Introducción
En el acelerado mundo actual, el servicio al cliente es un aspecto crucial de cualquier negocio. Un Answer Bot de Zendesk, impulsado por modelos de lenguajes grandes (LLM) como GPT-4, puede mejorar significativamente la eficiencia y la calidad de la atención al cliente al automatizar las respuestas. Esta publicación de blog lo guiará en la creación e implementación de su propio Zendesk Auto Responder utilizando LLM y la implementación de flujos de trabajo basados en RAG en GenAI para agilizar el proceso.

¿Qué son los flujos de trabajo basados en RAG en GenAI?
Los flujos de trabajo basados en RAG (Generación Aumentada de Recuperación) en GenAI (IA Generativa) combinan los beneficios de la recuperación y la generación para mejorar las capacidades del sistema de IA, particularmente en el manejo de datos específicos de dominio del mundo real. En términos simples, RAG permite a la IA extraer información relevante de una base de datos u otras fuentes para respaldar la generación de respuestas más precisas e informadas. Esto es particularmente beneficioso en entornos empresariales donde la precisión y el contexto son fundamentales.
¿Cuáles son los componentes de un flujo de trabajo basado en RAG?
- Base de conocimientos: La base de conocimientos es un depósito centralizado de información al que el sistema hace referencia al responder consultas. Puede incluir preguntas frecuentes, manuales y otros documentos relevantes.
- Activador/Consulta: Este componente es responsable de iniciar el flujo de trabajo. Generalmente es la pregunta o solicitud de un cliente la que necesita una respuesta o acción.
- Tarea/Acción: Con base en el análisis del disparador/consulta, el sistema realiza una tarea o acción específica, como generar una respuesta o realizar una operación de backend.
Algunos ejemplos de flujos de trabajo basados en RAG
- Flujo de trabajo de interacción con el cliente en la banca:
- Los chatbots impulsados por GenAI y RAG pueden mejorar significativamente las tasas de participación en la industria bancaria al personalizar las interacciones.
- A través de RAG, los chatbots pueden recuperar y utilizar información relevante de una base de datos para generar respuestas personalizadas a las consultas de los clientes.
- Por ejemplo, durante una sesión de chat, un sistema GenAI basado en RAG podría extraer el historial de transacciones del cliente o la información de la cuenta de una base de datos para proporcionar respuestas más informadas y personalizadas.
- Este flujo de trabajo no solo mejora la satisfacción del cliente, sino que también aumenta potencialmente la tasa de retención al brindar una experiencia de interacción más personalizada e informativa.
- Flujo de trabajo de campañas de correo electrónico:
- En marketing y ventas, crear campañas específicas es fundamental.
- RAG se puede emplear para obtener la información más reciente sobre productos, comentarios de clientes o tendencias de mercado de fuentes externas para ayudar a generar material de marketing/ventas más informado y eficaz.
- Por ejemplo, al diseñar una campaña de correo electrónico, un flujo de trabajo basado en RAG podría recuperar reseñas positivas recientes o nuevas características del producto para incluirlas en el contenido de la campaña, mejorando así potencialmente las tasas de participación y los resultados de ventas.
- Flujo de trabajo de modificación y documentación de código automatizado:
- Inicialmente, un sistema RAG puede extraer la documentación del código existente, la base del código y los estándares de codificación del repositorio del proyecto.
- Cuando un desarrollador necesita agregar una nueva característica, RAG puede generar un fragmento de código siguiendo los estándares de codificación del proyecto haciendo referencia a la información recuperada.
- Si se necesita una modificación en el código, el sistema RAG puede proponer cambios analizando el código y la documentación existentes, garantizando la coherencia y el cumplimiento de los estándares de codificación.
- Después de la modificación o adición de código, RAG puede actualizar automáticamente la documentación del código para reflejar los cambios, obteniendo la información necesaria de la base del código y la documentación existente.
Cómo descargar e indexar todos los tickets de Zendesk para recuperarlos
Comencemos ahora con el tutorial. Crearemos un bot para responder tickets entrantes de Zendesk mientras usamos una base de datos personalizada de tickets y respuestas anteriores de Zendesk para generar la respuesta con la ayuda de LLM.
- Acceda a la API de Zendesk: Utilice la API de Zendesk para acceder y descargar todos los boletos. Asegúrese de tener los permisos necesarios y las claves API para acceder a los datos.
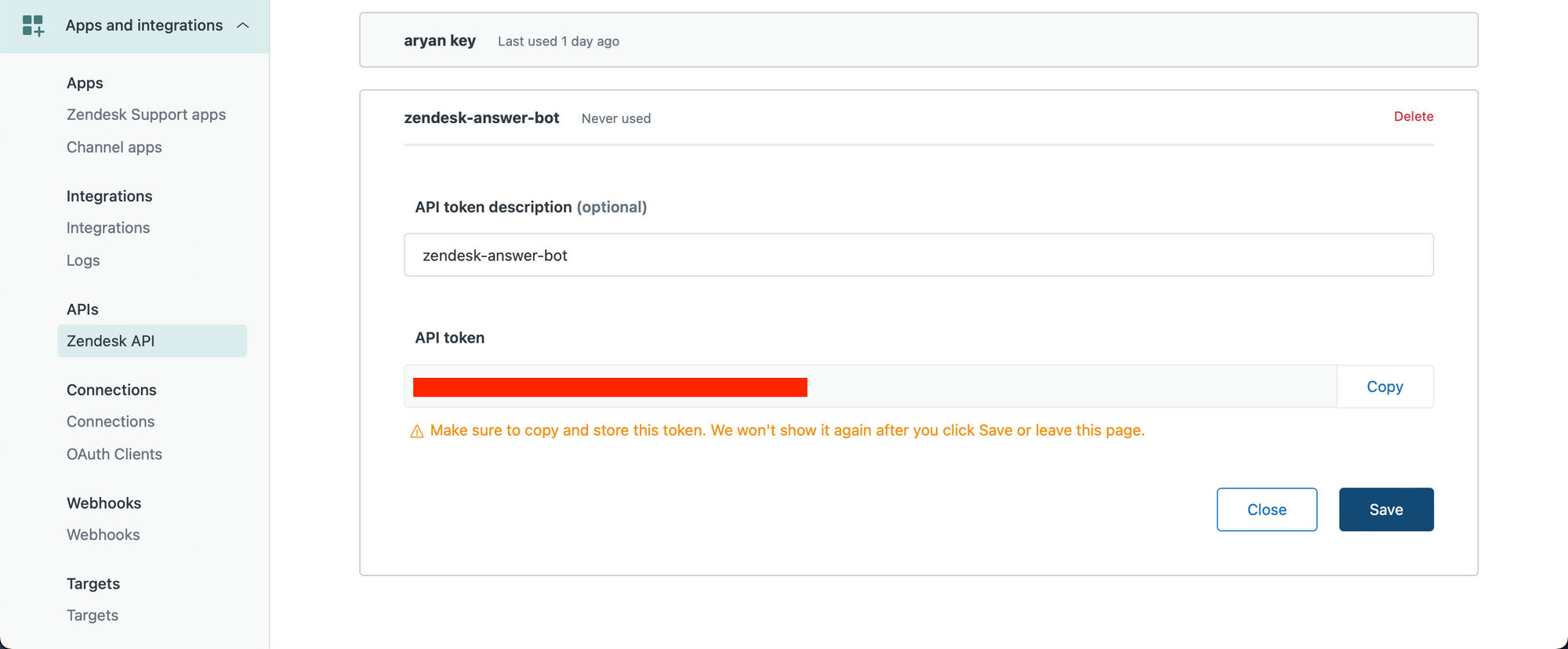
Primero creamos nuestra clave API de Zendesk. Asegúrese de ser un usuario administrador y visite el siguiente enlace para crear su clave API: https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/apis/zendesk-api/settings/tokens
Cree una clave API y cópiela en su portapapeles.
Comencemos ahora con un cuaderno de Python.
Ingresamos nuestras credenciales de Zendesk, incluida la clave API que acabamos de obtener.
subdomain = YOUR_SUBDOMAIN
username = ZENDESK_USERNAME
password = ZENDESK_API_KEY
username = '{}/token'.format(username)Ahora recuperamos los datos del ticket. En el siguiente código, hemos recuperado consultas y respuestas de cada ticket y almacenamos cada conjunto [consulta, conjunto de respuestas] que representa un ticket en una matriz llamada datos del billete.
Solo estamos obteniendo los últimos 1000 boletos. Puede modificar esto según sea necesario.
import requests ticketdata = []
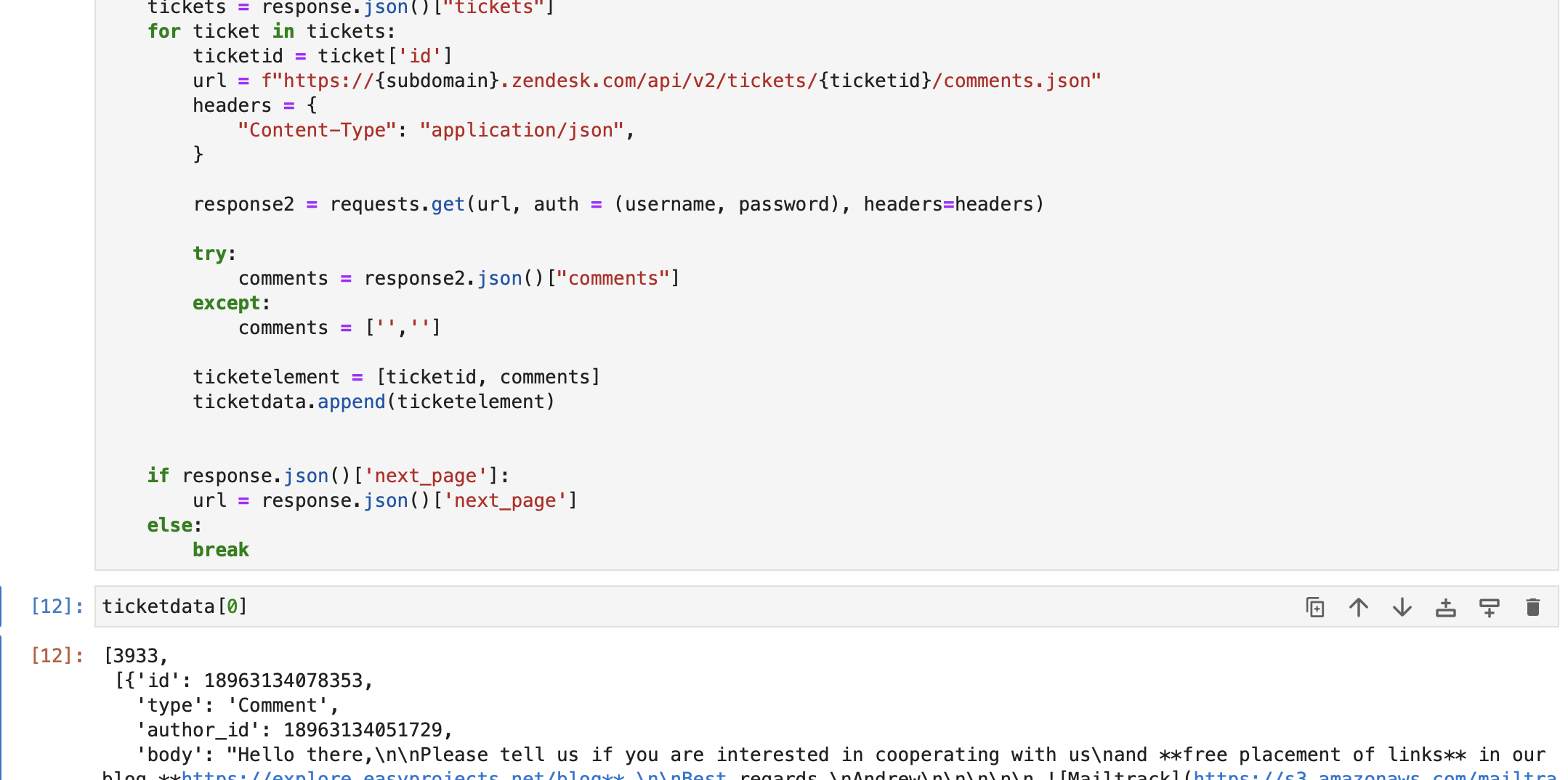
url = f"https://{subdomain}.zendesk.com/api/v2/tickets.json" params = {"sort_by": "created_at", "sort_order": "desc"} headers = {"Content-Type": "application/json"} tickettext = "" while len(ticketdata) <= 1000: response = requests.get( url, auth=(username, password), params=params, headers=headers ) tickets = response.json()["tickets"] for ticket in tickets: ticketid = ticket["id"] url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticketid}/comments.json" headers = { "Content-Type": "application/json", } response2 = requests.get(url, auth=(username, password), headers=headers) try: comments = response2.json()["comments"] except: comments = ["", ""] ticketelement = [ticketid, comments] ticketdata.append(ticketelement) if response.json()["next_page"]: url = response.json()["next_page"] else: breakComo puede ver a continuación, hemos recuperado datos de tickets de la base de datos de Zendesk. Cada elemento en datos del billete contiene -
a. Identificación de entradas
b. Todos los comentarios/respuestas en el ticket.
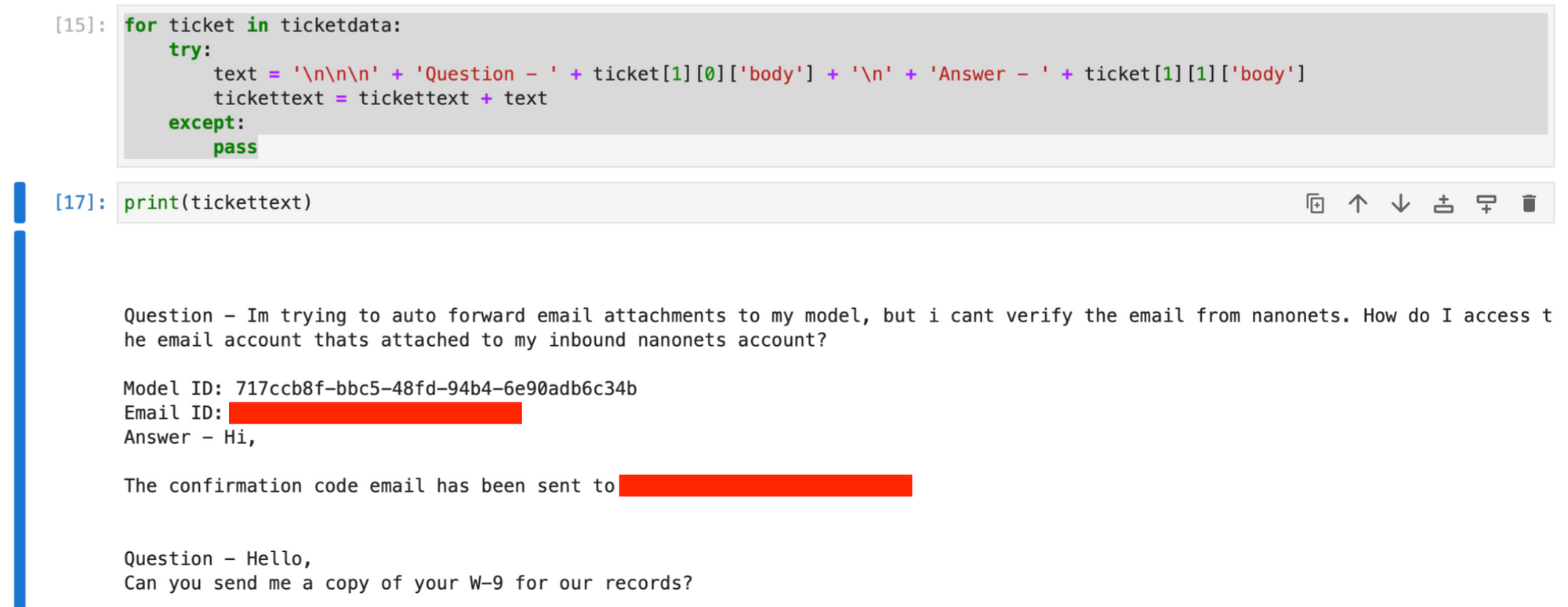
Luego pasamos a crear una cadena basada en texto que tenga las consultas y las primeras respuestas de todos los tickets recuperados, usando el datos del billete formación.
for ticket in ticketdata: try: text = ( "nnn" + "Question - " + ticket[1][0]["body"] + "n" + "Answer - " + ticket[1][1]["body"] ) tickettext = tickettext + text except: passEl texto del ticket La cadena ahora contiene todos los tickets y las primeras respuestas, con los datos de cada ticket separados por caracteres de nueva línea.
Opcional : También puede obtener datos de sus artículos de Zendesk Support para ampliar aún más la base de conocimientos ejecutando el siguiente código.
import re def remove_tags(text): clean = re.compile("<.*?>") return re.sub(clean, "", text) articletext = ""
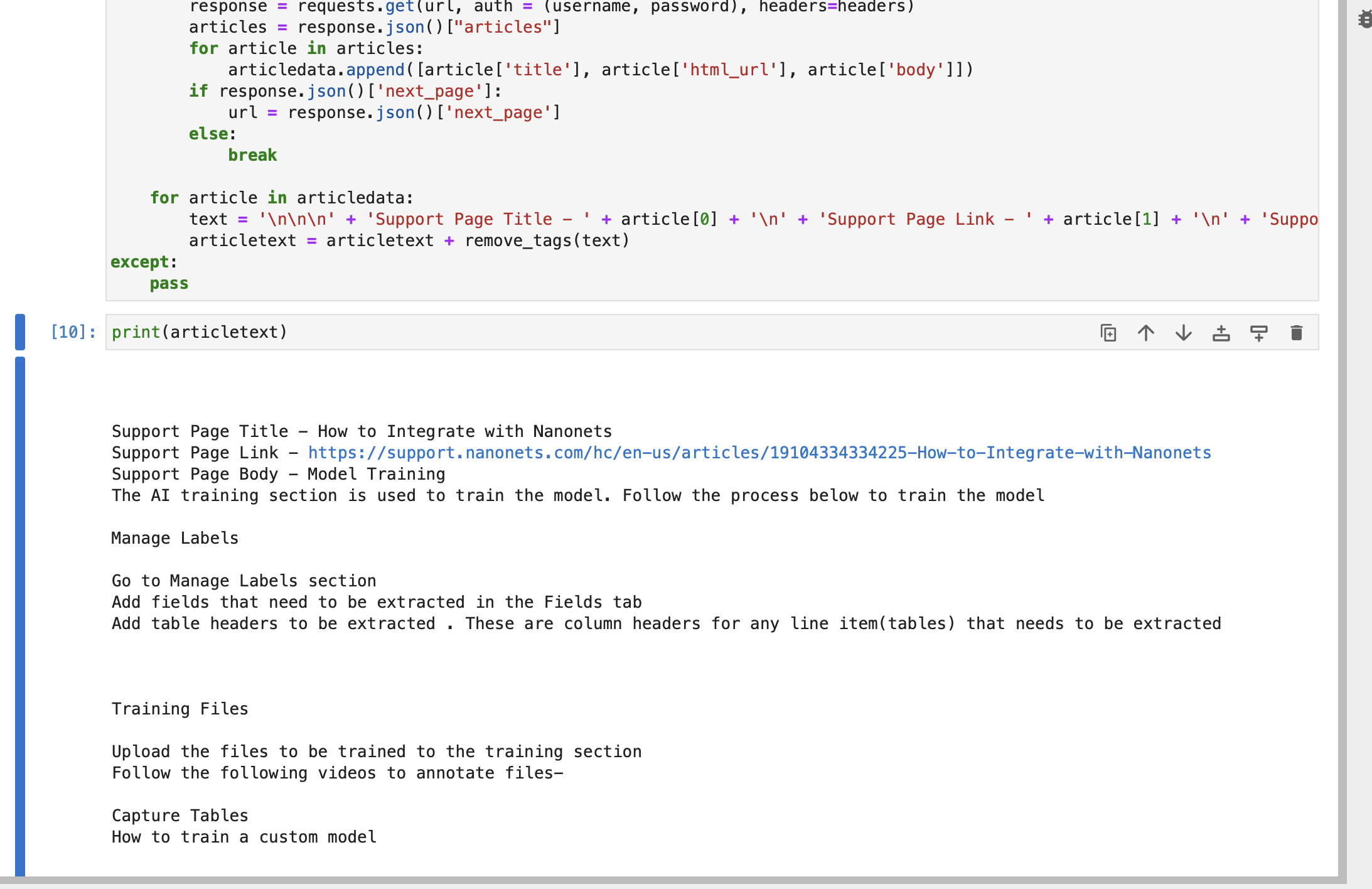
try: articledata = [] url = f"https://{subdomain}.zendesk.com/api/v2/help_center/en-us/articles.json" headers = {"Content-Type": "application/json"} while True: response = requests.get(url, auth=(username, password), headers=headers) articles = response.json()["articles"] for article in articles: articledata.append([article["title"], article["html_url"], article["body"]]) if response.json()["next_page"]: url = response.json()["next_page"] else: break for article in articledata: text = ( "nnn" + "Support Page Title - " + article[0] + "n" + "Support Page Link - " + article[1] + "n" + "Support Page Body - " + article[2] ) articletext = articletext + remove_tags(text)
except: passLa cuerda texto del artículo contiene el título, el enlace y el cuerpo de cada artículo de sus páginas de soporte de Zendesk.
Opcional : Puede conectar su base de datos de clientes o cualquier otra base de datos relevante y luego usarla mientras crea el almacén de índice.
Combine los datos obtenidos.
knowledge = tickettext + "nnn" + articletext- Entradas índice: Una vez descargados, indexe los tickets utilizando un método de indexación adecuado para facilitar una recuperación rápida y eficiente.
Para hacer esto, primero instalamos las dependencias necesarias para crear la tienda de vectores.
pip install langchain openai pypdf faiss-cpuCree un almacén de índice utilizando los datos obtenidos. Esto actuará como nuestra base de conocimientos cuando intentemos responder nuevos tickets a través de GPT.
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY" from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np tokenizer = GPT2TokenizerFast.from_pretrained("gpt2") def count_tokens(text: str) -> int: return len(tokenizer.encode(text)) text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=24, length_function=count_tokens,
) chunks = text_splitter.create_documents([knowledge]) token_counts = [count_tokens(chunk.page_content) for chunk in chunks]
df = pd.DataFrame({"Token Count": token_counts})
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(chunks, embeddings)
path = "zendesk-index"
db.save_local(path)
Su índice se guarda en su sistema local.

- Actualizar el índice periódicamente: Actualice periódicamente el índice para incluir nuevos tickets y modificaciones a los existentes, asegurando que el sistema tenga acceso a los datos más actualizados.
Podemos programar el script anterior para que se ejecute cada semana y actualizar nuestro 'índice zendesk' o cualquier otra frecuencia deseada.
Cómo realizar la recuperación cuando llega un nuevo billete
- Monitorear nuevos boletos: Configure un sistema para monitorear Zendesk en busca de nuevos tickets continuamente.
Crearemos una API Flask básica y la alojaremos. Para empezar,
- Cree una nueva carpeta llamada 'Zendesk Answer Bot'.
- Agregue su carpeta de base de datos FAISS 'zendesk-index' a la carpeta 'Zendesk Answer Bot'.
- Cree un nuevo archivo Python zendesk.py y copie el siguiente código en él.
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): return 'dummy response' if __name__ == '__main__': app.run(port=3001, debug=True)- Ejecute el código Python.
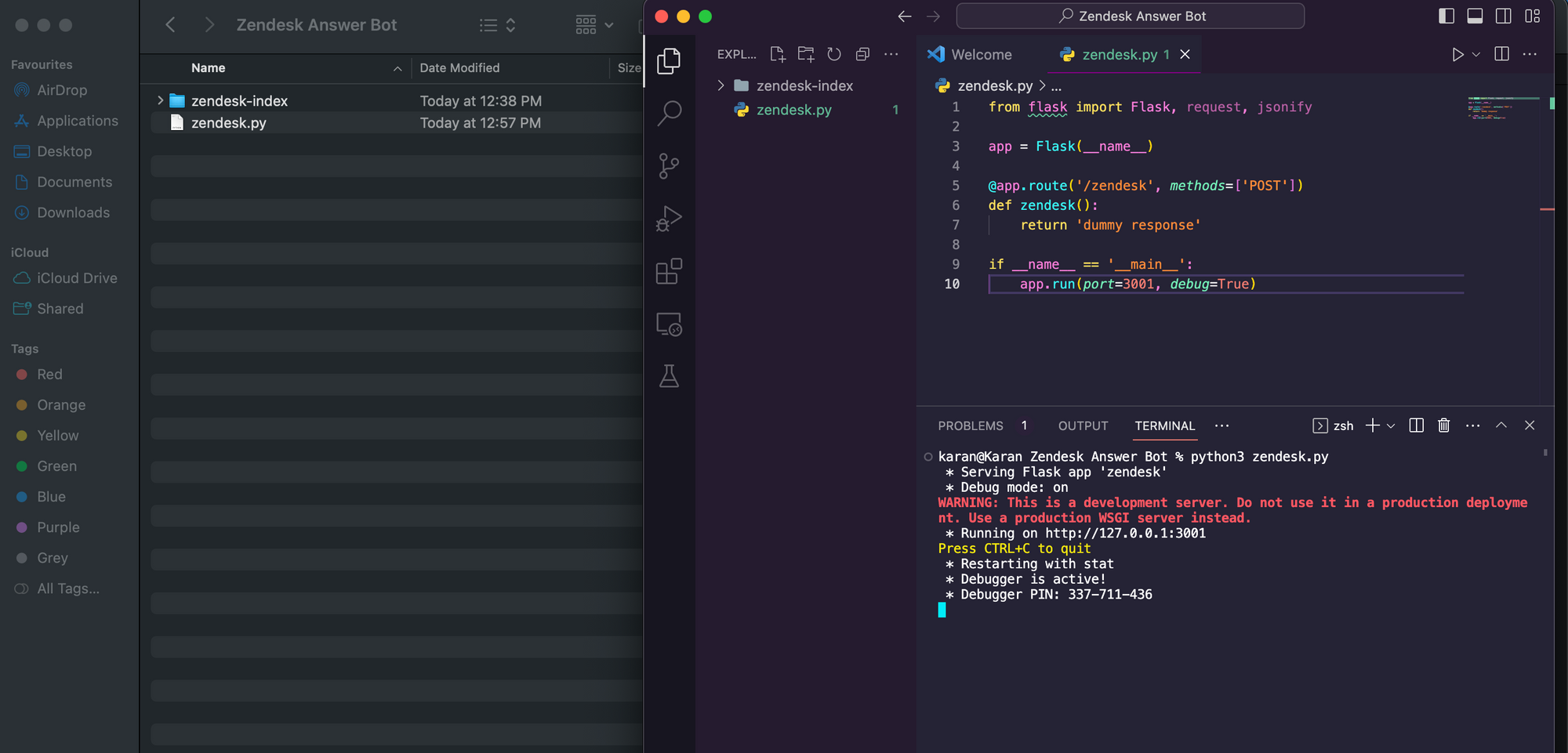
- Descargar y configurar ngrok usando las instrucciones aquí. Asegúrese de configurar el token de autenticación ngrok en su terminal como se indica en el enlace.
- Abra una nueva instancia de terminal y ejecute el siguiente comando.
ngrok http 3001- Ahora tenemos nuestro servicio Flask expuesto a través de una IP externa mediante la cual podemos realizar llamadas API a nuestro servicio desde cualquier lugar.
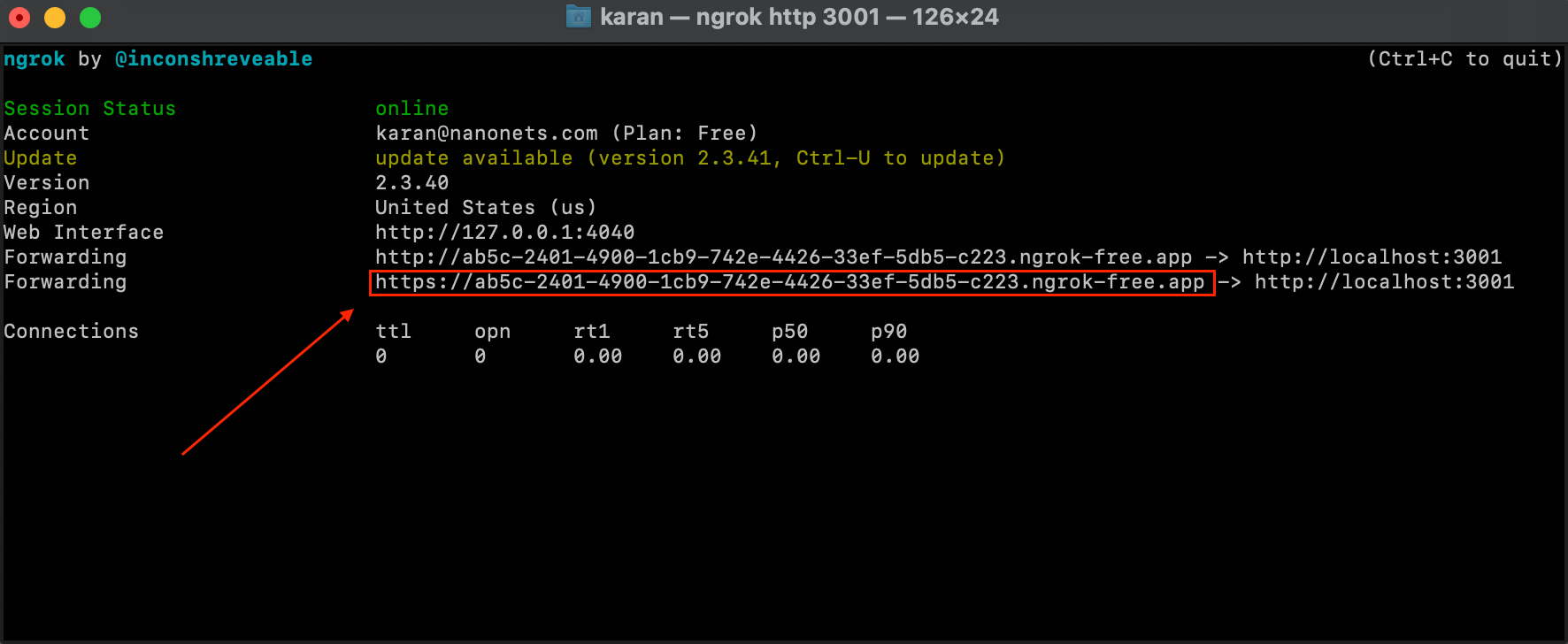
- Luego configuramos un Webhook de Zendesk, ya sea visitando el siguiente enlace: https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/webhooks/webhooks O ejecutando directamente el siguiente código en nuestro cuaderno Jupyter original.
NOTA: Es importante tener en cuenta que, si bien el uso de ngrok es bueno para fines de prueba, se recomienda encarecidamente cambiar el servicio Flask API a una instancia de servidor. En ese caso, la IP estática del servidor se convierte en el punto final de Zendesk Webhook y deberá configurar el punto final en su Zendesk Webhook para que apunte hacia esta dirección: https://YOUR_SERVER_STATIC_IP:3001/zendesk
zendesk_workflow_endpoint = "HTTPS_NGROK_FORWARDING_ADDRESS" url = "https://" + subdomain + ".zendesk.com/api/v2/webhooks"
payload = { "webhook": { "endpoint": zendesk_workflow_endpoint, "http_method": "POST", "name": "Nanonets Workflows Webhook v1", "status": "active", "request_format": "json", "subscriptions": ["conditional_ticket_events"], }
}
headers = {"Content-Type": "application/json"} auth = (username, password) response = requests.post(url, json=payload, headers=headers, auth=auth)
webhook = response.json() webhookid = webhook["webhook"]["id"]
- Ahora configuramos un activador de Zendesk, que activará el webhook anterior que acabamos de crear para que se ejecute cada vez que aparezca un ticket nuevo. Podemos configurar el activador de Zendesk visitando el siguiente enlace: https://YOUR_SUBDOMAIN.zendesk.com/admin/objects-rules/rules/triggers O ejecutando directamente el siguiente código en nuestro cuaderno Jupyter original.
url = "https://" + subdomain + ".zendesk.com/api/v2/triggers.json" trigger_payload = { "trigger": { "title": "Nanonets Workflows Trigger v1", "active": True, "conditions": {"all": [{"field": "update_type", "value": "Create"}]}, "actions": [ { "field": "notification_webhook", "value": [ webhookid, json.dumps( { "ticket_id": "{{ticket.id}}", "org_id": "{{ticket.url}}", "subject": "{{ticket.title}}", "body": "{{ticket.description}}", } ), ], } ], }
} response = requests.post(url, auth=(username, password), json=trigger_payload)
trigger = response.json()
- Recuperar información relevante: Cuando llegue un ticket nuevo, utilice la base de conocimientos indexada para recuperar información relevante y tickets anteriores que puedan ayudar a generar una respuesta.
Una vez configurados el activador y el webhook, Zendesk se asegurará de que nuestro servicio Flask que se ejecuta actualmente reciba una llamada API en la ruta /zendesk con el ID, el asunto y el cuerpo del ticket cada vez que llegue un nuevo ticket.
Ahora tenemos que configurar nuestro Flask Service para
a. genere una respuesta utilizando nuestra tienda de vectores 'zendesk-index'.
b. actualizar el ticket con la respuesta generada.
Reemplazamos nuestro código de servicio de matraz actual en zendesk.py con el siguiente código:
from flask import Flask, request, jsonify
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson['body'] zendb = FAISS.load_local('zendesk-index', zenembeddings) docs = zendb.similarity_search(query) if __name__ == '__main__': app.run(port=3001, debug=True)Como puede ver, realizamos una búsqueda de similitudes en nuestro índice de vectores y recuperamos los tickets y artículos más relevantes para ayudar a generar una respuesta.
Cómo generar una respuesta y publicarla en Zendesk
- Generar respuesta: Utilice el LLM para generar una respuesta coherente y precisa basada en la información recuperada y el contexto analizado.
Sigamos ahora configurando nuestro punto final API. Modificamos aún más el código como se muestra a continuación para generar una respuesta basada en la información relevante recuperada.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query)
El https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be La variable contendrá la respuesta generada.
- Respuesta de revisión: Opcionalmente, haga que un agente humano revise la respuesta generada para verificar su precisión y adecuación antes de publicarla.
La forma en que garantizamos esto es NO publicar la respuesta generada por GPT directamente como respuesta de Zendesk. En su lugar, crearemos una función para actualizar nuevos tickets con una nota interna que contenga la respuesta generada por GPT.
Agregue la siguiente función al servicio flask de zendesk.py:
def update_ticket_with_internal_note( subdomain, ticket_id, username, password, comment_body
): url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticket_id}.json" email = username headers = {"Content-Type": "application/json"} comment_body = "Suggested Response - " + comment_body data = {"ticket": {"comment": {"body": comment_body, "public": False}}} response = requests.put(url, json=data, headers=headers, auth=(email, password))
- Publicar en Zendesk: Utilice la API de Zendesk para publicar la respuesta generada en el ticket correspondiente, asegurando una comunicación oportuna con el cliente.
Incorporemos ahora la función de creación de notas internas en nuestro punto final API.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query) update_ticket_with_internal_note(subdomain, ticket, username, password, answer) return answer
¡Esto completa nuestro flujo de trabajo!
Revisemos el flujo de trabajo que hemos configurado:
- Nuestro Zendesk Trigger inicia el flujo de trabajo cuando aparece un nuevo ticket de Zendesk.
- El disparador envía los datos del nuevo ticket a nuestro Webhook.
- Nuestro Webhook envía una solicitud a nuestro Servicio Flask.
- Nuestro servicio Flask consulta el almacén de vectores creado con datos anteriores de Zendesk para recuperar tickets y artículos anteriores relevantes para responder al nuevo ticket.
- Los tickets y artículos anteriores relevantes se pasan a GPT junto con los datos del ticket nuevo para generar una respuesta.
- El nuevo ticket se actualiza con una nota interna que contiene la respuesta generada por GPT.
Podemos probar esto manualmente –
- Creamos un ticket en Zendesk manualmente para probar el flujo.
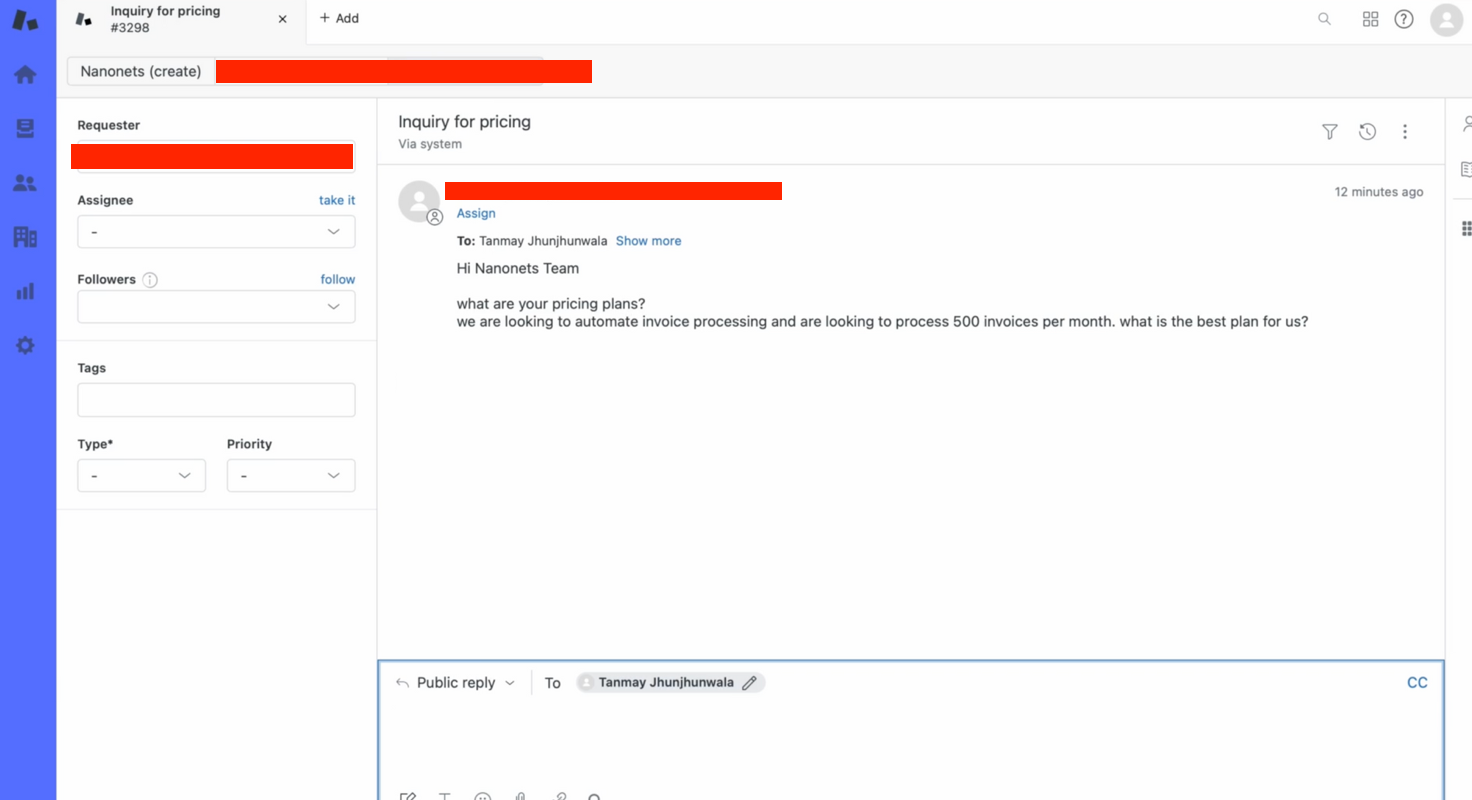
- ¡En cuestión de segundos, nuestro bot proporciona una respuesta relevante a la consulta del ticket!

Cómo hacer todo este flujo de trabajo con Nanonets
Nanonets ofrece una poderosa plataforma para implementar y administrar flujos de trabajo basados en RAG sin problemas. Así es como puede aprovechar las Nanonets para este flujo de trabajo:
- Integrar con Zendesk: Conecte Nanonets con Zendesk para monitorear y recuperar tickets de manera eficiente.
- Construir y entrenar modelos: Utilice Nanonets para crear y capacitar LLM para generar respuestas precisas y coherentes basadas en la base de conocimientos y el contexto analizado.
- Automatizar respuestas: Configure reglas de automatización en Nanonets para publicar automáticamente las respuestas generadas en Zendesk o reenviarlas a agentes humanos para su revisión.
- Supervisar y optimizar: Supervise continuamente el rendimiento del flujo de trabajo y optimice los modelos y reglas para mejorar la precisión y la eficiencia.
Al integrar los LLM con flujos de trabajo basados en RAG en GenAI y aprovechar las capacidades de Nanonets, las empresas pueden mejorar significativamente sus operaciones de atención al cliente, brindando respuestas rápidas y precisas a las consultas de los clientes en Zendesk.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://nanonets.com/blog/build-your-own-zendesk-answer-bot-with-llms/

