libros que pueden ayudarlo a aprender por sí mismo.
3. ¿Qué título necesitas para el aprendizaje automático?
La mayoría de las empresas de contratación buscarán una maestría o un doctorado en el dominio relevante. El campo de estudio incluye informática o matemáticas. Pero tener las habilidades necesarias, incluso sin el título, también puede ayudarlo a conseguir un trabajo de ML.
4. ¿Cómo incursiona en el aprendizaje automático?
La forma más común de ingresar a una carrera de aprendizaje automático es adquirir las habilidades necesarias. Aprende lenguajes de programación como C, C++, Python y Java. Obtenga conocimientos básicos sobre varios algoritmos de ML, conocimientos matemáticos sobre cálculo y estadísticas. Esto te ayudará a recorrer un largo camino.
5. ¿Qué tan difícil es el aprendizaje automático?
Machine Learning es un concepto amplio que contiene muchos aspectos diferentes. Con la orientación adecuada y un trabajo duro constante, puede que no sea muy difícil de aprender. Definitivamente requiere mucho tiempo y esfuerzo, pero si te interesa el tema y estás dispuesto a aprender, no será demasiado difícil.
6. ¿Qué es el aprendizaje automático para principiantes?
El aprendizaje automático para principiantes consistirá en los conceptos básicos, como los tipos de aprendizaje automático (supervisado, no supervisado, aprendizaje por refuerzo). Cada uno de estos tipos de ML tiene diferentes algoritmos y bibliotecas dentro de ellos, como Clasificación y Regresión. Hay varios algoritmos de clasificación y algoritmos de regresión, como la regresión lineal. Esto sería lo primero que aprenderás antes de seguir adelante con otros conceptos.
7. ¿Qué nivel de matemáticas se requiere para el aprendizaje automático?
Necesitarás conocer conceptos de estadística, álgebra lineal, probabilidad, Cálculo Multivariante, Optimización. A medida que profundice en los conceptos de ML, necesitará más conocimientos sobre estos temas.
8. ¿El aprendizaje automático requiere codificación?
La programación es una parte del aprendizaje automático. Es importante conocer lenguajes de programación como Python.
Estén atentos a esta página para obtener más información sobre las preguntas de la entrevista y asistencia profesional. Puede consultar nuestros otros blogs sobre Aprendizaje automático (Machine learning & LLM) para obtener más información.
También puede tomar el Curso de Inteligencia Artificial y Aprendizaje Automático PGP ofrecido por Great Learning en colaboración con UT Austin. El curso ofrece aprendizaje en línea con tutoría y también brinda asistencia profesional. El plan de estudios ha sido diseñado por profesores de Great Lakes y la Universidad de Texas en Austin-McCombs y lo ayuda a impulsar su carrera.
Seguí leyendo
Al igual que las Preguntas de entrevista sobre aprendizaje automático, aquí hay algunas otras Preguntas de entrevista que pueden ayudarlo:
- Preguntas y respuestas de la entrevista de Python
- Preguntas y respuestas de la entrevista de PNL
- Preguntas de la entrevista de inteligencia artificial
- Más de 100 preguntas de entrevistas sobre ciencia de datos
- Preguntas de la entrevista de Hadoop
- Preguntas y respuestas de la entrevista SQL
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.mygreatlearning.com/blog/machine-learning-interview-questions/

