At AWS re: Invent 2023, anunciamos la disponibilidad general de Bases de conocimiento para Amazon Bedrock. Con Knowledge Bases para Amazon Bedrock, puede conectar de forma segura modelos de base (FM) en lecho rocoso del amazonas a los datos de su empresa utilizando un modelo de generación aumentada de recuperación (RAG) totalmente administrado.
Para aplicaciones basadas en RAG, la precisión de las respuestas generadas por los FM depende del contexto proporcionado al modelo. Los contextos se recuperan de los almacenes de vectores en función de las consultas de los usuarios. En la función publicada recientemente para las bases de conocimientos de Amazon Bedrock, búsqueda híbrida, puedes combinar la búsqueda semántica con la búsqueda de palabras clave. Sin embargo, en muchas situaciones, es posible que necesites recuperar documentos creados en un período definido o etiquetados con determinadas categorías. Para refinar los resultados de la búsqueda, puede filtrar según los metadatos del documento para mejorar la precisión de la recuperación, lo que a su vez conduce a generaciones de FM más relevantes y alineadas con sus intereses.
En esta publicación, analizamos la nueva función de filtrado de metadatos personalizado en Knowledge Bases para Amazon Bedrock, que puede utilizar para mejorar los resultados de búsqueda al filtrar previamente sus recuperaciones de las tiendas de vectores.
Descripción general del filtrado de metadatos
Antes del lanzamiento del filtrado de metadatos, todos los fragmentos semánticamente relevantes hasta el máximo preestablecido se devolverían como contexto para que el FM los usara para generar una respuesta. Ahora, con los filtros de metadatos, puede recuperar no solo fragmentos semánticamente relevantes, sino también un subconjunto bien definido de esos fragmentos relevantes en función de los filtros de metadatos aplicados y los valores asociados.
Con esta función, ahora puede proporcionar un archivo de metadatos personalizado (cada uno de hasta 10 KB) para cada documento de la base de conocimientos. Puede aplicar filtros a sus recuperaciones, indicando al almacén de vectores que realice un filtrado previo en función de los metadatos del documento y luego busque documentos relevantes. De esta manera, tendrá control sobre los documentos recuperados, especialmente si sus consultas son ambiguas. Por ejemplo, puedes utilizar documentos legales con términos similares para diferentes contextos, o películas que tengan una trama similar estrenadas en diferentes años. Además, al reducir la cantidad de fragmentos que se buscan, se obtienen ventajas de rendimiento como una reducción en los ciclos de CPU y el costo de consultar el almacén de vectores, además de una mejora en la precisión.

Para utilizar la función de filtrado de metadatos, debe proporcionar archivos de metadatos junto con los archivos de datos de origen con el mismo nombre que el archivo de datos de origen y .metadata.json sufijo. Los metadatos pueden ser cadenas, números o booleanos. El siguiente es un ejemplo del contenido del archivo de metadatos:
La función de filtrado de metadatos de las bases de conocimiento de Amazon Bedrock está disponible en las regiones de AWS EE. UU. Este (Norte de Virginia) y EE. UU. Oeste (Oregón).
Los siguientes son casos de uso comunes para el filtrado de metadatos:
- Chatbot de documentos para una empresa de software – Esto permite a los usuarios encontrar información del producto y guías de solución de problemas. Los filtros sobre el sistema operativo o la versión de la aplicación, por ejemplo, pueden ayudar a evitar la recuperación de documentos obsoletos o irrelevantes.
- Búsqueda conversacional de la aplicación de una organización. – Esto permite a los usuarios buscar documentos, kanbans, transcripciones de grabaciones de reuniones y otros activos. Al utilizar filtros de metadatos en grupos de trabajo, unidades de negocios o ID de proyectos, puede personalizar la experiencia de chat y mejorar la colaboración. Un ejemplo sería "¿Cuál es el estado del proyecto Sphinx y los riesgos planteados?", donde los usuarios pueden filtrar documentos para un proyecto o tipo de fuente específico (como correo electrónico o documentos de reuniones).
- Búsqueda inteligente de desarrolladores de software – Esto permite a los desarrolladores buscar información de una versión específica. Los filtros según la versión de lanzamiento y el tipo de documento (como código, referencia de API o problema) pueden ayudar a identificar documentos relevantes.
Resumen de la solución
En las siguientes secciones, demostramos cómo preparar un conjunto de datos para usarlo como base de conocimientos y luego realizar consultas con filtrado de metadatos. Puede realizar la consulta mediante el Consola de administración de AWS o SDK.
Prepare un conjunto de datos para las bases de conocimientos de Amazon Bedrock
Para esta publicación, usamos un conjunto de datos de muestra sobre videojuegos ficticios para ilustrar cómo ingerir y recuperar metadatos utilizando las bases de conocimiento de Amazon Bedrock. Si desea seguirlo en su propia cuenta de AWS, descargue el archivo.
Si desea agregar metadatos a sus documentos en una base de conocimientos existente, cree los archivos de metadatos con el nombre de archivo y el esquema esperados, luego vaya al paso para sincronizar sus datos con la base de conocimientos para iniciar la ingesta incremental.
En nuestro conjunto de datos de muestra, el documento de cada juego es un archivo CSV independiente (por ejemplo, s3://$bucket_name/video_game/$game_id.csv) con las siguientes columnas:
title, description, genres, year, publisher, score
Los metadatos de cada juego tienen el sufijo .metadata.json (por ejemplo, s3://$bucket_name/video_game/$game_id.csv.metadata.json) con el siguiente esquema:
Cree una base de conocimientos para Amazon Bedrock
Para obtener instrucciones para crear una nueva base de conocimientos, consulte Crea una base de conocimiento. Para este ejemplo, utilizamos la siguiente configuración:
- En Configurar fuente de datos página, debajo estrategia de fragmentación, seleccione sin fragmentación, porque ya procesó previamente los documentos en el paso anterior.
- En Modelo de incrustaciones sección, elija Incrustaciones de Titan G1 – Texto.
- En Base de datos vectorial sección, elija Crea rápidamente una nueva tienda de vectores. La función de filtrado de metadatos está disponible para todos los almacenes de vectores compatibles.
Sincronizar el conjunto de datos con la base de conocimientos
Después de crear la base de conocimientos y de que sus archivos de datos y archivos de metadatos estén en un Servicio de almacenamiento simple de Amazon (Amazon S3), puede iniciar la ingesta incremental. Para obtener instrucciones, consulte Sincronice para incorporar sus fuentes de datos en la base de conocimientos.
Consulta con filtrado de metadatos en la consola de Amazon Bedrock
Para utilizar las opciones de filtrado de metadatos en la consola de Amazon Bedrock, complete los siguientes pasos:
- En la consola de Amazon Bedrock, elija Bases de conocimiento en el panel de navegación.
- Elija la base de conocimientos que creó.
- Elige Base de conocimientos de prueba.
- Elija el Configuraciones icono, luego expandir Filtros.
- Ingrese una condición usando el formato: clave = valor (por ejemplo, géneros = Estrategia) y presione Participar.
- Para cambiar la clave, el valor o el operador, elija la condición.
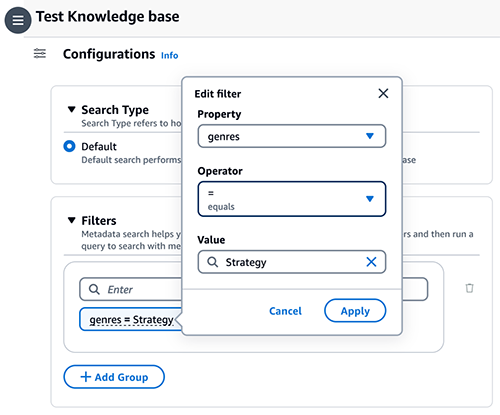
- Continúe con las condiciones restantes (por ejemplo, (géneros = Estrategia Y año >= 2023) O (calificación >= 9))

- Cuando termine, ingrese su consulta en el cuadro de mensaje, luego elija Ejecutar.
Para esta publicación, ingresamos la consulta "Un juego de estrategia con gráficos geniales lanzado después de 2023".
Consulta con filtrado de metadatos usando el SDK
Para utilizar el SDK, primero cree el cliente para el Agentes de Amazon Bedrock tiempo de ejecución:
Luego construya el filtro (los siguientes son algunos ejemplos):
Pasar el filtro a retrievalConfiguration de las API de recuperación or Recuperar y generar API:
La siguiente tabla enumera algunas respuestas con diferentes condiciones de filtrado de metadatos.
| Consulta | Filtrado de metadatos | Documentos recuperados | Observaciones |
| “Un juego de estrategia con gráficos geniales lanzado después de 2023” | DESC |
* Viking Saga: The Sea Raider, año: 2023, géneros: Estrategia * Castillo Medieval: Asedio y Conquista, año:2022, géneros: Estrategia *Revolución Cibernética: El Auge de las Máquinas, año:2022, géneros: Estrategia |
2/5 juegos cumplen la condición (géneros = Estrategia y año >= 2023) |
| On | * Viking Saga: The Sea Raider, año: 2023, géneros: Estrategia * Fantasy Kingdoms: Chronicles of Eldoria, año: 2023, géneros: Estrategia |
2/2 juegos cumplen la condición (géneros = Estrategia y año >= 2023) |
Además de los metadatos personalizados, también puede filtrar utilizando prefijos S3 (que son metadatos integrados, por lo que no es necesario proporcionar ningún archivo de metadatos). Por ejemplo, si organiza los documentos del juego en prefijos por editor (por ejemplo, s3://$bucket_name/video_game/$publisher/$game_id.csv), puede filtrar con el editor específico (por ejemplo, neo_tokyo_games) utilizando la siguiente sintaxis:
Limpiar
Para limpiar sus recursos, complete los siguientes pasos:
- Eliminar la base de conocimientos:
- En la consola de Amazon Bedrock, elija Bases de conocimiento bajo Orquestación en el panel de navegación.
- Elija la base de conocimientos que creó.
- Toma nota del Gestión de identidades y accesos de AWS (IAM) nombre del rol de servicio en el Descripción general de la base de conocimientos .
- En Base de datos vectorial sección, tome nota del ARN de la colección.
- Elige Borrary luego ingrese eliminar para confirmar.
- Eliminar la base de datos de vectores:
- En Servicio Amazon OpenSearch consola, elige Colecciones bajo Sin servidor en el panel de navegación.
- Ingrese el ARN de la colección que guardó en la barra de búsqueda.
- Selecciona la colección y elige Borrar.
- Ingrese confirmar en el mensaje de confirmación, luego elija Borrar.
- Elimine la función del servicio IAM:
- En la consola de IAM, elija Roles en el panel de navegación.
- Busque el nombre del rol que anotó anteriormente.
- Seleccione el rol y elija Borrar.
- Ingrese el nombre del rol en el mensaje de confirmación y elimine el rol.
- Eliminar el conjunto de datos de muestra:
- En la consola de Amazon S3, navegue hasta el depósito de S3 que utilizó.
- Seleccione el prefijo y los archivos, luego elija Borrar.
- Ingrese eliminar permanentemente en el mensaje de confirmación para eliminar.
Conclusión
En esta publicación, cubrimos la función de filtrado de metadatos en las bases de conocimiento de Amazon Bedrock. Aprendió a agregar metadatos personalizados a los documentos y usarlos como filtros mientras recupera y consulta los documentos usando la consola de Amazon Bedrock y el SDK. Esto ayuda a mejorar la precisión del contexto, haciendo que las respuestas a las consultas sean aún más relevantes y, al mismo tiempo, logra una reducción en el costo de consultar la base de datos vectorial.
Para recursos adicionales, consulte lo siguiente:
Acerca de los autores
 Corvus Lee es un arquitecto senior de soluciones de GenAI Labs con sede en Londres. Le apasiona diseñar y desarrollar prototipos que utilizan IA generativa para resolver los problemas de los clientes. También se mantiene al día con los últimos avances en IA generativa y técnicas de recuperación aplicándolas a escenarios del mundo real.
Corvus Lee es un arquitecto senior de soluciones de GenAI Labs con sede en Londres. Le apasiona diseñar y desarrollar prototipos que utilizan IA generativa para resolver los problemas de los clientes. También se mantiene al día con los últimos avances en IA generativa y técnicas de recuperación aplicándolas a escenarios del mundo real.
 Ahmed Ewis es arquitecto de soluciones senior en AWS GenAI Labs y ayuda a los clientes a crear prototipos de IA generativa para resolver problemas comerciales. Cuando no colabora con los clientes, le gusta jugar con sus hijos y cocinar.
Ahmed Ewis es arquitecto de soluciones senior en AWS GenAI Labs y ayuda a los clientes a crear prototipos de IA generativa para resolver problemas comerciales. Cuando no colabora con los clientes, le gusta jugar con sus hijos y cocinar.
 Chris Pecora es científico de datos de IA generativa en Amazon Web Services. Le apasiona crear productos y soluciones innovadores y, al mismo tiempo, centrarse en la ciencia obsesionada con el cliente. Cuando no realiza experimentos y se mantiene al día con los últimos avances en GenAI, le encanta pasar tiempo con sus hijos.
Chris Pecora es científico de datos de IA generativa en Amazon Web Services. Le apasiona crear productos y soluciones innovadores y, al mismo tiempo, centrarse en la ciencia obsesionada con el cliente. Cuando no realiza experimentos y se mantiene al día con los últimos avances en GenAI, le encanta pasar tiempo con sus hijos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

