Amazon Textil es un servicio de aprendizaje automático (ML) que extrae automáticamente texto, escritura a mano y datos de documentos escaneados. Consultas es una característica que le permite extraer información específica de documentos variados y complejos utilizando lenguaje natural. Consultas personalizadas le proporciona una forma de personalizar la función Consultas para documentos no estándar específicos de su negocio, como contratos de préstamo de automóviles, cheques y extractos de pago, de forma autoservicio. Al personalizar la función para reconocer los términos, estructuras e información clave únicos específicos de estos tipos de documentos, puede satisfacer sus necesidades de procesamiento posterior con mayor precisión y mínima intervención humana. Las consultas personalizadas son fáciles de integrar en su canal de Textract existente y usted continúa beneficiándose de las funciones de procesamiento de documentos inteligentes totalmente administradas de Amazon Textract sin tener que invertir en experiencia en aprendizaje automático o administración de infraestructura.
En esta publicación, mostramos cómo las consultas personalizadas pueden extraer datos con precisión de cheques que son documentos complejos y no estándar. Además, analizamos los beneficios de las consultas personalizadas y compartimos las mejores prácticas para utilizar esta función de forma eficaz.
Resumen de la solución
Al comenzar con un nuevo caso de uso, puede evaluar el rendimiento de Textract Queries en sus documentos navegando a la página Consola de texto y utilizando la demostración de análisis de documentos o el cargador masivo de documentos. Referirse a Prácticas recomendadas para consultas para redactar consultas aplicables a su caso de uso. Si identifica errores en las respuestas a la consulta debido a la naturaleza de sus documentos comerciales, puede utilizar Consultas personalizadas para mejorar la precisión. En cuestión de horas, puede anotar sus documentos de muestra utilizando el Consola de administración de AWS y entrenar a un adaptador. Los adaptadores son componentes que se conectan al modelo de aprendizaje profundo previamente entrenado de Amazon Textract, personalizando su salida en función de sus documentos anotados. Puede utilizar el adaptador para realizar inferencias pasando el identificador del adaptador como parámetro adicional al Analizar consultas de documentos Solicitud de API.
Examinemos cómo Consultas personalizadas puede mejorar la precisión de la extracción en un escenario desafiante del mundo real, como la extracción de datos de controles. El principal desafío al procesar cheques surge de su alto grado de variación dependiendo del tipo (por ejemplo, cheques personales o de caja), institución financiera y país (por ejemplo, formato de línea MICR). . Estas variaciones pueden incluir la ubicación del nombre del beneficiario, el monto en números y palabras, la fecha y la firma. Reconocer y adaptarse a estas variaciones puede ser una tarea compleja durante la extracción de datos. Para mejorar la extracción de datos, las organizaciones suelen emplear procesos de verificación y validación manuales, lo que aumenta el costo y el tiempo del proceso de extracción.
Las consultas personalizadas abordan estos desafíos al permitirle personalizar las funciones de consultas previamente capacitadas en las diferentes variaciones de cheques. La personalización de la función previamente entrenada le ayuda a lograr una alta precisión de extracción de datos en la variedad específica de diseños que procesa.
En nuestro caso de uso, una institución financiera desea extraer los siguientes campos de un cheque: nombre del beneficiario, nombre del pagador, número de cuenta, número de ruta, monto del pago (en números), monto del pago (en palabras), número de cheque, fecha y memorándum.
Exploremos el proceso de generación de un adaptador (componente que personaliza la salida) para el procesamiento de cheques. Los adaptadores se pueden crear a través de la consola o mediante programación a través de la API. Esta publicación detalla la experiencia de la consola; sin embargo, si desea crear el adaptador mediante programación, consulte los ejemplos de código en el consultas-personalizadas-verificaciones-blog.ipynb Cuaderno Jupyter (Opción 2).
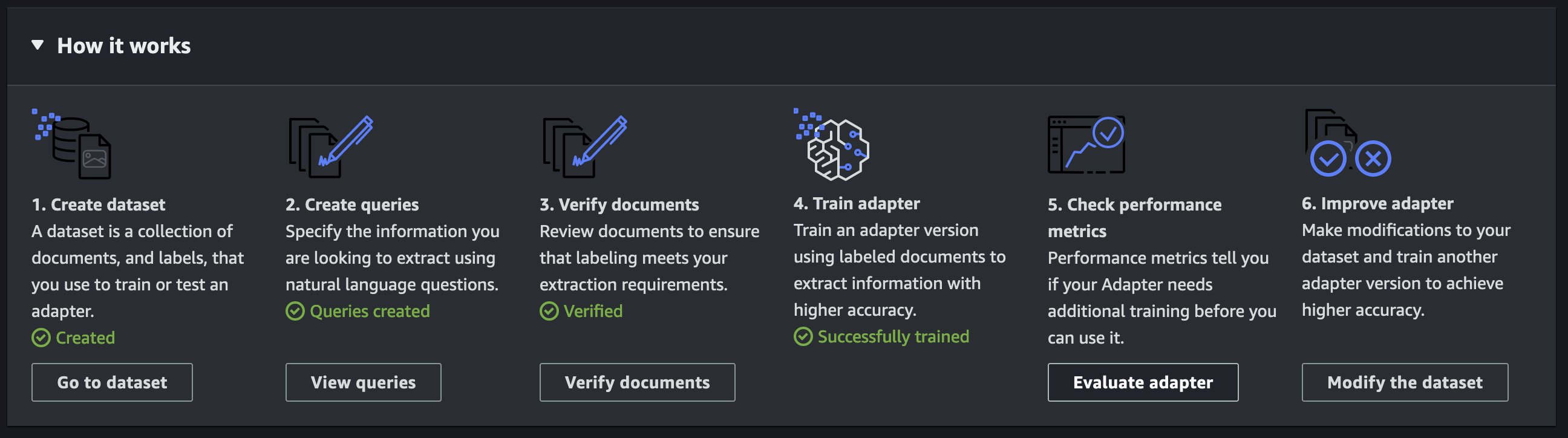
El proceso de generación de adaptadores implica cinco pasos de alto nivel: crear un adaptador, cargar documentos de muestra, anotar los documentos, entrenar el adaptador y evaluar las métricas de rendimiento.
Crear un adaptador
En la consola de Amazon Textract, cree un nuevo adaptador proporcionando un nombre, una descripción y etiquetas opcionales que puedan ayudarle a identificar el adaptador. Tiene la opción de habilitar las actualizaciones automáticas, lo que permite a Amazon Textract actualizar su adaptador cuando la función de Consultas subyacente se actualiza con nuevas capacidades.

Después de crear el adaptador, verá una página de detalles del adaptador con una lista de pasos en el Cómo funciona sección. Esta sección activará sus próximos pasos a medida que los complete secuencialmente.

Cargar documentos de muestra
La fase inicial en la generación de adaptadores implica la selección cuidadosa de un conjunto apropiado de documentos de muestra para anotaciones, capacitación y pruebas. Tenemos una opción para dividir automáticamente los documentos en conjuntos de datos de prueba y entrenamiento; sin embargo, para este proceso, dividimos manualmente el conjunto de datos.
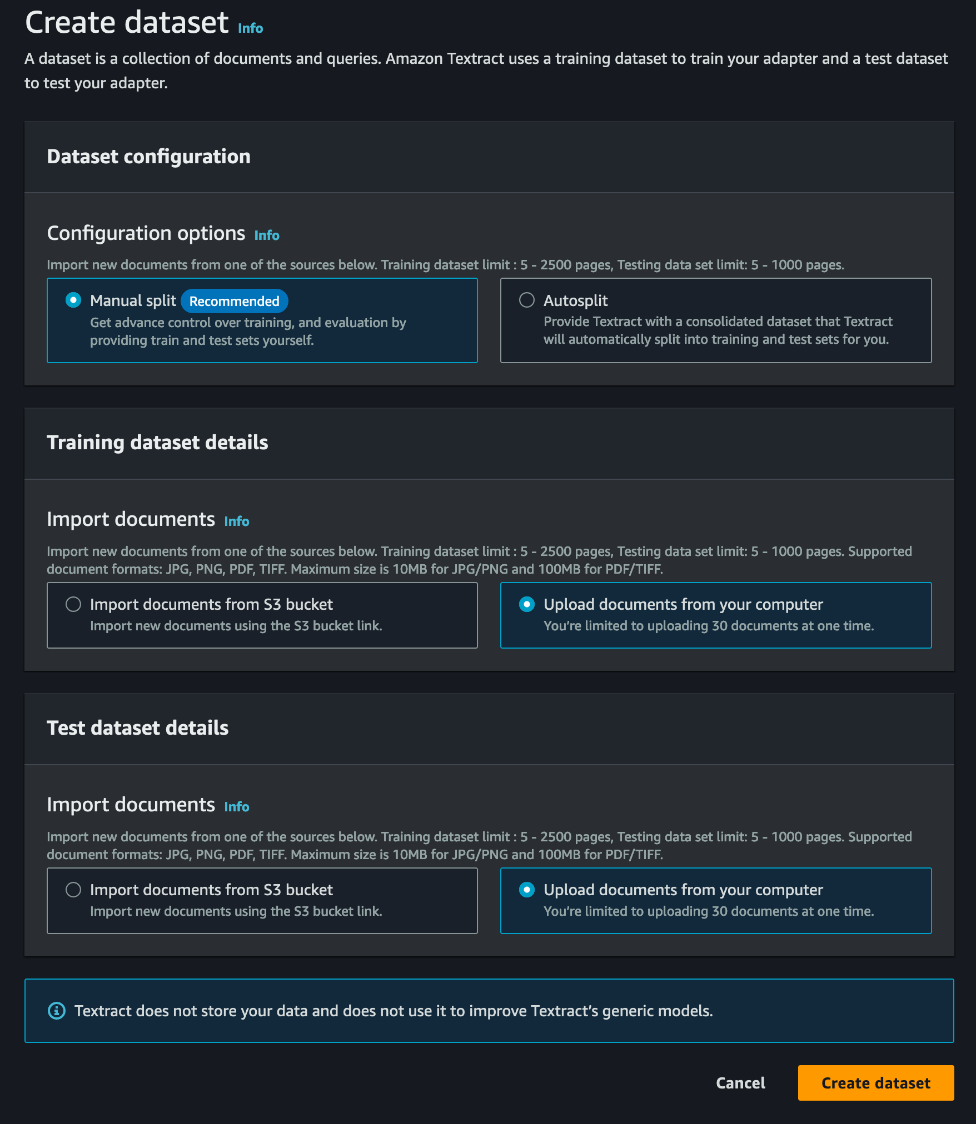
Es importante tener en cuenta que puede construir un adaptador con tan solo cinco muestras de prueba y cinco de entrenamiento, pero es esencial garantizar que este conjunto de muestras sea diverso y representativo de la carga de trabajo encontrada en un entorno de producción.
Para este tutorial, hemos seleccionado conjuntos de datos de verificación de muestra que puede descargar. Nuestro conjunto de datos incluye variaciones como cheques personales, cheques de caja, cheques de estímulo y cheques integrados en recibos de pago. También incluimos cheques escritos a mano e impresos; junto con variaciones en campos como la línea de nota.
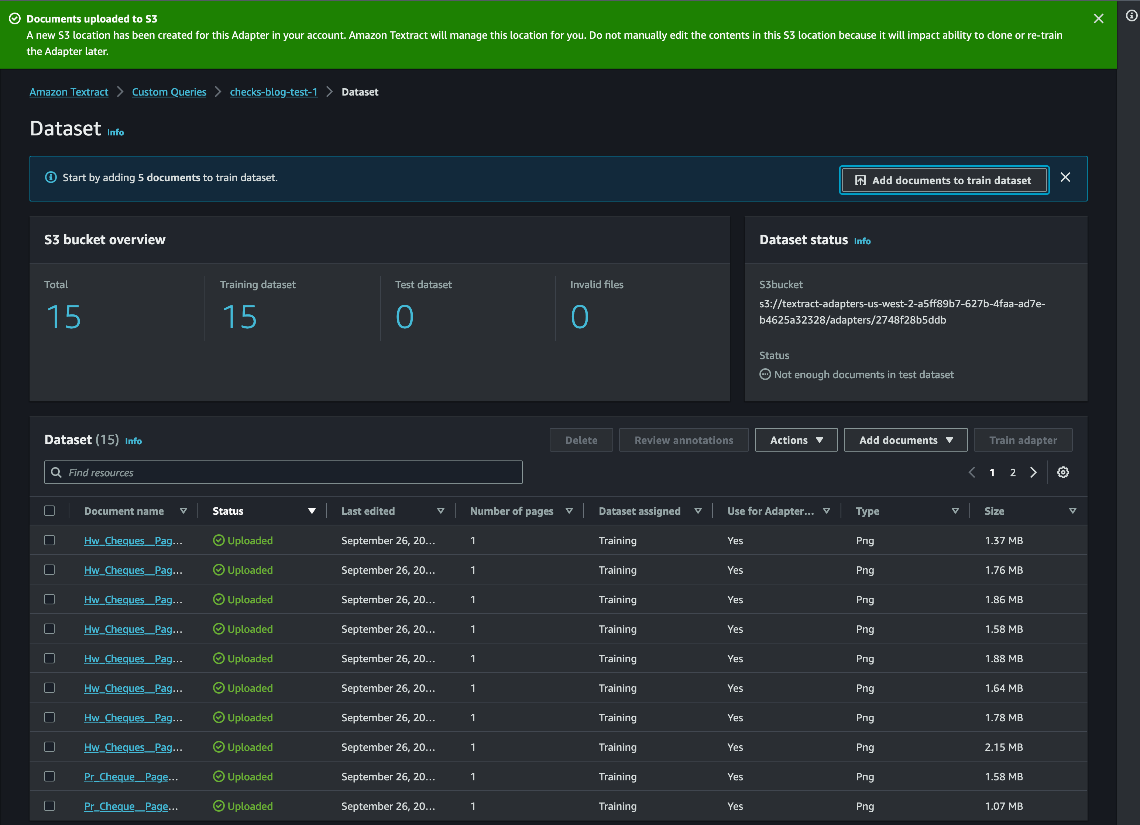
Anotar documentos de muestra
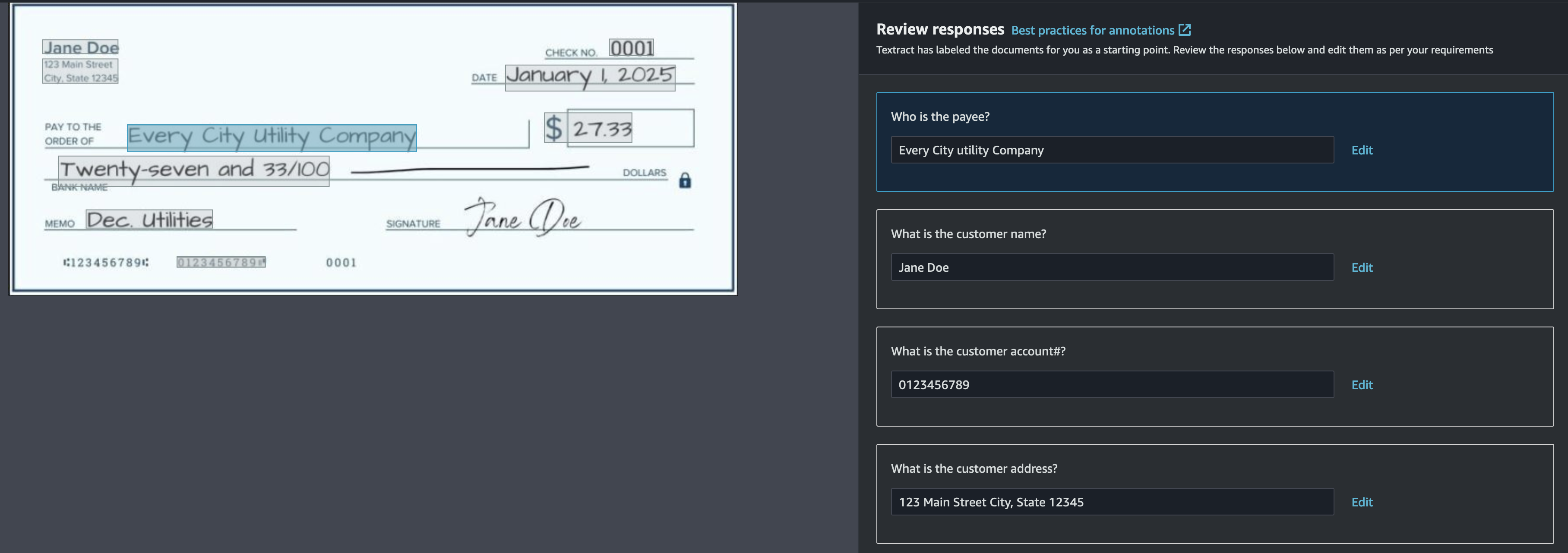
Como siguiente paso, puede anotar los documentos de muestra asociando consultas con sus respuestas correspondientes a través de la consola. Puede iniciar la anotación mediante etiquetado automático o etiquetado manual. El etiquetado automático utiliza consultas de Amazon Textract para etiquetar previamente el conjunto de datos. Recomendamos utilizar el etiquetado automático para acelerar el proceso de anotación.
Para este caso de uso de procesamiento de comprobaciones, utilizamos las siguientes consultas. Si su caso de uso involucra otros tipos de documentos, consulte Prácticas recomendadas para consultas para redactar consultas aplicables a su caso de uso.
- ¿Quién es el beneficiario?
- ¿Cuál es el número de cheque?
- ¿Cuál es la dirección del beneficiario?
- ¿Cual es la fecha?
- ¿Cuál es el número de cuenta?
- ¿Cuál es el monto del cheque en palabras?
- ¿Cuál es el nombre de la cuenta/pagador/nombre del librador?
- ¿Cuál es el monto en dólares?
- ¿Cuál es el nombre del banco/nombre del librado?
- ¿Cuál es el número de ruta bancaria?
- ¿Qué es la línea MICR?
- ¿Qué es la nota?

Cuando se completa el proceso de etiquetado automático, tiene la opción de revisar y editar las respuestas proporcionadas para cada documento. Elegir Empezar a revisar para revisar las anotaciones de cada imagen.
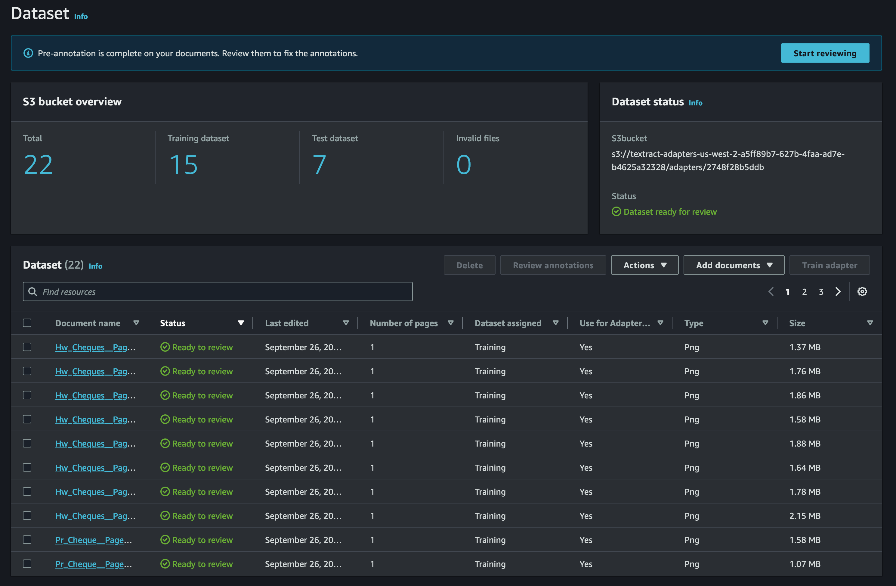
Si falta la respuesta a una consulta o es incorrecta, puede agregar o editar la respuesta dibujando un cuadro delimitador o ingresando la respuesta manualmente.
Para acelerar su recorrido, hemos anotado previamente los ejemplos de cheques para que los copie en su cuenta de AWS. Ejecute el consultas-personalizadas-verificaciones-blog.ipynb Cuaderno Jupyter dentro del Ejemplos de código de Amazon Texttract biblioteca para actualizar automáticamente sus anotaciones.
Entrenar al adaptador
Una vez que haya revisado todos los documentos de muestra para garantizar la precisión de las anotaciones, puede comenzar el proceso de capacitación del adaptador. Durante este paso, debe designar una ubicación de almacenamiento donde se debe guardar el adaptador. La duración del proceso de capacitación variará según el tamaño del conjunto de datos utilizado para la capacitación. La API de entrenamiento también se puede invocar mediante programación si elige utilizar una herramienta de anotación de su propia elección y pasa los archivos de entrada relevantes a la API. Referirse a Consultas personalizadas para más información.

Evaluar métricas de rendimiento
Una vez que el adaptador haya completado la capacitación, puede evaluar su rendimiento examinando métricas de evaluación como Puntuación F1, precisión y recuperación. Puede analizar estas métricas de forma colectiva o por documento. Al utilizar nuestro conjunto de datos de comprobaciones de muestra, verá que la métrica de precisión (puntuación F1) mejora del 68 % al 92 % con el adaptador entrenado.

Además, puede probar la salida del adaptador en documentos nuevos eligiendo Pruebe el adaptador.

Después de la evaluación, puede optar por mejorar el rendimiento del adaptador incorporando documentos de muestra adicionales en el conjunto de datos de entrenamiento o volviendo a anotar documentos con puntuaciones inferiores a su umbral. Para volver a anotar documentos, elija Verificar documentos en la página de detalles del adaptador, seleccione el documento y elija Revisar anotaciones.
Pruebe programáticamente el adaptador
Una vez completada con éxito la capacitación, ahora puede utilizar el adaptador en su AnalizarDocumento Llamadas API. La solicitud de API es similar a la solicitud de API de consultas de Amazon Textract, con la adición de AdaptersConfig objeto.
Puede ejecutar el siguiente código de muestra o ejecutarlo directamente dentro del consultas-personalizadas-verificaciones-blog.ipynb Cuaderno Jupyter. El cuaderno de muestra también proporciona código para comparar resultados entre consultas de Amazon Textract y consultas personalizadas de Amazon Textract.
Crear una Configuración de adaptadores objeto con el ID del adaptador y la versión del adaptador y, opcionalmente, incluya las páginas a las que desea que se aplique el adaptador:
Créar un QueriesConfig objeto con las consultas con las que entrenó el adaptador y llame a la API de Amazon Textract. Tenga en cuenta que también puede incluir consultas adicionales en las que el adaptador no haya recibido capacitación. Amazon Textract utilizará automáticamente la función Consultas para estas preguntas y no Consultas personalizadas, lo que le brindará la flexibilidad de utilizar Consultas personalizadas solo cuando sea necesario.
Finalmente, tabulamos nuestros resultados para una mejor legibilidad:
Limpiar
Para limpiar sus recursos, complete los siguientes pasos:
- En la consola de Amazon Textract, elija Consultas personalizadas en el panel de navegación.
- Seleccione el adaptador que desea eliminar.
- Elige Borrar.
Gestión de adaptadores
Puede mejorar periódicamente sus adaptadores creando nuevas versiones de un adaptador generado previamente. Para crear una nueva versión de un adaptador, agregue nuevos documentos de muestra a un adaptador existente, etiquete los documentos y realice capacitación. Puede mantener simultáneamente varias versiones de un adaptador para utilizarlo en sus procesos de desarrollo. Para actualizar sus adaptadores sin problemas, no realice cambios ni elimine su Servicio de almacenamiento simple de Amazon (Amazon S3) depósito donde se guardan los archivos necesarios para la generación del adaptador.
Mejores prácticas
Cuando utilice consultas personalizadas en sus documentos, consulte Mejores prácticas para consultas personalizadas de Amazon Textract para consideraciones adicionales y mejores prácticas.
Beneficios de las consultas personalizadas
Consultas personalizadas ofrece los siguientes beneficios:
- Comprensión mejorada de los documentos – Gracias a su capacidad para extraer y normalizar datos con alta precisión, las consultas personalizadas reducen la dependencia de revisiones y auditorías manuales, y le permiten crear una automatización más confiable para sus flujos de trabajo de procesamiento de documentos inteligentes.
- Tiempo de valoración más rápido – Cuando encuentre nuevos tipos de documentos en los que necesite mayor precisión, puede utilizar consultas personalizadas para generar un adaptador de forma autoservicio en unas pocas horas. No tiene que esperar una actualización del modelo previamente entrenado cuando encuentre nuevos tipos de documentos o variaciones de los existentes en su flujo de trabajo. Tiene control total sobre su canalización y no necesita depender de Amazon Textract para admitir sus nuevos tipos de documentos.
- Privacidad de datos – Custom Queries no retiene ni utiliza los datos empleados en la generación de adaptadores para mejorar nuestros modelos generales previamente entrenados disponibles para todos los clientes. El adaptador se limita a la cuenta del cliente u otras cuentas designadas explícitamente por el cliente, lo que garantiza que solo dichas cuentas puedan acceder a las mejoras realizadas utilizando los datos del cliente.
- Conveniencia –Las consultas personalizadas proporcionan una experiencia de inferencia completamente administrada similar a las consultas. La formación del adaptador es gratuita y sólo pagarás por la inferencia. Las consultas personalizadas le ahorran los gastos generales y los gastos de capacitación y operación de modelos personalizados.
Conclusión
En esta publicación, analizamos los beneficios de las consultas personalizadas, mostramos cómo las consultas personalizadas pueden extraer datos de los cheques con precisión y compartimos las mejores prácticas para utilizar esta función de manera efectiva. En solo unas horas, puede crear un adaptador usando la consola y usarlo en la API AnalyzeDocument para sus necesidades de extracción de datos. Para obtener más información, consulte Consultas personalizadas.
Sobre los autores
 Shibin Michael Raj es gerente de producto sénior del equipo de Amazon Textract. Se centra en la creación de productos basados en IA/ML para clientes de AWS. Le entusiasma ayudar a los clientes a resolver sus complejos desafíos comerciales aprovechando las tecnologías de inteligencia artificial y aprendizaje automático. En su tiempo libre, le gusta correr, escuchar podcasts y perfeccionar sus habilidades en el tenis amateur.
Shibin Michael Raj es gerente de producto sénior del equipo de Amazon Textract. Se centra en la creación de productos basados en IA/ML para clientes de AWS. Le entusiasma ayudar a los clientes a resolver sus complejos desafíos comerciales aprovechando las tecnologías de inteligencia artificial y aprendizaje automático. En su tiempo libre, le gusta correr, escuchar podcasts y perfeccionar sus habilidades en el tenis amateur.
 keith mascarenhas es un arquitecto de soluciones sénior del equipo de servicio de Amazon Textract. Le apasiona resolver problemas comerciales a escala utilizando el aprendizaje automático y actualmente ayuda a nuestros clientes en todo el mundo a automatizar el procesamiento de documentos para lograr un tiempo de comercialización más rápido con costos operativos reducidos.
keith mascarenhas es un arquitecto de soluciones sénior del equipo de servicio de Amazon Textract. Le apasiona resolver problemas comerciales a escala utilizando el aprendizaje automático y actualmente ayuda a nuestros clientes en todo el mundo a automatizar el procesamiento de documentos para lograr un tiempo de comercialización más rápido con costos operativos reducidos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/customize-amazon-textract-with-business-specific-documents-using-custom-queries/

