
Imagen del autor
ChatGPT es un modelo de lenguaje de IA y ganó fuerza en los últimos meses. Tiene dos lanzamientos populares, GPT-3.5 y GPT-4. GPT-4 es la versión mejorada de GPT-3.5 con respuestas más precisas. Pero el principal problema de ChatGPT es que no es de código abierto, es decir, no permite que los usuarios vean y modifiquen su código fuente. Esto lleva a muchos problemas como la personalización, la privacidad y la democratización de la IA.
Existe la necesidad de tales chatbots de lenguaje AI que puedan funcionar como ChatGPT pero que sean gratuitos, de código abierto y menos intensivos en CPU. Uno de esos modelos de IA es Aplaca LoRA, del que hablaremos en el tutorial. Al final de este tutorial, lo comprenderá bien y podrá ejecutarlo en su máquina local usando Python. Pero primero, analicemos qué es Alpaca LoRA.
Alpaca es un modelo de lenguaje de IA desarrollado por un equipo de investigadores de la Universidad de Stanford. Usa LLaMA, que es el modelo de lenguaje a gran escala de Meta. Utiliza GPT de OpenAI (text-davinci-003) para ajustar el modelo LLaMA de tamaño de parámetros 7B. Es gratuito para fines académicos y de investigación y tiene requisitos computacionales bajos.
El equipo comenzó con el modelo LLaMA 7B y lo entrenó previamente con 1 billón de tokens. Comenzaron con 175 pares de instrucciones y resultados escritos por humanos y le pidieron a la API de ChatGPT que generara más pares usando estos pares. Recolectaron 52000 conversaciones de muestra, que usaron para afinar aún más su modelo LLaMA.
LLaMA Los modelos tienen varias versiones, es decir, 7B, 13B, 30B y 65B. Alpaca se puede ampliar a los modelos de parámetros 7B, 13B, 30B y 65B.

Fig.1 Arquitectura Aplaca 7B | Imagen por Stanford
Alpaca-LoRA es una versión más pequeña de Alpaca Stanford que consume menos energía y puede ejecutarse en dispositivos de gama baja como Raspberry Pie. Usos de Alpaca-LoRA Adaptación de bajo rango (LoRA) para acelerar el entrenamiento de modelos grandes mientras se consume menos memoria.
Crearemos un entorno de Python para ejecutar Alpaca-Lora en nuestra máquina local. Necesitas una GPU para ejecutar ese modelo. No puede ejecutarse en la CPU (o sale muy lentamente). Si usa el modelo 7B, se requieren al menos 12 GB de RAM o más si usa los modelos 13B o 30B.
Si no tiene una GPU, puede realizar los mismos pasos en el Colaboración de Google. Al final, compartiré el enlace de Colab contigo.
Seguiremos así Repo de GitHub de Alpaca-LoRA por tloen.
1. Creación de un entorno virtual
Instalaremos todas nuestras bibliotecas en un entorno virtual. No es obligatorio pero sí recomendable. Los siguientes comandos son para el sistema operativo Windows. (Este paso no es necesario para Google Colab)
Comando para crear venv
$ py -m venv venv
Comando para activarlo
$ .venvScriptsactivate
Comando para desactivarlo
$ deactivate2. Clonación del repositorio de GitHub
Ahora, clonaremos el repositorio de Alpaca LoRA.
$ git clone https://github.com/tloen/alpaca-lora.git
$ cd .alpaca-lora
Instalación de las bibliotecas
$ pip install -r .requirements.txt3. Formación
El archivo python llamado finetune.py contiene los hiperparámetros del modelo LLaMA, como el tamaño del lote, el número de épocas, la tasa de aprendizaje (LR), etc., con los que puede jugar. Correr finetune.py no es obligatorio. De lo contrario, el archivo ejecutor lee el modelo de cimentación y los pesos de tloen/alpaca-lora-7b.
$ python finetune.py --base_model 'decapoda-research/llama-7b-hf' --data_path 'yahma/alpaca-cleaned' --output_dir './lora-alpaca' --batch_size 128 --micro_batch_size 4 --num_epochs 3 --learning_rate 1e-4 --cutoff_len 512 --val_set_size 2000 --lora_r 8 --lora_alpha 16 --lora_dropout 0.05 --lora_target_modules '[q_proj,v_proj]' --train_on_inputs --group_by_length4. Ejecutando el modelo
El archivo python llamado generate.py leerá el modelo Hugging Face y los pesos LoRA de tloen/alpaca-lora-7b. Ejecuta una interfaz de usuario usando Gradio, donde el usuario puede escribir una pregunta en un cuadro de texto y recibir el resultado en un cuadro de texto separado.
Nota: Si está trabajando en Google Colab, marque share=True existentes launch() función de la generate.py archivo. Ejecutará la interfaz en una URL pública. De lo contrario, se ejecutará en localhost http://0.0.0.0:7860
$ python generate.py --load_8bit --base_model 'decapoda-research/llama-7b-hf' --lora_weights 'tloen/alpaca-lora-7b'
Salida:
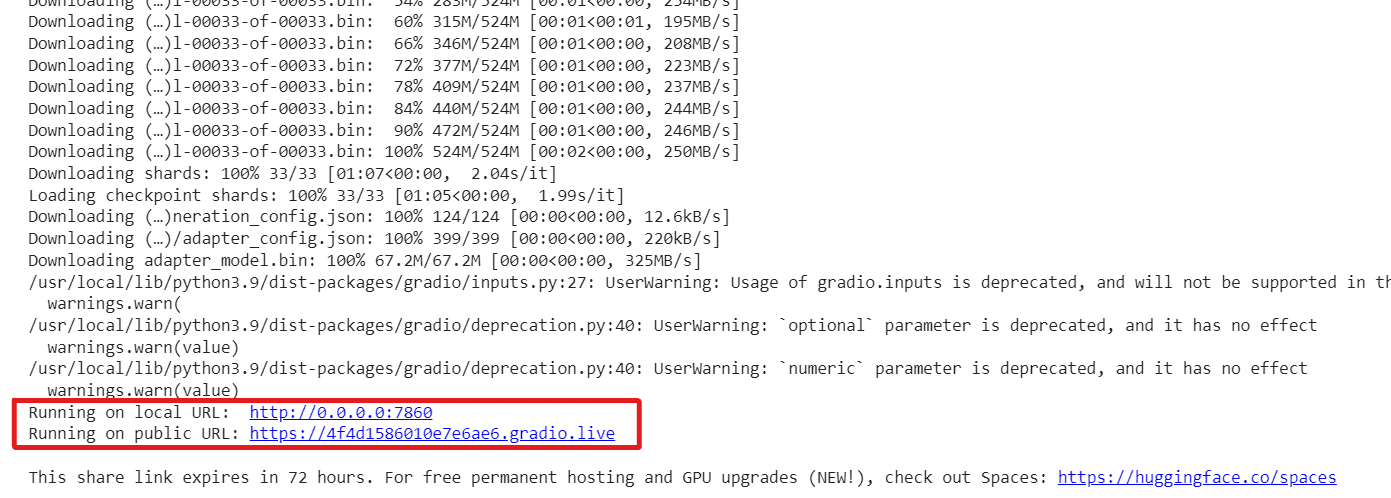
Tiene dos URL, una es pública y otra se ejecuta en el host local. Si usa Google Colab, se puede acceder al enlace público.
5. Dockerizar la aplicación
solicite dockerizar su aplicación en un contenedor Docker si desea que se exporte a algún lugar o si enfrenta algunos problemas de dependencia. Docker es una herramienta que crea una imagen inmutable de la aplicación. Luego, esta imagen se puede compartir y volver a convertir en la aplicación, que se ejecuta en un contenedor que tiene todas las bibliotecas, herramientas, códigos y tiempo de ejecución necesarios. Puede descargar Docker para Windows desde esta página.
Nota: Puede omitir este paso si está utilizando Google Colab.
Cree la imagen del contenedor:
$ docker build -t alpaca-lora .
Ejecute el contenedor:
$ docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${HOME}/.cache:/root/.cache --rm alpaca-lora generate.py --load_8bit --base_model 'decapoda-research/llama-7b-hf' --lora_weights 'tloen/alpaca-lora-7b'
Ejecutará su aplicación en https://localhost:7860.
Por ahora, tenemos nuestro Alpaca-LoRA funcionando. Ahora exploraremos algunas de sus características y le pediremos que escriba algo para nosotros.
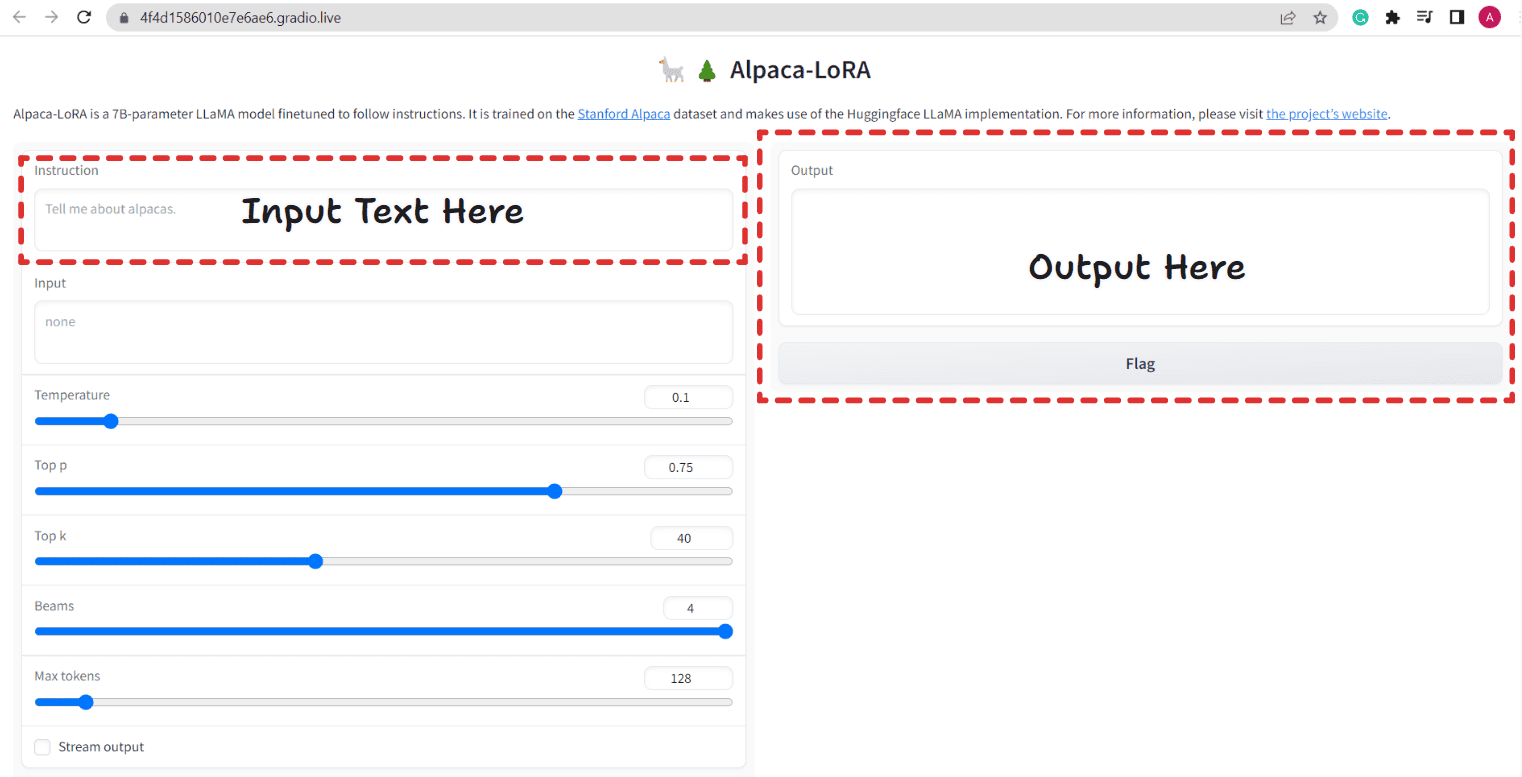
Fig. 2 Interfaz de usuario de Aplaca-LoRA | Imagen por autor
Proporciona una interfaz de usuario similar a ChatGPT, donde podemos hacer una pregunta y responde en consecuencia. También toma otros parámetros como Temperatura, Top p, Top k, Beams y Max Tokens. Básicamente, estas son configuraciones de generación utilizadas en el momento de la evaluación.
Hay una casilla de verificación Stream Output. Si marca esa casilla de verificación, el bot responderá un token a la vez (es decir, escribe el resultado línea por línea, al igual que ChatGPT). Si no marca esa opción, se escribirá de una sola vez.
Hagámosle algunas preguntas.
P1: Escriba un código de Python para encontrar el factorial de un número.
Salida:
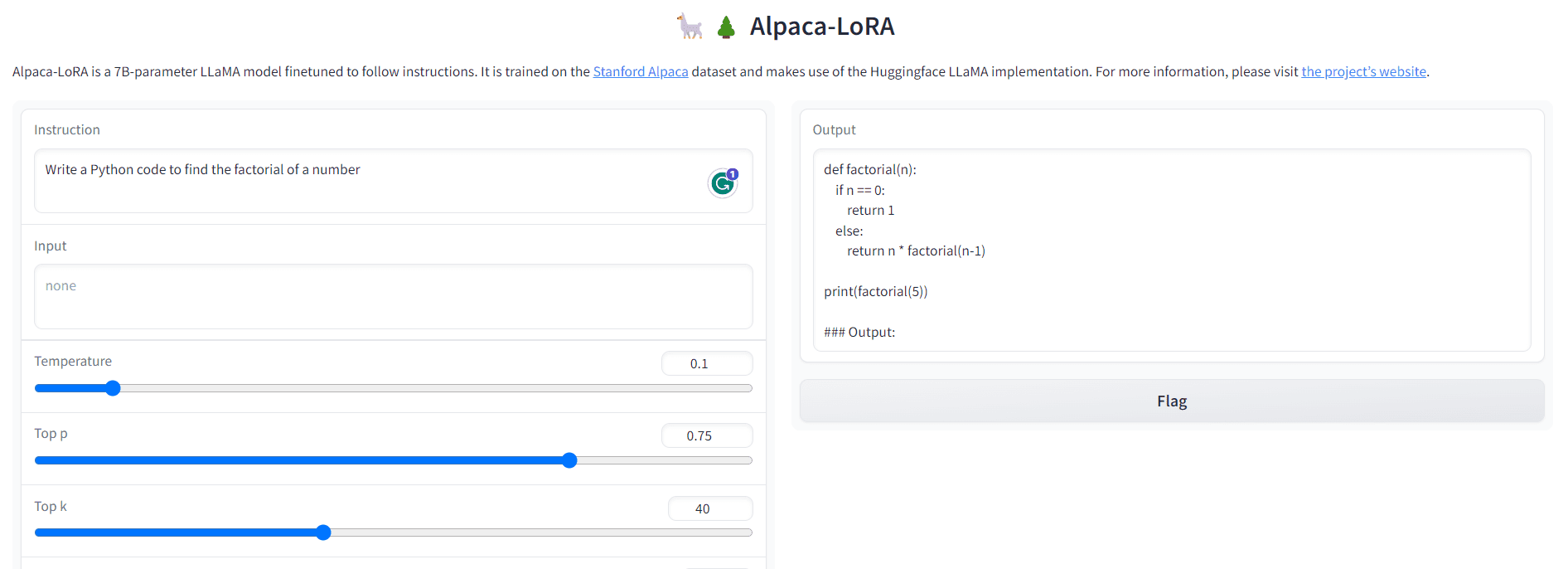
Fig. 3 Salida-1 | Imagen por autor
P2: Traducir “KDnuggets es un sitio líder en ciencia de datos, aprendizaje automático, inteligencia artificial y análisis. ” en francés
Salida:
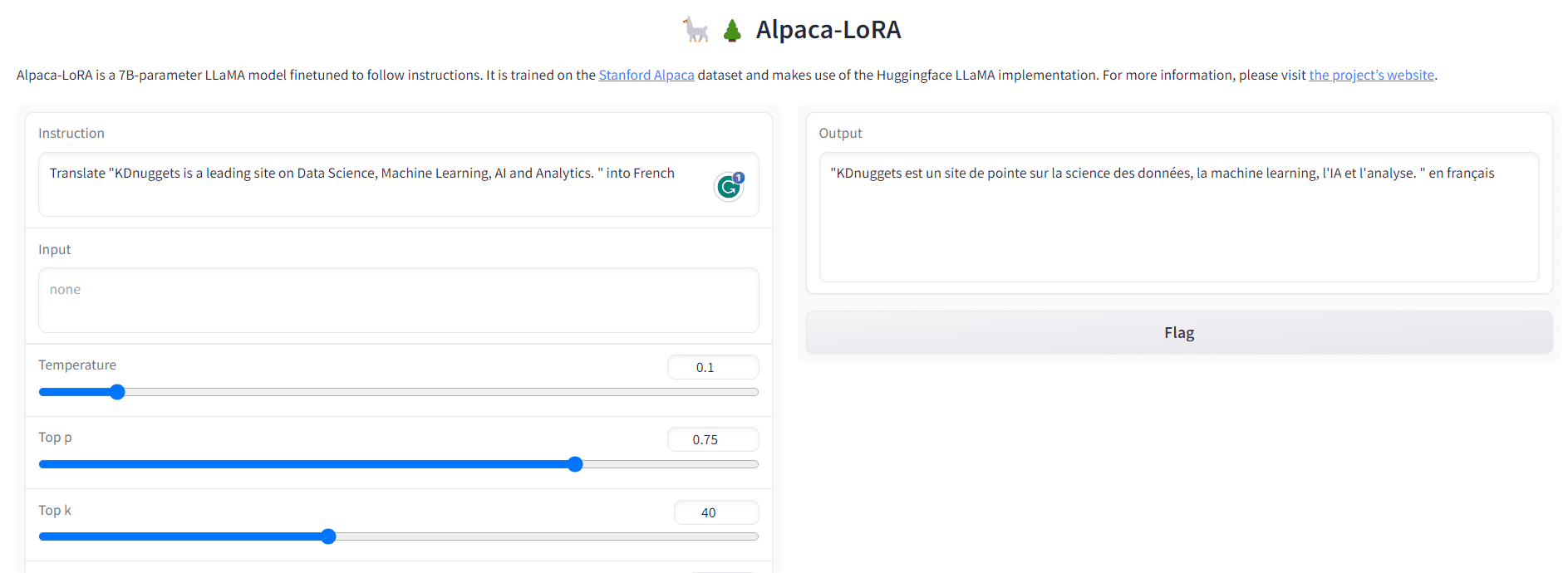
Fig. 4 Salida-2 | Imagen por autor
A diferencia de ChatGPT, también tiene algunas limitaciones. Es posible que no le proporcione la información más reciente porque no está conectado a Internet. Además, puede difundir el odio y la desinformación hacia los sectores vulnerables de la sociedad. A pesar de esto, es una excelente herramienta gratuita de código abierto con menores demandas de cómputo. Puede ser beneficioso para investigadores y académicos para actividades éticas de IA y seguridad cibernética.
Enlace de colaboración de Google – Enlace
- GitHub - tloen/alpaca-lora
- Alpaca Stanford - Un modelo de seguimiento de instrucciones fuerte y replicable
En este tutorial, hemos discutido el funcionamiento de Alpaca-LoRA y los comandos para ejecutarlo localmente o en Google Colab. Alpaca-LoRA no es el único chatbot de código abierto. Hay muchos otros chatbots que son de código abierto y de uso gratuito, como LLaMA, GPT4ALL, Vicuna, etc. Si desea una sinopsis rápida, puede consultar así artículo de Abid Ali Awan sobre KDnuggets.
Eso es todo por hoy. Espero que hayas disfrutado leyendo este artículo. Nos volveremos a encontrar en algún otro artículo. Hasta entonces, sigue leyendo y sigue aprendiendo.
Garg ario es un B.Tech. Estudiante de Ingeniería Eléctrica, actualmente en el último año de la carrera. Su interés radica en el campo del Desarrollo Web y el Aprendizaje Automático. Ha perseguido este interés y estoy ansioso por trabajar más en estas direcciones.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/05/learn-run-alpacalora-device-steps.html?utm_source=rss&utm_medium=rss&utm_campaign=learn-how-to-run-alpaca-lora-on-your-device-in-just-a-few-steps

