ETL (Extraer, Transformar y Cargar) es una técnica muy común en la ingeniería de datos. Implica extraer los datos operativos de varias fuentes, transformarlos en un formato adecuado para las necesidades comerciales y cargarlos en los sistemas de almacenamiento de datos.
Tradicionalmente, los procesos ETL se ejecutan en servidores, que requieren mantenimiento continuo e intervención manual. Sin embargo, con el auge de la tecnología sin servidor, ahora es posible realizar ETL sin necesidad de servidores dedicados. Aquí es donde entran en juego AWS Glue y PySpark.
AWS Glue es una oferta de ETL completamente administrada de AWS que facilita la manipulación y el movimiento de datos entre varios almacenes de datos. Puede rastrear fuentes de datos, identificar tipos y formatos de datos y sugerir esquemas, lo que facilita la extracción, transformación y carga de datos para análisis.
PySpark es el envoltorio de Python de Apache Spark (que es un poderoso marco de computación distribuida de código abierto ampliamente utilizado para el procesamiento de big data).
¿Cómo funcionan AWS Glue y PySpark?
Juntos, Glue y PySpark brindan una poderosa solución ETL sin servidor que es fácil de usar y escalable. Así es como funciona:
- Primero, Glue rastrea sus fuentes de datos para identificar los formatos de datos y sugerir un esquema. A continuación, puede editar y refinar el esquema según sea necesario.
- A continuación, utiliza PySpark para escribir secuencias de comandos ETL que extraen los datos de las fuentes, los transforman de acuerdo con el esquema y los cargan en su almacén de datos u otros sistemas de almacenamiento.
- Luego, los scripts de PySpark son ejecutados por Glue, que se escala automáticamente hacia arriba o hacia abajo para manejar la carga de trabajo. Esto le permite procesar grandes cantidades de datos sin tener que preocuparse por administrar servidores o infraestructura.
- Finalmente, Glue también proporciona un amplio conjunto de herramientas para monitorear y administrar sus procesos ETL, incluido un editor de flujo de trabajo visual, programación de trabajos y seguimiento de linaje de datos.
El caso de uso
En este caso de uso, desarrollaremos una canalización de datos de muestra (Glue Job) con el SDK de AWS TypeScript, que leerá los datos de una tabla de base de datos de Dynamo, realizará alguna transformación de datos con PySpark y los escribirá en un depósito S3 en formato CSV. DynamoDB es un servicio de base de datos NoSQL completamente administrado ofrecido por AWS, que es fácilmente escalable y se usa en múltiples aplicaciones. Por otro lado, S3 es una oferta de almacenamiento de uso general de AWS.
Para simplificar, podemos considerar esto como un caso de uso para mover una aplicación o datos transaccionales al lago de datos.
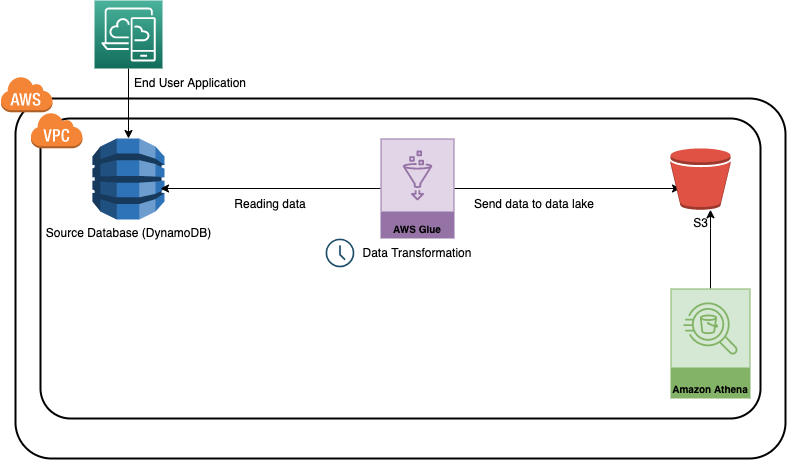
Estructura del proyecto
lib/cdk-workshop-stack.tses donde se define la pila principal de la aplicación CDK. Definiremos los recursos de AWS necesarios aquí.bin/cdk-workshop.tses el punto de entrada o función 'principal' de cualquier aplicación CDK. Cargará la pila definida enlib/cdk-workshop-stack.ts.package.jsones el manifiesto del módulo npm, que contiene información como el nombre de la aplicación CDK, la versión, las dependencias y diferentes scripts de compilacióncdk.jsonle dice al conjunto de herramientas cómo ejecutar su aplicación CDK. En nuestro caso será"npx ts-node bin/cdk-workshop.ts"stack-configuration.tsse utiliza para mantener detalles relacionados con la configuración, como el nombre de la tabla, el trabajo de encolado, etc.assets/glue-cdk-asset-etl.pyes el script de python que se ejecuta desde el trabajo de pegadotsconfig.jsontu proyecto configuración mecanografiada.gitignorey.npmignoredecirle a los administradores de paquetes que incluyan/excluyan archivos específicos del control de código fuente al publicar este módulonode_moduleses mantenido por npm e incluye las dependencias de su proyecto.
Comprensión de la pila principal en AWS Glue
Hay varias formas de crear recursos en AWS
- Basado en la interfaz de usuario: utilizando la consola en la nube de AWS
- Basado en terminal: utilizando AWS CDK
- Forma programática: también podemos crear/eliminar/actualizar recursos de AWS mediante programación utilizando los SDK.
En este caso de uso, usaremos el SDK de mecanografiado para desarrollar los recursos y Python para el script de pegamento. (Glue es compatible con python y scala actualmente). Echemos un vistazo a cómo estamos creando recursos clave en la pila principal
Creación de un depósito S3 que se utilizará para almacenar los archivos procesados
const etl_bucket=nuevo Cubo(esto,'pegamento-etl-cubo',{
bucketName:StackConfiguration.bucketName, RemovalPolicy:RemovalPolicy.DESTROY, enforceSSL:true });
Crear un rastreador de Glue que ayude a descubrir el esquema
/create glue crawler const glue_crawler = new glue.CfnCrawler(this, "glue-crawler-dynamoDB", { nombre: "glue-dynamo-crawler", rol: glue_service_role.roleName, targets: { dynamoDbTargets:[ { path:sourcetable. tableName } ] }, databaseName: StackConfiguration.glueCatlogDBName, tablePrefix:'demo-', schemaChangePolicy: { updateBehavior: "UPDATE_IN_DATABASE", deleteBehavior: "DEPRECATE_IN_DATABASE", }, }); Creación de una tabla de base de datos de Dynamo que se utilizará como fuente para este caso de uso
// creando la tabla fuente
const sourcetable=new dynamodb.Table(this,'etl-glue-source',{
PartitionKey :{name:"policy_id",type:dynamodb.AttributeType.STRING}, sortKey:{name:"age_of_car",type:dynamodb.AttributeType.STRING}, tableName:"glue-etl-demo-source", RemovalPolicy: Política de eliminación. DESTRUIR })
Creación de un trabajo de pegamento
//crear trabajo de pegado const etl_glue_job=pegamento nuevo.CfnJob(this,'glue-etl-demo-job',{ role:glue_service_role.roleArn, command:{ name:'glue-etl', scriptLocation:f_pyAssetETL.s3ObjectUrl, pythonVersion :'3.9', }, defaultArguments:job_params, description:'Ejemplo de trabajo de procesamiento de Glue de DynamoDB a S3', name:StackConfiguration.glueJobName, glueVersion:'3.0', workerType:'G.1X', numberOfWorkers:2, tiempo de espera: 5, número máximo de intentos: 0 }) } }
Nota: para simplificar, no estamos creando ningún disparador aquí y ejecutaremos el trabajo manualmente desde la consola. En la práctica, podemos crear disparadores programados basados en el tiempo que se ejecutarán automáticamente como un trabajo cron.
Comprender el script de PySpark
Veamos ahora las operaciones que estamos realizando en el trabajo de Glue usando PySpark Script. Los datos que hemos utilizado provienen de una muestra de reclamos de seguros de automóviles.
Estamos realizando las siguientes operaciones aquí.
1. Leer los datos de la tabla de base de datos de Dynamo de origen – La primera operación que estamos haciendo aquí es leer los datos de la tabla DB de Dynamo de origen, que simula los datos de reclamos de seguros. Tenga en cuenta que el nombre de la tabla de la base de datos y otros metadatos se pasan a través de variables ambientales.
2. Convertir el marco dinámico en un marco de datos PySpark – Por defecto, cuando leemos los datos usando la API de AWS Glue, crea un marco dinámico. Necesitamos convertirlo en el marco de datos PySpark para facilitar la manipulación de datos.
3. Manteniendo solo las columnas necesarias para nuestras necesidades de informes – La siguiente operación que estamos haciendo es eliminar columnas no deseadas. Supongamos que solo necesitamos unas pocas columnas para generar el informe de la tabla de reclamaciones de seguros. Este paso asegura que solo estamos considerando los atributos necesarios.
4. Filtrar la antigüedad de los datos de la columna de los coches. – Mientras trabajamos en un caso de uso de ETL específico, no siempre necesitamos todos los datos. Es una buena práctica seleccionar solo la información necesaria. Hemos ordenado y filtrado el marco de datos en estos pasos usando la funcionalidad de clasificación y filtrado de PySpark. Hemos asumido un umbral de 0.7 para la columna 'edad de los automóviles'.
5. Escribir los datos en un depósito S3 – Una vez que hemos extraído y transformado los datos en función de nuestras necesidades comerciales, debemos volver a escribirlos en un depósito S3. Para lograr eso, hay dos operaciones que necesitamos realizar
- Convertir a marco de datos PySpark de nuevo a marco dinámico
- Escriba el marco dinámico en el depósito S3 utilizando la API 'escribir marco dinámico'
# crear un marco dinámico a partir de la tabla de la base de datos datasource0 = glueContext.create_dynamic_frame.from_catalog(database = args['DATABASE_NAME'], table_name = args['TABLE_NAME'], transform_ctx = "datasource0") # convertir el marco dinámico en un marco de datos pyspark data_frame = datasource0.toDF() # seleccionar un subconjunto de columnas data_frame=data_frame[["policy_id","policy_tenure","make","model","age_of_car","is_claim"]] # clasificar el marco de datos por antigüedad del automóvil data_frame =data_frame.orderBy(col("age_of_car").desc()) # filtrar los autos - elige solo aquellos donde age<0.7 data_frame=data_frame.filter(data_frame.age_of_car<0.7) data_frame = data_frame.repartition(1) # convert el dataframe pyspark vuelve al marco dinámico dynamic_frame_write = DynamicFrame.fromDF(data_frame, glueContext, "dynamic_frame_write") # escribe los datos en s3 s3bucket_node=glueContext.write_dynamic_frame.from_options( frame=dynamic_frame_write, connection_type="s3", format="csv" , opciones_de conexión={"ruta":argumentos['BUCKET_PATH']}, transformación on_ctx="S3bucket_node" )
El código completo está disponible en https://github.com/arpan65/aws-serverless-etl
¿Cómo podemos implementar el código en AWS Glue?
Lo primero es lo primero: tenga en cuenta que, antes de continuar, debemos tener una cuenta de AWS (el nivel gratuito es suficiente) y configurar la CLI de AWS (consulte este documento https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html)
Ahora aprenderemos sobre dos importantes comandos CLI
cdk bootstrapCuando estamos implementando una aplicación CDK por primera vez, necesitamos usar este comando que inicia los recursos necesarios para la operación del kit de herramientas CDK.

cdk synthComo se mencionó anteriormente, el código que hemos escrito en nuestra pila es solo la definición de los recursos de AWS. Cuando usamos este comando, las aplicaciones CDK se sintetizan. es decir, se generan plantillas de formación de nubes
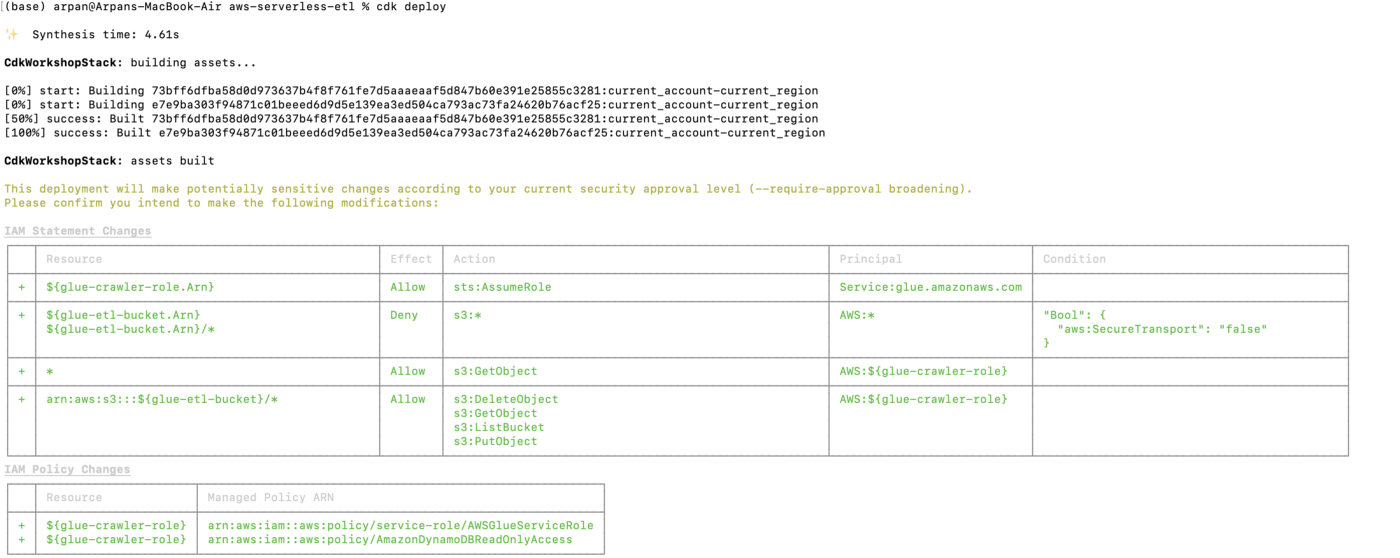
cdk deployCuando se ejecuta, este comando implementa el conjunto de cambios de formación de nubes en aws

Una vez completada la implementación, vaya a la consola de AWS; deberías ver la pila allí. Por favor, asegúrese de que está buscando en la región adecuada.
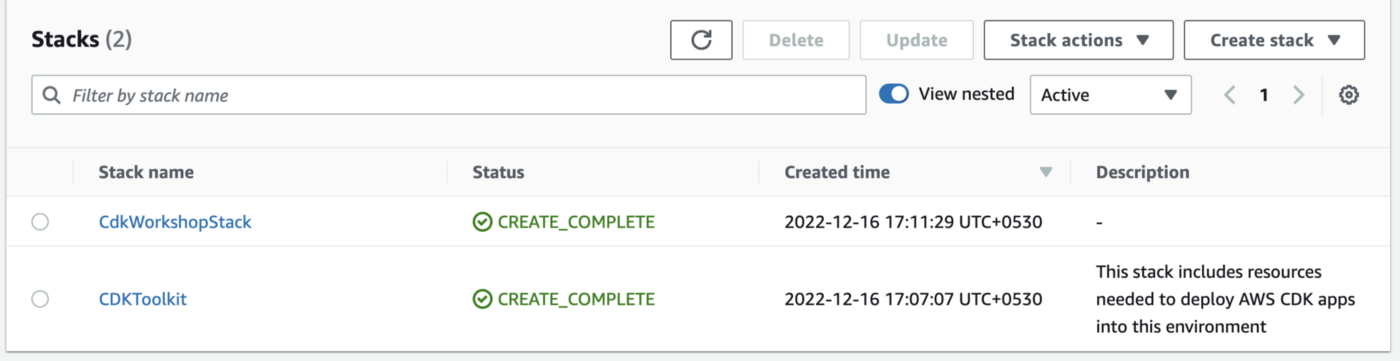
¿Cómo probar la tubería?
1. Cree datos de muestra para dynamo DB utilizando el esquema del archivo lib/sample data/sample.csv.
2. Navegue al servicio Glue desde la consola de AWS y haga clic en los trabajos; debería poder ver un nuevo trabajo presente allí.

3. Haga clic en el trabajo y ejecútelo.
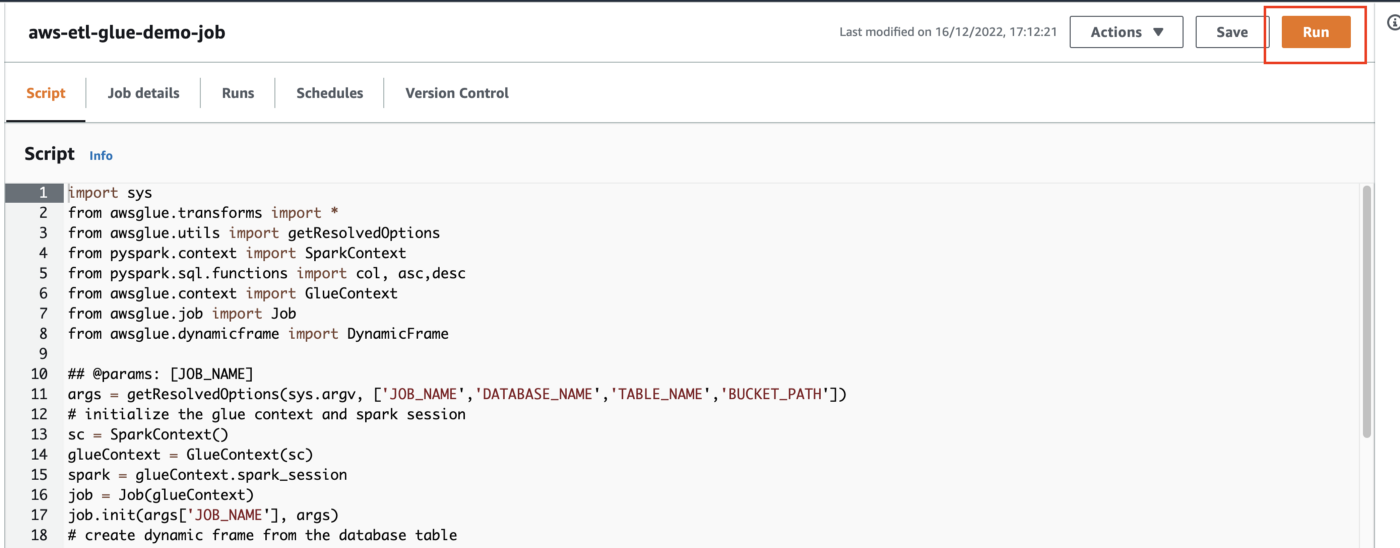
4. Una vez que el trabajo se complete correctamente, navegue hasta el depósito S3. El archivo formateado final estará presente allí.
Por favor, eche un vistazo a la demostración completa para una mejor comprensión:
Conclusión
AWS Glue ha preparado el juego para las soluciones ETL sin servidor y facilita el desarrollo y el mantenimiento de canalizaciones de datos con facilidad. resumamos nuestros aprendizajes de este artículo
- Hemos demostrado un caso de uso común de ETL del marco Glue y PySpark, ampliamente utilizado en la industria en varios dominios.
- Hemos aprendido a definir y administrar recursos de AWS (DynamoDB, Glue Jobs, Crawlers, roles de IAM, etc.) mediante programación usando el SDK de TypeScript de AWS y realizando las operaciones básicas de manipulación de datos usando PySpark en python.
- Como parte de este caso de uso, aprendimos cómo iniciar e implementar los recursos de AWS mediante la CLI.
- Hemos aprendido cómo configurar un trabajo de Glue para ejecutar el script PySpark y cómo podemos transformar y mover fácilmente los datos operativos de la tabla Dynamo DB a S3 sin necesidad de aprovisionar ni mantener ningún servidor.
Si está buscando experiencia práctica en AWS, lo animo a probarlo por su cuenta y configurar el trabajo para que se ejecute según un cronograma (bueno, eso suena como tarea 😊). Feliz aprendizaje.
Citación
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/12/crafting-serverless-etl-pipeline-using-aws-glue-and-pyspark/

