Con Amazon SageMaker, puede administrar todo el ciclo de vida de aprendizaje automático (ML) de extremo a extremo. Ofrece muchas capacidades nativas para ayudar a administrar los aspectos de los flujos de trabajo de ML, como el seguimiento de experimentos y la gobernanza de modelos a través del registro de modelos. Esta publicación proporciona una solución adaptada a los clientes que ya usan MLflow, una plataforma de código abierto para administrar flujos de trabajo de ML.
En un Publicación anterior, discutimos MLflow y cómo puede ejecutarse en AWS e integrarse con SageMaker, en particular, al realizar un seguimiento de los trabajos de capacitación como experimentos y al implementar un modelo registrado en MLflow en la infraestructura administrada de SageMaker. sin embargo, el versión de código abierto de MLflow no proporciona mecanismos de control de acceso de usuarios nativos para varios inquilinos en el servidor de seguimiento. Esto significa que cualquier usuario con acceso al servidor tiene derechos de administrador y puede modificar experimentos, versiones de modelos y etapas. Esto puede ser un desafío para las empresas en industrias reguladas que necesitan mantener un gobierno modelo sólido para fines de auditoría.
En esta publicación, abordamos estas limitaciones implementando el control de acceso fuera del servidor MLflow y descargando las tareas de autenticación y autorización a Puerta de enlace API de Amazon, donde implementamos mecanismos de control de acceso detallados a nivel de recursos utilizando Gestión de identidades y acceso (SOY). Al hacerlo, podemos lograr un acceso sólido y seguro al servidor MLflow desde la infraestructura administrada de SageMaker y Estudio Amazon SageMaker, sin tener que preocuparse por las credenciales y toda la complejidad detrás de la gestión de credenciales. El diseño modular propuesto en esta arquitectura hace que la modificación de la lógica de control de acceso sea sencilla sin afectar al propio servidor MLflow. Por último, gracias a la extensibilidad de SageMaker Studio, mejoramos aún más la experiencia de los científicos de datos al hacer que MLflow sea accesible dentro de Studio, como se muestra en la siguiente captura de pantalla.
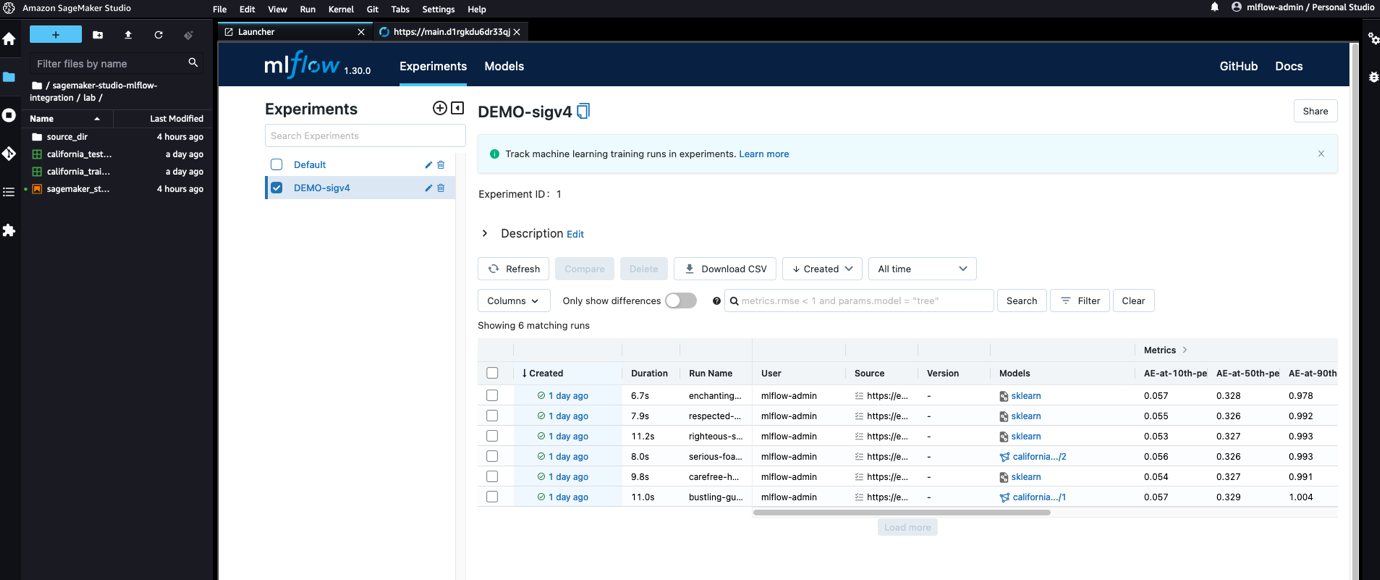
MLflow ha integrado la función que permite solicitud de firma con credenciales de AWS en el repositorio ascendente para su Python SDK, mejorando la integración con SageMaker. Los cambios en el SDK de Python de MLflow están disponibles para todos desde la versión 1.30.0 de MLflow.
En un alto nivel, esta publicación demuestra lo siguiente:
- Cómo implementar un servidor MLflow en una arquitectura sin servidor que se ejecuta en una subred privada a la que no se puede acceder directamente desde el exterior. Para esta tarea, construimos encima el siguiente repositorio de GitHub: Administre su ciclo de vida de aprendizaje automático con MLflow y Amazon SageMaker.
- Cómo exponer el servidor MLflow a través de integraciones privadas a una puerta de enlace API e implementar un control de acceso seguro para el acceso programático a través del SDK y el acceso del navegador a través de la interfaz de usuario de MLflow.
- Cómo registrar experimentos y ejecuciones, y registrar modelos en un servidor MLflow desde SageMaker usando los roles de ejecución de SageMaker asociados para autenticar y autorizar solicitudes, y cómo autenticarse a través de Cognito Amazonas a la interfaz de usuario de MLflow. Proporcionamos ejemplos que demuestran el seguimiento de experimentos y el uso del registro de modelos con MLflow de los trabajos de capacitación de SageMaker y Studio, respectivamente, en el archivo proporcionado. cuaderno.
- Cómo usar MLflow como un repositorio centralizado en una configuración de múltiples cuentas.
- Cómo ampliar Studio para mejorar la experiencia del usuario mediante la representación de MLflow dentro de Studio. Para esta tarea, mostramos cómo aprovechar la extensibilidad de Studio instalando una extensión de JupyterLab.
Ahora profundicemos en los detalles.
Resumen de la solución
Puede pensar en MLflow como tres componentes principales diferentes que funcionan en paralelo:
- Una API de REST para el servidor de seguimiento de back-end de MLflow
- SDK para que interactúe mediante programación con las API del servidor de seguimiento de MLflow desde el código de entrenamiento de su modelo
- Una interfaz de React para la interfaz de usuario de MLflow para visualizar sus experimentos, ejecuciones y artefactos
En un alto nivel, la arquitectura que hemos imaginado e implementado se muestra en la siguiente figura.
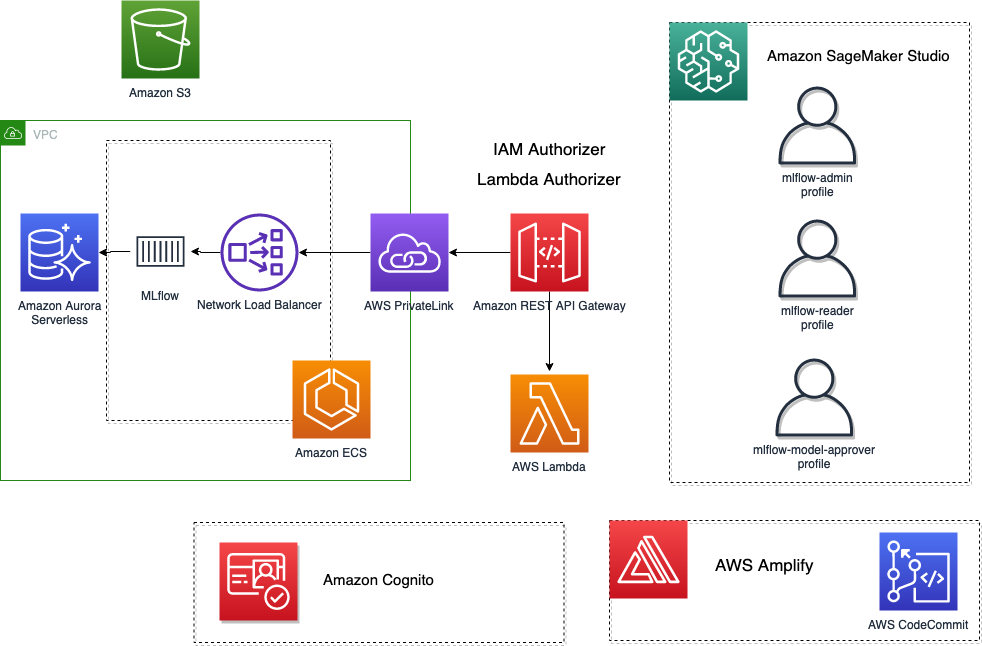
Requisitos previos
Antes de implementar la solución, asegúrese de tener acceso a una cuenta de AWS con permisos de administrador.
Implementar la infraestructura de la solución
Para implementar la solución descrita en esta publicación, siga las instrucciones detalladas en el Repositorio GitHub LÉAME. Para automatizar el despliegue de la infraestructura, utilizamos el Kit de desarrollo en la nube de AWS (CDK de AWS). AWS CDK es un marco de desarrollo de software de código abierto para crear Formación en la nube de AWS pilas a través de automático Plantilla de CloudFormation generación. Una pila es una colección de recursos de AWS que se pueden actualizar, mover o eliminar mediante programación. CDK de AWS construcciones son los componentes básicos de las aplicaciones de AWS CDK y representan el modelo para definir arquitecturas en la nube.
Combinamos cuatro pilas:
- El MLFlowVPCSapilar stack realiza las siguientes acciones:
- El RestApiGatewayPila stack realiza las siguientes acciones:
- Expone el servidor MLflow a través de AWS PrivateLink a una puerta de enlace API REST.
- Implementa un grupo de usuarios de Amazon Cognito para administrar los usuarios que acceden a la interfaz de usuario (todavía vacío después de la implementación).
- Despliega un AWS Lambda autorizador para verificar el token JWT con las claves de ID del grupo de usuarios de Amazon Cognito y devuelve las políticas de IAM para permitir o denegar una solicitud. Esta estrategia de autorización se aplica a
<MLFlow-Tracking-Server-URI>/*. - Agrega un autorizador de IAM. Esto se aplicará a la a la
<MLFlow-Tracking-Server-URI>/api/*, que prevalecerá sobre el anterior.
- El AmplificarMLFlowStack stack realiza la siguiente acción:
- Crea una aplicación vinculada al repositorio de MLflow parcheado en Compromiso de código de AWS para compilar e implementar la interfaz de usuario de MLflow.
- El SageMakerStudioUserStack stack realiza las siguientes acciones:
- Implementa un dominio de Studio (si aún no existe).
- Agrega tres usuarios, cada uno con un rol de ejecución de SageMaker diferente que implementa un nivel de acceso diferente:
- administrador-mlflow – Tiene permiso de administrador para cualquier recurso de MLflow.
- mlflow-lector – Tiene permisos de administrador de solo lectura para cualquier recurso de MLflow.
- mlflow-modelo-aprobador – Tiene los mismos permisos que mlflow-reader, además puede registrar nuevos modelos de ejecuciones existentes en MLflow y promover modelos registrados existentes a nuevas etapas.
Implemente el servidor de seguimiento de MLflow en una arquitectura sin servidor
Nuestro objetivo es tener una implementación confiable, de alta disponibilidad, rentable y segura del servidor de seguimiento de MLflow. Las tecnologías sin servidor son el candidato perfecto para satisfacer todos estos requisitos con una sobrecarga operativa mínima. Para lograrlo, creamos una imagen de contenedor de Docker para el servidor de seguimiento de experimentos de MLflow y la ejecutamos en AWS Fargate en Amazon ECS en su VPC dedicada que se ejecuta en una subred privada. MLflow se basa en dos componentes de almacenamiento: el almacén de back-end y el almacén de artefactos. Para la tienda backend, usamos Aurora Serverless y para la tienda de artefactos, usamos Amazon S3. Para la arquitectura de alto nivel, consulte Escenario 4: MLflow con servidor de seguimiento remoto, backend y almacenes de artefactos. Se pueden encontrar detalles extensos sobre cómo realizar esta tarea en el siguiente repositorio de GitHub: Administre su ciclo de vida de aprendizaje automático con MLflow y Amazon SageMaker.
MLflow seguro a través de API Gateway
En este momento, todavía no contamos con un mecanismo de control de acceso. Como primer paso, exponemos MLflow al mundo exterior mediante AWS PrivateLink, que establece una conexión privada entre la VPC y otros servicios de AWS, en nuestro caso API Gateway. Las solicitudes entrantes a MLflow luego se envían a través de un Puerta de enlace API REST, dándonos la posibilidad de implementar varios mecanismos para autorizar solicitudes entrantes. Para nuestros propósitos, nos enfocamos solo en dos:
- Uso de autorizadores de IAM - Con Autorizadores de IAM, el solicitante debe tener asignada la política de IAM correcta para acceder a los recursos de API Gateway. Cada solicitud debe agregar información de autenticación a las solicitudes enviadas a través de HTTP por AWS Signature Versión 4.
- Uso de autorizadores de Lambda – Esto ofrece la mayor flexibilidad porque deja un control total sobre cómo se puede autorizar una solicitud. Eventualmente, el autorizador lambda debe devolver una política de IAM, que a su vez será evaluada por API Gateway para determinar si la solicitud debe permitirse o denegarse.
Para obtener una lista completa de los mecanismos de autenticación y autorización admitidos en API Gateway, consulte Controlar y administrar el acceso a una API REST en API Gateway.
Autenticación de MLflow Python SDK (autorizador de IAM)
El servidor de seguimiento de experimentos de MLflow implementa un REST API interactuar de forma programática con los recursos y artefactos. El SDK de Python de MLflow proporciona una forma conveniente de registrar métricas, ejecuciones y artefactos, e interactúa con los recursos de la API alojados en el espacio de nombres. <MLflow-Tracking-Server-URI>/api/. Configuramos API Gateway para usar el autorizador de IAM para el control de acceso a recursos en este espacio de nombres, por lo que se requiere que cada solicitud se firme con AWS Signature Version 4.
Para facilitar el proceso de firma de solicitudes, a partir de MLflow 1.30.0, esta capacidad se puede habilitar sin problemas. Asegúrese de que el requests_auth_aws_sigv4 biblioteca está instalada en el sistema y establecer la MLFLOW_TRACKING_AWS_SIGV4 variable de entorno a True. Puede encontrar más información en el documentación oficial de MLflow.
En este punto, el SDK de MLflow solo necesita credenciales de AWS. Porque request_auth_aws_sigv4 usos boto3 para recuperar credenciales, sabemos que puede cargar credenciales desde los metadatos de la instancia cuando un rol de IAM está asociado con un Nube informática elástica de Amazon (Amazon EC2) instancia (para conocer otras formas de proporcionar credenciales a Boto3, consulte Referencias). Esto significa que también puede cargar credenciales de AWS cuando se ejecuta desde una instancia administrada de SageMaker desde el rol de ejecución asociado, como se explica más adelante en esta publicación.
Configurar políticas de IAM para acceder a las API de MLflow a través de API Gateway
Puede utilizar roles y políticas de IAM para controlar quién puede invocar recursos en API Gateway. Para obtener más detalles y declaraciones de referencia de políticas de IAM, consulte Controlar el acceso para invocar una API.
El siguiente código muestra un ejemplo de política de IAM que otorga a la persona que llama permisos para todos los métodos en todos los recursos en API Gateway que protege MLflow, prácticamente otorgando acceso de administrador al servidor MLflow:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/*/*",
"Effect": "Allow"
}
]
}Si queremos una política que permita a un usuario acceso de solo lectura a todos los recursos, la política de IAM se vería como el siguiente código:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": [
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search",
],
"Effect": "Allow"
}
]
}Otro ejemplo podría ser una política para otorgar permisos a usuarios específicos para registrar modelos en el registro de modelos y promoverlos más tarde a etapas específicas (escenario, producción, etc.):
{ "Version": "2012-10-17", "Statement": [ { "Action": "execute-api:Invoke", "Resource": [ "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/model-versions/*", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/registered-models/*" ], "Effect": "Allow" } ]
}Autenticación de la interfaz de usuario de MLflow (autorizador de Lambda)
El acceso del navegador al servidor MLflow es manejado por la interfaz de usuario de MLflow implementada con React. La interfaz de usuario de MLflow no se ha diseñado para admitir usuarios autenticados. Implementar un flujo de inicio de sesión sólido puede parecer una tarea desalentadora, pero afortunadamente podemos confiar en el Amplifica los componentes de UI React para la autenticación, lo que reduce en gran medida el esfuerzo de crear un flujo de inicio de sesión en una aplicación React, utilizando Amazon Cognito para el almacén de identidades.
Amazon Cognito nos permite administrar nuestra propia base de usuarios y también admitir la federación de identidad de terceros, lo que hace factible construir, por ejemplo, una federación ADFS (ver Creación de una federación ADFS para su aplicación web mediante grupos de usuarios de Amazon Cognito para más detalles). Los tokens emitidos por Amazon Cognito deben verificarse en API Gateway. La simple verificación del token no es suficiente para un control de acceso detallado, por lo tanto, el autorizador de Lambda nos permite la flexibilidad para implementar la lógica que necesitamos. Luego, podemos crear nuestro propio autorizador Lambda para verificar el token JWT y generar las políticas de IAM para permitir que API Gateway rechace o permita la solicitud. El siguiente diagrama ilustra el flujo de inicio de sesión de MLflow.
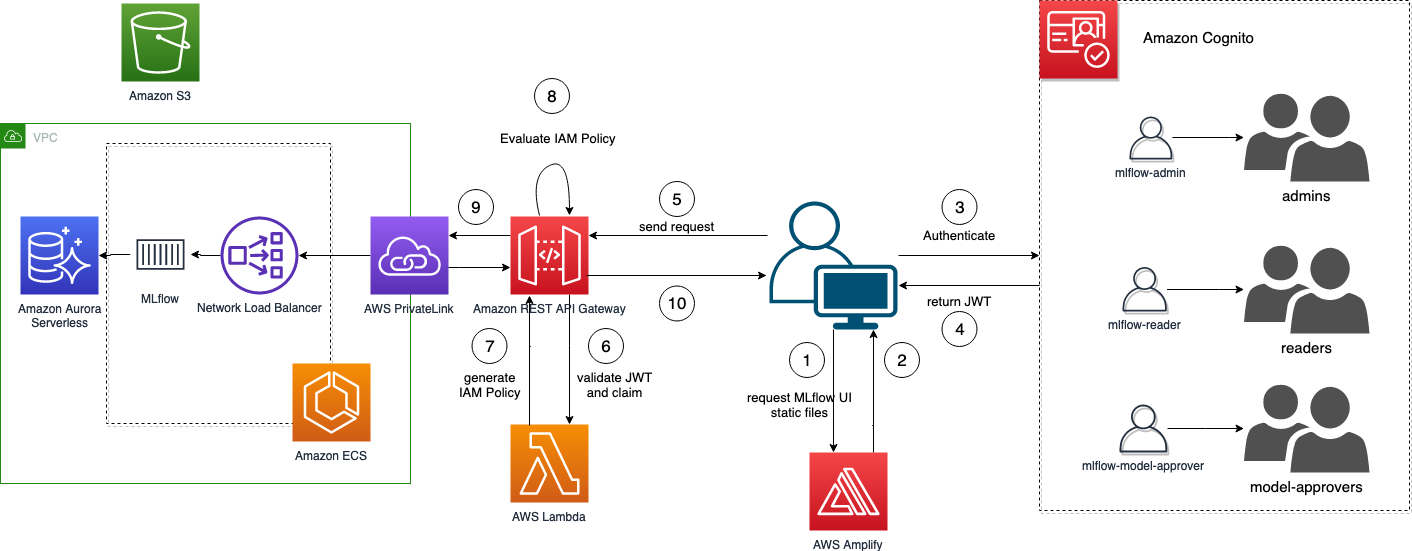
Para obtener más información sobre los cambios de código reales, consulte el archivo de parche cognito.parche, aplicable a la versión 2.3.1 de MLflow.
Este parche presenta dos capacidades:
- Agregue los componentes de la interfaz de usuario de Amplify y configure los detalles de Amazon Cognito mediante variables de entorno que implementan el flujo de inicio de sesión
- Extraiga el JWT de la sesión y cree un encabezado de Autorización con un token de portador de dónde enviar el JWT
Aunque mantener el código divergente del anterior siempre agrega más complejidad que confiar en el anterior, vale la pena señalar que los cambios son mínimos porque confiamos en los componentes de la interfaz de usuario de Amplify React.
Con el nuevo flujo de inicio de sesión implementado, creemos la compilación de producción para nuestra interfaz de usuario de MLflow actualizada. Alojamiento de AWS Amplify es un servicio de AWS que proporciona un flujo de trabajo basado en git para CI/CD y alojamiento de aplicaciones web. El paso de construcción en la canalización está definido por el buildspec.yaml, donde podemos inyectar como variables de entorno detalles sobre el ID del grupo de usuarios de Amazon Cognito, el ID del grupo de identidades de Amazon Cognito y el ID del cliente del grupo de usuarios que necesita el componente React de la interfaz de usuario de Amplify para configurar el flujo de autenticación. El siguiente código es un ejemplo de la buildspec.yaml archivo:
version: "1.0"
applications: - frontend: phases: preBuild: commands: - fallocate -l 4G /swapfile - chmod 600 /swapfile - mkswap /swapfile - swapon /swapfile - swapon -s - yarn install build: commands: - echo "REACT_APP_REGION=$REACT_APP_REGION" >> .env - echo "REACT_APP_COGNITO_USER_POOL_ID=$REACT_APP_COGNITO_USER_POOL_ID" >> .env - echo "REACT_APP_COGNITO_IDENTITY_POOL_ID=$REACT_APP_COGNITO_IDENTITY_POOL_ID" >> .env - echo "REACT_APP_COGNITO_USER_POOL_CLIENT_ID=$REACT_APP_COGNITO_USER_POOL_CLIENT_ID" >> .env - yarn run build artifacts: baseDirectory: build files: - "**/*"Registre experimentos y ejecuciones de forma segura mediante el rol de ejecución de SageMaker
Uno de los aspectos clave de la solución que se analiza aquí es la integración segura con SageMaker. SageMaker es un servicio administrado y, como tal, realiza operaciones en su nombre. Lo que SageMaker puede hacer está definido por las políticas de IAM adjuntas a la función de ejecución que asocia a un trabajo de capacitación de SageMaker o que asocia a un perfil de usuario que trabaja desde Studio. Para obtener más información sobre la función de ejecución de SageMaker, consulte Funciones de SageMaker.
Al configurar API Gateway para usar la autenticación de IAM en el <MLFlow-Tracking-Server-URI>/api/* recursos, podemos definir un conjunto de políticas de IAM en el rol de ejecución de SageMaker que permitirá que SageMaker interactúe con MLflow según el nivel de acceso especificado.
Al configurar el MLFLOW_TRACKING_AWS_SIGV4 variable de entorno a True mientras trabaja en Studio o en un trabajo de capacitación de SageMaker, el SDK de Python de MLflow firmará automáticamente todas las solicitudes, que serán validadas por API Gateway:
os.environ['MLFLOW_TRACKING_AWS_SIGV4'] = "True"
mlflow.set_tracking_uri(tracking_uri)
mlflow.set_experiment(experiment_name)Pruebe la función de ejecución de SageMaker con el SDK de MLflow
Si accede al dominio de Studio que se generó, encontrará tres usuarios:
- administrador-mlflow – Asociado a un rol de ejecución con permisos similares a los del usuario en los administradores del grupo de Amazon Cognito
- mlflow-lector – Asociado a un rol de ejecución con permisos similares a los del usuario en el grupo de lectores de Amazon Cognito
- mlflow-modelo-aprobador – Asociado a un rol de ejecución con permisos similares a los del usuario en el grupo de aprobadores de modelos de Amazon Cognito
Para probar los tres roles diferentes, consulte los laboratorios proporcionada como parte de esta muestra en cada perfil de usuario.
El siguiente diagrama ilustra el flujo de trabajo para los perfiles de usuario de Studio y la autenticación de trabajos de SageMaker con MLflow.
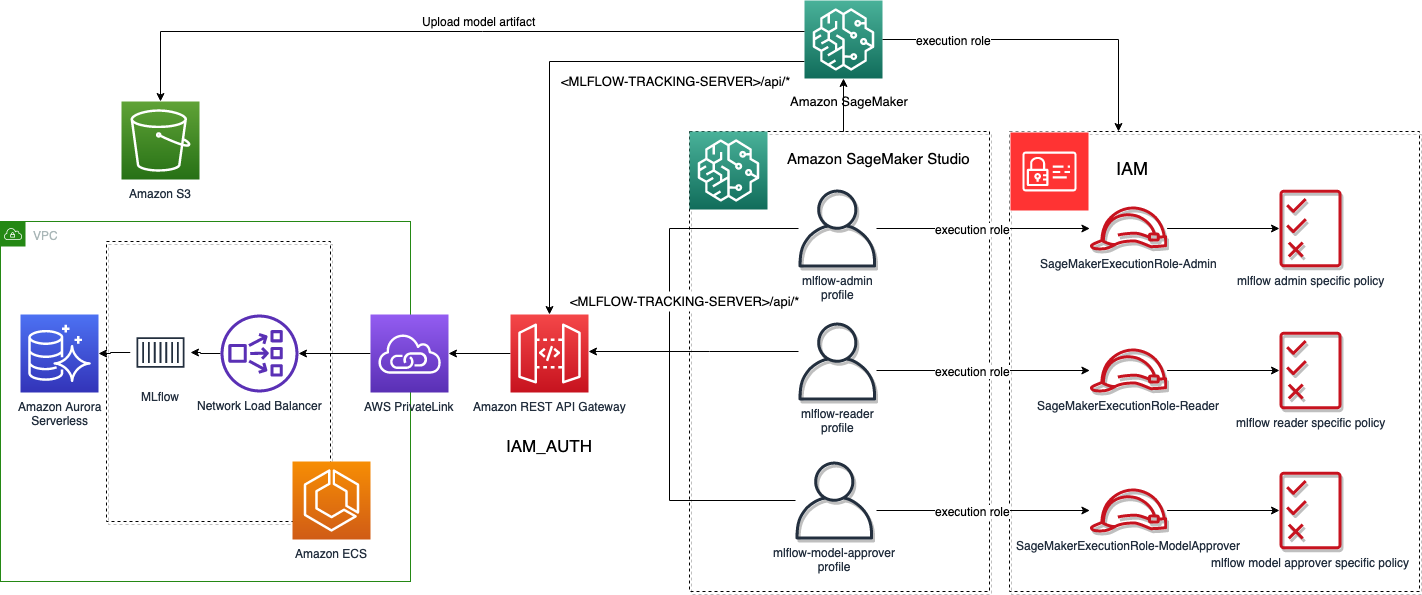
De manera similar, al ejecutar trabajos de SageMaker en la infraestructura administrada de SageMaker, si configura la variable de entorno MLFLOW_TRACKING_AWS_SIGV4 a True, y el rol de ejecución de SageMaker pasado a los trabajos tiene la política de IAM correcta para acceder a API Gateway, puede interactuar de forma segura con su servidor de seguimiento de MLflow sin necesidad de administrar las credenciales usted mismo. Al ejecutar trabajos de entrenamiento de SageMaker e inicializar una clase de estimador, puede pasar variables de entorno que SageMaker inyectará y las pondrá a disposición del script de entrenamiento, como se muestra en el siguiente código:
environment={ "AWS_DEFAULT_REGION": region, "MLFLOW_EXPERIMENT_NAME": experiment_name, "MLFLOW_TRACKING_URI": tracking_uri, "MLFLOW_AMPLIFY_UI_URI": mlflow_amplify_ui, "MLFLOW_TRACKING_AWS_SIGV4": "true", "MLFLOW_USER": user
} estimator = SKLearn( entry_point='train.py', source_dir='source_dir', role=role, metric_definitions=metric_definitions, hyperparameters=hyperparameters, instance_count=1, instance_type='ml.m5.large', framework_version='1.0-1', base_job_name='mlflow', environment=environment
)Visualice ejecuciones y experimentos desde la interfaz de usuario de MLflow
Una vez completada la primera implementación, completemos el grupo de usuarios de Amazon Cognito con tres usuarios, cada uno perteneciente a un grupo diferente, para probar los permisos que hemos implementado. Puedes usar este guión agregar_usuarios_y_grupos.py para sembrar el grupo de usuarios. Después de ejecutar el script, si comprueba el grupo de usuarios de Amazon Cognito en la consola de Amazon Cognito, debería ver los tres usuarios creados.
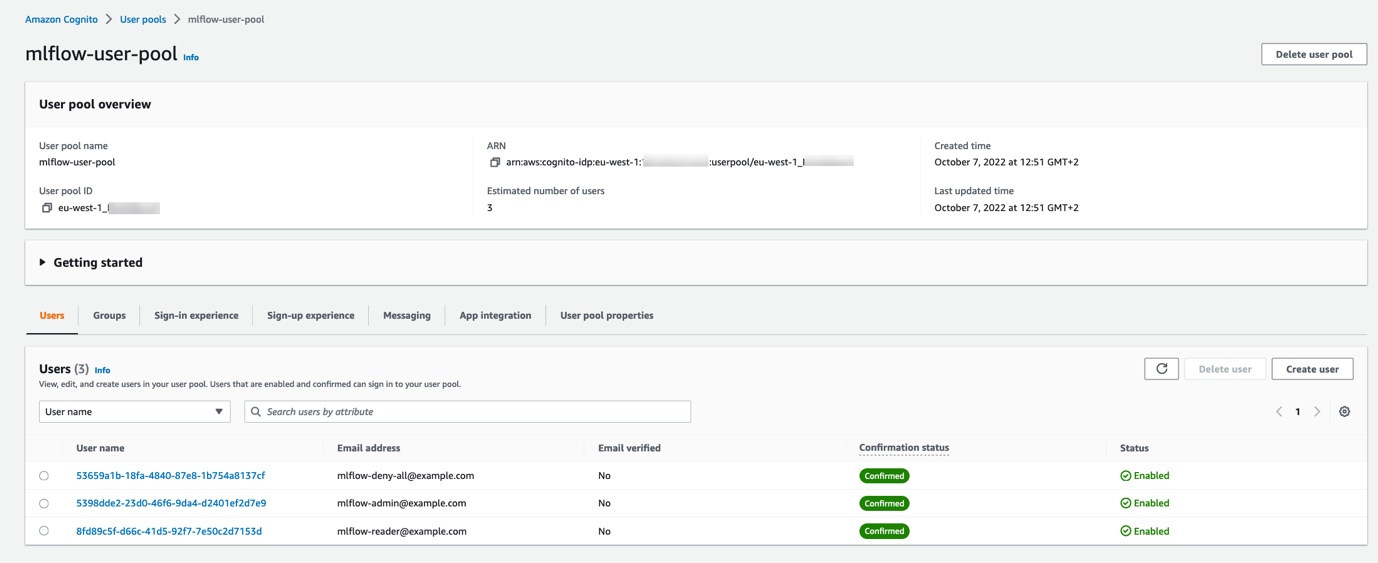
En el lado de REST API Gateway, el autorizador de Lambda primero verificará la firma del token mediante la clave del grupo de usuarios de Amazon Cognito y verificará las notificaciones. Solo después de eso, extraerá el grupo de Amazon Cognito al que pertenece el usuario del reclamo en el token JWT (cognito:groups) y aplicar diferentes permisos en función del grupo que tengamos programado.
Para nuestro caso concreto, tenemos tres grupos:
- administradores – Puede ver y puede editar todo
- lectores – Solo se puede ver todo
- aprobadores de modelos – Lo mismo que los lectores, además puede registrar modelos, crear versiones y promover versiones de modelos a la siguiente etapa
Según el grupo, el autorizador de Lambda generará diferentes políticas de IAM. Este es solo un ejemplo de cómo se puede lograr la autorización; con un autorizador Lambda, puede implementar cualquier lógica que necesite. Hemos optado por construir la política de IAM en tiempo de ejecución en la propia función de Lambda; sin embargo, puede pregenerar políticas de IAM apropiadas, almacenarlas en Amazon DynamoDBy recuperarlos en tiempo de ejecución de acuerdo con su propia lógica empresarial. Sin embargo, si desea restringir solo un subconjunto de acciones, debe tener en cuenta las Definición de la API REST de MLflow.
Puede explorar el código para el autorizador de Lambda en el Repositorio GitHub.
Consideraciones multicuenta
Los flujos de trabajo de ciencia de datos tienen que pasar por múltiples etapas a medida que avanzan desde la experimentación hasta la producción. Un enfoque común involucra cuentas separadas dedicadas a diferentes fases del flujo de trabajo de AI/ML (experimentación, desarrollo y producción). Sin embargo, a veces es deseable tener una cuenta dedicada que actúe como repositorio central de modelos. Aunque nuestra arquitectura y muestra se refieren a una sola cuenta, se puede ampliar fácilmente para implementar este último escenario, gracias a la Capacidad de IAM para cambiar roles incluso entre cuentas.
El siguiente diagrama ilustra una arquitectura que utiliza MLflow como repositorio central en una cuenta de AWS aislada.
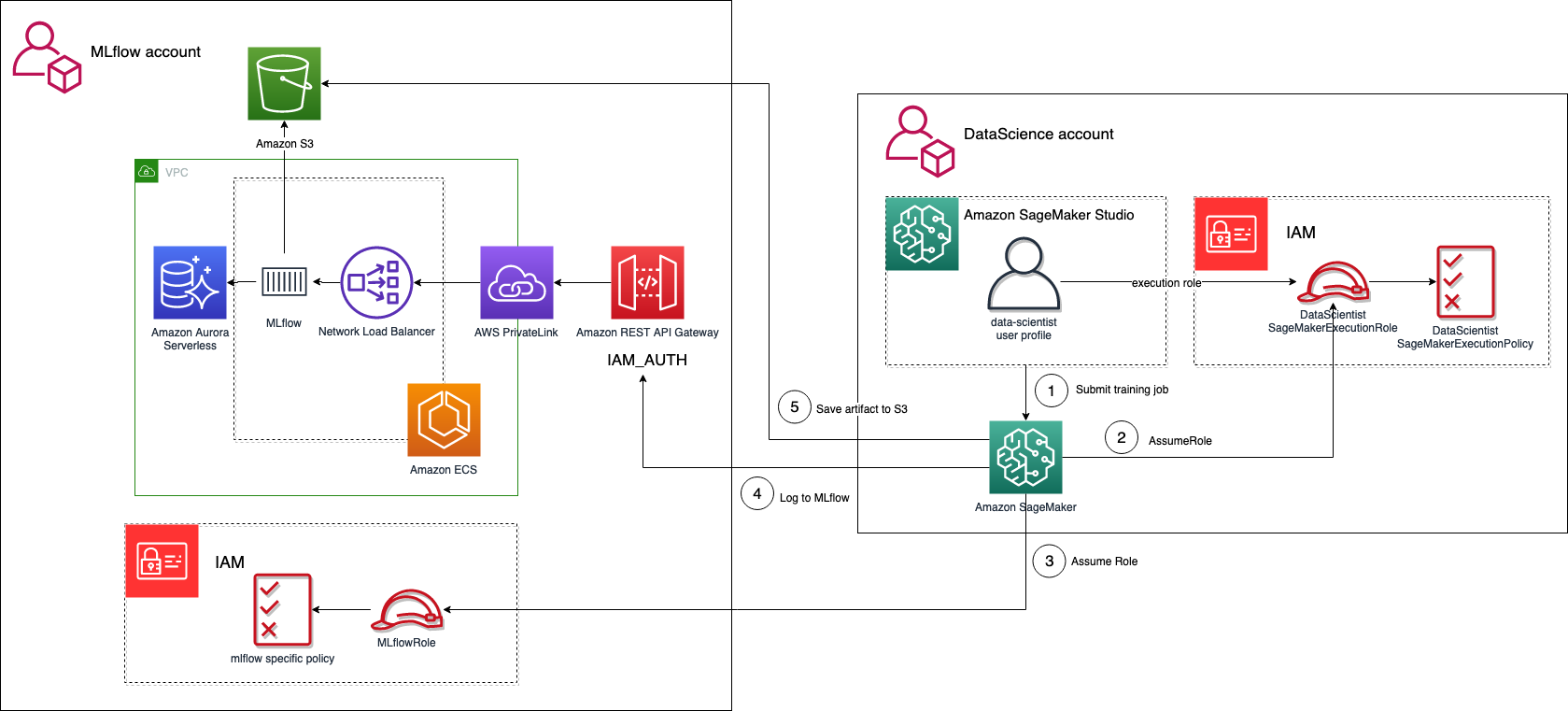
Para este caso de uso, tenemos dos cuentas: una para el servidor de MLflow y otra para la experimentación a la que puede acceder el equipo de ciencia de datos. Para habilitar el acceso entre cuentas desde un trabajo de capacitación de SageMaker que se ejecuta en la cuenta de ciencia de datos, necesitamos los siguientes elementos:
- Un rol de ejecución de SageMaker en la cuenta de AWS de ciencia de datos con una política de IAM adjunta que permite asumir un rol diferente en la cuenta de MLflow:
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "<ARN-ROLE-IN-MLFLOW-ACCOUNT>" }
}- Una función de IAM en la cuenta de MLflow con la política de IAM correcta adjunta que otorga acceso al servidor de seguimiento de MLflow y permite que la función de ejecución de SageMaker en la cuenta de ciencia de datos la asuma:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "<ARN-SAGEMAKER-EXECUTION-ROLE-IN-DATASCIENCE-ACCOUNT>" }, "Action": "sts:AssumeRole" } ]
}Dentro del script de entrenamiento que se ejecuta en la cuenta de ciencia de datos, puede usar este ejemplo antes de inicializar el cliente de MLflow. Debe asumir el rol en la cuenta de MLflow y almacenar las credenciales temporales como variables de entorno, ya que este nuevo conjunto de credenciales será recogido por una nueva sesión de Boto3 inicializada dentro del cliente de MLflow.
import boto3 # Session using the SageMaker Execution Role in the Data Science Account
session = boto3.Session()
sts = session.client("sts") response = sts.assume_role( RoleArn="<ARN-ROLE-IN-MLFLOW-ACCOUNT>", RoleSessionName="AssumedMLflowAdmin"
) credentials = response['Credentials']
os.environ['AWS_ACCESS_KEY_ID'] = credentials['AccessKeyId']
os.environ['AWS_SECRET_ACCESS_KEY'] = credentials['SecretAccessKey']
os.environ['AWS_SESSION_TOKEN'] = credentials['SessionToken'] # set remote mlflow server and initialize a new boto3 session in the context
# of the assumed role
mlflow.set_tracking_uri(tracking_uri)
experiment = mlflow.set_experiment(experiment_name)En este ejemplo, RoleArn es el ARN del rol que desea asumir, y RoleSessionName es el nombre que elige para la sesión asumida. El sts.assume_role El método devuelve credenciales de seguridad temporales que el cliente de MLflow usará para crear un nuevo cliente para el rol asumido. El cliente de MLflow luego enviará solicitudes firmadas a API Gateway en el contexto del rol asumido.
Renderizar MLflow dentro de SageMaker Studio
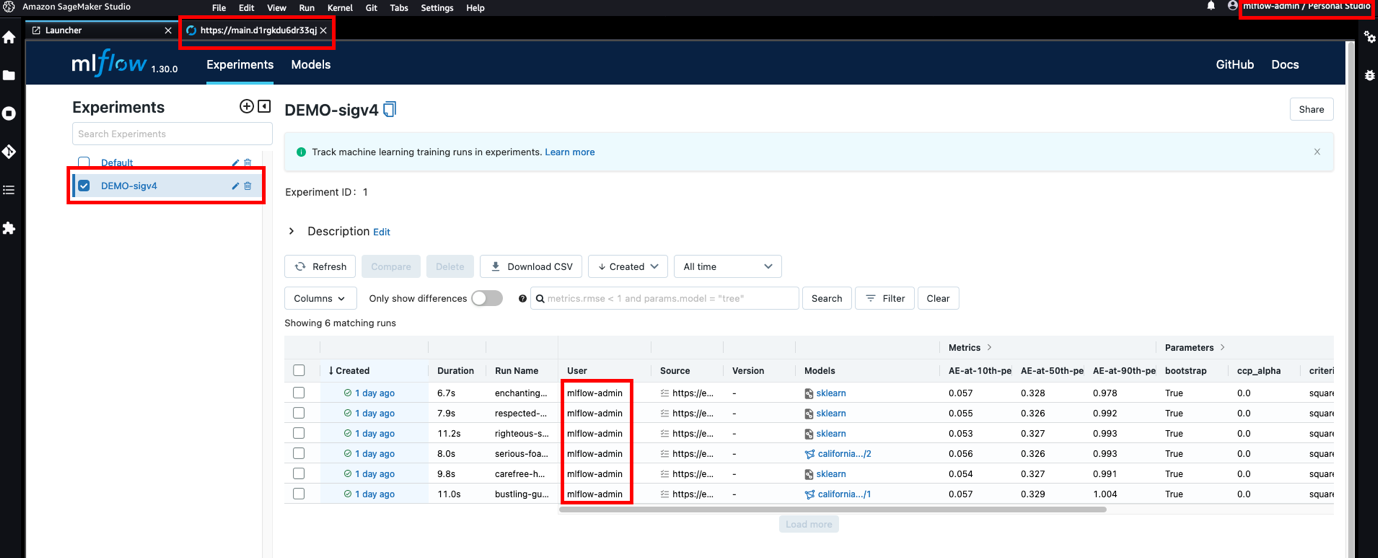
SageMaker Studio se basa en JupyterLab y, al igual que en JupyterLab, puede instalar extensiones para aumentar su productividad. Gracias a esta flexibilidad, los científicos de datos que trabajan con MLflow y SageMaker pueden mejorar aún más su integración al acceder a la interfaz de usuario de MLflow desde el entorno de Studio y visualizar inmediatamente los experimentos y las ejecuciones registradas. La siguiente captura de pantalla muestra un ejemplo de MLflow renderizado en Studio.
Para obtener información sobre la instalación de extensiones de JupyterLab en Studio, consulte Amazon SageMaker Studio y SageMaker Notebook Instance ahora vienen con notebooks JupyterLab 3 para aumentar la productividad de los desarrolladores. Para obtener detalles sobre cómo agregar automatización a través de configuraciones de ciclo de vida, consulte Personalice Amazon SageMaker Studio mediante configuraciones de ciclo de vida.
En el repositorio de muestra que respalda esta publicación, proporcionamos Instrucciones sobre cómo instalar el jupyterlab-iframe extensión. Una vez instalada la extensión, puede acceder a la interfaz de usuario de MLflow sin salir de Studio utilizando el mismo conjunto de credenciales que ha almacenado en el grupo de usuarios de Amazon Cognito.
Próximos pasos
Hay varias opciones para ampliar este trabajo. Una idea es consolidar el almacén de identidades para SageMaker Studio y la interfaz de usuario de MLflow. Otra opción sería utilizar un servicio de federación de identidad de terceros con Amazon Cognito y luego utilizar Centro de identidad de AWS IAM (sucesor de AWS Single Sign-On) para otorgar acceso a Studio utilizando la misma identidad de terceros. Otra es introducir la automatización completa usando Canalizaciones de Amazon SageMaker para la parte de CI/CD de la creación de modelos, y usar MLflow como un servidor de seguimiento de experimentos centralizado y un registro de modelos con sólidas capacidades de gobierno, así como automatización para implementar automáticamente modelos aprobados en un punto final de alojamiento de SageMaker.
Conclusión
El objetivo de esta publicación era proporcionar un control de acceso de nivel empresarial para MLflow. Para lograr esto, separamos los procesos de autenticación y autorización del servidor MLflow y los transferimos a API Gateway. Utilizamos dos métodos de autorización ofrecidos por API Gateway, autorizadores de IAM y autorizadores de Lambda, para satisfacer los requisitos del SDK de Python de MLflow y la interfaz de usuario de MLflow. Es importante comprender que los usuarios son externos a MLflow, por lo tanto, una gobernanza coherente requiere mantener las políticas de IAM, especialmente en el caso de permisos muy granulares. Finalmente, demostramos cómo mejorar la experiencia de los científicos de datos mediante la integración de MLflow en Studio a través de extensiones simples.
Pruebe la solución usted mismo accediendo a la Repositorio GitHub ¡y háganos saber si tiene alguna pregunta en los comentarios!
Recursos adicionales
Para obtener más información sobre SageMaker y MLflow, consulte lo siguiente:
Acerca de los autores
 paolo di francesco es Arquitecto de Soluciones Sénior en Amazon Web Services (AWS). Es Doctor en Ingeniería de Telecomunicaciones y tiene experiencia en ingeniería de software. Le apasiona el aprendizaje automático y actualmente se está enfocando en usar su experiencia para ayudar a los clientes a alcanzar sus objetivos en AWS, en particular en discusiones sobre MLOps. Fuera del trabajo, le gusta jugar al fútbol y leer.
paolo di francesco es Arquitecto de Soluciones Sénior en Amazon Web Services (AWS). Es Doctor en Ingeniería de Telecomunicaciones y tiene experiencia en ingeniería de software. Le apasiona el aprendizaje automático y actualmente se está enfocando en usar su experiencia para ayudar a los clientes a alcanzar sus objetivos en AWS, en particular en discusiones sobre MLOps. Fuera del trabajo, le gusta jugar al fútbol y leer.
 chris fregly es Arquitecto Especialista Principal de Soluciones para IA y aprendizaje automático en Amazon Web Services (AWS) con sede en San Francisco, California. Es coautor del libro de O'Reilly, "Ciencia de datos en AWS". Chris también es el fundador de muchas reuniones globales centradas en Apache Spark, TensorFlow, Ray y KubeFlow. Habla regularmente en conferencias de inteligencia artificial y aprendizaje automático en todo el mundo, incluidas O'Reilly AI, Open Data Science Conference y Big Data Spain.
chris fregly es Arquitecto Especialista Principal de Soluciones para IA y aprendizaje automático en Amazon Web Services (AWS) con sede en San Francisco, California. Es coautor del libro de O'Reilly, "Ciencia de datos en AWS". Chris también es el fundador de muchas reuniones globales centradas en Apache Spark, TensorFlow, Ray y KubeFlow. Habla regularmente en conferencias de inteligencia artificial y aprendizaje automático en todo el mundo, incluidas O'Reilly AI, Open Data Science Conference y Big Data Spain.
 irshad buchh es Arquitecto Principal de Soluciones en Amazon Web Services (AWS). Irshad trabaja con grandes socios ISV globales y SI de AWS y los ayuda a desarrollar su estrategia de nube y una amplia adopción de la plataforma de computación en la nube de Amazon. Irshad interactúa con los CIO, CTO y sus arquitectos y los ayuda a ellos y a sus clientes finales a implementar su visión de la nube. Irshad posee los compromisos estratégicos y técnicos y el éxito final en torno a proyectos de implementación específicos, y desarrolla una profunda experiencia en las tecnologías de Amazon Web Services, así como un amplio conocimiento sobre cómo se construyen las aplicaciones y los servicios utilizando la plataforma de Amazon Web Services.
irshad buchh es Arquitecto Principal de Soluciones en Amazon Web Services (AWS). Irshad trabaja con grandes socios ISV globales y SI de AWS y los ayuda a desarrollar su estrategia de nube y una amplia adopción de la plataforma de computación en la nube de Amazon. Irshad interactúa con los CIO, CTO y sus arquitectos y los ayuda a ellos y a sus clientes finales a implementar su visión de la nube. Irshad posee los compromisos estratégicos y técnicos y el éxito final en torno a proyectos de implementación específicos, y desarrolla una profunda experiencia en las tecnologías de Amazon Web Services, así como un amplio conocimiento sobre cómo se construyen las aplicaciones y los servicios utilizando la plataforma de Amazon Web Services.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/securing-mlflow-in-aws-fine-grained-access-control-with-aws-native-services/

