Los lagos de datos han ido ganando popularidad para almacenar grandes cantidades de datos de diversas fuentes de forma escalable y rentable. A medida que crece el número de consumidores de datos, los administradores del lago de datos a menudo necesitan implementar controles de acceso detallados para diferentes perfiles de usuario. Es posible que necesiten restringir el acceso a determinadas tablas o columnas según el tipo de usuario que realiza la solicitud. Además, a veces las empresas quieren que los datos estén disponibles para aplicaciones externas, pero no están seguras de cómo hacerlo de forma segura. Para abordar estos desafíos, las organizaciones pueden recurrir a GraphQL y Formación del lago AWS.
GraphQL proporciona una forma potente, segura y flexible de consultar y recuperar datos. Sincronización de aplicaciones de AWS es un servicio para crear API GraphQL que puede consultar múltiples bases de datos, microservicios y API desde un punto final GraphQL unificado.
Los administradores del lago de datos pueden utilizar Lake Formation para controlar el acceso a los lagos de datos. Lake Formation ofrece controles de acceso detallados para administrar permisos de usuarios y grupos a nivel de tabla, columna y celda. Por lo tanto, puede garantizar la seguridad y el cumplimiento de los datos. Además, este Lake Formation se integra con otros servicios de AWS, como Atenea amazónica, lo que lo hace ideal para consultar lagos de datos a través de API.
En esta publicación, demostramos cómo crear una aplicación que pueda extraer datos de un lago de datos a través de una API GraphQL y entregar los resultados a diferentes tipos de usuarios según sus privilegios de acceso a datos específicos. La aplicación de ejemplo descrita en esta publicación fue creada por un socio de AWS Tecnologías NETSOL.
Resumen de la solución
Nuestra solución utiliza Servicio de almacenamiento simple de Amazon (Amazon S3) para almacenar los datos, Pegamento AWS Data Catalog para albergar el esquema de los datos y Lake Formation para proporcionar gobernanza sobre los objetos de AWS Glue Data Catalog mediante la implementación de acceso basado en roles. También usamos Puente de eventos de Amazon para capturar eventos en nuestro lago de datos y lanzar procesos posteriores. La arquitectura de la solución se muestra en el siguiente diagrama.
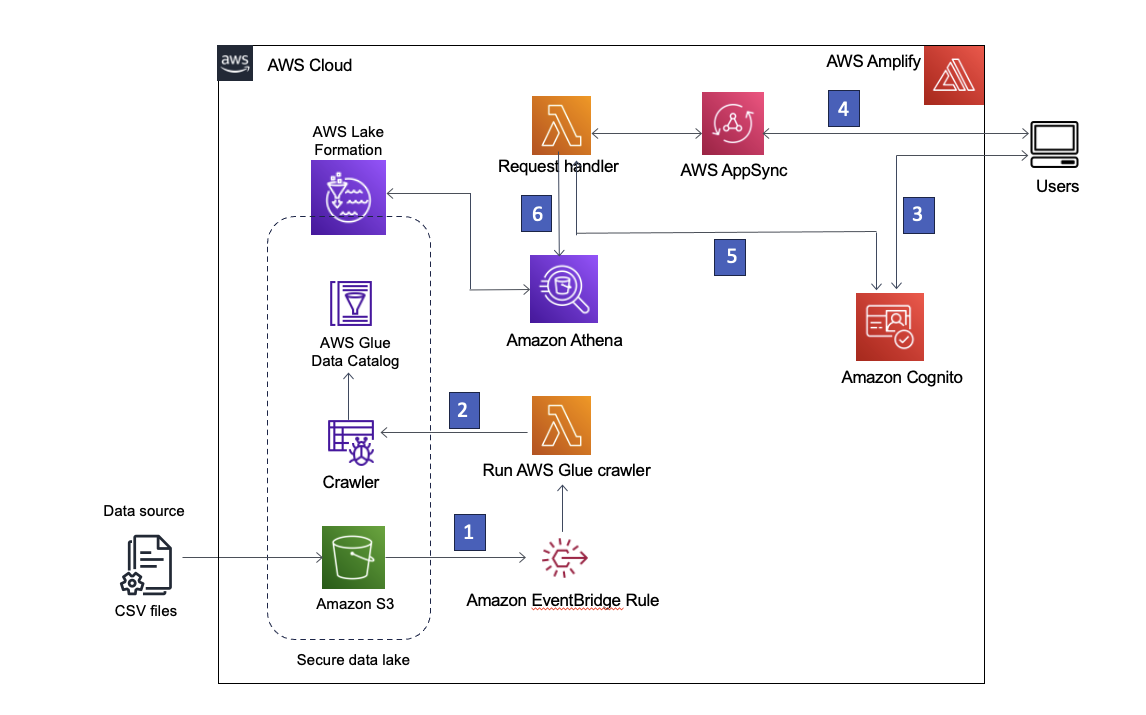
Figura 1 – Arquitectura de la solución
La siguiente es una descripción paso a paso de la solución:
- El lago de datos se crea en un depósito de S3 registrado en Lake Formation. Cada vez que llegan nuevos datos, se invoca una regla de EventBridge.
- La regla EventBridge ejecuta una AWS Lambda función para iniciar un rastreador de AWS Glue para descubrir nuevos datos y actualizar cualquier cambio en el esquema para que se puedan consultar los datos más recientes.
Nota: Los rastreadores de AWS Glue también se pueden iniciar directamente desde eventos de Amazon S3, como se describe en este del blog. - AWS amplificar permite a los usuarios iniciar sesión usando Cognito Amazonas como proveedor de identidad. Cognito autentica las credenciales del usuario y devuelve tokens de acceso.
- Los usuarios autenticados invocan una API GraphQL de AWS AppSync a través de Amplify, obteniendo datos del lago de datos. Se ejecuta una función Lambda para manejar la solicitud.
- La función Lambda recupera los detalles del usuario de Cognito y asume la Administración de acceso e identidad de AWS (IAM) rol asociado con el grupo de usuarios de Cognito del usuario solicitante.
- Luego, la función Lambda ejecuta una consulta de Athena en las tablas del lago de datos y devuelve los resultados a AWS AppSync, que luego devuelve los resultados al usuario.
Requisitos previos
Para implementar esta solución, primero debe hacer lo siguiente:
Preparar permisos de formación de lagos
Inicia sesión en el Consola LakeFormation y agréguese como administrador. Si inicia sesión en Lake Formation por primera vez, puede hacerlo seleccionando Agregarme en la pantalla Bienvenido a Lake Formation y eligiendo Comenzar como se muestra en la Figura 2.

Figura 2: Agréguese como administrador de Lake Formation
De lo contrario, puede elegir funciones y tareas administrativas en la barra de navegación izquierda y elegir Administrar administradores para agregarse. Debería ver su nombre de usuario de IAM en Administradores del lago de datos con acceso completo cuando haya terminado.
Seleccione Configuración del catálogo de datos en la barra de navegación izquierda y asegúrese de que las dos casillas de control de acceso de IAM no estén seleccionadas, como se muestra en la Figura 3. Quiere que Lake Formation, no IAM, controle el acceso a nuevas bases de datos.
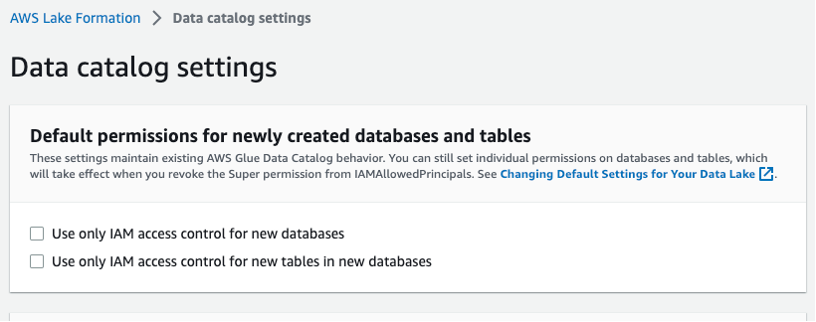
Figura 3 – Configuración del catálogo de datos de Lake Formation
Implementar la solución
Para crear la solución en su entorno de AWS, inicie la siguiente pila de AWS CloudFormation: ![]()
Los siguientes recursos se lanzarán a través de la plantilla de CloudFormation:
- Amazon VPC y componentes de red (subredes, grupos de seguridad y puerta de enlace NAT)
- IAM roles
- Lake Formation encapsula el depósito S3, el rastreador de AWS Glue y la base de datos de AWS Glue
- Funciones lambda
- Grupo de usuarios de Cognito
- API GraphQL de AWS AppSync
- Reglas de EventBridge
Una vez que se hayan implementado los recursos necesarios desde la pila de CloudFormation, debe crear dos funciones Lambda y cargar el conjunto de datos en Amazon S3. Lake Formation gobernará el lago de datos que se almacena en el depósito de S3.
Crear las funciones Lambda
Cada vez que se coloca un archivo nuevo en el depósito S3 designado, se invoca una regla de EventBridge, que inicia una función Lambda para iniciar el rastreador de AWS Glue. El rastreador actualiza el catálogo de datos de AWS Glue para reflejar cualquier cambio en el esquema.
Cuando la aplicación realiza una consulta de datos a través de la API GraphQL, se invoca una función Lambda del controlador de solicitudes para procesar la consulta y devolver los resultados.
Para crear estas dos funciones Lambda, proceda de la siguiente manera.
- Inicie sesión en la consola Lambda.
- Seleccione la función Lambda del controlador de solicitudes denominada
dl-dev-crawlerLambdaFunction. - Busque el archivo de función Lambda del rastreador en su
lambdas/crawler-lambdacarpeta en el repositorio de git que clonaste en tu máquina local. - Copie y pegue el código de ese archivo en la sección Código del
dl-dev-crawlerLambdaFunctionen su consola Lambda. Luego elija Implementar para implementar la función.
Figura 4: copiar y pegar código en la función Lambda
- Repita los pasos 2 a 4 para la función del controlador de solicitudes denominada
dl-dev-requestHandlerLambdaFunctionusando el código enlambdas/request-handler-lambda.
Cree una capa para el controlador de solicitudes Lambda
Ahora debe cargar algún código de biblioteca adicional que necesita la función Lambda del controlador de solicitudes.
- Seleccione capas en el menú de la izquierda y elija Crear capa.
- Introduzca un nombre como
appsync-lambda-layer. - Descargar archivo ZIP de capa de paquete a su máquina local.
- Cargue el archivo ZIP usando el Subir botón de la Crear capa .
- Elige 3.7 Python como tiempo de ejecución de la capa.
- Elige Crear.
- Seleccione Clave en el menú de la izquierda y seleccione el
dl-dev-requestHandlerFunción lambda. - Desplázate hacia abajo hasta capas sección y elegir Agregar una capa.
- Seleccione Capas personalizadas y luego seleccione la capa que creó anteriormente.
- Haga Clic en Añada.
Cargue los datos a Amazon S3
Navegue hasta el directorio raíz del repositorio git clonado y ejecute los siguientes comandos para cargar el conjunto de datos de muestra. Reemplace la bucket_name marcador de posición con el depósito de S3 aprovisionado mediante la plantilla de CloudFormation. Puede obtener el nombre del depósito desde la consola de CloudFormation yendo a Salidas pestaña con llave datalakes3bucketNombre como se muestra en la imagen de abajo.

Figura 5: nombre del depósito de S3 que se muestra en la pestaña Salidas de CloudFormation
Ingrese los siguientes comandos en la carpeta de su proyecto en su máquina local para cargar el conjunto de datos en el depósito S3.
Ahora echemos un vistazo a los artefactos desplegados.
Lago de datos
El depósito S3 contiene datos de muestra para dos entidades: empresas y sus respectivos propietarios. El depósito está registrado con Lake Formation, como se muestra en la Figura 6. Esto permite a Lake Formation crear y administrar catálogos de datos y administrar permisos sobre los datos.

Figura 6: Consola de Lake Formation que muestra la ubicación del lago de datos
Se crea una base de datos para contener el esquema de datos presentes en Amazon S3. Se utiliza un rastreador de AWS Glue para actualizar cualquier cambio en el esquema en el depósito de S3. A este rastreador se le concede permiso para CREAR, ALTERAR y BORRAR tablas en la base de datos mediante Lake Formation.
Aplicar controles de acceso al lago de datos
Se crean dos roles de IAM, dl-us-east-1-developer y dl-us-east-1-business-analyst, cada uno asignado a un grupo de usuarios de Cognito diferente. A cada rol se le asignan diferentes autorizaciones a través de Lake Formation. La función de desarrollador obtiene acceso a todas las columnas del lago de datos, mientras que la función de analista de negocios solo tiene acceso a las columnas de información de identificación no personal (PII).
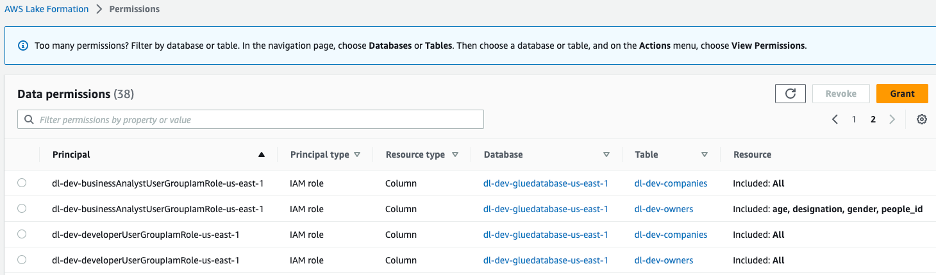
Figura 7: Permisos del lago de datos de la consola de Lake Formation asignados a roles de grupo
Esquema GraphQL
La API GraphQL se puede ver desde la consola de AWS AppSync. El Companies El tipo incluye varios atributos que describen a los propietarios de las empresas.
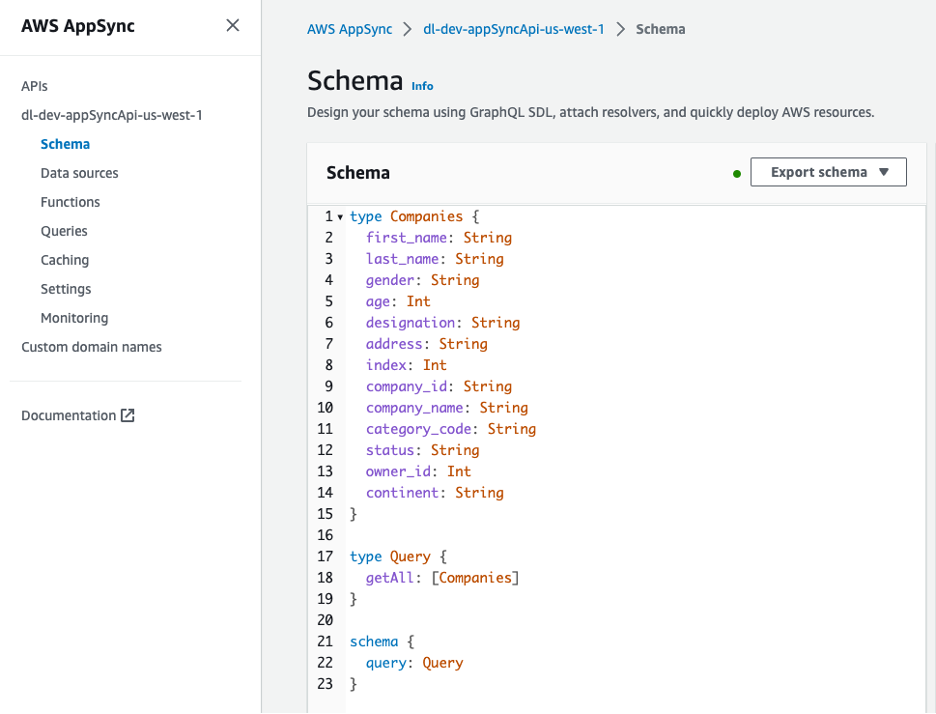
Figura 8: Esquema de la API GraphQL
La fuente de datos de la API GraphQL es una función Lambda, que maneja las solicitudes.
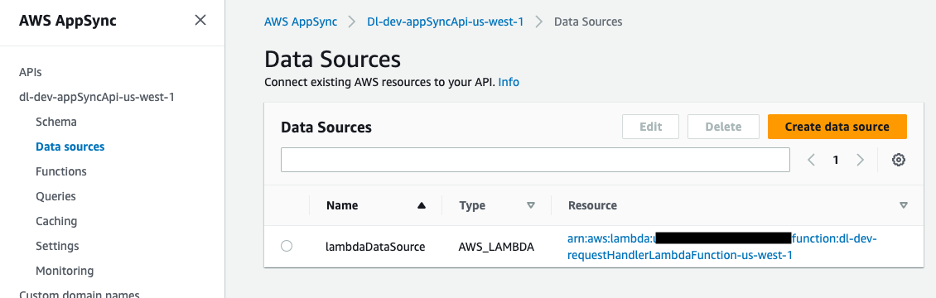
Figura 9: fuente de datos de AWS AppSync asignada a la función Lambda
Manejo de las solicitudes de la API GraphQL
La función Lambda del controlador de solicitudes de la API GraphQL recupera el ID del grupo de usuarios de Cognito de las variables de entorno. Usando la biblioteca boto3, crea un cliente Cognito y usa el get_group Método para obtener el rol de IAM asociado al grupo de usuarios de Cognito.
Utilice una función auxiliar en la función Lambda para obtener el rol.
Usando el Servicio de token de seguridad de AWS (AWS STS) A través de un cliente boto3, puede asumir el rol de IAM y obtener las credenciales temporales que necesita para ejecutar la consulta de Athena.
Pasamos las credenciales temporales como parámetros al crear nuestro cliente Boto3 Amazon Athena.
athena_client = boto3.client('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)El cliente y la consulta se pasan a nuestra función auxiliar de consulta de Athena, que ejecuta la consulta y devuelve una identificación de consulta. Con la identificación de la consulta, podemos leer los resultados de S3 y agruparlos como un diccionario de Python para devolverlos en la respuesta.
Habilitar el acceso del lado del cliente al lago de datos
Del lado del cliente, AWS Amplify está configurado con un grupo de usuarios de Amazon Cognito para la autenticación. Navegaremos a la consola de Amazon Cognito para ver el grupo de usuarios y los grupos que se crearon.
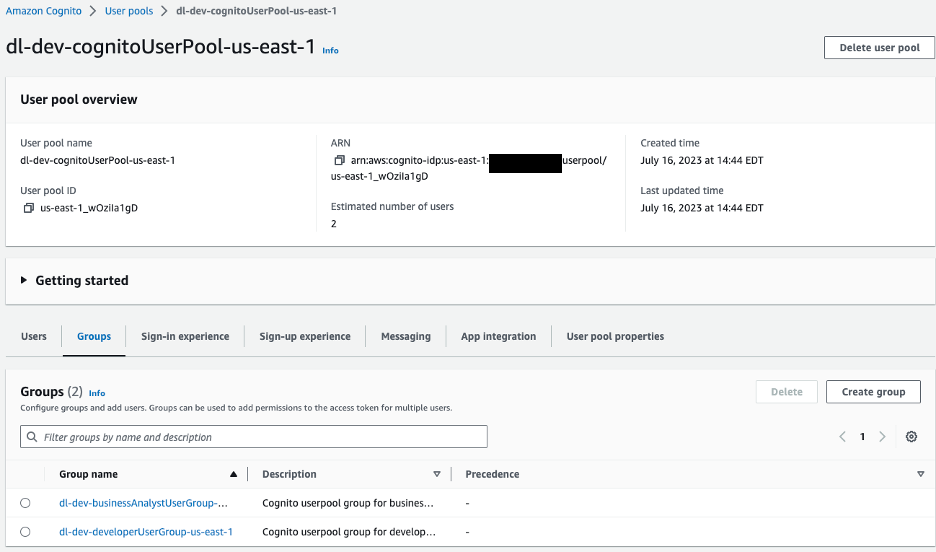
Figura 10: Grupos de usuarios de Amazon Cognito
Para nuestra aplicación de muestra tenemos dos grupos en nuestro grupo de usuarios:
dl-dev-businessAnalystUserGroup– Analistas de negocios con permisos limitados.dl-dev-developerUserGroup– Desarrolladores con permisos completos.
Si explora estos grupos, verá una función de IAM asociada a cada uno. Este es el rol de IAM que se asigna al usuario cuando se autentica. Athena asume este rol al consultar el lago de datos.
Si ve los permisos para esta función de IAM, notará que no incluye controles de acceso debajo del nivel de la tabla. Necesita la capa adicional de gobernanza proporcionada por Lake Formation para agregar un control de acceso detallado.
Una vez que Cognito verifica y autentica al usuario, Amplify utiliza tokens de acceso para invocar la API GraphQL de AWS AppSync y recuperar los datos. Según el grupo de usuarios, una función Lambda asume el rol correspondiente del grupo de usuarios de Cognito. Utilizando el rol asumido, se ejecuta una consulta de Athena y el resultado se devuelve al usuario.
Crear usuarios de prueba
Cree dos usuarios, uno para desarrolladores y otro para analistas de negocios, y agréguelos a grupos de usuarios.
- Navegue a Cognito y seleccione el grupo de usuarios.
dl-dev-cognitoUserPool, eso se crea. - Elige Crear usuario y proporcione los detalles para crear un nuevo usuario analista de negocios. El nombre de usuario puede ser analista de negocios. Deje la dirección de correo electrónico en blanco e ingrese una contraseña.
- Seleccione Usuarios y seleccione el usuario que acaba de crear.
- Agregue este usuario al grupo de analistas de negocios eligiendo la opción Agregar usuario al grupo del botón.
- Sigue los mismos pasos para crear otro usuario con el nombre de usuario revelador y agregue el usuario al grupo de desarrolladores.
Prueba la solución
Para probar su solución, inicie la aplicación React en su máquina local.
- En el directorio del proyecto clonado, navegue hasta el
react-appdirectorio. - Instale las dependencias del proyecto.
- Instale la CLI de amplificación:
- Crea un nuevo archivo llamado
.envejecutando los siguientes comandos. Luego use un editor de texto para actualizar los valores de las variables de entorno en el archivo.
Ingrese al Salidas pestaña de la pila de su consola CloudFormation para obtener los valores requeridos de las claves de la siguiente manera:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- Agregue las variables anteriores a su entorno.
- Genere el código necesario para interactuar con la API usando Amplificar CodeGen. En la pestaña Salidas de su consola de Cloudformation, busque su ID de API de AWS Appsync junto al
appsyncApiIdclave.
Acepte todas las opciones predeterminadas para el comando anterior presionando Participar en cada indicación.
- Inicie la aplicación.
Puede confirmar que la aplicación se está ejecutando visitando http://localhost:3000 e iniciar sesión como el usuario desarrollador que creó anteriormente.
Ahora que tiene la aplicación en ejecución, echemos un vistazo a cómo se cumple cada función desde el companies punto final
Primero, firme como rol de desarrollador, que tiene acceso a todos los campos, y realice la solicitud de API al punto final de la empresa. Tenga en cuenta a qué campos tiene acceso.
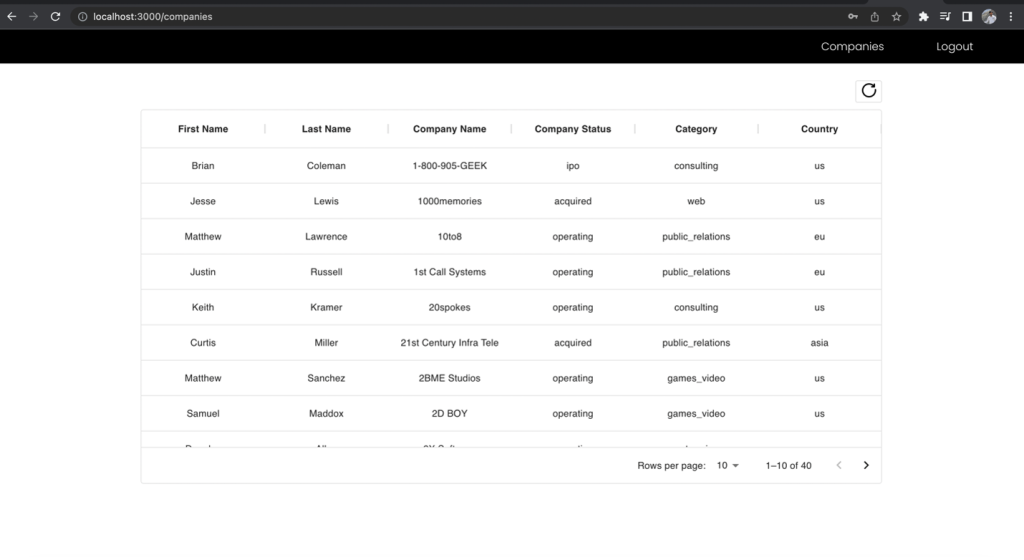
Figura 11: Resultados para el rol de desarrollador
Ahora, inicie sesión como usuario analista de negocios, realice la solicitud al mismo punto final y compare los campos incluidos.
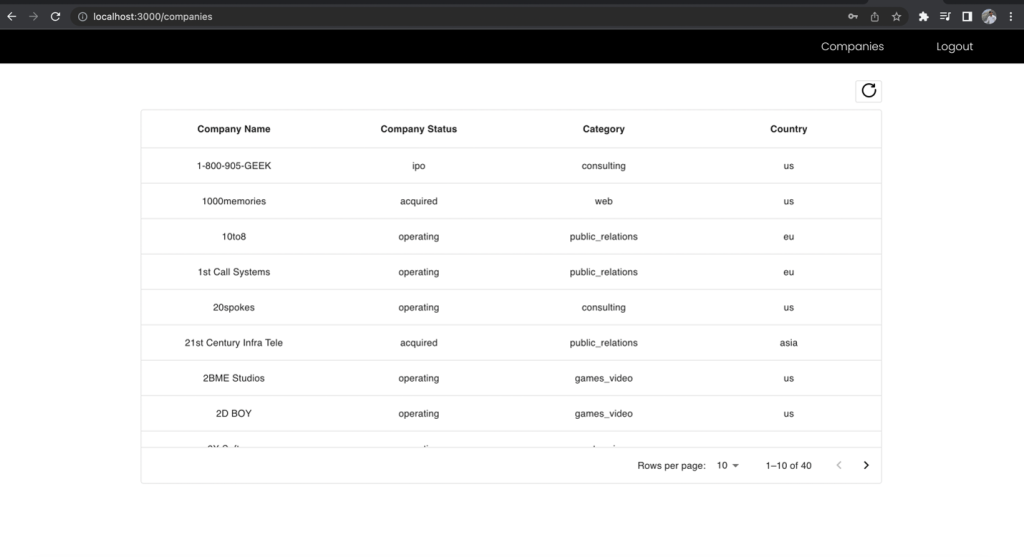
Figura 12: Resultados para el rol de Analista de Negocios
Las columnas Nombre y Apellido de la lista de empresas se excluyen de la vista de analista de negocios aunque haya realizado la solicitud al mismo punto final. Esto demuestra el poder de usar un punto final GraphQL unificado junto con múltiples roles de IAM de grupos de usuarios de Cognito asignados a permisos de Lake Formation para administrar el acceso basado en roles a sus datos.
Limpiar
Una vez que haya terminado de probar la solución, limpie los siguientes recursos para evitar incurrir en cargos futuros:
- Vacíe los depósitos de S3 creados por la plantilla de CloudFormation.
- Elimine la pila de CloudFormation para eliminar los depósitos de S3 y otros recursos.
Conclusión
En esta publicación, le mostramos cómo entregar datos de forma segura en un lago de datos a usuarios autenticados de una aplicación React en función de sus privilegios de acceso basados en roles. Para lograr esto, utilizó las API GraphQL en AWS AppSync, controles de acceso detallados de Lake Formation y Cognito para autenticar usuarios por grupo y asignarlos a roles de IAM. También usaste Athena para consultar los datos.
Para lecturas relacionadas sobre este tema, consulte Visualización de big data con AWS AppSync, Amazon Athena y AWS Amplify y Diseñe una arquitectura de malla de datos con AWS Lake Formation y AWS Glue.
¿Implementará este enfoque para ofrecer datos desde su lago de datos? ¡Háganos saber en los comentarios!
Acerca de los autores
 Rana Dutt es arquitecto principal de soluciones en Amazon Web Services. Tiene experiencia en la arquitectura de plataformas de software escalables para empresas de servicios financieros, atención médica y telecomunicaciones, y le apasiona ayudar a los clientes a desarrollar AWS.
Rana Dutt es arquitecto principal de soluciones en Amazon Web Services. Tiene experiencia en la arquitectura de plataformas de software escalables para empresas de servicios financieros, atención médica y telecomunicaciones, y le apasiona ayudar a los clientes a desarrollar AWS.
 Ranjith Rayaprolu es arquitecto senior de soluciones en AWS y trabaja con clientes en el noroeste del Pacífico. Ayuda a los clientes a diseñar y operar soluciones de buena arquitectura en AWS que abordan sus problemas comerciales y aceleran la adopción de los servicios de AWS. Se centra en las tecnologías de redes y seguridad de AWS para desarrollar soluciones en la nube en diferentes sectores verticales de la industria. Ranjith vive en el área de Seattle y le encantan las actividades al aire libre.
Ranjith Rayaprolu es arquitecto senior de soluciones en AWS y trabaja con clientes en el noroeste del Pacífico. Ayuda a los clientes a diseñar y operar soluciones de buena arquitectura en AWS que abordan sus problemas comerciales y aceleran la adopción de los servicios de AWS. Se centra en las tecnologías de redes y seguridad de AWS para desarrollar soluciones en la nube en diferentes sectores verticales de la industria. Ranjith vive en el área de Seattle y le encantan las actividades al aire libre.
 justin leto es arquitecto senior de soluciones en Amazon Web Services con especialización en bases de datos, análisis de big data y aprendizaje automático. Su pasión es ayudar a los clientes a lograr una mejor adopción de la nube. En su tiempo libre le gusta navegar en alta mar y tocar el piano de jazz. Vive en la ciudad de Nueva York con su esposa y su hija pequeña.
justin leto es arquitecto senior de soluciones en Amazon Web Services con especialización en bases de datos, análisis de big data y aprendizaje automático. Su pasión es ayudar a los clientes a lograr una mejor adopción de la nube. En su tiempo libre le gusta navegar en alta mar y tocar el piano de jazz. Vive en la ciudad de Nueva York con su esposa y su hija pequeña.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/using-aws-appsync-and-aws-lake-formation-to-access-a-secure-data-lake-through-a-graphql-api/

