Esta es una publicación de blog invitado coescrita con Hussain Jagirdar de Games24x7.
Juegos24x7 es una de las plataformas de juegos múltiples más valiosas de la India y entretiene a más de 100 millones de jugadores en varios juegos de habilidad. Con la "Ciencia de los juegos" como su filosofía central, han permitido una visión de la informática de extremo a extremo en torno a la dinámica del juego, las plataformas de juego y los jugadores mediante la consolidación de direcciones de investigación ortogonales de IA de juegos, ciencia de datos de juegos e investigación de usuarios de juegos. El equipo de inteligencia artificial y ciencia de datos se sumerge en una plétora de datos multidimensionales y ejecuta una variedad de casos de uso, como la optimización del viaje del jugador, la detección de acciones del juego, la hiperpersonalización, el cliente 360 y más en AWS.
Games24x7 emplea un marco automatizado, basado en datos y alimentado por IA para la evaluación del comportamiento de cada jugador a través de interacciones en la plataforma y señala a los usuarios con comportamiento anómalo. Han construido un modelo de aprendizaje profundo ScarceGAN, que se centra en la identificación de muestras extremadamente raras o escasas a partir de datos de telemetría longitudinal multidimensional con etiquetas pequeñas y débiles. Este trabajo ha sido publicado en CIKM'21 y es de código abierto para la identificación de clase rara para cualquier dato de telemetría longitudinal. La necesidad de producción y adopción del modelo fue primordial para crear una columna vertebral detrás de permitir el juego responsable en su plataforma, donde los usuarios marcados pueden ser llevados a través de un viaje diferente de moderación y control.
En esta publicación, compartimos cómo Games24x7 mejoró sus canales de capacitación para su plataforma de juego responsable usando Amazon SageMaker.
Desafíos del cliente
El equipo de DS/IA de Games24x7 usó varios servicios proporcionados por AWS, incluidos los portátiles de SageMaker, Funciones de paso de AWS, AWS Lambday EMR de Amazon, para construir tuberías para varios casos de uso. Para manejar la deriva en la distribución de datos y, por lo tanto, para volver a entrenar su modelo ScarceGAN, descubrieron que el sistema existente necesitaba una mejor solución MLOps.
En la canalización anterior a través de Step Functions, una sola base de código monolítica ejecutaba el preprocesamiento, el reentrenamiento y la evaluación de datos. Esto se convirtió en un cuello de botella en la resolución de problemas, la adición o eliminación de un paso, o incluso en la realización de pequeños cambios en la infraestructura general. Esta función escalonada creó una instancia de un grupo de instancias para extraer y procesar datos de S3 y los pasos posteriores de preprocesamiento, capacitación y evaluación se ejecutarían en una sola instancia grande de EC2. En escenarios en los que la canalización fallaba en cualquier paso, todo el flujo de trabajo debía reiniciarse desde el principio, lo que generaba ejecuciones repetidas y un aumento de los costos. Todas las métricas de capacitación y evaluación fueron inspeccionadas manualmente desde Amazon Simple Storage Service (Amazon S3). No había ningún mecanismo para pasar y almacenar los metadatos de los múltiples experimentos realizados en el modelo. Debido al monitoreo descentralizado del modelo, la investigación exhaustiva y la selección selectiva del mejor modelo requirieron horas del equipo de ciencia de datos. La acumulación de todos estos esfuerzos había dado como resultado una menor productividad del equipo y un aumento de los gastos generales. Además, con un equipo de rápido crecimiento, fue muy difícil compartir este conocimiento con todo el equipo.
Debido a que los conceptos de MLOps son muy extensos y la implementación de todos los pasos requeriría tiempo, decidimos que en la primera etapa abordaríamos los siguientes problemas centrales:
- Un entorno seguro, controlado y con plantillas para volver a capacitar nuestro modelo interno de aprendizaje profundo utilizando las mejores prácticas de la industria
- Un entorno de entrenamiento parametrizado para enviar un conjunto diferente de parámetros para cada trabajo de reentrenamiento y auditar las últimas ejecuciones
- La capacidad de rastrear visualmente las métricas de entrenamiento y las métricas de evaluación, y tener metadatos para rastrear y comparar experimentos.
- La capacidad de escalar cada paso individualmente y reutilizar los pasos anteriores en casos de fallas en los pasos
- Un único entorno dedicado para registrar modelos, almacenar funciones e invocar canalizaciones de inferencia
- Un conjunto de herramientas moderno que podría minimizar los requisitos informáticos, reducir los costos e impulsar el desarrollo y las operaciones sostenibles de ML al incorporar la flexibilidad de usar diferentes instancias para diferentes pasos.
- Creación de una plantilla de referencia de canalización de MLOps de última generación que podría usarse en varios equipos de ciencia de datos
Games24x7 comenzó a evaluar otras soluciones, incluidas Canalizaciones de Amazon SageMaker Studio. La solución ya existente a través de Step Functions tenía limitaciones. Las canalizaciones de Studio tenían la flexibilidad de agregar o eliminar un paso en cualquier momento. Además, la arquitectura general y sus dependencias de datos entre cada paso se pueden visualizar a través de DAG. La evaluación y el ajuste de los pasos de reentrenamiento se volvieron bastante eficientes después de que adoptamos diferentes funcionalidades de Amazon SageMaker, como Amazon SageMaker Studio, Pipelines, Processing, Training, Model Registry y Experiments and Trials. El equipo de arquitectura de soluciones de AWS mostró una gran inmersión y fue realmente fundamental en el diseño y la implementación de esta solución.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución.
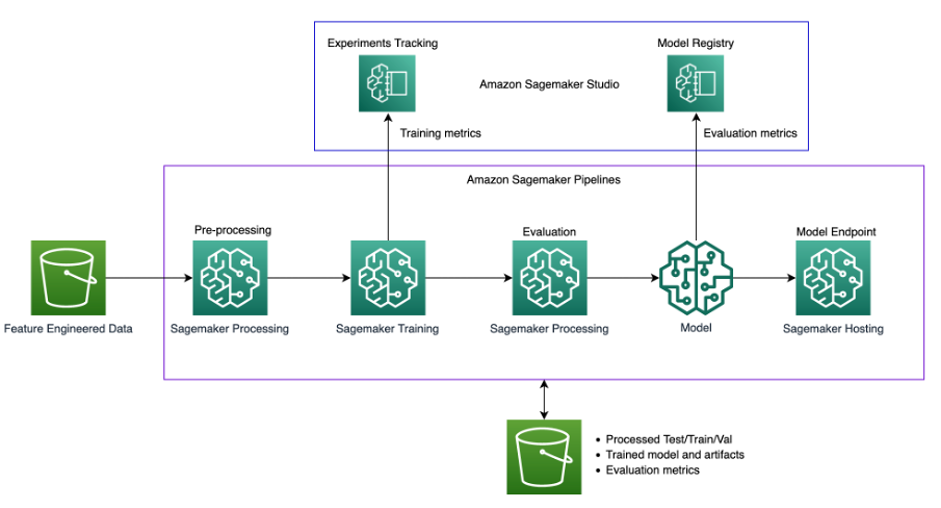
La solución utiliza un Estudio SageMaker entorno para ejecutar los experimentos de reentrenamiento. El código para invocar el script de canalización está disponible en los cuadernos de Studio y podemos cambiar los hiperparámetros y la entrada/salida al invocar la canalización. Esto es bastante diferente de nuestro método anterior en el que teníamos todos los parámetros codificados dentro de los scripts y todos los procesos estaban inextricablemente vinculados. Esto requirió la modularización del código monolítico en diferentes pasos.
El siguiente diagrama ilustra nuestro proceso monolítico original.
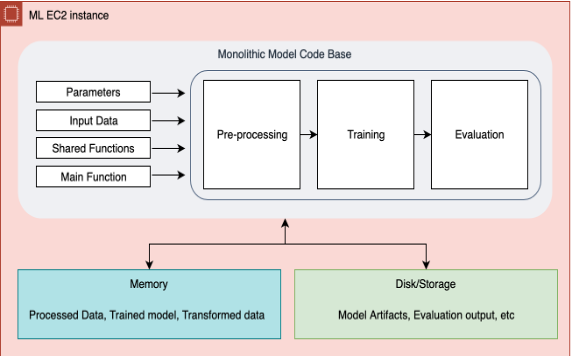
Modularización
Para escalar, rastrear y ejecutar cada paso individualmente, el código monolítico necesitaba ser modularizado. Se eliminaron las dependencias de parámetros, datos y código entre cada paso, y se crearon módulos compartidos para los componentes compartidos en los pasos. A continuación se muestra una ilustración de la modularización:
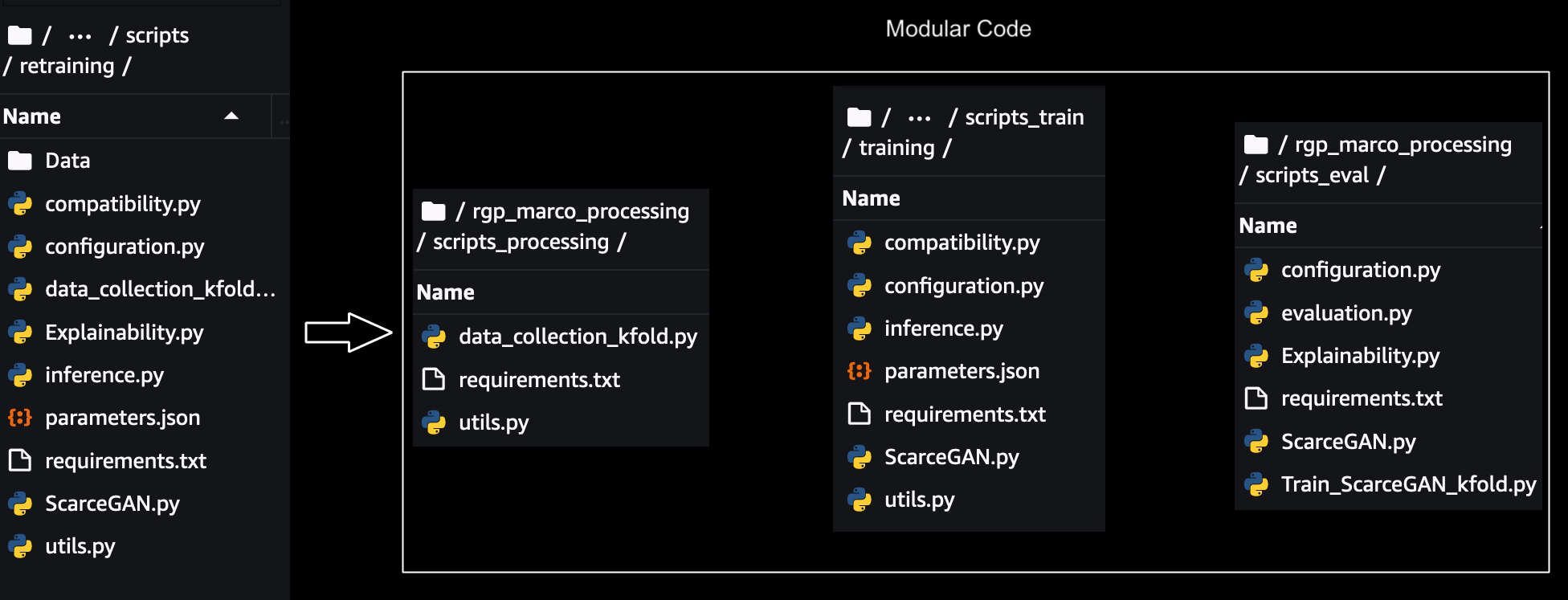
Para cada módulo individual, la prueba se realizó localmente utilizando SageMaker SDK Modo de secuencia de comandos para la formación, el procesamiento y la evaluación que cambios menores requeridos en el código para ejecutar con SageMaker. El prueba de modo local para los scripts de aprendizaje profundo se pueden hacer en cuadernos de SageMaker si ya se están usando o usando Modo local con SageMaker Pipelines en caso de comenzar directamente con Pipelines. Esto ayuda a validar si nuestros scripts personalizados se ejecutarán en instancias de SageMaker.
A continuación, cada módulo se probó de forma aislada utilizando SageMaker Training/processing SDK utilizando Modo de secuencia de comandos y los ejecutó en una secuencia manualmente usando las instancias de SageMaker para cada paso, como se muestra a continuación:
Se utilizó Amazon S3 para procesar los datos de origen y luego almacenar los datos intermedios, los marcos de datos y los resultados de NumPy en Amazon S3 para el siguiente paso. Después de completar las pruebas de integración entre los módulos individuales para el preprocesamiento, la capacitación y la evaluación, el SageMaker Pipeline SDK que está integrado con SageMaker Python SDK que ya usamos en los pasos anteriores, nos permitió encadenar todos estos módulos mediante programación al pasar los parámetros de entrada, los datos, los metadatos y la salida de cada paso como entrada a los pasos siguientes.
Podríamos reutilizar el código anterior del SDK de Python de Sagemaker para ejecutar los módulos individualmente en ejecuciones basadas en el SDK de Sagemaker Pipeline. Las relaciones entre cada paso de la canalización están determinadas por las dependencias de datos entre los pasos.
Los pasos finales de la canalización son los siguientes:
- Preprocesamiento de datos
- Reentrenamiento
- Evaluación
- Registro de modelo
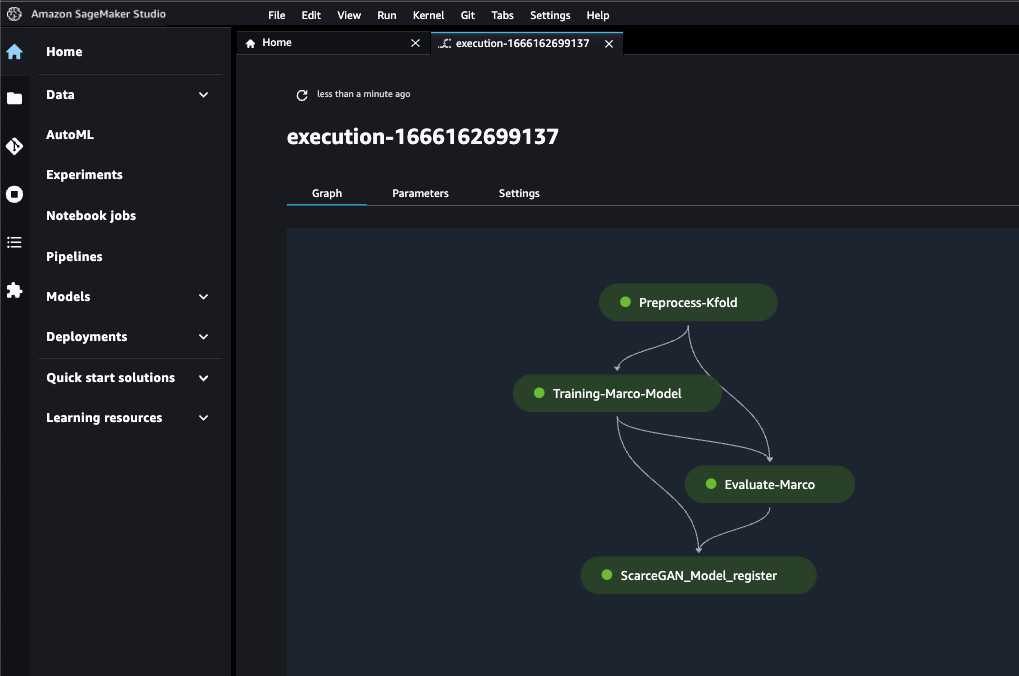
En las siguientes secciones, analizamos cada uno de los pasos con más detalle cuando se ejecutan con SageMaker Pipeline SDK.
Preprocesamiento de datos
Este paso transforma los datos de entrada sin procesar y los preprocesa y los divide en conjuntos de entrenamiento, validación y prueba. Para este paso de procesamiento, creamos una instancia de un trabajo de procesamiento de SageMaker con Procesador de marco TensorFlow, que toma nuestro script, copia los datos de Amazon S3 y luego extrae una imagen de Docker proporcionada y mantenida por SageMaker. Este contenedor de Docker nos permitió pasar las dependencias de nuestra biblioteca en el archivo requirements.txt mientras teníamos todas las bibliotecas de TensorFlow ya incluidas, y pasar la ruta de source_dir para la secuencia de comandos. Los datos de entrenamiento y validación van al paso de entrenamiento y los datos de prueba se envían al paso de evaluación. La mejor parte de usar este contenedor fue que nos permitió pasar una variedad de entradas y salidas como diferentes ubicaciones de S3, que luego podrían pasar como una dependencia de paso a los siguientes pasos en la canalización de SageMaker.
Reentrenamiento
Envolvimos el módulo de capacitación a través del Tuberías de SageMaker TrainingStep API y usó imágenes de contenedor de aprendizaje profundo ya disponibles a través del estimador de TensorFlow Framework (también conocido como modo Script) para Entrenamiento de SageMaker. El modo de script nos permitió tener cambios mínimos en nuestro código de entrenamiento, y el contenedor Docker preconstruido de SageMaker maneja las versiones de Python, Framework, etc. Las salidas de procesamiento del Data_Preprocessing step se reenviaron como TrainingInput de este paso.
Todos los hiperparámetros se pasaron por el estimador a través de un archivo JSON. Para cada época de nuestro entrenamiento, ya estábamos enviando nuestras métricas de entrenamiento a través de stdOut en el script. Debido a que queríamos realizar un seguimiento de las métricas de un trabajo de capacitación en curso y compararlas con trabajos de capacitación anteriores, solo tuvimos que analizar este StdOut definiendo las definiciones de métricas a través de expresiones regulares para obtener las métricas de StdOut para cada época.
Fue interesante entender que SageMaker Pipelines automáticamente se integra con la API de experimentos de SageMaker, que de forma predeterminada crea un experimento, una prueba y un componente de prueba para cada ejecución. Esto nos permite comparar métricas de entrenamiento como exactitud y precisión en múltiples ejecuciones, como se muestra a continuación.
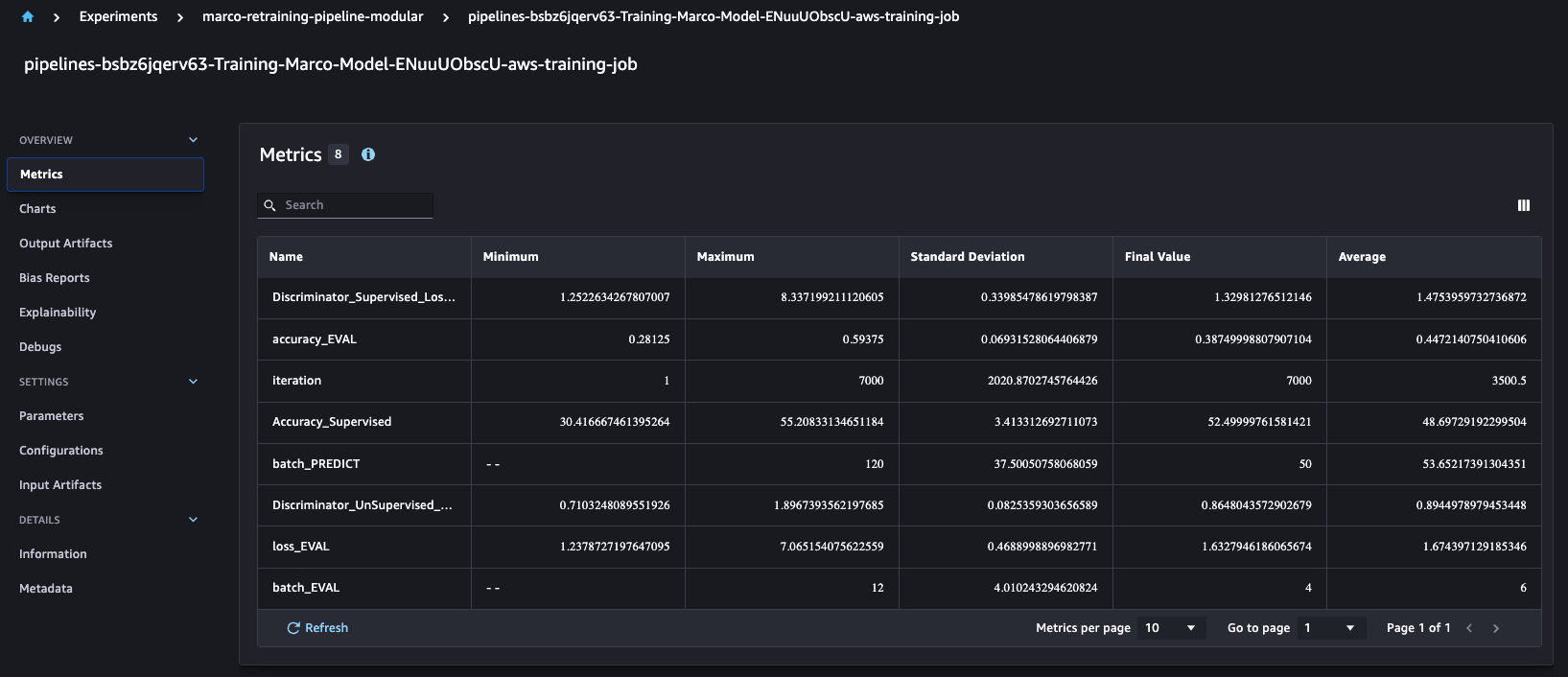
Para cada ejecución de trabajo de capacitación, generamos cuatro modelos diferentes para Amazon S3 en función de nuestra definición comercial personalizada.
Evaluación
Este paso carga los modelos entrenados de Amazon S3 y evalúa nuestras métricas personalizadas. Este ProcessingStep toma el modelo y los datos de prueba como entrada y vuelca los informes del rendimiento del modelo en Amazon S3.
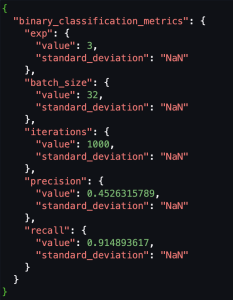
Estamos utilizando métricas personalizadas, por lo que para registrar estas métricas personalizadas en el registro del modelo, necesitábamos convertir el esquema de las métricas de evaluación almacenadas en Amazon S3 como CSV al SageMaker Calidad del modelo Salida JSON. Luego, podemos registrar la ubicación de esta métrica JSON de evaluación en el registro del modelo.
Las siguientes capturas de pantalla muestran un ejemplo de cómo convertimos un CSV al formato JSON de calidad Sagemaker Model.

Registro de modelo
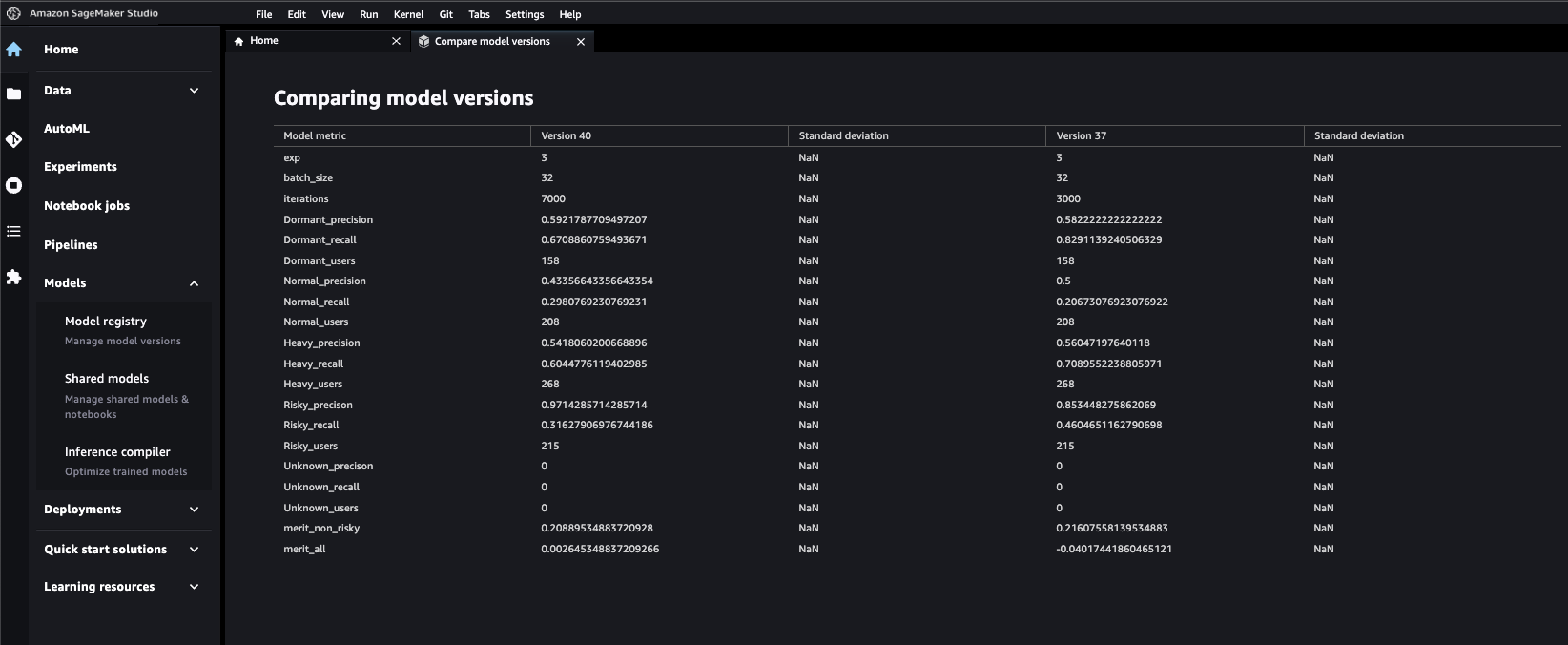
Como se mencionó anteriormente, estábamos creando varios modelos en un solo paso de capacitación, por lo que tuvimos que usar una integración Lambda de SageMaker Pipelines para registrar los cuatro modelos en un registro de modelos. Para el registro de un solo modelo podemos utilizar el ModeloPaso API para crear un modelo de SageMaker en el registro. Para cada modelo, la función de Lambda recupera el artefacto del modelo y la métrica de evaluación de Amazon S3 y crea un paquete de modelo para un ARN específico, de modo que los cuatro modelos se puedan registrar en un único registro de modelo. Las API de Python de SageMaker también nos permitió enviar metadatos personalizados que queríamos pasar para seleccionar los mejores modelos. Esto resultó ser un hito importante para la productividad porque todos los modelos ahora se pueden comparar y auditar desde una sola ventana. Proporcionamos metadatos para distinguir de forma única el modelo entre sí. Esto también ayudó a aprobar un modelo único con la ayuda de revisiones por pares y revisiones de gestión basadas en métricas del modelo.
El bloque de código anterior muestra un ejemplo de cómo agregamos metadatos a través de la entrada del paquete del modelo al registro del modelo junto con las métricas del modelo.
La siguiente captura de pantalla muestra la facilidad con la que podemos comparar las métricas de diferentes versiones del modelo una vez que están registradas.
Invocación de canalización
La canalización se puede invocar a través de EventoPuente , Sagemaker Studio o el SDK sí mismo. La invocación ejecuta los trabajos en función de las dependencias de datos entre los pasos.
Conclusión
En esta publicación, demostramos cómo Games24x7 transformó sus activos de MLOps a través de las canalizaciones de SageMaker. La capacidad de realizar un seguimiento visual de las métricas de capacitación y evaluación, con un entorno parametrizado, escalando los pasos individualmente con la plataforma de procesamiento adecuada y un registro de modelo central, demostró ser un hito importante en la estandarización y el avance hacia un flujo de trabajo auditable, reutilizable, eficiente y explicable. . Este proyecto es un modelo para diferentes equipos de ciencia de datos y ha aumentado la productividad general al permitir que los miembros operen, administren y colaboren con las mejores prácticas.
Si tiene un caso de uso similar y desea comenzar, le recomendamos que consulte SageMaker. Modo de secuencia de comandos y del Ejemplos completos de SageMaker utilizando Sagemaker Studio. Estos ejemplos tienen los detalles técnicos que se han cubierto en este blog.
Una estrategia de datos moderna le brinda un plan integral para administrar, acceder, analizar y actuar sobre los datos. AWS proporciona el conjunto de servicios más completo para todo el viaje de datos de extremo a extremo para todas las cargas de trabajo, todos los tipos de datos y todos los resultados comerciales deseados. A su vez, esto convierte a AWS en el mejor lugar para obtener valor de sus datos y convertirlos en información.
Acerca de los autores
![]() Hussain Yagirdar es un científico senior - Investigación aplicada en Games24x7. Actualmente está involucrado en esfuerzos de investigación en el área de inteligencia artificial explicable y aprendizaje profundo. Su trabajo reciente ha involucrado modelado generativo profundo, modelado de series de tiempo y subáreas relacionadas de aprendizaje automático e IA. También le apasionan los MLOps y la estandarización de proyectos que exigen restricciones como escalabilidad, confiabilidad y sensibilidad.
Hussain Yagirdar es un científico senior - Investigación aplicada en Games24x7. Actualmente está involucrado en esfuerzos de investigación en el área de inteligencia artificial explicable y aprendizaje profundo. Su trabajo reciente ha involucrado modelado generativo profundo, modelado de series de tiempo y subáreas relacionadas de aprendizaje automático e IA. También le apasionan los MLOps y la estandarización de proyectos que exigen restricciones como escalabilidad, confiabilidad y sensibilidad.
![]() sumir kumar es arquitecto de soluciones en AWS y tiene más de 13 años de experiencia en la industria de la tecnología. En AWS, trabaja en estrecha colaboración con clientes clave de AWS para diseñar e implementar soluciones basadas en la nube que resuelven problemas comerciales complejos. Es un apasionado del análisis de datos y el aprendizaje automático y tiene un historial probado de ayudar a las organizaciones a desbloquear todo el potencial de sus datos mediante la nube de AWS.
sumir kumar es arquitecto de soluciones en AWS y tiene más de 13 años de experiencia en la industria de la tecnología. En AWS, trabaja en estrecha colaboración con clientes clave de AWS para diseñar e implementar soluciones basadas en la nube que resuelven problemas comerciales complejos. Es un apasionado del análisis de datos y el aprendizaje automático y tiene un historial probado de ayudar a las organizaciones a desbloquear todo el potencial de sus datos mediante la nube de AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-games24x7-transformed-their-retraining-mlops-pipelines-with-amazon-sagemaker/

