Imagen del autor
Al sumergirte en el mundo de la ciencia de datos y el aprendizaje automático, una de las habilidades fundamentales que encontrarás es el arte de leer datos. Si ya tiene algo de experiencia con él, probablemente esté familiarizado con JSON (JavaScript Object Notation), un formato popular para almacenar e intercambiar datos.
Piense en cómo a las bases de datos NoSQL como MongoDB les encanta almacenar datos en JSON, o cómo las API REST suelen responder en el mismo formato.
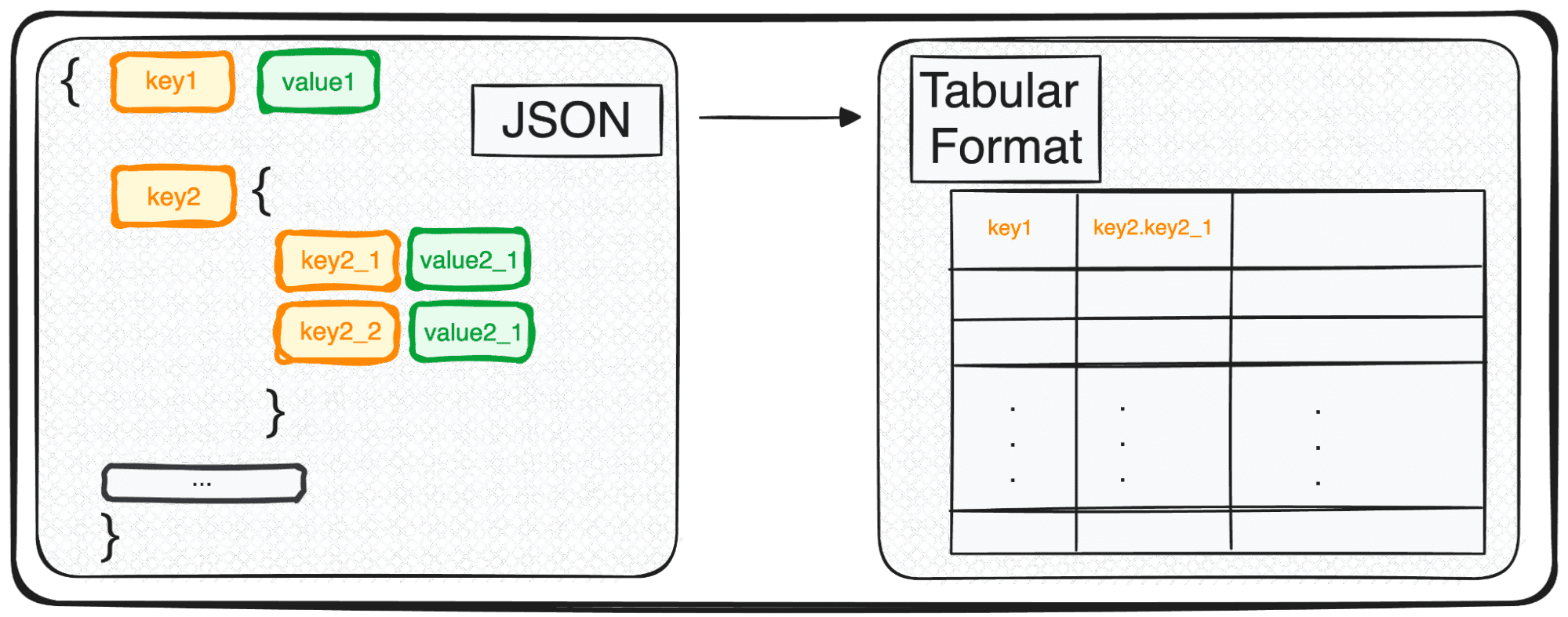
Sin embargo, JSON, si bien es perfecto para almacenamiento e intercambio, no está del todo preparado para un análisis en profundidad en su forma original. Aquí es donde lo transformamos en algo más amigable desde el punto de vista analítico: un formato tabular.
Entonces, ya sea que estés tratando con un solo objeto JSON o una deliciosa variedad de ellos, en términos de Python, básicamente estás manejando un dict o una lista de dicts.
Exploremos juntos cómo se desarrolla esta transformación, haciendo que nuestros datos estén listos para el análisis.
Hoy explicaré un comando mágico que nos permite analizar fácilmente cualquier JSON en formato tabular en segundos.
Y es…pd.json_normalizar()
Entonces, veamos cómo funciona con diferentes tipos de JSON.
El primer tipo de JSON con el que podemos trabajar son los JSON de un solo nivel con algunas claves y valores. Definimos nuestros primeros JSON simples de la siguiente manera:
Código por autor
Entonces, simulemos la necesidad de trabajar con estos JSON. Todos sabemos que no hay mucho que hacer en su formato JSON. Necesitamos transformar estos JSON en algún formato legible y modificable... ¡lo que significa Pandas DataFrames!
1.1 Manejo de estructuras JSON simples
Primero, necesitamos importar la biblioteca pandas y luego podemos usar el comando pd.json_normalize(), de la siguiente manera:
import pandas as pd
pd.json_normalize(json_string)
Aplicando este comando a un JSON de un solo registro obtenemos la tabla más básica. Sin embargo, cuando nuestros datos son un poco más complejos y presentan una lista de JSON, aún podemos usar el mismo comando sin más complicaciones y la salida corresponderá a una tabla con múltiples registros.

Imagen del autor
Fácil… ¿verdad?
La siguiente pregunta natural es qué sucede cuando faltan algunos de los valores.
1.2 Manejo de valores nulos
Imagine que algunos de los valores no están informados, como por ejemplo, falta el registro de ingresos de David. Al transformar nuestro JSON en un marco de datos pandas simple, el valor correspondiente aparecerá como NaN.

Imagen del autor
¿Y qué pasa si sólo quiero obtener algunos de los campos?
1.3 Seleccionar solo aquellas columnas de interés
En caso de que solo queramos transformar algunos campos específicos en un DataFrame tabular de pandas, el comando json_normalize() no nos permite elegir qué campos transformar.
Por lo tanto, se debe realizar un pequeño preprocesamiento del JSON donde filtramos solo aquellas columnas de interés.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Entonces, pasemos a una estructura JSON más avanzada.
Cuando tratamos con JSON de múltiples niveles, nos encontramos con JSON anidados dentro de diferentes niveles. El procedimiento es el mismo que antes, pero en este caso podremos elegir cuántos niveles queremos transformar. De forma predeterminada, el comando siempre expandirá todos los niveles y generará nuevas columnas que contienen el nombre concatenado de todos los niveles anidados.
Entonces, si normalizamos los siguientes JSON.
Código por autor
Obtendríamos la siguiente tabla con 3 columnas debajo del campo habilidades:
- habilidades.python
- habilidades.SQL
- habilidades.GCP
y 4 columnas debajo de los roles de campo
- roles.gerente de proyecto
- roles.ingeniero de datos
- roles.científico de datos
- roles.analista de datos

Imagen del autor
Sin embargo, imaginemos que solo queremos transformar nuestro nivel superior. Podemos hacerlo definiendo específicamente el parámetro max_level en 0 (el max_level que queremos expandir).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Los valores pendientes se mantendrán dentro de JSON dentro de nuestro marco de datos de pandas.

Imagen del autor
El último caso que podemos encontrar es el de tener una Lista anidada dentro de un campo JSON. Entonces, primero definimos nuestros JSON a usar.
Código por autor
Podemos gestionar estos datos de forma eficaz utilizando Pandas en Python. La función pd.json_normalize() es particularmente útil en este contexto. Puede aplanar los datos JSON, incluida la lista anidada, en un formato estructurado adecuado para el análisis. Cuando esta función se aplica a nuestros datos JSON, produce una tabla normalizada que incorpora la lista anidada como parte de sus campos.
Además, Pandas ofrece la capacidad de perfeccionar aún más este proceso. Al utilizar el parámetro record_path en pd.json_normalize(), podemos dirigir la función para normalizar específicamente la lista anidada.
Esta acción da como resultado una tabla dedicada exclusivamente al contenido de la lista. De forma predeterminada, este proceso solo desplegará los elementos dentro de la lista. Sin embargo, para enriquecer esta tabla con contexto adicional, como conservar un ID asociado para cada registro, podemos usar el metaparámetro.

Imagen del autor
En resumen, la transformación de datos JSON en archivos CSV utilizando la biblioteca Pandas de Python es fácil y eficaz.
JSON sigue siendo el formato más común en el almacenamiento e intercambio de datos modernos, especialmente en bases de datos NoSQL y API REST. Sin embargo, presenta algunos desafíos analíticos importantes cuando se trata de datos en su formato sin procesar.
El papel fundamental de pd.json_normalize() de Pandas surge como una excelente manera de manejar dichos formatos y convertir nuestros datos en Pandas DataFrame.
Espero que esta guía haya sido útil y que la próxima vez que trabaje con JSON pueda hacerlo de una manera más efectiva.
Puede consultar el Jupyter Notebook correspondiente en el siguiente repositorio de GitHub.
Josep Ferrer es un ingeniero analítico de Barcelona. Se graduó en ingeniería física y actualmente trabaja en el campo de la Ciencia de Datos aplicada a la movilidad humana. Es un creador de contenido a tiempo parcial centrado en la ciencia y la tecnología de datos. Puedes contactarlo en Etiqueta LinkedIn, Twitter or Medio.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way

