Los asistentes de inteligencia artificial (IA) conversacionales están diseñados para brindar respuestas precisas y en tiempo real a través del enrutamiento inteligente de consultas a las funciones de IA más adecuadas. Con servicios de IA generativa de AWS como lecho rocoso del amazonas, los desarrolladores pueden crear sistemas que administren y respondan de manera experta a las solicitudes de los usuarios. Amazon Bedrock es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Stability AI y Amazon utilizando una única API, junto con un amplio conjunto de capacidades que necesita para crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable.
Esta publicación evalúa dos enfoques principales para desarrollar asistentes de IA: usar servicios administrados como Agentes de Amazon Bedrocky empleando tecnologías de código abierto como LangChain. Exploramos las ventajas y desafíos de cada uno, para que puedas elegir el camino más adecuado a tus necesidades.
¿Qué es un asistente de IA?
Un asistente de IA es un sistema inteligente que comprende consultas en lenguaje natural e interactúa con diversas herramientas, fuentes de datos y API para realizar tareas o recuperar información en nombre del usuario. Los asistentes de IA eficaces poseen las siguientes capacidades clave:
- Procesamiento del lenguaje natural (PNL) y flujo conversacional
- Integración de la base de conocimientos y búsquedas semánticas para comprender y recuperar información relevante basada en los matices del contexto de la conversación.
- Ejecución de tareas, como consultas de bases de datos y personalizadas. AWS Lambda funciones
- Manejo de conversaciones especializadas y solicitudes de usuarios.
Demostramos los beneficios de los asistentes de IA utilizando la gestión de dispositivos de Internet de las cosas (IoT) como ejemplo. En este caso de uso, la IA puede ayudar a los técnicos a gestionar la maquinaria de manera eficiente con comandos que obtienen datos o automatizan tareas, agilizando las operaciones de fabricación.
Agentes para el enfoque de Amazon Bedrock
Agentes de Amazon Bedrock le permite crear aplicaciones de IA generativa que pueden ejecutar tareas de varios pasos en los sistemas y fuentes de datos de una empresa. Ofrece las siguientes capacidades clave:
- Creación automática de avisos a partir de instrucciones, detalles de API e información de fuentes de datos, lo que ahorra semanas de esfuerzo de ingeniería rápido.
- Recuperación de generación aumentada (RAG) para conectar de forma segura a los agentes con las fuentes de datos de una empresa y proporcionar respuestas relevantes.
- Orquestación y ejecución de tareas de varios pasos dividiendo las solicitudes en secuencias lógicas y llamando a las API necesarias.
- Visibilidad del razonamiento del agente a través de un rastro de cadena de pensamiento (CoT), que permite solucionar problemas y dirigir el comportamiento del modelo.
- Capacidades de ingeniería de mensajes para modificar la plantilla de mensajes generada automáticamente para mejorar el control sobre los agentes.
Puede utilizar Agentes para Amazon Bedrock y Bases de conocimiento para Amazon Bedrock para construir e implementar asistentes de IA para casos de uso de enrutamiento complejos. Proporcionan una ventaja estratégica para desarrolladores y organizaciones al simplificar la gestión de la infraestructura, mejorar la escalabilidad, mejorar la seguridad y reducir el trabajo pesado indiferenciado. También permiten un código de capa de aplicación más simple porque la lógica de enrutamiento, la vectorización y la memoria están completamente administradas.
Resumen de la solución
Esta solución presenta un asistente de IA conversacional diseñado para la administración y operaciones de dispositivos IoT cuando se usa Claude v2.1 de Anthropic en Amazon Bedrock. La funcionalidad principal del asistente de IA se rige por un conjunto completo de instrucciones, conocido como aviso del sistema, que delimita sus capacidades y áreas de especialización. Esta guía garantiza que el asistente de IA pueda manejar una amplia gama de tareas, desde administrar información del dispositivo hasta ejecutar comandos operativos.
Equipado con estas capacidades, como se detalla en el mensaje del sistema, el asistente de IA sigue un flujo de trabajo estructurado para abordar las preguntas de los usuarios. La siguiente figura proporciona una representación visual de este flujo de trabajo, ilustrando cada paso desde la interacción inicial del usuario hasta la respuesta final.
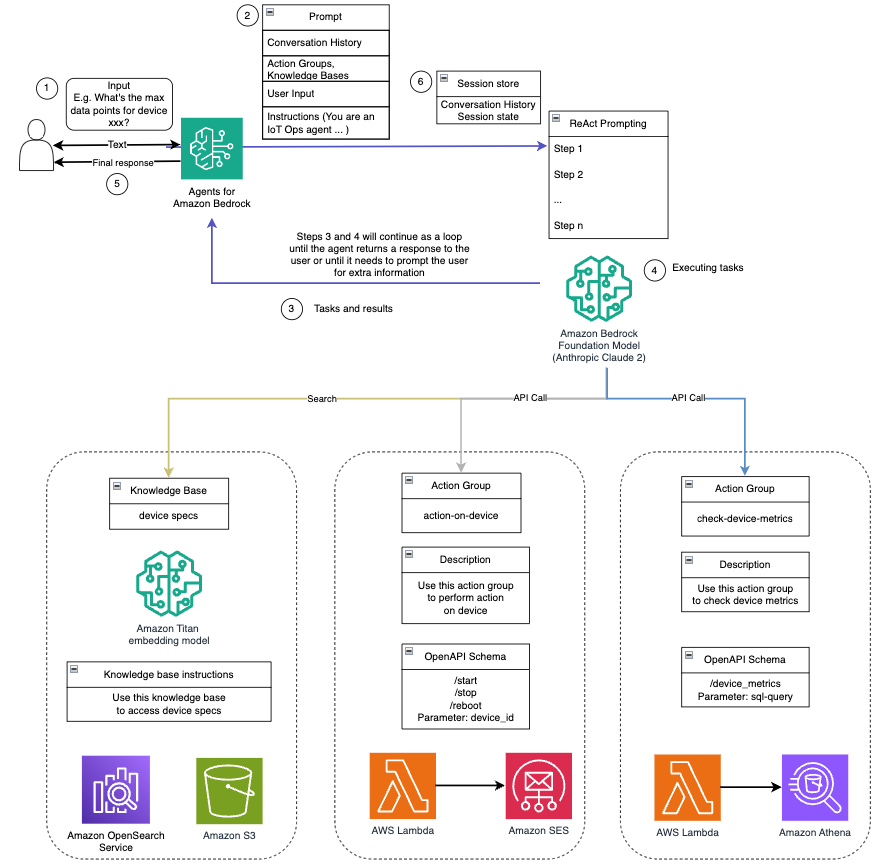
El flujo de trabajo se compone de los siguientes pasos:
- El proceso comienza cuando un usuario solicita al asistente que realice una tarea; por ejemplo, solicitar los puntos de datos máximos para un dispositivo IoT específico
device_xxx. Esta entrada de texto se captura y envía al asistente de IA. - El asistente de IA interpreta la entrada de texto del usuario. Utiliza el historial de conversaciones, los grupos de acciones y las bases de conocimientos proporcionados para comprender el contexto y determinar las tareas necesarias.
- Una vez analizada y comprendida la intención del usuario, el asistente de IA define las tareas. Esto se basa en las instrucciones que interpreta el asistente según las indicaciones del sistema y las entradas del usuario.
- Luego, las tareas se ejecutan a través de una serie de llamadas API. Esto se hace usando Reaccionar indicaciones, que dividen la tarea en una serie de pasos que se procesan secuencialmente:
- Para comprobar las métricas del dispositivo, utilizamos el
check-device-metricsgrupo de acciones, que implica una llamada API a funciones Lambda que luego consultan Atenea amazónica para los datos solicitados. - Para acciones directas del dispositivo como iniciar, detener o reiniciar, utilizamos el
action-on-devicegrupo de acciones, que invoca una función Lambda. Esta función inicia un proceso que envía comandos al dispositivo IoT. Para esta publicación, la función Lambda envía notificaciones usando Servicio de correo electrónico simple de Amazon (Amazon SES). - Usamos las bases de conocimiento de Amazon Bedrock para obtener datos históricos almacenados como incrustaciones en el Servicio Amazon OpenSearch base de datos vectorial.
- Para comprobar las métricas del dispositivo, utilizamos el
- Una vez completadas las tareas, Amazon Bedrock FM genera la respuesta final y la transmite al usuario.
- Los agentes de Amazon Bedrock almacenan información automáticamente mediante una sesión con estado para mantener la misma conversación. El estado se elimina después de que transcurre un tiempo de espera de inactividad configurable.
Resumen técnico
El siguiente diagrama ilustra la arquitectura para implementar un asistente de IA con Agents for Amazon Bedrock.
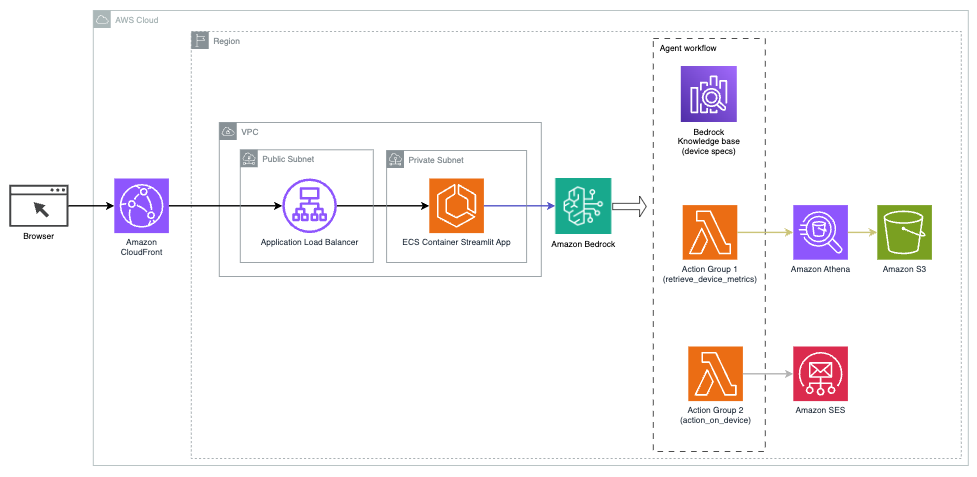
Consta de los siguientes componentes clave:
- Interfaz conversacional – La interfaz conversacional utiliza Streamlit, una biblioteca Python de código abierto que simplifica la creación de aplicaciones web personalizadas y visualmente atractivas para aprendizaje automático (ML) y ciencia de datos. Está alojado en Servicio de contenedor elástico de Amazon (Amazon ECS) con AWS Fargatey se accede a él mediante un balanceador de carga de aplicaciones. Puede utilizar Fargate con Amazon ECS para ejecutar contenedores sin tener que administrar servidores, clusters o máquinas virtuales.
- Agentes de Amazon Bedrock – Los agentes de Amazon Bedrock completan las consultas de los usuarios a través de una serie de pasos de razonamiento y acciones correspondientes basadas en Reaccionar solicitando:
- Bases de conocimiento para Amazon Bedrock – Bases de conocimiento para Amazon Bedrock proporciona información totalmente administrada. RAG para proporcionar al asistente de IA acceso a sus datos. En nuestro caso de uso, cargamos las especificaciones del dispositivo en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo. Sirve como fuente de datos para la base de conocimientos.
- Grupos de acción – Estos son esquemas de API definidos que invocan funciones Lambda específicas para interactuar con dispositivos IoT y otros servicios de AWS.
- Claude antrópico v2.1 en Amazon Bedrock – Este modelo interpreta las consultas de los usuarios y organiza el flujo de tareas.
- Incrustaciones de Amazon Titan – Este modelo sirve como modelo de incrustación de texto, transformando texto en lenguaje natural (desde palabras individuales hasta documentos complejos) en vectores numéricos. Esto habilita capacidades de búsqueda vectorial, lo que permite que el sistema haga coincidir semánticamente las consultas de los usuarios con las entradas más relevantes de la base de conocimientos para una búsqueda efectiva.
La solución está integrada con servicios de AWS como Lambda para ejecutar código en respuesta a llamadas API, Athena para consultar conjuntos de datos, OpenSearch Service para buscar en bases de conocimiento y Amazon S3 para almacenamiento. Estos servicios trabajan juntos para brindar una experiencia perfecta para la gestión de operaciones de dispositivos IoT a través de comandos de lenguaje natural.
Beneficios
Esta solución ofrece los siguientes beneficios:
- Complejidad de implementación:
- Se requieren menos líneas de código porque Agents for Amazon Bedrock abstrae gran parte de la complejidad subyacente, lo que reduce el esfuerzo de desarrollo.
- La administración de bases de datos vectoriales como OpenSearch Service se simplifica porque Knowledge Bases for Amazon Bedrock maneja la vectorización y el almacenamiento.
- La integración con varios servicios de AWS se simplifica a través de grupos de acciones predefinidos
- Experiencia del desarrollador:
- La consola de Amazon Bedrock proporciona una interfaz fácil de usar para un desarrollo, pruebas y análisis de causa raíz (RCA) rápidos, lo que mejora la experiencia general del desarrollador.
- Agilidad y flexibilidad:
- Agents for Amazon Bedrock permite actualizaciones fluidas a FM más nuevos (como Claude 3.0) cuando estén disponibles, para que su solución se mantenga actualizada con los últimos avances.
- AWS administra las cuotas y limitaciones del servicio, lo que reduce la sobrecarga de monitoreo y escalado de la infraestructura.
- Seguridad:
- Amazon Bedrock es un servicio totalmente administrado que cumple con los estrictos estándares de seguridad y cumplimiento de AWS, lo que potencialmente simplifica las revisiones de seguridad organizacional.
Aunque Agents for Amazon Bedrock ofrece una solución optimizada y administrada para crear aplicaciones de IA conversacionales, algunas organizaciones pueden preferir un enfoque de código abierto. En tales casos, puede utilizar marcos como LangChain, que analizamos en la siguiente sección.
Enfoque de enrutamiento dinámico de LangChain
LangChain es un marco de código abierto que simplifica la creación de IA conversacional al permitir la integración de grandes modelos de lenguaje (LLM) y capacidades de enrutamiento dinámico. Con LangChain Expression Language (LCEL), los desarrolladores pueden definir el enrutamiento, que le permite crear cadenas no deterministas donde el resultado de un paso anterior define el siguiente paso. El enrutamiento ayuda a proporcionar estructura y coherencia en las interacciones con los LLM.
Para esta publicación, usamos el mismo ejemplo que el asistente de IA para la administración de dispositivos IoT. Sin embargo, la principal diferencia es que debemos manejar las indicaciones del sistema por separado y tratar cada cadena como una entidad separada. La cadena de enrutamiento decide la cadena de destino en función de la entrada del usuario. La decisión se toma con el apoyo de un LLM pasando el mensaje del sistema, el historial de chat y la pregunta del usuario.
Resumen de la solución
El siguiente diagrama ilustra el flujo de trabajo de la solución de enrutamiento dinámico.
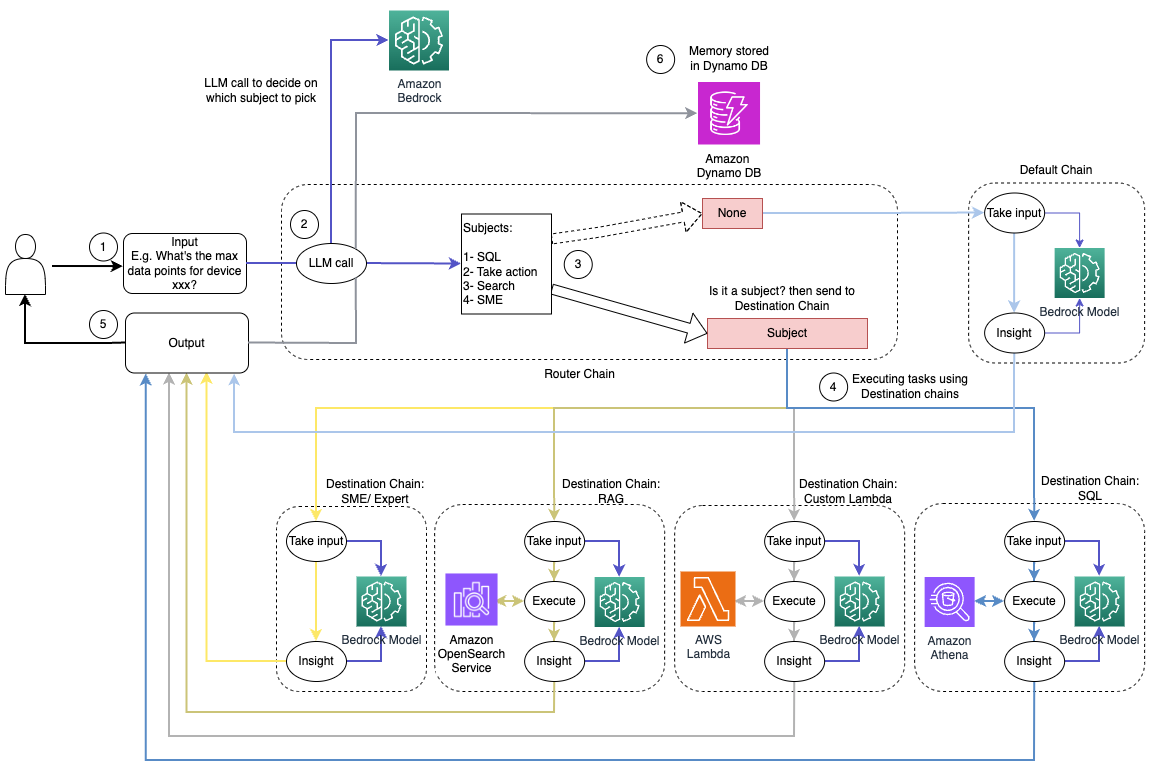
El flujo de trabajo consta de los siguientes pasos:
- El usuario presenta una pregunta al asistente de IA. Por ejemplo, "¿Cuáles son las métricas máximas para el dispositivo 1009?"
- Un LLM evalúa cada pregunta junto con el historial de chat de la misma sesión para determinar su naturaleza y a qué área temática pertenece (como SQL, acción, búsqueda o SME). El LLM clasifica la entrada y la cadena de enrutamiento LCEL toma esa entrada.
- La cadena de enrutador selecciona la cadena de destino según la entrada y el LLM recibe el siguiente mensaje del sistema:
El LLM evalúa la pregunta del usuario junto con el historial de chat para determinar la naturaleza de la consulta y a qué área temática pertenece. Luego, el LLM clasifica la entrada y genera una respuesta JSON en el siguiente formato:
La cadena de enrutador utiliza esta respuesta JSON para invocar la cadena de destino correspondiente. Hay cuatro cadenas de destinos específicas para cada tema, cada una con su propio mensaje del sistema:
- Las consultas relacionadas con SQL se envían a la cadena de destino SQL para interacciones con la base de datos. Puede utilizar LCEL para construir el Cadena SQL.
- Las preguntas orientadas a la acción invocan la cadena de destino Lambda personalizada para ejecutar operaciones. Con LCEL, puedes definir tu propio función personalizada; en nuestro caso, es una función para ejecutar una función Lambda predefinida para enviar un correo electrónico con una ID de dispositivo analizada. Un ejemplo de entrada del usuario podría ser "Apagar el dispositivo 1009".
- Las consultas centradas en la búsqueda pasan al RAG Cadena de destino para la recuperación de información.
- Las preguntas relacionadas con las PYME se dirigen a la cadena de destino de PYME/expertos para obtener información especializada.
- Cada cadena de destino toma la entrada y ejecuta los modelos o funciones necesarios:
- La cadena SQL utiliza Athena para ejecutar consultas.
- La cadena RAG utiliza el servicio OpenSearch para la búsqueda semántica.
- La cadena Lambda personalizada ejecuta funciones Lambda para acciones.
- La cadena de PYME/expertos proporciona información utilizando el modelo Amazon Bedrock.
- El LLM formula las respuestas de cada cadena de destino en conocimientos coherentes. Luego, estos conocimientos se entregan al usuario, completando el ciclo de consulta.
- Las entradas y respuestas del usuario se almacenan en Amazon DynamoDB para proporcionar contexto al LLM para la sesión actual y de interacciones pasadas. La aplicación controla la duración de la información persistente en DynamoDB.
Resumen técnico
El siguiente diagrama ilustra la arquitectura de la solución de enrutamiento dinámico LangChain.
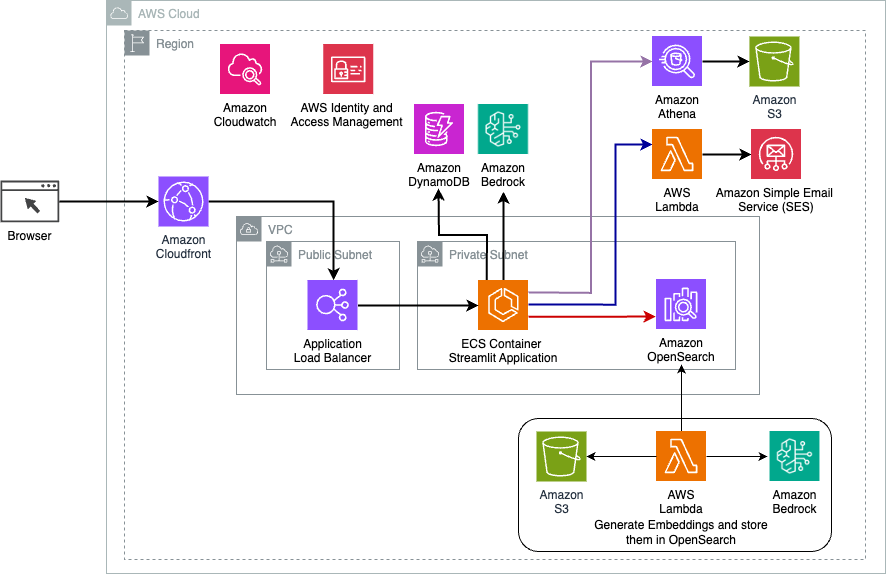
La aplicación web está construida en Streamlit alojado en Amazon ECS con Fargate y se accede a ella mediante un balanceador de carga de aplicaciones. Usamos Claude v2.1 de Anthropic en Amazon Bedrock como nuestro LLM. La aplicación web interactúa con el modelo mediante bibliotecas LangChain. También interactúa con una variedad de otros servicios de AWS, como OpenSearch Service, Athena y DynamoDB para satisfacer las necesidades de los usuarios finales.
Beneficios
Esta solución ofrece los siguientes beneficios:
- Complejidad de implementación:
- Aunque requiere más código y desarrollo personalizado, LangChain proporciona mayor flexibilidad y control sobre la lógica de enrutamiento y la integración con varios componentes.
- La gestión de bases de datos vectoriales como OpenSearch Service requiere esfuerzos adicionales de instalación y configuración. El proceso de vectorización se implementa en código.
- La integración con los servicios de AWS puede implicar más código y configuración personalizados.
- Experiencia del desarrollador:
- El enfoque basado en Python de LangChain y su extensa documentación pueden resultar atractivos para los desarrolladores que ya están familiarizados con Python y las herramientas de código abierto.
- El desarrollo y la depuración rápidos pueden requerir más esfuerzo manual en comparación con el uso de la consola de Amazon Bedrock.
- Agilidad y flexibilidad:
- LangChain admite una amplia gama de LLM, lo que le permite cambiar entre diferentes modelos o proveedores, fomentando la flexibilidad.
- La naturaleza de código abierto de LangChain permite mejoras y personalizaciones impulsadas por la comunidad.
- Seguridad:
- Como marco de código abierto, LangChain puede requerir revisiones y controles de seguridad más rigurosos dentro de las organizaciones, lo que podría agregar gastos generales.
Conclusión
Los asistentes conversacionales de IA son herramientas transformadoras para optimizar las operaciones y mejorar las experiencias de los usuarios. Esta publicación exploró dos enfoques poderosos que utilizan los servicios de AWS: los Agentes administrados para Amazon Bedrock y el enrutamiento dinámico LangChain, flexible y de código abierto. La elección entre estos enfoques depende de los requisitos, las preferencias de desarrollo y el nivel de personalización deseado de su organización. Independientemente del camino tomado, AWS le permite crear asistentes inteligentes de IA que revolucionan las interacciones comerciales y con los clientes.
Encuentre el código de la solución y los recursos de implementación en nuestro Repositorio GitHub, donde puede seguir los pasos detallados para cada enfoque de IA conversacional.
Acerca de los autores
 Ameer Hakme es un arquitecto de soluciones de AWS con sede en Pensilvania. Colabora con proveedores de software independientes (ISV) en la región noreste, ayudándolos a diseñar y construir plataformas modernas y escalables en la nube de AWS. Ameer, experto en IA/ML e IA generativa, ayuda a los clientes a desbloquear el potencial de estas tecnologías de vanguardia. En su tiempo libre le gusta andar en motocicleta y pasar tiempo de calidad con su familia.
Ameer Hakme es un arquitecto de soluciones de AWS con sede en Pensilvania. Colabora con proveedores de software independientes (ISV) en la región noreste, ayudándolos a diseñar y construir plataformas modernas y escalables en la nube de AWS. Ameer, experto en IA/ML e IA generativa, ayuda a los clientes a desbloquear el potencial de estas tecnologías de vanguardia. En su tiempo libre le gusta andar en motocicleta y pasar tiempo de calidad con su familia.
 Sharon Lic es un arquitecto de soluciones de IA/ML en Amazon Web Services con sede en Boston, y le apasiona diseñar y crear aplicaciones de IA generativa en AWS. Colabora con los clientes para aprovechar los servicios de IA/ML de AWS para obtener soluciones innovadoras.
Sharon Lic es un arquitecto de soluciones de IA/ML en Amazon Web Services con sede en Boston, y le apasiona diseñar y crear aplicaciones de IA generativa en AWS. Colabora con los clientes para aprovechar los servicios de IA/ML de AWS para obtener soluciones innovadoras.
 Kawsar Kamal es un arquitecto senior de soluciones en Amazon Web Services con más de 15 años de experiencia en el espacio de seguridad y automatización de infraestructuras. Ayuda a los clientes a diseñar y crear soluciones escalables de DevSecOps y AI/ML en la nube.
Kawsar Kamal es un arquitecto senior de soluciones en Amazon Web Services con más de 15 años de experiencia en el espacio de seguridad y automatización de infraestructuras. Ayuda a los clientes a diseñar y crear soluciones escalables de DevSecOps y AI/ML en la nube.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

