Introducción
En el campo de la inteligencia artificial, los modelos de lenguaje grande (LLM) y los modelos de IA generativa como GPT-4 de OpenAI, Claude 2 de Anthropic, Llama de Meta, Falcon, Palm de Google, etc., han revolucionado la forma en que resolvemos problemas. Los LLM utilizan técnicas de aprendizaje profundo para realizar tareas de procesamiento del lenguaje natural. Este artículo le enseñará a crear aplicaciones LLM utilizando una base de datos vectorial. Es posible que haya interactuado con un chatbot como el servicio de atención al cliente de Amazon o Flipkart Decision Assistant. Generan texto similar al humano y brindan una experiencia de usuario interactiva casi indistinguible de las conversaciones de la vida real. Sin embargo, estos LLM deben optimizarse para que produzcan resultados muy relevantes y específicos que sean realmente útiles para casos de uso específicos.

Por ejemplo, si pregunta: "¿Cómo cambio mi idioma en la aplicación de Android?" a la aplicación de servicio al cliente de Amazon, es posible que no haya sido capacitado en este texto exacto y, por lo tanto, es posible que no pueda responder. Aquí es donde una base de datos vectorial viene al rescate. Una base de datos vectorial almacena los textos del dominio (en este caso, documentos de ayuda) y consultas anteriores de todos los usuarios, incluido el historial de pedidos, etc., como incrustaciones numéricas y proporciona una búsqueda de vectores similares en tiempo real. En este caso, codifica esta consulta en un vector numérico y lo utiliza para realizar una búsqueda de similitud en su base de datos de vectores y encontrar sus vecinos más cercanos. Con esta ayuda, el chatbot puede guiar al usuario correctamente a la sección "Cambiar tu preferencia de idioma" en la aplicación de Amazon.
OBJETIVOS DE APRENDIZAJE
- ¿Cómo funcionan los LLM, cuáles son sus limitaciones y por qué necesitan bases de datos vectoriales?
- Introducción a la incorporación de modelos y cómo codificarlos y utilizarlos en aplicaciones.
- Aprenda qué es una base de datos vectorial y cómo forman parte de la arquitectura de la aplicación LLM.
- Aprenda a codificar aplicaciones LLM/IA generativa utilizando bases de datos vectoriales y tensorflow.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué son los LLM?
Los modelos de lenguaje grande (LLM) son modelos fundamentales de aprendizaje automático que utilizan algoritmos de aprendizaje profundo para procesar y comprender el lenguaje natural. Estos modelos están entrenados en cantidades masivas de datos de texto para aprender patrones y relaciones de entidades en el idioma. Los LLM pueden realizar muchos tipos de tareas lingüísticas, como traducir idiomas, analizar sentimientos, conversaciones de chatbot y más. Pueden comprender datos textuales complejos, identificar entidades y relaciones entre ellos y generar texto nuevo que sea coherente y gramaticalmente preciso.
Leer más sobre LLM esta página.
¿Cómo funcionan los LLM?
Los LLM se entrenan utilizando una gran cantidad de datos, a menudo terabytes, incluso petabytes, con miles de millones o billones de parámetros, lo que les permite predecir y generar respuestas relevantes basadas en las indicaciones o consultas del usuario. Procesan datos de entrada a través de incrustaciones de palabras, capas de autoatención y redes de retroalimentación para generar texto significativo. Puedes leer más sobre arquitecturas LLM esta página.
Limitaciones de los LLM
Si bien los LLM parecen generar respuestas con una precisión bastante alta, incluso mejor que los humanos en muchos estandarizados pruebas, estos modelos todavía tienen limitaciones. En primer lugar, dependen únicamente de sus datos de entrenamiento para desarrollar su razonamiento y, por lo tanto, pueden carecer de información específica o actual en los datos. Esto lleva a que el modelo genere respuestas incorrectas o inusuales, también conocidas como "alucinaciones". Ha habido una continua esfuerzo para mitigar esto. En segundo lugar, es posible que el modelo no se comporte o responda de una manera que se alinee con las expectativas del usuario.
Para abordar esto, las bases de datos vectoriales y los modelos integrados mejoran el conocimiento de los LLM/IA generativa al proporcionar búsquedas adicionales de modalidades similares (texto, imagen, video, etc.) para las cuales el usuario busca información. A continuación se muestra un ejemplo en el que los LLM no tienen la respuesta que solicita el usuario y, en cambio, dependen de una base de datos vectorial para encontrar esa información.

LLM y bases de datos vectoriales
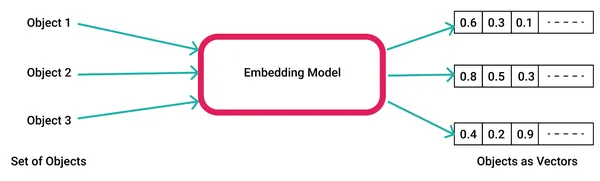
Los modelos de lenguaje grande (LLM) se están utilizando o integrando en muchas partes de la industria, como el comercio electrónico, los viajes, la búsqueda, la creación de contenido y las finanzas. Estos modelos se basan en un tipo de base de datos relativamente nuevo, conocida como base de datos vectorial, que almacena una representación numérica de texto, imágenes, videos y otros datos en una representación binaria llamada incrustaciones. Esta sección destaca los fundamentos de las bases de datos vectoriales y las incrustaciones y, más significativamente, se centra en cómo usarlas para integrarlas con aplicaciones LLM.
Una base de datos vectorial es una base de datos que almacena y busca incrustaciones utilizando un espacio de alta dimensión. Estos vectores son representaciones numéricas de las características o atributos de los datos. Utilizando algoritmos que calculan la distancia o la similitud entre vectores en un espacio de alta dimensión, las bases de datos vectoriales pueden recuperar datos similares de forma rápida y eficiente. A diferencia de las bases de datos tradicionales basadas en escalares que almacenan datos en filas o columnas y utilizan métodos de búsqueda basados en coincidencias exactas o palabras clave, las bases de datos vectoriales funcionan de manera diferente. Utilizan bases de datos vectoriales para buscar y comparar una gran colección de vectores en un período de tiempo muy corto (del orden de milisegundos) utilizando técnicas como los vecinos más cercanos aproximados (ANN).
Un tutorial rápido sobre incrustaciones
Los modelos de IA generan incrustaciones ingresando datos sin procesar, como texto, video e imágenes, en una biblioteca de incrustación de vectores como palabra2vec y En el contexto de la IA y el aprendizaje automático, estas características representan diferentes dimensiones de los datos que son esenciales para comprender las relaciones de patrones y las estructuras subyacentes.
A continuación se muestra un ejemplo de cómo generar incrustaciones de palabras usando word2vec.
1. Genere el modelo utilizando su corpus de datos personalizado o utilice un modelo de muestra prediseñado de Google o Texto rápido. Si genera el suyo propio, puede guardarlo en su sistema de archivos como un archivo “word2vec.model”.
import gensim # Create a word2vec model
model = gensim.models.Word2Vec(corpus) # Save the model file
model.save('word2vec.model')2. Cargue el modelo, genere una incrustación vectorial para una palabra de entrada y utilícela para obtener palabras similares en el espacio de incrustación vectorial.
import gensim
import numpy as np # Load the word2vec model
model = gensim.models.Word2Vec.load('word2vec.model') # Get the vector for the word "king"
king_vector = model['king'] # Get the most similar vectors to the king vector
similar_vectors = model.similar_by_vector(king_vector, topn=5) # Print the most similar vectors
for vector in similar_vectors: print(vector[0], vector[1]) 3. Aquí están las 5 palabras principales cercanas a la palabra de entrada.
Output: man 0.85
prince 0.78
queen 0.75
lord 0.74
emperor 0.72Arquitectura de aplicaciones LLM utilizando bases de datos vectoriales
En un nivel alto, las bases de datos vectoriales se basan en modelos de incrustación para manejar tanto la creación como la consulta de incrustaciones. En la ruta de ingesta, el contenido del corpus se codifica en vectores utilizando el modelo de incrustación y se almacena en bases de datos vectoriales como Pinecone, ChromaDB, Weaviate, etc. En la ruta de lectura, la aplicación realiza una consulta utilizando oraciones o palabras y se codifica nuevamente. por el modelo de incrustación en un vector que luego se consulta en la base de datos del vector para obtener los resultados.
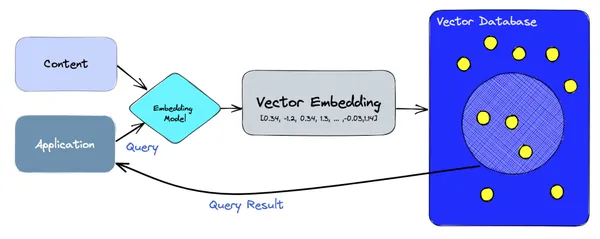
Aplicaciones LLM que utilizan bases de datos vectoriales
LLM ayuda en las tareas lingüísticas y está integrado en una clase más amplia de modelos, como IA generativa que puede generar imágenes y videos además de solo texto. En esta sección, aprenderemos cómo crear aplicaciones prácticas de LLM/IA generativa utilizando bases de datos vectoriales. Utilicé transformadores y bibliotecas de antorchas para modelos de lenguaje y piña como base de datos vectorial. Puede elegir cualquier modelo de lenguaje para LLM/incrustaciones y cualquier base de datos vectorial para almacenamiento y búsqueda.
Aplicación Chatbot
Para crear un chatbot utilizando una base de datos vectorial, puede seguir estos pasos:
- Elija una base de datos vectorial como Pinecone, Chroma, Weaviate, AWS Kendra, etc.
- Crea un índice vectorial para tu chatbot.
- Entrene un modelo de lenguaje utilizando un corpus de texto grande de su elección. Por ejemplo, para un chatbot de noticias, puede introducir datos de noticias.
- Integrar la base de datos vectorial y el modelo de lenguaje.
A continuación se muestra un ejemplo sencillo de una aplicación de chatbot que utiliza una base de datos vectorial y un modelo de lenguaje:
import pinecone
import transformers # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the language model
model = transformers.AutoModelForCausalLM.from_pretrained("google/bigbird-roberta-base") # Define a function to generate text
def generate_text(prompt): inputs = model.prepare_inputs_for_generation(prompt, return_tensors="pt") outputs = model.generate(inputs, max_length=100) return outputs[0].decode("utf-8") # Define a function to retrieve the most similar vectors to the user's query vector
def retrieve_similar_vectors(query_vector): results = client.search("my_index", query_vector) return results # Define a function to generate a response to the user's query
def generate_response(query): # Retrieve the most similar vectors to the user's query vector similar_vectors = retrieve_similar_vectors(query) # Generate text based on the retrieved vectors response = generate_text(similar_vectors[0]) return response # Start the chatbot
while True: # Get the user's query query = input("What is your question? ") # Generate a response to the user's query response = generate_response(query) # Print the response print(response)Esta aplicación de chatbot recuperará los vectores más similares al vector de consulta del usuario de la base de datos de vectores y luego generará texto utilizando el modelo de lenguaje basado en los vectores recuperados.
ChatBot > What is your question?
User_A> How tall is the Eiffel Tower?
ChatBot>The height of the Eiffel Tower measures 324 meters (1,063 feet) from its base to the top of its antenna. Aplicación Generador de Imágenes
Exploremos cómo crear una aplicación Generador de imágenes que utilice ambos IA generativa y bibliotecas LLM.
- Cree una base de datos de vectores para almacenar sus vectores de imágenes.
- Extraiga vectores de imágenes de sus datos de entrenamiento.
- Inserte los vectores de imagen en la base de datos de vectores.
- Entrenar una red generativa adversarial (GAN). Leer esta página si necesita una introducción a GAN.
- Integre la base de datos vectorial y la GAN.
Aquí hay un ejemplo simple de un programa que integra una base de datos vectorial y una GAN para generar imágenes:
import pinecone
import torch
from torchvision import transforms # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the GAN
generator = torch.load("generator.pt") # Define a function to generate an image from a vector
def generate_image(vector): # Convert the vector to a tensor tensor = torch.from_numpy(vector).float() # Generate the image image = generator(tensor) # Transform the image to a PIL image image = transforms.ToPILImage()(image) return image # Start the image generator
while True: # Get the user's query query = input("What kind of image would you like to generate? ") # Retrieve the most similar vector to the user's query vector similar_vectors = client.search("my_index", query) # Generate an image from the retrieved vector image = generate_image(similar_vectors[0]) # Display the image image.show()Este programa recuperará el vector más similar al vector de consulta del usuario de la base de datos de vectores y luego generará una imagen usando GAN basada en el vector recuperado.
ImageBot>What kind of image would you like to generate?
Me>An idyllic image of a mountain with a flowing river.
ImageBot> Wait a minute! Here you go...
Puede personalizar este programa para satisfacer sus necesidades específicas. Por ejemplo, puedes entrenar una GAN especializada en generar un tipo particular de imagen, como retratos o paisajes.
Aplicación de recomendación de películas
Exploremos cómo crear una aplicación de recomendación de películas a partir de un corpus de películas. Puede utilizar una idea similar para crear un sistema de recomendación para productos u otras entidades.
- Cree una base de datos de vectores para almacenar los vectores de sus películas.
- Extraiga vectores de películas de los metadatos de su película.
- Inserte los vectores de la película en la base de datos de vectores.
- Recomendar películas a los usuarios.
A continuación se muestra un ejemplo de cómo utilizar la API Pinecone para recomendar películas a los usuarios:
import pinecone # Create an API client
client = pinecone.Client(api_key="YOUR_API_KEY") # Get the user's vector
user_vector = client.get_vector("user_index", user_id) # Recommend movies to the user
results = client.search("movie_index", user_vector) # Print the results
for result in results: print(result["title"])Aquí hay una recomendación de muestra para un usuario.
The Shawshank Redemption
The Dark Knight
Inception
The Godfather
Pulp FictionCasos de uso del mundo real de LLM que utilizan búsqueda de vectores/base de datos
- Microsoft y TikTok utilizan bases de datos vectoriales como Pinecone para obtener memoria a largo plazo y búsquedas más rápidas. Esto es algo que los LLM no pueden hacer solos sin una base de datos vectorial. Ayuda a los usuarios a guardar sus preguntas/respuestas anteriores y reanudar su sesión. Por ejemplo, los usuarios pueden preguntar: "Cuéntame más sobre la receta de pasta que discutimos la semana pasada". Leer esta página.

- El Asistente de decisiones de Flipkart recomienda productos a los usuarios codificando primero la consulta como incrustación de vectores y realizando una búsqueda en los vectores que almacenan productos relevantes en un espacio de alta dimensión. Por ejemplo, si busca "Chaqueta de cuero Wrangler marrón para hombre mediana", recomienda productos relevantes al usuario mediante una búsqueda por similitud de vectores. De lo contrario, LLM no tendría ninguna recomendación, ya que ningún catálogo de productos contendría tales títulos o detalles del producto. Puedes leerlo esta página.
- Chipper Cash, una fintech de África, utiliza una base de datos vectorial para reducir 10 veces los registros de usuarios fraudulentos. Para ello, almacena todas las imágenes de registros de usuarios anteriores como incrustaciones de vectores. Luego, cuando un nuevo usuario se registra, lo codifica como un vector y lo compara con los usuarios existentes para detectar fraude. Puedes leerlo esta página.

- Facebook ha estado utilizando su biblioteca de búsqueda vectorial llamada FAISS (blog) en muchos productos internamente, incluidos Instagram Reels y Facebook Stories, para realizar una búsqueda rápida de cualquier multimedia y encontrar candidatos similares para mostrar mejores sugerencias al usuario.
Conclusión
Las bases de datos vectoriales son útiles para crear diversas aplicaciones LLM, como generación de imágenes, recomendaciones de películas o productos y chatbots. Proporcionan a los LLM información adicional o similar sobre la que los LLM no han recibido capacitación. Almacenan las incrustaciones de vectores de manera eficiente en un espacio de alta dimensión y utilizan la búsqueda de vecinos más cercanos para encontrar incrustaciones similares con alta precisión.
Puntos clave
Las conclusiones clave de este artículo son que las bases de datos vectoriales son muy adecuadas para aplicaciones LLM y ofrecen las siguientes características importantes para que los usuarios las integren:
- Rendimiento: Las bases de datos vectoriales están diseñadas específicamente para almacenar y recuperar datos vectoriales de manera eficiente, lo cual es importante para desarrollar aplicaciones LLM de alto rendimiento.
- Precisión: Las bases de datos de vectores pueden coincidir con precisión con vectores similares, incluso si presentan ligeras variaciones. Utilizan algoritmos del vecino más cercano para calcular vectores similares.
- multimodal: Las bases de datos vectoriales pueden acomodar varios datos multimodales, incluidos texto, imágenes y sonido. Esta versatilidad los convierte en una opción ideal para aplicaciones LLM/IA generativa que requieren trabajar con diversos tipos de datos.
- Amigable para el desarrollador: Las bases de datos vectoriales son relativamente fáciles de usar, incluso para desarrolladores que no posean un conocimiento amplio de las técnicas de aprendizaje automático.
Además, me gustaría resaltar que muchas soluciones SQL/NoSQL existentes ya agregan almacenamiento de incrustación de vectores, indexación y funciones de búsqueda de similitudes más rápidas, por ejemplo, PostgreSQL y Redis. Este es un espacio en rápida evolución, por lo que los desarrolladores de aplicaciones tendrán muchas opciones disponibles en un futuro próximo para crear aplicaciones innovadoras.
Preguntas frecuentes
R. Los modelos de lenguaje grande o LLM son programas avanzados de inteligencia artificial (IA) entrenados en un gran corpus de datos de texto que utilizan redes neuronales para imitar respuestas similares a las humanas con contexto. Pueden predecir, responder y generar datos textuales en el dominio en el que han sido entrenados.
R. Las incrustaciones son representaciones numéricas de texto, imágenes, videos u otros formatos de datos. Facilitan la colocación y la búsqueda de objetos semánticamente similares en un espacio de alta dimensión.
R. Una base de datos almacena y consulta incrustaciones de vectores de alta dimensión para encontrar vectores similares utilizando algoritmos de vecino más cercano, como el hash sensible a la localidad. Los LLM/IA generativa los necesitan para ayudarlos a proporcionar búsquedas adicionales para vectores similares en lugar de ajustar el LLM ellos mismos.
R. Las bases de datos vectoriales son bases de datos especializadas que ayudan a indexar y buscar incrustaciones de vectores. Son muy populares en la comunidad de código abierto y muchas organizaciones/aplicaciones se están integrando con ellos. Sin embargo, muchas bases de datos SQL/NoSQL existentes están agregando capacidades similares para que la comunidad de desarrolladores tenga muchas opciones en el futuro cercano.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/10/how-to-build-llm-apps-using-vector-database/

