En la era digital actual, el registro es un aspecto crítico del desarrollo y la administración de aplicaciones, pero administrar registros de manera eficiente y cumplir con las normas de protección de datos puede ser un desafío importante. Zoom, en colaboración con la Laboratorio de datos de AWS equipo, desarrolló una arquitectura innovadora para superar estos desafíos y agilizar sus procesos de registro y eliminación de registros. En esta publicación, exploramos la arquitectura y los beneficios que brinda a Zoom y sus usuarios.
Desafíos del registro de aplicaciones: gestión de datos y cumplimiento
Los registros de aplicaciones son un componente esencial de cualquier aplicación; proporcionan información valiosa sobre el uso y el rendimiento del sistema. Estos registros se utilizan para diversos fines, como depuración, auditoría, supervisión del rendimiento, inteligencia empresarial, mantenimiento del sistema y seguridad. Sin embargo, aunque estos registros de la aplicación son necesarios para mantener y mejorar la aplicación, también representan un desafío interesante. Estos registros de aplicaciones pueden contener datos de identificación personal, como nombres de usuario, direcciones de correo electrónico, direcciones IP e historial de navegación, lo que crea un problema de privacidad de datos.
Leyes como el Reglamento General de Protección de Datos (GDPR) y la Ley de Privacidad del Consumidor de California (CCPA) exigen que las organizaciones conserven los registros de las aplicaciones durante un período de tiempo específico. El tiempo exacto requerido para el almacenamiento de datos varía según la regulación específica y el tipo de datos que se almacenan. El motivo de estos períodos de retención de datos es garantizar que las empresas no conserven los datos personales más tiempo del necesario, lo que podría aumentar el riesgo de filtraciones de datos y otros incidentes de seguridad. Esto también ayuda a garantizar que las empresas no utilicen datos personales para fines distintos a aquellos para los que fueron recopilados, lo que podría ser una violación de las leyes de privacidad. Estas leyes también otorgan a las personas el derecho a solicitar la eliminación de sus datos personales, también conocido como el “derecho al olvido”. Las personas tienen derecho a que se supriman sus datos personales, sin dilación indebida.
Entonces, por un lado, las organizaciones necesitan recopilar datos de registro de aplicaciones para garantizar el correcto funcionamiento de sus servicios y conservar los datos durante un período de tiempo específico. Pero, por otro lado, pueden recibir solicitudes de personas para eliminar sus datos personales de los registros. Esto crea un acto de equilibrio para las organizaciones porque deben cumplir con los requisitos de retención y eliminación de datos.
Este problema se vuelve cada vez más desafiante para las organizaciones más grandes que operan en varios países y estados, porque cada país y estado puede tener sus propias reglas y regulaciones con respecto a la retención y eliminación de datos. Por ejemplo, la Ley de Protección de Información Personal y Documentos Electrónicos (PIPEDA) en Canadá y la Ley de Privacidad de Australia en Australia son leyes similares al RGPD, pero pueden tener diferentes períodos de retención o diferentes excepciones. Por lo tanto, las organizaciones, grandes o pequeñas, deben navegar este complejo panorama de requisitos de retención y eliminación de datos, al mismo tiempo que se aseguran de que cumplen con todas las leyes y regulaciones aplicables.
Arquitectura inicial de Zoom
Durante la pandemia de COVID-19, el uso de Zoom se disparó a medida que se pedía a más y más personas que trabajaran y asistieran a clases desde casa. La empresa tuvo que escalar rápidamente sus servicios para adaptarse al aumento y trabajó con AWS para implementar la capacidad en la mayoría de las regiones del mundo. Con un aumento repentino en la gran cantidad de puntos de enlace de aplicaciones, tuvieron que hacer evolucionar rápidamente su arquitectura de análisis de registros y trabajaron con el equipo de AWS Data Lab para crear prototipos e implementar rápidamente una arquitectura para su caso de uso de cumplimiento.
En Zoom, las necesidades de rendimiento y rendimiento de la ingesta de datos son muy estrictas. Los datos debían ingerirse desde varios miles de puntos finales de aplicaciones que producían más de 30 millones de mensajes cada minuto, lo que generaba más de 100 TB de datos de registro por día. La canalización de ingesta existente consistía en escribir los datos en Apache Hadoop Almacenamiento HDFS a través de Apache Kafka primero y luego ejecutar trabajos diarios para mover los datos al almacenamiento persistente. Esto tomó varias horas mientras también ralentizaba la ingestión y creaba el potencial de pérdida de datos. Escalar la arquitectura también fue un problema porque los datos de HDFS tendrían que moverse cada vez que se agregaran o eliminaran nodos. Además, la semántica transaccional en miles de millones de registros era necesaria para ayudar a cumplir con las solicitudes de eliminación de datos relacionadas con el cumplimiento, y la arquitectura existente de trabajos por lotes diarios era ineficiente desde el punto de vista operativo.
Fue en ese momento, a través de conversaciones con el equipo de cuentas de AWS, que el equipo de laboratorio de datos de AWS se involucró para ayudar a crear una solución para la hiperescala de Zoom.
Resumen de la solución
El laboratorio de datos de AWS ofrece compromisos de ingeniería conjuntos y acelerados entre los clientes y los recursos técnicos de AWS para crear productos tangibles que aceleren las iniciativas de datos, análisis, inteligencia artificial (IA), aprendizaje automático (ML), sin servidor y de modernización de contenedores. El Data Lab tiene tres ofertas: Build Lab, Design Lab y Resident Architect. Durante los laboratorios de construcción y diseño, los arquitectos de soluciones de laboratorio de datos de AWS y los expertos de AWS apoyaron a Zoom específicamente al proporcionar orientación arquitectónica prescriptiva, compartir las mejores prácticas, crear un prototipo funcional y eliminar obstáculos técnicos para ayudar a satisfacer sus necesidades de producción.
Zoom y el equipo de AWS (denominados colectivamente como "el equipo" en el futuro) identificaron dos flujos de trabajo principales para la ingesta y eliminación de datos.
Flujo de trabajo de ingesta de datos
El siguiente diagrama ilustra el flujo de trabajo de ingesta de datos.
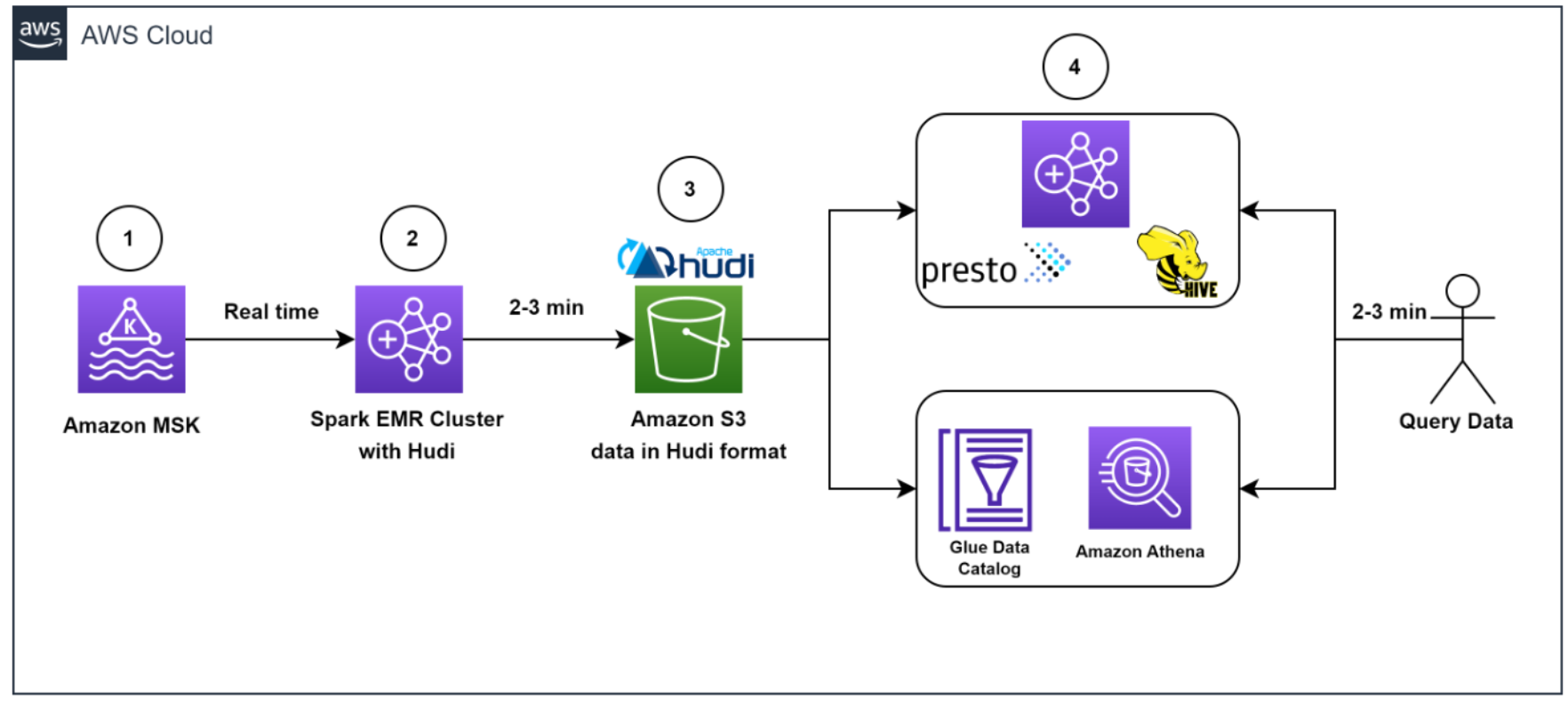
El equipo necesitaba completar rápidamente millones de mensajes de Kafka en el entorno de desarrollo/prueba para lograrlo. Para acelerar el proceso, nosotros (el equipo) optamos por utilizar Streaming administrado por Amazon para Apache Kafka (Amazon MSK), que simplifica la ingesta y el procesamiento de datos de transmisión en tiempo real, y estuvimos en funcionamiento en menos de un día.
Para generar datos de prueba que se asemejaran a los datos de producción, el equipo de AWS Data Lab creó un script de Python personalizado que llenó uniformemente más de 1.2 millones de mensajes en varias particiones de Kafka. Para igualar la configuración de producción en la cuenta de desarrollo, tuvimos que aumentar el límite de cuota de la nube a través de un ticket de soporte.
Utilizamos Amazon MSK y la capacidad de transmisión estructurada de Spark en EMR de Amazon para ingerir y procesar los mensajes Kafka entrantes con alto rendimiento y baja latencia. Específicamente, insertamos los datos de la fuente en clústeres de EMR a una velocidad de entrada máxima de 150 millones de mensajes de Kafka cada 5 minutos, y cada mensaje de Kafka contiene de 7 a 25 registros de datos de registro.
Para almacenar los datos, elegimos usar apache hudi como el formato de la tabla. Optamos por Hudi porque es un marco de gestión de datos de código abierto que proporciona capacidades de inserción, actualización y eliminación a nivel de registro además de una capa de almacenamiento inmutable como Servicio de almacenamiento simple de Amazon (Amazon S3). Además, Hudi está optimizado para manejar grandes conjuntos de datos y funciona bien con Spark Structured Streaming, que ya se usaba en Zoom.
Después de almacenar en búfer 150 millones de mensajes, procesamos los mensajes con Spark Structured Streaming en Amazon EMR y escribimos los datos en Amazon S3 en formato compatible con Apache Hudi cada 5 minutos. Primero aplanamos la matriz de mensajes, creando un único registro a partir de la matriz anidada de mensajes. Luego agregamos una clave única, conocida como clave de registro Hudi, a cada mensaje. Esta clave permite a Hudi realizar operaciones de inserción, actualización y eliminación a nivel de registro en los datos. También extrajimos los valores de los campos, incluidas las claves de partición de Hudi, de los mensajes entrantes.
Esta arquitectura permitió a los usuarios finales consultar los datos almacenados en Amazon S3 utilizando Atenea amazónica con el Catálogo de datos de AWS Glue o utilizando Colmena Apache y presto.
Flujo de trabajo de eliminación de datos
El siguiente diagrama ilustra el flujo de trabajo de eliminación de datos.
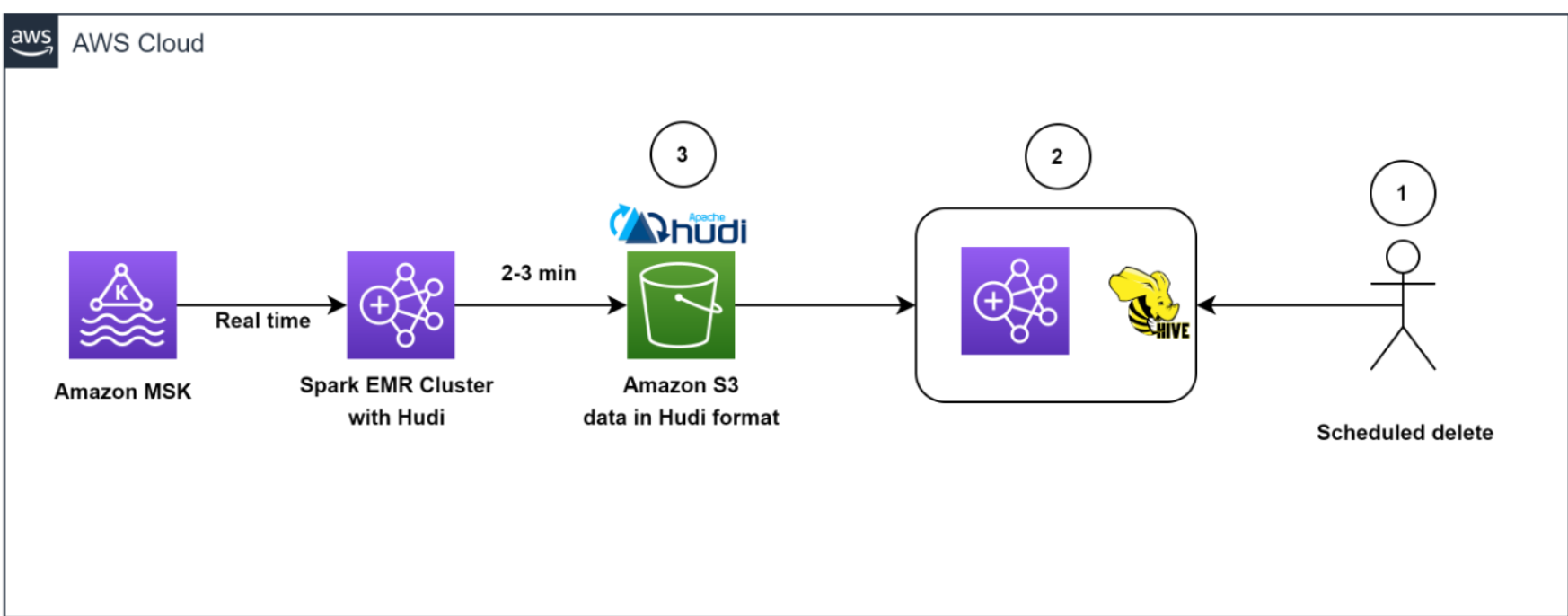
Nuestra arquitectura permitió eliminaciones de datos eficientes. Para ayudar a cumplir con la política de retención de datos iniciada por el cliente para las eliminaciones de GDPR, los trabajos programados se ejecutaron diariamente para identificar los datos que se eliminarán en modo por lotes.
Luego activamos un clúster EMR transitorio para ejecutar el trabajo upsert GDPR para eliminar los registros. Los datos se almacenaron en Amazon S3 en formato Hudi, y el índice integrado de Hudi nos permitió eliminar registros de manera eficiente mediante filtros de floración y rangos de archivos. Debido a que solo era necesario leer y reescribir los archivos que contenían las claves de registro, solo tomó entre 1 y 2 minutos eliminar 1,000 registros de los 1 millones de registros, lo que antes tomaba horas completar cuando se leían particiones completas.
En general, nuestra solución permitió la eliminación eficiente de datos, lo que proporcionó una capa adicional de seguridad de datos que era fundamental para Zoom, a la luz de sus requisitos de GDPR.
Arquitectura para optimizar la escala, el rendimiento y el costo
En esta sección, compartimos las siguientes estrategias que Zoom tomó para optimizar la escala, el rendimiento y el costo:
- Optimización de la ingestión
- Optimización del rendimiento y la utilización de Amazon EMR
- Desvincular la ingestión y la eliminación del RGPD mediante EMRFS
- Eliminaciones eficientes con Apache Hudi
- Optimización para lecturas de baja latencia con Apache Hudi
- Monitoreo
Optimización de la ingestión
Para mantener el almacenamiento en Kafka optimizado y óptimo, así como para obtener una vista en tiempo real de los datos, creamos un trabajo de Spark para leer los mensajes entrantes de Kafka en lotes de 150 millones de mensajes y escribimos en Amazon S3 en formato compatible con Hudi cada 5 minutos. Incluso durante las etapas iniciales de la iteración, cuando aún no habíamos comenzado a escalar y ajustar, pudimos cargar con éxito todos los mensajes de Kafka de manera constante en menos de 2.5 minutos usando el Tiempo de ejecución de Amazon EMR para Apache Spark.
Optimización del rendimiento y la utilización de Amazon EMR
Lanzamos un clúster de EMR de costo optimizado y cambiamos de grupos de instancias uniformes a usar flotas de instancias de EMR. Elegimos flotas de instancias porque necesitábamos la flexibilidad para usar instancias de spot para nodos de tareas y queríamos diversificar el riesgo de quedarnos sin capacidad para un tipo de instancia específico en nuestra zona de disponibilidad.
Comenzamos a experimentar con ejecuciones de prueba cambiando primero la cantidad de particiones de Kafka de 400 a 1,000 y luego cambiando la cantidad de nodos de tareas y tipos de instancias. En función de los resultados de la ejecución, el equipo de AWS recomendó usar Amazon EMR con tres nodos principales (r5.16xlarge (64 vCPU cada uno)) y 18 nodos de tareas mediante instancias de flota de Spot (una combinación de r5.16xlarge ( 64 vCPU), r5.12xlarge (48 vCPU), r5.8xlarge (32 vCPU)). Estas recomendaciones ayudaron a Zoom a reducir sus costos de Amazon EMR en más del 80 % mientras cumplía con los objetivos de rendimiento deseados de ingerir 150 millones de mensajes de Kafka en menos de 5 minutos.
Desvincular la ingestión y la eliminación del RGPD mediante EMRFS
Un beneficio bien conocido de la separación del almacenamiento y la computación es que puede escalar los dos de forma independiente. Pero una ventaja no tan obvia es que puede desacoplar las cargas de trabajo continuas de las cargas de trabajo esporádicas. Anteriormente, los datos se almacenaban en HDFS. Los trabajos de eliminación de RGPD y los trabajos de movimiento de datos que consumen muchos recursos competirían por los recursos con la ingestión de secuencias, lo que provocaría un retraso de más de 5 horas en los clústeres de Kafka ascendentes, que estuvo cerca de llenar el almacenamiento de Kafka (que solo tenía 6 horas de retención de datos ) y potencialmente causar la pérdida de datos. La descarga de datos de HDFS a Amazon S3 nos dio la libertad de lanzar clústeres de EMR transitorios independientes bajo demanda para realizar la eliminación de datos, lo que ayuda a garantizar que la ingesta continua de datos de Kafka a Amazon EMR no se vea privada de recursos. Esto permitió que el sistema ingiera datos cada 5 minutos y complete cada lectura de Spark Streaming en 2 o 3 minutos. Otro efecto secundario del uso de EMRFS es un clúster de costos optimizados, porque eliminamos la dependencia de Tienda de bloques elásticos de Amazon (Amazon EBS) para más de 300 TB de almacenamiento que se utilizó para tres copias (incluidas dos réplicas) de datos HDFS. Ahora pagamos solo por una copia de los datos en Amazon S3, que proporciona 11 9s de durabilidad y es un almacenamiento relativamente económico.
Eliminaciones eficientes con Apache Hudi
¿Qué pasa con el conflicto entre las escrituras de ingesta y las eliminaciones de GDPR cuando se ejecutan simultáneamente? Aquí es donde destaca el poder de Apache Hudi.
Apache Hudi proporciona un formato de tabla para lagos de datos con semántica transaccional que permite la separación de cargas de trabajo de ingesta y actualizaciones cuando se ejecutan simultáneamente. El sistema pudo eliminar 1,000 registros de manera consistente en menos de un minuto. Había algunas limitaciones en las escrituras simultáneas en ApacheHudi 0.7.0, pero el equipo de Amazon EMR solucionó este problema rápidamente con una adaptación ApacheHudi 0.8.0, cual apoya optimista control de concurrencia, a la versión actual (en el momento de la colaboración de AWS Data Lab) de Amazon EMR 6.4. Esto ahorró tiempo en las pruebas y permitió una transición rápida a la nueva versión con pruebas mínimas. Esto nos permitió consultar los datos directamente con Athena rápidamente sin tener que activar un clúster para ejecutar consultas ad hoc, así como consultar los datos con Presto, Trino y Hive. El desacoplamiento de las capas de almacenamiento y computación proporcionó la flexibilidad no solo para consultar datos en diferentes clústeres de EMR, sino también para eliminar datos mediante un clúster transitorio completamente independiente.
Optimización para lecturas de baja latencia con Apache Hudi
Para optimizar las lecturas de baja latencia con Apache Hudi, necesitábamos abordar el problema de la creación de demasiados archivos pequeños en Amazon S3 debido a la transmisión continua de datos al lago de datos.
Utilizamos las características de Apache Hudi para ajustar el tamaño de los archivos para una consulta óptima. Específicamente, redujimos el grado de paralelismo en Hudi del valor predeterminado de 1,500 a un número más bajo. El paralelismo se refiere a la cantidad de subprocesos utilizados para escribir datos en Hudi; al reducirlo, pudimos crear archivos más grandes que eran más óptimos para realizar consultas.
Debido a que necesitábamos optimizar para la ingestión de transmisión de alto volumen, decidimos implementar el fusionar en lectura tipo de tabla (en lugar de Copiar en escrito) para nuestra carga de trabajo. Este tipo de tabla nos permitió ingerir rápidamente los datos entrantes en archivos delta en formato de fila (Avro) y compactar de forma asíncrona los archivos delta en archivos Parquet en columnas para lecturas rápidas. Para hacer esto, ejecutamos el trabajo de compactación de Hudi en segundo plano. La compactación es el proceso de combinar archivos delta basados en filas para producir nuevas versiones de archivos en columnas. Debido a que el trabajo de compactación usaría recursos informáticos adicionales, ajustamos el grado de paralelismo para la inserción a un valor más bajo de 1,000 para tener en cuenta el uso de recursos adicionales. Este ajuste nos permitió crear archivos más grandes sin sacrificar el rendimiento.
En general, nuestro enfoque de optimización para lecturas de baja latencia con Apache Hudi nos permitió administrar mejor el tamaño de los archivos y mejorar el rendimiento general de nuestro lago de datos.
Monitoreo
El equipo supervisó los clústeres de MSK con Prometeo (una herramienta de monitoreo de código abierto). Además, mostramos cómo monitorear los trabajos de transmisión de Spark usando Reloj en la nube de Amazon métrica. Para obtener más información, consulte Monitoree las aplicaciones de transmisión de Spark en Amazon EMR.
Resultados
La colaboración entre Zoom y AWS Data Lab demostró mejoras significativas en la ingesta, el procesamiento, el almacenamiento y la eliminación de datos mediante una arquitectura con Amazon EMR y Apache Hudi. Un beneficio clave de la arquitectura fue la reducción de los costos de infraestructura, que se logró mediante el uso de tecnologías nativas de la nube y la gestión eficiente del almacenamiento de datos. Otro beneficio fue una mejora en las capacidades de gestión de datos.
Mostramos que los costos de los clústeres de EMR se pueden reducir en aproximadamente un 82 % y, al mismo tiempo, reducir los costos de almacenamiento en aproximadamente un 90 % en comparación con la arquitectura anterior basada en HDFS. Todo esto mientras hace que los datos estén disponibles en el lago de datos dentro de los 5 minutos posteriores a la ingesta desde la fuente. También demostramos que las eliminaciones de datos de un lago de datos que contiene varios petabytes de datos se pueden realizar de manera mucho más eficiente. Con nuestro enfoque optimizado, pudimos eliminar aproximadamente 1,000 registros en solo 1 a 2 minutos, en comparación con las 3 horas o más requeridas anteriormente.
Conclusión
En conclusión, el proceso de análisis de registros, que implica la recopilación, el procesamiento, el almacenamiento, el análisis y la eliminación de datos de registro de diversas fuentes, como servidores, aplicaciones y dispositivos, es fundamental para ayudar a las organizaciones a trabajar para cumplir con la resiliencia, la seguridad y el rendimiento de sus servicios. necesidades de monitoreo, solución de problemas y cumplimiento, como GDPR.
Esta publicación compartió lo que Zoom y el equipo de AWS Data Lab lograron juntos para resolver los desafíos críticos de canalización de datos, y Zoom amplió aún más la solución para optimizar los trabajos de extracción, transformación y carga (ETL) y la eficiencia de los recursos. Sin embargo, también puede usar los patrones de arquitectura que se presentan aquí para crear rápidamente soluciones rentables y escalables para otros casos de uso. Comuníquese con su equipo de AWS para obtener más información o comuníquese Ventas.
Acerca de los autores
 Sekar Srinivasan es un Arquitecto de Soluciones Especialista Sr. en AWS centrado en Big Data y Analytics. Sekar tiene más de 20 años de experiencia trabajando con datos. Le apasiona ayudar a los clientes a crear soluciones escalables que modernicen su arquitectura y generen información a partir de sus datos. En su tiempo libre le gusta trabajar en proyectos sin fines de lucro enfocados en la educación de niños desfavorecidos.
Sekar Srinivasan es un Arquitecto de Soluciones Especialista Sr. en AWS centrado en Big Data y Analytics. Sekar tiene más de 20 años de experiencia trabajando con datos. Le apasiona ayudar a los clientes a crear soluciones escalables que modernicen su arquitectura y generen información a partir de sus datos. En su tiempo libre le gusta trabajar en proyectos sin fines de lucro enfocados en la educación de niños desfavorecidos.
 Chandra Dhandapani es arquitecto sénior de soluciones en AWS, donde se especializa en crear soluciones para clientes en análisis, IA/ML y bases de datos. Tiene mucha experiencia en la creación y escalado de aplicaciones en diferentes industrias, incluidas la atención médica y la tecnología financiera. Fuera del trabajo, es un ávido viajero y disfruta de los deportes, la lectura y el entretenimiento.
Chandra Dhandapani es arquitecto sénior de soluciones en AWS, donde se especializa en crear soluciones para clientes en análisis, IA/ML y bases de datos. Tiene mucha experiencia en la creación y escalado de aplicaciones en diferentes industrias, incluidas la atención médica y la tecnología financiera. Fuera del trabajo, es un ávido viajero y disfruta de los deportes, la lectura y el entretenimiento.
 Amit Kumar Agrawal es arquitecto sénior de soluciones en AWS, con sede en el área de la bahía de San Francisco. Trabaja con grandes clientes ISV estratégicos para diseñar soluciones en la nube que aborden sus desafíos comerciales. Durante su tiempo libre le gusta explorar el aire libre con su familia.
Amit Kumar Agrawal es arquitecto sénior de soluciones en AWS, con sede en el área de la bahía de San Francisco. Trabaja con grandes clientes ISV estratégicos para diseñar soluciones en la nube que aborden sus desafíos comerciales. Durante su tiempo libre le gusta explorar el aire libre con su familia.
 Shah viral es un especialista en ventas de análisis que trabaja con AWS durante 5 años ayudando a los clientes a tener éxito en su viaje de datos. Tiene más de 20 años de experiencia trabajando con clientes empresariales y nuevas empresas, principalmente en el espacio de datos y bases de datos. Le encanta viajar y pasar tiempo de calidad con su familia.
Shah viral es un especialista en ventas de análisis que trabaja con AWS durante 5 años ayudando a los clientes a tener éxito en su viaje de datos. Tiene más de 20 años de experiencia trabajando con clientes empresariales y nuevas empresas, principalmente en el espacio de datos y bases de datos. Le encanta viajar y pasar tiempo de calidad con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/how-zoom-implemented-streaming-log-ingestion-and-efficient-gdpr-deletes-using-apache-hudi-on-amazon-emr/

