apache hudi es un marco de lago de datos transaccionales de código abierto que simplifica en gran medida el procesamiento de datos incrementales y el desarrollo de canalizaciones de datos. Para ello, lleva la funcionalidad principal de la base de datos y el almacén directamente a un lago de datos en Servicio de almacenamiento simple de Amazon (Amazon S3) o Apache HDFS. Hudi proporciona gestión de mesas, vistas instantáneas, upserts/eliminaciones eficientes, índices avanzados, servicios de ingestión de streaming, datos y optimizaciones de diseño de archivos (a través de clustering y compactación), o concurrencia control, todo mientras mantiene sus datos en formatos de archivo de código abierto como Apache Parquet y Apache Avro. Además, Apache Hudi está integrado con marcos de análisis de big data de código abierto, como Apache Spark, Apache Hive, Apache Flink, Presto y Trino.
En esta publicación, cubrimos las mejores prácticas al construir lagos de datos de Hudi en AWS usando EMR de Amazon. Esta publicación asume que usted tiene la comprensión de Hudi diseño de datos, diseño de archivoy tipos de tablas y consultas. La configuración y las características pueden cambiar con las nuevas versiones de Hudi; el concepto de esta publicación se aplica a las versiones de Hudi de 0.11.0 (Amazon EMR versión 6.7), 0.11.1 (Amazon EMR versión 6.8) y 0.12.1 (Amazon EMR versión 6.9).
Especifique el tipo de tabla: Copiar en escritura vs. Fusionar en lectura
Cuando escribimos datos en Hudi, tenemos la opción de especificar el tipo de tabla: Copiar al escribir (CoW) o Combinar al leer (MoR). Esta decisión debe tomarse en la configuración inicial y el tipo de tabla no se puede cambiar después de que se haya creado la tabla. Estos dos tipos de tablas ofrecen diferentes compensaciones entre la ingesta y el rendimiento de las consultas, y los archivos de datos se almacenan de manera diferente según el tipo de tabla elegido. Si no lo especifica, se utiliza el tipo de almacenamiento predeterminado CoW.
La siguiente tabla resume la comparación de características de los dos tipos de almacenamiento.
| Vaca | MdR |
| Los datos se almacenan en archivos base (formato Parquet columnar). | Los datos se almacenan como una combinación de archivos base (formato Parquet en columnas) y archivos de registro con cambios incrementales (formato Avro basado en filas). |
| COMPROMISO: cada nueva escritura crea una nueva versión de los archivos base, que contienen registros combinados de archivos base más antiguos y registros entrantes más nuevos. Cada escritura agrega una acción de confirmación a la línea de tiempo, y cada escritura agrega atómicamente una acción de confirmación a la línea de tiempo, lo que garantiza que una escritura (y todos sus cambios) tengan éxito por completo o se reviertan por completo. | DELTA_COMMIT: cada nueva escritura crea archivos de registro incrementales para las actualizaciones, que se asocian con los archivos base de Parquet. Para las inserciones, crea una nueva versión del archivo base similar a CoW. Cada escritura agrega una acción de confirmación delta a la línea de tiempo. |
| Escribe. | |
| En caso de actualizaciones, la latencia de escritura es más alta que MoR debido al costo de la fusión porque necesita volver a escribir todos los archivos de Parquet afectados con las actualizaciones fusionadas. Además, la escritura en formato Parquet de columnas (para actualizaciones de CoW) es más latente en comparación con el formato Avro basado en filas (para actualizaciones de MoR). | No hay costo de combinación para las actualizaciones durante el tiempo de escritura, y la operación de escritura es más rápida porque solo agrega los cambios de datos al nuevo archivo de registro correspondiente al archivo base cada vez. |
| No es necesaria la compactación porque todos los datos se escriben directamente en los archivos de Parquet. | Compactación es necesario fusionar los archivos base y de registro para crear una nueva versión del archivo base. |
| Mayor amplificación de escritura porque se crean nuevas versiones de archivos base para cada escritura. El costo de escritura será O (número de archivos en almacenamiento modificados por la escritura). | Menor amplificación de escritura porque las actualizaciones van a los archivos de registro. El costo de escritura será O(1) para conjuntos de datos de solo actualización y puede aumentar cuando hay nuevas inserciones. |
| Leer | |
| La tabla CoW admite consultas instantáneas y consultas incrementales. |
MoR ofrece dos formas de consultar el mismo almacenamiento subyacente: tablas optimizadas para lectura y tablas casi en tiempo real (consultas instantáneas). Las tablas ReadOptimized admiten consultas optimizadas para lectura y las tablas Near-Realtime admiten consultas instantáneas y consultas incrementales. |
| Las consultas optimizadas para lectura no se aplican a CoW porque los datos ya se fusionaron con los archivos base durante la escritura. | Las consultas optimizadas para lectura muestran los datos compactados más recientes, que no incluyen las actualizaciones más recientes en los archivos de registro aún no compactados. |
| Las consultas de instantáneas no tienen costo de combinación durante la lectura. | Las consultas de instantáneas combinan datos durante la lectura si no están compactados y, por lo tanto, pueden ser más lentas que CoW al consultar los datos más recientes. |
CoW es el tipo de almacenamiento predeterminado y se prefiere para casos de uso simples de lectura intensiva. Se recomiendan casos de uso con las siguientes características para CoW:
- Tablas con una tasa de ingesta más baja y casos de uso sin ingesta en tiempo real
- Casos de uso que requieren los datos más actualizados con una latencia de lectura mínima porque el costo de fusión se cubre en la fase de escritura
- Cargas de trabajo de solo agregar donde los datos existentes son inmutables
MoR se recomienda para tablas con casos de uso intensivos en escritura y actualización. Se recomiendan casos de uso con las siguientes características para MoR:
- Requisitos de ingesta más rápidos y casos de uso de ingesta en tiempo real.
- Patrones de escritura variados o en ráfagas (por ejemplo, ingerir eliminaciones aleatorias masivas en una base de datos ascendente) debido al costo de combinación cero para las actualizaciones durante el tiempo de escritura
- Casos de uso de transmisión
- Mezcla de consumidores intermedios, donde algunos buscan datos más actualizados pagando un costo de lectura adicional, y otros necesitan lecturas más rápidas con cierta compensación en la actualización de los datos
Para casos de uso de transmisión que exigen un rendimiento de ingestión estricto con tablas MoR, sugerimos ejecutar los servicios de tabla (por ejemplo, compactación y limpieza) de forma asíncrona, lo cual se analiza en la próxima Parte 3 de esta serie.
Para obtener más detalles sobre tipos de tablas y casos de uso, consulte ¿Cómo elijo un tipo de almacenamiento para mi carga de trabajo?
Seleccione la clave de registro, el generador de claves, el campo preCombinar y la carga útil del registro
En esta sección se analizan las configuraciones básicas para la clave de registro, el generador de claves, el campo preCombine y la carga útil del registro.
Grabar clave
Cada registro en Hudi se identifica de manera única mediante una clave con capucha (similar a las claves primarias en las bases de datos), que generalmente es un par de claves de registro y una ruta de partición. Con las claves de sudadera con capucha, puede habilitar actualizaciones y eliminaciones eficientes en los registros, así como evitar registros duplicados. Las particiones de Hudi tienen varios grupos de archivos y cada grupo de archivos se identifica mediante un ID de archivo. Hudi asigna las claves de Hoodie a los ID de los archivos mediante un mecanismo de indexación.
Una clave de registro que seleccione de sus datos puede ser única dentro de una partición o entre particiones. Si la clave de registro seleccionada es única dentro de una partición, se puede identificar de forma única en el conjunto de datos de Hudi mediante la combinación de la clave de registro y la ruta de la partición. También puede combinar varios campos de su conjunto de datos en una clave de registro compuesta. Las claves de registro no pueden ser nulas.
Generador de llaves
Los generadores de claves son diferentes implementaciones para generar claves de registro y rutas de partición en función de los valores especificados para estos campos en la configuración de Hudi. El generador de claves correcto debe configurarse según el tipo de clave (clave simple o compuesta) y el tipo de datos de columna utilizado en las columnas de clave de registro y ruta de partición (por ejemplo, TimestampBasedKeyGenerator se usa para la ruta de partición del tipo de datos de marca de tiempo). Hudi proporciona varios generadores de claves listos para usar, que puede especificar en su trabajo usando la siguiente configuración.
| Parámetro de configuración | Descripción | Valor |
hoodie.datasource.write.keygenerator.class |
Clase de generador de claves, que genera la clave de registro y la ruta de partición | El valor predeterminado es SimpleKeyGenerator |
La siguiente tabla describe los diferentes tipos de generadores de claves en Hudi.
| Generadores de claves | Caso de uso |
SimpleKeyGenerator |
Utilice este generador de claves si su clave de registro se refiere a una sola columna por nombre y, de manera similar, su ruta de partición también se refiere a una sola columna por nombre. |
ComplexKeyGenerator |
Utilice este generador de claves cuando la clave de registro y las rutas de partición comprendan varias columnas. Se espera que las columnas estén separadas por comas en el valor de configuración (por ejemplo, "hoodie.datasource.write.recordkey.field" : “col1,col4”). |
GlobalDeleteKeyGenerator |
Utilice este generador de claves cuando no pueda determinar la partición de los registros entrantes que se eliminarán y necesite eliminar solo en función de la clave de registro. Este generador de claves ignora la ruta de la partición mientras genera claves para identificar de forma única los registros de Hudi. Cuando use este generador de claves, configure la sudadera con capucha de configuración. |
NonPartitionedKeyGenerator |
Utilice este generador de claves para conjuntos de datos no particionados porque devuelve una partición vacía para todos los registros. |
TimestampBasedKeyGenerator |
Utilice este generador de claves para una ruta de partición de tipo de datos de marca de tiempo. Con este generador de claves, los valores de la columna de ruta de partición se interpretan como marcas de tiempo. La clave de registro es la misma que antes, que es una sola columna convertida en cadena. Si usa TimestampBasedKeyGenerator, algunos más configs necesita ser configurado. |
CustomKeyGenerator |
Utilice este generador de claves para aprovechar los beneficios de SimpleKeyGenerator, ComplexKeyGenerator y TimestampBasedKeyGenerator, todo al mismo tiempo. Con esto, puede configurar la clave de registro y las rutas de partición como un solo campo o una combinación de campos. Esto es útil si desea generar particiones anidadas con cada clave de partición de diferentes tipos (por ejemplo, field_3:simple,field_5:timestamp). Para obtener más información, consulte Generador de claves personalizadas. |
Hudi puede inferir automáticamente la clase de generador de claves si la clave de registro y la ruta de partición especificadas requieren un SimpleKeyGenerator o ComplexKeyGenerator, dependiendo de si hay una o varias columnas de clave de registro o ruta de partición. Para todos los demás casos, debe especificar el generador de claves.
El siguiente diagrama de flujo explica cómo seleccionar el generador de claves correcto para su caso de uso.
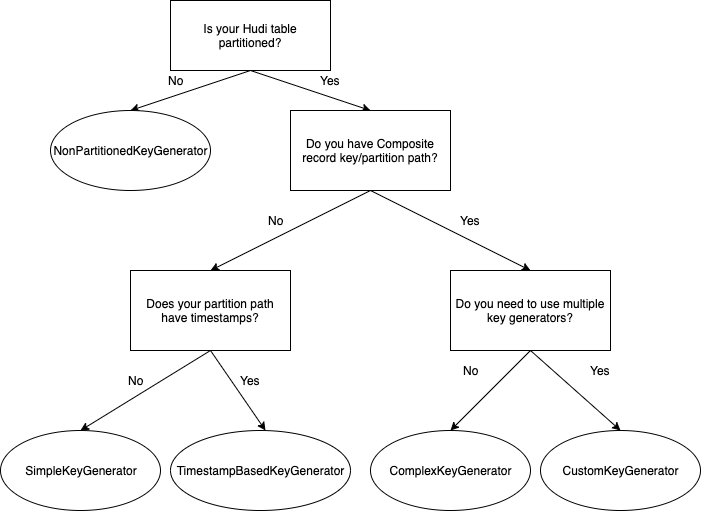
campo PreCombinar
Este es un campo obligatorio que utiliza Hudi para deduplicar los registros dentro del mismo lote antes de escribirlos. Cuando dos registros tienen la misma clave de registro, pasan por el proceso de preCombinación y el registro con el mayor valor para la clave de preCombinación se selecciona de manera predeterminada. Este comportamiento se puede personalizar a través de la implementación personalizada de la clase de carga útil de Hudi, que describimos en la siguiente sección.
La siguiente tabla resume las configuraciones relacionadas con preCombine.
| Parámetro de configuración | Descripción | Valor |
hoodie.datasource.write.precombine.field |
El campo utilizado en preCombining antes de la escritura real. Ayuda a seleccionar el registro más reciente siempre que haya varias actualizaciones del mismo registro en un solo lote de datos entrantes. |
El valor predeterminado es ts. Puede configurarlo en cualquier columna de su conjunto de datos que desee que utilice Hudi para deduplicar los registros siempre que haya varios registros con la misma clave de registro en el mismo lote. Actualmente, solo puede elegir un campo como el campo preCombine. Seleccione una columna con el tipo de datos de marca de tiempo o cualquier columna que pueda determinar qué registro contiene la última versión, como un número que aumenta monótonamente. |
hoodie.combine.before.upsert |
Durante upsert, esta configuración controla si se debe realizar la deduplicación para el lote entrante antes de ingerirlo en Hudi. Esto es aplicable solo para operaciones upsert. | El valor por defecto es verdadero. Recomendamos mantenerlo por defecto para evitar duplicados. |
hoodie.combine.before.delete |
Igual que la configuración anterior, pero aplicable solo para operaciones de eliminación. | El valor por defecto es verdadero. Recomendamos mantenerlo por defecto para evitar duplicados. |
hoodie.combine.before.insert |
Cuando los registros insertados comparten la misma clave, la configuración controla si primero deben combinarse (desduplicarse) antes de escribir en el almacenamiento. | El valor predeterminado es falso. Recomendamos establecerlo en verdadero si las inserciones entrantes o las inserciones masivas pueden tener duplicados. |
Grabar carga útil
La carga útil de registro define cómo fusionar nuevos registros entrantes con registros antiguos almacenados para upserts.
El valor por defecto OverwriteWithLatestAvroPayload La clase de carga útil siempre sobrescribe el registro almacenado con el último registro entrante. Esto funciona bien para trabajos por lotes y la mayoría de los casos de uso. Pero supongamos que tiene un trabajo de transmisión y desea evitar que los datos que llegan tarde sobrescriban el último registro almacenado. Debe usar una implementación de clase de carga útil diferente (DefaultHoodieRecordPayload) para determinar el último registro en almacenamiento en función de un campo de pedido que proporcione.
Por ejemplo, en el siguiente ejemplo, la confirmación 1 tiene HoodieKey 1, Val 1, preCombine10 y la confirmación en curso 2 tiene HoodieKey 1, Val 2, preCombine 5.

Si usa el valor predeterminado OverwriteWithLatestAvroPayload, la versión Val 2 del registro será la versión final del registro almacenado (Amazon S3) porque es la versión más reciente del registro.
Si usas DefaultHoodieRecordPayload, respetará Val 1 porque la versión de registro de Val 2 tiene un valor de preCombine más bajo (preCombine 5) en comparación con la versión de registro de Val 1, mientras fusiona varias versiones del registro.
Puede seleccionar una clase de carga útil mientras escribe en la tabla Hudi usando la configuración hoodie.datasource.write.payload.class.
En la siguiente tabla se describen algunas implementaciones útiles de clases de carga útil integradas.
| Clase de carga útil | Descripción |
Sobrescribir con la última carga útil de Avro (org.apache.hudi.common.model.OverwriteWithLatestAvroPayload) |
Elige el último registro entrante para sobrescribir cualquier versión anterior de los registros. Clase de carga útil predeterminada. |
Carga útil de registro de sudadera con capucha predeterminada (org.apache.hudi.common.model.DefaultHoodieRecordPayload) |
Usos hoodie.payload.ordering.field para determinar la versión final del registro mientras se escribe en el almacenamiento. |
VacíoHoodieRecordPayload (org.apache.hudi.common.model.EmptyHoodieRecordPayload) |
Use esto como clase de carga útil para eliminar todos los registros en el conjunto de datos. |
AWSDmsAvroPayload (org.apache.hudi.common.model.AWSDmsAvroPayload) |
Use esto como clase de carga útil si AWS DMS se usa como fuente. Brinda soporte para aplicar sin problemas los cambios capturados a través de AWS DMS. Esta implementación de carga útil realiza operaciones de inserción, eliminación y actualización en la tabla de Hudi según el tipo de operación para el registro de CDC obtenido de AWS DMS. |
Separador de ambientes
El particionamiento es la organización física de archivos dentro de una tabla. Actúan como columnas virtuales y pueden afectar el paralelismo máximo que podemos usar al escribir.
Las particiones extremadamente detalladas (por ejemplo, más de 20,000 XNUMX particiones) pueden crear una sobrecarga excesiva para el motor de Spark que administra todas las tareas pequeñas y pueden degradar el rendimiento de las consultas al reducir el tamaño de los archivos. Además, una estrategia de partición demasiado gruesa, sin agrupamiento ni omisión de datos, puede afectar negativamente tanto al rendimiento de lectura como al de inserción con la necesidad de escanear más archivos en cada partición.
La partición correcta ayuda a mejorar el rendimiento de lectura al reducir la cantidad de datos escaneados por consulta. También mejora el rendimiento de upsert al limitar la cantidad de archivos escaneados para encontrar el grupo de archivos en el que existe un registro específico durante la ingesta. Una columna que se usa con frecuencia en los filtros de consulta sería una buena candidata para la partición.
Para casos de uso a gran escala con patrones de consulta en evolución, sugerimos particiones de granularidad gruesa (como la fecha), mientras se usan técnicas de optimización de diseño de datos de granularidad fina (agrupación) dentro de cada partición. Esto abre la posibilidad de evolución del diseño de datos.
De forma predeterminada, Hudi crea las carpetas de partición solo con los valores de partición. Recomendamos usar el particionamiento estilo Hive, en el que el nombre de las columnas de partición se antepone a los valores de partición en la ruta (por ejemplo, year=2022/month=07 en contraposición a 2022/07). Esto permite una mejor integración con las metatiendas de Hive, como usar reparación de msck para arreglar rutas de partición.
Para admitir particiones de estilo Apache Hive en Hudi, debemos habilitarlo en la configuración hoodie.datasource.write.hive_style_partitioning.
La siguiente tabla resume las configuraciones clave relacionadas con la partición de Hudi.
| Parámetro de configuración | Descripción | Valor |
hoodie.datasource.write.partitionpath.field |
Campo de ruta de partición. Esta es una configuración requerida que debe pasar mientras escribe el conjunto de datos de Hudi. | No hay un valor predeterminado establecido para esto. Establézcalo en la columna que haya determinado para particionar los datos. Recomendamos que no cause particiones extremadamente finas. |
hoodie.datasource.write.hive_style_partitioning |
Determina si se usa la partición de estilo Hive. Si se establece en verdadero, los nombres de las carpetas de partición siguen <partition_column_name>=<partition_value> formato. |
El valor predeterminado es falso. Establézcalo en verdadero para usar la partición de estilo Hive. |
hoodie.datasource.write.partitionpath.urlencode |
Indica si debemos codificar en URL el valor de la ruta de la partición antes de crear la estructura de carpetas. | El valor predeterminado es falso. Establézcalo en verdadero si desea codificar como URL el valor de la ruta de la partición. Por ejemplo, si está utilizando el formato de datos "yyyy-MM-dd HH:mm:ss“, la codificación de URL debe establecerse en verdadero porque dará como resultado una ruta no válida debido a:. |
Tenga en cuenta que si los datos no están particionados, debe usar específicamente NonPartitionedKeyGenerator para la clave de registro, que se explica en la sección anterior. Además, Hudi no permite cambiar o evolucionar las columnas de partición.
Elija el índice correcto
Después de seleccionar el tipo de almacenamiento en Hudi y determinar la clave de registro y la ruta de la partición, debemos elegir el índice correcto para mejorar el rendimiento. Apache Hudi emplea un índice para ubicar el grupo de archivos al que pertenece una actualización/eliminación. Esto permite operaciones eficientes de upsert y delete y aplica la unicidad en función de las claves de registro.
Índice global frente a índice no global
Al elegir la estrategia de indexación correcta, la primera decisión es si usar un índice global (nivel de tabla) o no global (nivel de partición). La principal diferencia entre los índices globales y los no globales es el alcance de las restricciones de exclusividad clave. Los índices globales imponen la unicidad de las claves en todas las particiones de una tabla. Las implementaciones de índices no globales imponen esta restricción solo dentro de una partición específica. Los índices globales ofrecen garantías de unicidad más sólidas, pero tienen un costo de actualización/eliminación más alto, por ejemplo, eliminaciones globales con solo la clave de registro necesaria para escanear todo el conjunto de datos. Los índices HBase son una excepción aquí, pero vienen con una sobrecarga operativa.

Para casos de uso de índices globales a gran escala, use un índice HBase o índice de nivel de registro (disponible en Hudi 0.13) porque para todos los demás índices globales, el costo de actualización/eliminación crece con el tamaño de la tabla, O (tamaño de la tabla).
Cuando utilice un índice global, tenga en cuenta la configuración hoodie[bloom|simple|hbase].index.update.partition.path, que ya está establecido en verdadero de forma predeterminada. Para los registros existentes que se insertan en una nueva partición, habilitar esta configuración ayudará a eliminar el registro anterior en la partición anterior e insertarlo en la partición nueva.
Opciones de índice Hudi
Después de elegir el alcance del índice, el siguiente paso es decidir qué opción de indexación se adapta mejor a su carga de trabajo. La siguiente tabla explica las opciones de indexación disponibles en Hudi a partir de 0.11.0.
| Opción de indexación | ¿Cómo funciona? | Característica | Lo que hacemos |
| Índice simple | Realiza una combinación de los registros upsert/delete entrantes con las claves extraídas de la partición involucrada en el caso de conjuntos de datos no globales y el conjunto de datos completo en el caso de conjuntos de datos globales o no particionados. | Más fácil de configurar. Adecuado para casos de uso básicos como tablas pequeñas con actualizaciones distribuidas uniformemente. Incluso para tablas más grandes donde las actualizaciones son muy aleatorias para todas las particiones, un índice simple es la opción correcta porque se une directamente con los campos interesados de cada archivo de datos sin ninguna poda inicial, en comparación con Bloom, que en el caso de upserts aleatorios agrega información adicional. sobrecarga y no brinda suficientes beneficios de poda porque los filtros Bloom podrían indicar un verdadero positivo para la mayoría de los archivos y terminar comparando rangos y filtros contra todos estos archivos. | Global/No global |
| Índice Bloom (índice predeterminado en EMR Hudi) | Emplea filtros Bloom creados a partir de las claves de registro y, opcionalmente, también elimina los archivos candidatos mediante rangos de claves de registro. El filtro Bloom se almacena en el pie de página del archivo de datos mientras se escriben los datos. |
Filtro más eficiente en comparación con el índice simple para casos de uso como actualizaciones tardías de tablas de hechos y deduplicación en tablas de eventos con claves de registro ordenadas, como la marca de tiempo. Hudi implementa un mecanismo de filtro Bloom dinámico para reducir los falsos positivos proporcionados por los filtros Bloom. En general, la probabilidad de falsos positivos aumenta con el número de registros en un archivo determinado. Comprobar el Preguntas frecuentes sobre Hudi para las mejores prácticas de configuración del filtro Bloom. |
Global/No global |
| Índice de cubo | Distribuye registros a depósitos mediante una función hash basada en las claves de registro o un subconjunto de la misma. Utiliza la misma función hash para determinar qué grupo de archivos hacer coincidir con los registros entrantes. Nueva opción de indexación desde hudi 0.11.0. | Fácil de configurar. Tiene un mejor rendimiento de rendimiento de upsert en comparación con el filtro Bloom. A partir de Hudi 0.11.1, solo se admite un número de depósito fijo. Esto ya no será un problema con la próxima función de índice de cubo de hashing consistente, que puede cambiar dinámicamente los números de cubo. | No global |
| Índice HBase | El mapeo de índices se administra en una tabla HBase externa. | Mejor tiempo de búsqueda, especialmente para grandes cantidades de particiones y archivos. Viene con una sobrecarga operativa adicional porque necesita administrar una tabla HBase externa. | Buscar |
Casos de uso adecuados para índice simple
Los índices simples son más adecuados para cargas de trabajo con actualizaciones distribuidas uniformemente en particiones y archivos en tablas pequeñas, y también para tablas más grandes con cargas de trabajo de tipo de dimensión porque las actualizaciones son aleatorias para todas las particiones. Un ejemplo común es una canalización de CDC para una tabla de dimensiones. En este caso, las actualizaciones acaban tocando una gran cantidad de archivos y particiones. Por lo tanto, una unión sin otra poda es más eficiente.
Casos de uso adecuados para el índice de Bloom
Los índices Bloom son adecuados para la mayoría de las cargas de trabajo de producción con una distribución de actualizaciones desigual entre particiones. Para las cargas de trabajo con la mayoría de las actualizaciones de datos recientes, como tablas de hechos, el filtro Bloom se ajusta perfectamente. Pueden ser datos de flujo de clics recopilados de un sitio de comercio electrónico, transacciones bancarias en una aplicación FinTech o registros de CDC para una tabla de hechos.
Cuando utilice un índice Bloom, tenga en cuenta las siguientes configuraciones:
hoodie.bloom.index.use.metadata– De forma predeterminada, se establece en falso. Cuando esta marca está activada, el escritor de Hudi obtiene la información de metadatos del índice de la tabla de metadatos y no necesita abrir los pies de página del archivo de Parquet para obtener los filtros y las estadísticas de Bloom. Elimina los archivos simplemente usando la tabla de metadatos y, por lo tanto, tiene un rendimiento mejorado para tablas más grandes.hoodie.bloom.index.prune.by.ranges– Habilite o deshabilite la poda de rango según el caso de uso. De forma predeterminada, ya está establecido en verdadero. Cuando esta bandera está activada, la información de rango de los archivos se usa para acelerar las búsquedas de índice. Esto es útil si la clave de registro seleccionada aumenta monótonamente. Puede configurar cualquier clave de registro para que aumente de forma monótona agregando un prefijo de marca de tiempo. Si la clave de registro es completamente aleatoria y no tiene un orden natural (como los UUID), es mejor desactivarla, ya que la poda de rango solo agregará una sobrecarga adicional a la búsqueda de índice.
Casos de uso adecuados para el índice de depósito
Los índices de depósito son adecuados para casos de uso de upsert en grandes conjuntos de datos con una gran cantidad de grupos de archivos dentro de las particiones, una distribución de datos relativamente uniforme entre particiones y pueden lograr una distribución de datos relativamente uniforme en la columna de campo hash del depósito. Puede tener un mejor rendimiento de upsert en estos casos debido a que no involucra la búsqueda de índice ya que los grupos de archivos se ubican en función de un mecanismo de hash, que es muy rápido. Esto es totalmente diferente de los índices simples y Bloom, donde se involucra un paso de búsqueda de índice explícito durante la escritura. Los cubos aquí tienen un mapeo uno a uno con el grupo de archivos hudi y dado que el número total de cubos (definido por hoodie.bucket.index.num.buckets(predeterminado: 4)) se corrige aquí, puede conducir potencialmente a problemas de datos sesgados (datos distribuidos de manera desigual entre los depósitos) y problemas de escalabilidad (los depósitos pueden crecer con el tiempo). Estos problemas se abordarán en los próximos índice de cubo hash consistente, que va a ser un tipo especial de índice de depósito.
Casos de uso adecuados para el índice HBase
Los índices de HBase son adecuados para casos de uso en los que no se puede lograr el rendimiento de ingesta con los otros tipos de índice. Estos son en su mayoría casos de uso con índices globales y una gran cantidad de archivos y particiones. Los índices de HBase brindan el mejor tiempo de búsqueda, pero conllevan grandes gastos generales operativos si ya usa HBase para otras cargas de trabajo.
Para obtener más información sobre cómo elegir el índice adecuado y las estrategias de indexación para casos de uso comunes, consulte Empleando los índices correctos para actualizaciones y eliminaciones rápidas en Apache Hudi. Como ya ha visto, el rendimiento del índice Hudi depende en gran medida de la carga de trabajo real. Le recomendamos que evalúe diferentes índices para su carga de trabajo y elija el que mejor se adapte a su caso de uso.
Guía de migración
Con la creciente popularidad de Apache Hudi, uno de los desafíos fundamentales es migrar de manera eficiente los conjuntos de datos existentes a Apache Hudi. Apache Hudi mantiene metadatos de nivel de registro para realizar operaciones centrales como upserts y extracciones incrementales. Para aprovechar la compatibilidad con el procesamiento incremental y upsert de Hudi, debe agregar Metadatos de nivel de registro de Hudi a su conjunto de datos original.
Usando bulk_insert
La forma recomendada para la migración de datos a Hudi es realizar una reescritura completa usando inserción_masiva. No hay búsqueda de registros existentes en bulk_insert y optimizaciones de escritor como el manejo de archivos pequeños. Realizar una reescritura completa única es una buena oportunidad para escribir sus datos en formato Hudi con todos los metadatos e índices generados y también potencialmente controlar el tamaño del archivo y clasificar los datos por claves de registro.
Puede establecer el modo de clasificación en un bulk_insert operación usando la configuración hoodie.bulkinsert.sort.mode. bulk_insert ofrece los siguientes modos de clasificación para configurar.
| Modos de clasificación | Descripción |
NONE |
No se clasifican los registros. Puede obtener el rendimiento más rápido (comparable a escribir archivos de parquet con chispa) para la carga inicial con este modo. |
GLOBAL_SORT |
Use esto para ordenar registros globalmente en particiones de Spark. Tiene menos rendimiento en la carga inicial que otros modos, ya que reparticiona los datos por ruta de partición y los ordena por clave de registro dentro de cada partición. Esto ayuda a controlar la cantidad de archivos generados en el destino, controlando así el tamaño del archivo de destino. Además, los archivos de destino generados no tendrán valores mínimos y máximos superpuestos para las claves de registro, lo que ayudará aún más a acelerar las búsquedas de índices durante las operaciones de upsert/eliminaciones mediante la eliminación de archivos en función de los rangos de claves de registro en el índice de floración. |
PARTITION_SORT |
Use esto para ordenar registros dentro de las particiones de Spark. Es más eficaz para la carga inicial que Global_Sort y si sus particiones de Spark en el marco de datos ya están bastante asignadas a las particiones de Hudi (el marco de datos ya está dividido por columna de partición), sería preferible utilizar este modo, ya que puede obtener registros ordenados por clave de registro dentro de cada partición. |
Recomendamos usar Global_Sort modo si puede manejar el costo único. El modo de clasificación predeterminado se cambia de Global_Sort a Ninguno desde EMR 6.9 (Hudi 0.12.1). Durante bulk_insert con Global_Sort, dos configuraciones controlan los tamaños de los archivos de destino generados por Hudi.
| Parámetro de configuración | Descripción | Valor |
hoodie.bulkinsert.shuffle.parallelism |
El número de archivos generados a partir de la inserción masiva está determinado por esta configuración. Cuanto mayor sea el paralelismo, más tareas de Spark procesarán los datos. | El valor predeterminado es 200. Para controlar el tamaño del archivo y lograr el máximo rendimiento (más paralelismo), recomendamos establecerlo en un valor tal que los archivos generados sean iguales a los hoodie.parquet.max.file.size. Si hace que el paralelismo sea realmente alto, no se puede respetar el tamaño máximo de archivo porque las tareas de Spark están trabajando en cantidades de datos más pequeñas. |
hoodie.parquet.max.file.size |
Tamaño de destino para los archivos Parquet producidos por las fases de escritura de Hudi. | El valor predeterminado es 120 MB. Si las particiones de Spark generadas con hoodie.bulkinsert.shuffle.parallelism son más grandes que este tamaño, lo divide y genera múltiples archivos para no exceder el tamaño máximo de archivo. |
Digamos que tenemos un conjunto de datos de origen de Parquet de 100 GB y estamos insertando de forma masiva con Global_Sort en una tabla Hudi particionada con 10 particiones Hudi distribuidas uniformemente. Queremos tener el tamaño de archivo de destino preferido de 120 MB (valor predeterminado para hoodie.parquet.max.file.size). El paralelismo aleatorio de inserción masiva de Hudi debe calcularse de la siguiente manera:
- El tamaño total de datos en MB es 100 * 1024 = 102400 MB
hoodie.bulkinsert.shuffle.parallelismdebe establecerse en 102400/120 = ~ 854
Tenga en cuenta que, en realidad, incluso con Global_Sort, cada partición Spark se puede asignar a más de una partición hudi y este cálculo solo debe usarse como una estimación aproximada y puede terminar potencialmente con más archivos que el paralelismo especificado.
Usando bootstrapping
Para los clientes que operan a escala en cientos de terabytes o petabytes de datos, migrar sus conjuntos de datos para comenzar a usar Apache Hudi puede llevar mucho tiempo. Apache Hudi proporciona una característica llamada bootstrap para ayudar con este desafío.
La operación de arranque contiene dos modos: METADATA_ONLY y FULL_RECORD.
FULL_RECORD es lo mismo que la reescritura completa, donde los datos originales se copian y se reescriben con los metadatos como archivos Hudi.
El METADATA_ONLY El modo es la clave para acelerar el progreso de la migración. La idea conceptual es desacoplar los metadatos a nivel de registro de los datos reales escribiendo solo las columnas de metadatos en los archivos Hudi generados mientras los datos no se copian y permanecen en su ubicación original. Esto reduce significativamente la cantidad de datos escritos, lo que mejora el tiempo para migrar y comenzar con Hudi. Sin embargo, esto se produce a expensas del rendimiento de lectura, lo que implica la combinación de archivos Hudi y archivos de datos originales para obtener el registro completo. Por lo tanto, es posible que no desee usarlo para particiones consultadas con frecuencia.
Puede seleccionar y elegir estos modos a nivel de partición. Una estrategia común es jerarquizar sus datos. Usar FULL_RECORD modo para un pequeño conjunto de particiones activas, a las que se accede con frecuencia, y METADATA_ONLY para un conjunto más grande de particiones frías.
Considere lo siguiente:
Sincronización de catálogo
Hudi admite la sincronización de columnas y particiones de tablas de Hudi con un catálogo. En AWS, puede usar el Pegamento AWS Data Catalog o Hive metastore como almacén de metadatos para sus tablas de Hudi. Para registrar y sincronizar los metadatos con su canal de escritura regular, debe habilitar la sincronización de Hive o ejecutar el hive_sync_herramienta or Herramienta AwsGlueCatalogSync utilidad de línea de comandos.
Recomendamos habilitar la función de sincronización de Hive con su canal de escritura regular para asegurarse de que el catálogo esté actualizado. Si no espera que se agregue una nueva partición o que se cambie el esquema como parte de cada lote, le recomendamos habilitar hoodie.datasource.meta_sync.condition.sync también para que le permita a Hudi determinar si la sincronización de colmena es necesaria para el trabajo.
Si tiene trabajos de ingestión frecuentes y necesita maximizar el rendimiento de la ingestión, puede deshabilitar Hive Sync y ejecutar el hive_sync_tool asincrónicamente
Si tiene el tipo de datos de marca de tiempo en sus datos de Hudi, le recomendamos configurar hoodie.datasource.hive_sync.support_timestamp a verdadero para convertir int64 (timestamp_micros) a la marca de tiempo de tipo colmena. De lo contrario, verá los valores en bigint mientras consulta los datos.
La siguiente tabla resume las configuraciones relacionadas con hive_sync.
| Parámetro de configuración | Descripción | Valor |
hoodie.datasource.hive_sync.enable |
Para registrar o sincronizar la tabla con un metastore de Hive o el catálogo de datos de AWS Glue. | El valor predeterminado es falso. Recomendamos establecer el valor en verdadero para asegurarse de que el catálogo esté actualizado y debe habilitarse en cada escritura individual para evitar una tienda de metadatos no sincronizada. |
hoodie.datasource.hive_sync.mode |
Esta configuración establece el modo para que HiveSynctool se conecte al servidor de metastore de Hive. Para obtener más información, consulte Modos de sincronización. | Los valores válidos son hms, jdbc y hiveql. Si no se especifica el modo, el valor predeterminado es jdbc. Hms y jdbc se comunican con el servidor de ahorro subyacente, pero jdbc necesita un controlador jdbc independiente. Recomendamos configurarlo en 'hms', que usa el cliente metastore de Hive para sincronizar las tablas de Hudi usando las API de ahorro directamente. Esto ayuda al usar AWS Glue Data Catalog porque no necesita instalar Hive como una aplicación en el clúster de EMR (porque no necesita el servidor). |
hoodie.datasource.hive_sync.database |
Nombre de la base de datos de destino con la que debemos sincronizar la tabla Hudi. | El valor predeterminado es predeterminado. Establézcalo en el nombre de la base de datos de su catálogo. |
hoodie.datasource.hive_sync.table |
Nombre de la tabla de destino con la que debemos sincronizar la tabla Hudi. | En Amazon EMR, el valor se deduce del nombre de la tabla de Hudi. Puede establecer esta configuración si necesita un nombre de tabla diferente. |
hoodie.datasource.hive_sync.support_timestamp |
Para convertir tipo lógico TIMESTAMP_MICROS como marca de tiempo de tipo colmena. |
El valor predeterminado es falso. Establézcalo en verdadero para convertirlo en una marca de tiempo de tipo colmena. |
hoodie.datasource.meta_sync.condition.sync |
Si es verdadero, solo se sincroniza en condiciones como cambio de esquema o cambio de partición. | El valor predeterminado es falso. |
Escritura y lectura de conjuntos de datos de Hudi, y su integración con otros servicios de AWS
Hay diferentes formas de escribir los datos en Hudi mediante Amazon EMR, como se explica en la siguiente tabla.
| Opciones de escritura de Hudi | Descripción |
| Origen de datos de Spark |
Puede usar esta opción para realizar upsert, insert o bulk insert para la operación de escritura. Consulte Trabajar con un conjunto de datos de Hudi para ver un ejemplo de cómo escribir datos usando DataSourceWrite. |
| Chispa SQL | Puede escribir fácilmente datos en Hudi con instrucciones SQL. Elimina la necesidad de escribir código Scala o PySpark y adopta un paradigma de código bajo. |
| Flink SQL, API de flujo de datos de Flink | Si usa Flink para la ingestión de transmisión en tiempo real, puede usar la API Flink SQL o Flink DataStream de alto nivel para escribir los datos en Hudi. |
| deltastreamer | DeltaStreamer es una herramienta autogestionada que admite fuentes de datos estándar como Apache Kafka, eventos de Amazon S3, DFS, AWS DMS, JDBC y fuentes SQL, gestión de puntos de control integrada, validaciones de esquemas y transformaciones ligeras. También puede funcionar en un modo continuo, en el que un solo trabajo autónomo de Spark puede extraer datos de la fuente, escribirlos en tablas de Hudi y realizar limpieza, agrupación en clústeres, compactaciones y sincronización de catálogos de forma asincrónica, confiando en los grupos de trabajos de Spark para Administracion de recursos. Es fácil de usar y recomendamos usarlo para todos los casos de uso de transmisión e ingestión en los que se prefiere un enfoque de código bajo. Para obtener más información, consulte Ingestión de transmisión. |
| Streaming estructurado Spark | Para los casos de uso que requieren transformaciones de datos complejas del marco de datos de origen escrito en las API de Spark DataFrame o SQL avanzado, recomendamos el receptor de transmisión estructurado. La fuente de transmisión se puede usar para obtener fuentes de cambios de las tablas de Hudi para casos de uso de transmisión o procesamiento incremental. |
| Fregadero Kafka Connect | Si estandariza el marco Apache Kafka Connect para sus necesidades de ingesta, también puede usar Hudi Connect Sink. |
Consulte lo siguiente matriz de soporte para soporte de consultas en motores de consulta específicos. La siguiente tabla explica las diferentes opciones para leer el conjunto de datos de Hudi utilizando Amazon EMR.
| Opciones de lectura de Hudi | Descripción |
| Origen de datos de Spark | Puede leer conjuntos de datos de Hudi directamente desde Amazon S3 usando esta opción. No es necesario registrar las tablas con Hive metastore o AWS Glue Data Catalog para esta opción. Puede usar esta opción si su caso de uso no requiere un catálogo de metadatos. Referirse a Trabajar con un conjunto de datos de Hudi por ejemplo de cómo leer datos usando DataSourceReadOptions. |
| Chispa SQL | Puede consultar las tablas de Hudi con instrucciones DML/DDL. Las tablas deben registrarse con Hive metastore o AWS Glue Data Catalog para esta opción. |
| enlace SQL | Una vez que las tablas de Flink Hudi se han registrado en el catálogo de Flink, se pueden consultar mediante Flink SQL. |
| PrestoDB/Trino | Las tablas deben registrarse con Hive metastore o AWS Glue Data Catalog para esta opción. Este motor es el preferido para consultas interactivas. Hay un nuevo Conector trino en el próximo Hudi 0.13, y recomendamos leer conjuntos de datos a través de este conector cuando use Trino para obtener beneficios de rendimiento. |
| Colmena | Las tablas deben registrarse con Hive metastore o AWS Glue Data Catalog para esta opción. |
Apache Hudi está bien integrado con los servicios de AWS, y estas integraciones funcionan cuando se usa AWS Glue Data Catalog, con la excepción de Athena, donde también puede usar un conector de origen de datos para un metastore de Hive externo. La siguiente tabla resume las integraciones de servicio.
Conclusión
Esta publicación cubrió las mejores prácticas para configurar lagos de datos de Apache Hudi con Amazon EMR. Discutimos las configuraciones clave para migrar su conjunto de datos existente a Hudi y compartimos orientación sobre cómo determinar las opciones correctas para diferentes casos de uso al configurar tablas de Hudi.
La próxima Parte 2 de esta serie se centra en las optimizaciones que se pueden realizar en esta configuración, junto con la supervisión mediante Reloj en la nube de Amazon.
Acerca de los autores
 Suthan Phillips es Arquitecto de Big Data para Amazon EMR en AWS. Trabaja con los clientes para brindar mejores prácticas y orientación técnica, y los ayuda a lograr soluciones altamente escalables, confiables y seguras para aplicaciones complejas en Amazon EMR. En su tiempo libre, le gusta caminar y explorar el noroeste del Pacífico.
Suthan Phillips es Arquitecto de Big Data para Amazon EMR en AWS. Trabaja con los clientes para brindar mejores prácticas y orientación técnica, y los ayuda a lograr soluciones altamente escalables, confiables y seguras para aplicaciones complejas en Amazon EMR. En su tiempo libre, le gusta caminar y explorar el noroeste del Pacífico.
 dylan qu es un arquitecto de soluciones de AWS responsable de brindar orientación arquitectónica en toda la pila de AWS con un enfoque en análisis de datos, IA/ML y DevOps.
dylan qu es un arquitecto de soluciones de AWS responsable de brindar orientación arquitectónica en toda la pila de AWS con un enfoque en análisis de datos, IA/ML y DevOps.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/part-1-build-your-apache-hudi-data-lake-on-aws-using-amazon-emr/

