Flujos de trabajo administrados por Amazon para Apache Airflow (Amazon MWAA) es un servicio de orquestación administrado para Flujo de aire Apache que puede utilizar para configurar y operar canalizaciones de datos en la nube a escala. Apache Airflow es una herramienta de código abierto que se utiliza para crear, programar y monitorear mediante programación secuencias de procesos y tareas, denominadas flujos de trabajo. Con Amazon MWAA, puede utilizar Apache Airflow y Python para crear flujos de trabajo sin tener que administrar la infraestructura subyacente para lograr escalabilidad, disponibilidad y seguridad.
Al utilizar varias cuentas de AWS, las organizaciones pueden escalar eficazmente sus cargas de trabajo y administrar su complejidad a medida que crecen. Este enfoque proporciona un mecanismo sólido para mitigar el impacto potencial de interrupciones o fallas, asegurando que las cargas de trabajo críticas sigan operativas. Además, permite la optimización de costos al alinear los recursos con casos de uso específicos, asegurando que los gastos estén bien controlados. Al aislar las cargas de trabajo con requisitos de seguridad o necesidades de cumplimiento específicos, las organizaciones pueden mantener los niveles más altos de privacidad y seguridad de los datos. Además, la capacidad de organizar varias cuentas de AWS de manera estructurada le permite alinear sus procesos y recursos comerciales de acuerdo con sus requisitos operativos, regulatorios y presupuestarios únicos. Este enfoque promueve la eficiencia, la flexibilidad y la escalabilidad, lo que permite a las grandes empresas satisfacer sus necesidades cambiantes y alcanzar sus objetivos.
Esta publicación demuestra cómo orquestar una canalización de extracción, transformación y carga (ETL) de un extremo a otro utilizando Servicio de almacenamiento simple de Amazon (Amazon S3), Pegamento AWSy Amazon Redshift sin servidor con Amazon MWAA.
Resumen de la solución
Para esta publicación, consideramos un caso de uso en el que un equipo de ingeniería de datos desea crear un proceso ETL y brindar la mejor experiencia a sus usuarios finales cuando desean consultar los datos más recientes después de agregar nuevos archivos sin formato a Amazon S3 en la plataforma central. cuenta (Cuenta A en el siguiente diagrama de arquitectura). El equipo de ingeniería de datos quiere separar los datos sin procesar en su propia cuenta de AWS (Cuenta B en el diagrama) para mayor seguridad y control. También quieren realizar el trabajo de procesamiento y transformación de datos en su propia cuenta (Cuenta B) para compartimentar las tareas y evitar cambios no deseados en los datos sin procesar de origen presentes en la cuenta central (Cuenta A). Este enfoque permite al equipo procesar los datos sin procesar extraídos de la Cuenta A a la Cuenta B, que está dedicada a tareas de manejo de datos. Esto garantiza que los datos sin procesar y procesados se puedan mantener separados de forma segura en varias cuentas, si es necesario, para mejorar la gobernanza y la seguridad de los datos.
Nuestra solución utiliza una canalización ETL de un extremo a otro orquestada por Amazon MWAA que busca nuevos archivos incrementales en una ubicación de Amazon S3 en la Cuenta A, donde están presentes los datos sin procesar. Esto se hace invocando trabajos ETL de AWS Glue y escribiendo en objetos de datos en un clúster sin servidor de Redshift en la cuenta B. Luego, la canalización comienza a ejecutarse. procedimientos almacenados y comandos SQL en Redshift Serverless. Cuando las consultas terminan de ejecutarse, aparece un DESCARGAR La operación se invoca desde el almacén de datos de Redshift al depósito S3 en la cuenta A.
Debido a que la seguridad es importante, esta publicación también cubre cómo configurar una conexión Airflow usando Director de secretos de AWS para evitar almacenar las credenciales de la base de datos dentro de las conexiones y variables de Airflow.
El siguiente diagrama ilustra la descripción general de la arquitectura de los componentes involucrados en la orquestación del flujo de trabajo.
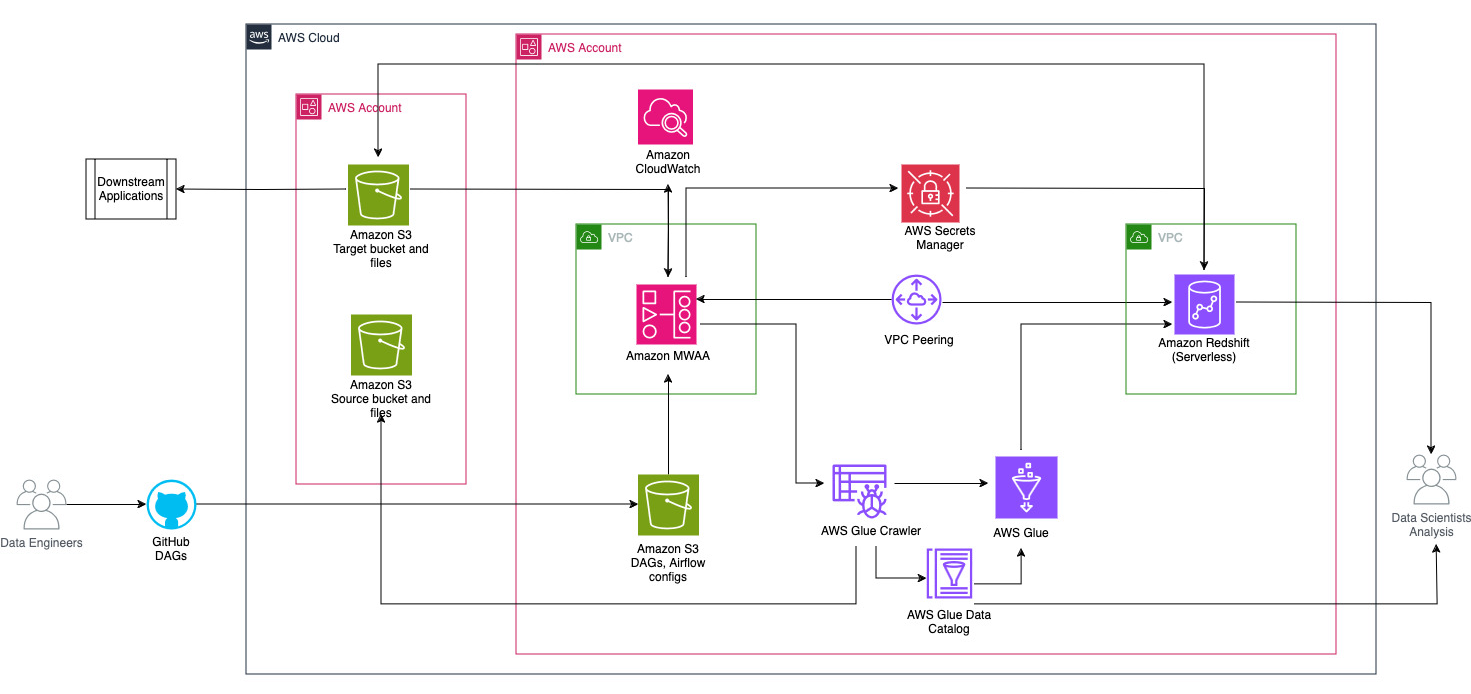
El flujo de trabajo consta de los siguientes componentes:
- Los depósitos S3 de origen y de destino están en una cuenta central (Cuenta A), mientras que Amazon MWAA, AWS Glue y Amazon Redshift están en una cuenta diferente (Cuenta B). Se ha configurado el acceso entre cuentas entre depósitos de S3 en la cuenta A con recursos en la cuenta B para poder cargar y descargar datos.
- En la segunda cuenta, Amazon MWAA está alojado en una VPC y Redshift Serverless en una VPC diferente, que están conectados mediante emparejamiento de VPC. Un grupo de trabajo Redshift Serverless está protegido dentro de subredes privadas en tres zonas de disponibilidad.
- Los secretos como el nombre de usuario, la contraseña, el puerto de base de datos y la región de AWS para Redshift Serverless se almacenan en Secrets Manager.
- Los puntos de enlace de VPC se crean para que Amazon S3 y Secrets Manager interactúen con otros recursos.
- Por lo general, los ingenieros de datos crean un gráfico acíclico dirigido por flujo de aire (DAG) y envían sus cambios a GitHub. Con las acciones de GitHub, se implementan en un depósito de S3 en la cuenta B (para esta publicación, cargamos los archivos directamente en el depósito de S3). El depósito S3 almacena archivos relacionados con Airflow, como archivos DAG,
requirements.txtarchivos y complementos. Los activos y scripts ETL de AWS Glue se almacenan en otro depósito de S3. Esta separación ayuda a mantener la organización y evitar confusiones. - Airflow DAG utiliza varios operadores, sensores, conexiones, tareas y reglas para ejecutar la canalización de datos según sea necesario.
- Los registros de Airflow están registrados Reloj en la nube de Amazony se pueden configurar alertas para tareas de monitoreo. Para más información, ver Monitoreo de paneles y alarmas en Amazon MWAA.
Requisitos previos
Debido a que esta solución se centra en el uso de Amazon MWAA para organizar la canalización de ETL, es necesario configurar ciertos recursos fundamentales en todas las cuentas de antemano. Específicamente, debe crear los depósitos y las carpetas de S3, los recursos de AWS Glue y los recursos de Redshift Serverless en sus respectivas cuentas antes de implementar la integración completa del flujo de trabajo mediante Amazon MWAA.
Implemente recursos en la cuenta A mediante AWS CloudFormation
En la cuenta A, inicie el proporcionado Formación en la nube de AWS pila para crear los siguientes recursos:
- Las carpetas y depósitos de S3 de origen y de destino. Como práctica recomendada, las estructuras de los depósitos de entrada y salida están formateadas con particiones estilo colmena como
s3://<bucket>/products/YYYY/MM/DD/. - Un conjunto de datos de muestra llamado
products.csv, que utilizamos en esta publicación.
![]()
Cargue el trabajo de AWS Glue en Amazon S3 en la cuenta B
En la cuenta B, cree una ubicación de Amazon S3 llamada aws-glue-assets-<account-id>-<region>/scripts (si no está presente). Reemplace los parámetros para el ID de cuenta y la región en el muestra_pegamento_trabajo.py script y cargue el archivo de trabajo de AWS Glue en la ubicación de Amazon S3.
Implemente recursos en la cuenta B mediante AWS CloudFormation
En la Cuenta B, inicie la plantilla de pila de CloudFormation proporcionada para crear los siguientes recursos:
- El cubo S3
airflow-<username>-bucketpara almacenar archivos relacionados con Airflow con la siguiente estructura:- días – La carpeta para archivos DAG.
- plugins – El archivo para cualquier complemento de Airflow personalizado o comunitario.
- requisitos - El
requirements.txtarchivo para cualquier paquete de Python. - guiones – Cualquier script SQL utilizado en el DAG.
- datos – Cualquier conjunto de datos utilizado en el DAG.
- Un entorno Redshift Serverless. El nombre del grupo de trabajo y el espacio de nombres tienen el prefijo
sample. - Un entorno de AWS Glue, que contiene lo siguiente:
- Un pegamento AWS rastreador, que rastrea los datos del depósito de origen de S3
sample-inp-bucket-etl-<username>en la cuenta A. - Una base de datos llamada
products_dben el catálogo de datos de AWS Glue. - Un ELT trabajo , que son
sample_glue_job. Este trabajo puede leer archivos delproductstabla en el catálogo de datos y cargar datos en la tabla Redshiftproducts.
- Un pegamento AWS rastreador, que rastrea los datos del depósito de origen de S3
- Un punto de enlace de puerta de enlace de VPC para Amazon S3.
- Un entorno de Amazon MWAA. Para conocer los pasos detallados para crear un entorno de Amazon MWAA mediante la consola de Amazon MWAA, consulte Presentamos los flujos de trabajo administrados de Amazon para Apache Airflow (MWAA).
![]()
Crear recursos de Amazon Redshift
Cree dos tablas y un procedimiento almacenado en un grupo de trabajo Redshift Serverless utilizando el productos.sql archivo.
En este ejemplo, creamos dos tablas llamadas products y products_f. El nombre del procedimiento almacenado es sp_products.
Configurar permisos de flujo de aire
Una vez creado correctamente el entorno de Amazon MWAA, el estado se mostrará como Disponible. Escoger Abrir la interfaz de usuario de flujo de aire para ver la interfaz de usuario de Airflow. Los DAG se sincronizan automáticamente desde el depósito de S3 y son visibles en la interfaz de usuario. Sin embargo, en esta etapa, no hay DAG en la carpeta S3.
Agregar la política administrada por el cliente AmazonMWAAFullConsoleAccess, que otorga a los usuarios de Airflow permisos para acceder Gestión de identidades y accesos de AWS (IAM) y adjunte esta política al rol de Amazon MWAA. Para más información, ver Acceso a un entorno de Amazon MWAA.
Las políticas adjuntas al rol de Amazon MWAA tienen acceso completo y solo deben usarse con fines de prueba en un entorno de prueba seguro. Para implementaciones de producción, siga el principio de privilegios mínimos.
Configurar el entorno
Esta sección describe los pasos para configurar el entorno. El proceso implica los siguientes pasos de alto nivel:
- Actualice los proveedores necesarios.
- Configure el acceso entre cuentas.
- Establezca una conexión de intercambio de tráfico de VPC entre la VPC de Amazon MWAA y la VPC de Amazon Redshift.
- Configure Secrets Manager para integrarlo con Amazon MWAA.
- Definir conexiones de flujo de aire.
Actualizar los proveedores
Siga los pasos de esta sección si su versión de Amazon MWAA es inferior a 2.8.1 (la última versión al momento de escribir esta publicación).
Los proveedores son paquetes mantenidos por la comunidad e incluyen todos los operadores, ganchos y sensores principales para un servicio determinado. El proveedor de Amazon se utiliza para interactuar con servicios de AWS como Amazon S3, Amazon Redshift Serverless, AWS Glue y más. Hay más de 200 módulos dentro del proveedor de Amazon.
Aunque la versión de Airflow admitida en Amazon MWAA es 2.6.3, que viene incluida con la versión 8.2.0 del paquete proporcionado por Amazon, la compatibilidad con Amazon Redshift Serverless no se agregó hasta la versión 8.4.0 del paquete proporcionado por Amazon. Debido a que la versión predeterminada del proveedor incluido es anterior a cuando se introdujo la compatibilidad con Redshift Serverless, la versión del proveedor debe actualizarse para poder utilizar esa funcionalidad.
El primer paso es actualizar el archivo de restricciones y requirements.txt archivo con las versiones correctas. Referirse a Especificación de paquetes de proveedores más nuevos para conocer los pasos para actualizar el paquete del proveedor de Amazon.
- Especifique los requisitos de la siguiente manera:
- Actualice la versión en el archivo de restricciones a 8.4.0 o superior.
- Agregue la restricciones-3.11-actualizado.txt presentar a la
/dagscarpeta.
Consulte Versiones de Apache Airflow en Amazon Managed Workflows para Apache Airflow para obtener versiones correctas del archivo de restricciones según la versión de Airflow.
- Navegue hasta el entorno de Amazon MWAA y elija Editar.
- under Código DAG en Amazon S3, Para Archivo de requisitos, elija la última versión.
- Elige Guardar.
Esto actualizará el entorno y entrarán en vigor nuevos proveedores.
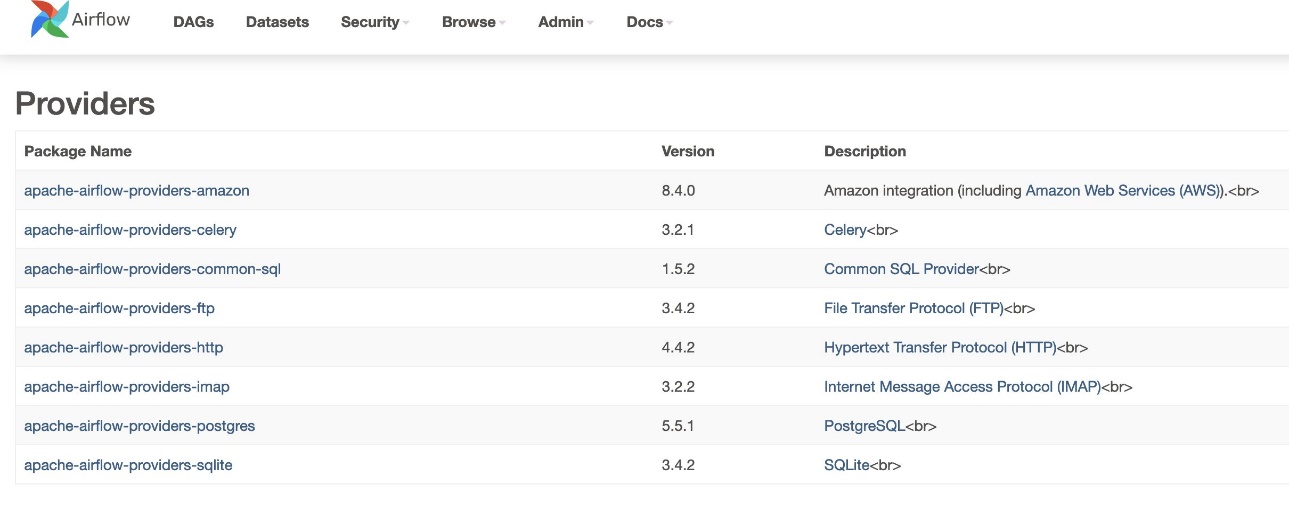
- Para verificar la versión del proveedor, vaya a Los proveedores bajo el Administración mesa.
La versión del paquete del proveedor de Amazon debe ser 8.4.0, como se muestra en la siguiente captura de pantalla. Si no, hubo un error al cargar requirements.txt. Para depurar cualquier error, vaya a la consola de CloudWatch y abra el requirements_install_ip iniciar sesión Secuencias de registro, donde se enumeran los errores. Referirse a Habilitación de registros en la consola de Amazon MWAA para más información.
Configurar el acceso entre cuentas
Debe configurar políticas y roles entre cuentas entre la cuenta A y la cuenta B para acceder a los depósitos de S3 para cargar y descargar datos. Complete los siguientes pasos:
- En la cuenta A, configure la política del depósito para el depósito.
sample-inp-bucket-etl-<username>para otorgar permisos a los roles de AWS Glue y Amazon MWAA en la cuenta B para objetos en el depósitosample-inp-bucket-etl-<username>: - De manera similar, configure la política del depósito para el depósito.
sample-opt-bucket-etl-<username>para otorgar permisos a los roles de Amazon MWAA en la cuenta B para colocar objetos en este depósito: - En la cuenta A, cree una política de IAM llamada
policy_for_roleA, que permite las acciones necesarias de Amazon S3 en el depósito de salida: - Cree un nuevo rol de IAM llamado
RoleAcon la Cuenta B como rol de entidad de confianza y agregue esta política al rol. Esto permite que la cuenta B asuma el rol A para realizar las acciones necesarias de Amazon S3 en el depósito de salida. - En la cuenta B, cree una política de IAM llamada
s3-cross-account-accesscon permiso para acceder a objetos en el depósitosample-inp-bucket-etl-<username>, que está en la cuenta A. - Agregue esta política al rol de AWS Glue y al rol de Amazon MWAA:
- En la cuenta B, cree la política de IAM
policy_for_roleBespecificando la Cuenta A como entidad confiable. La siguiente es la política de confianza a asumirRoleAen la cuenta A: - Cree un nuevo rol de IAM llamado
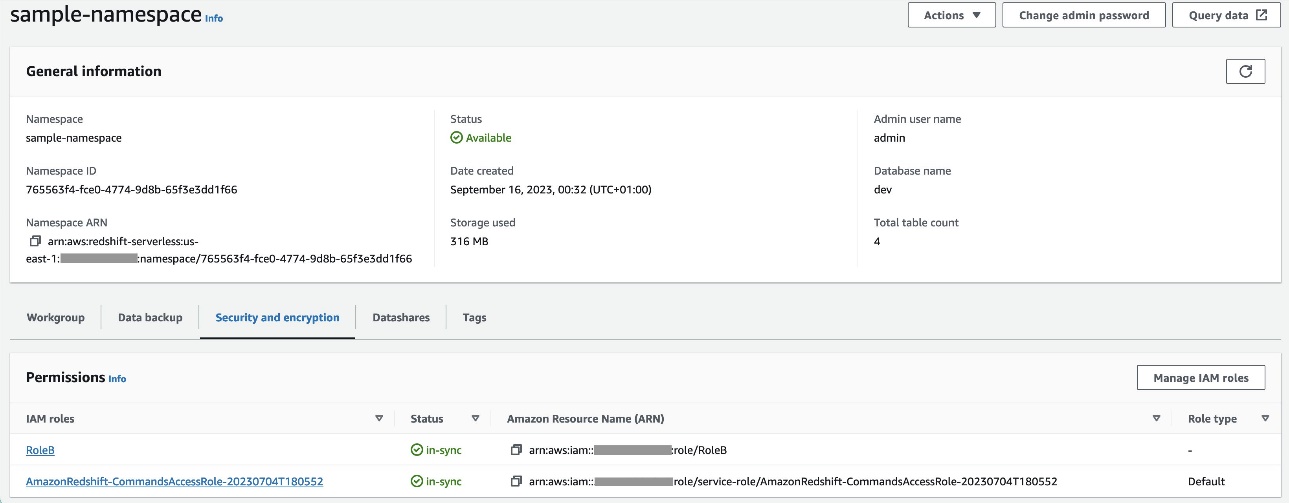
RoleBcon Amazon Redshift como tipo de entidad de confianza y agregue esta política al rol. Esto permiteRoleBasumirRoleAen la Cuenta A y también para que Amazon Redshift pueda asumirlo. - Adjuntar
RoleBal espacio de nombres Redshift Serverless, de modo que Amazon Redshift pueda escribir objetos en el depósito de salida de S3 en la cuenta A. - Adjunte la política
policy_for_roleBal rol de Amazon MWAA, que permite a Amazon MWAA acceder al depósito de salida en la cuenta A.
Consulte ¿Cómo puedo proporcionar acceso entre cuentas a los objetos que se encuentran en los depósitos de Amazon S3? para obtener más detalles sobre cómo configurar el acceso entre cuentas a objetos en Amazon S3 desde AWS Glue y Amazon MWAA. Referirse a ¿Cómo COPIO o DESCARGO datos de Amazon Redshift a un depósito de Amazon S3 en otra cuenta? para obtener más detalles sobre la configuración de roles para descargar datos de Amazon Redshift a Amazon S3 desde Amazon MWAA.
Configure el emparejamiento de VPC entre las VPC de Amazon MWAA y Amazon Redshift
Dado que Amazon MWAA y Amazon Redshift están en dos VPC independientes, debe configurar el emparejamiento de VPC entre ellos. Debe agregar una ruta a las tablas de rutas asociadas a las subredes para ambos servicios. Referirse a Trabajar con conexiones de peering de VPC para obtener detalles sobre el emparejamiento de VPC.

Asegúrese de que el rango CIDR de la VPC de Amazon MWAA esté permitido en el grupo de seguridad de Redshift y que el rango CIDR de la VPC de Amazon Redshift esté permitido en el grupo de seguridad de Amazon MWAA, como se muestra en la siguiente captura de pantalla.

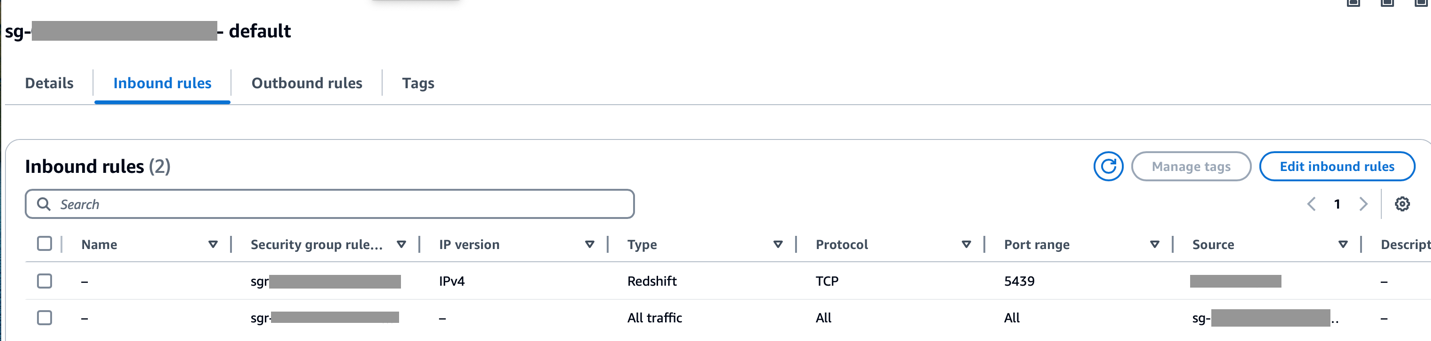
Si alguno de los pasos anteriores está configurado incorrectamente, es probable que encuentre un error de "Tiempo de espera de conexión" en la ejecución de DAG.
Configure la conexión de Amazon MWAA con Secrets Manager
Cuando la canalización de Amazon MWAA está configurada para utilizar Secrets Manager, primero buscará conexiones y variables en un backend alternativo (como Secrets Manager). Si el backend alternativo contiene el valor necesario, se devuelve. De lo contrario, comprobará el valor en la base de datos de metadatos y lo devolverá en su lugar. Para obtener más detalles, consulte Configuración de una conexión Apache Airflow mediante un secreto de AWS Secrets Manager.
Complete los siguientes pasos:
- Configura un Punto de enlace de VPC para vincular Amazon MWAA y Secrets Manager (
com.amazonaws.us-east-1.secretsmanager).
Esto permite a Amazon MWAA acceder a las credenciales almacenadas en Secrets Manager.

- Para proporcionar a Amazon MWAA permiso para acceder a las claves secretas de Secrets Manager, agregue la política denominada
SecretsManagerReadWriteal papel IAM del medio ambiente. - Para crear el backend de Secrets Manager como una opción de configuración de Apache Airflow, vaya a las opciones de configuración de Airflow, agregue los siguientes pares clave-valor y guarde su configuración.
Esto configura Airflow para buscar cadenas de conexión y variables en el airflow/connections/* y airflow/variables/* caminos:

- Para generar una cadena URI de conexión de Airflow, vaya a AWS CloudShell e ingrese a un shell de Python.
- Ejecute el siguiente código para generar la cadena URI de conexión:
La cadena de conexión debe generarse de la siguiente manera:
- Agregue la conexión en Secrets Manager usando el siguiente comando en el Interfaz de línea de comandos de AWS (CLI de AWS).
Esto también se puede hacer desde la consola de Secrets Manager. Esto se agregará en Secrets Manager como texto sin formato.
Usa la conexión airflow/connections/secrets_redshift_connection en el DAG. Cuando se ejecuta DAG, buscará esta conexión y recuperará los secretos de Secrets Manager. En caso de RedshiftDataOperator, pasa el secret_arn como parámetro en lugar del nombre de la conexión.
También puede agregar secretos utilizando la consola de Secrets Manager como pares clave-valor.
- Agregue otro secreto en Secrets Manager y guárdelo como
airflow/connections/redshift_conn_test.
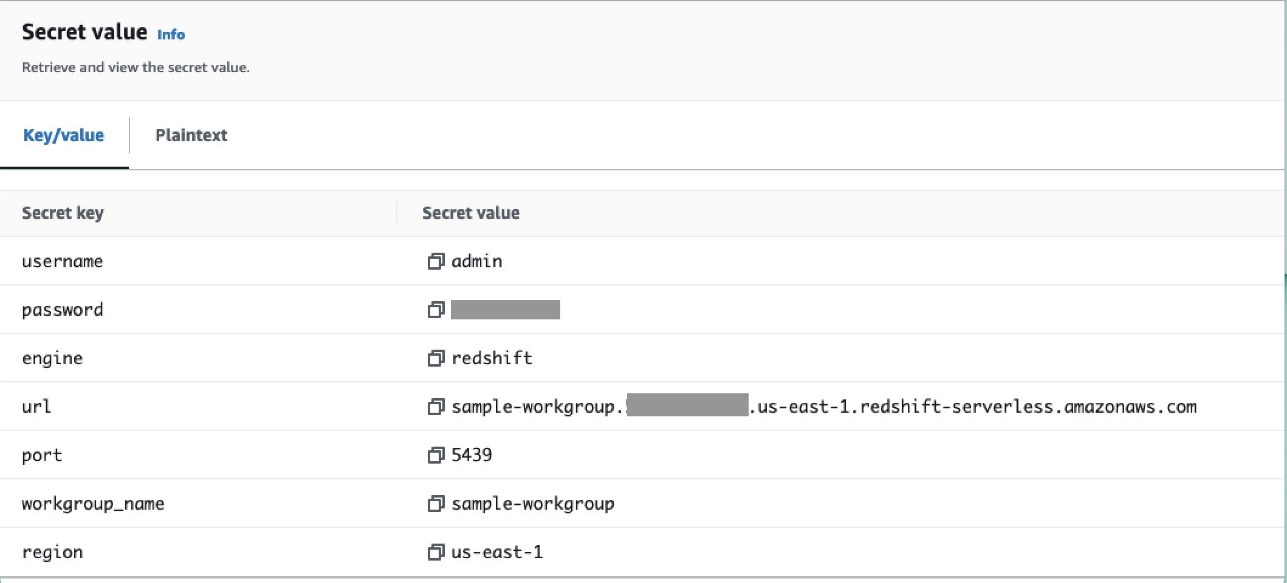
Cree una conexión Airflow a través de la base de datos de metadatos
También puede crear conexiones en la interfaz de usuario. En este caso, los detalles de la conexión se almacenarán en una base de datos de metadatos de Airflow. Si el entorno de Amazon MWAA no está configurado para utilizar el backend de Secrets Manager, comprobará el valor en la base de datos de metadatos y lo devolverá. Puede crear una conexión Airflow mediante la interfaz de usuario, la CLI de AWS o la API. En esta sección, mostramos cómo crear una conexión usando la interfaz de usuario de Airflow.
- ID de conexión, ingrese un nombre para la conexión.
- Tipo de conexión, escoger Desplazamiento al rojo de Amazon.
- Anfitrión, ingrese el punto final de Redshift (sin puerto ni base de datos) para Redshift Serverless.
- Base de datos, introduzca
dev. - Usuario, ingrese su nombre de usuario administrador.
- Contraseña, Ingresa tu contraseña.
- Puerto, utilice el puerto 5439.
- Extra, selecciona el
regionytimeoutparámetros. - Pruebe la conexión y luego guarde su configuración.

Crear y ejecutar un DAG
En esta sección, describimos cómo crear un DAG utilizando varios componentes. Después de crear y ejecutar el DAG, puede verificar los resultados consultando las tablas de Redshift y verificando los depósitos S3 de destino.
Crear un DAG
En Airflow, las canalizaciones de datos se definen en código Python como DAG. Creamos un DAG que consta de varios operadores, sensores, conexiones, tareas y reglas:
- El DAG comienza buscando archivos fuente en el depósito S3
sample-inp-bucket-etl-<username>en la Cuenta A para el día actual usandoS3KeySensor. S3KeySensor se utiliza para esperar a que haya una o varias claves en un depósito de S3.- Por ejemplo, nuestro depósito S3 está particionado como
s3://bucket/products/YYYY/MM/DD/, por lo que nuestro sensor debería buscar carpetas con la fecha actual. Derivamos la fecha actual en el DAG y la pasamos aS3KeySensor, que busca archivos nuevos en la carpeta del día actual. - también establecemos
wildcard_matchasTrue, que permite realizar búsquedas enbucket_keydebe interpretarse como un patrón comodín de Unix. Selecciona elmodeareschedulepara que la tarea del sensor libere el espacio del trabajador cuando no se cumplan los criterios y se reprograme en un momento posterior. Como práctica recomendada, utilice este modo cuandopoke_intervales más de 1 minuto para evitar demasiada carga en un programador.
- Por ejemplo, nuestro depósito S3 está particionado como
- Una vez que el archivo esté disponible en el depósito S3, el rastreador de AWS Glue se ejecuta utilizando
GlueCrawlerOperatorpara rastrear el depósito de origen de S3sample-inp-bucket-etl-<username>en Cuenta A y actualiza los metadatos de la tabla en la cuentaproducts_dbbase de datos en el catálogo de datos. El rastreador utiliza el rol de AWS Glue y la base de datos del catálogo de datos que se crearon en los pasos anteriores. - El DAG utiliza
GlueCrawlerSensoresperar a que se complete el rastreador. - Cuando se complete el trabajo del rastreador,
GlueJobOperatorse utiliza para ejecutar el trabajo de AWS Glue. El nombre del script de AWS Glue (junto con la ubicación) se pasa al operador junto con la función IAM de AWS Glue. Otros parámetros comoGlueVersion,NumberofWorkersyWorkerTypese pasan usando elcreate_job_kwargsparámetro. - El DAG utiliza
GlueJobSensoresperar a que se complete el trabajo de AWS Glue. Cuando esté completa, la mesa de preparación de Redshiftproductsse cargará con datos del archivo S3. - Puede conectarse a Amazon Redshift desde Airflow usando tres diferentes operadores:
PythonOperator.SQLExecuteQueryOperator, que utiliza una conexión PostgreSQL yredshift_defaultcomo conexión predeterminada.RedshiftDataOperator, que utiliza la API de datos Redshift yaws_defaultcomo conexión predeterminada.
En nuestro DAG, usamos SQLExecuteQueryOperator y RedshiftDataOperator para mostrar cómo utilizar estos operadores. Se ejecutan los procedimientos almacenados de Redshift. RedshiftDataOperator. El DAG también ejecuta comandos SQL en Amazon Redshift para eliminar los datos de la tabla provisional mediante SQLExecuteQueryOperator.
Debido a que configuramos nuestro entorno Amazon MWAA para buscar conexiones en Secrets Manager, cuando se ejecuta DAG, recupera los detalles de la conexión de Redshift como nombre de usuario, contraseña, host, puerto y región de Secrets Manager. Si la conexión no se encuentra en Secrets Manager, los valores se recuperan de las conexiones predeterminadas.
In SQLExecuteQueryOperator, le pasamos el nombre de la conexión que creamos en Secrets Manager. busca airflow/connections/secrets_redshift_connection y recupera los secretos de Secrets Manager. Si Secrets Manager no está configurado, la conexión creada manualmente (por ejemplo, redshift-conn-id) se puede pasar.
In RedshiftDataOperator, pasamos el secret_arn del airflow/connections/redshift_conn_test conexión creada en Secrets Manager como parámetro.
- Como tarea final,
RedshiftToS3Operatorse utiliza para descargar datos de la tabla Redshift a un depósito S3sample-opt-bucket-etlen la cuenta B.airflow/connections/redshift_conn_testde Secrets Manager se utiliza para descargar los datos. TriggerRulese establece aALL_DONE, que permite que se ejecute el siguiente paso una vez completadas todas las tareas anteriores.- La dependencia de las tareas se define utilizando el
chain()función, que permite ejecuciones paralelas de tareas si es necesario. En nuestro caso, queremos que todas las tareas se ejecuten en secuencia.
El siguiente es el código DAG completo. El dag_id debe coincidir con el nombre del script DAG; de lo contrario, no se sincronizará con la interfaz de usuario de Airflow.
Verificar la ejecución de DAG
Después de crear el archivo DAG (reemplace las variables en el script DAG) y cargarlo en el s3://sample-airflow-instance/dags carpeta, se sincronizará automáticamente con la interfaz de usuario de Airflow. Todos los DAG aparecen en el DAG pestaña. Alternar el ON opción para hacer que el DAG sea ejecutable. Porque nuestro DAG está configurado para schedule="@once", debe ejecutar manualmente el trabajo eligiendo el icono de ejecución debajo Acciones. Cuando se completa el DAG, el estado se actualiza en verde, como se muestra en la siguiente captura de pantalla.
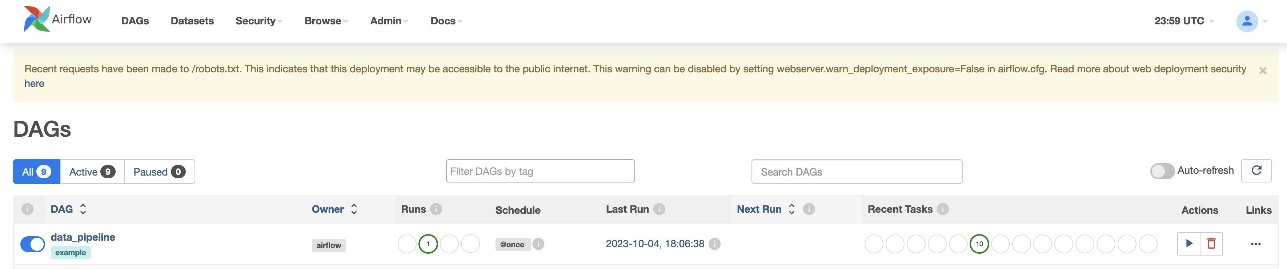
En Enlaces sección, hay opciones para ver el código, el gráfico, la cuadrícula, el registro y más. Elegir Gráfico para visualizar el DAG en formato gráfico. Como se muestra en la siguiente captura de pantalla, cada color del nodo indica un operador específico y el color del contorno del nodo indica un estado específico.

Verificar los resultados
En la consola de Amazon Redshift, vaya a la Editor de consultas v2 y seleccione los datos en el products_f mesa. La tabla debe estar cargada y tener la misma cantidad de registros que los archivos S3.

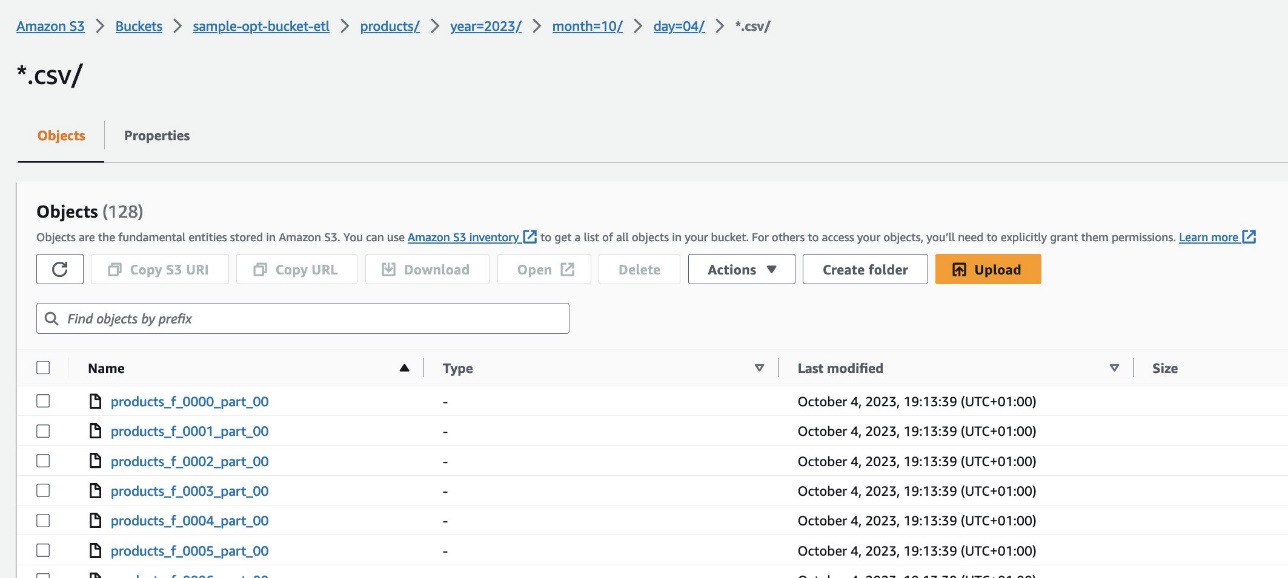
En la consola de Amazon S3, navegue hasta el depósito S3. s3://sample-opt-bucket-etl en la cuenta B. El product_f Los archivos deben crearse bajo la estructura de carpetas. s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.
Limpiar
Limpie los recursos creados como parte de esta publicación para evitar incurrir en cargos continuos:
- Elimine las pilas de CloudFormation y el depósito de S3 que creó como requisitos previos.
- Elimine las VPC y las conexiones de intercambio de tráfico de VPC, las políticas y roles entre cuentas y los secretos en Secrets Manager.
Conclusión
Con Amazon MWAA, puede crear flujos de trabajo complejos utilizando Airflow y Python sin administrar clústeres, nodos o cualquier otra sobrecarga operativa típicamente asociada con la implementación y el escalado de Airflow en producción. En esta publicación, mostramos cómo Amazon MWAA proporciona una forma automatizada de ingerir, transformar, analizar y distribuir datos entre diferentes cuentas y servicios dentro de AWS. Para obtener más ejemplos de otros operadores de AWS, consulte lo siguiente Repositorio GitHub; Le animamos a aprender más probando algunos de estos ejemplos.
Acerca de los autores

Radhika Jakkula es arquitecto de soluciones de creación de prototipos de Big Data en AWS. Ayuda a los clientes a crear prototipos utilizando los servicios de análisis de AWS y bases de datos diseñadas específicamente. Es especialista en evaluar una amplia gama de requisitos y aplicar servicios, herramientas de big data y marcos de AWS relevantes para crear una arquitectura sólida.
 Sidhanth Muralidhar es gerente técnico principal de cuentas en AWS. Trabaja con grandes clientes empresariales que ejecutan sus cargas de trabajo en AWS. Le apasiona trabajar con los clientes y ayudarlos a diseñar cargas de trabajo para lograr costos, confiabilidad, rendimiento y excelencia operativa a escala en su viaje a la nube. También tiene un gran interés en el análisis de datos.
Sidhanth Muralidhar es gerente técnico principal de cuentas en AWS. Trabaja con grandes clientes empresariales que ejecutan sus cargas de trabajo en AWS. Le apasiona trabajar con los clientes y ayudarlos a diseñar cargas de trabajo para lograr costos, confiabilidad, rendimiento y excelencia operativa a escala en su viaje a la nube. También tiene un gran interés en el análisis de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/

