
Introducción
Bienvenido a nuestro completo análisis de los datos Blog que profundiza en el mundo de Netflix. Como una de las principales plataformas de transmisión a nivel mundial, Netflix ha revolucionado la forma en que consumimos entretenimiento. Con su amplia biblioteca de películas y programas de televisión, ofrece una gran cantidad de opciones para los espectadores de todo el mundo.
Alcance global de Netflix
Netflix ha experimentado un crecimiento notable y ha ampliado su presencia para convertirse en una fuerza dominante en la industria del streaming. Aquí hay algunas estadísticas notables que muestran su impacto global:
- Usuario base: A principios del segundo trimestre de 2022, Netflix había acumulado aproximadamente 222 millones de suscriptores internacionales, que abarca más de 190 países (excluyendo China, Crimea, Corea del Norte, Rusia y Siria). Estas impresionantes cifras subrayan la amplia aceptación y popularidad de la plataforma entre los espectadores de todo el mundo.
- Expansión internacional: Con su disponibilidad en más de 190 países, Netflix ha establecido con éxito una presencia global. La empresa ha realizado importantes esfuerzos para localizar su contenido ofreciendo subtítulos y doblaje en varios idiomas, asegurando la accesibilidad a una audiencia diversa.
En este blog, nos embarcamos en un emocionante viaje para explorar los intrigantes patrones, tendencias y conocimientos ocultos en el panorama del contenido de Netflix. Aprovechando el poder de Python y su análisis de los datos bibliotecas, nos sumergimos en la vasta colección de ofertas de Netflix para descubrir información valiosa que arroja luz sobre las adiciones de contenido, las distribuciones de duración, las correlaciones de género e incluso las palabras más utilizadas en títulos y descripciones.
A través de fragmentos de código detallados y visualizaciones, retiramos las capas del ecosistema de contenido de Netflix para brindar una nueva perspectiva sobre cómo ha evolucionado la plataforma. Al analizar los patrones de lanzamiento, las tendencias estacionales y las preferencias de la audiencia, nuestro objetivo es comprender mejor la dinámica del contenido dentro del vasto universo de Netflix.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Preparación de datos
Los datos utilizados en este estudio de caso provienen de Kaggle, una plataforma popular para los entusiastas de la ciencia de datos y el aprendizaje automático. El conjunto de datos, titulado “Películas y programas de televisión de Netflix”, está disponible públicamente en Kaggle y brinda información valiosa sobre las películas y los programas de televisión en la plataforma de transmisión de Netflix.
El conjunto de datos consta de un formato tabular que contiene varias columnas que describen los diferentes aspectos de cada película o programa de televisión. Aquí hay una tabla que resume las columnas y sus descripciones:
| Nombre de columna | Descripción |
|---|---|
| mostrar_id | Identificación única para cada película/programa de televisión |
| tipo | Identificador: una película o un programa de televisión |
| título | Título de la película/programa de televisión |
| director | Director de la película |
| emitir | Actores involucrados en la Película/Espectáculo |
| país | País donde se produjo la Película/Serie |
| Fecha Agregada | Fecha en que se agregó en Netflix |
| año de lanzamiento | Año de lanzamiento real de la película/espectáculo |
| . | Clasificación de TV de la película/programa |
| duración | Duración total: en minutos o número de temporadas |
En esta sección, realizaremos tareas de preparación de datos en el conjunto de datos de Netflix para garantizar su limpieza e idoneidad para el análisis. Manejaremos valores faltantes y duplicados y realizaremos conversiones de tipos de datos según sea necesario. Profundicemos en el código y exploremos cada paso.
Importando Bibliotecas
Para empezar, importamos las librerías necesarias para el análisis y visualización de datos. Estas bibliotecas incluyen Los pandas, numpy y matplotlib. pyplot y seaborn. Proporcionan funciones y herramientas esenciales para manipular y visualizar los datos de manera efectiva.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationCargando el conjunto de datos
A continuación, cargamos el conjunto de datos de Netflix usando la función pd.read_csv(). El conjunto de datos se almacena en el archivo 'netflix.csv'. Veamos los primeros cinco registros del conjunto de datos para comprender su estructura.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Estadísticas descriptivas
Es crucial comprender las características generales del conjunto de datos a través de estadísticas descriptivas. Podemos obtener información sobre los atributos numéricos, como el conteo, la media, la desviación estándar, el mínimo, el máximo y los cuartiles.
# Computing descriptive statistics for the dataset
df.describe()Resumen conciso
Para obtener un resumen conciso del conjunto de datos, usamos la función df.info(). Proporciona información sobre el número de valores no nulos y los tipos de datos de cada columna. Este resumen ayuda a identificar los valores que faltan y los posibles problemas con los tipos de datos.
# Obtaining information about the dataset
df.info()Manejo de valores perdidos
Los valores faltantes pueden dificultar un análisis preciso. Este conjunto de datos explora los valores que faltan en cada columna usando df. es nulo().sum(). Nuestro objetivo es identificar las columnas con valores faltantes y determinar el porcentaje de datos faltantes en cada columna.
# Checking for missing values in the dataset
df.isnull().sum()Para manejar los valores faltantes, empleamos diferentes estrategias para diferentes columnas. Repasemos cada paso:
Duplicados
Los duplicados pueden distorsionar los resultados del análisis, por lo que es esencial abordarlos. Identificamos y eliminamos registros duplicados usando df.duplicated().sum().
# Checking for duplicate rows in the dataset
df.duplicated().sum()Manejo de valores faltantes en columnas específicas
Para las columnas "director" y "elenco", reemplazamos los valores faltantes con "Sin datos" para mantener la integridad de los datos y evitar cualquier sesgo en el análisis.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)En la columna 'país', completamos los valores que faltan con la moda (valor que ocurre con mayor frecuencia) para garantizar la coherencia y minimizar la pérdida de datos.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])Para la columna "calificación", completamos los valores que faltan según el "tipo" del programa. Asignamos el modo de 'calificación' para películas y programas de televisión por separado.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)Para la columna 'duración', completamos los valores faltantes según el 'tipo' del programa. Asignamos el modo de 'duración' para películas y programas de televisión por separado.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Descartar los valores faltantes restantes
Después de manejar los valores faltantes en columnas específicas, descartamos las filas restantes con valores faltantes para garantizar un conjunto de datos limpio para el análisis.
# Dropping rows with missing values
df.dropna(inplace=True)Manejo de fecha
Convertimos la columna 'date_added' al formato de fecha y hora usando pd.to_datetime() para permitir un análisis más detallado basado en atributos relacionados con la fecha.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Transformaciones de datos adicionales
Extraemos atributos adicionales de la columna 'date_added' para mejorar nuestras capacidades de análisis. Eliminamos los valores de mes y año para analizar tendencias en función de estos aspectos temporales.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearTransformación de datos: Reparto, País, Listado y Director
Para analizar los atributos categóricos de manera más efectiva, los transformamos en marcos de datos separados, lo que permite una exploración y un análisis más pausados.
Para las columnas 'reparto', 'país', 'lista_en' y 'director', dividimos los valores según el separador de coma y creamos filas separadas para cada valor. Esta transformación nos permite analizar los datos a un nivel más granular.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']Después de completar estos pasos de preparación de datos, tenemos un conjunto de datos limpio y transformado listo para un análisis posterior. Estas manipulaciones de datos iniciales sentaron las bases para explorar el conjunto de datos de Netflix y descubrir información sobre las estrategias basadas en datos de la plataforma de transmisión.
Análisis exploratorio de datos
Distribución de tipos de contenido
Para determinar la distribución de contenido en la biblioteca de Netflix, podemos calcular la distribución porcentual de los tipos de contenido (películas y programas de TV) usando el siguiente código:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
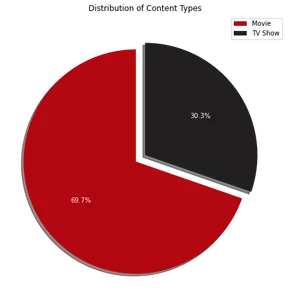
La visualización del gráfico circular muestra que aproximadamente el 70 % del contenido de Netflix consiste en películas, mientras que el 30 % restante son programas de televisión. A continuación, para identificar los 10 principales países donde Netflix es popular, podemos usar el siguiente código:
Los 10 principales países donde Netflix es popular
A continuación, para identificar los 10 principales países donde Netflix es popular, podemos usar el siguiente código:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()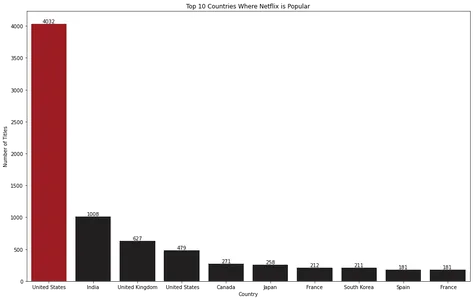
La visualización del gráfico de barras revela que Estados Unidos es el principal país donde Netflix es popular.
Los 10 mejores actores por número de películas/programas de televisión
Para identificar a los 10 actores principales con el mayor número de apariciones en películas y programas de televisión, puede utilizar el siguiente código:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
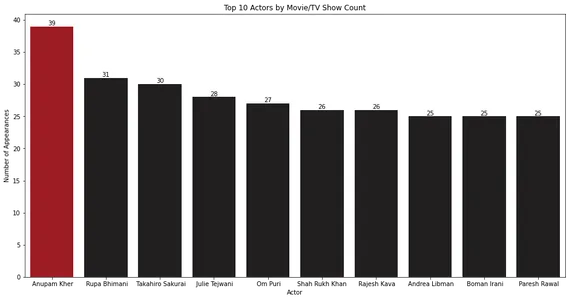
El gráfico de barras muestra que Anupam Kher tiene las apariciones más altas en películas y programas de televisión.
Los 10 mejores directores por número de películas/programas de televisión
Para identificar a los 10 mejores directores que han dirigido la mayor cantidad de películas o programas de televisión, puede usar el siguiente código:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()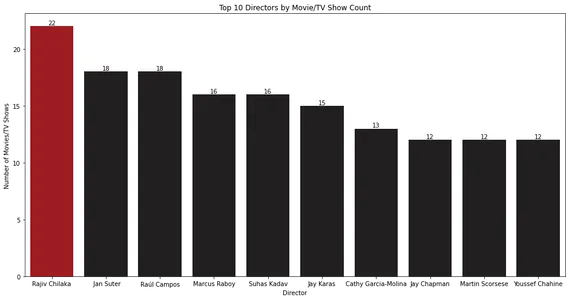
El gráfico de barras muestra los 10 principales directores con más películas o programas de televisión. Rajiv Chilaka parece haber dirigido la mayor parte del contenido de la biblioteca de Netflix.
Las 10 categorías principales por recuento de películas/programas de televisión
Para analizar la distribución de contenido en diferentes categorías, puede utilizar el siguiente código:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()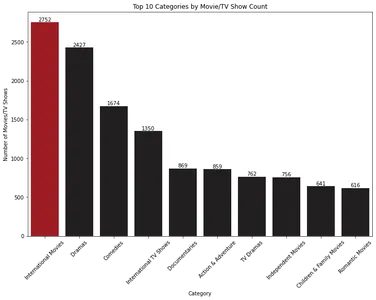
El gráfico de barras muestra las 10 categorías principales de películas y programas de televisión según su recuento. “Películas internacionales” es la categoría más dominante, seguida de “Dramas”.
Películas y programas de TV agregados con el tiempo
Para analizar la adición de películas y programas de TV a lo largo del tiempo, puede usar el siguiente código:
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
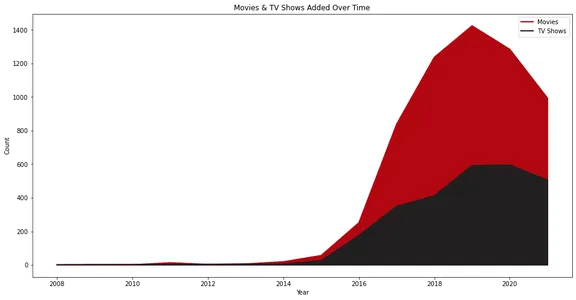
El gráfico de líneas ilustra la cantidad de películas y programas de TV agregados a Netflix a lo largo del tiempo. Representa visualmente el crecimiento y las tendencias en las adiciones de contenido, con líneas separadas para películas y programas de televisión.
Netflix vio su crecimiento real a partir del año 2015, y podemos ver que agregó más películas que programas de televisión a lo largo de los años.
Además, es interesante que la adición de contenido se redujo en 2020. Esto podría deberse a la situación de la pandemia.
A continuación, exploramos la distribución de las adiciones de contenido en diferentes meses. Este análisis nos ayuda a identificar patrones y comprender cuándo Netflix presenta contenido nuevo.
Contenido agregado por mes
Para investigar esto, extraemos el mes de la columna 'date_added' y contamos las ocurrencias de cada mes. La visualización de estos datos como un gráfico de barras nos permite identificar rápidamente los meses con las mayores adiciones de contenido.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()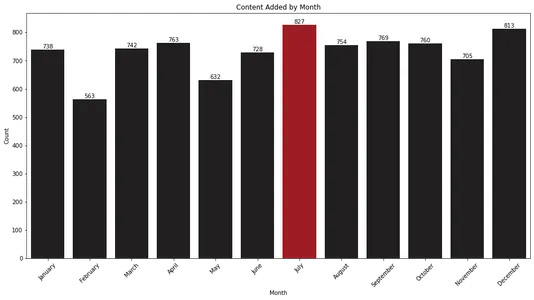
El gráfico de barras muestra que julio y diciembre son los meses en los que Netflix agrega más contenido a su biblioteca. Esta información puede ser valiosa para los espectadores que quieran anticiparse a los nuevos lanzamientos durante estos meses.
Otro aspecto crucial del análisis de contenido de Netflix es comprender la distribución de las calificaciones. Al examinar el recuento de cada categoría de calificación, podemos determinar los tipos de contenido más frecuentes en la plataforma.
Distribución de Calificaciones
Comenzamos calculando las ocurrencias de cada categoría de calificación y las visualizamos usando un gráfico de barras. Esta visualización proporciona una visión general clara de la distribución de las calificaciones.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()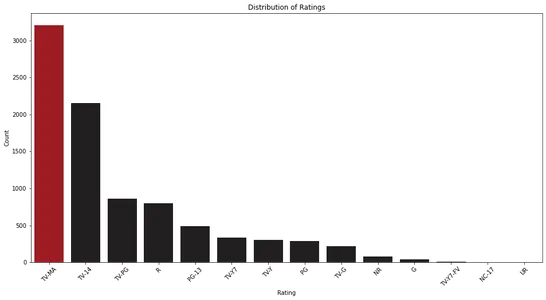
Al analizar el gráfico de barras, podemos observar la distribución de ratings en Netflix. Nos ayuda a identificar las categorías de calificación más comunes y su frecuencia relativa.
Mapa de calor de correlación de género
Los géneros juegan un papel importante en la categorización y organización del contenido en Netflix. Analizar la correlación entre géneros puede revelar relaciones interesantes entre diferentes tipos de contenido.
Creamos un marco de datos de datos de género para investigar la correlación de género y llenarlo con ceros. Al iterar sobre cada fila en el DataFrame original, actualizamos el DataFrame de datos de género en función de los géneros enumerados. Luego creamos una matriz de correlación utilizando estos datos de género y la visualizamos como un mapa de calor.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()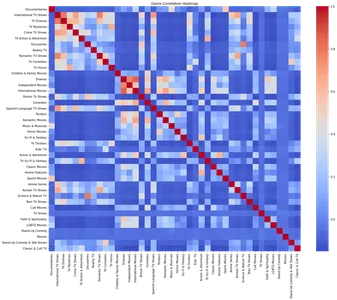
El mapa de calor demuestra la correlación entre diferentes géneros. Al analizar el mapa de calor, podemos identificar fuertes correlaciones positivas entre géneros específicos, como dramas de televisión y programas de televisión internacionales, programas de televisión románticos y programas de televisión internacionales.
Distribución de la duración de las películas y recuentos de episodios de programas de televisión
Comprender la duración de las películas y los programas de televisión brinda información sobre la duración del contenido y ayuda a los espectadores a planificar su tiempo de visualización. Al examinar la distribución de la duración de las películas y los programas de televisión, podemos comprender mejor el contenido disponible en Netflix.
Para lograr esto, extraemos la duración de las películas y el número de episodios de los programas de televisión de la columna "duración". Luego trazamos histogramas y diagramas de caja para visualizar la distribución de la duración de las películas y la duración de los programas de televisión.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()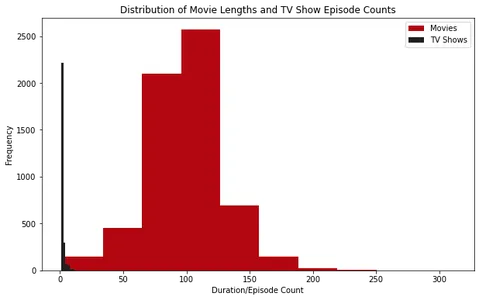
Analizando los histogramas, podemos observar que la mayoría de las películas en Netflix tienen una duración de alrededor de 100 minutos. Por otro lado, la mayoría de los programas de televisión en Netflix tienen solo una temporada.
Además, al examinar los diagramas de caja, podemos ver que las películas de más de aproximadamente 2.5 horas se consideran atípicas. Para los programas de televisión, es poco común encontrar aquellos con más de cuatro temporadas.
La tendencia de la duración de las películas/programas de televisión a lo largo de los años
Podemos trazar gráficos de líneas para comprender cómo ha evolucionado la duración de las películas y el recuento de episodios de programas de televisión a lo largo de los años. Identificar patrones o cambios en la duración del contenido mediante el análisis de estas tendencias.
Comenzamos extrayendo la duración de las películas y el número de episodios de los programas de televisión de la columna "duración". Luego, creamos diagramas de líneas para visualizar los cambios en la duración de las películas y los episodios de programas de televisión a lo largo de los años.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()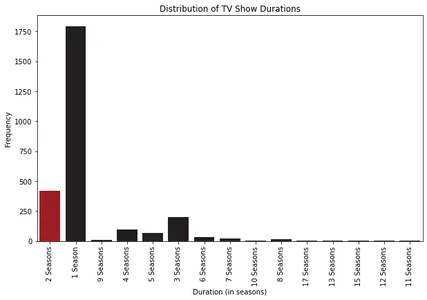
Al analizar los gráficos de líneas, observamos patrones interesantes. Podemos ver que la duración de la película inicialmente aumentó hasta alrededor de 1963-1964 y luego disminuyó gradualmente, estabilizándose alrededor de un promedio de 100 minutos. Esto sugiere un cambio en las preferencias de la audiencia a lo largo del tiempo.
Con respecto a los episodios de programas de televisión, hemos notado una tendencia constante desde principios de la década de 2000, donde la mayoría de los programas de televisión en Netflix tienen de una a tres temporadas. Esto indica una preferencia por series más cortas o formatos de series limitadas entre los espectadores.
Palabras más comunes en títulos y descripciones
El análisis de las palabras más comunes que se usan en los títulos y las descripciones puede brindar información sobre los temas y el enfoque del contenido en Netflix. Podemos generar nubes de palabras para descubrir estos patrones en función de los títulos y las descripciones del contenido de Netflix.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
Al examinar la nube de palabras en busca de títulos, observamos que términos como "Amor", "Niña", "Hombre", "Vida" y "Mundo" se usan con frecuencia, lo que indica la presencia de romanticismo, mayoría de edad y drama. géneros en la biblioteca de contenido de Netflix.
Al analizar la nube de palabras en busca de descripciones, notamos palabras dominantes como "vida", "encontrar" y "familia", que sugieren temas de viajes personales, relaciones y dinámicas familiares que prevalecen en el contenido de Netflix.
Distribución de duración para películas y programas de televisión
Analizar la distribución de duración de películas y programas de televisión nos permite comprender la duración típica del contenido disponible en Netflix. Podemos crear diagramas de caja para visualizar estas distribuciones e identificar valores atípicos o duraciones estándar.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()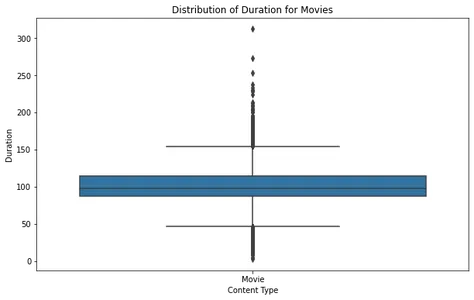
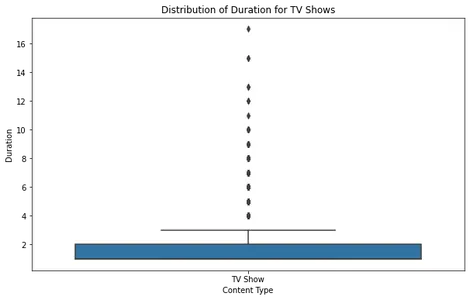
Al analizar el diagrama de cuadro de la película, podemos ver que la mayoría de las películas se encuentran dentro de un rango de duración razonable, con algunos valores atípicos que superan aproximadamente las 2.5 horas. Esto sugiere que la mayoría de las películas en Netflix están diseñadas para ajustarse a un tiempo de visualización estándar.
Para los programas de televisión, el diagrama de caja revela que la mayoría de los programas tienen de una a cuatro temporadas, y muy pocos valores atípicos tienen una duración más larga. Esto se alinea con las tendencias anteriores, lo que indica que Netflix se enfoca en formatos de series más cortas.
Conclusión
Con la ayuda de este artículo, hemos podido aprender sobre:
- Cantidad: nuestro análisis reveló que Netflix había agregado más películas que programas de televisión, lo que se ajusta a la expectativa de que las películas dominen su biblioteca de contenido.
- Adición de contenido: julio surgió como el mes en que Netflix agrega la mayor cantidad de contenido, seguido de cerca por diciembre, lo que indica un enfoque estratégico para el lanzamiento de contenido.
- Correlación de género: Se observaron fuertes asociaciones positivas entre varios géneros, como dramas de televisión y programas de televisión internacionales, programas de televisión románticos e internacionales, y películas y dramas independientes. Estas correlaciones brindan información sobre las preferencias de los espectadores y las interconexiones de contenido.
- Duración de las películas: el análisis de la duración de las películas indicó un pico alrededor de la década de 1960, seguido de una estabilización alrededor de los 100 minutos, lo que destaca una tendencia en la duración de las películas a lo largo del tiempo.
- Episodios de programas de televisión: la mayoría de los programas de televisión en Netflix tienen una temporada, lo que sugiere una preferencia por series más cortas entre los espectadores.
- Temas comunes: palabras como amor, vida, familia y aventura se encontraban con frecuencia en títulos y descripciones, capturando temas recurrentes en el contenido de Netflix.
- Distribución de calificaciones: la distribución de calificaciones a lo largo de los años ofrece información sobre el panorama del contenido en evolución y la recepción de la audiencia.
- Información basada en datos: nuestro viaje de análisis de datos mostró el poder de los datos para desentrañar los misterios del panorama de contenido de Netflix, brindando información valiosa para los espectadores y creadores de contenido.
- Relevancia continua: a medida que evoluciona la industria del streaming, comprender estos patrones y tendencias se vuelve cada vez más esencial para navegar por el panorama dinámico de Netflix y su amplia biblioteca.
- Happy Streaming: Esperamos que este blog haya sido un viaje esclarecedor y entretenido al mundo de Netflix, y lo alentamos a explorar las cautivadoras historias dentro de sus ofertas de contenido en constante cambio. ¡Deje que los datos guíen sus aventuras de transmisión!
Documentación y recursos oficiales
A continuación encontrará los enlaces oficiales a las bibliotecas utilizadas en nuestro análisis. Puede consultar estos enlaces para obtener más información sobre los métodos y funcionalidades proporcionados por estas bibliotecas:
- pandas: https://pandas.pydata.org/
- NúmPy: https://numpy.org/
- matplotlib: https://matplotlib.org/
- Ciencia: https://scipy.org/
- nacido en el mar: https://seaborn.pydata.org/
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/

