
Los árboles de decisión son uno de los algoritmos supervisados no lineales más simples en el mundo del aprendizaje automático. Como sugiere el nombre, se usan para tomar decisiones en términos de ML, lo llamamos clasificación (aunque también se pueden usar para regresión).
Los árboles de decisión tienen una estructura de árbol unidireccional, es decir, en cada nodo, el algoritmo toma la decisión de dividirse en nodos secundarios según ciertos criterios de parada. Más comúnmente, los DT usan entropía, ganancia de información, índice de Gini, etc.
Hay algunos algoritmos conocidos en DT como ID3, C4.5, CART, C5.0, CHAID, QUEST, CRUISE. En este artículo, discutiremos el más simple y antiguo: ID3.
ID3, o Iternative Dichotomizer, fue la primera de tres implementaciones de Decision Tree desarrolladas por Ross Quinlan.
El algoritmo construye un árbol de arriba hacia abajo, a partir de un conjunto de filas/objetos y una especificación de características. En cada nodo del árbol, se prueba una característica basada en minimizar la entropía o maximizar la ganancia de información para dividir el conjunto de objetos. Este proceso continúa hasta que el conjunto en un nodo dado es homogéneo (es decir, el nodo contiene objetos de la misma categoría). El algoritmo utiliza una búsqueda codiciosa. Selecciona una prueba usando el criterio de ganancia de información y luego nunca explora la posibilidad de opciones alternativas.
Contras:
- El modelo puede estar sobreajustado.
- Solo funciona en características categóricas
- No maneja los valores faltantes
- Baja velocidad
- No admite poda
- No admite impulso
Tantas desventajas de un algoritmo, ¿por qué estamos discutiendo esto?
Respuesta: es simple y es excelente para desarrollar la intuición de los algoritmos de árbol.
Una de las canciones infantiles más populares donde la lluvia decide si Johny/Arthur jugaría afuera es nuestra muestra de hoy. El único cambio es que no solo la lluvia sino cualquier mal tiempo afecta el juego del niño y usaríamos un DT para predecir su presencia afuera.

Fuente: Wikipedia
Los datos se ven así:
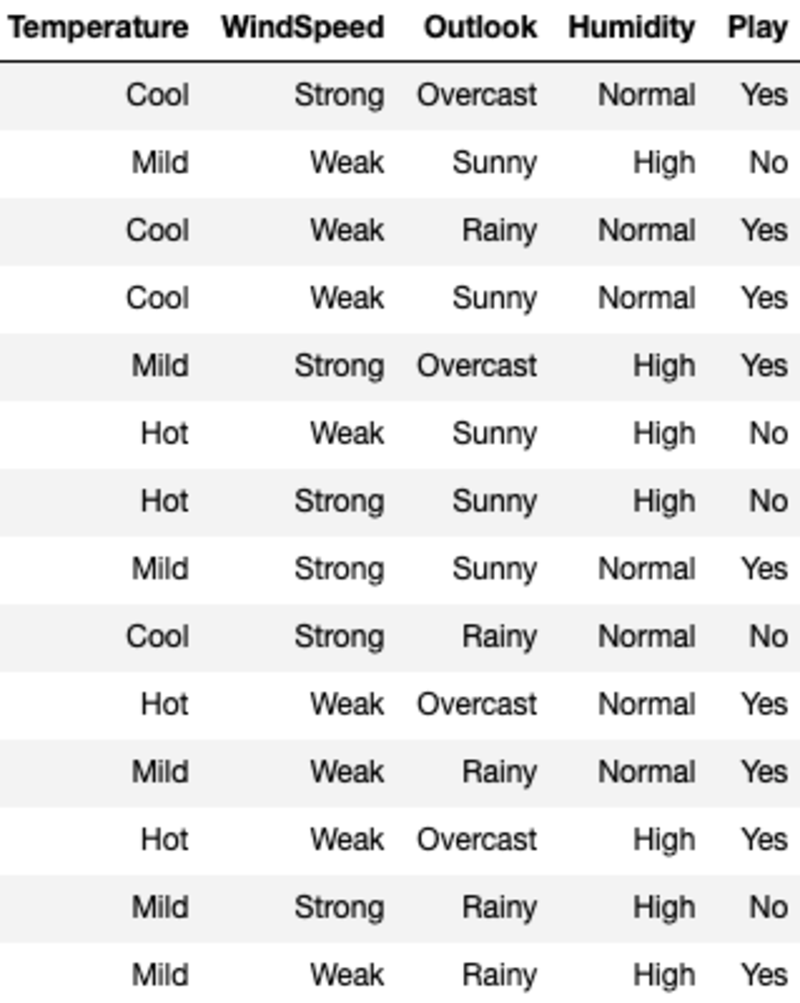
'Temperatura', 'Velocidad del viento', 'Perspectiva' y 'Humedad' son las características, y 'Reproducir' es la variable objetivo. Solo los datos categóricos y sin valores perdidos significan que podemos usar ID3.
Repasemos los criterios de división antes de saltar al algoritmo en sí. Para simplificar, discutiremos cada criterio solo para el caso de clasificación binaria.
Entropía: Se utiliza para calcular la heterogeneidad de una muestra y su valor se encuentra entre 0 y 1. Si la muestra es homogénea la entropía es 0 y si la muestra tiene la misma proporción de todas las clases tiene una entropía de 1.
S = -(p * log₂p + q * log₂q)
Dónde p y q son la proporción respectiva de las 2 clases en la muestra.
Esto también se puede escribir como: S = -(p * log₂p + (1-p)* log₂(1-p))
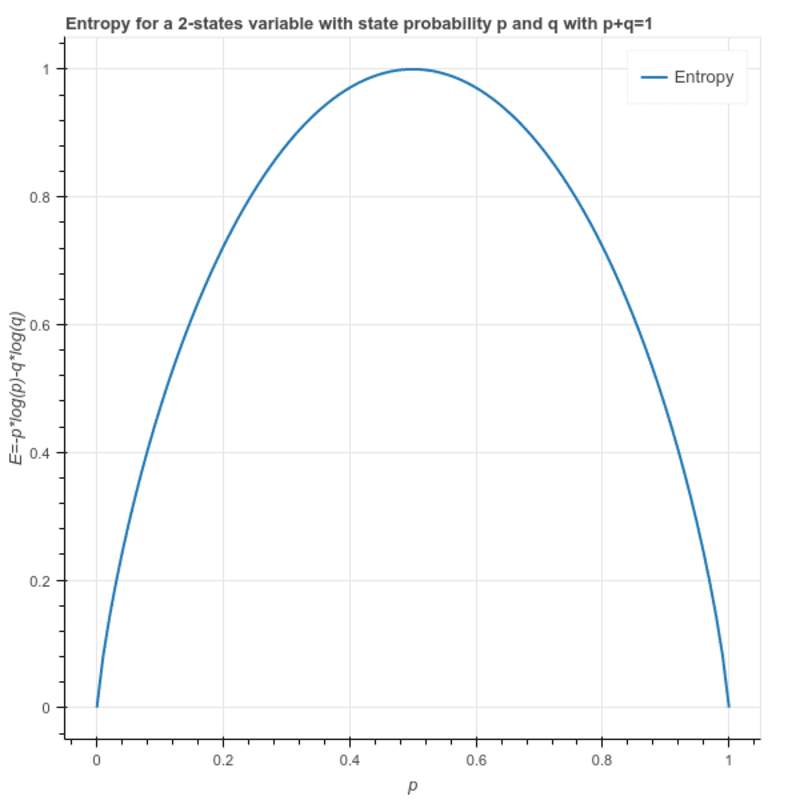
Ganancia de información: Es la diferencia en la entropía de un nodo y la entropía promedio de todos los valores de un nodo hijo. La función que proporciona la máxima ganancia de información se elige para la división.
La entropía del nodo raíz: (9 — Sí y 5 — No)
S = -(9/14)*log(9/14) — (5/14) * log(5/14) = 0.94
Hay 4 formas posibles de dividir el nodo raíz. ('Temperatura', 'Velocidad del viento', 'Perspectiva' y 'Humedad'). Por lo tanto, calculamos la entropía promedio ponderada del nodo hijo si elegimos cualquiera de los anteriores:
I(Temperature) = Hot*E(Temperature=Hot) + Mild*E(Temperature=Mild) + Cool*E(Temperature=Cool)
Donde Hot, Mild y Cool representan la proporción de los 3 valores en los datos.
I(Temperature) = (4/14)*1 + (6/14)*0.918 + (4/14)*0.811 = 0.911
Aquí, la entropía para cada valor se calcula filtrando la muestra usando el valor de la característica y luego usando la fórmula para la entropía. Por ejemplo, E(Temperature=Hot) se calcula filtrando la muestra original donde la temperatura es Hot (en este caso tenemos un número igual de Sí y No, lo que significa que la entropía es igual a 1).
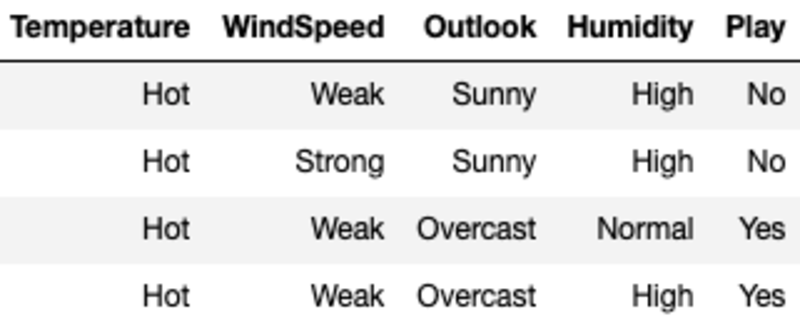
Calculamos la ganancia de información de la división en temperatura restando la entropía promedio para la temperatura de la entropía de los nodos raíz.
G(Temperature) = S — I(Temperature) = 0.94–0.911 = 0.029
Del mismo modo, calculamos la Ganancia de las cuatro características y elegimos la 1 con la Ganancia máxima.
G(WindSpeed) = S — I(WindSpeed) = 0.94–0.892 =0.048
G(Outlook) = S — I(Outlook) = 0.94–0.693 =0.247
G(Humidity) = S — I(Humidity) = 0.94–0.788 =0.152
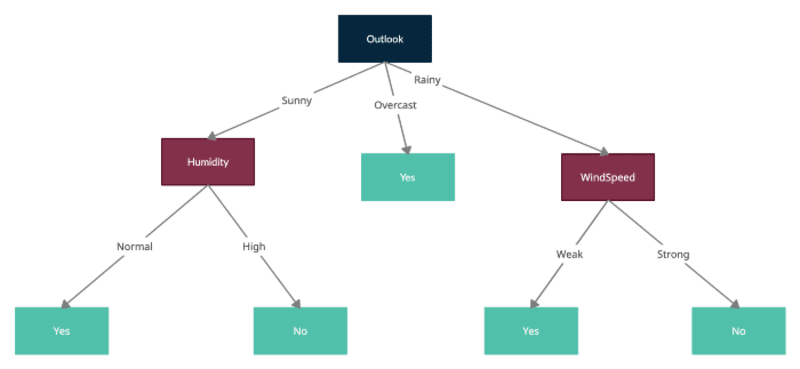
Outlook tiene la máxima ganancia de información, por lo que dividiríamos el nodo raíz en Outlook y cada uno de los nodos secundarios representa la muestra filtrada por uno de los valores de Outlook, es decir, soleado, nublado y lluvioso.
Ahora repetiríamos el mismo proceso tratando los nuevos nodos formados como nodos raíz con muestras filtradas y calculando entropías para cada uno y probando las divisiones calculando la entropía promedio para cada división adicional y restándola de la entropía del nodo actual para obtener la ganancia de información. Tenga en cuenta que ID3 no permite usar la función ya utilizada para dividir nodos secundarios. Por lo tanto, cada función solo se puede usar una vez en un árbol para la división.
Aquí está el árbol final formado por todas las divisiones:
Se puede encontrar una implementación simple con código Python esta página
Conclusión
Hice todo lo posible para explicar el funcionamiento del ID3, pero sé que es posible que tenga preguntas. Por favor, hágamelo saber en los comentarios y estaré feliz de tomarlos todos.
¡Gracias por leer!
Ankit Malik está creando soluciones escalables de inteligencia artificial y aprendizaje automático en varios dominios, como marketing, cadena de suministro, comercio minorista, publicidad y automatización de procesos. Ha trabajado en ambos extremos del espectro, desde liderar proyectos de ciencia de datos en compañías Fortune 500 hasta ser miembro fundador de una incubadora de ciencia de datos en múltiples empresas emergentes. Ha sido pionero en varios productos y servicios innovadores y cree en el liderazgo de servicio.
Original. Publicado de nuevo con permiso.

