Con la rápida adopción de aplicaciones de IA generativa, es necesario que estas aplicaciones respondan a tiempo para reducir la latencia percibida con un mayor rendimiento. Los modelos básicos (FM) a menudo se entrenan previamente en vastos corpus de datos con parámetros que varían en escalas de millones a miles de millones y más. Los modelos de lenguaje grande (LLM) son un tipo de FM que generan texto como respuesta a la inferencia del usuario. Inferir estos modelos con diferentes configuraciones de parámetros de inferencia puede generar latencias inconsistentes. La inconsistencia podría deberse a la cantidad variable de tokens de respuesta que espera del modelo o al tipo de acelerador en el que se implementa el modelo.
En cualquier caso, en lugar de esperar la respuesta completa, puede adoptar el enfoque de transmisión de respuesta para sus inferencias, que envía fragmentos de información tan pronto como se generan. Esto crea una experiencia interactiva al permitirle ver respuestas parciales transmitidas en tiempo real en lugar de una respuesta completa retrasada.
Con el anuncio oficial de que La inferencia en tiempo real de Amazon SageMaker ahora admite la transmisión de respuestas, ahora puede transmitir continuamente respuestas de inferencia al cliente cuando usa Amazon SageMaker inferencia en tiempo real con transmisión de respuesta. Esta solución le ayudará a crear experiencias interactivas para diversas aplicaciones de IA generativa, como chatbots, asistentes virtuales y generadores de música. Esta publicación le muestra cómo lograr tiempos de respuesta más rápidos en forma de tiempo hasta el primer byte (TTFB) y reducir la latencia percibida general al inferir los modelos Llama 2.
Para implementar la solución, utilizamos SageMaker, un servicio totalmente administrado para preparar datos y crear, entrenar e implementar modelos de aprendizaje automático (ML) para cualquier caso de uso con infraestructura, herramientas y flujos de trabajo totalmente administrados. Para obtener más información sobre las diversas opciones de implementación que ofrece SageMaker, consulte Preguntas frecuentes sobre alojamiento de modelos de Amazon SageMaker. Entendamos cómo podemos abordar los problemas de latencia mediante inferencia en tiempo real con transmisión de respuesta.
Resumen de la solución
Debido a que queremos abordar las latencias antes mencionadas asociadas con la inferencia en tiempo real con LLM, primero comprendamos cómo podemos usar el soporte de transmisión de respuesta para la inferencia en tiempo real para Llama 2. Sin embargo, cualquier LLM puede aprovechar el soporte de transmisión de respuesta con datos reales. -inferencia del tiempo.
Llama 2 es una colección de modelos de texto generativo previamente entrenados y ajustados que varían en escala de 7 mil millones a 70 mil millones de parámetros. Los modelos Llama 2 son modelos autorregresivos con arquitectura solo decodificador. Cuando se les proporciona un mensaje y parámetros de inferencia, los modelos Llama 2 son capaces de generar respuestas de texto. Estos modelos se pueden utilizar para traducción, resúmenes, respuesta a preguntas y chat.
Para esta publicación, implementamos el modelo Llama 2 Chat. meta-llama/Llama-2-13b-chat-hf en SageMaker para inferencias en tiempo real con transmisión de respuestas.
Cuando se trata de implementar modelos en puntos finales de SageMaker, puede contener los modelos utilizando herramientas especializadas. Contenedor de aprendizaje profundo de AWS (DLC) imágenes disponibles para bibliotecas populares de código abierto. Los modelos Llama 2 son modelos de generación de texto; puedes usar el Contenedores de inferencia Hugging Face LLM en SageMaker impulsado por Hugging Face Inferencia de generación de texto (TGI) o DLC de AWS para Inferencia de modelo grande (LMI).
En esta publicación, implementamos el modelo Llama 2 13B Chat usando DLC en SageMaker Hosting para inferencia en tiempo real impulsada por instancias G5. Las instancias G5 son instancias basadas en GPU de alto rendimiento para aplicaciones con uso intensivo de gráficos e inferencia de aprendizaje automático. También puede utilizar los tipos de instancia admitidos p4d, p3, g5 y g4dn con los cambios apropiados según la configuración de la instancia.
Requisitos previos
Para implementar esta solución, debe tener lo siguiente:
- Una cuenta de AWS con un Gestión de identidades y accesos de AWS (IAM) con permisos para administrar los recursos creados como parte de la solución.
- Si es la primera vez que trabaja con Estudio Amazon SageMaker, primero debe crear un Dominio de SageMaker.
- Una cuenta de Hugging Face. Regístrate con su correo electrónico si aún no tiene una cuenta.
- Para acceder sin problemas a los modelos disponibles en Hugging Face, especialmente a los modelos cerrados como Llama, para fines de ajuste e inferencia, debe tener una cuenta de Hugging Face para obtener un token de acceso de lectura. Después de registrarse para obtener su cuenta Hugging Face, iniciar sesión visitar https://huggingface.co/settings/tokens para crear un token de acceso de lectura.
- Accede a Llama 2, utilizando el mismo ID de correo electrónico que utilizaste para registrarte en Hugging Face.
- Los modelos Llama 2 disponibles a través de Hugging Face son modelos cerrados. El uso del modelo Llama se rige por la licencia Meta. Para descargar los pesos del modelo y el tokenizador, solicitar acceso a Llama y aceptar su licencia.
- Una vez que se le haya concedido el acceso (normalmente en un par de días), recibirá una confirmación por correo electrónico. Para este ejemplo utilizamos el modelo
Llama-2-13b-chat-hf, pero también deberías poder acceder a otras variantes.
Enfoque 1: Abrazar la cara TGI
En esta sección, le mostramos cómo implementar el meta-llama/Llama-2-13b-chat-hf modelo a un punto final en tiempo real de SageMaker con transmisión de respuesta usando Hugging Face TGI. La siguiente tabla describe las especificaciones para esta implementación.
| Especificaciones | Valor |
| Envase | Abrazando la cara TGI |
| Nombre de Modelo | meta-llama/Llama-2-13b-chat-hf |
| Instancia de aprendizaje automático | ml.g5.12xgrande |
| Inferencia | En tiempo real con transmisión de respuesta |
Implementar el modelo
Primero, recupera la imagen base para que se implemente el LLM. Luego construye el modelo sobre la imagen base. Finalmente, implementa el modelo en la instancia de ML para SageMaker Hosting para realizar inferencias en tiempo real.
Observemos cómo lograr la implementación mediante programación. Para abreviar, en esta sección solo se analiza el código que ayuda con los pasos de implementación. El código fuente completo para la implementación está disponible en el cuaderno. llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
Recupere el último DLC de Hugging Face LLM impulsado por TGI a través de archivos prediseñados Contenidos descargables de SageMaker. Esta imagen se utiliza para implementar el meta-llama/Llama-2-13b-chat-hf modelo en SageMaker. Vea el siguiente código:
Defina el entorno para el modelo con los parámetros de configuración definidos de la siguiente manera:
Reemplaza <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> para el parámetro de configuración HUGGING_FACE_HUB_TOKEN con el valor del token obtenido de tu perfil de Hugging Face como se detalla en la sección de requisitos previos de esta publicación. En la configuración, usted define la cantidad de GPU utilizadas por réplica de un modelo como 4 para SM_NUM_GPUS. Entonces puedes implementar el meta-llama/Llama-2-13b-chat-hf modelo en una instancia ml.g5.12xlarge que viene con 4 GPU.
Ahora puedes construir la instancia de HuggingFaceModel con la configuración de entorno antes mencionada:
Finalmente, implemente el modelo proporcionando argumentos para el método de implementación disponible en el modelo con varios valores de parámetros, como endpoint_name, initial_instance_county instance_type:
Realizar inferencia
El DLC Hugging Face TGI viene con la capacidad de transmitir respuestas sin personalizaciones ni cambios de código en el modelo. Puedes usar invoke_endpoint_with_response_stream si estás usando Boto3 o Invocar punto final con flujo de respuesta al programar con el SDK de SageMaker Python.
El InvokeEndpointWithResponseStream La API de SageMaker permite a los desarrolladores transmitir respuestas desde los modelos de SageMaker, lo que puede ayudar a mejorar la satisfacción del cliente al reducir la latencia percibida. Esto es especialmente importante para aplicaciones creadas con modelos de IA generativa, donde el procesamiento inmediato es más importante que esperar la respuesta completa.
Para este ejemplo, usamos Boto3 para inferir el modelo y usamos la API de SageMaker. invoke_endpoint_with_response_stream como sigue:
El argumento CustomAttributes se establece en el valor accept_eula=false. El accept_eula el parámetro debe establecerse en true para obtener con éxito la respuesta de los modelos Llama 2. Después de la invocación exitosa usando invoke_endpoint_with_response_stream, el método devolverá un flujo de respuesta de bytes.
El siguiente diagrama ilustra este flujo de trabajo.
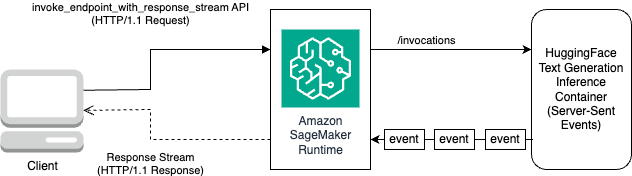
Necesita un iterador que recorra el flujo de bytes y los analice en texto legible. El LineIterator La implementación se puede encontrar en llama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py. Ahora está listo para preparar el mensaje y las instrucciones para usarlos como carga útil mientras infiere el modelo.
Prepare un mensaje e instrucciones.
En este paso, preparará el mensaje y las instrucciones para su LLM. Para solicitar Llama 2, debe tener la siguiente plantilla de solicitud:
Usted construye la plantilla de solicitud definida mediante programación en el método. build_llama2_prompt, que se alinea con la plantilla de aviso antes mencionada. Luego, define las instrucciones según el caso de uso. En este caso, le estamos indicando al modelo que genere un correo electrónico para una campaña de marketing como se describe en el get_instructions método. El código para estos métodos está en el llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb computadora portátil. Construya la instrucción combinada con la tarea a realizar como se detalla en user_ask_1 como sigue:
Pasamos las instrucciones para crear el mensaje según la plantilla de mensaje generada por build_llama2_prompt.
Agrupamos los parámetros de inferencia junto con el mensaje con la clave. stream con el valor True para formar una carga útil final. Enviar la carga útil a get_realtime_response_stream, que se utilizará para invocar un punto final con transmisión de respuesta:
El texto generado por el LLM se transmitirá a la salida como se muestra en la siguiente animación.
Enfoque 2: LMI con servicio DJL
En esta sección, demostramos cómo implementar el meta-llama/Llama-2-13b-chat-hf modelo a un punto final en tiempo real de SageMaker con transmisión de respuesta usando LMI con DJL Serving. La siguiente tabla describe las especificaciones para esta implementación.
| Especificaciones | Valor |
| Envase | Imagen del contenedor LMI con DJL Serving |
| Nombre de Modelo | meta-llama/Llama-2-13b-chat-hf |
| Instancia de aprendizaje automático | ml.g5.12xgrande |
| Inferencia | En tiempo real con transmisión de respuesta |
Primero descarga el modelo y lo almacena en Servicio de almacenamiento simple de Amazon (Amazon S3). Luego, especifica el URI de S3 que indica el prefijo S3 del modelo en el serving.properties archivo. A continuación, recupera la imagen base para que se implemente el LLM. Luego construye el modelo sobre la imagen base. Finalmente, implementa el modelo en la instancia de ML para SageMaker Hosting para realizar inferencias en tiempo real.
Observemos cómo lograr los pasos de implementación antes mencionados mediante programación. Para abreviar, en esta sección solo se detalla el código que ayuda con los pasos de implementación. El código fuente completo para esta implementación está disponible en el cuaderno. llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
Descargue la instantánea del modelo de Hugging Face y cargue los artefactos del modelo en Amazon S3
Con los requisitos previos antes mencionados, descargue el modelo en la instancia del cuaderno de SageMaker y luego cárguelo en el depósito de S3 para su posterior implementación:
Tenga en cuenta que aunque no proporcione un token de acceso válido, el modelo se descargará. Pero cuando se implementa un modelo de este tipo, el modelo que se sirve no tendrá éxito. Por lo tanto, se recomienda reemplazar <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> por el argumento token con el valor del token obtenido de su perfil de Hugging Face como se detalla en los requisitos previos. Para esta publicación, especificamos el nombre del modelo oficial de Llama 2 como se identifica en Hugging Face con el valor meta-llama/Llama-2-13b-chat-hf. El modelo sin comprimir se descargará a local_model_path como resultado de ejecutar el código antes mencionado.
Cargue los archivos en Amazon S3 y obtenga el URI, que luego se utilizará en serving.properties.
Estarás empaquetando el meta-llama/Llama-2-13b-chat-hf modelo en la imagen del contenedor LMI con DJL Serving usando la configuración especificada a través de serving.properties. Luego, implementa el modelo junto con los artefactos del modelo empaquetados en la imagen del contenedor en la instancia de SageMaker ML ml.g5.12xlarge. Luego, utilizará esta instancia de ML para SageMaker Hosting para realizar inferencias en tiempo real.
Preparar artefactos modelo para DJL Serving
Prepare los artefactos de su modelo creando un serving.properties archivo de configuración:
Usamos las siguientes configuraciones en este archivo de configuración:
- motor – Esto especifica el motor de ejecución que utilizará DJL. Los valores posibles incluyen
Python,DeepSpeed,FasterTransformeryMPI. En este caso, lo configuramos enMPI. La paralelización e inferencia de modelos (MPI) facilita la partición del modelo en todas las GPU disponibles y, por lo tanto, acelera la inferencia. - opción.punto de entrada – Esta opción especifica qué controlador ofrecido por DJL Serving le gustaría utilizar. Los valores posibles son
djl_python.huggingface,djl_python.deepspeedydjl_python.stable-diffusion. Usamosdjl_python.huggingfacepara abrazar la cara Acelerar. - opción.tensor_parallel_degree – Esta opción especifica el número de particiones tensoriales paralelas realizadas en el modelo. Puede establecer la cantidad de dispositivos GPU sobre los cuales Accelerate necesita particionar el modelo. Este parámetro también controla la cantidad de trabajadores por modelo que se iniciarán cuando se ejecute el servicio DJL. Por ejemplo, si tenemos una máquina de 4 GPU y estamos creando cuatro particiones, entonces tendremos un trabajador por modelo para atender las solicitudes.
- opción.low_cpu_mem_usage – Esto reduce el uso de memoria de la CPU al cargar modelos. Le recomendamos que establezca esto en
TRUE. - opción.rolling_batch – Esto permite el procesamiento por lotes a nivel de iteración utilizando una de las estrategias admitidas. Los valores incluyen
auto,schedulerylmi-dist. Usamoslmi-distpara activar el procesamiento por lotes continuo para Llama 2. - opción.max_rolling_batch_size – Esto limita el número de solicitudes simultáneas en el lote continuo. El valor predeterminado es 32.
- opción.model_id – Deberías reemplazar
{{model_id}}con el ID de modelo de un modelo previamente entrenado alojado dentro de un repositorio de modelos en Hugging Face o ruta S3 a los artefactos del modelo.
Se pueden encontrar más opciones de configuración en Configuraciones y ajustes.
Debido a que DJL Serving espera que los artefactos del modelo estén empaquetados y formateados en un archivo .tar, ejecute el siguiente fragmento de código para comprimir y cargar el archivo .tar en Amazon S3:
Recupere la última imagen del contenedor LMI con DJL Serving
A continuación, utiliza los DLC disponibles con SageMaker for LMI para implementar el modelo. Recupere el URI de la imagen de SageMaker para el djl-deepspeed contenedor mediante programación usando el siguiente código:
Puede utilizar la imagen antes mencionada para implementar el meta-llama/Llama-2-13b-chat-hf modelo en SageMaker. Ahora puedes proceder a crear el modelo.
Crea el modelo
Puede crear el modelo cuyo contenedor se construye utilizando el inference_image_uri y el código de servicio del modelo ubicado en el URI de S3 indicado por s3_code_artifact:
Ahora puede crear la configuración del modelo con todos los detalles para la configuración del punto final.
Crear la configuración del modelo
Utilice el siguiente código para crear una configuración de modelo para el modelo identificado por model_name:
La configuración del modelo está definida para el ProductionVariants parámetro InstanceType para la instancia de ML ml.g5.12xlarge. También proporcionas el ModelName utilizando el mismo nombre que utilizó para crear el modelo en el paso anterior, estableciendo así una relación entre el modelo y la configuración del punto final.
Ahora que ha definido el modelo y la configuración del modelo, puede crear el punto final de SageMaker.
Crear el punto final de SageMaker
Cree el punto final para implementar el modelo usando el siguiente fragmento de código:
Puede ver el progreso de la implementación utilizando el siguiente fragmento de código:
Una vez que la implementación sea exitosa, el estado del punto final será InService. Ahora que el punto final está listo, realicemos una inferencia con la transmisión de respuesta.
Inferencia en tiempo real con transmisión de respuesta
Como cubrimos en el enfoque anterior para Hugging Face TGI, puedes usar el mismo método get_realtime_response_stream para invocar la transmisión de respuesta desde el punto final de SageMaker. El código para inferir utilizando el enfoque LMI se encuentra en el llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb computadora portátil. El LineIterator La implementación se encuentra en llama-2-lmi/utils/LineIterator.py. Tenga en cuenta que el LineIterator para el modelo Llama 2 Chat implementado en el contenedor LMI es diferente al LineIterator mencionado en la sección TGI de Hugging Face. El LineIterator recorre el flujo de bytes de los modelos Llama 2 Chat inferidos con el contenedor LMI con djl-deepspeed versión 0.25.0. La siguiente función auxiliar analizará el flujo de respuesta recibido de la solicitud de inferencia realizada a través del invoke_endpoint_with_response_stream API:
El método anterior imprime el flujo de datos leído por el LineIterator en un formato legible por humanos.
Exploremos cómo preparar el mensaje y las instrucciones para usarlos como carga útil mientras inferimos el modelo.
Debido a que está infiriendo el mismo modelo tanto en Hugging Face TGI como en LMI, el proceso de preparación del mensaje y las instrucciones es el mismo. Por lo tanto, puedes utilizar los métodos. get_instructions y build_llama2_prompt para inferir.
El get_instructions El método devuelve las instrucciones. Construya las instrucciones combinadas con la tarea a realizar como se detalla en user_ask_2 como sigue:
Pase las instrucciones para crear el mensaje según la plantilla de mensaje generada por build_llama2_prompt:
Combinamos los parámetros de inferencia junto con el mensaje para formar una carga útil final. Luego envías la carga útil a get_realtime_response_stream, que se utiliza para invocar un punto final con transmisión de respuesta:
El texto generado por el LLM se transmitirá a la salida como se muestra en la siguiente animación.

Limpiar
Para evitar incurrir en cargos innecesarios, utilice el Consola de administración de AWS para eliminar los puntos finales y sus recursos asociados que se crearon mientras se ejecutaban los enfoques mencionados en la publicación. Para ambos enfoques de implementación, realice la siguiente rutina de limpieza:
Reemplaza <SageMaker_Real-time_Endpoint_Name> para variable endpoint_name con el punto final real.
Para el segundo enfoque, almacenamos el modelo y los artefactos de código en Amazon S3. Puede limpiar el depósito S3 usando el siguiente código:
Conclusión
En esta publicación, analizamos cómo una cantidad variable de tokens de respuesta o un conjunto diferente de parámetros de inferencia pueden afectar las latencias asociadas con los LLM. Mostramos cómo abordar el problema con la ayuda de la transmisión de respuestas. Luego identificamos dos enfoques para implementar e inferir modelos de Llama 2 Chat utilizando DLC de AWS: LMI y Hugging Face TGI.
Ahora debería comprender la importancia de la respuesta de transmisión y cómo puede reducir la latencia percibida. La transmisión de respuesta puede mejorar la experiencia del usuario, lo que de otro modo le haría esperar hasta que el LLM cree la respuesta completa. Además, implementar modelos de Llama 2 Chat con transmisión de respuesta mejora la experiencia del usuario y hace felices a sus clientes.
Puede consultar las muestras oficiales de AWS. recetas-de-transmisión-de-respuesta-de-amazon-sagemaker-llama2 que cubre el despliegue de otras variantes del modelo Llama 2.
Referencias
Acerca de los autores
 Pavan Kumar Rao Navule es arquitecto de soluciones en Amazon Web Services. Trabaja con ISV en India para ayudarlos a innovar en AWS. Es autor publicado del libro "Getting Started with V Programming". Obtuvo un Executive M.Tech en Ciencia de Datos del Instituto Indio de Tecnología (IIT), Hyderabad. También obtuvo un MBA Ejecutivo en especialización en TI de la Escuela India de Gestión y Administración de Empresas, y tiene una Licenciatura en Tecnología en Ingeniería Electrónica y Comunicaciones del Instituto Vaagdevi de Tecnología y Ciencia. Pavan es un arquitecto profesional de soluciones certificado por AWS y posee otras certificaciones como AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP) y Microsoft Certified Technology Specialist (MCTS). También es un entusiasta del código abierto. En su tiempo libre le encanta escuchar las grandes voces mágicas de Sia y Rihanna.
Pavan Kumar Rao Navule es arquitecto de soluciones en Amazon Web Services. Trabaja con ISV en India para ayudarlos a innovar en AWS. Es autor publicado del libro "Getting Started with V Programming". Obtuvo un Executive M.Tech en Ciencia de Datos del Instituto Indio de Tecnología (IIT), Hyderabad. También obtuvo un MBA Ejecutivo en especialización en TI de la Escuela India de Gestión y Administración de Empresas, y tiene una Licenciatura en Tecnología en Ingeniería Electrónica y Comunicaciones del Instituto Vaagdevi de Tecnología y Ciencia. Pavan es un arquitecto profesional de soluciones certificado por AWS y posee otras certificaciones como AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP) y Microsoft Certified Technology Specialist (MCTS). También es un entusiasta del código abierto. En su tiempo libre le encanta escuchar las grandes voces mágicas de Sia y Rihanna.
 Odio Sudhanshu es el principal especialista en IA/ML de AWS y trabaja con clientes para asesorarlos sobre sus MLOps y su viaje hacia la IA generativa. En su puesto anterior en Amazon, conceptualizó, creó y dirigió equipos para construir plataformas de gamificación e inteligencia artificial basadas en código abierto, y las comercializó con éxito con más de 100 clientes. Sudhanshu tiene en su haber un par de patentes, ha escrito dos libros y varios artículos y blogs, y ha presentado sus puntos de vista en diversos foros técnicos. Ha sido un líder intelectual y orador, y ha estado en la industria durante casi 25 años. Ha trabajado con clientes de Fortune 1000 en todo el mundo y, más recientemente, con clientes nativos digitales en India.
Odio Sudhanshu es el principal especialista en IA/ML de AWS y trabaja con clientes para asesorarlos sobre sus MLOps y su viaje hacia la IA generativa. En su puesto anterior en Amazon, conceptualizó, creó y dirigió equipos para construir plataformas de gamificación e inteligencia artificial basadas en código abierto, y las comercializó con éxito con más de 100 clientes. Sudhanshu tiene en su haber un par de patentes, ha escrito dos libros y varios artículos y blogs, y ha presentado sus puntos de vista en diversos foros técnicos. Ha sido un líder intelectual y orador, y ha estado en la industria durante casi 25 años. Ha trabajado con clientes de Fortune 1000 en todo el mundo y, más recientemente, con clientes nativos digitales en India.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/inference-llama-2-models-with-real-time-response-streaming-using-amazon-sagemaker/

