Los modelos de lenguaje grandes (LLM) han revolucionado el campo del procesamiento del lenguaje natural (NLP), mejorando tareas como la traducción de idiomas, el resumen de textos y el análisis de sentimientos. Sin embargo, a medida que estos modelos continúan creciendo en tamaño y complejidad, monitorear su desempeño y comportamiento se ha vuelto cada vez más desafiante.
Monitorear el desempeño y el comportamiento de los LLM es una tarea crítica para garantizar su seguridad y efectividad. Nuestra arquitectura propuesta proporciona una solución escalable y personalizable para el monitoreo de LLM en línea, lo que permite a los equipos adaptar su solución de monitoreo a sus casos de uso y requisitos específicos. Al utilizar los servicios de AWS, nuestra arquitectura proporciona visibilidad en tiempo real del comportamiento de LLM y permite a los equipos identificar y abordar rápidamente cualquier problema o anomalía.
En esta publicación, demostramos algunas métricas para el monitoreo de LLM en línea y su respectiva arquitectura para escalar utilizando servicios de AWS como Reloj en la nube de Amazon y AWS Lambda. Esto ofrece una solución personalizable más allá de lo que es posible con evaluación del modelo trabajos con lecho rocoso del amazonas.
Resumen de la solución
Lo primero a considerar es que diferentes métricas requieren diferentes consideraciones de cálculo. Es necesaria una arquitectura modular, donde cada módulo pueda recibir datos de inferencia del modelo y producir sus propias métricas.
Sugerimos que cada módulo lleve las solicitudes de inferencia entrantes al LLM, pasando pares de indicaciones y finalización (respuesta) a los módulos de cálculo métrico. Cada módulo es responsable de calcular sus propias métricas con respecto al mensaje de entrada y la finalización (respuesta). Estas métricas se pasan a CloudWatch, que puede agregarlas y trabajar con alarmas de CloudWatch para enviar notificaciones sobre condiciones específicas. El siguiente diagrama ilustra esta arquitectura.
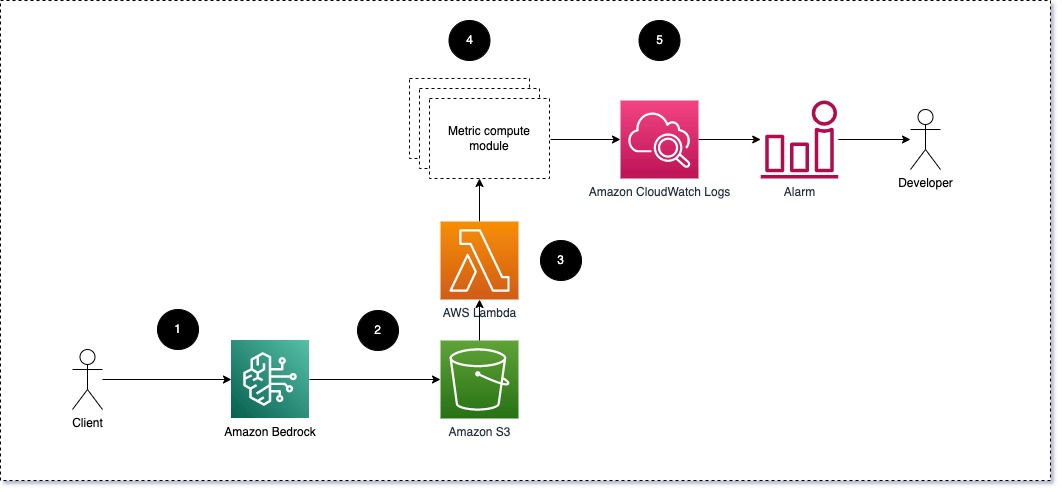
Fig 1: Módulo de cálculo métrico: descripción general de la solución
El flujo de trabajo incluye los siguientes pasos:
- Un usuario realiza una solicitud a Amazon Bedrock como parte de una aplicación o interfaz de usuario.
- Amazon Bedrock guarda la solicitud y la finalización (respuesta) en Servicio de almacenamiento simple de Amazon (Amazon S3) según la configuración de registro de invocaciones.
- El archivo guardado en Amazon S3 crea un evento que dispara una función Lambda. La función invoca los módulos.
- Los módulos publican sus respectivas métricas en Métricas de CloudWatch.
- Alarmas: puede notificar al equipo de desarrollo sobre valores de métricas inesperados.
Lo segundo que hay que considerar al implementar el seguimiento de LLM es elegir las métricas adecuadas para realizar un seguimiento. Aunque existen muchas métricas potenciales que puede utilizar para monitorear el desempeño de LLM, explicamos algunas de las más amplias en esta publicación.
En las siguientes secciones, destacamos algunas de las métricas de módulo relevantes y su respectiva arquitectura de módulo de computación métrica.
Similitud semántica entre aviso y finalización (respuesta)
Al ejecutar LLM, puede interceptar el mensaje y la finalización (respuesta) de cada solicitud y transformarlos en incrustaciones utilizando un modelo de incrustación. Las incrustaciones son vectores de alta dimensión que representan el significado semántico del texto. Titán Amazonas proporciona dichos modelos a través de Titan Embeddings. Al tomar una distancia como el coseno entre estos dos vectores, puede cuantificar qué tan semánticamente similares son la indicación y la finalización (respuesta). Puedes usar Ciencia or scikit-aprender para calcular la distancia del coseno entre vectores. El siguiente diagrama ilustra la arquitectura de este módulo de computación métrica.
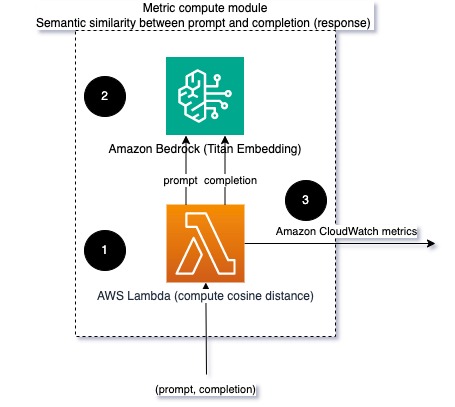
Fig 2: Módulo de cálculo métrico: similitud semántica
Este flujo de trabajo incluye los siguientes pasos clave:
- Una función Lambda recibe un mensaje transmitido a través de Kinesis amazónica que contiene un par de indicación y finalización (respuesta).
- La función obtiene una incrustación tanto para el mensaje como para la finalización (respuesta) y calcula la distancia del coseno entre los dos vectores.
- La función envía esa información a las métricas de CloudWatch.
Sentimiento y toxicidad
El seguimiento del sentimiento le permite medir el tono general y el impacto emocional de las respuestas, mientras que el análisis de toxicidad proporciona una medida importante de la presencia de lenguaje ofensivo, irrespetuoso o dañino en los resultados del LLM. Cualquier cambio en el sentimiento o la toxicidad debe ser monitoreado de cerca para garantizar que el modelo se esté comportando como se esperaba. El siguiente diagrama ilustra el módulo de cálculo métrico.

Fig. 3: Módulo de cálculo de métricas: sentimiento y toxicidad
El flujo de trabajo incluye los siguientes pasos:
- Una función Lambda recibe un par de aviso y finalización (respuesta) a través de Amazon Kinesis.
- A través de la orquestación de AWS Step Functions, la función llama Amazon Comprehend para detectar el sentimiento y toxicidad.
- La función guarda la información en las métricas de CloudWatch.
Para obtener más información sobre la detección de sentimientos y toxicidad con Amazon Comprehend, consulte Cree un predictor de toxicidad sólido basado en texto y Marcar contenido dañino mediante la detección de toxicidad de Amazon Comprehend.
Ratio de rechazos
Un aumento en las denegaciones, como cuando un LLM niega la finalización debido a falta de información, podría significar que usuarios malintencionados están tratando de utilizar el LLM de maneras destinadas a liberarlo, o que las expectativas de los usuarios no se están cumpliendo y están recibiendo respuestas de bajo valor. Una forma de medir la frecuencia con la que esto sucede es comparar las negativas estándar del modelo LLM que se utiliza con las respuestas reales del LLM. Por ejemplo, las siguientes son algunas de las frases de rechazo comunes de Claude v2 LLM de Anthropic:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Ante un conjunto fijo de indicaciones, un aumento en estas negativas puede ser una señal de que el modelo se ha vuelto demasiado cauteloso o sensible. También debe evaluarse el caso inverso. Podría ser una señal de que el modelo ahora es más propenso a entablar conversaciones tóxicas o dañinas.
Para ayudar a modelar la integridad y el índice de rechazo, podemos comparar la respuesta con un conjunto de frases de rechazo conocidas del LLM. Este podría ser un clasificador real que pueda explicar por qué el modelo rechazó la solicitud. Puede tomar la distancia del coseno entre la respuesta y las respuestas de rechazo conocidas del modelo que se está monitoreando. El siguiente diagrama ilustra este módulo de cálculo métrico.
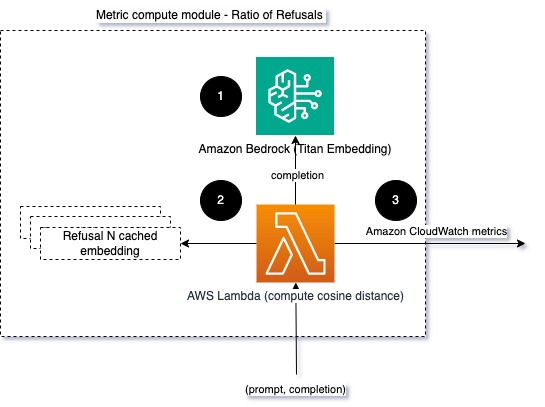
Fig. 4: Módulo de cálculo métrico: proporción de rechazos
El flujo de trabajo consta de los siguientes pasos:
- Una función Lambda recibe un mensaje y una finalización (respuesta) y obtiene una incrustación de la respuesta mediante Amazon Titan.
- La función calcula el coseno o la distancia euclidiana entre la respuesta y los mensajes de rechazo existentes almacenados en la memoria caché.
- La función envía ese promedio a las métricas de CloudWatch.
Otra opción es usar coincidencia difusa para un enfoque sencillo pero menos poderoso para comparar las negativas conocidas con la producción de LLM. Referirse a Documentación de Python para un ejemplo.
Resumen
La observabilidad de los LLM es una práctica crítica para garantizar el uso confiable y confiable de los LLM. Monitorear, comprender y garantizar la precisión y confiabilidad de los LLM puede ayudarlo a mitigar los riesgos asociados con estos modelos de IA. Al monitorear las alucinaciones, las malas terminaciones (respuestas) y las indicaciones, puede asegurarse de que su LLM se mantenga encaminado y brinde el valor que usted y sus usuarios están buscando. En esta publicación, analizamos algunas métricas para mostrar ejemplos.
Para obtener más información sobre la evaluación de modelos de cimentación, consulte Utilice SageMaker Clarify para evaluar modelos de cimientosy buscar más ejemplo cuadernos disponible en nuestro repositorio de GitHub. También puede explorar formas de poner en práctica las evaluaciones de LLM a escala en Ponga en funcionamiento la evaluación de LLM a escala utilizando los servicios Amazon SageMaker Clarify y MLOps. Finalmente recomendamos consultar Evaluar grandes modelos lingüísticos en cuanto a calidad y responsabilidad. para obtener más información sobre la evaluación de LLM.
Acerca de los autores
 bruno klein es ingeniero senior de aprendizaje automático con práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar soluciones de análisis y big data. Fuera del trabajo, le gusta pasar tiempo con la familia, viajar y probar comida nueva.
bruno klein es ingeniero senior de aprendizaje automático con práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar soluciones de análisis y big data. Fuera del trabajo, le gusta pasar tiempo con la familia, viajar y probar comida nueva.
 Rushabh Lokhande es ingeniero senior de datos y aprendizaje automático con práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar soluciones de análisis, aprendizaje automático y big data. Fuera del trabajo, le gusta pasar tiempo con la familia, leer, correr y jugar golf.
Rushabh Lokhande es ingeniero senior de datos y aprendizaje automático con práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar soluciones de análisis, aprendizaje automático y big data. Fuera del trabajo, le gusta pasar tiempo con la familia, leer, correr y jugar golf.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

