
Estoy seguro de que todo el mundo conoce los algoritmos GBM y XGBoost. Son algoritmos de referencia para muchos casos de uso y competencia del mundo real porque el resultado métrico suele ser mejor que el de otros modelos.
Para aquellos que no conocen GBM y XGBoost, GBM (Gradient Boosting Machine) y XGBoost (eXtreme Gradient Boosting) son métodos de aprendizaje conjunto. El aprendizaje conjunto es una técnica de aprendizaje automático en la que se entrenan y combinan múltiples modelos "débiles" (a menudo árboles de decisión) para fines posteriores.
El algoritmo se basó en la técnica de impulso del aprendizaje conjunto que se muestra en su nombre. Las técnicas de impulso son un método que intenta combinar varios alumnos débiles de forma secuencial, y cada uno corrige a su predecesor. Cada alumno aprendería de sus errores anteriores y corregiría los errores de los modelos anteriores.
Esa es la similitud fundamental entre GBM y XGB, pero ¿qué pasa con las diferencias? Discutiremos eso en este artículo, así que entremos en ello.
Como se mencionó anteriormente, GBM se basa en el impulso, que intenta iterar secuencialmente al alumno débil para aprender del error y desarrollar un modelo sólido. GBM desarrolló un mejor modelo para cada iteración minimizando la función de pérdida mediante el descenso de gradiente. El descenso de gradiente es un concepto para encontrar la función mínima con cada iteración, como la función de pérdida. La iteración continuaría hasta alcanzar el criterio de parada.
Para los conceptos de GBM, puedes verlo en la imagen a continuación.
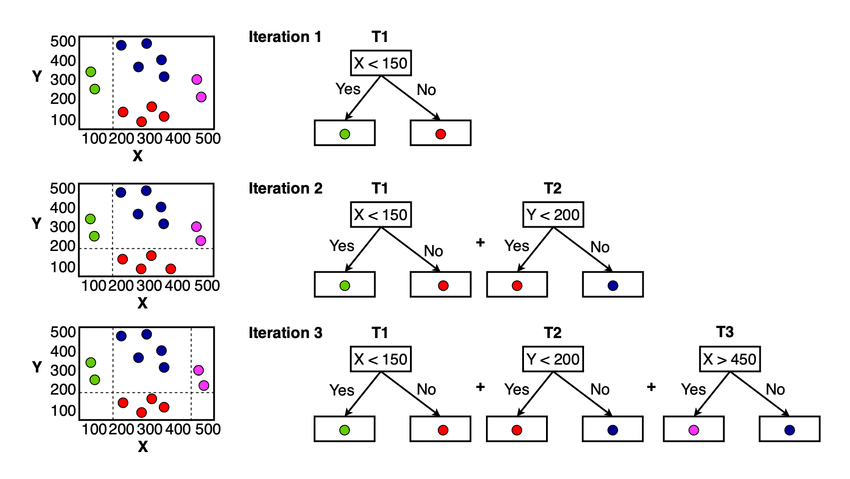
Concepto del modelo GBM (chhetri et al. (2022))
Puedes ver en la imagen de arriba que para cada iteración, el modelo intenta minimizar la función de pérdida y aprender del error anterior. El modelo final sería el alumno débil completo que resume todas las predicciones del modelo.
XGBoost o eXtreme Gradient Boosting es un algoritmo de aprendizaje automático basado en el algoritmo de aumento de gradiente desarrollado por Tiangqi Chen y Carlos Guestrin en 2016. En un nivel básico, el algoritmo todavía sigue una estrategia secuencial para mejorar el siguiente modelo basado en el descenso de gradiente. Sin embargo, algunas diferencias de XGBoost sitúan a este modelo como uno de los mejores en términos de rendimiento y velocidad.
1. Regularización
La regularización es una técnica de aprendizaje automático para evitar el sobreajuste. Es una colección de métodos para obligar al modelo a volverse demasiado complicado y tener poco poder de generalización. Se ha convertido en una técnica importante ya que muchos modelos se ajustan demasiado bien a los datos de entrenamiento.
GBM no implementa la regularización en su algoritmo, lo que hace que el algoritmo solo se centre en lograr funciones de pérdida mínima. En comparación con GBM, XGBoost implementa métodos de regularización para penalizar el modelo de sobreajuste.
Hay dos tipos de regularización que XGBoost podría aplicar: Regularización L1 (Lasso) y Regularización L2 (Ridge). La regularización L1 intenta minimizar los pesos o coeficientes de las características a cero (convirtiéndose efectivamente en una selección de características), mientras que la regularización L2 intenta reducir el coeficiente de manera uniforme (ayuda a lidiar con la multicolinealidad). Al implementar ambas regularizaciones, XGBoost podría evitar el sobreajuste mejor que GBM.
2. Paralelización
GBM tiende a tener un tiempo de entrenamiento más lento que XGBoost porque este último algoritmo implementa paralelización durante el proceso de entrenamiento. La técnica de impulso podría ser secuencial, pero la paralelización aún podría realizarse dentro del proceso XGBoost.
La paralelización tiene como objetivo acelerar el proceso de construcción del árbol, principalmente durante el evento de división. Al utilizar todos los núcleos de procesamiento disponibles, se puede acortar el tiempo de entrenamiento de XGBoost.
Hablando de acelerar el proceso XGBoost, el desarrollador también preprocesó los datos en su formato de datos desarrollado, DMatrix, para lograr eficiencia de la memoria y mejorar la velocidad de entrenamiento.
3. Manejo de datos faltantes
Nuestro conjunto de datos de entrenamiento podría contener datos faltantes, que debemos manejar explícitamente antes de pasarlos al algoritmo. Sin embargo, XGBoost tiene su propio controlador de datos faltantes incorporado, mientras que GBM no.
XGBoost implementó su técnica para manejar datos faltantes, llamada Sparsity-aware Split Finding. Para cualquier dato disperso que encuentre XGBoost (datos faltantes, cero denso, OHE), el modelo aprenderá de estos datos y encontrará la división más óptima. El modelo asignaría dónde se deben colocar los datos faltantes durante la división y vería qué dirección minimiza la pérdida.
4. Poda de árboles
La estrategia de crecimiento del GBM es dejar de dividirse después de que el algoritmo llegue a la pérdida negativa en la división. La estrategia podría conducir a resultados subóptimos porque se basa únicamente en la optimización local y podría descuidar el panorama general.
XGBoost intenta evitar la estrategia GBM y hace crecer el árbol hasta que la profundidad máxima del parámetro establecido comienza a podarse hacia atrás. La división con pérdida negativa se elimina, pero hay un caso en el que la división de pérdida negativa no se elimina. Cuando la división genera una pérdida negativa, pero la división adicional es positiva, aún se retendrá si la división general es positiva.
5. Validación cruzada incorporada
La validación cruzada es una técnica para evaluar la capacidad de generalización y robustez de nuestro modelo dividiendo los datos sistemáticamente durante varias iteraciones. En conjunto, su resultado mostraría si el modelo se está sobreajustando o no.
Normalmente, el algoritmo de la máquina requeriría ayuda externa para implementar la validación cruzada, pero XGBoost tiene una validación cruzada incorporada que podría usarse durante la sesión de entrenamiento. La validación cruzada se realizaría en cada iteración de impulso y garantizaría que el árbol de producción sea sólido.
GBM y XGBoost son algoritmos populares en muchos casos y competiciones del mundo real. Conceptualmente, ambos son algoritmos de impulso que utilizan alumnos débiles para lograr mejores modelos. Sin embargo, contienen pocas diferencias en la implementación de su algoritmo. XGBoost mejora el algoritmo al incorporar regularización, realizar paralelización, manejar mejor los datos faltantes, diferentes estrategias de poda de árboles y técnicas de validación cruzada integradas.
Cornelio Yudha Wijaya es subgerente de ciencia de datos y escritor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos sobre Python y datos a través de las redes sociales y los medios de escritura.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/wtf-is-the-difference-between-gbm-and-xgboost?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-the-difference-between-gbm-and-xgboost

