Amazon EMR sin servidor le permite ejecutar marcos de big data de código abierto como Apache Spark y Apache Hive sin administrar clústeres y servidores. Muchos clientes que ejecutan aplicaciones Spark y Hive desean agregar sus propias bibliotecas y dependencias al tiempo de ejecución de la aplicación. Por ejemplo, es posible que desee agregar extensiones populares de código abierto a Spark, o agregar un módulo de cifrado y descifrado personalizado que utilice su aplicación.
Nos complace anunciar una nueva capacidad que le permite personalizar la imagen de tiempo de ejecución utilizada en EMR Serverless agregando bibliotecas personalizadas que sus aplicaciones necesitan usar. Esta característica le permite hacer lo siguiente:
- Mantenga un conjunto de bibliotecas controladas por versiones que se reutilicen y estén disponibles para su uso en todos sus trabajos de EMR Serverless como parte del tiempo de ejecución de EMR Serverless
- Agregue extensiones populares a los marcos de código abierto Spark y Hive, como pandas, NumPy, matplotlib y más, que desee que use su aplicación EMR sin servidor
- Use procesos de CI/CD establecidos para crear, probar e implementar sus bibliotecas de extensión personalizadas en el tiempo de ejecución sin servidor de EMR
- Aplique procesos de seguridad establecidos, como el escaneo de imágenes, para cumplir con los requisitos de cumplimiento y gobernanza dentro de su organización.
- Use una versión diferente de un componente de tiempo de ejecución (por ejemplo, el tiempo de ejecución de JDK o el tiempo de ejecución de SDK de Python) que la versión que está disponible de forma predeterminada con EMR Serverless
En esta publicación, demostramos cómo usar esta nueva función.
Descripción general de la solución
Para usar esta capacidad, personalice la imagen base de EMR Serverless usando Registro de contenedores elásticos de Amazon (Amazon ECR), que es un registro de contenedores completamente administrado que facilita a sus desarrolladores compartir e implementar imágenes de contenedores. Amazon ECR elimina la necesidad de operar sus propios repositorios de contenedores o preocuparse por escalar la infraestructura subyacente. Después de que la imagen personalizada se inserte en el registro del contenedor, especifique la imagen personalizada mientras crea sus aplicaciones EMR Serverless.
El siguiente diagrama ilustra los pasos involucrados en el uso de imágenes personalizadas para sus aplicaciones EMR Serverless.

En las siguientes secciones, demostramos el uso de imágenes personalizadas con Amazon EMR Serverless para abordar tres casos de uso comunes:
- Agregue bibliotecas populares de Python de código abierto a la imagen de tiempo de ejecución de EMR Serverless
- Use una versión diferente o más nueva del tiempo de ejecución de Java para la aplicación EMR Serverless
- Instale un agente de Prometheus y personalice el tiempo de ejecución de Spark para impulsar las métricas de Spark JMX a Servicio administrado de Amazon para Prometheusy visualice las métricas en un tablero de Grafana
Requisitos generales
Los siguientes son los requisitos previos para usar imágenes personalizadas con EMR Serverless. Complete los siguientes pasos antes de continuar con los pasos siguientes:
- Crear una Gestión de identidades y accesos de AWS (IAM) rol con permisos de IAM para Aplicaciones sin servidor de Amazon EMR, Permisos de Amazon ECRy Permisos de Amazon S3 para Servicio de almacenamiento simple de Amazon (Amazon S3) depósito
aws-bigdata-blogy cualquier depósito S3 en su cuenta donde almacenará los artefactos de la aplicación. - Instalar o actualizar a la última Interfaz de línea de comandos de AWS (AWS CLI) e instale el servicio Docker en un sistema basado en Amazon Linux 2 Nube informática elástica de Amazon (Amazon EC2) instancia. Adjunte el rol de IAM del paso anterior para esta instancia EC2.
- Seleccione una imagen básica de EMR Serverless de las siguientes repositorio público de Amazon ECR. Ejecute los siguientes comandos en la instancia EC2 con Docker instalado para verificar que puede extraer la imagen base del repositorio público:
- Inicie sesión en Amazon ECR con los siguientes comandos y cree un repositorio llamado
emr-serverless-ci-examples, proporcionando su ID de cuenta y región de AWS: - Proporcione permisos de IAM a la entidad principal del servicio EMR Serverless para el repositorio de Amazon ECR:
- En la consola de Amazon ECR, elija Permisos bajo Repositorios en el panel de navegación.
- Elige Editar política JSON.

- Ingrese el siguiente JSON y guarde:
Asegúrese de que la política esté actualizada en la consola de Amazon ECR.

Para las cargas de trabajo de producción, recomendamos agregar una condición en la política de Amazon ECR para garantizar que solo las aplicaciones sin servidor de EMR permitidas puedan obtener, describir y descargar imágenes de este repositorio. Para obtener más información, consulte Permitir que EMR Serverless acceda al repositorio de imágenes personalizadas.
En los siguientes pasos, creamos y usamos imágenes personalizadas en nuestras aplicaciones EMR Serverless para los tres casos de uso diferentes.
Caso de uso 1: ejecutar aplicaciones de ciencia de datos
Una de las aplicaciones comunes de Spark en Amazon EMR es la capacidad de ejecutar aplicaciones de ciencia de datos y aprendizaje automático (ML) a escala. Para grandes conjuntos de datos, Spark incluye SparkML, que ofrece algoritmos de ML comunes que se pueden usar para entrenar modelos de forma distribuida. Sin embargo, a menudo necesita ejecutar muchas iteraciones de clasificadores simples para ajustar hiperparámetros, conjuntos y soluciones de clases múltiples en datos de tamaño pequeño a mediano (100,000 1 a XNUMX millón de registros). Spark es un gran motor para ejecutar múltiples iteraciones de dichos clasificadores en paralelo. En este ejemplo, demostramos este caso de uso, donde usamos Spark para ejecutar múltiples iteraciones de un modelo XGBoost para seleccionar los mejores parámetros. La capacidad de incluir dependencias de Python en la imagen de EMR Serverless debería facilitar la creación de diversas dependencias (xgboost, sk-dist, pandas, numpy, etc.) disponibles para la aplicación.
Requisitos previos
El EMR sin servidor rol de IAM en tiempo de ejecución del trabajo se le deben otorgar permisos para su depósito S3 donde almacenará su archivo PySpark y los registros de la aplicación:
Crear una imagen para instalar dependencias de ML
Creamos un Imagen personalizada desde la imagen base de EMR Serverless para instalar las dependencias requeridas por la aplicación SparkML. Cree el siguiente Dockerfile en su instancia EC2 que ejecuta el proceso docker dentro de un nuevo directorio llamado datascience:
Cree y envíe la imagen al repositorio de Amazon ECR emr-serverless-ci-examples, proporcionando su ID de cuenta y región de AWS:
Envíe su aplicación Spark
Cree una aplicación EMR Serverless con la imagen personalizada creada en el paso anterior:
Tome nota del valor de applicationId devuelto por el comando.
Una vez creada la aplicación, estamos listos para enviar nuestro trabajo. Copie el archivo de la aplicación en su depósito S3:
Envíe el trabajo de ciencia de datos de Spark. En el siguiente comando, proporcione el nombre del depósito S3 y el prefijo donde almacenó su archivo de aplicación. Adicionalmente, proporcione la applicationId valor obtenido de la create-application y el ARN del rol de IAM en tiempo de ejecución del trabajo sin servidor de EMR.
Después de que el trabajo de Spark tenga éxito, puede ver las mejores estimaciones del modelo de nuestra aplicación al ver el controlador de Spark stdout registros Navegar a Servidor de historial de chispas, Ejecutores, Destornillador, Troncos, stdout.

Caso de uso 2: usar un entorno de tiempo de ejecución de Java personalizado
Otro caso de uso para imágenes personalizadas es la capacidad de usar una versión personalizada de Java para sus aplicaciones EMR Serverless. Por ejemplo, si usa Java11 para compilar y empaquetar sus aplicaciones Java o Scala e intenta ejecutarlas directamente en EMR Serverless, puede generar errores de tiempo de ejecución porque EMR Serverless usa Java 8 JRE de forma predeterminada. Para que los entornos de tiempo de ejecución de sus aplicaciones EMR Serverless sean compatibles con su entorno de compilación, puede utilizar la función de imágenes personalizadas para instalar la versión de Java que está utilizando para empaquetar sus aplicaciones.
Requisitos previos
Un EMR sin servidor rol de IAM en tiempo de ejecución del trabajo se le debe otorgar permisos a su depósito S3 donde almacenará su aplicación JAR y registros:
Cree una imagen para instalar una versión personalizada de Java
Primero creamos una imagen que instalará un entorno de tiempo de ejecución de Java 11. Cree el siguiente Dockerfile en su instancia EC2 dentro de un nuevo directorio llamado customjre:
Cree y envíe la imagen al repositorio de Amazon ECR emr-serverless-ci-examples, proporcionando su ID de cuenta y región de AWS:
Envíe su aplicación Spark
Cree una aplicación EMR Serverless con la imagen personalizada creada en el paso anterior:
Copie el archivo JAR de la aplicación en su depósito S3:
Envíe un trabajo de Spark Scala compilado con Java11 JRE. Esto trabajo también utiliza las API de Java que pueden producir resultados diferentes para diferentes versiones de Java (por ejemplo: java.time.ZoneId). En el siguiente comando, proporcione el nombre del depósito S3 y el prefijo donde almacenó su JAR de aplicación. Adicionalmente, proporcione la applicationId valor obtenido de la create-application y el ARN de la función de tiempo de ejecución del trabajo sin servidor de EMR con los permisos de IAM mencionados en los requisitos previos. Tenga en cuenta que en el sparkSubmitParameters, pasamos una versión de Java personalizada para nuestros entornos de controlador y ejecución de Spark para indicarle a nuestro trabajo que use el tiempo de ejecución de Java11.
También puede extender este caso de uso para instalar y usar una versión personalizada de Python para sus aplicaciones PySpark.
Caso de uso 3: monitorear las métricas de Spark en un solo tablero de Grafana
La telemetría Spark JMX proporciona una gran cantidad de detalles detallados sobre cada etapa de la aplicación Spark, incluso a nivel de JVM. Esta información se puede usar para ajustar y optimizar las aplicaciones de Spark para reducir el tiempo de ejecución y el costo del trabajo. Prometheus es una herramienta popular que se utiliza para recopilar, consultar y visualizar métricas de aplicaciones y hosts de varios procesos diferentes. Después de recopilar las métricas en Prometheus, podemos consultar estas métricas o usar Grafana para crear paneles y visualizarlos. En este caso de uso, usamos Amazon Managed Prometheus para recopilar métricas de controlador y ejecutor de Spark de nuestra aplicación EMR Serverless Spark, y usamos Grafana para visualizar las métricas recopiladas. La siguiente captura de pantalla es un panel de Grafana de ejemplo para una aplicación EMR Serverless Spark.

Requisitos previos
Complete los siguientes pasos de requisitos previos:
- Cree una VPC, una subred privada y un grupo de seguridad. La subred privada debe tener una puerta de enlace NAT o Punto de enlace S3 de la VPC adjunto. El grupo de seguridad debe permitir el acceso saliente al puerto HTTPS 443 y debe tener una regla de entrada autorreferenciada para todo el tráfico.


Tanto la subred privada como el grupo de seguridad deben estar asociados con los dos Interfaces de punto de enlace de Amazon Managed Prometheus VPC. - En Nube privada virtual de Amazon (Amazon VPC), cree dos puntos de enlace para Amazon Managed Prometheus y el espacio de trabajo de Amazon Managed Prometheus. Asocie los puntos de enlace a la VPC, la subred privada y el grupo de seguridad a ambos puntos de enlace. Opcionalmente, proporcione una etiqueta de nombre para sus puntos finales y deje todo lo demás como predeterminado.

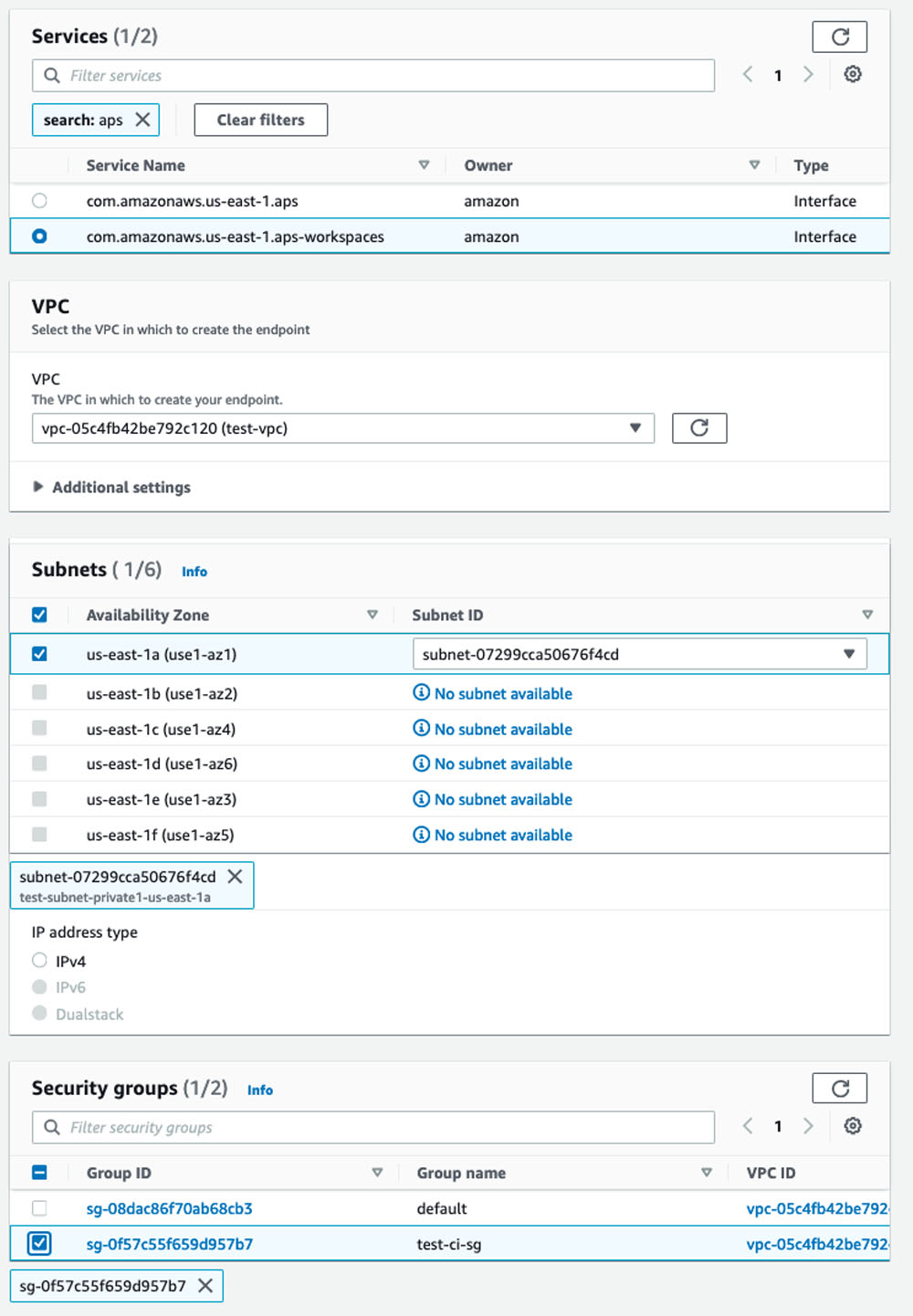
- Cree un nuevo espacio de trabajo en la consola de Amazon Managed Prometheus.
- Tenga en cuenta el ARN y los valores para Punto final: URL de escritura remota y Punto final: URL de consulta.
- Adjunte la siguiente política a su Amazon EMR Serverless rol de IAM en tiempo de ejecución del trabajo para proporcionar acceso de escritura remoto a su espacio de trabajo de Prometheus. Reemplace el ARN copiado del paso anterior en el
Resourcesección de"Sid": "AccessToPrometheus". Este rol también debe tener permisos para su depósito de S3 donde almacenará los registros y el archivo JAR de su aplicación. - Cree un usuario o rol de IAM con permisos para crear y consultar el espacio de trabajo de Amazon Managed Prometheus.
Usamos el mismo usuario o rol de IAM para autenticar en Grafana o consultar el espacio de trabajo de Prometheus.
Crear una imagen para instalar el agente de Prometheus
Creamos una imagen personalizada a partir de la imagen base de EMR Serverless para hacer lo siguiente:
- Actualice la configuración de métricas de Spark para usar
PrometheusServletpara publicar métricas JMX de controlador y ejecutor en formato Prometheus - Descargue e instale el agente de Prometheus
- Cargue el archivo YAML de configuración para indicar al agente de Prometheus que envíe las métricas al espacio de trabajo de Amazon Managed Prometheus.
Cree el archivo YAML de configuración de Prometheus para extraer las métricas del controlador, el ejecutor y la aplicación. Puede ejecutar los siguientes comandos de ejemplo en la instancia EC2.
- Copia el
prometheus.yamlarchivo de nuestra ruta S3: - modificar
prometheus.yamlpara reemplazar la Región y el valor de laremote_writeURL con la URL de escritura remota obtenida de los requisitos previos: - Cargue el archivo en su propio depósito de S3:
- Cree el siguiente Dockerfile dentro de un nuevo directorio llamado
prometheusen la misma instancia EC2 que ejecuta el servicio Docker. Proporcione la ruta S3 donde cargó elprometheus.yamlarchivo. - Cree el Dockerfile y impulsar a Amazon ECR, proporcionando su ID de cuenta y región de AWS:
Envíe la aplicación Spark
Una vez que la imagen de Docker se haya enviado correctamente, puede crear la aplicación Spark sin servidor con la imagen personalizada que creó. Usamos la CLI de AWS para enviar trabajos de Spark con la imagen personalizada en EMR Serverless. Su AWS CLI debe actualizarse a la última versión para ejecutar los siguientes comandos.
- En el siguiente comando de la CLI de AWS, proporcione su ID de cuenta y región de AWS. Además, proporcione la subred y el grupo de seguridad de los requisitos previos en la configuración de la red. Para enviar correctamente las métricas de EMR Serverless a Amazon Managed Prometheus, asegúrese de utilizar la misma VPC, subred y grupo de seguridad que creó en función de los requisitos previos.
- Copie el archivo JAR de la aplicación en su depósito S3:
- En el siguiente comando, proporcione el nombre del depósito S3 y el prefijo donde almacenó su JAR de aplicación. Adicionalmente, proporcione la
applicationIdvalor obtenido de lacreate-applicationy el ARN de la función de IAM del tiempo de ejecución del trabajo sin servidor de EMR de los requisitos previos, con permisos para escribir en el espacio de trabajo de Amazon Managed Prometheus.
Dentro de esto aplicación chispa, ejecutamos el script bash en la imagen para iniciar el proceso de Prometheus. Deberá agregar las siguientes líneas a su código de Spark después de iniciar la sesión de Spark si planea usar esta imagen para monitorear su propia aplicación de Spark:
Para las aplicaciones PySpark, puede usar el siguiente código:
Consulta las métricas de Prometheus y visualízalas en Grafana
Aproximadamente un minuto después de que el trabajo cambia a Running estado, puede consultar las métricas de Prometheus usando awscurl.
- Reemplace el valor de
AMP_QUERY_ENDPOINTcon la URL de consulta que anotó anteriormente y proporcione el ID de ejecución del trabajo obtenido después de enviar el trabajo de Spark. Asegúrese de utilizar las credenciales de un usuario o rol de IAM que tenga permisos para consultar el espacio de trabajo de Prometheus antes de ejecutar los comandos.El siguiente es un ejemplo de salida de la consulta:
- Instalar Grafana en su escritorio local y configure nuestro espacio de trabajo AMP como fuente de datos. Grafana es una plataforma de uso común para visualizar las métricas de Prometheus.
- Antes de iniciar el servidor de Grafana, habilite la autenticación SIGv4 de AWS para firmar consultas en AMP con permisos de IAM.
- En la misma sesión, inicie el servidor Grafana. Tenga en cuenta que la ruta de instalación de Grafana puede variar según las configuraciones de su sistema operativo. Modifique el comando para iniciar el servidor Grafana en caso de que su ruta de instalación sea diferente de
/usr/local/. Además, asegúrese de estar utilizando las credenciales de un usuario o rol de IAM que tenga permisos para consultar el espacio de trabajo de Prometheus antes de ejecutar los siguientes comandos - Inicie sesión en Grafana y vaya a la página de configuración de fuentes de datos /fuentes de datos para agregar su espacio de trabajo de AMP como fuente de datos. La URL debe estar sin el
/api/v1/queryal final. HabilitarSigV4 auth, luego elija la región adecuada y guarde.

Cuando explora la fuente de datos guardada, puede ver las métricas de la solicitud que acabamos de enviar.

Ahora puede visualizar estas métricas y crear paneles elaborados en Grafana.
Limpiar
Cuando haya terminado de ejecutar los ejemplos, limpie los recursos. Puede usar el siguiente script para eliminar los recursos creados en EMR Serverless, Amazon Managed Prometheus y Amazon ECR. Pase la Región y, opcionalmente, el ID del espacio de trabajo de Amazon Managed Prometheus como argumentos al script. Tenga en cuenta que este script no eliminará las aplicaciones EMR Serverless en Running de estado.
Conclusión
En esta publicación, aprendió a usar imágenes personalizadas con Amazon EMR Serverless para abordar algunos casos de uso comunes. Para obtener más información sobre cómo crear imágenes personalizadas o ver ejemplos de Dockerfiles, consulte Personalización de la imagen de EMR Serverless y Muestras de imágenes personalizadas.
Sobre la autora
 Veena Vasudevan es arquitecta sénior de soluciones de socios y especialista de Amazon EMR en AWS y se enfoca en Big Data y análisis. Ayuda a los clientes y socios a crear soluciones altamente optimizadas, escalables y seguras; modernizar sus arquitecturas; y migrar sus cargas de trabajo de Big Data a AWS.
Veena Vasudevan es arquitecta sénior de soluciones de socios y especialista de Amazon EMR en AWS y se enfoca en Big Data y análisis. Ayuda a los clientes y socios a crear soluciones altamente optimizadas, escalables y seguras; modernizar sus arquitecturas; y migrar sus cargas de trabajo de Big Data a AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/add-your-own-libraries-and-application-dependencies-to-spark-and-hive-on-amazon-emr-serverless-with-custom-images/

