Corporación KT es uno de los proveedores de telecomunicaciones más grandes de Corea del Sur y ofrece una amplia gama de servicios que incluyen telefonía fija, comunicaciones móviles, Internet y servicios de inteligencia artificial. AI Food Tag de KT es una solución de gestión dietética basada en IA que identifica el tipo y el contenido nutricional de los alimentos en fotografías utilizando un modelo de visión por computadora. Este modelo de visión desarrollado por KT se basa en un modelo previamente entrenado con una gran cantidad de datos de imágenes sin etiquetar para analizar el contenido nutricional y la información calórica de varios alimentos. La AI Food Tag puede ayudar a los pacientes con enfermedades crónicas como la diabetes a controlar su dieta. KT utilizó AWS y Amazon SageMaker entrenar este modelo AI Food Tag 29 veces más rápido que antes y optimizarlo para la implementación de producción con una técnica de destilación de modelos. En esta publicación, describimos el viaje de desarrollo de modelos de KT y su éxito con SageMaker.
Presentación del proyecto KT y definición del problema.
El modelo AI Food Tag previamente entrenado por KT se basa en la arquitectura de transformadores de visión (ViT) y tiene más parámetros de modelo que su modelo de visión anterior para mejorar la precisión. Para reducir el tamaño del modelo para la producción, KT está utilizando una técnica de destilación de conocimientos (KD) para reducir la cantidad de parámetros del modelo sin un impacto significativo en la precisión. Con la destilación del conocimiento, el modelo previamente entrenado se llama modelo de maestroy se entrena un modelo de salida ligero como modelo de estudiante, como se ilustra en la siguiente figura. El modelo ligero de estudiante tiene menos parámetros de modelo que el de profesor, lo que reduce los requisitos de memoria y permite la implementación en instancias más pequeñas y menos costosas. El estudiante mantiene una precisión aceptable aunque sea más pequeña al aprender de los resultados del modelo del maestro.

El modelo de profesor permanece sin cambios durante KD, pero el modelo de estudiante se entrena utilizando los logits de salida del modelo de profesor como etiquetas para calcular la pérdida. Con este paradigma KD, tanto el profesor como el alumno necesitan estar en una única memoria GPU para realizar el entrenamiento. Inicialmente, KT utilizó dos GPU (A100 de 80 GB) en su entorno interno local para entrenar el modelo de estudiante, pero el proceso tardó unos 40 días en cubrir 300 épocas. Para acelerar la formación y generar un modelo de estudiante en menos tiempo, KT se asoció con AWS. Juntos, los equipos redujeron significativamente el tiempo de formación del modelo. Esta publicación describe cómo el equipo usó Capacitación de Amazon SageMaker, el Biblioteca de paralelismo de datos de SageMaker, Depurador de Amazon SageMakery Perfilador de Amazon SageMaker para desarrollar con éxito un modelo ligero de etiqueta de alimentos AI.
Creación de un entorno de formación distribuido con SageMaker
SageMaker Training es un entorno de capacitación de aprendizaje automático (ML) administrado en AWS que proporciona un conjunto de características y herramientas para simplificar la experiencia de capacitación y puede resultar útil en la informática distribuida, como se ilustra en el siguiente diagrama.
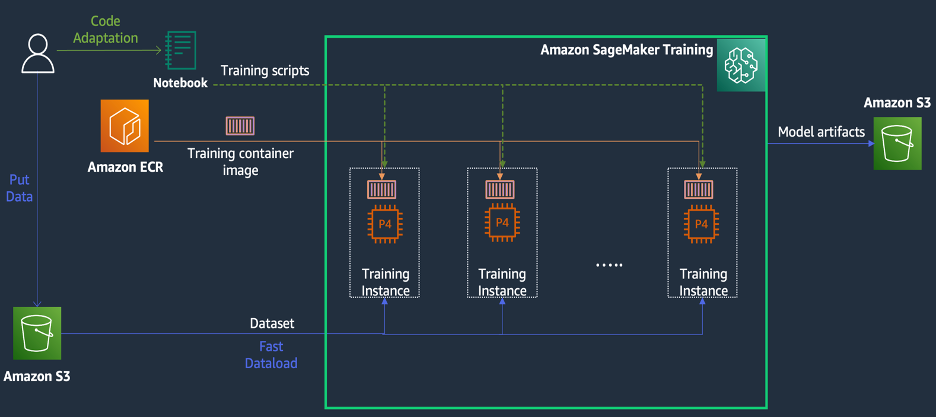
Los clientes de SageMaker también pueden acceder a imágenes de Docker integradas con varios marcos de aprendizaje profundo preinstalados y los paquetes necesarios de Linux, NCCL y Python para la capacitación de modelos. Los científicos de datos o los ingenieros de ML que quieran ejecutar la capacitación de modelos pueden hacerlo sin la carga de configurar la infraestructura de capacitación o administrar Docker y la compatibilidad de diferentes bibliotecas.
Durante un taller de 1 día, pudimos establecer una configuración de capacitación distribuida basada en SageMaker dentro de la cuenta AWS de KT, acelerar los scripts de capacitación de KT usando la biblioteca de datos distribuidos paralelos (DDP) de SageMaker e incluso probar un trabajo de capacitación usando dos ml. p4d.24xinstancias grandes. En esta sección, describimos la experiencia de KT trabajando con el equipo de AWS y utilizando SageMaker para desarrollar su modelo.
En la prueba de concepto, queríamos acelerar un trabajo de capacitación utilizando la biblioteca DDP de SageMaker, que está optimizada para la infraestructura de AWS durante la capacitación distribuida. Para cambiar de PyTorch DDP a SageMaker DDP, simplemente necesita declarar el torch_smddp paquete y cambiar el backend a smddp, como se muestra en el siguiente código:
Para obtener más información sobre la biblioteca DDP de SageMaker, consulte Biblioteca de paralelismo de datos de SageMaker.
Análisis de las causas de la velocidad de entrenamiento lenta con SageMaker Debugger and Profiler
El primer paso para optimizar y acelerar una carga de trabajo de capacitación implica comprender y diagnosticar dónde se producen los cuellos de botella. Para el trabajo de entrenamiento de KT, medimos el tiempo de entrenamiento por iteración del cargador de datos, paso hacia adelante y paso hacia atrás:
| Tiempo de 1 iter – cargador de datos: 0.00053 s, adelante: 7.77474 s, atrás: 1.58002 AMF |
| Tiempo de 2 iter – cargador de datos: 0.00063 s, adelante: 0.67429 s, atrás: 24.74539 AMF |
| Tiempo de 3 iter – cargador de datos: 0.00061 s, adelante: 0.90976 s, atrás: 8.31253 AMF |
| Tiempo de 4 iter – cargador de datos: 0.00060 s, adelante: 0.60958 s, atrás: 30.93830 AMF |
| Tiempo de 5 iter – cargador de datos: 0.00080 s, adelante: 0.83237 s, atrás: 8.41030 AMF |
| Tiempo de 6 iter – cargador de datos: 0.00067 s, adelante: 0.75715 s, atrás: 29.88415 AMF |
Al observar el tiempo en la salida estándar para cada iteración, vimos que el tiempo de ejecución del paso hacia atrás fluctuó significativamente de una iteración a otra. Esta variación es inusual y puede afectar el tiempo total de entrenamiento. Para encontrar la causa de esta velocidad de entrenamiento inconsistente, primero intentamos identificar cuellos de botella de recursos utilizando el Monitor del sistema (UI de SageMaker Debugger), que le permite depurar trabajos de entrenamiento en SageMaker Training y ver el estado de recursos como los de la plataforma de entrenamiento administrada. CPU, GPU, red y E/S en un número determinado de segundos.
La interfaz de usuario de SageMaker Debugger proporciona datos detallados y esenciales que pueden ayudar a identificar y diagnosticar cuellos de botella en un trabajo de capacitación. Específicamente, nos llamó la atención el gráfico de líneas de utilización de CPU y las tablas del mapa de calor de utilización de CPU/GPU por instancia.
En el gráfico de líneas de utilización de CPU, notamos que algunas CPU se estaban utilizando al 100 %.
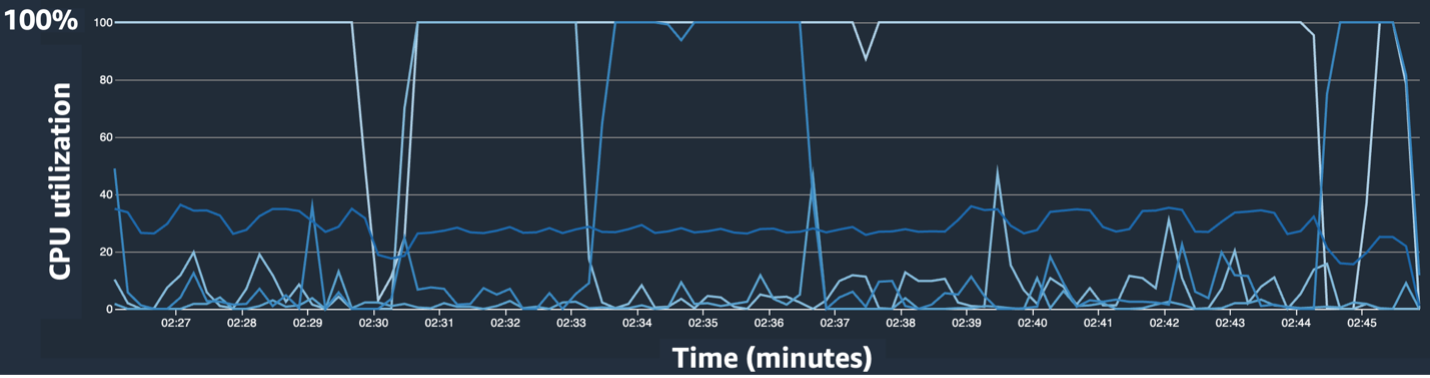
En el mapa de calor (donde los colores más oscuros indican una mayor utilización), notamos que algunos núcleos de CPU tuvieron una alta utilización durante todo el entrenamiento, mientras que la utilización de GPU no fue consistentemente alta a lo largo del tiempo.

A partir de aquí, comenzamos a sospechar que una de las razones de la baja velocidad de entrenamiento era un cuello de botella en la CPU. Revisamos el código del script de entrenamiento para ver si algo estaba causando el cuello de botella de la CPU. La parte más sospechosa fue el gran valor de num_workers en el cargador de datos, por lo que cambiamos este valor a 0 o 1 para reducir la utilización de la CPU. Luego ejecutamos nuevamente el trabajo de capacitación y verificamos los resultados.
Las siguientes capturas de pantalla muestran el gráfico de líneas de utilización de la CPU, la utilización de la GPU y el mapa de calor después de mitigar el cuello de botella de la CPU.
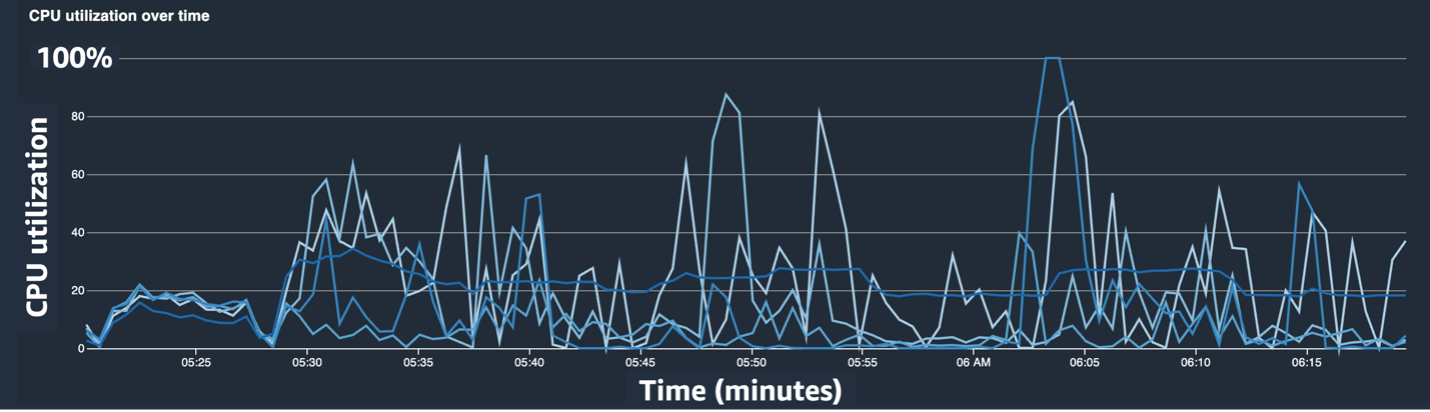


Simplemente cambiando num_workers, vimos una disminución significativa en la utilización de la CPU y un aumento general en la utilización de la GPU. Este fue un cambio importante que mejoró significativamente la velocidad de entrenamiento. Aun así, queríamos ver dónde podíamos optimizar la utilización de la GPU. Para ello, utilizamos SageMaker Profiler.
SageMaker Profiler ayuda a identificar pistas de optimización al brindar visibilidad de la utilización por operaciones, incluido el seguimiento de las métricas de utilización de GPU y CPU y el consumo del kernel de GPU/CPU dentro de los scripts de entrenamiento. Ayuda a los usuarios a comprender qué operaciones consumen recursos. Primero, para usar SageMaker Profiler, debe agregar ProfilerConfig a la función que invoca el trabajo de entrenamiento usando el SDK de SageMaker, como se muestra en el siguiente código:
En SageMaker Python SDK, tiene la flexibilidad de agregar el annotate funciones para que SageMaker Profiler seleccione código o pasos en el script de capacitación que necesitan creación de perfiles. El siguiente es un ejemplo del código que debe declarar para SageMaker Profiler en los scripts de capacitación:
Después de agregar el código anterior, si ejecuta un trabajo de entrenamiento usando los scripts de entrenamiento, puede obtener información sobre las operaciones consumidas por el kernel de GPU (como se muestra en la siguiente figura) después de que el entrenamiento se ejecute durante un período de tiempo. En el caso de los scripts de entrenamiento de KT, los ejecutamos durante una época y obtuvimos los siguientes resultados.
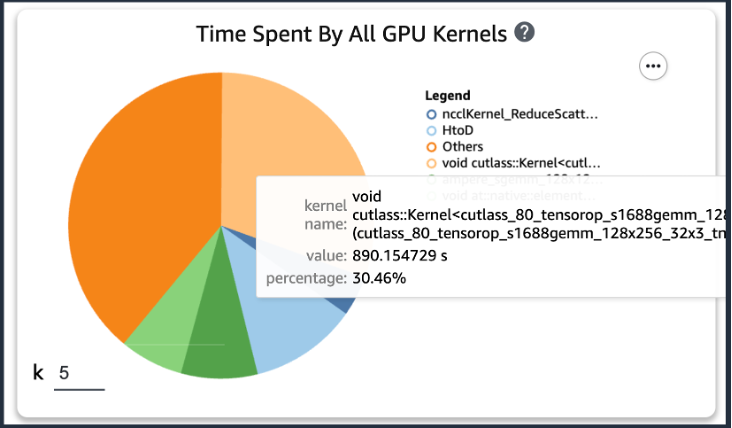
Cuando verificamos los cinco tiempos de consumo de operaciones principales del kernel de GPU entre los resultados de SageMaker Profiler, encontramos que para el script de entrenamiento KT, la operación del producto matricial consume la mayor parte del tiempo, que es una operación de multiplicación de matrices general (GEMM). en GPU. Con esta importante información de SageMaker Profiler, comenzamos a investigar formas de acelerar estas operaciones y mejorar la utilización de la GPU.
Acelerar el tiempo de entrenamiento
Revisamos varias formas de reducir el tiempo de cálculo de la multiplicación de matrices y aplicamos dos funciones de PyTorch.
Estados del optimizador de fragmentos con ZeroRedundancyOptimizer
Si nos fijamos en el Optimizador de redundancia cero (ZeRO), la técnica DeepSpeed/ZeRO permite entrenar un modelo grande de manera eficiente con una mejor velocidad de entrenamiento al eliminar las redundancias en la memoria utilizada por el modelo. Optimizador de redundancia cero en PyTorch utiliza la técnica de fragmentar el estado del optimizador para reducir el uso de memoria por proceso en datos distribuidos en paralelo (DDP). DDP utiliza gradientes sincronizados en el paso hacia atrás para que todas las réplicas del optimizador iteren sobre los mismos parámetros y valores de gradiente, pero en lugar de tener todos los parámetros del modelo, cada estado del optimizador se mantiene fragmentando solo para diferentes procesos DDP para reducir el uso de memoria.
Para usarlo, puede dejar su Optimizador existente en optimizer_class y declarar un ZeroRedundancyOptimizer con el resto de parámetros del modelo y la tasa de aprendizaje como parámetros.
Precisión mixta automática
Precisión mixta automática (AMP) utiliza el tipo de datos torch.float32 para algunas operaciones y antorcha.bfloat16 o torch.float16 para otros, por la conveniencia de un cálculo rápido y un uso reducido de memoria. En particular, debido a que los modelos de aprendizaje profundo suelen ser más sensibles a los bits exponentes que a los bits fraccionarios en sus cálculos, torch.bfloat16 es equivalente a los bits exponentes de torch.float32, lo que les permite aprender rápidamente con una pérdida mínima. torch.bfloat16 solo se ejecuta en instancias con arquitectura NVIDIA A100 (Ampere) o superior, como ml.p4d.24xlarge, ml.p4de.24xlarge y ml.p5.48xlarge.
Para aplicar AMP, puedes declarar torch.cuda.amp.autocast en los scripts de entrenamiento como se muestra en el código anterior y declarar dtype como torch.bfloat16.
Resultados en SageMaker Profiler
Después de aplicar las dos funciones a los scripts de entrenamiento y ejecutar nuevamente un trabajo de entrenamiento durante una época, verificamos los cinco tiempos de consumo de operaciones principales para el kernel de GPU en SageMaker Profiler. La siguiente figura muestra nuestros resultados.
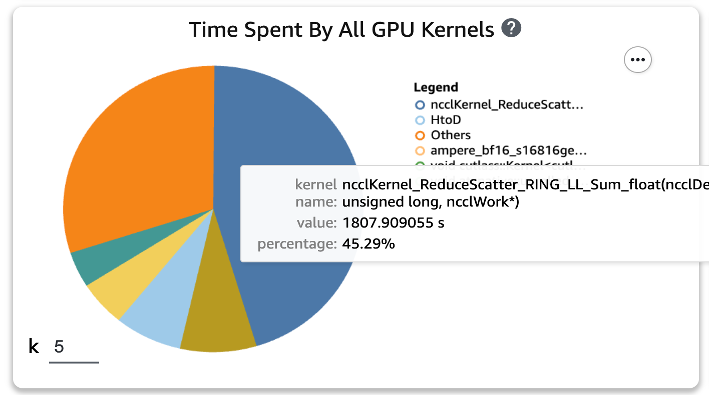
Podemos ver que la operación GEMM, que estaba en la parte superior de la lista antes de aplicar las dos funciones de Torch, ha desaparecido de las cinco operaciones principales, reemplazada por la operación ReduceScatter, que normalmente ocurre en el entrenamiento distribuido.
Resultados de velocidad de entrenamiento del modelo destilado KT
Aumentamos el tamaño del lote de entrenamiento en 128 más para tener en cuenta el ahorro de memoria al aplicar las dos funciones de Torch, lo que resultó en un tamaño de lote final de 1152 en lugar de 1024. El entrenamiento del modelo de estudiante final pudo ejecutar 210 épocas por 1 día. ; El tiempo de entrenamiento y la aceleración entre el entorno de entrenamiento interno de KT y SageMaker se resumen en la siguiente tabla.
| Medio Ambiente Formación | Especificaciones de GPU de entrenamiento. | Número de GPU | Tiempo de entrenamiento (horas) | Epoch | Horas por época | Relación de reducción |
| El entorno de formación interno de KT | A100 (80 GB) | 2 | 960 | 300 | 3.20 | 29 |
| Amazon SageMaker | A100 (40 GB) | 32 | 24 | 210 | 0.11 | 1 |
La escalabilidad de AWS nos permitió completar el trabajo de capacitación 29 veces más rápido que antes usando 32 GPU en lugar de 2 en las instalaciones. Como resultado, usar más GPU en SageMaker habría reducido significativamente el tiempo de capacitación sin diferencia en los costos generales de capacitación.
Conclusión
Park Sang-min (líder del equipo de tecnología de servicio de Vision AI) del laboratorio AI2XL en el centro de tecnología de convergencia de KT comentó sobre la colaboración con AWS para desarrollar el modelo AI Food Tag:
“Recientemente, a medida que hay más modelos basados en transformadores en el campo de visión, los parámetros del modelo y la memoria GPU requerida están aumentando. Estamos utilizando tecnología liviana para resolver este problema y lleva mucho tiempo, aproximadamente un mes, aprender una vez. A través de esta PoC con AWS, pudimos identificar los cuellos de botella de recursos con la ayuda de SageMaker Profiler y Debugger, resolverlos y luego usar la biblioteca de paralelismo de datos de SageMaker para completar la capacitación en aproximadamente un día con código de modelo optimizado en cuatro ml.p4d. 24 instancias grandes”.
SageMaker ayudó al equipo de Sang-min a ahorrar semanas de tiempo en capacitación y desarrollo de modelos.
Sobre la base de esta colaboración en el modelo de visión, AWS y el equipo de SageMaker continuarán colaborando con KT en varios proyectos de investigación de IA/ML para mejorar el desarrollo de modelos y la productividad del servicio mediante la aplicación de las capacidades de SageMaker.
Para obtener más información sobre las funciones relacionadas en SageMaker, consulte lo siguiente:
Sobre los autores
 Young Joon Choi, AI/ML Expert SA, tiene experiencia en TI empresarial en diversas industrias, como la fabricación, la alta tecnología y las finanzas, como desarrollador, arquitecto y científico de datos. Realizó investigaciones sobre aprendizaje automático y aprendizaje profundo, específicamente sobre temas como optimización de hiperparámetros y adaptación de dominio, presentando algoritmos y artículos. En AWS, se especializa en IA/ML en todas las industrias, brindando validación técnica utilizando servicios de AWS para capacitación distribuida/modelos a gran escala y creación de MLOps. Propone y revisa arquitecturas, con el objetivo de contribuir a la expansión del ecosistema AI/ML.
Young Joon Choi, AI/ML Expert SA, tiene experiencia en TI empresarial en diversas industrias, como la fabricación, la alta tecnología y las finanzas, como desarrollador, arquitecto y científico de datos. Realizó investigaciones sobre aprendizaje automático y aprendizaje profundo, específicamente sobre temas como optimización de hiperparámetros y adaptación de dominio, presentando algoritmos y artículos. En AWS, se especializa en IA/ML en todas las industrias, brindando validación técnica utilizando servicios de AWS para capacitación distribuida/modelos a gran escala y creación de MLOps. Propone y revisa arquitecturas, con el objetivo de contribuir a la expansión del ecosistema AI/ML.
 Jung Hoon Kim es una cuenta SA de AWS Corea. Basado en experiencias en diseño de arquitectura de aplicaciones, desarrollo y modelado de sistemas en diversas industrias, como alta tecnología, manufactura, finanzas y sector público, está trabajando en el viaje a la nube de AWS y la optimización de cargas de trabajo en AWS para clientes empresariales.
Jung Hoon Kim es una cuenta SA de AWS Corea. Basado en experiencias en diseño de arquitectura de aplicaciones, desarrollo y modelado de sistemas en diversas industrias, como alta tecnología, manufactura, finanzas y sector público, está trabajando en el viaje a la nube de AWS y la optimización de cargas de trabajo en AWS para clientes empresariales.
 Roca Sakong es investigador en KT R&D. Ha realizado investigación y desarrollo para la visión artificial en varios campos y principalmente ha realizado atributos faciales (género/gafas, sombreros, etc.)/tecnología de reconocimiento facial relacionados con el rostro. Actualmente trabaja en tecnología ligera para los modelos de visión.
Roca Sakong es investigador en KT R&D. Ha realizado investigación y desarrollo para la visión artificial en varios campos y principalmente ha realizado atributos faciales (género/gafas, sombreros, etc.)/tecnología de reconocimiento facial relacionados con el rostro. Actualmente trabaja en tecnología ligera para los modelos de visión.
 manoj ravi es gerente senior de productos de Amazon SageMaker. Le apasiona crear productos de IA de próxima generación y trabaja en software y herramientas para facilitar el aprendizaje automático a gran escala para los clientes. Tiene un MBA de la Haas School of Business y una maestría en Gestión de Sistemas de Información de la Universidad Carnegie Mellon. En su tiempo libre, Manoj disfruta jugar al tenis y dedicarse a la fotografía de paisajes.
manoj ravi es gerente senior de productos de Amazon SageMaker. Le apasiona crear productos de IA de próxima generación y trabaja en software y herramientas para facilitar el aprendizaje automático a gran escala para los clientes. Tiene un MBA de la Haas School of Business y una maestría en Gestión de Sistemas de Información de la Universidad Carnegie Mellon. En su tiempo libre, Manoj disfruta jugar al tenis y dedicarse a la fotografía de paisajes.
 Roberto Van Dusen es gerente senior de productos en Amazon SageMaker. Lidera marcos, compiladores y técnicas de optimización para la capacitación en aprendizaje profundo.
Roberto Van Dusen es gerente senior de productos en Amazon SageMaker. Lidera marcos, compiladores y técnicas de optimización para la capacitación en aprendizaje profundo.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/kts-journey-to-reduce-training-time-for-a-vision-transformers-model-using-amazon-sagemaker/

