Colmena Apache es un sistema de almacenamiento de datos basado en SQL para procesar conjuntos de datos altamente distribuidos en la plataforma Apache Hadoop. Hay dos componentes clave para Apache Hive: el motor de consulta SQL de Hive y el metastore de Hive (HMS). El metaalmacén de Hive es un depósito de metadatos sobre las tablas SQL, como nombres de bases de datos, nombres de tablas, esquemas, información de serialización y deserialización, ubicación de datos y detalles de partición de cada tabla. Apache Hive, Apache Spark, Presto y Trino pueden usar Hive Metastore para recuperar metadatos para ejecutar consultas. El metastore de Hive se puede alojar en un clúster de Apache Hadoop o puede estar respaldado por una base de datos relacional externa a un clúster de Hadoop. Aunque Hive metastore almacena los metadatos de las tablas, los datos reales de la tabla podrían residir en Servicio de almacenamiento simple de Amazon (Amazon S3), el sistema de archivos distribuidos de Hadoop (HDFS) del clúster de Hadoop o cualquier otro almacén de datos compatible con Hive.
Debido a que Apache Hive se creó sobre Apache Hadoop, muchas organizaciones han estado usando el software desde el momento en que usaban Hadoop para el procesamiento de big data. Además, Hive metastore proporciona una integración flexible con muchos otros software de big data de código abierto como Apache HBase, Apache Spark, Presto y Apache Impala. Por lo tanto, las organizaciones han llegado a alojar grandes volúmenes de metadatos de sus conjuntos de datos estructurados en el metaalmacén de Hive. Un metastore es una parte crítica de un lago de datos, y es importante tener esta información disponible, dondequiera que resida. Sin embargo, muchos servicios de análisis de AWS no se integran de forma nativa con el metastore de Hive y, por lo tanto, las organizaciones han tenido que migrar sus datos al Pegamento AWS Catálogo de datos para utilizar estos servicios.
Formación del lago AWS ha lanzado soporte para administrar el acceso de los usuarios a las metatiendas de Apache Hive a través de una conexión federada de AWS Glue. Anteriormente, podía usar Lake Formation para administrar los permisos de usuario en Catálogo de datos de AWS Glue recursos solamente. Con la conexión de la metatienda de Hive desde AWS Glue, puede conectarse a una base de datos en una metatienda de Hive externa al catálogo de datos, asignarla a una base de datos federada en el catálogo de datos, aplicar permisos de Lake Formation en la base de datos y las tablas de Hive, compartirlas con otras cuentas de AWS y consultarlas mediante servicios como Atenea amazónica, Espectro de Redshift de Amazon, EMR de Amazony AWS Glue ETL (extracción, transformación y carga). Para obtener detalles adicionales sobre cómo funciona la integración de Hive metastore con Lake Formation, consulte Administrar permisos en conjuntos de datos que usan metaalmacenes externos.
Los casos de uso para la integración de Hive metastore con Data Catalog incluyen lo siguiente:
- Un metastore de Apache Hive externo utilizado para cargas de trabajo de big data heredadas, como clústeres de Hadoop locales con datos en Amazon S3
- Cargas de trabajo transitorias de Amazon EMR con datos subyacentes en Amazon S3 y Hive metastore en Servicio de base de datos relacional de Amazon (Amazon RDS) clústeres.
En esta publicación, demostramos cómo aplicar los permisos de Lake Formation en una base de datos y tablas de metastore de Hive y consultarlos con Athena. Ilustramos un caso de uso de uso compartido entre cuentas, en el que un administrador de Lake Formation en la cuenta de productor A comparte una base de datos y tablas de Hive federadas mediante etiquetas LF con la cuenta de consumidor B.
Resumen de la solución
La cuenta de productor A aloja un metaalmacén de Apache Hive en un clúster de EMR, con datos subyacentes en Amazon S3. Lanzamos el conector metastore de AWS Glue Hive desde Repositorio de aplicaciones sin servidor de AWS en la cuenta A y cree la conexión de metastore de Hive en el catálogo de datos de la cuenta A. Después de crear la conexión HMS, creamos una base de datos en el catálogo de datos de la cuenta A (llamada base de datos federada) y la asignamos a una base de datos en el metaalmacén de Hive usando la conexión. Luego, el administrador de Lake Formation en la cuenta A puede acceder a las tablas de la base de datos de Hive, al igual que cualquier otra tabla en el catálogo de datos. El administrador continúa configurando el control de acceso basado en etiquetas de Lake Formation (LF-TBAC) en la base de datos federada de Hive y lo comparte con la cuenta B.
Los usuarios del lago de datos en la cuenta B accederán a la base de datos de Hive y a las tablas de la cuenta A, al igual que consultar cualquier otro recurso compartido del catálogo de datos utilizando los permisos de Lake Formation.
El siguiente diagrama ilustra esta arquitectura.

La solución consta de pasos en ambas cuentas. En la cuenta A, realice los siguientes pasos:
- Cree un depósito de S3 para alojar los datos de muestra.
- Inicie un clúster de EMR 6.10 con Hive. Descargue los datos de muestra en el depósito de S3. Cree una base de datos y tablas externas, apuntando a los datos de muestra descargados, en su metaalmacén de Hive.
- Implementar la aplicación GlueDataCatalogFederation-HiveMetastore de AWS Serverless Application Repository y configúrelo para usar el metastore de Amazon EMR Hive. Esto creará una conexión de AWS Glue al metastore de Hive que aparece en la consola de Lake Formation.
- Con la conexión de metastore de Hive, cree una base de datos federada en AWS Glue Data Catalog.
- Cree etiquetas LF y asócielas a la base de datos federada.
- Otorgue permisos en las etiquetas LF a la cuenta B. Otorgue permisos de base de datos y tablas a la cuenta B mediante expresiones de etiquetas LF.
En la cuenta B, realice los siguientes pasos:
- Como administrador del lago de datos, revise y acepte el Administrador de acceso a recursos de AWS (AWS RAM) invita a los recursos compartidos de la cuenta A.
- El administrador del lago de datos luego ve la base de datos y las tablas compartidas. El administrador crea un enlace de recursos a la base de datos y otorga permisos detallados a un analista de datos en esta cuenta.
- Tanto el administrador del lago de datos como el analista de datos consultan las tablas de Hive que están disponibles para ellos mediante Athena.
La cuenta A tiene las siguientes personas:
- hmsblog-productor mayordomo – Administra el lago de datos en la cuenta del productor A
La cuenta B tiene las siguientes personas:
- hmsblog-consumidor mayordomo – Administra el lago de datos en la cuenta del consumidor B
- hmsblog-analista – Un analista de datos que necesita acceso a tablas de Hive seleccionadas
Requisitos previos
Para seguir el tutorial de este post, necesitas lo siguiente:
Configuración de Lake Formation y AWS CloudFormation en la cuenta A
Para simplificar la configuración, tenemos un administrador de IAM registrado como administrador del lago de datos. Complete los siguientes pasos:
- Iniciar sesión en el Consola de administración de AWS Y elige la
us-west-2Región. - En la consola de Lake Formation, debajo Permisos en el panel de navegación, elija Funciones y tareas administrativas.
- Elige Gestiona administradores existentes Administradores de lago de datos .
- under Usuarios y roles de IAM, elija el usuario administrador de IAM con el que ha iniciado sesión y elija Guardar.
- Elige Pila de lanzamiento para implementar la plantilla de CloudFormation:

- Elige Siguiente.
- Proporcione un nombre para la pila y elija Siguiente.
- En la página siguiente, elija Siguiente.
- Revise los detalles en la página final y seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM.
- Elige Crear.
La creación de la pila tarda unos 10 minutos. La pila establece la configuración de la cuenta del productor A de la siguiente manera:
- Crea un depósito de lago de datos S3
- Registra el depósito del lago de datos en Lake Formation con el Habilitar la federación de catálogos bandera
- Lanza un clúster de EMR 6.10 con Hive y ejecuta dos pasos en Amazon EMR:
- Descarga los datos de muestra del depósito público de S3 al depósito recién creado
- Crea una base de datos de Hive y cuatro tablas externas para los datos en Amazon S3 mediante un script HQL
- Crea un usuario de IAM (
hmsblog-producersteward) y establece este usuario como administrador de Lake Formation - Crea etiquetas LF (
LFHiveBlogCampaignRole=Admin,Analyst)
Revise la salida de la pila de CloudFormation en la cuenta A
Para revisar el resultado de su pila de CloudFormation, complete los siguientes pasos:
- Inicie sesión en la consola como el usuario administrador de IAM que utilizó anteriormente para ejecutar la plantilla de CloudFormation.
- Abra la consola de CloudFormation en otra pestaña del navegador.
- Revisa y anota la pila Salidas detalles de la pestaña.

- Elija el enlace debajo Valor para
ProducerStewardCredentials.
Esto abrirá la Director de secretos de AWS consola.
- Elige Recuperar valor y anotar las credenciales de
hmsblog-producersteward.

Configure una conexión de AWS Glue federada en la cuenta A
Para configurar una conexión de AWS Glue federada, complete los siguientes pasos:
- Abra la consola del repositorio de aplicaciones sin servidor de AWS en otra pestaña del navegador.
- En el panel de navegación, elija Aplicaciones disponibles.
- Seleccione Mostrar aplicaciones que crean funciones de IAM personalizadas o políticas de recursos.
- En la barra de búsqueda, ingresa Pegamento.
Esto enumerará varias aplicaciones.
- Elija la aplicación nombrada
GlueDataCatalogFederation-HiveMetastore.
Esto abrirá la AWS Lambda página de configuración de la consola para una función de Lambda que ejecuta el código de la aplicación del conector.

Para configurar la función Lambda, necesita detalles del clúster de EMR lanzado por la pila de CloudFormation.
- En otra pestaña de su navegador, abra la consola de Amazon EMR.
- Navegue hasta el clúster lanzado para esta publicación y anote los siguientes detalles de la página de detalles del clúster:
- DNS público del nodo principal
- ID de subred
- Id. de grupo de seguridad del nodo principal


- De vuelta en la página de configuración de Lambda, en Revisar, configurar e implementar, En la Configuración de la aplicación sección, proporcione los siguientes detalles. Deje el resto como los valores predeterminados.
- PegamentoConexiónNombre, introduzca
hive-metastore-connection. - HiveMetastoreURI entrar
thrift://<Primary-node-public-DNS-of your-EMR>:9083. For example, thrift://ec2-54-70-203-146.us-west-2.compute.amazonaws.com:9083, Donde9083es el puerto de metastore de Hive en el clúster de EMR. - ID de grupo de seguridad VPCS, ingrese el ID del grupo de seguridad del nodo principal de EMR.
- ID de subred VPCS, ingrese el ID de subred del clúster de EMR.
- PegamentoConexiónNombre, introduzca
- Elige Despliegue.

Esperen al Crear completado estado de la aplicación Lambda. Puede revisar los detalles de la aplicación Lambda en la consola de Lambda.

- Abra la consola Lake Formation y, en el panel de navegación, elija Compartir datos.
Debería ver hive-metastore-connection bajo Conexiones.

- Elígelo y revisa los detalles.

- En el panel de navegación, debajo Funciones y tareas administrativas, escoger Etiquetas LF.
Debería ver la etiqueta LF creada LFHiveBlogCampaignRole con dos valores: Analyst y Admin.

- Elige Permisos de etiqueta LF y elige Grant.
- Elige Usuarios y roles de IAM e introduzca
hmsblog-producersteward. - under Etiquetas LF, escoger Agregar etiqueta LF.
- Participar
LFHiveBlogCampaignRolepara Clave e introduzcaAnalystyAdminpara Valores. - under Permisos, seleccione Describir y Consejos para Permisos de etiqueta LF y Permisos concedidos.
- Elige Grant.
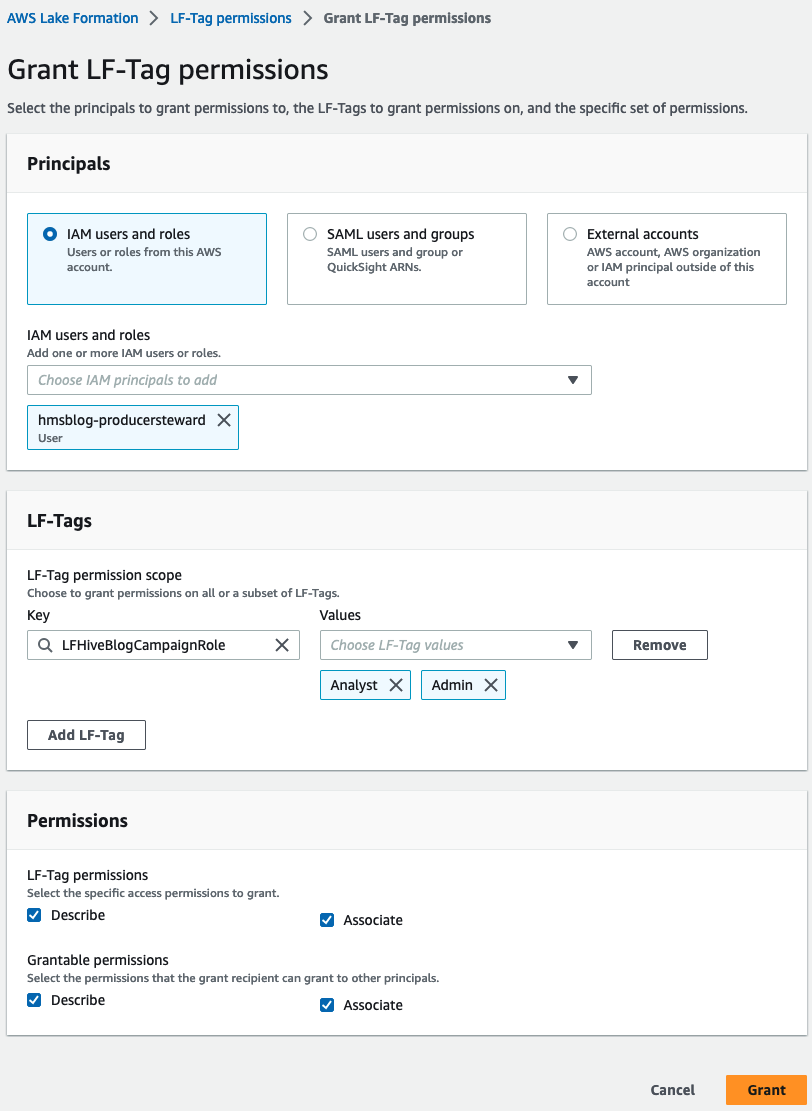
Esto otorga permisos de LF-Tags para el administrador del productor.
- Cierre sesión como usuario administrador de IAM.
Otorgar permisos de Lake Formation como administrador de productores
Complete los siguientes pasos:
- Inicie sesión en la consola como
hmsblog-producersteward, utilizando las credenciales de la pila de CloudFormation Salida pestaña que anotó anteriormente. - En la consola de Lake Formation, en el panel de navegación, elija Funciones y tareas administrativas.
- under creadores de bases de datos, escoger Grant.

- Añada
hmsblog-producerstewardcomo creador de base de datos.
- En el panel de navegación, elija Compartir datos.
- under Conexiones, elegir la
hive-metastore-connectionhiperenlace.
- En Detalles de conexión página, elige Crear base de datos.
- Nombre de la base de datos, introduzca
federated_emrhivedb.
Esta es la base de datos federada en el AWS Glue Data Catalog local que apuntará a una base de datos metastore de Hive. Esta es una asignación uno a uno de una base de datos en el catálogo de datos a una base de datos en el almacén de metadatos de Hive externo.
- Identificador de base de datos, ingrese el nombre de la base de datos en el almacén de metadatos de Hive de EMR que fue creado por el script Hive SQL. Para esta publicación, usamos
emrhms_salesdb.
- Una vez creado, seleccione
federated_emrhivedby elige Ver tablas.
Esto obtendrá los metadatos de la tabla y la base de datos del almacén de metadatos de Hive en el clúster de EMR y mostrará las tablas creadas por el script de Hive.

Ahora asocie las etiquetas LF creadas por el script de CloudFormation en esta base de datos federada y compártalas con la cuenta de consumidor B mediante expresiones de etiquetas LF.
- En el panel de navegación, elija Bases de datos.
- Seleccione
federated_emrhivedby en la Acciones menú, seleccione Editar etiquetas LF. - Elige Asignar nueva etiqueta LF.
- Participar
LFHiveBlogCampaignRolepara Teclas asignadas yAdminpara Valores, A continuación, elija Guardar.
- En el panel de navegación, elija Permisos del lago de datos.
- Elige Grant.
- Seleccione Cuentas externas e ingrese el número de cuenta B del consumidor.
- under LF-Tags o recursos del catálogo, escoger Recurso emparejado por etiquetas LF.
- Elige Agregar etiqueta LF.
- Participar
LFHiveBlogCampaignRolepara Clave yAdminpara Valores.
- En Permisos de la base de datos sección, seleccionar Describir para Permisos de la base de datos y Permisos concedidos.
- En Permisos de mesa sección, seleccionar Seleccionar y describir para Permisos de mesa y Permisos concedidos.
- Elige Grant.

- En el panel de navegación, debajo Funciones y tareas administrativas, escoger Permisos de etiqueta LF.
- Elige Grant.
- Seleccione Cuentas externas e ingrese el ID de cuenta de la cuenta de consumidor B.
- under Etiquetas LF, introduzca
LFHiveBlogCampaignRolepara Clave e introduzcaAnalystyAdminpara Valores. - under Permisos, seleccione Describir y Consejos bajo Permisos de etiqueta LF y Permisos concedidos.
- Elige Grant y verifique que los permisos de etiqueta LF otorgados se muestren correctamente.

- En el panel de navegación, elija Permisos del lago de datos.
Puede revisar y verificar los permisos otorgados a la cuenta B.
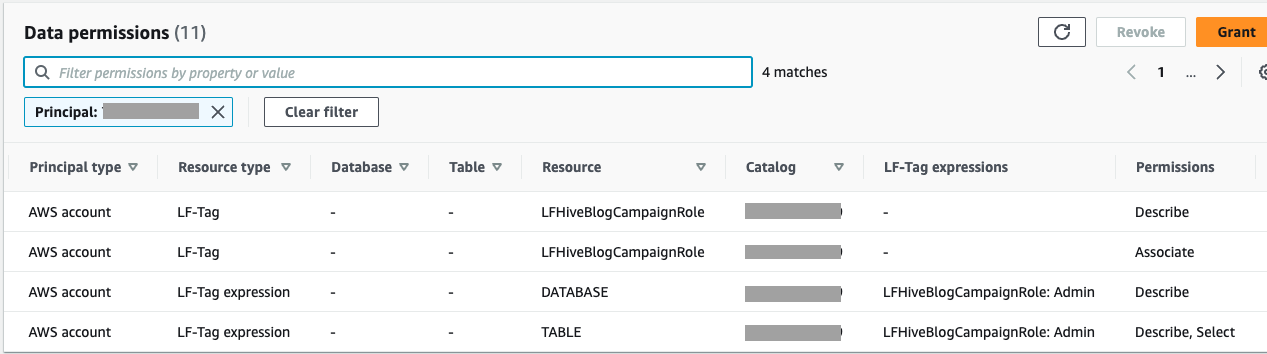
- En el panel de navegación, debajo Funciones y tareas administrativas, escoger Permisos de etiqueta LF.
Puede revisar y verificar los permisos otorgados a la cuenta B.

- Cerrar sesión en la cuenta A.
Configuración de Lake Formation y AWS CloudFormation en la cuenta B
Para simplificar la configuración, usamos un administrador de IAM registrado como administrador del lago de datos.
- Iniciar sesión en el Consola de administración de AWS de la cuenta B y seleccione el
us-west-2Región. - En la consola de Lake Formation, debajo Permisos en el panel de navegación, elija Funciones y tareas administrativas.
- Elige Administrar administradores existentes Administradores de lago de datos .
- En Usuarios y roles de IAM, elija el usuario administrador de IAM con el que inició sesión y elija Guardar.
- Elige Pila de lanzamiento para implementar la plantilla de CloudFormation:
- Elige Siguiente.
- Proporcione un nombre para la pila y elija Siguiente.
- En la página siguiente, elija Siguiente.
- Revise los detalles en la página final y seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM.
- Elige Crear.
La creación de la pila debería llevar unos 5 minutos. La pila establece la configuración de la cuenta B del productor de la siguiente manera:
- Crea un usuario de IAM
hmsblog-consumerstewardy establece a este usuario como administrador de Lake Formation - Crea otro usuario de IAM
hmsblog-analyst - Crea un depósito de lago de datos de S3 para almacenar los resultados de las consultas de Athena, con
ListBuckety escribir permisos de objeto para amboshmsblog-consumerstewardyhmsblog-analyst
Anote los detalles de salida de la pila.

Aceptar recursos compartidos en la cuenta B
Inicie sesión en la consola como hmsblog-consumersteward y completa los siguientes pasos:
- En la consola de AWS CloudFormation, vaya a la pila Salidas .
- Elija el enlace para
ConsumerStewardCredentialspara ser redirigido a la consola de Secrets Manager. - En la consola de Secrets Manager, elija Recuperar valor secreto y copie la contraseña para el usuario administrador del consumidor.
- Ingrese al
ConsoleIAMLoginURLvalor de la plantilla de CloudFormation Salida para iniciar sesión en la cuenta B con el nombre de usuario del administrador del consumidorhmsblog-consumerstewardy la contraseña que copió de Secrets Manager. - Abra la consola de RAM de AWS en otra pestaña del navegador.
- En el panel de navegación, debajo Comparte conmigo, escoger Recursos compartidos para ver las invitaciones pendientes.
Debería ver dos invitaciones para compartir recursos de la cuenta A del productor: una para un recurso compartido a nivel de base de datos y otra para un recurso compartido a nivel de tabla.

- Elija cada enlace para compartir recursos, revise los detalles y elija Aceptar.

Después de aceptar las invitaciones, el estado de los recursos compartidos cambia de Pendiente a Active.
- Abra la consola de Lake Formation en otra pestaña del navegador.
- En el panel de navegación, elija Bases de datos.
Deberías ver la base de datos compartida. federated_emrhivedb de la cuenta del productor A.
- Elija la base de datos y elija Ver tablas para revisar la lista de tablas compartidas en esa base de datos.

Debería ver las cuatro tablas de la base de datos de Hive que está alojada en el clúster de EMR en la cuenta del productor.

Otorgar permisos en la cuenta B
Para otorgar permisos en la cuenta B, complete los siguientes pasos como hmsblog-consumersteward:
- En la consola de Lake Formation, en el panel de navegación, elija Funciones y tareas administrativas.
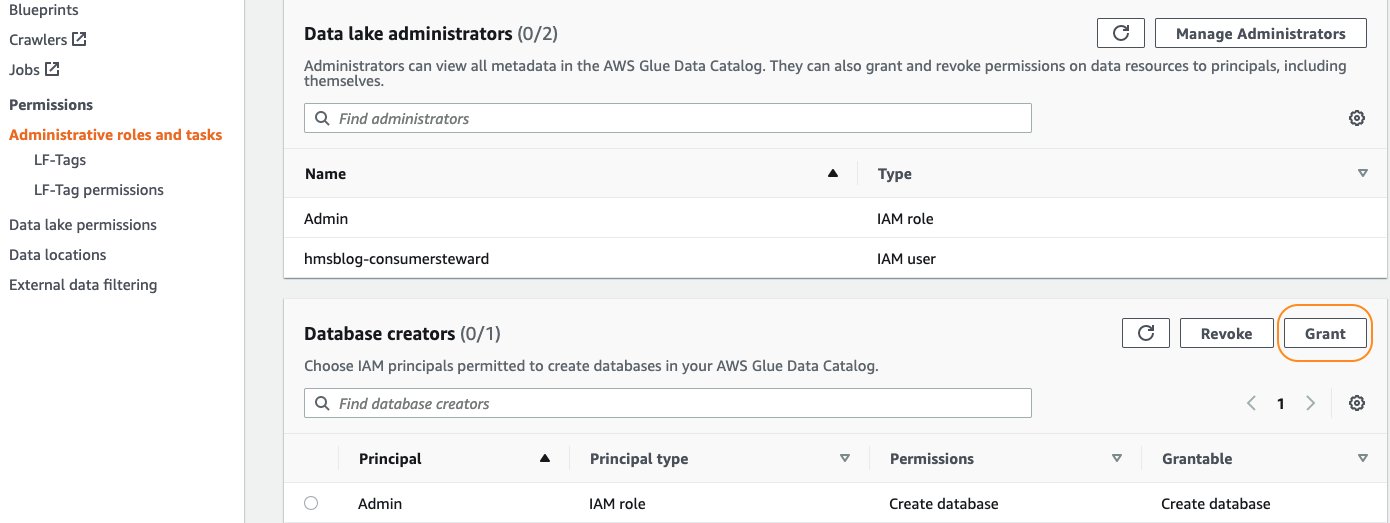
- under creadores de bases de datos, escoger Grant.
- Usuarios y roles de IAM, introduzca
hmsblog-consumersteward. - Permisos de catálogo, seleccione Crear base de datos.
- Elige Grant.

Esto permite hmsblog-consumersteward para crear un enlace de recursos de base de datos.
- En el panel de navegación, elija Bases de datos.
- Seleccione
federated_emrhivedby en la Acciones menú, seleccione Crear enlace de recursos.
- Participar
rl_federatedhivedbpara Nombre del enlace de recurso y elige Crear.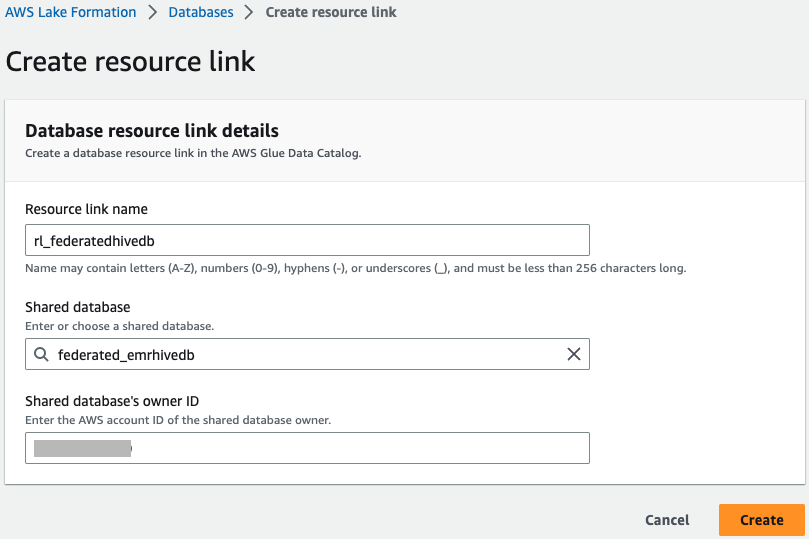
- Elige Bases de datos en el panel de navegación.
- Seleccione el enlace del recurso
rl_federatedhivedby en la Acciones menú, seleccione Grant. - Elige
hmsblog-analystpara Usuarios y roles de IAM.
- under Permisos de enlace de recursos, seleccione Describir, A continuación, elija Grant.
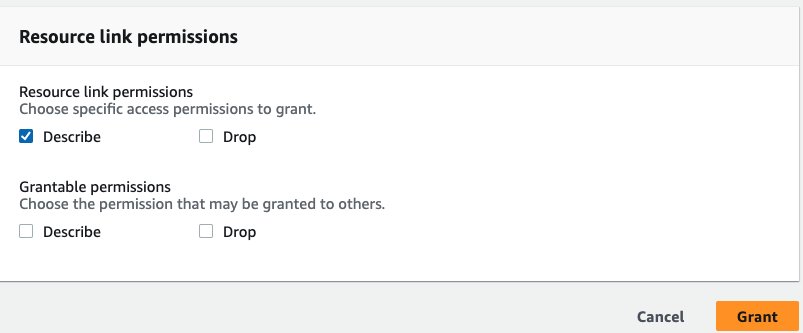
- Seleccione Bases de datos en el panel de navegación.
- Seleccione el enlace del recurso
rl_federatedhivedby en la Acciones menú, seleccione Otorgar en el objetivo. - Elige
hmsblog-analystpara Usuarios y roles de IAM. - Elige
hms_productcategoryyhms_supplierpara Mesas.
- Permisos de mesa, seleccione Seleccione y Describir, A continuación, elija Grant.

- En el panel de navegación, elija Permisos del lago de datos y revisar los permisos otorgados a
hms-analyst.
Consulta la base de datos Apache Hive del productor desde el consumidor Athena
Complete los siguientes pasos:
- En la consola de Athena, vaya al editor de consultas.
- Elige Editar la configuración para configurar los resultados de la consulta de Athena.

- Examine y elija el depósito S3
hmsblog-athenaresults-<your-account-B>-us-west-2que creó la plantilla de CloudFormation. - Elige Guardar.

hmsblog-consumersteward tiene acceso a las cuatro mesas bajo federated_emrhivedb de la cuenta del productor.
- En el editor de consultas de Athena, elija la base de datos
rl_federatedhivedby ejecutar una consulta en cualquiera de las tablas.
Pudo consultar una base de datos externa de Metastore de Apache Hive de la cuenta del productor a través de los permisos de AWS Glue Data Catalog y Lake Formation utilizando Athena desde la cuenta del consumidor del destinatario.
- Sal de la consola como
hmsblog-consumerstewardy vuelva a iniciar sesión comohmsblog-analyst. - Use el mismo método que se explicó anteriormente para obtener las credenciales de inicio de sesión de la pila de CloudFormation Salidas .
hmsblog-analyst tiene permisos Describir en el enlace de recursos y acceso a dos de las cuatro tablas de Hive. Puedes verificar que los ves en el Bases de datos y Mesas páginas en la consola Lake Formation.


En la consola de Athena, ahora configura el depósito de resultados de consultas de Athena, de forma similar a como lo configuró como hmsblog-consumersteward.
- En el editor de consultas, elija Editar la configuración.
- Examine y elija el depósito S3
hmsblog-athenaresults-<your-account-B>-us-west-2que creó la plantilla de CloudFormation. - Elige Guardar.
- En el editor de consultas de Athena, elija la base de datos
rl_federatedhivedby ejecute una consulta en las dos tablas.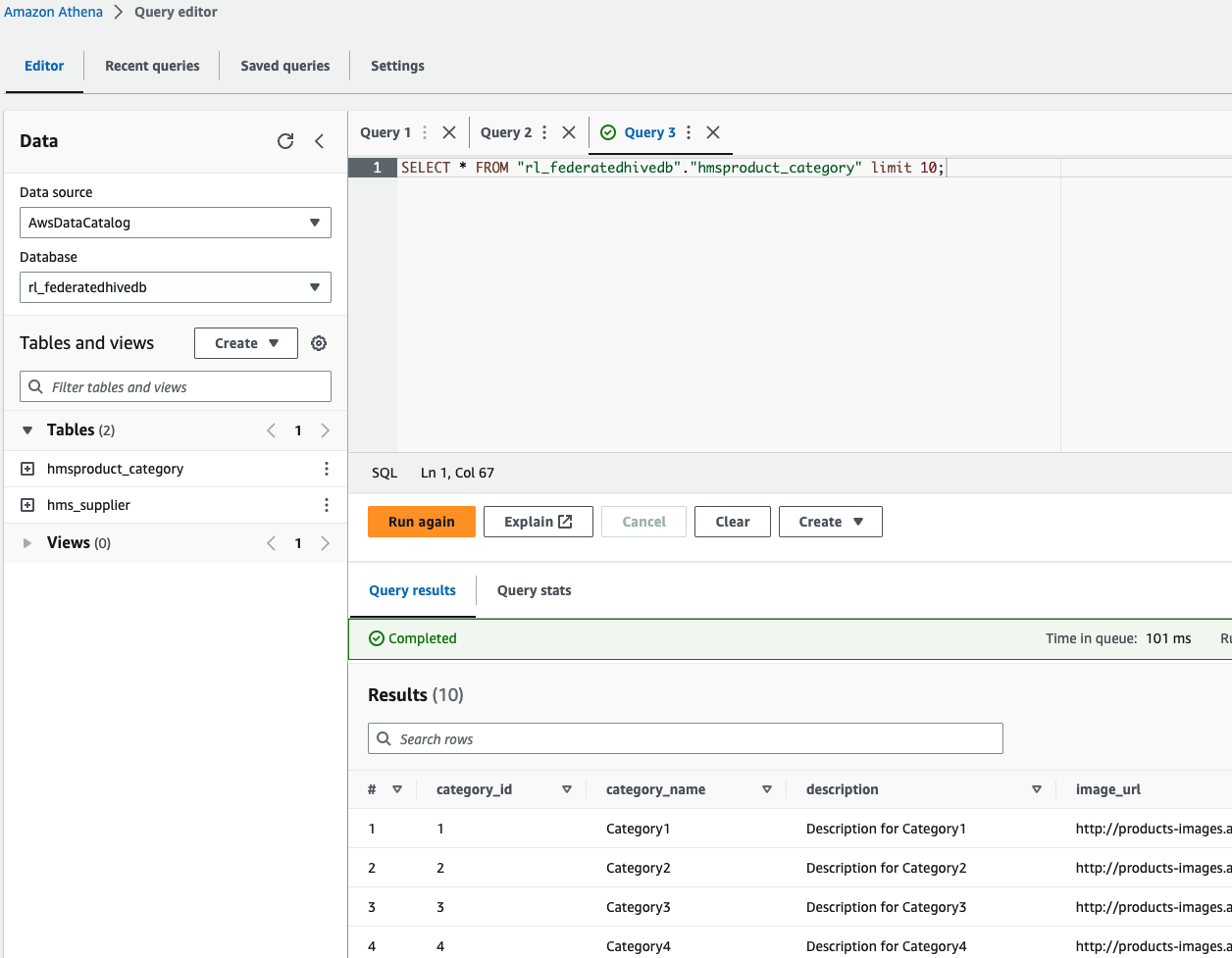
- Sal de la consola como
hmsblog-analyst.
Pudo restringir el uso compartido de tablas de metastore de Apache Hive externas mediante los permisos de Lake Formation de una cuenta a otra y consultarlas mediante Athena. También puede consultar las tablas de Hive con Redshift Spectrum, Amazon EMR y AWS Glue ETL desde la cuenta del consumidor.
Limpiar
Para evitar incurrir en cargos por los recursos de AWS creados en esta publicación, puede realizar los siguientes pasos.
Limpiar recursos en la cuenta A
Hay dos pilas de CloudFormation asociadas con la cuenta de productor A. Debe eliminar las dependencias y las dos pilas en el orden correcto.
- Inicie sesión como usuario administrador en la cuenta de productor B.
- En la consola de Lake Formation, elija Permisos del lago de datos en el panel de navegación.
- Elige Grant.
- Otorgue permisos Drop a su rol o usuario en
federated_emrhivedb.
- En el panel de navegación, elija Bases de datos.
- Seleccione
federated_emrhivedby en la Acciones menú, seleccione Borrar para eliminar la base de datos federada que está asociada con la conexión de metastore de Hive.
Esto hace que la pila de CloudFormation de la conexión de AWS Glue esté lista para ser eliminada.

- En el panel de navegación, elija Funciones y tareas administrativas.
- under creadores de bases de datos, seleccione Revocar y quitar
hmsblog-producerstewardpermisos - En la consola de CloudFormation, elimine la pila denominada
serverlessrepo-GlueDataCatalogFederation-HiveMetastorede antemano.
Este es el creado por su aplicación AWS SAM para la conexión de metastore de Hive. Espere a que se complete la eliminación.
- Elimine la pila de CloudFormation que creó para la configuración de la cuenta del productor.
Esto elimina los depósitos de S3, el clúster de EMR, las funciones y políticas de IAM personalizadas y las etiquetas LF, la base de datos, las tablas y los permisos.
Limpiar recursos en la cuenta B
Complete los siguientes pasos en la cuenta B:
- Revocar el permiso para
hmsblog-consumerstewardcomo creador de la base de datos, similar a los pasos de la sección anterior. - Elimine la pila de CloudFormation que creó para la configuración de la cuenta del consumidor.
Esto elimina los usuarios de IAM, el depósito S3 y todos los permisos de Lake Formation.
Si quedan enlaces de recursos y permisos, elimínelos manualmente en Lake Formation desde ambas cuentas.
Conclusión
En esta publicación, le mostramos cómo iniciar la aplicación de federación de metastore de AWS Glue Hive desde el repositorio de aplicaciones sin servidor de AWS, configurarla con un metastore de Hive que se ejecuta en un clúster de EMR, crear una base de datos federada en AWS Glue Data Catalog y asignarla a una base de datos de metastore de Hive en el clúster de EMR. Ilustramos cómo compartir y acceder a las tablas de la base de datos de Hive para un escenario de varias cuentas y los beneficios de usar Lake Formation para restringir los permisos.
Todas las funciones de Lake Formation, como compartir con principales de IAM dentro de la misma cuenta, compartir con cuentas externas, compartir con principales de IAM de cuentas externas, restringir el acceso a columnas y configurar filtros de datos, funcionan en bases de datos y tablas federadas de Hive. Puede utilizar cualquiera de los servicios de análisis de AWS que están integrados con Lake Formation, como Athena, Redshift Spectrum, AWS Glue ETL y Amazon EMR para consultar las tablas y la base de datos federada de Hive.
Lo alentamos a que consulte las características del conector de federación de metastore de AWS Glue Hive y explore los permisos de Lake Formation en su base de datos y tablas de Hive. Comente esta publicación o hable con su equipo de cuenta de AWS para compartir comentarios sobre esta función.
Para más detalles, consulte Administrar permisos en conjuntos de datos que usan metaalmacenes externos.
Sobre los autores
 Aarthi Srinivasan es Arquitecto Senior de Big Data con AWS Lake Formation. Le gusta crear soluciones de lagos de datos para clientes y socios de AWS. Cuando no está en el teclado, explora las últimas tendencias científicas y tecnológicas y pasa tiempo con su familia.
Aarthi Srinivasan es Arquitecto Senior de Big Data con AWS Lake Formation. Le gusta crear soluciones de lagos de datos para clientes y socios de AWS. Cuando no está en el teclado, explora las últimas tendencias científicas y tecnológicas y pasa tiempo con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/query-your-apache-hive-metastore-with-aws-lake-formation-permissions/

