Hoy nos complace anunciar que Zona de datos de Amazon ahora puede presentar información sobre la calidad de los datos para los activos de datos. Esta información permite a los usuarios finales tomar decisiones informadas sobre si utilizar o no activos específicos.
Muchas organizaciones ya utilizan Calidad de datos de AWS Glue definir y hacer cumplir reglas de calidad de datos en sus datos, validar datos contra reglas predefinidas, realizar un seguimiento de las métricas de calidad de los datos y monitorear la calidad de los datos a lo largo del tiempo utilizando inteligencia artificial (IA). Otras organizaciones monitorean la calidad de sus datos a través de soluciones de terceros.
Amazon DataZone ahora se integra directamente con AWS Glue para mostrar puntuaciones de calidad de datos para los activos del catálogo de datos de AWS Glue. Además, Amazon DataZone ahora ofrece API para importar puntuaciones de calidad de datos desde sistemas externos.
En esta publicación, analizamos las características más recientes de Amazon DataZone para la calidad de los datos, la integración entre Amazon DataZone y AWS Glue Data Quality y cómo puede importar puntuaciones de calidad de datos producidas por sistemas externos a Amazon DataZone a través de API.
Desafios
Una de las preguntas más comunes que recibimos de los clientes está relacionada con la visualización de puntuaciones de calidad de datos en el Catálogo de datos empresariales de Amazon DataZone para permitir que los usuarios empresariales tengan visibilidad del estado y la confiabilidad de los conjuntos de datos.
A medida que los datos se vuelven cada vez más cruciales para impulsar las decisiones comerciales, los usuarios de Amazon DataZone están muy interesados en proporcionar los más altos estándares de calidad de datos. Reconocen la importancia de contar con datos precisos, completos y oportunos para permitir la toma de decisiones informadas y fomentar la confianza en sus procesos de análisis e informes.
Los activos de datos de Amazon DataZone se pueden actualizar con distintas frecuencias. A medida que los datos se actualizan y actualizan, pueden ocurrir cambios a través de procesos ascendentes que los ponen en riesgo de no mantener la calidad deseada. Los puntajes de calidad de los datos lo ayudan a comprender si los datos han mantenido el nivel esperado de calidad para que los utilicen los consumidores (a través de análisis o procesos posteriores).
Desde la perspectiva de un productor, los administradores de datos ahora pueden configurar Amazon DataZone para importar automáticamente los puntajes de calidad de los datos de AWS Glue Data Quality (programados o bajo demanda) e incluir esta información en el catálogo de Amazon DataZone para compartirla con los usuarios comerciales. Además, ahora puede utilizar las nuevas API de Amazon DataZone para importar puntuaciones de calidad de datos producidas por sistemas externos a los activos de datos.
Con la última mejora, los usuarios de Amazon DataZone ahora pueden lograr lo siguiente:
- Acceda a información sobre estándares de calidad de datos directamente desde el portal web de Amazon DataZone
- Ver puntuaciones de calidad de datos en varios KPI, incluida la integridad, singularidad y precisión de los datos.
- Asegúrese de que los usuarios tengan una visión holística de la calidad y confiabilidad de sus datos.
En la primera parte de esta publicación, analizamos la integración entre AWS Glue Data Quality y Amazon DataZone. Analizamos cómo visualizar puntuaciones de calidad de datos en Amazon DataZone, habilitar AWS Glue Data Quality al crear una nueva fuente de datos de Amazon DataZone y habilitar la calidad de datos para un activo de datos existente.
En la segunda parte de esta publicación, analizamos cómo importar puntuaciones de calidad de datos producidas por sistemas externos a Amazon DataZone a través de API. En este ejemplo, utilizamos Amazon EMR sin servidor en combinación con la biblioteca de código abierto Pydeequ actuar como un sistema externo para la calidad de los datos.
Visualice las puntuaciones de calidad de datos de AWS Glue en Amazon DataZone
Ahora puede visualizar las puntuaciones de calidad de datos de AWS Glue en activos de datos que se han publicado en el catálogo empresarial de Amazon DataZone y que se pueden buscar a través del portal web de Amazon DataZone.
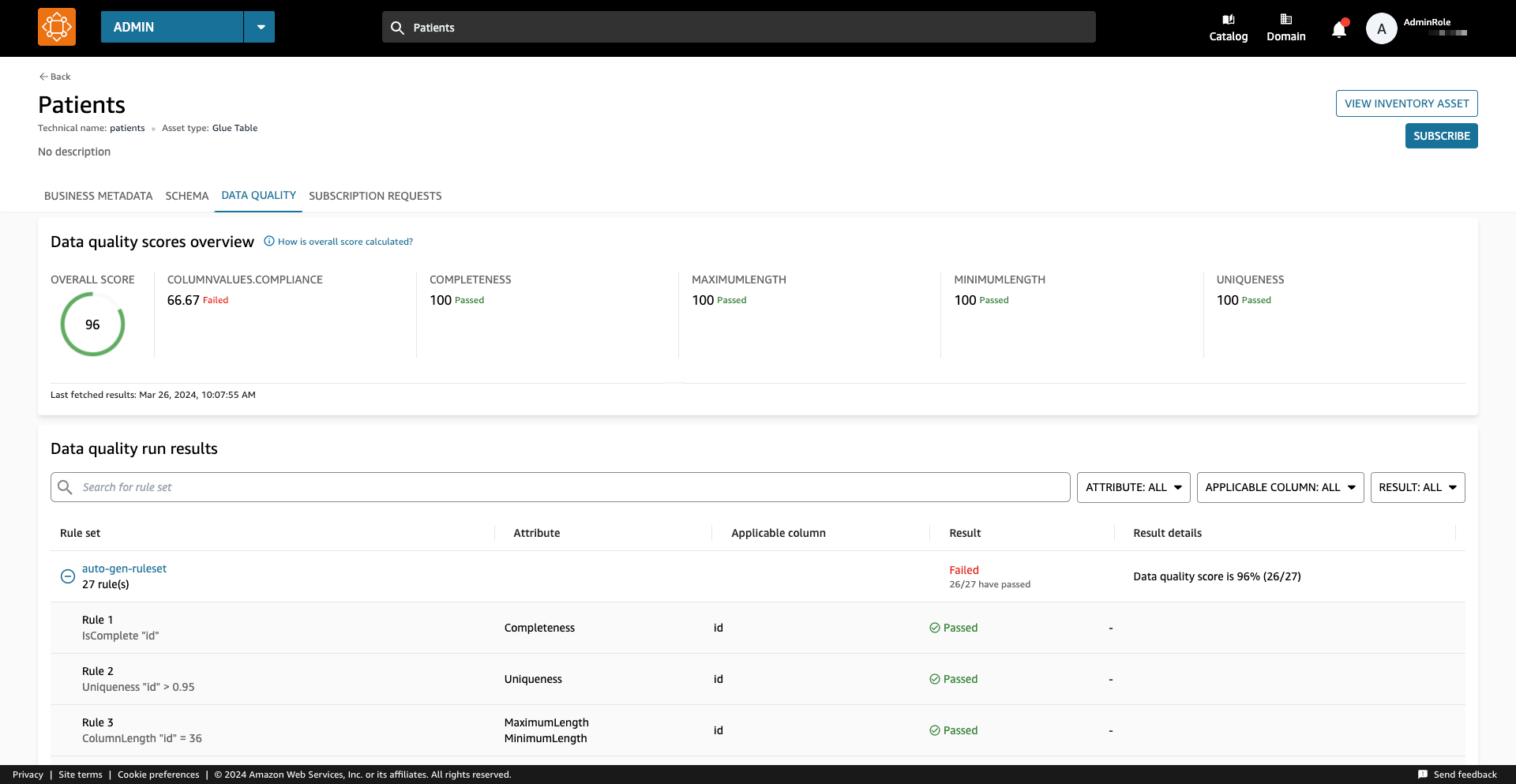
Si el activo tiene habilitada la calidad de datos de AWS Glue, ahora puede visualizar rápidamente el puntaje de calidad de los datos directamente en el panel de búsqueda del catálogo.

Al seleccionar el activo correspondiente, podrá comprender su contenido a través del archivo Léame, términos del glosarioy metadatos técnicos y comerciales. Además, el indicador de puntuación de calidad general se muestra en la Detalles del activo .

Un puntaje de calidad de datos sirve como un indicador general de la calidad de un conjunto de datos, calculado en función de las reglas que usted define.
En Calidad de datos pestaña, puede acceder a los detalles de los indicadores de descripción general de la calidad de los datos y a los resultados de las ejecuciones de calidad de los datos.
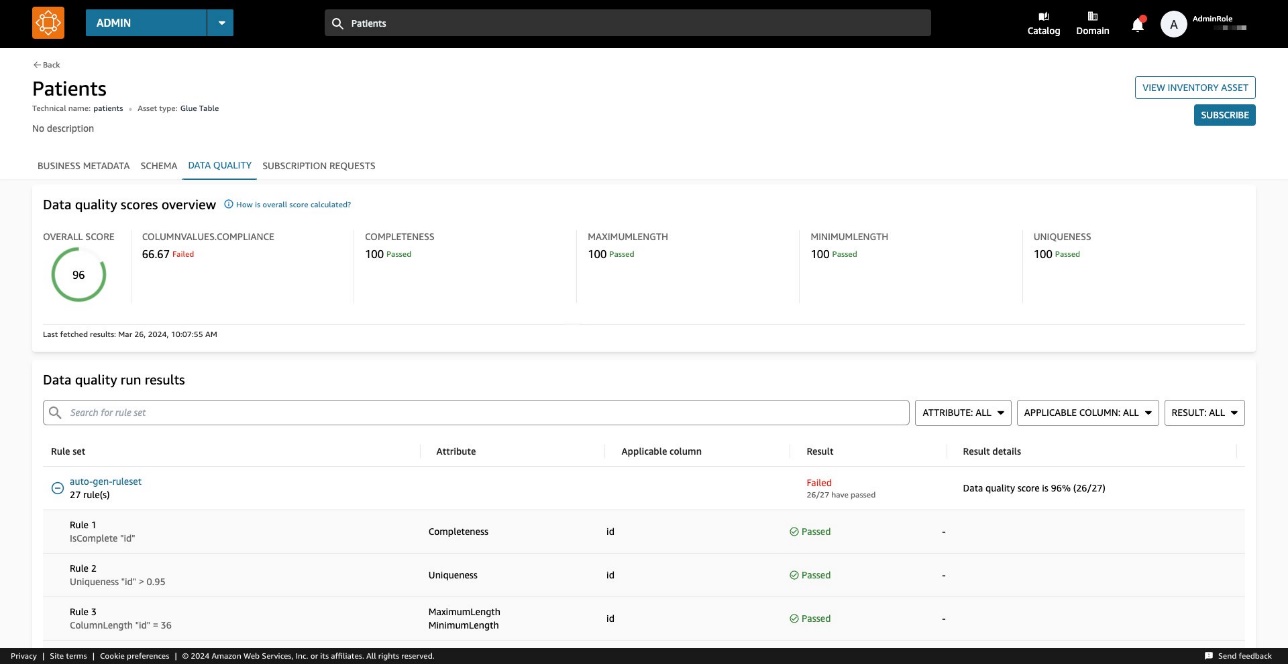
Los indicadores mostrados en el General La pestaña se calcula en función de los resultados de los conjuntos de reglas de las ejecuciones de calidad de datos.
A cada regla se le asigna un atributo que contribuye al cálculo del indicador. Por ejemplo, las reglas que tienen la Completeness El atributo contribuirá al cálculo del indicador correspondiente en el General .
Para filtrar los resultados de calidad de los datos, elija la opción Columna aplicable menú desplegable y elija el parámetro de filtro que desee.

También puede visualizar la calidad de los datos a nivel de columna comenzando en la Esquema .

Cuando la calidad de los datos está habilitada para el activo, los resultados de la calidad de los datos están disponibles, lo que proporciona puntuaciones de calidad reveladoras que reflejan la integridad y confiabilidad de cada columna dentro del conjunto de datos.
Cuando elige uno de los enlaces de resultados de calidad de los datos, se le redirige a la página de detalles de la calidad de los datos, filtrada por la columna seleccionada.

Resultados históricos de calidad de datos en Amazon DataZone
La calidad de los datos puede cambiar con el tiempo por muchas razones:
- Los formatos de datos pueden cambiar debido a cambios en los sistemas de origen.
- A medida que los datos se acumulan con el tiempo, pueden volverse obsoletos o inconsistentes.
- La calidad de los datos puede verse afectada por errores humanos en la entrada, el procesamiento o la manipulación de datos.
En Amazon DataZone, ahora puede realizar un seguimiento de la calidad de los datos a lo largo del tiempo para confirmar la confiabilidad y precisión. Al analizar la instantánea del informe histórico, puede identificar áreas de mejora, implementar cambios y medir la efectividad de esos cambios.

Habilite la calidad de datos de AWS Glue al crear una nueva fuente de datos de Amazon DataZone
En esta sección, explicamos los pasos para habilitar AWS Glue Data Quality al crear una nueva fuente de datos de Amazon DataZone.
Requisitos previos
Para seguir adelante, debe tener un dominio para Amazon DataZone, un proyecto de Amazon DataZone y un nuevo Entorno de Amazon DataZone (con un DataLakeProfile). Para obtener instrucciones, consulte Inicio rápido de Amazon DataZone con datos de AWS Glue.
También debe definir y ejecutar un conjunto de reglas para sus datos, que es un conjunto de reglas de calidad de datos en AWS Glue Data Quality. Para configurar las reglas de calidad de datos y obtener más información sobre el tema, consulte las siguientes publicaciones:
Después de crear las reglas de calidad de datos, asegúrese de que Amazon DataZone tenga los permisos para acceder a la base de datos de AWS Glue administrada a través de Formación del lago AWS. Para instrucciones, vea Configurar permisos de Lake Formation para Amazon DataZone.
En nuestro ejemplo, hemos configurado un conjunto de reglas en función de una tabla que contiene datos de pacientes dentro de un conjunto de datos sintéticos de atención médica generado usando Sintea. Synthea es un generador de pacientes sintético que crea datos realistas de pacientes y registros médicos asociados que pueden usarse para probar aplicaciones de software de atención médica.
El conjunto de reglas contiene 27 reglas individuales (una de las cuales falla), por lo que la puntuación general de calidad de los datos es del 96 %.
Si utiliza políticas administradas de Amazon DataZone, no es necesario realizar ninguna acción porque se actualizarán automáticamente con las acciones necesarias. De lo contrario, debe permitir que Amazon DataZone tenga los permisos necesarios para enumerar y obtener resultados de calidad de datos de AWS Glue, como se muestra en la Guía del usuario de Amazon DataZone.
Crear una fuente de datos con la calidad de datos habilitada
En esta sección, creamos una fuente de datos y habilitamos la calidad de los datos. También puede actualizar una fuente de datos existente para habilitar la calidad de los datos. Utilizamos esta fuente de datos para importar información de metadatos relacionados con nuestros conjuntos de datos. Amazon DataZone también importará información sobre la calidad de los datos relacionada con los (uno o más) activos contenidos en la fuente de datos.
- En la consola de Amazon DataZone, elija Fuentes de datos en el panel de navegación.
- Elige Crear fuente de datos.

- Nombre, ingrese un nombre para su fuente de datos.
- Tipo de fuente de datos, seleccione Pegamento AWS.
- Entorno, elige tu entorno.

- Nombre de la base de datos, introduzca un nombre para la base de datos.
- Criterios de selección de mesa., elige tu criterio.
- Elige Siguiente.

- Calidad de datos, seleccione Habilitar la calidad de los datos para esta fuente de datos.
Si la calidad de los datos está habilitada, Amazon DataZone obtendrá automáticamente puntuaciones de calidad de los datos de AWS Glue en cada ejecución de la fuente de datos.
- Elige Siguiente.

Ahora puede ejecutar la fuente de datos.

Mientras ejecuta la fuente de datos, Amazon DataZone importa los últimos 100 resultados de ejecución de AWS Glue Data Quality. Esta información ahora está visible en la página del activo y será visible para todos los usuarios de Amazon DataZone después de publicar el activo.
Habilitar la calidad de los datos para un activo de datos existente
En esta sección, habilitamos la calidad de los datos para un activo existente. Esto puede resultar útil para los usuarios que ya tienen fuentes de datos implementadas y desean habilitar la función más adelante.
Requisitos previos
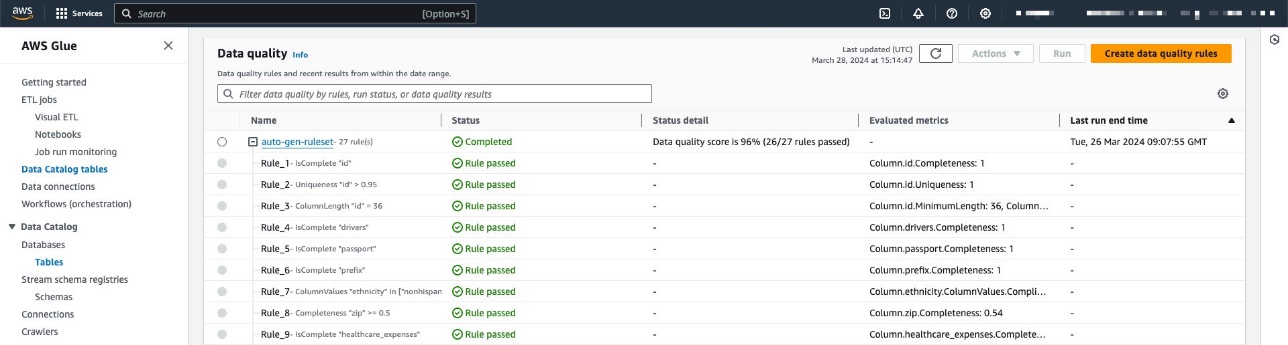
Para seguir adelante, ya debería haber ejecutado la fuente de datos y producido un recurso de datos de tabla de AWS Glue. Además, debería haber definido un conjunto de reglas en AWS Glue Data Quality sobre la tabla de destino en el catálogo de datos.

Para este ejemplo, ejecutamos el trabajo de calidad de datos varias veces en la tabla, generando las puntuaciones de calidad de datos de AWS Glue relacionadas, como se muestra en la siguiente captura de pantalla.

Importar puntuaciones de calidad de datos al activo de datos
Complete los siguientes pasos para importar las puntuaciones de calidad de datos de AWS Glue existentes al activo de datos en Amazon DataZone:
- Dentro del proyecto Amazon DataZone, navegue hasta el Datos de inventario y elija la fuente de datos.
Si elige la Calidad de datos , puede ver que todavía no hay información sobre la calidad de los datos porque la integración de AWS Glue Data Quality aún no está habilitada para este activo de datos.
- En Calidad de datos pestaña, elegir Habilitar la calidad de los datos.

- En Calidad de datos sección, seleccionar Habilitar la calidad de los datos para esta fuente de datos.
- Elige Guardar.

Ahora, de vuelta en el panel de datos del inventario, puede ver una nueva pestaña: Calidad de datos.
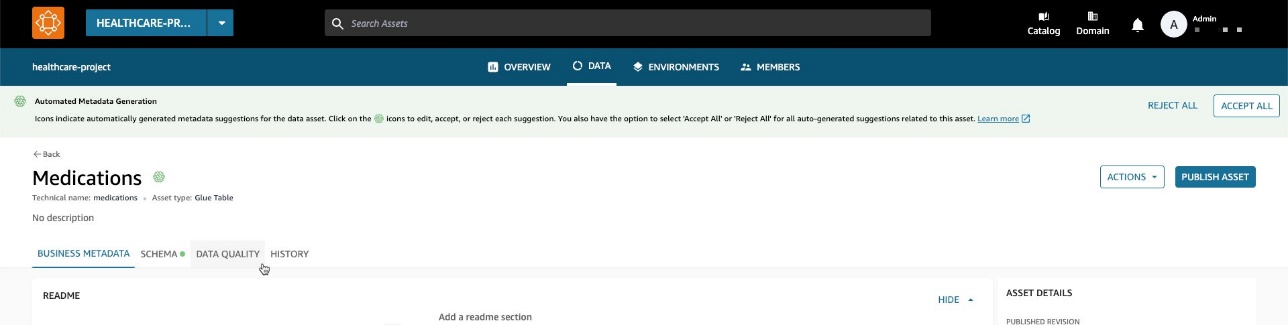
En Calidad de datos , puede ver las puntuaciones de calidad de los datos importadas desde AWS Glue Data Quality.
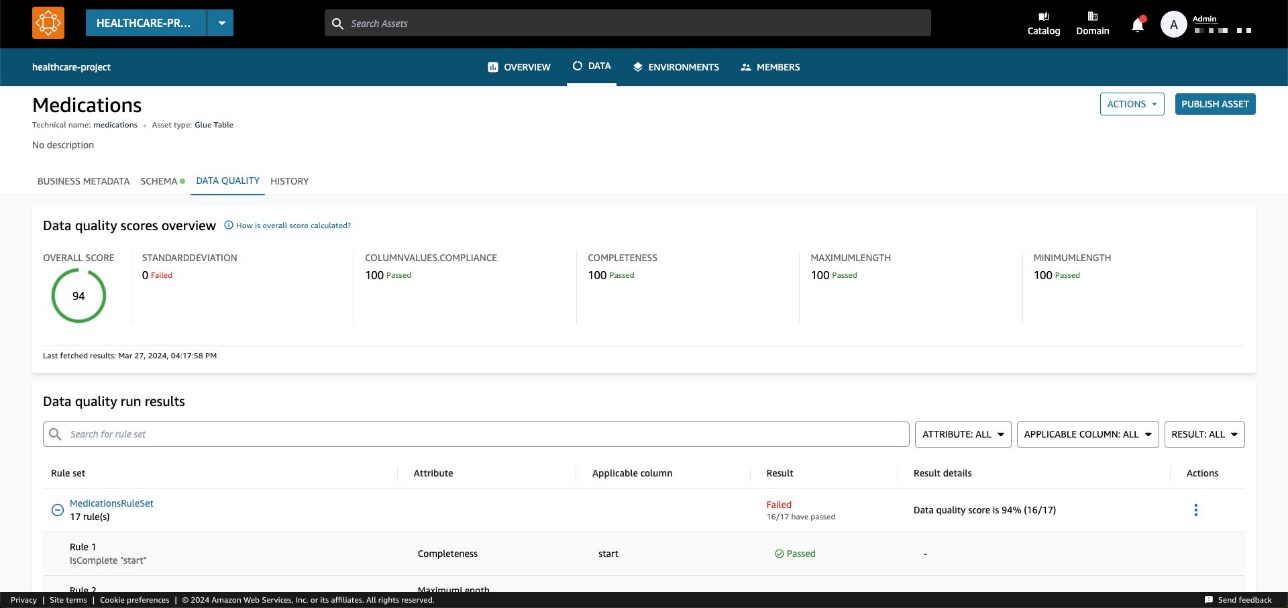
Ingerir puntuaciones de calidad de datos de una fuente externa mediante las API de Amazon DataZone
Muchas organizaciones ya utilizan sistemas que calculan la calidad de los datos realizando pruebas y afirmaciones en sus conjuntos de datos. Amazon DataZone ahora admite la importación de puntuaciones de calidad de datos originadas por terceros a través de API, permitiendo a los usuarios que navegan por el portal web visualizar esta información.
En esta sección, simulamos un sistema de terceros que envía puntuaciones de calidad de datos a Amazon DataZone a través de API a través de boto3 (SDK de Python para AWS).
Para este ejemplo, utilizamos el mismo conjunto de datos sintético como antes, generado con Sintea.
El siguiente diagrama ilustra la arquitectura de la solución.

El flujo de trabajo consta de los siguientes pasos:
- Leer un conjunto de datos de pacientes en Servicio de almacenamiento simple de Amazon (Amazon S3) directamente desde Amazon EMR usando Spark.
El conjunto de datos se crea como una colección de activos S3 genérica en Amazon DataZone.
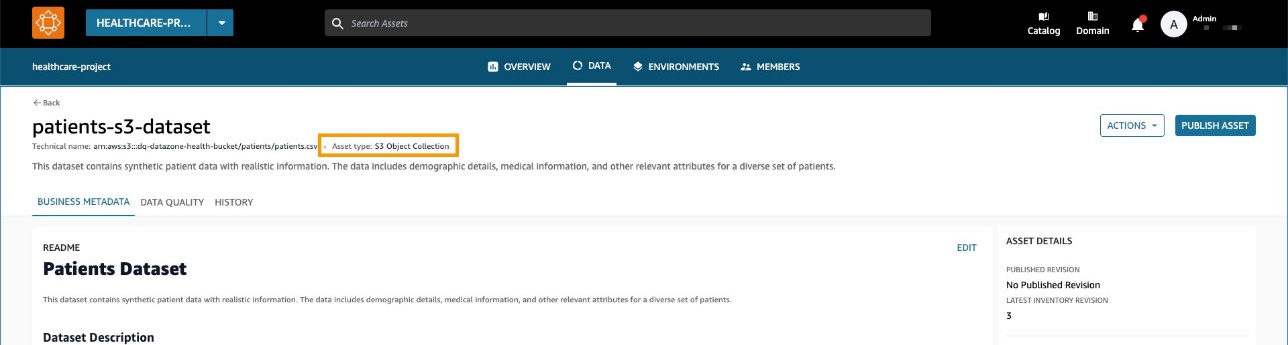
- En Amazon EMR, ejecute reglas de validación de datos con respecto al conjunto de datos.
- Las métricas se guardan en Amazon S3 para tener un resultado persistente.
- Utilice las API de Amazon DataZone a través de Boto3 para impulsar metadatos de calidad de datos personalizados.
- Los usuarios finales pueden ver los puntajes de calidad de los datos navegando al portal de datos.
Requisitos previos
Utilizamos Amazon EMR sin servidor y Pydeequ para ejecutar un sistema totalmente gestionado Spark ambiente. Para obtener más información sobre Pydeequ como marco de prueba de datos, consulte Probar la calidad de los datos a escala con Pydeequ.
Para permitir que Amazon EMR envíe datos al dominio de Amazon DataZone, asegúrese de que la función de IAM utilizada por Amazon EMR tenga los permisos para hacer lo siguiente:
- Leer y escribir en los depósitos de S3
- Llama a el
post_time_series_data_pointsAcción para Amazon DataZone:
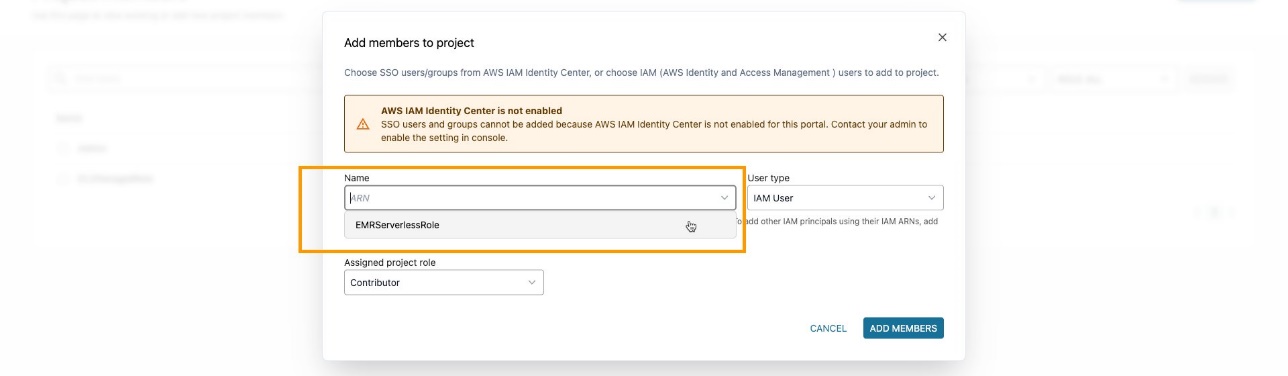
Asegúrese de haber agregado la función EMR como miembro del proyecto en el proyecto Amazon DataZone. En la consola de Amazon DataZone, navegue hasta el miembros del proyecto página y elige Añadir miembros.

Agregue el rol de EMR como colaborador.
Ingerir y analizar código PySpark
En esta sección, analizamos el código PySpark que utilizamos para realizar comprobaciones de calidad de los datos y enviar los resultados a Amazon DataZone. Puedes descargar el completo Secuencia de comandos PySpark.
Para ejecutar el script por completo, puede enviar un trabajo a EMR Serverless. El servicio se encargará de programar el trabajo y asignar automáticamente los recursos necesarios, permitiéndole realizar un seguimiento del estados de ejecución de trabajos durante todo el proceso.
solicite enviar un trabajo a EMR dentro de la consola de Amazon EMR utilizando EMR Studio o mediante programación, utilizando el CLI de AWS o usando uno de los SDK de AWS.
En Apache Spark, un SparkSession es el punto de entrada para interactuar con DataFrames y las funciones integradas de Spark. El script comenzará a inicializar un SparkSession:
Leemos un conjunto de datos de Amazon S3. Para una mayor modularidad, puede utilizar la entrada del script para hacer referencia a la ruta S3:
A continuación, configuramos un repositorio de métricas. Esto puede resultar útil para conservar los resultados de la ejecución en Amazon S3.
Pydeequ le permite crear reglas de calidad de datos utilizando el patrón constructor, que es un patrón de diseño de ingeniería de software bien conocido, que concatena instrucciones para crear instancias de un VerificationSuite :
El siguiente es el resultado de las reglas de validación de datos:
En este punto, queremos insertar estos valores de calidad de datos en Amazon DataZone. Para ello utilizamos el post_time_series_data_points función en el cliente Boto3 Amazon DataZone.
El PostTimeSeriesDataPoints API de zona de datos le permite insertar nuevos puntos de datos de series temporales para un activo o listado determinado, sin crear una nueva revisión.
En este punto, es posible que también desees tener más información sobre qué campos se envían como entrada para la API. Puedes usar el API para obtener la especificación de los tipos de formulario de Amazon DataZone; en nuestro caso es amazon.datazone.DataQualityResultFormType.
También puede utilizar la CLI de AWS para invocar la API y mostrar la estructura del formulario:
Este resultado ayuda a identificar los parámetros de API requeridos, incluidos campos y límites de valores:
Para enviar los datos del formulario apropiados, necesitamos convertir la salida de Pydeequ para que coincida con el DataQualityResultsFormType contrato. Esto se puede lograr con una función de Python que procese los resultados.
Para cada fila del DataFrame, extraemos información de la columna de restricción. Por ejemplo, tome el siguiente código:
Lo convertimos a lo siguiente:
Asegúrese de enviar un resultado que coincida con los KPI de los que desea realizar un seguimiento. En nuestro caso, estamos agregando _custom al nombre de la estadística, lo que da como resultado el siguiente formato para los KPI:
Completeness_customUniqueness_custom
En un escenario del mundo real, es posible que desee establecer un valor que coincida con su marco de calidad de datos en relación con los KPI de los que desea realizar un seguimiento en Amazon DataZone.
Después de aplicar una función de transformación, tenemos un objeto Python para cada evaluación de regla:
También usamos el constraint_status columna para calcular la puntuación general:
En nuestro ejemplo, esto da como resultado un porcentaje de aprobación del 85.71%.
Establecemos este valor en el passingPercentage campo de entrada junto con la otra información relacionada con las evaluaciones en la entrada del método Boto3 post_time_series_data_points:
Boto3 invoca el API de Amazon DataZone. En estos ejemplos, utilizamos Boto3 y Python, pero puedes elegir uno de los SDK de AWS desarrollado en el idioma que prefieras.
Después de configurar el dominio y el ID del activo adecuados y ejecutar el método, podemos verificar en la consola de Amazon DataZone que la calidad de los datos del activo ahora es visible en la página del activo.
Podemos observar que la puntuación general coincide con el valor de entrada de la API. También podemos ver que pudimos agregar KPI personalizados en la pestaña de descripción general a través de valores de parámetros de tipos personalizados.
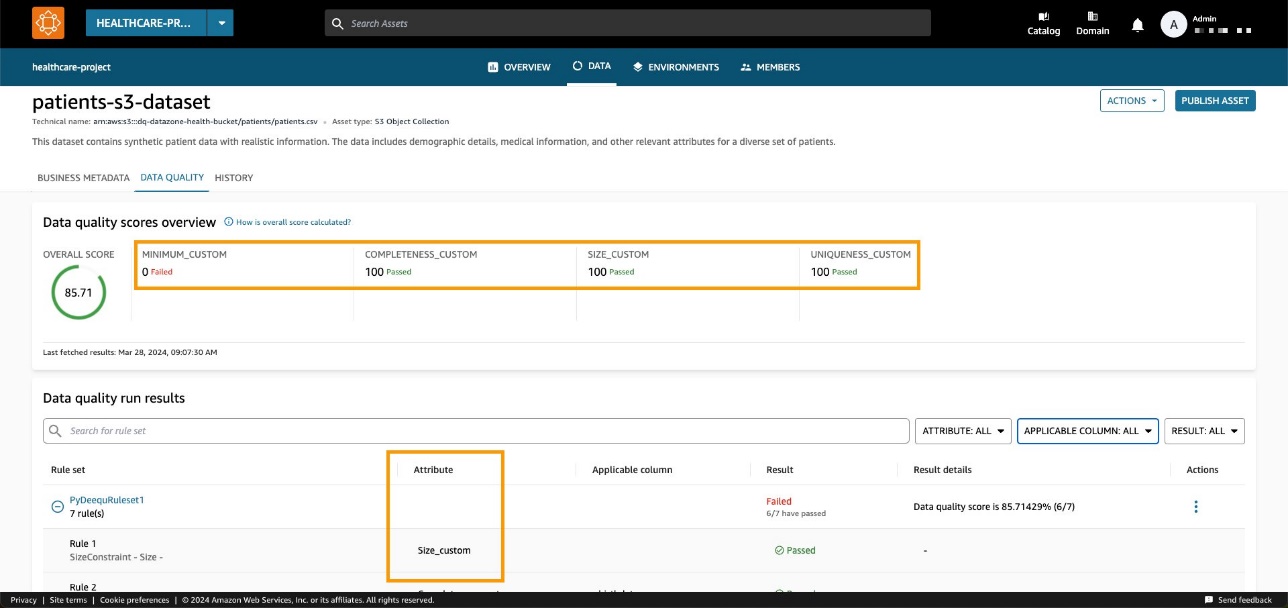
Con las nuevas API de Amazon DataZone, puede cargar reglas de calidad de datos desde sistemas de terceros en un activo de datos específico. Con esta capacidad, Amazon DataZone le permite ampliar los tipos de indicadores presentes en AWS Glue Data Quality (como integridad, mínimo y unicidad) con indicadores personalizados.
Limpiar
Recomendamos eliminar cualquier recurso potencialmente no utilizado para evitar incurrir en costos inesperados. Por ejemplo, puedes eliminar el dominio de Amazon DataZone y del aplicación REM que creaste durante este proceso.
Conclusión
En esta publicación, destacamos las características más recientes de Amazon DataZone para la calidad de los datos, brindando a los usuarios finales un contexto y una visibilidad mejorados de sus activos de datos. Además, profundizamos en la perfecta integración entre Amazon DataZone y AWS Glue Data Quality. También puede utilizar las API de Amazon DataZone para integrarse con proveedores de calidad de datos externos, lo que le permitirá mantener una estrategia de datos integral y sólida dentro de su entorno de AWS.
Para obtener más información sobre Amazon DataZone, consulte la Guía del usuario de Amazon DataZone.
Acerca de los autores
 Andrea Filippo es arquitecto de soluciones de socios en AWS y brinda soporte a socios y clientes del sector público en Italia. Se centra en arquitecturas de datos modernas y en ayudar a los clientes a acelerar su viaje a la nube con tecnologías sin servidor.
Andrea Filippo es arquitecto de soluciones de socios en AWS y brinda soporte a socios y clientes del sector público en Italia. Se centra en arquitecturas de datos modernas y en ayudar a los clientes a acelerar su viaje a la nube con tecnologías sin servidor.
 Emanuele es Arquitecto de Soluciones en AWS, con base en Italia, después de vivir y trabajar durante más de 5 años en España. Le gusta ayudar a grandes empresas con la adopción de tecnologías en la nube y su área de especialización se centra principalmente en Análisis y Gestión de Datos. Fuera del trabajo, le gusta viajar y coleccionar figuras de acción.
Emanuele es Arquitecto de Soluciones en AWS, con base en Italia, después de vivir y trabajar durante más de 5 años en España. Le gusta ayudar a grandes empresas con la adopción de tecnologías en la nube y su área de especialización se centra principalmente en Análisis y Gestión de Datos. Fuera del trabajo, le gusta viajar y coleccionar figuras de acción.
 Varsha Velagapudi es gerente técnico senior de productos en Amazon DataZone en AWS. Se centra en mejorar el descubrimiento y la curación de datos necesarios para el análisis de datos. Le apasiona simplificar el recorrido de análisis e IA/ML de los clientes para ayudarlos a tener éxito en sus tareas diarias. Fuera del trabajo, disfruta de la naturaleza y las actividades al aire libre, la lectura y los viajes.
Varsha Velagapudi es gerente técnico senior de productos en Amazon DataZone en AWS. Se centra en mejorar el descubrimiento y la curación de datos necesarios para el análisis de datos. Le apasiona simplificar el recorrido de análisis e IA/ML de los clientes para ayudarlos a tener éxito en sus tareas diarias. Fuera del trabajo, disfruta de la naturaleza y las actividades al aire libre, la lectura y los viajes.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/amazon-datazone-now-integrates-with-aws-glue-data-quality-and-external-data-quality-solutions/

