Servicio Amazon OpenSearch presentó recientemente la familia de instancias optimizadas OpenSearch (OR1), que ofrece una mejora de precio-rendimiento de hasta un 30 % con respecto a las instancias optimizadas de memoria existentes en pruebas comparativas internas, y utiliza Servicio de almacenamiento simple de Amazon (Amazon S3) para proporcionar 11 9 de durabilidad. Con esta nueva familia de instancias, OpenSearch Service utiliza la innovación de OpenSearch y las tecnologías de AWS para reinventar cómo se indexan y almacenan los datos en la nube.
Hoy en día, los clientes utilizan ampliamente OpenSearch Service para análisis operativos debido a su capacidad para ingerir grandes volúmenes de datos y, al mismo tiempo, proporcionar análisis ricos e interactivos. Para brindar estos beneficios, OpenSearch está diseñado como un sistema distribuido de alta escala con múltiples instancias independientes que indexan datos y procesan solicitudes. A medida que aumentan la velocidad de los datos de análisis operativo y el volumen de datos, pueden surgir cuellos de botella. Para soportar de manera sostenible un alto volumen de indexación y brindar durabilidad, creamos la familia de instancias OR1.
En esta publicación, analizamos cómo funciona el flujo de datos reinventado con instancias OR1 y cómo puede proporcionar un alto rendimiento de indexación y durabilidad mediante un nuevo protocolo de replicación física. También profundizamos en algunos de los desafíos que resolvimos para mantener la corrección y la integridad de los datos.
Diseño para un alto rendimiento con 11 9 de durabilidad
OpenSearch Service gestiona decenas de miles de clústeres de OpenSearch. Hemos obtenido información sobre las configuraciones típicas de clústeres que los clientes utilizan para alcanzar objetivos de alto rendimiento y durabilidad. Para lograr un mayor rendimiento, los clientes a menudo optan por descartar copias de réplica para ahorrar en la latencia de replicación; sin embargo, esta configuración da como resultado el sacrificio de disponibilidad y durabilidad. Otros clientes requieren una alta durabilidad y, como resultado, necesitan mantener múltiples copias de réplica, lo que genera mayores costos operativos para ellos.
La familia de instancias optimizadas de OpenSearch proporciona durabilidad adicional y al mismo tiempo mantiene los costos más bajos al almacenar una copia de los datos en Amazon S3. Con las instancias OR1, puede configurar múltiples copias de réplica para una alta disponibilidad de lectura mientras mantiene el rendimiento de indexación.
El siguiente diagrama ilustra un flujo de indexación que involucra una actualización de metadatos en OR1
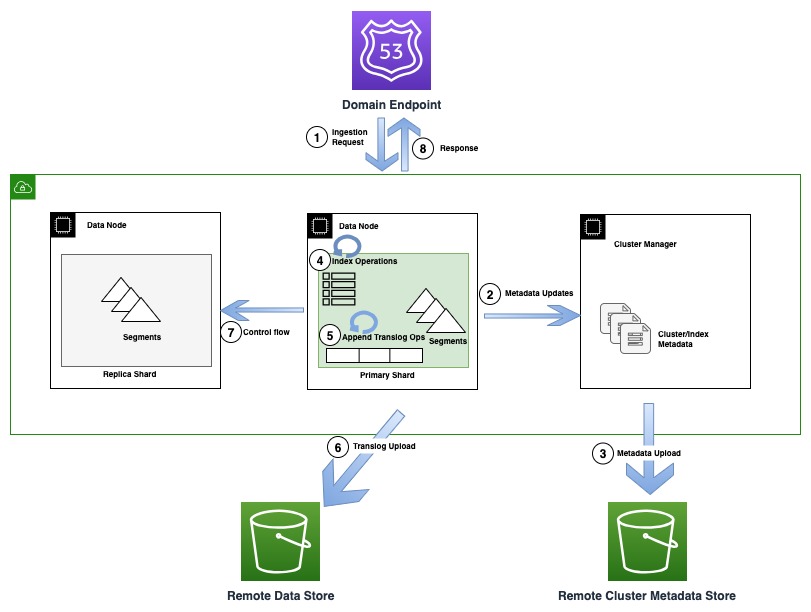
Durante las operaciones de indexación, los documentos individuales se indexan en Lucene y también se agregan a un registro de escritura anticipada, también conocido como translog. Antes de enviar una confirmación al cliente, todas las operaciones de translog se conservan en el almacén de datos remoto respaldado por Amazon S3. Si se configuran copias de réplica, la copia principal realiza comprobaciones para detectar la posibilidad de que existan múltiples escritores (flujo de control) en todas las copias de réplica por motivos de corrección.
El siguiente diagrama ilustra el flujo de generación y replicación de segmentos en instancias OR1.
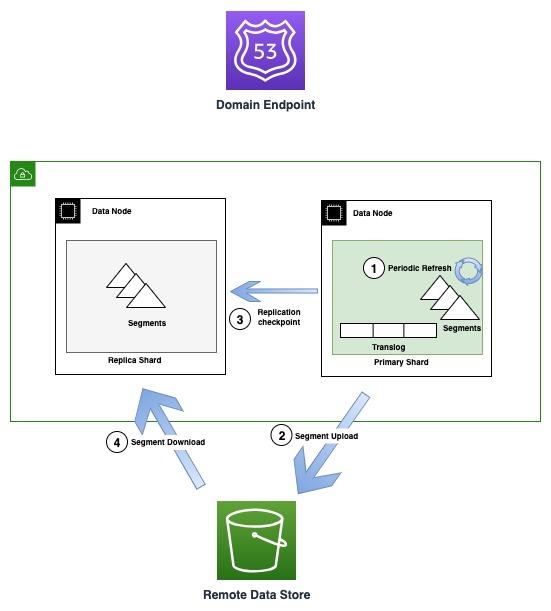
Periódicamente, a medida que se crean nuevos archivos de segmentos, el OR1 copia esos segmentos en Amazon S3. Cuando se completa la transferencia, el principal publica nuevos puntos de control en todas las copias de réplica, notificándoles que hay un nuevo segmento disponible para descargar. Posteriormente, las réplicas descargan segmentos más nuevos y los hacen aptos para búsquedas. Este modelo desacopla el flujo de datos que ocurre mediante Amazon S3 y el flujo de control (publicación de puntos de control y validación de términos) que ocurre a través de la comunicación de transporte entre nodos.
El siguiente diagrama ilustra el flujo de recuperación en instancias OR1.
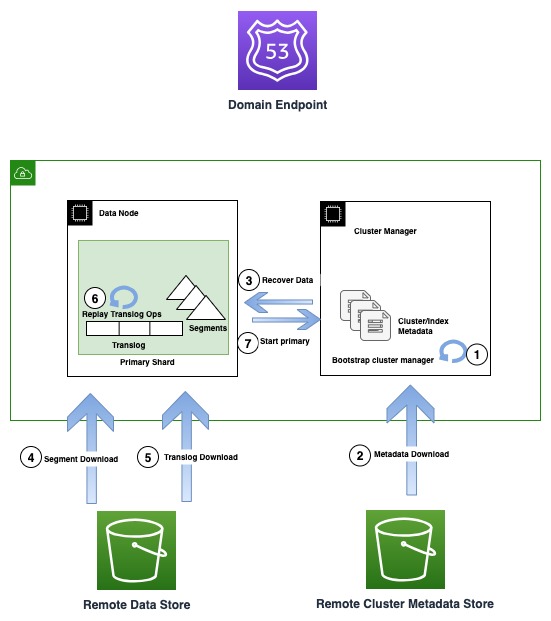
Las instancias OR1 conservan no solo los datos, sino también los metadatos del clúster, como asignaciones de índices, plantillas y configuraciones en Amazon S3. Esto garantiza que, en caso de pérdida de quórum del administrador de clústeres, que es un modo de falla común en configuraciones de administradores de clústeres no dedicados, OpenSearch pueda recuperar de manera confiable los últimos metadatos reconocidos.
En caso de una falla de infraestructura, un dominio OpenSearch puede terminar perdiendo uno o más nodos. En tal caso, la nueva familia de instancias garantiza la recuperación tanto de los metadatos del clúster como de los datos del índice hasta la última operación reconocida. A medida que nuevos nodos de reemplazo se unen al clúster, el mecanismo interno de recuperación del clúster arranca el nuevo conjunto de nodos y luego recupera los metadatos del clúster más recientes del almacén de metadatos del clúster remoto. Una vez recuperados los metadatos del clúster, el mecanismo de recuperación comienza a hidratar los datos del segmento faltante y a translogar desde Amazon S3. Luego, todas las operaciones de translog no confirmadas, hasta la última operación reconocida, se reproducen para restablecer la copia perdida.
El nuevo diseño no modifica la forma en que funcionan las búsquedas. Las consultas las procesa normalmente el fragmento principal o la réplica de cada fragmento del índice. Es posible que observe retrasos más prolongados (en el rango de 10 segundos) antes de que todas las copias sean coherentes en un momento determinado porque la replicación de datos utiliza Amazon S3.
Una ventaja clave de esta arquitectura es que sirve como elemento fundamental para futuras innovaciones, como la separación de lectores y escritores, y ayuda a segregar las capas de computación y almacenamiento.
Cómo la redefinición de la estrategia de replicación aumenta el rendimiento de la indexación
OpenSearch admite dos estrategias de replicación: replicación lógica (documento) y física (segmento). En el caso de la replicación lógica, los datos se indexan en todas las copias de forma independiente, lo que genera cálculos redundantes en el clúster. Las instancias OR1 utilizan el nuevo replicación física modelo, donde los datos se indexan solo en la copia principal y se crean copias adicionales copiando datos de la copia principal. Con una gran cantidad de copias de réplica, el nodo que aloja la copia principal requiere un ancho de banda de red significativo, replicando el segmento en todas las copias. Las nuevas instancias OR1 resuelven este problema al persistir de forma duradera el segmento en Amazon S3, que está configurado como almacenamiento remoto opción. También ayudan a escalar réplicas sin cuellos de botella en la primaria.
Después de cargar los segmentos en Amazon S3, el principal envía una solicitud de punto de control, notificando a todas las réplicas que descarguen los nuevos segmentos. Luego, las copias de réplica deben descargar los segmentos incrementales. Debido a que este proceso libera recursos informáticos en las réplicas, que de otro modo serían necesarios para indexar datos de forma redundante y la sobrecarga de red incurrida en los primarios para replicar datos, el clúster puede generar un mayor rendimiento. En caso de que las réplicas no puedan procesar los segmentos recién creados debido a una sobrecarga o rutas de red lentas, las réplicas más allá de un punto se marcan como fallidas para evitar que devuelvan resultados obsoletos.
Por qué una alta durabilidad es una buena idea, pero difícil de lograr
Aunque todos los segmentos comprometidos se conservan de forma duradera en Amazon S3 cada vez que se crean, uno de los desafíos clave para lograr una alta durabilidad es escribir sincrónicamente todas las operaciones no comprometidas en un registro de escritura anticipada en Amazon S3, antes de confirmar la solicitud al cliente, sin sacrificar rendimiento. La nueva semántica introduce latencia de red adicional para solicitudes individuales, pero la forma en que nos aseguramos de que no haya impacto en el rendimiento es agrupando y drenando solicitudes en un solo subproceso durante un intervalo específico, mientras nos aseguramos de que otros subprocesos continúen indexando. peticiones. Como resultado, puede impulsar un mayor rendimiento con más conexiones de clientes simultáneas agrupando de manera óptima sus cargas útiles masivas.
Otros desafíos en el diseño de un sistema altamente duradero incluyen hacer cumplir la integridad y corrección de los datos en todo momento. Aunque algunos eventos, como las particiones de red, son poco comunes, pueden alterar la corrección del sistema y, por lo tanto, el sistema debe estar preparado para lidiar con estos modos de falla. Por lo tanto, al cambiar al nuevo protocolo de replicación de segmentos, también introdujimos algunos otros cambios de protocolo, como detectar múltiples escritores en cada réplica. El protocolo garantiza que un escritor aislado no pueda reconocer una solicitud de escritura, mientras que otro primario recién ascendido, según el quórum del administrador del clúster, acepta simultáneamente escrituras más nuevas.
La nueva familia de instancias detecta automáticamente la pérdida de un fragmento primario mientras recupera datos y realiza comprobaciones exhaustivas sobre la accesibilidad de la red antes de que los datos puedan rehidratarse desde Amazon S3 y el clúster vuelva a un estado saludable.
Para garantizar la integridad de los datos, todos los archivos se someten a una exhaustiva suma de verificación para garantizar que podamos detectar y evitar daños en la red o en el sistema de archivos que puedan provocar que los datos sean ilegibles. Además, todos los archivos, incluidos los metadatos, están diseñados para ser inmutables, lo que proporciona seguridad adicional contra la corrupción y están versionados para evitar cambios mutacionales accidentales.
Reimaginando cómo fluyen los datos
Las instancias OR1 hidratan copias directamente desde Amazon S3 para realizar la recuperación de fragmentos perdidos durante una falla de infraestructura. Al utilizar Amazon S3, podemos liberar el ancho de banda de la red, el rendimiento del disco y la computación del nodo principal y, por lo tanto, brindar una experiencia de escalamiento in situ y de implementación azul/verde más fluida al orquestar todo el proceso con una coordinación mínima del nodo principal.
El servicio OpenSearch proporciona copias de seguridad automáticas de datos llamadas instantáneas a intervalos de una hora, lo que significa que, en caso de modificaciones accidentales de los datos, tiene la opción de volver a un estado anterior. Sin embargo, con la nueva familia de instancias OpenSearch, hemos comentado que los datos ya persisten de forma duradera en Amazon S3. Entonces, ¿cómo funcionan las instantáneas cuando ya tenemos los datos presentes en Amazon S3?
Con la nueva familia de instancias, las instantáneas sirven como puntos de control, haciendo referencia a los datos del segmento ya presentes tal como existen en un momento determinado. Esto hace que las instantáneas sean más ligeras y rápidas porque no es necesario volver a cargar ningún dato adicional. En cambio, cargan archivos de metadatos que capturan la vista de los segmentos en ese momento, lo que llamamos instantáneas superficiales. El beneficio de las instantáneas superficiales se extiende a todas las operaciones, es decir, la creación, eliminación y clonación de instantáneas. Todavía tienes la opción de tomar una instantánea de una copia independiente con instantáneas manuales para otras operaciones administrativas.
Resumen
OpenSearch es un software de código abierto impulsado por la comunidad. La mayoría de los cambios fundamentales, incluido el modelo de replicación, el almacenamiento con respaldo remoto y los metadatos del clúster remoto, se han contribuido al código abierto; de hecho, seguimos un primer modelo de desarrollo de código abierto.
Los esfuerzos para mejorar el rendimiento y la confiabilidad son un ciclo interminable a medida que continuamos aprendiendo y mejorando. Las nuevas instancias optimizadas de OpenSearch sirven como piedra angular y allanan el camino para futuras innovaciones. Estamos entusiasmados de continuar nuestros esfuerzos para mejorar la confiabilidad y el rendimiento y ver qué soluciones nuevas y existentes pueden crear los creadores utilizando OpenSearch Service. Esperamos que esto conduzca a una comprensión más profunda de la nueva familia de instancias OpenSearch, cómo esta oferta logra una alta durabilidad y un mejor rendimiento, y cómo puede ayudarlo a configurar clústeres según las necesidades de su negocio.
Si está entusiasmado de contribuir a OpenSearch, abra una Problema de GitHub y déjanos saber tu opinión. También nos encantaría conocer sus historias de éxito en el logro de un alto rendimiento y durabilidad en OpenSearch Service. Si tienes otras preguntas, por favor deja un comentario.
Acerca de los autores
 Bujtawar Khan es un ingeniero principal que trabaja en Amazon OpenSearch Service. Está interesado en construir sistemas distribuidos y autónomos. Es mantenedor y colaborador activo de OpenSearch.
Bujtawar Khan es un ingeniero principal que trabaja en Amazon OpenSearch Service. Está interesado en construir sistemas distribuidos y autónomos. Es mantenedor y colaborador activo de OpenSearch.
 GauravBafna es un ingeniero de software sénior que trabaja en OpenSearch en Amazon Web Services. Le fascina resolver problemas en sistemas distribuidos. Es mantenedor y colaborador activo de OpenSearch.
GauravBafna es un ingeniero de software sénior que trabaja en OpenSearch en Amazon Web Services. Le fascina resolver problemas en sistemas distribuidos. Es mantenedor y colaborador activo de OpenSearch.
 Col rizada Sachin es un ingeniero senior de desarrollo de software en AWS que trabaja en OpenSearch.
Col rizada Sachin es un ingeniero senior de desarrollo de software en AWS que trabaja en OpenSearch.
 Rohin Bhargava es gerente sénior de productos en el equipo de Amazon OpenSearch Service. Su pasión en AWS es ayudar a los clientes a encontrar la combinación correcta de servicios de AWS para lograr el éxito de sus objetivos comerciales.
Rohin Bhargava es gerente sénior de productos en el equipo de Amazon OpenSearch Service. Su pasión en AWS es ayudar a los clientes a encontrar la combinación correcta de servicios de AWS para lograr el éxito de sus objetivos comerciales.
 Ranjith Ramachandra es un gerente de ingeniería sénior que trabaja en Amazon OpenSearch Service. Le apasionan los sistemas distribuidos altamente escalables, los sistemas resilientes y de alto rendimiento.
Ranjith Ramachandra es un gerente de ingeniería sénior que trabaja en Amazon OpenSearch Service. Le apasionan los sistemas distribuidos altamente escalables, los sistemas resilientes y de alto rendimiento.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

