Esta publicación invitada está coescrita por Lydia Lihui Zhang, especialista en desarrollo empresarial, y Mansi Shah, ingeniera de software/científica de datos, en Planet Labs. El análisis que inspiró esta publicación Fue escrito originalmente por Jennifer Reiber Kyle.
Capacidades geoespaciales de Amazon SageMaker combinado con PlanetaLos datos satelitales de Se pueden utilizar para la segmentación de cultivos, y existen numerosas aplicaciones y beneficios potenciales de este análisis en los campos de la agricultura y la sostenibilidad. A finales de 2023, Planeta anunció una asociación con AWS para que sus datos geoespaciales estén disponibles a través Amazon SageMaker.
La segmentación de cultivos es el proceso de dividir una imagen de satélite en regiones de píxeles o segmentos que tienen características de cultivo similares. En esta publicación, ilustramos cómo utilizar un modelo de aprendizaje automático (ML) de segmentación para identificar regiones recortadas y no recortadas en una imagen.
La identificación de regiones de cultivo es un paso fundamental para obtener conocimientos agrícolas, y la combinación de datos geoespaciales ricos y aprendizaje automático puede conducir a conocimientos que impulsen decisiones y acciones. Por ejemplo:
- Tomar decisiones agrícolas basadas en datos – Al obtener una mejor comprensión espacial de los cultivos, los agricultores y otras partes interesadas agrícolas pueden optimizar el uso de los recursos, desde el agua hasta los fertilizantes y otros productos químicos a lo largo de la temporada. Esto sienta las bases para reducir el desperdicio, mejorar las prácticas agrícolas sostenibles siempre que sea posible y aumentar la productividad minimizando al mismo tiempo el impacto ambiental.
- Identificar tensiones y tendencias relacionadas con el clima – A medida que el cambio climático continúa afectando los patrones globales de temperatura y precipitaciones, la segmentación de cultivos puede usarse para identificar áreas que son vulnerables al estrés relacionado con el clima para las estrategias de adaptación climática. Por ejemplo, los archivos de imágenes satelitales se pueden utilizar para rastrear los cambios en una región de cultivo a lo largo del tiempo. Estos podrían ser los cambios físicos en el tamaño y la distribución de las tierras de cultivo. También podrían ser los cambios en la humedad del suelo, la temperatura del suelo y la biomasa, derivados de los diferentes índices espectrales de los datos satelitales, para un análisis más profundo de la salud de los cultivos.
- Evaluación y mitigación de daños – Por último, la segmentación de cultivos se puede utilizar para identificar de forma rápida y precisa áreas de daños a los cultivos en caso de un desastre natural, lo que puede ayudar a priorizar los esfuerzos de socorro. Por ejemplo, después de una inundación, se pueden utilizar imágenes satelitales de alta cadencia para identificar áreas donde los cultivos han quedado sumergidos o destruidos, lo que permite a las organizaciones de ayuda ayudar a los agricultores afectados más rápidamente.
En este análisis, utilizamos un modelo de K vecinos más cercanos (KNN) para realizar la segmentación de cultivos y comparamos estos resultados con imágenes reales sobre el terreno en una región agrícola. Nuestros resultados revelan que la clasificación del modelo KNN es representativa con mayor precisión del estado del campo de cultivo actual en 2017 que los datos de clasificación reales de 2015. Estos resultados son un testimonio del poder de las imágenes geoespaciales de alta cadencia de Planet. Los campos agrícolas cambian con frecuencia, a veces varias veces por temporada, y tener imágenes satelitales de alta frecuencia disponibles para observar y analizar esta tierra puede proporcionar un valor inmenso a nuestra comprensión de las tierras agrícolas y los entornos que cambian rápidamente.
Asociación de Planet y AWS en aprendizaje automático geoespacial
Capacidades geoespaciales de SageMaker capacite a los científicos de datos y a los ingenieros de aprendizaje automático para que creen, entrenen e implementen modelos utilizando datos geoespaciales. Las capacidades geoespaciales de SageMaker le permiten transformar o enriquecer de manera eficiente conjuntos de datos geoespaciales a gran escala, acelerar la creación de modelos con modelos de aprendizaje automático previamente entrenados y explorar predicciones de modelos y datos geoespaciales en un mapa interactivo utilizando gráficos acelerados en 3D y herramientas de visualización integradas. Con las capacidades geoespaciales de SageMaker, puede procesar grandes conjuntos de datos de imágenes satelitales y otros datos geoespaciales para crear modelos de aprendizaje automático precisos para diversas aplicaciones, incluida la segmentación de cultivos, que analizamos en esta publicación.
Laboratorios Planet PBC es una empresa líder en imágenes de la Tierra que utiliza su gran flota de satélites para capturar imágenes de la superficie de la Tierra a diario. Por lo tanto, los datos del planeta son un recurso valioso para el aprendizaje automático geoespacial. Sus imágenes satelitales de alta resolución se pueden utilizar para identificar diversas características de los cultivos y su salud a lo largo del tiempo, en cualquier lugar de la Tierra.
La asociación entre Planet y SageMaker permite a los clientes acceder y analizar fácilmente los datos satelitales de alta frecuencia de Planet utilizando las potentes herramientas de aprendizaje automático de AWS. Los científicos de datos pueden traer sus propios datos o buscar y suscribirse cómodamente a los datos de Planet sin cambiar de entorno.
Segmentación de cultivos en un cuaderno de Amazon SageMaker Studio con una imagen geoespacial
En este ejemplo de flujo de trabajo de aprendizaje automático geoespacial, analizamos cómo incorporar los datos de Planet junto con la fuente de datos reales a SageMaker y cómo entrenar, inferir e implementar un modelo de segmentación de cultivos con un clasificador KNN. Finalmente, evaluamos la precisión de nuestros resultados y la comparamos con nuestra clasificación de verdad básica.
El clasificador KNN utilizado fue entrenado en un Cuaderno Amazon SageMaker Studio con tecnología geoespacial imagen y proporciona un núcleo de cuaderno flexible y extensible para trabajar con datos geoespaciales.
La Estudio Amazon SageMaker El cuaderno con imagen geoespacial viene preinstalado con bibliotecas geoespaciales de uso común, como GDAL, Fiona, GeoPandas, Shapely y Rasterio, que permiten la visualización y el procesamiento de datos geoespaciales directamente dentro de un entorno de cuaderno Python. Las bibliotecas de aprendizaje automático comunes, como OpenCV o scikit-learn, también se utilizan para realizar la segmentación de cultivos mediante la clasificación KNN, y también se instalan en el kernel geoespacial.
Selección de datos
El campo agrícola que analizamos se encuentra en el generalmente soleado condado de Sacramento en California.
¿Por qué Sacramento? La selección de área y tiempo para este tipo de problema se define principalmente por la disponibilidad de datos reales sobre el terreno, y dichos datos sobre el tipo de cultivo y los datos de límites no son fáciles de conseguir. El Conjunto de datos de la encuesta DWR sobre el uso de la tierra del condado de Sacramento de 2015 es un conjunto de datos disponible públicamente que cubre el condado de Sacramento en ese año y proporciona límites ajustados manualmente.
La principal imagen de satélite que utilizamos es la de 4 bandas del planeta. Producto PSScene, que contiene las bandas Azul, Verde, Roja e IR cercano y está corregido radiométricamente según la radiancia en el sensor. Los coeficientes para corregir la reflectancia en el sensor se proporcionan en los metadatos de la escena, lo que mejora aún más la coherencia entre las imágenes tomadas en diferentes momentos.
Los satélites Dove de Planet que produjeron estas imágenes fueron lanzados el 14 de febrero de 2017 (comunicado de prensa), por lo tanto, no tomaron imágenes del condado de Sacramento en 2015. Sin embargo, han estado tomando imágenes diarias del área desde el lanzamiento. En este ejemplo, nos conformamos con la brecha imperfecta de dos años entre los datos reales del terreno y las imágenes satelitales. Sin embargo, las imágenes de menor resolución del Landsat 2 podrían haberse utilizado como puente entre 8 y 2015.
Acceder a los datos del Planeta
Para ayudar a los usuarios a obtener datos precisos y procesables más rápidamente, Planet también ha desarrollado el kit de desarrollo de software (SDK) Planet para Python. Esta es una herramienta poderosa para científicos y desarrolladores de datos que desean trabajar con imágenes satelitales y otros datos geoespaciales. Con este SDK, puedes buscar y acceder a la amplia colección de imágenes satelitales de alta resolución de Planet, así como a datos de otras fuentes como OpenStreetMap. El SDK proporciona un cliente Python para las API de Planet, así como una solución de interfaz de línea de comandos (CLI) sin código, lo que facilita la incorporación de imágenes satelitales y datos geoespaciales en los flujos de trabajo de Python. Este ejemplo utiliza el cliente Python para identificar y descargar las imágenes necesarias para el análisis.
Puede instalar el cliente Planet Python en el cuaderno de SageMaker Studio con imagen geoespacial usando un comando simple:
Puede utilizar el cliente para consultar imágenes satelitales relevantes y recuperar una lista de resultados disponibles según el área de interés, el rango de tiempo y otros criterios de búsqueda. En el siguiente ejemplo, comenzamos preguntando cuántos Escenas PlanetScope (Las imágenes diarias del planeta) cubren la misma área de interés (AOI) que definimos anteriormente a través de los datos terrestres en Sacramento, dado un cierto rango de tiempo entre el 1 de junio y el 1 de octubre de 2017; así como un cierto rango máximo deseado de cobertura de nubes del 10%:
Los resultados devueltos muestran la cantidad de escenas coincidentes que se superponen con nuestra área de interés. También contiene los metadatos de cada escena, su ID de imagen y una referencia de imagen de vista previa.
Después de seleccionar una escena en particular, con la especificación del ID de la escena, el tipo de artículo y los paquetes de productos (documentación de referencia), puedes utilizar el siguiente código para descargar la imagen y sus metadatos:
Este código descarga la imagen de satélite correspondiente al Sistema de archivos elástico de Amazon (Amazon EFS) volumen para SageMaker Studio.
Entrenamiento modelo
Una vez descargados los datos con el cliente Planet Python, se puede entrenar el modelo de segmentación. En este ejemplo, se utiliza una combinación de técnicas de clasificación KNN y segmentación de imágenes para identificar el área de cultivo y crear características geojson georreferenciadas.
Los datos de Planet se cargan y preprocesan utilizando las bibliotecas y herramientas geoespaciales integradas en SageMaker para prepararlos para entrenar el clasificador KNN. Los datos reales para el entrenamiento son el conjunto de datos de la Encuesta DWR de uso de la tierra del condado de Sacramento de 2015, y los datos de Planet de 2017 se utilizan para probar el modelo.
Convierta características reales del terreno en contornos
Para entrenar el clasificador KNN, la clase de cada píxel como crop or non-crop necesita ser identificado. La clase está determinada por si el píxel está asociado con una característica de recorte en los datos reales del terreno o no. Para hacer esta determinación, los datos reales del terreno primero se convierten en contornos OpenCV, que luego se usan para separar crop Desde non-crop píxeles. Luego, los valores de píxeles y su clasificación se utilizan para entrenar el clasificador KNN.
Para convertir las características reales del terreno en contornos, las características primero deben proyectarse al sistema de referencia de coordenadas de la imagen. Luego, las características se transforman en espacio de imagen y finalmente se convierten en contornos. Para garantizar la precisión de los contornos, se visualizan superpuestos en la imagen de entrada, como se muestra en el siguiente ejemplo.
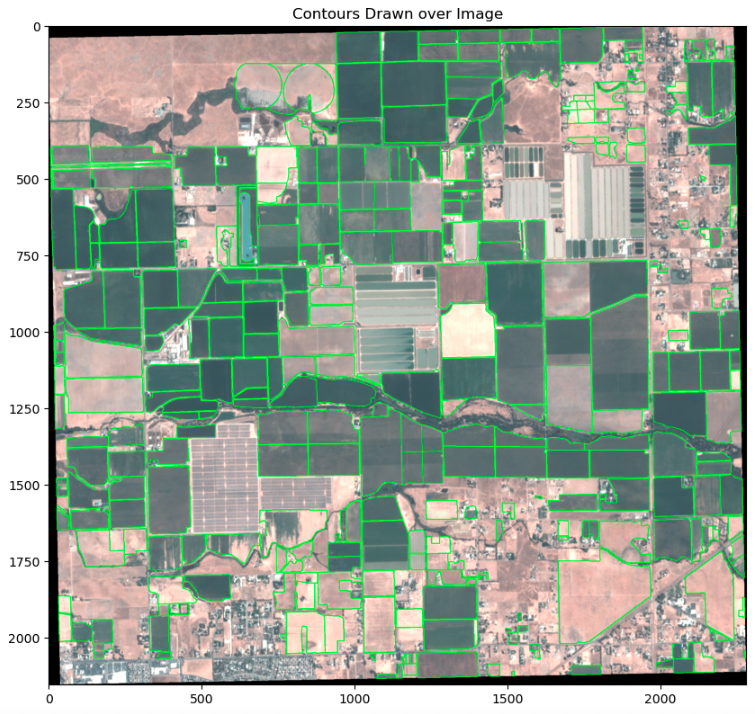
Para entrenar el clasificador KNN, los píxeles recortados y no recortados se separan utilizando los contornos de la entidad de recorte como máscara.

La entrada del clasificador KNN consta de dos conjuntos de datos: X, una matriz 2D que proporciona las características que se van a clasificar; e y, una matriz 1d que proporciona las clases (ejemplo). Aquí, se crea una única banda clasificada a partir de los conjuntos de datos de cultivos y sin cultivos, donde los valores de la banda indican la clase de píxel. Los valores de banda y de banda de píxeles de la imagen subyacente se convierten luego en las entradas X e y para la función de ajuste del clasificador.

Entrene al clasificador en píxeles recortados y no recortados
La clasificación KNN se realiza con el scikit-learn KNeighborsClassifier. El número de vecinos, un parámetro que afecta en gran medida el rendimiento del estimador, se ajusta mediante validación cruzada en la validación cruzada de KNN. Luego, el clasificador se entrena utilizando los conjuntos de datos preparados y el número ajustado de parámetros vecinos. Vea el siguiente código:
Para evaluar el rendimiento del clasificador en sus datos de entrada, la clase de píxel se predice utilizando los valores de la banda de píxeles. El rendimiento del clasificador se basa principalmente en la precisión de los datos de entrenamiento y la clara separación de las clases de píxeles en función de los datos de entrada (valores de bandas de píxeles). Los parámetros del clasificador, como el número de vecinos y la función de ponderación de distancia, se pueden ajustar para compensar cualquier imprecisión en esta última. Vea el siguiente código:
Evaluar las predicciones del modelo.
El clasificador KNN entrenado se utiliza para predecir regiones de cultivo en los datos de prueba. Estos datos de prueba constan de regiones que no estuvieron expuestas al modelo durante el entrenamiento. En otras palabras, el modelo no tiene conocimiento del área antes de su análisis y por lo tanto estos datos pueden usarse para evaluar objetivamente el desempeño del modelo. Comenzamos inspeccionando visualmente varias regiones, comenzando con una región que es comparativamente más ruidosa.

La inspección visual revela que las clases predichas son en su mayoría consistentes con las clases reales. Hay algunas zonas de desviación que examinamos más a fondo.

Tras una mayor investigación, descubrimos que parte del ruido en esta región se debía a que los datos reales carecían del detalle que está presente en la imagen clasificada (arriba a la derecha en comparación con la parte superior izquierda y la parte inferior izquierda). Un hallazgo particularmente interesante es que el clasificador identifica los árboles a lo largo del río como non-crop, mientras que los datos reales los identifican erróneamente como crop. Esta diferencia entre estas dos segmentaciones puede deberse a que los árboles dan sombra a la región sobre los cultivos.
Después de esto, inspeccionamos otra región que se clasificó de manera diferente entre los dos métodos. Estas regiones resaltadas se marcaron previamente como regiones sin cultivo en los datos reales del terreno en 2015 (arriba a la derecha), pero cambiaron y se muestran claramente como tierras de cultivo en 2017 a través de las escenas de Planetscope (arriba a la izquierda y abajo a la izquierda). También se clasificaron en gran medida como tierras de cultivo mediante el clasificador (abajo a la derecha).

Nuevamente, vemos que el clasificador KNN presenta un resultado más granular que la clase de verdad básica y también captura con éxito el cambio que ocurre en las tierras de cultivo. Este ejemplo también habla del valor de los datos satelitales actualizados diariamente porque el mundo a menudo cambia mucho más rápido que los informes anuales, y un método combinado con ML como este puede ayudarnos a detectar los cambios a medida que ocurren. Ser capaz de monitorear y descubrir dichos cambios a través de datos satelitales, especialmente en los campos agrícolas en evolución, proporciona información útil para que los agricultores optimicen su trabajo y para que cualquier actor agrícola en la cadena de valor obtenga un mejor pulso de la temporada.
Evaluación modelo
La comparación visual de las imágenes de las clases predichas con las clases reales puede ser subjetiva y no puede generalizarse para evaluar la precisión de los resultados de la clasificación. Para obtener una evaluación cuantitativa, obtenemos métricas de clasificación utilizando scikit-learn. classification_report función:
La clasificación de píxeles se utiliza para crear una máscara de segmentación de regiones de recorte, lo que hace que tanto la precisión como la recuperación sean métricas importantes, y la puntuación F1 es una buena medida general para predecir la precisión. Nuestros resultados nos brindan métricas para regiones con y sin cultivos en el conjunto de datos de entrenamiento y prueba. Sin embargo, para simplificar las cosas, echemos un vistazo más de cerca a estas métricas en el contexto de las regiones de cultivo en el conjunto de datos de prueba.
La precisión es una medida de cuán precisas son las predicciones positivas de nuestro modelo. En este caso, una precisión de 0.94 para las regiones de cultivo indica que nuestro modelo tiene mucho éxito a la hora de identificar correctamente áreas que en realidad son regiones de cultivo, donde se minimizan los falsos positivos (regiones reales que no son de cultivo identificadas incorrectamente como regiones de cultivo). La recuperación, por otro lado, mide la integridad de las predicciones positivas. En otras palabras, el recuerdo mide la proporción de positivos reales que se identificaron correctamente. En nuestro caso, un valor de recuperación de 0.73 para las regiones de cultivo significa que el 73% de todos los píxeles reales de la región de cultivo se identifican correctamente, lo que minimiza la cantidad de falsos negativos.
Idealmente, se prefieren valores altos tanto de precisión como de recuperación, aunque esto puede depender en gran medida de la aplicación del estudio de caso. Por ejemplo, si estuviéramos examinando estos resultados para agricultores que buscan identificar regiones de cultivo para la agricultura, querríamos dar preferencia a un mayor recuerdo que a la precisión, para minimizar el número de falsos negativos (áreas identificadas como regiones sin cultivo que son en realidad regiones de cultivo) para aprovechar al máximo la tierra. La puntuación F1 sirve como una métrica de precisión general que combina precisión y recuperación, y mide el equilibrio entre las dos métricas. Una puntuación F1 alta, como la nuestra para las regiones de cultivo (0.82), indica un buen equilibrio entre precisión y recuperación y una alta precisión de clasificación general. Aunque la puntuación F1 cae entre los conjuntos de datos del tren y de prueba, esto es de esperarse porque el clasificador fue entrenado en el conjunto de datos del tren. Una puntuación F1 promedio ponderada general de 0.77 es prometedora y lo suficientemente adecuada como para probar esquemas de segmentación de los datos clasificados.
Crea una máscara de segmentación a partir del clasificador.
La creación de una máscara de segmentación utilizando las predicciones del clasificador KNN en el conjunto de datos de prueba implica limpiar la salida predicha para evitar pequeños segmentos causados por el ruido de la imagen. Para eliminar el ruido moteado, utilizamos OpenCV. filtro de desenfoque mediano. Este filtro preserva mejor la delimitación de caminos entre cultivos que el funcionamiento morfológico abierto.

Para aplicar la segmentación binaria a la salida sin ruido, primero debemos convertir los datos ráster clasificados en características vectoriales usando OpenCV. encontrarContornos función.

Finalmente, las regiones de cultivos segmentadas reales se pueden calcular utilizando los contornos de cultivos segmentados.

Las regiones de cultivos segmentadas producidas a partir del clasificador KNN permiten una identificación precisa de las regiones de cultivos en el conjunto de datos de prueba. Estas regiones segmentadas se pueden utilizar para diversos fines, como identificación de límites de campo, seguimiento de cultivos, estimación de rendimiento y asignación de recursos. La puntuación F1 obtenida de 0.77 es buena y proporciona evidencia de que el clasificador KNN es una herramienta eficaz para la segmentación de cultivos en imágenes de teledetección. Estos resultados se pueden utilizar para mejorar y perfeccionar aún más las técnicas de segmentación de cultivos, lo que podría conducir a una mayor precisión y eficiencia en el análisis de cultivos.
Conclusión
Esta publicación demostró cómo puedes usar la combinación de del planeta alta cadencia, imágenes satelitales de alta resolución y Capacidades geoespaciales de SageMaker para realizar análisis de segmentación de cultivos, desbloqueando conocimientos valiosos que pueden mejorar la eficiencia agrícola, la sostenibilidad ambiental y la seguridad alimentaria. La identificación precisa de las regiones de cultivo permite realizar más análisis sobre el crecimiento y la productividad de los cultivos, monitorear los cambios en el uso de la tierra y detectar posibles riesgos para la seguridad alimentaria.
Además, la combinación de datos de Planet y SageMaker ofrece una amplia gama de casos de uso más allá de la segmentación de cultivos. Los conocimientos pueden permitir decisiones basadas en datos sobre el manejo de cultivos, la asignación de recursos y la planificación de políticas solo en la agricultura. Con diferentes modelos de datos y aprendizaje automático, la oferta combinada también podría expandirse a otras industrias y casos de uso hacia la transformación digital, la transformación de la sostenibilidad y la seguridad.
Para comenzar a utilizar las capacidades geoespaciales de SageMaker, consulte Comience a utilizar las capacidades geoespaciales de Amazon SageMaker.
Para obtener más información sobre las especificaciones de imágenes de Planet y los materiales de referencia para desarrolladores, visite Centro de desarrolladores de planetas. Para obtener documentación sobre el SDK de Planet para Python, consulte Planeta SDK para Python. Para obtener más información sobre Planet, incluidos sus productos de datos existentes y los próximos lanzamientos de productos, visite https://www.planet.com/.
Declaraciones prospectivas de Planet Labs PBC
Excepto por la información histórica contenida en este documento, los asuntos establecidos en esta publicación de blog son declaraciones prospectivas dentro del significado de las disposiciones de "puerto seguro" de la Ley de Reforma de Litigios sobre Valores Privados de 1995, que incluyen, entre otras, Planet Labs. La capacidad de PBC para capturar oportunidades de mercado y obtener cualquiera de los beneficios potenciales de mejoras de productos actuales o futuras, nuevos productos o asociaciones estratégicas y colaboraciones con clientes. Las declaraciones a futuro se basan en las creencias de la administración de Planet Labs PBC, así como en las suposiciones hechas por ellos y en la información actualmente disponible para ellos. Debido a que dichas declaraciones se basan en expectativas sobre eventos y resultados futuros y no son declaraciones de hechos, los resultados reales pueden diferir materialmente de los proyectados. Los factores que pueden causar que los resultados reales difieran materialmente de las expectativas actuales incluyen, entre otros, los factores de riesgo y otras divulgaciones sobre Planet Labs PBC y su negocio incluidas en los informes periódicos, declaraciones de poder y otros materiales de divulgación de Planet Labs PBC presentados de vez en cuando. periódicamente con la Comisión de Bolsa y Valores (SEC), que están disponibles en línea en www.sec.govy en el sitio web de Planet Labs PBC en www.planet.com. Todas las declaraciones prospectivas reflejan las creencias y suposiciones de Planet Labs PBC únicamente a partir de la fecha en que se realizan dichas declaraciones. Planet Labs PBC no asume ninguna obligación de actualizar las declaraciones prospectivas para reflejar eventos o circunstancias futuros.
Sobre los autores
 Lydia Lihui Zhang es especialista en desarrollo empresarial en Planet Labs PBC, donde ayuda a conectar el espacio para el mejoramiento de la Tierra en varios sectores y una gran variedad de casos de uso. Anteriormente, fue científica de datos en McKinsey ACRE, una solución centrada en la agricultura. Tiene una Maestría en Ciencias del Programa de Política Tecnológica del MIT, centrándose en la política espacial. Los datos geoespaciales y su impacto más amplio en los negocios y la sostenibilidad han sido el enfoque de su carrera.
Lydia Lihui Zhang es especialista en desarrollo empresarial en Planet Labs PBC, donde ayuda a conectar el espacio para el mejoramiento de la Tierra en varios sectores y una gran variedad de casos de uso. Anteriormente, fue científica de datos en McKinsey ACRE, una solución centrada en la agricultura. Tiene una Maestría en Ciencias del Programa de Política Tecnológica del MIT, centrándose en la política espacial. Los datos geoespaciales y su impacto más amplio en los negocios y la sostenibilidad han sido el enfoque de su carrera.
 mansi shah es un ingeniero de software, científico de datos y músico cuyo trabajo explora los espacios donde chocan el rigor artístico y la curiosidad técnica. Ella cree que los datos (¡como el arte!) imitan la vida y está interesada en las historias profundamente humanas detrás de los números y las notas.
mansi shah es un ingeniero de software, científico de datos y músico cuyo trabajo explora los espacios donde chocan el rigor artístico y la curiosidad técnica. Ella cree que los datos (¡como el arte!) imitan la vida y está interesada en las historias profundamente humanas detrás de los números y las notas.
 xiong zhou es científico aplicado sénior en AWS. Dirige el equipo científico de capacidades geoespaciales de Amazon SageMaker. Su área actual de investigación incluye visión por computadora y entrenamiento de modelos eficientes. En su tiempo libre le gusta correr, jugar baloncesto y pasar tiempo con su familia.
xiong zhou es científico aplicado sénior en AWS. Dirige el equipo científico de capacidades geoespaciales de Amazon SageMaker. Su área actual de investigación incluye visión por computadora y entrenamiento de modelos eficientes. En su tiempo libre le gusta correr, jugar baloncesto y pasar tiempo con su familia.
 Janosch Woschitz es arquitecto senior de soluciones en AWS, especializado en IA/ML geoespacial. Con más de 15 años de experiencia, apoya a clientes de todo el mundo a aprovechar la IA y el aprendizaje automático para soluciones innovadoras que aprovechan los datos geoespaciales. Su experiencia abarca el aprendizaje automático, la ingeniería de datos y los sistemas distribuidos escalables, complementados con una sólida experiencia en ingeniería de software y experiencia en la industria en dominios complejos como la conducción autónoma.
Janosch Woschitz es arquitecto senior de soluciones en AWS, especializado en IA/ML geoespacial. Con más de 15 años de experiencia, apoya a clientes de todo el mundo a aprovechar la IA y el aprendizaje automático para soluciones innovadoras que aprovechan los datos geoespaciales. Su experiencia abarca el aprendizaje automático, la ingeniería de datos y los sistemas distribuidos escalables, complementados con una sólida experiencia en ingeniería de software y experiencia en la industria en dominios complejos como la conducción autónoma.
 Shital Dhakal es gerente sénior de programas del equipo de aprendizaje automático geoespacial de SageMaker con sede en el Área de la Bahía de San Francisco. Tiene experiencia en teledetección y Sistemas de Información Geográfica (SIG). Le apasiona comprender los puntos débiles de los clientes y crear productos geoespaciales para resolverlos. En su tiempo libre le gusta hacer senderismo, viajar y jugar tenis.
Shital Dhakal es gerente sénior de programas del equipo de aprendizaje automático geoespacial de SageMaker con sede en el Área de la Bahía de San Francisco. Tiene experiencia en teledetección y Sistemas de Información Geográfica (SIG). Le apasiona comprender los puntos débiles de los clientes y crear productos geoespaciales para resolverlos. En su tiempo libre le gusta hacer senderismo, viajar y jugar tenis.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/build-a-crop-segmentation-machine-learning-model-with-planet-data-and-amazon-sagemaker-geospatial-capabilities/

