Las organizaciones a menudo necesitan gestionar un gran volumen de datos que crece a un ritmo extraordinario. Al mismo tiempo, necesitan optimizar los costos operativos para desbloquear el valor de estos datos para obtener información oportuna y hacerlo con un rendimiento consistente.
Con este crecimiento masivo de datos, la proliferación de datos en sus almacenes de datos, almacenes de datos y lagos de datos puede volverse igualmente desafiante. Con un arquitectura de datos moderna en AWS, puede crear rápidamente lagos de datos escalables; utilizar una colección amplia y profunda de servicios de datos diseñados específicamente; garantizar el cumplimiento a través del acceso, la seguridad y la gobernanza unificados de los datos; escale sus sistemas a bajo costo sin comprometer el rendimiento; y comparta datos a través de los límites organizacionales con facilidad, lo que le permitirá tomar decisiones con velocidad y agilidad a escala.
Puede tomar todos sus datos de varios silos, agregarlos en su lago de datos y realizar análisis y aprendizaje automático (ML) directamente sobre esos datos. También puede almacenar otros datos en almacenes de datos especialmente diseñados para analizar y obtener información rápida a partir de datos estructurados y no estructurados. Este movimiento de datos puede ser de adentro hacia afuera, de afuera hacia adentro, alrededor del perímetro o compartido.
Por ejemplo, los registros de aplicaciones y los seguimientos de las aplicaciones web se pueden recopilar directamente en un lago de datos, y una parte de esos datos se puede trasladar a un almacén de análisis de registros como Amazon OpenSearch Service para su análisis diario. Pensamos en este concepto como De adentro hacia afuera movimiento de datos. Los datos analizados y agregados almacenados en Amazon OpenSearch Service se pueden mover nuevamente al lago de datos para ejecutar algoritmos de aprendizaje automático para el consumo posterior desde las aplicaciones. Nos referimos a este concepto como de fuera hacia dentro movimiento de datos.
Veamos un caso de uso de ejemplo. Ejemplo Corp. es una empresa líder de Fortune 500 que se especializa en contenido social. Tienen cientos de aplicaciones que generan datos y rastreos a aproximadamente 500 TB por día y tienen los siguientes criterios:
- Tenga registros disponibles para análisis rápidos durante 2 días
- Más allá de 2 días, tener datos disponibles en un nivel de almacenamiento que pueda estar disponible para análisis con un SLA razonable.
- Conservar los datos más allá de 1 semana en almacenamiento en frío durante 30 días (para fines de cumplimiento, auditoría y otros)
En las siguientes secciones, analizamos tres posibles soluciones para abordar casos de uso similares:
- Almacenamiento por niveles en Amazon OpenSearch Service y gestión del ciclo de vida de los datos
- Ingestión de registros bajo demanda utilizando Ingestión de Amazon OpenSearch
- Consultas directas de Amazon OpenSearch Service con Amazon Simple Storage Service (Amazon S3)
Solución 1: almacenamiento por niveles en OpenSearch Service y gestión del ciclo de vida de los datos
OpenSearch Service admite tres niveles de almacenamiento integrados: almacenamiento activo, UltraWarm y frío. Según sus requisitos de retención de datos, latencia de consultas y presupuesto, puede elegir la mejor estrategia para equilibrar el costo y el rendimiento. También puede migrar datos entre diferentes niveles de almacenamiento.
El almacenamiento en caliente se utiliza para indexar y actualizar y proporciona el acceso más rápido a los datos. El almacenamiento en caliente toma la forma de un almacén de instancias o Tienda de bloques elásticos de Amazon (Amazon EBS) volúmenes adjuntos a cada nodo.
UltraWarm ofrece costos por GiB significativamente más bajos para datos de solo lectura que consulta con menos frecuencia y no necesita el mismo rendimiento que el almacenamiento activo. Los nodos UltraWarm utilizan Amazon S3 con soluciones de almacenamiento en caché relacionadas para mejorar el rendimiento.
El almacenamiento en frío está optimizado para almacenar datos históricos o a los que se accede con poca frecuencia. Cuando utiliza almacenamiento en frío, desconecta sus índices del nivel UltraWarm, lo que los vuelve inaccesibles. Puede volver a adjuntar estos índices en unos segundos cuando necesite consultar esos datos.
Para obtener más detalles sobre los niveles de datos dentro del servicio OpenSearch, consulte Elija el nivel de almacenamiento adecuado para sus necesidades en Amazon OpenSearch Service.
Resumen de la solución
El flujo de trabajo para esta solución consta de los siguientes pasos:
- Los datos entrantes generados por las aplicaciones se transmiten a un lago de datos S3.
- Los datos se incorporan a Amazon OpenSearch mediante Ingestión de S3-SQS casi en tiempo real a través de notificaciones configuradas en los depósitos de S3.
- Después de 2 días, los datos activos se migran al almacenamiento UltraWarm para admitir consultas de lectura.
- Después de 5 días en UltraWarm, los datos se migran a un almacenamiento en frío durante 21 días y se desconectan de cualquier proceso. Los datos se pueden volver a adjuntar a UltraWarm cuando sea necesario. Los datos se eliminan del almacenamiento en frío después de 21 días.
- Los índices diarios se mantienen para facilitar la transferencia. Una política de gestión del estado del índice (ISM) automatiza la renovación o eliminación de índices que tienen más de 2 días.
A continuación se muestra un ejemplo de política ISM que transfiere datos al nivel UltraWarm después de 2 días, los mueve al almacenamiento en frío después de 5 días y los elimina del almacenamiento en frío después de 21 días:
Consideraciones
UltraWarm utiliza técnicas sofisticadas de almacenamiento en caché para permitir la consulta de datos a los que se accede con poca frecuencia. Aunque el acceso a los datos es poco frecuente, el cálculo de los nodos UltraWarm debe estar ejecutándose todo el tiempo para que este acceso sea posible.
Cuando se opera a escala PB, para reducir el área de efecto de cualquier error, recomendamos descomponer la implementación en varios dominios del servicio OpenSearch cuando se utiliza almacenamiento por niveles.
Los siguientes dos patrones eliminan la necesidad de tener computación de larga duración y describen técnicas bajo demanda donde los datos se traen cuando se necesitan o se consultan directamente donde residen.
Solución 2: ingesta bajo demanda de datos de registros a través de OpenSearch Ingestion
OpenSearch Ingestion es un recopilador de datos totalmente administrado que ofrece datos de registro y seguimiento en tiempo real a los dominios del servicio OpenSearch. OpenSearch Ingestion funciona con el recopilador de datos de código abierto Preparador de datos. Data Prepper es parte del proyecto de código abierto OpenSearch.
Con OpenSearch Ingestion, puede filtrar, enriquecer, transformar y entregar sus datos para su análisis y visualización posteriores. Usted configura sus productores de datos para enviar datos a OpenSearch Ingestion. Entrega automáticamente los datos al dominio o colección que usted especifique. También puede configurar OpenSearch Ingestion para transformar sus datos antes de entregarlos. OpenSearch Ingestion no tiene servidor, por lo que no necesita preocuparse por escalar su infraestructura, operar su flota de ingesta ni parchear o actualizar el software.
Hay dos formas de utilizar Amazon S3 como fuente para procesar datos con OpenSearch Ingestion. La primera opción es el procesamiento S3-SQS. Puede utilizar el procesamiento S3-SQS cuando necesite escanear archivos casi en tiempo real después de escribirlos en S3. Requiere un Servicio de cola simple de Amazon (Amazon S3) cola que recibe Notificaciones de eventos S3. Puede configurar depósitos de S3 para generar un evento cada vez que un objeto se almacene o modifique dentro del depósito que se va a procesar.
Alternativamente, puede utilizar un análisis programado único o recurrente para procesar datos por lotes en un depósito de S3. Para configurar un análisis programado, configure su canalización con un cronograma en el nivel de análisis que se aplica a todos sus depósitos de S3, o en el nivel de depósito. Puede configurar análisis programados con un análisis único o un análisis recurrente para el procesamiento por lotes.
Para obtener una descripción general completa de OpenSearch Ingestion, consulte Ingestión de Amazon OpenSearch. Para obtener más información sobre el proyecto de código abierto Data Prepper, visite Preparador de datos.
Resumen de la solución
Presentamos un patrón de arquitectura con los siguientes componentes clave:
- Los registros de aplicaciones se transmiten al lago de datos, lo que ayuda a introducir datos importantes en el servicio OpenSearch casi en tiempo real mediante OpenSearch Ingestion. Procesamiento S3-SQS.
- Las políticas ISM dentro del servicio OpenSearch manejan las transferencias o eliminaciones de índices. Las políticas de ISM le permiten automatizar estas operaciones administrativas periódicas activándolas en función de los cambios en la antigüedad del índice, el tamaño del índice o la cantidad de documentos. Por ejemplo, puede definir una política que mueva su índice a un estado de solo lectura después de 2 días y luego lo elimine después de un período establecido de 3 días.
- Los datos fríos están disponibles en el lago de datos de S3 para ser consumidos bajo demanda en el servicio OpenSearch mediante OpenSearch Ingestion. exploraciones programadas.
El siguiente diagrama ilustra la arquitectura de la solución.
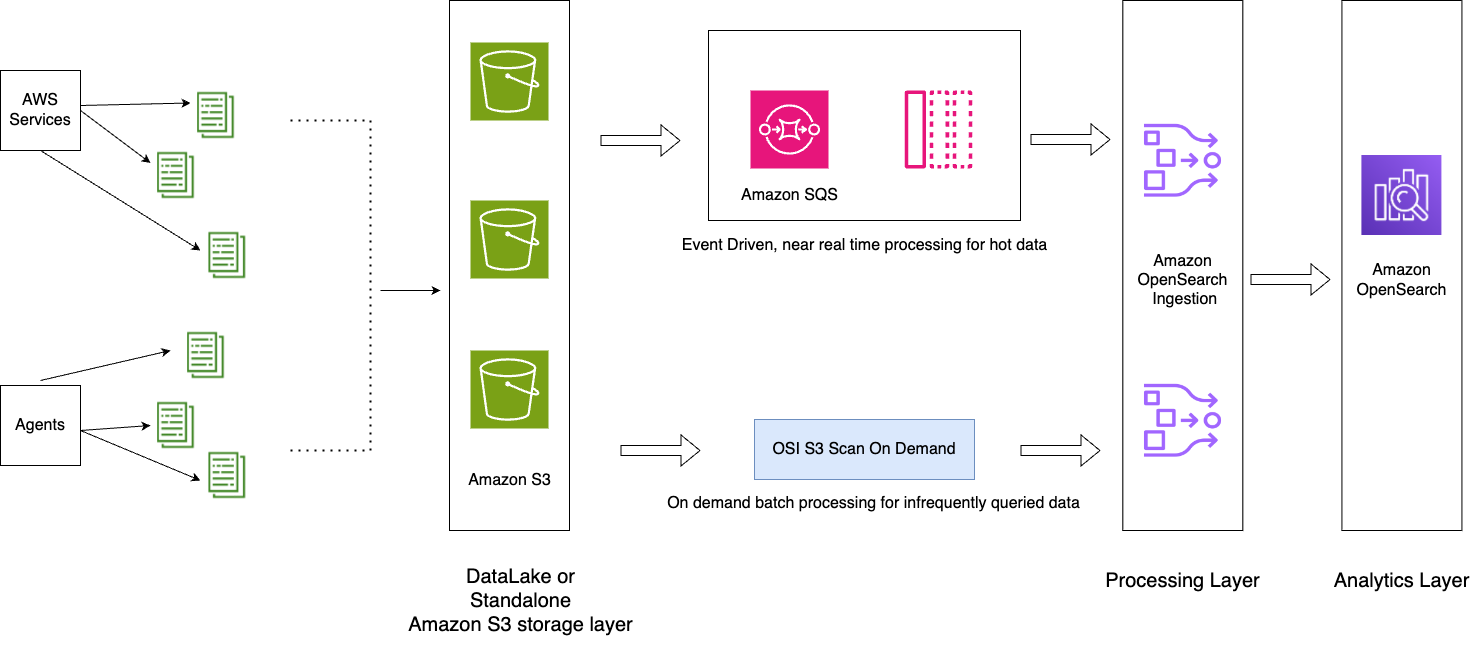
El flujo de trabajo incluye los siguientes pasos:
- Los datos entrantes generados por las aplicaciones se transmiten al lago de datos de S3.
- Para el día actual, los datos se incorporan al servicio OpenSearch mediante la ingesta casi en tiempo real de S3-SQS a través de notificaciones configuradas en los depósitos de S3.
- Los índices diarios se mantienen para facilitar la transferencia. Una política ISM automatiza la renovación o eliminación de índices que tienen más de 2 días.
- Si se realiza una solicitud para el análisis de datos más allá de 2 días y los datos no están en el nivel UltraWarm, los datos se ingerirán utilizando la función de escaneo único de Amazon S3 entre el período de tiempo específico.
Por ejemplo, si el día actual es el 10 de enero de 2024 y necesita datos del 6 de enero de 2024 en un intervalo específico para el análisis, puede crear una canalización de ingesta de OpenSearch con un análisis de Amazon S3 en su configuración de YAML, con el start_time y end_time para especificar cuándo desea que se analicen los objetos del depósito:
Consideraciones
Aprovecha la compresión
Los datos de Amazon S3 se pueden comprimir, lo que reduce el espacio total de datos y genera importantes ahorros de costos. Por ejemplo, si genera 15 PB de registros de aplicaciones JSON sin formato por mes, puede utilizar un mecanismo de compresión como GZIP, que puede reducir el tamaño a aproximadamente 1 PB o menos, lo que genera importantes ahorros de costos.
Detener el oleoducto cuando sea posible
OpenSearch Ingestion escala automáticamente entre las OCU mínimas y máximas establecidas para la canalización. Una vez que la canalización ha completado el análisis de Amazon S3 durante la duración especificada mencionada en la configuración de la canalización, la canalización continúa ejecutándose para un monitoreo continuo en las OCU mínimas.
Para la ingesta bajo demanda durante periodos de tiempo pasados en los que no espera que se creen nuevos objetos, considere usar métricas de canalización admitidas, como recordsOut.count crear Reloj en la nube de Amazon alarmas que pueden detener el oleoducto. Para obtener una lista de métricas admitidas, consulte Monitoreo de métricas de canalización.
Las alarmas de CloudWatch realizan una acción cuando una métrica de CloudWatch excede un valor específico durante un período de tiempo. Por ejemplo, es posible que desee monitorear recordsOut.count ser 0 durante más de 5 minutos para iniciar una solicitud a detener el oleoducto a través de Interfaz de línea de comandos de AWS (AWS CLI) o API.
Solución 3: consultas directas del servicio OpenSearch con Amazon S3
Consultas directas del servicio OpenSearch con Amazon S3 (versión preliminar) es una nueva forma de consultar registros operativos en Amazon S3 y lagos de datos S3 sin necesidad de cambiar entre servicios. Ahora puede analizar datos consultados con poca frecuencia en almacenes de objetos en la nube y utilizar simultáneamente las capacidades de visualización y análisis operativos de OpenSearch Service.
Las consultas directas del servicio OpenSearch con Amazon S3 proporcionan integración ETL cero para reducir la complejidad operativa de duplicar datos o administrar múltiples herramientas de análisis al permitirle consultar directamente sus datos operativos, lo que reduce los costos y el tiempo de acción. Esta integración de ETL cero se puede configurar dentro de OpenSearch Service, donde puede aprovechar varias plantillas de tipos de registros, incluidos paneles predefinidos, y configurar aceleraciones de datos adaptadas a ese tipo de registro. Las plantillas incluyen Registros de flujo de VPC, Equilibrio de carga elástica registros y registros NGINX, y las aceleraciones incluyen índices de omisión, vistas materializadas e índices cubiertos.
Con las consultas directas de OpenSearch Service con Amazon S3, puede realizar consultas complejas que son fundamentales para la seguridad forense y el análisis de amenazas, y correlacionar datos entre múltiples fuentes de datos, lo que ayuda a los equipos a investigar el tiempo de inactividad del servicio y los eventos de seguridad. Después de crear una integración, puede comenzar a consultar sus datos directamente desde los paneles de OpenSearch o la API de OpenSearch. Puede auditar las conexiones para asegurarse de que estén configuradas de forma escalable, rentable y segura.
Las consultas directas desde OpenSearch Service a Amazon S3 utilizan tablas Spark dentro del Pegamento AWS Catálogo de datos. Una vez catalogada la tabla en su catálogo de metadatos de AWS Glue, puede ejecutar consultas directamente en sus datos en su lago de datos de S3 a través de OpenSearch Dashboards.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución.
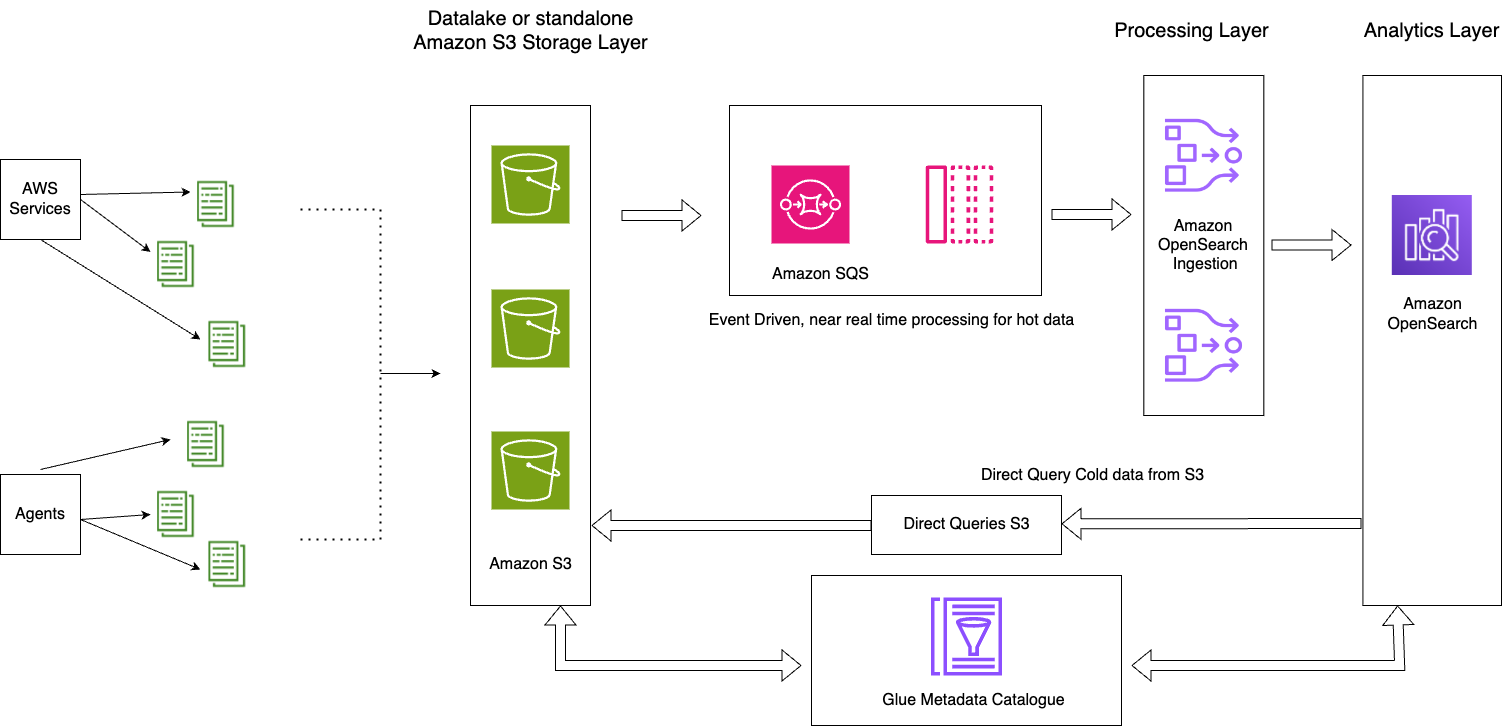
Esta solución consta de los siguientes componentes clave:
- Los datos importantes del día actual se procesan en secuencia en los dominios del servicio OpenSearch a través del patrón de arquitectura basada en eventos utilizando la función de procesamiento OpenSearch Ingestion S3-SQS.
- El ciclo de vida de los datos activos se gestiona a través de políticas ISM adjuntas a índices diarios.
- Los datos fríos residen en su depósito de Amazon S3 y están particionados y catalogados.
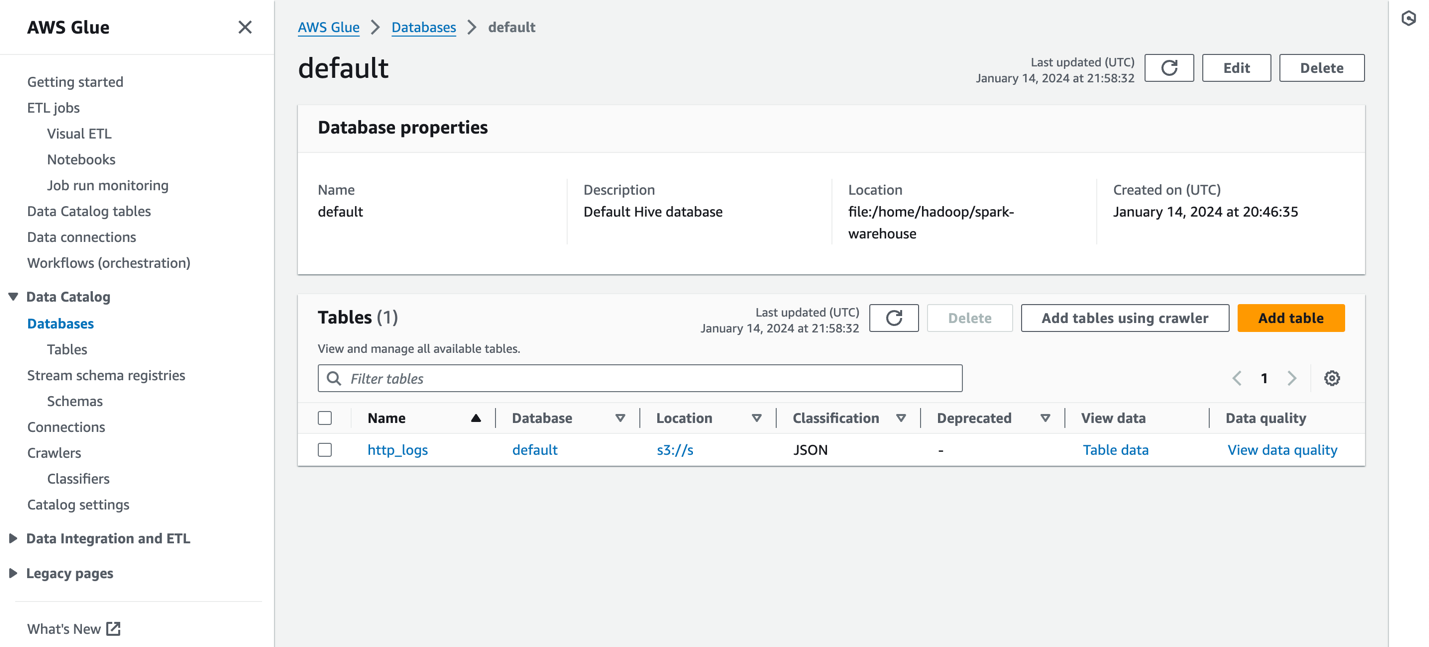
La siguiente captura de pantalla muestra un ejemplo. http_logs tabla que está catalogada en el catálogo de metadatos de AWS Glue. Para conocer los pasos detallados, consulte Catálogo de datos y rastreadores en AWS Glue.
Antes de crear una fuente de datos, debe tener un dominio de servicio OpenSearch con la versión 2.11 o posterior y una tabla S3 de destino en el catálogo de datos de AWS Glue con la información adecuada. Gestión de identidades y accesos de AWS (IAM) permisos. IAM necesitará acceso a los depósitos S3 deseados y acceso de lectura y escritura al catálogo de datos de AWS Glue. A continuación se muestra un ejemplo de función y política de confianza con los permisos adecuados para acceder al catálogo de datos de AWS Glue a través del servicio OpenSearch:
La siguiente es una política personalizada de ejemplo con acceso a Amazon S3 y AWS Glue:
Para crear una nueva fuente de datos en la consola del servicio OpenSearch, proporcione el nombre de su nueva fuente de datos, especifique el tipo de fuente de datos como Amazon S3 con el catálogo de datos de AWS Gluey elija la función de IAM para su fuente de datos.
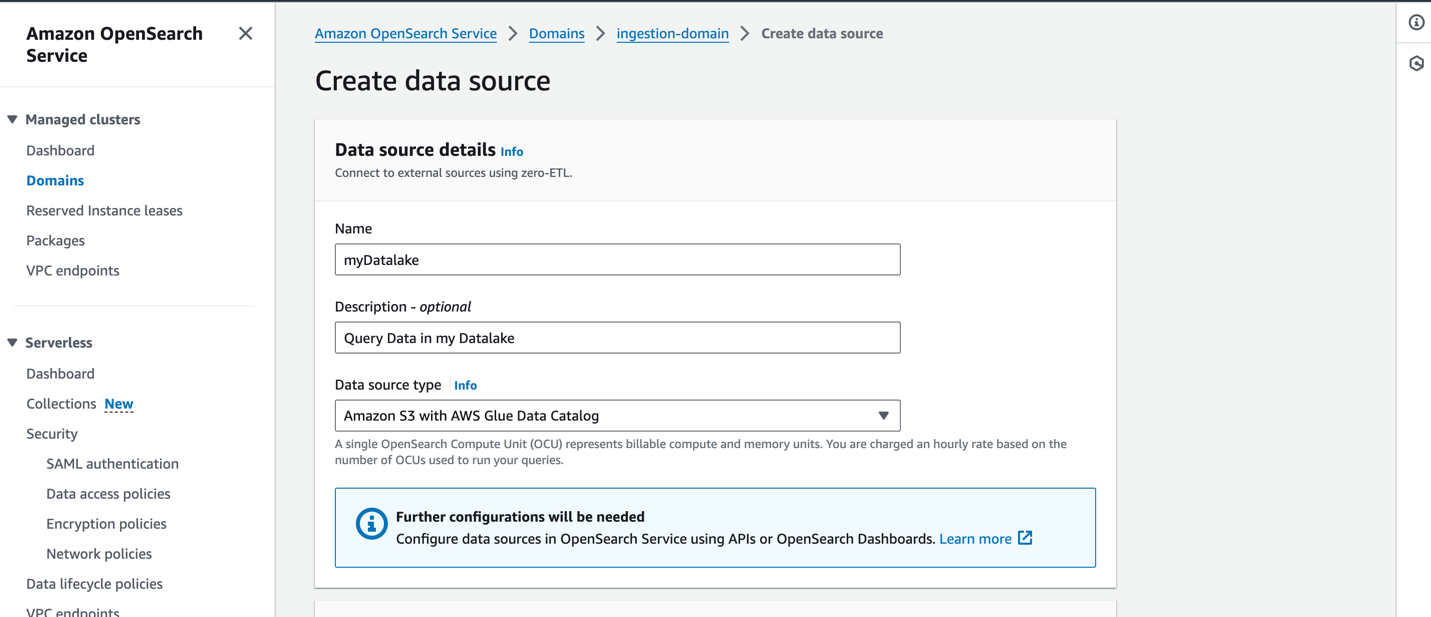
Después de crear una fuente de datos, puede ir al panel de OpenSearch del dominio, que utiliza para configurar el control de acceso, definir tablas, configurar paneles basados en tipos de registros para tipos de registros populares y consultar sus datos.

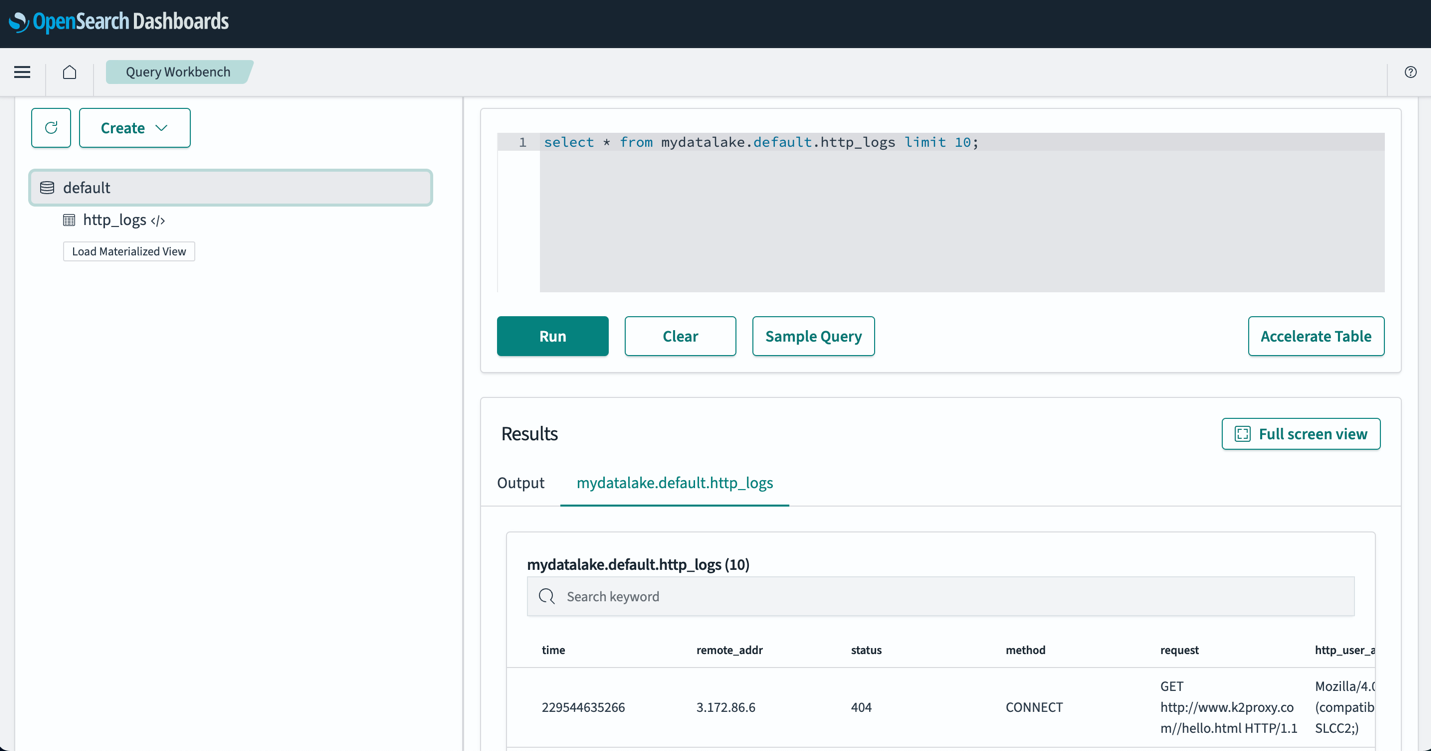
Después de configurar sus tablas, puede consultar sus datos en su lago de datos S3 a través de OpenSearch Dashboards. Puede ejecutar una consulta SQL de ejemplo para el http_logs tabla que creó en las tablas del catálogo de datos de AWS Glue, como se muestra en la siguiente captura de pantalla.
Mejores prácticas
Ingiere solo los datos que necesitas
Trabaje hacia atrás a partir de las necesidades de su negocio y establezca los conjuntos de datos correctos que necesitará. Evalúe si puede evitar la ingesta de datos ruidosos e ingerir solo datos seleccionados, muestreados o agregados. El uso de estos conjuntos de datos limpios y seleccionados lo ayudará a optimizar los recursos informáticos y de almacenamiento necesarios para ingerir estos datos.
Reducir el tamaño de los datos antes de la ingestión
Cuando diseñe sus canalizaciones de ingesta de datos, utilice estrategias como compresión, filtrado y agregación para reducir el tamaño de los datos ingeridos. Esto permitirá transferir tamaños de datos más pequeños a través de la red y almacenarlos en su capa de datos.
Conclusión
En esta publicación, analizamos soluciones que permiten análisis de registros a escala de petabytes utilizando OpenSearch Service en una arquitectura de datos moderna. Aprendió a crear una canalización de ingesta sin servidor para entregar registros a un dominio de OpenSearch Service, administrar índices a través de políticas ISM, configurar permisos de IAM para comenzar a usar OpenSearch Ingestion y crear la configuración de canalización para los datos en su lago de datos. También aprendió a configurar y utilizar las consultas directas del servicio OpenSearch con la función Amazon S3 (vista previa) para consultar datos de su lago de datos.
Para elegir el patrón de arquitectura adecuado para sus cargas de trabajo cuando utilice OpenSearch Service a escala, considere el rendimiento, la latencia, el costo y el crecimiento del volumen de datos a lo largo del tiempo para tomar la decisión correcta.
- Utilice la arquitectura de almacenamiento por niveles con políticas de Index State Management cuando necesite un acceso rápido a sus datos activos y desee equilibrar el costo y el rendimiento con nodos UltraWarm para datos de solo lectura.
- Utilice la ingesta bajo demanda de sus datos en el servicio OpenSearch cuando pueda tolerar latencias de ingesta para consultar los datos que no se conservan en sus nodos activos. Puede lograr importantes ahorros de costos al utilizar datos comprimidos en Amazon S3 e incorporar datos bajo demanda en OpenSearch Service.
- Utilice la función Consulta directa con S3 cuando desee analizar directamente sus registros operativos en Amazon S3 con las funciones completas de análisis y visualización de OpenSearch Service.
Como siguiente paso, consulte la Guía para desarrolladores de Amazon OpenSearch para explorar registros y canalizaciones de métricas que puede usar para crear una solución de observabilidad escalable para sus aplicaciones empresariales.
Acerca de los autores
 Jagadish Kumar (Jag) es un arquitecto senior de soluciones especializado en AWS centrado en Amazon OpenSearch Service. Es un apasionado de la arquitectura de datos y ayuda a los clientes a crear soluciones de análisis a escala en AWS.
Jagadish Kumar (Jag) es un arquitecto senior de soluciones especializado en AWS centrado en Amazon OpenSearch Service. Es un apasionado de la arquitectura de datos y ayuda a los clientes a crear soluciones de análisis a escala en AWS.
 Muthu Pitchaimani es un arquitecto senior de soluciones especializado en Amazon OpenSearch Service. Crea aplicaciones y soluciones de búsqueda a gran escala. Muthu está interesado en los temas de redes y seguridad y reside en Austin, Texas.
Muthu Pitchaimani es un arquitecto senior de soluciones especializado en Amazon OpenSearch Service. Crea aplicaciones y soluciones de búsqueda a gran escala. Muthu está interesado en los temas de redes y seguridad y reside en Austin, Texas.
 Sam Selván es arquitecto de soluciones principal especializado en Amazon OpenSearch Service.
Sam Selván es arquitecto de soluciones principal especializado en Amazon OpenSearch Service.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

