Introducción
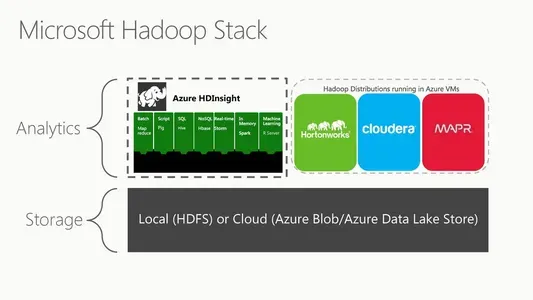
Microsoft Azure HDInsight (o Microsoft HDFS) es una versión del sistema de archivos distribuidos de Hadoop basada en la nube. Un sistema de archivos distribuido se ejecuta en hardware básico y administra recopilaciones masivas de datos. Es un entorno basado en la nube totalmente administrado para analizar y procesar enormes volúmenes de datos. HDInsight funciona a la perfección con el ecosistema de Hadoop, que incluye tecnologías como MapReduce, Hive, Pig y Spark. También es compatible con las potentes tecnologías de procesamiento de datos de Microsoft, como Azure Data Lake Storage y Azure Blob Storage.
La escalabilidad es una de las características más esenciales de HDInsight. Microsoft Azure HDInsight también tiene funciones de seguridad de nivel empresarial, incluido el control de acceso basado en funciones, el cifrado y el aislamiento de la red. HDInsight se integra fácilmente con otros servicios en la nube de Microsoft, incluidos Power BI, Azure Stream Analytics y Azure Data Factory. Finalmente, es un servicio basado en la nube totalmente administrado, lo que significa que Microsoft es responsable de la infraestructura subyacente, el mantenimiento y las actualizaciones.
OBJETIVOS DE APRENDIZAJE
- Revisaremos Microsoft HDFS y cómo funciona en un contexto de datos significativo.
- Comprender cómo utilizar Azure HDInsight en la nube para manejar y analizar enormes volúmenes de datos
- Revisaremos las herramientas de Hadoop, como MapReduce, Hive y Spark, y cómo se pueden utilizar con HDInsight.
- También aprenderá sobre las funciones de diferentes nodos en HDInsight.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
HDInsight de Azure es una solución en la nube completamente administrada que ejecuta importantes tecnologías de procesamiento de datos como Apache Hadoop y Apache Spark. Es una implementación de Hadoop basada en la nube para el procesamiento y análisis masivo de datos en un sistema distribuido. Hadoop es un marco de software disponible gratuitamente para compartir enormes conjuntos de datos entre nodos informáticos. Desempeña un papel crucial en la infraestructura general de Hadoop. Es un sistema de archivos distribuido que almacena datos de aplicaciones en servidores básicos económicos en varias ubicaciones, lo que los hace accesibles a altas velocidades. La arquitectura maestro/esclavo de HDFS garantiza que incluso los conjuntos de datos más masivos puedan almacenarse y administrarse sin pérdida de integridad o rendimiento.
El sistema de archivos distribuido de HDInsight es HDFS. Cuando los usuarios envían tareas a HDInsight, los datos se distribuyen automáticamente entre los nodos del clúster y se guardan en HDFS. HDInsight también incluye otros componentes del ecosistema de Hadoop como MapReduce, Hive, Pig y Spark para procesar y analizar datos en HDFS. HDInsight es una plataforma basada en la nube que permite a los clientes aprovechar las capacidades de Hadoop y sus productos de ecosistema sin necesidad de una gestión de infraestructura subyacente. Utiliza HDFS como su sistema de archivos para facilitar el almacenamiento y procesamiento de datos distribuidos.

Fuente: hkrtrainings.com
Q2. ¿Cómo funciona Microsoft Azure Data Lake Storage Gen2 con HDFS?
Almacenamiento de lago de datos de Microsoft Azure Gen2 es una solución de almacenamiento basada en la nube con un sistema de archivos jerárquico para almacenar y analizar volúmenes masivos de datos. Está destinado a interactuar con grandes plataformas de procesamiento de datos como Hadoop y Spark e interactúa sin problemas con HDFS. Azure Data Lake Storage Gen2 incluye una interfaz de sistema de archivos compatible con Hadoop (HCFS), lo que permite que Hadoop y otras herramientas de procesamiento de big data accedan a datos en Data Lake Storage Gen2 como si estuvieran en HDFS. Los clientes pueden manejar y analizar los datos almacenados en Data Lake Storage Gen2 utilizando sus herramientas y aplicaciones de Hadoop existentes.
Cuando los trabajos de Hadoop se ejecutan en HDInsight, los datos se distribuyen automáticamente entre los nodos del clúster y se almacenan en HDFS. Sin embargo, Azure Data Lake Storage Gen2 puede almacenar datos directamente en la cuenta de almacenamiento sin crear una colección de HDInsight. Luego se puede acceder a estos datos mediante la interfaz HCFS, que proporciona la misma funcionalidad que HDFS. Azure Data Lake Storage Gen2 también ofrece características avanzadas, como la integración de Azure Blob Storage, la integración de Azure Active Directory y características de seguridad de nivel empresarial, como el control de acceso basado en funciones y el cifrado. En general, Data Lake Storage Gen2 proporciona una solución de almacenamiento escalable y segura para el procesamiento y análisis de big data, y se integra a la perfección con Hadoop y HDFS.
Q3. ¿Puede explicar el papel de NameNode y DataNode en HDFS?
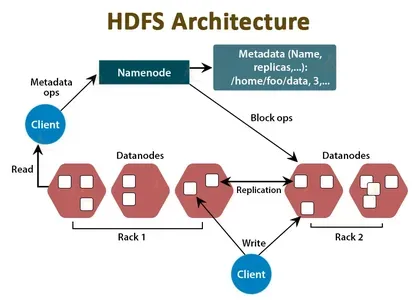
Los componentes NameNode y DataNode de HDFS crean un entorno de procesamiento y almacenamiento distribuido para conjuntos de datos masivos. Así es como funcionan:
- NombreNodo: NameNode sirve como coordinador central y almacén de metadatos del clúster HDFS. Mantiene información sobre ubicaciones de archivos, jerarquía y propiedades de archivos y directorios. El NameNode almacena esta información en memoria y en disco, y se encarga de gestionar el acceso a los datos HDFS. Cuando una aplicación cliente necesita leer o escribir datos de HDFS, primero se comunica con NameNode para recuperar la ubicación de los datos y otra información.
- Nodo de datos: El DataNode es el caballo de batalla de HDFS. Se encarga de almacenar los bloques de datos que componen los archivos en HDFS. Cada DataNode administra el almacenamiento de un subconjunto de datos en el clúster HDFS y duplica los datos en otros DataNodes para redundancia y tolerancia a fallas. Cuando una aplicación cliente necesita leer o escribir datos, habla directamente con los nodos de datos que contienen los bloques de datos.
En resumen, NameNode y DataNode colaboran para producir un sistema de archivos distribuido capaz de almacenar y procesar conjuntos de datos masivos. El NameNode maneja la información del archivo, mientras que los DataNodes contienen los bloques de datos reales. Para proporcionar redundancia de datos, tolerancia a fallas y recuperación rápida de datos, NameNode y DataNodes interactúan entre sí.
Q4. ¿Cómo garantiza HDFS la confiabilidad de los datos y la tolerancia a fallas?
Su objetivo es ofrecer almacenamiento tolerante a fallas para conjuntos de datos masivos. Lo hace duplicando datos en varios nodos de clúster, detectando y recuperándose de fallas y manteniendo la confiabilidad y precisión del almacenamiento de datos. HDFS garantiza la confiabilidad de los datos y la tolerancia a fallas de las siguientes maneras:
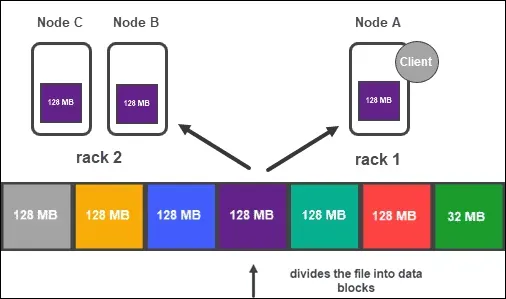
- Almacena datos en bloques duplicados en varios nodos de datos en el clúster. Cada bloque se replica tres veces por defecto, aunque esto se puede cambiar según las necesidades de la aplicación. La replicación de datos en varios nodos garantiza que los datos estén disponibles en otros nodos incluso si uno o más fallan.
- Detección y recuperación de fallas: HDFS verifica continuamente el estado de los nodos de datos del clúster. Cada vez que un DataNode falla o deja de responder, NameNode nota la falla y duplica los datos del nodo fallido en otros nodos del clúster. Luego, NameNode actualiza los metadatos para reflejar las nuevas ubicaciones de los bloques de datos replicados.
- Coherencia de los datos: al utilizar una arquitectura de escritura única, lectura múltiple (WORM), HDFS garantiza que los datos se guarden de manera confiable y precisa. Los datos que se han escrito en HDFS no se pueden cambiar. Esto garantiza que se mantenga la consistencia de los datos incluso cuando numerosos clientes acceden a los mismos datos simultáneamente.
- Ubicación de bloques: para garantizar que los bloques de datos se coloquen en bastidores distintos en el clúster, HDFS emplea una estrategia de ubicación con reconocimiento de bastidores. Esto garantiza que incluso si falla un marco completo, los datos aún están accesibles en los otros bastidores del clúster.
En general, mediante la duplicación de datos en varios nodos, la detección y recuperación de fallas, la garantía de la consistencia de los datos y el empleo de una política de ubicación consciente de los racks para reducir la pérdida de datos debido a fallas en los racks, HDFS proporciona una solución de almacenamiento confiable y tolerante a fallas para conjuntos de datos masivos.
P5. ¿Puede describir cuáles son los roles de NameNode y DataNode en HDFS?
HDFS es un sistema de archivos distribuido que almacena y maneja conjuntos de datos masivos en hardware básico en un clúster. Como se explicó en la pregunta anterior, la arquitectura HDFS consta de dos componentes clave: NameNode y DataNode. Para brindar confiabilidad de datos y tolerancia a fallas, NameNode y DataNodes interactúan. Cuando un cliente necesita leer o escribir datos de HDFS, habla con NameNode para encontrar los bloques de datos. Luego, el cliente discute con los DataNodes directamente para leer o escribir bloques de datos.
MapReduce, un marco de procesamiento de datos distribuido, se combina con frecuencia con HDFS. MapReduce está diseñado para manejar grandes conjuntos de datos dividiéndolos en partes más pequeñas, distribuyendo el procesamiento de esos fragmentos en un grupo de procesadores y agregando los resultados. Así es como MapReduce interactúa con HDFS:
- Los datos de entrada se guardan en HDFS. MapReduce recibe datos de entrada de HDFS y los divide en partes más pequeñas denominadas divisiones de entrada.
- Las divisiones de entrada se distribuyen en el clúster y se asignan a trabajos de Map específicos mediante MapReduce. Cada trabajo de mapa maneja una única división de entrada y produce pares clave-valor intermedios.
- A continuación, los pares clave-valor intermedios se ordenan y mezclan antes de enviarse a los trabajos de reducción. Cada trabajo de Reduce recopila entradas intermedias y genera el resultado final.
- El resultado final se guarda en HDFS.
En general, HDFS y MapReduce colaboran para crear una arquitectura tolerante a fallas y escalable para el procesamiento masivo de conjuntos de datos. Ofrece almacenamiento confiable para datos de entrada y salida, mientras que MapReduce distribuye el procesamiento de datos en todo el clúster.
P6.¿Qué hace que HDFS sea diferente de otros sistemas de archivos y cuáles son los beneficios de usar HDFS en un entorno de datos enorme?
HDFS difiere de los sistemas de archivos estándar en numerosas áreas cruciales, y estas distinciones brindan varios beneficios cuando se trabaja con grandes cantidades de datos. Estas son algunas distinciones y ventajas importantes de utilizar HDFS en un entorno de datos de gran tamaño:
- Escalabilidad: los sistemas de archivos convencionales no están diseñados para administrar las cantidades masivas de datos que son frecuentes en situaciones de big data. Está diseñado para crecer horizontalmente, lo que significa que puede acomodar petabytes o incluso exabytes de almacenamiento y procesamiento de datos al distribuir los datos en un grupo de hardware básico.
- Tolerancia a fallas: está construido para ser tolerante a fallas. Puede soportar la falla de los nodos individuales en el clúster mediante la duplicación de datos en varios nodos del clúster. También tiene técnicas para detectar y recuperarse automáticamente de fallas de nodos.
- Está destinado a tener un alto rendimiento tanto para la lectura como para la escritura de datos. Al trabajar con archivos de gran tamaño, HDFS puede lograr velocidades de lectura y escritura rápidas, ya que está especializado para transferencias masivas de datos.
- Localidad de los datos: está diseñado para maximizar la localidad de los datos, lo que significa que los datos se almacenan y procesan en los mismos nodos del clúster siempre que sea posible. La reducción del tránsito de datos a través de la red minimiza el tráfico de la red y aumenta el rendimiento.
- Rentabilidad: debido a que está diseñado para ejecutarse en hardware básico, puede implementarse en servidores de bajo costo o en la nube. Como resultado, proporciona una opción de bajo costo para almacenar y procesar grandes volúmenes de datos.
En general, los beneficios de emplear HDFS en un contexto de big data son escalabilidad, tolerancia a fallas, alto rendimiento, localización de datos y rentabilidad. Al explotar estas funciones, las organizaciones pueden almacenar, administrar y analizar conjuntos de datos masivos de manera más eficiente y rentable que los sistemas de archivos tradicionales.
Conclusión
En este artículo, examinamos diferentes características de Microsoft HDFS, incluida su introducción, arquitectura, trabajo con Azure Data Lake Storage Gen2 y su función en MapReduce. También revisamos preguntas comunes de entrevistas en configuraciones de Amazon y Microsoft. Es importante para las aplicaciones de big data porque proporciona almacenamiento escalable y tolerante a fallas para conjuntos de datos masivos. Comprender el diseño y el funcionamiento es esencial para los ingenieros y desarrolladores de datos que trabajan con soluciones de big data.
Estos son algunos puntos clave para llevar:
- Es un sistema de archivos distribuido que almacena y maneja grandes conjuntos de datos en hardware básico en un clúster.
- NameNode y DataNode son los dos componentes fundamentales de HDFS. NameNode guarda la información del sistema de archivos, mientras que DataNode almacena los bloques de datos reales que componen los archivos.
- Está diseñado para ser extremadamente tolerante a fallas y proporcionar almacenamiento confiable para aplicaciones de big data. Puede acomodar petabytes o incluso exabytes de almacenamiento y procesamiento de datos al distribuir los datos en un grupo de computadoras básicas.
- MapReduce, un marco de procesamiento de datos distribuido, puede usarse en combinación con HDFS. MapReduce divide grandes conjuntos de datos en bits más pequeños y distribuye su procesamiento en un grupo de procesadores.
- Por último, Microsoft proporciona HDInsight, una distribución de Hadoop basada en la nube que contiene HDFS, MapReduce y otros componentes.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/03/top-6-microsoft-hdfs-interview-questions/

