Wrangler de datos de Amazon SageMaker es una única interfaz visual que reduce el tiempo necesario para preparar datos y realizar ingeniería de funciones de semanas a minutos con la capacidad de seleccionar y limpiar datos, crear funciones y automatizar la preparación de datos en flujos de trabajo de aprendizaje automático (ML) sin escribir ningún código.
SageMaker Data Wrangler admite Copo de nieve, una fuente de datos popular para los usuarios que desean realizar ML. Lanzamos la conexión directa de Snowflake desde SageMaker Data Wrangler para mejorar la experiencia del cliente. Antes del lanzamiento de esta función, los administradores debían configurar la integración de almacenamiento inicial para conectarse con Snowflake y crear funciones para ML en Data Wrangler. Esto incluye el aprovisionamiento Servicio de almacenamiento simple de Amazon (Amazon S3) baldes, Gestión de identidades y accesos de AWS (IAM), integración de almacenamiento de Snowflake para usuarios individuales y un mecanismo continuo para administrar o limpiar copias de datos en Amazon S3. Este proceso no es escalable para clientes con un estricto control de acceso a datos y una gran cantidad de usuarios.
En esta publicación, mostramos cómo la conexión directa de Snowflake en SageMaker Data Wrangler simplifica la experiencia del administrador y el viaje de aprendizaje automático del científico de datos desde los datos hasta la información comercial.
Resumen de la solución
En esta solución, usamos SageMaker Data Wrangler para acelerar la preparación de datos para ML y Piloto automático Amazon SageMaker para crear, entrenar y ajustar automáticamente los modelos de ML en función de sus datos. Ambos servicios están diseñados específicamente para aumentar la productividad y acortar el tiempo de obtención de valor para los profesionales de ML. También demostramos el acceso a datos simplificado de SageMaker Data Wrangler a Snowflake con conexión directa para consultar y crear funciones para ML.
Consulte el siguiente diagrama para obtener una descripción general del proceso de aprendizaje automático de código bajo con Snowflake, SageMaker Data Wrangler y SageMaker Autopilot.

El flujo de trabajo incluye los siguientes pasos:
- Navegue a SageMaker Data Wrangler para sus tareas de ingeniería de características y preparación de datos.
- Configure la conexión de Snowflake con SageMaker Data Wrangler.
- Explore sus tablas de Snowflake en SageMaker Data Wrangler, cree un conjunto de datos de ML y realice ingeniería de funciones.
- Entrene y pruebe los modelos con SageMaker Data Wrangler y SageMaker Autopilot.
- Cargue el mejor modelo en un punto final de inferencia en tiempo real para realizar predicciones.
- Use un cuaderno de Python para invocar el punto final de inferencia en tiempo real lanzado.
Requisitos previos
Para esta publicación, el administrador necesita los siguientes requisitos previos:
Los científicos de datos deben tener los siguientes requisitos previos
Por último, debe preparar sus datos para Snowflake
- Usamos datos de transacciones de tarjetas de crédito de Kaggle para construir modelos ML para detectar transacciones fraudulentas con tarjetas de crédito, de modo que a los clientes no se les cobre por artículos que no compraron. El conjunto de datos incluye transacciones con tarjeta de crédito en septiembre de 2013 realizadas por titulares de tarjetas europeos.
- Se debe utilizar la Cliente SnowSQL e instálelo en su máquina local, para que pueda usarlo para cargar el conjunto de datos en una tabla de Snowflake.
Los siguientes pasos muestran cómo preparar y cargar el conjunto de datos en la base de datos de Snowflake. Esta es una configuración única.
Tabla de copos de nieve y preparación de datos.
Complete los siguientes pasos para esta configuración única:
- En primer lugar, como administrador, cree un almacén virtual, un usuario y un rol de Snowflake, y otorgue acceso a otros usuarios, como los científicos de datos, para crear una base de datos y preparar datos para sus casos de uso de ML:
- Como científico de datos, ahora vamos a crear una base de datos e importar las transacciones de la tarjeta de crédito a la base de datos de Snowflake para acceder a los datos de SageMaker Data Wrangler. Con fines ilustrativos, creamos una base de datos Snowflake denominada
SF_FIN_TRANSACTION: - Descargue el archivo CSV del conjunto de datos a su máquina local y cree una etapa para cargar los datos en la tabla de la base de datos. Actualice la ruta del archivo para que apunte a la ubicación del conjunto de datos descargado antes de ejecutar el comando PUT para importar los datos a la etapa creada:
- Crea una tabla llamada
credit_card_transactions: - Importe los datos a la tabla creada desde el escenario:

Configurar la conexión de SageMaker Data Wrangler y Snowflake
Después de preparar el conjunto de datos para usarlo con SageMaker Data Wrangler, creemos una nueva conexión de Snowflake en SageMaker Data Wrangler para conectarnos al sf_fin_transaction base de datos en Snowflake y consultar la credit_card_transaction mesa:
- Elige Copo de nieve en SageMaker Data Wrangler Conexión .
- Proporcione un nombre para identificar su conexión.
- Seleccione su método de autenticación para conectarse con la base de datos de Snowflake:
- Si utiliza la autenticación básica, proporcione el nombre de usuario y la contraseña compartidos por su administrador de Snowflake. Para esta publicación, usamos autenticación básica para conectarnos a Snowflake usando las credenciales de usuario que creamos en el paso anterior.
- Si usa OAuth, proporcione las credenciales de su proveedor de identidad.
SageMaker Data Wrangler consulta sus datos de forma predeterminada directamente desde Snowflake sin crear ninguna copia de datos en depósitos S3. La nueva mejora de usabilidad de SageMaker Data Wrangler utiliza Apache Spark para integrarse con Snowflake a fin de preparar y crear sin problemas un conjunto de datos para su proceso de aprendizaje automático.
Hasta ahora, creamos la base de datos en Snowflake, importamos el archivo CSV a la tabla de Snowflake, creamos las credenciales de Snowflake y creamos un conector en SageMaker Data Wrangler para conectarnos a Snowflake. Para validar la conexión de Snowflake configurada, ejecute la siguiente consulta en la tabla de Snowflake creada:

Tenga en cuenta que la opción de integración de almacenamiento que antes era necesaria ahora es opcional en la configuración avanzada.
Explora los datos de Snowflake
Después de validar los resultados de la consulta, elija Importa para guardar los resultados de la consulta como el conjunto de datos. Utilizamos este conjunto de datos extraído para el análisis de datos exploratorios y la ingeniería de características.

Puede optar por probar los datos de Snowflake en la interfaz de usuario de SageMaker Data Wrangler. Otra opción es descargar datos completos para sus casos de uso de entrenamiento de modelos de ML mediante trabajos de procesamiento de SageMaker Data Wrangler.

Realizar análisis de datos exploratorios en SageMaker Data Wrangler
Los datos dentro de Data Wrangler deben diseñarse antes de poder entrenarse. En esta sección, demostramos cómo realizar la ingeniería de funciones en los datos de Snowflake utilizando las funciones integradas de SageMaker Data Wrangler.
Primero, usemos el Data Quality and Insights Report dentro de SageMaker Data Wrangler para generar informes para verificar automáticamente la calidad de los datos y detectar anomalías en los datos de Snowflake.
Puede usar el informe para ayudarlo a limpiar y procesar sus datos. Le brinda información como la cantidad de valores faltantes y la cantidad de valores atípicos. Si tiene problemas con sus datos, como fugas o desequilibrios en el objetivo, el informe de conocimientos puede llamar su atención sobre esos problemas. Para comprender los detalles del informe, consulte Acelere la preparación de datos con información y calidad de datos en Amazon SageMaker Data Wrangler.
Después de verificar la coincidencia de tipos de datos aplicada por SageMaker Data Wrangler, complete los siguientes pasos:
- Elija el signo más junto a Tipos de datos y elige Agregar análisis.

- Tipo de análisis, escoger Informe de información y calidad de datos.
- Elige Crear.

- Consulte los detalles del Informe de información y calidad de los datos para ver las advertencias de alta prioridad.
Puede optar por resolver las advertencias notificadas antes de continuar con su viaje de ML.

La columna de destino Class que se va a predecir se clasifica como una cadena. Primero, apliquemos una transformación para eliminar los caracteres vacíos obsoletos.
- Elige Agregar paso y elige Cadena de formato.
- En la lista de transformaciones, elija Tira a la izquierda y a la derecha.
- Introduce los caracteres a eliminar y elige Añada.

A continuación, convertimos la columna de destino Class del tipo de datos de cadena a booleano porque la transacción es legítima o fraudulenta.
- Elige Agregar paso.
- Elige Analizar columna como tipo.
- Para Columna, elija
Class. - Desde, escoger Cordón.
- A, escoger Boolean.
- Elige Añada.

Después de la transformación de la columna de destino, reducimos la cantidad de columnas de características porque hay más de 30 características en el conjunto de datos original. Usamos el análisis de componentes principales (PCA) para reducir las dimensiones en función de la importancia de las características. Para comprender más acerca de PCA y la reducción de dimensionalidad, consulte Algoritmo de análisis de componentes principales (PCA).
- Elige Agregar paso.

- Elige Reducción de dimensionalidad.
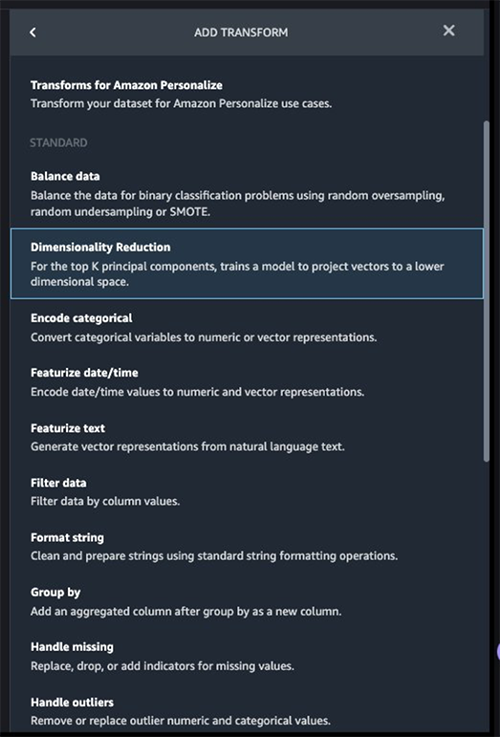
- Transformar, escoger Análisis de componentes principales.
- Columnas de entrada, elija todas las columnas excepto la columna de destino
Class.
- Elija el signo más junto a Flujo de datos y elige Añadir análisis.
- Tipo de análisis, escoger Modelo rápido.
- Nombre del análisis, ingresa un nombre.
- Label, escoger
Class.
- Elige Ejecutar.
En función de los resultados de PCA, puede decidir qué características usar para construir el modelo. En la siguiente captura de pantalla, el gráfico muestra las características (o dimensiones) ordenadas de mayor a menor importancia para predecir la clase objetivo, que en este conjunto de datos es si la transacción es fraudulenta o válida.

Puede optar por reducir la cantidad de funciones en función de este análisis, pero para esta publicación, dejamos los valores predeterminados como están.
Esto concluye nuestro proceso de ingeniería de funciones, aunque puede optar por ejecutar el modelo rápido y crear un Informe de información y calidad de datos nuevamente para comprender los datos antes de realizar más optimizaciones.
Exportar datos y entrenar el modelo
En el siguiente paso, usamos SageMaker Autopilot para crear, entrenar y ajustar automáticamente los mejores modelos de ML en función de sus datos. Con SageMaker Autopilot, aún mantiene el control total y la visibilidad de sus datos y modelo.
Ahora que hemos completado la exploración y la ingeniería de características, entrenemos un modelo en el conjunto de datos y exportemos los datos para entrenar el modelo ML usando SageMaker Autopilot.
- En Formación pestaña, elegir Exportar y entrenar.

Podemos monitorear el progreso de la exportación mientras esperamos que se complete.

Configuremos SageMaker Autopilot para ejecutar un trabajo de entrenamiento automatizado especificando el objetivo que queremos predecir y el tipo de problema. En este caso, debido a que estamos entrenando el conjunto de datos para predecir si la transacción es fraudulenta o válida, usamos la clasificación binaria.
- Ingrese un nombre para su experimento, proporcione los datos de ubicación de S3 y elija Siguiente: Destino y características.

- Target, escoger
Classcomo la columna para predecir. - Elige Siguiente: Método de entrenamiento.

Permitamos que SageMaker Autopilot decida el método de entrenamiento en función del conjunto de datos.
- Método de entrenamiento y algoritmos., seleccione Auto.
Para obtener más información sobre los modos de entrenamiento admitidos por SageMaker Autopilot, consulte Modos de entrenamiento y algoritmo apoyo.
- Elige Siguiente: Implementación y configuración avanzada.

- Opción de implementación, escoger Implemente automáticamente el mejor modelo con transformaciones de Data Wrangler, que carga el mejor modelo para la inferencia una vez finalizada la experimentación.
- Introduzca un nombre para su terminal.
- Seleccione el tipo de problema de aprendizaje automático, escoger Clasificación binaria.
- Métrica de objeción, escoger F1.
- Elige Siguiente: Revisar y crear.

- Elige Crear experimento.
Esto inicia un trabajo de SageMaker Autopilot que crea un conjunto de trabajos de entrenamiento que usa combinaciones de hiperparámetros para optimizar la métrica objetiva.

Espere a que SageMaker Autopilot termine de crear los modelos y evaluar el mejor modelo de ML.
Inicie un punto final de inferencia en tiempo real para probar el mejor modelo
SageMaker Autopilot ejecuta experimentos para determinar el mejor modelo que puede clasificar las transacciones con tarjeta de crédito como legítimas o fraudulentas.
Cuando SageMaker Autopilot completa el experimento, podemos ver los resultados de la capacitación con las métricas de evaluación y explorar el mejor modelo desde la página de descripción del trabajo de SageMaker Autopilot.
- Seleccione el mejor modelo y elija Implementar modelo.

Usamos un punto final de inferencia en tiempo real para probar el mejor modelo creado a través de SageMaker Autopilot.
- Seleccione Haz predicciones en tiempo real.
Cuando el punto final está disponible, podemos pasar la carga útil y obtener resultados de inferencia.

Iniciemos un cuaderno de Python para usar el punto final de inferencia.
- En la consola de SageMaker Studio, elija el icono de la carpeta en el panel de navegación y elija Crear cuaderno.

- Utilice el siguiente código de Python para invocar el punto final de inferencia en tiempo real implementado:
La salida muestra el resultado como false, lo que implica que los datos de características de muestra no son fraudulentos.

Limpiar
Para asegurarse de no incurrir en cargos después de completar este tutorial, cierre la aplicación SageMaker Data Wrangler y cerrar la instancia del cuaderno utilizado para realizar inferencias. También deberías eliminar el punto final de inferencia que creó utilizando SageMaker Autopilot para evitar cargos adicionales.
Conclusión
En esta publicación, demostramos cómo traer sus datos desde Snowflake directamente sin crear copias intermedias en el proceso. Puede probar o cargar su conjunto de datos completo en SageMaker Data Wrangler directamente desde Snowflake. A continuación, puede explorar los datos, limpiarlos y realizar funciones de ingeniería mediante la interfaz visual de SageMaker Data Wrangler.
También destacamos cómo puede entrenar y ajustar fácilmente un modelo con SageMaker Autopilot directamente desde la interfaz de usuario de SageMaker Data Wrangler. Con la integración de SageMaker Data Wrangler y SageMaker Autopilot, podemos construir rápidamente un modelo después de completar la ingeniería de características, sin escribir ningún código. Luego hicimos referencia al mejor modelo de SageMaker Autopilot para ejecutar inferencias utilizando un punto final en tiempo real.
Pruebe la nueva integración directa de Snowflake con SageMaker Data Wrangler hoy mismo para crear fácilmente modelos de aprendizaje automático con sus datos mediante SageMaker.
Sobre los autores
 Hariharan Suresh es arquitecto sénior de soluciones en AWS. Le apasionan las bases de datos, el aprendizaje automático y el diseño de soluciones innovadoras. Antes de unirse a AWS, Hariharan fue arquitecto de productos, especialista en implementación de banca central y desarrollador, y trabajó con organizaciones BFSI durante más de 11 años. Fuera de la tecnología, disfruta del parapente y el ciclismo.
Hariharan Suresh es arquitecto sénior de soluciones en AWS. Le apasionan las bases de datos, el aprendizaje automático y el diseño de soluciones innovadoras. Antes de unirse a AWS, Hariharan fue arquitecto de productos, especialista en implementación de banca central y desarrollador, y trabajó con organizaciones BFSI durante más de 11 años. Fuera de la tecnología, disfruta del parapente y el ciclismo.
 Aparajithan Vaidyanathan es Arquitecto Principal de Soluciones Empresariales en AWS. Ayuda a los clientes empresariales a migrar y modernizar sus cargas de trabajo en la nube de AWS. Es un arquitecto de la nube con más de 23 años de experiencia en el diseño y desarrollo de sistemas de software empresariales, a gran escala y distribuidos. Se especializa en aprendizaje automático y análisis de datos con enfoque en el dominio de ingeniería de características y datos. Es un aspirante a corredor de maratón y sus pasatiempos incluyen el senderismo, andar en bicicleta y pasar tiempo con su esposa y sus dos hijos.
Aparajithan Vaidyanathan es Arquitecto Principal de Soluciones Empresariales en AWS. Ayuda a los clientes empresariales a migrar y modernizar sus cargas de trabajo en la nube de AWS. Es un arquitecto de la nube con más de 23 años de experiencia en el diseño y desarrollo de sistemas de software empresariales, a gran escala y distribuidos. Se especializa en aprendizaje automático y análisis de datos con enfoque en el dominio de ingeniería de características y datos. Es un aspirante a corredor de maratón y sus pasatiempos incluyen el senderismo, andar en bicicleta y pasar tiempo con su esposa y sus dos hijos.
 canción de tim es ingeniero de desarrollo de software en AWS SageMaker, con más de 10 años de experiencia como desarrollador de software, consultor y líder tecnológico, ha demostrado su capacidad para ofrecer productos escalables y confiables y resolver problemas complejos. En su tiempo libre, disfruta de la naturaleza, correr al aire libre, hacer senderismo, etc.
canción de tim es ingeniero de desarrollo de software en AWS SageMaker, con más de 10 años de experiencia como desarrollador de software, consultor y líder tecnológico, ha demostrado su capacidad para ofrecer productos escalables y confiables y resolver problemas complejos. En su tiempo libre, disfruta de la naturaleza, correr al aire libre, hacer senderismo, etc.
 Bosco Alburquerque es arquitecto sénior de soluciones de socios en AWS y tiene más de 20 años de experiencia trabajando con productos de análisis y bases de datos de proveedores de bases de datos empresariales y proveedores de la nube. Ha ayudado a grandes empresas de tecnología a diseñar soluciones de análisis de datos y ha dirigido equipos de ingeniería en el diseño e implementación de plataformas de análisis de datos y productos de datos.
Bosco Alburquerque es arquitecto sénior de soluciones de socios en AWS y tiene más de 20 años de experiencia trabajando con productos de análisis y bases de datos de proveedores de bases de datos empresariales y proveedores de la nube. Ha ayudado a grandes empresas de tecnología a diseñar soluciones de análisis de datos y ha dirigido equipos de ingeniería en el diseño e implementación de plataformas de análisis de datos y productos de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/accelerate-time-to-business-insights-with-the-amazon-sagemaker-data-wrangler-direct-connection-to-snowflake/

