Introducción
El campo de la inteligencia artificial ha experimentado avances notables en los últimos años, particularmente en el área de grandes modelos de lenguaje. Los LLM pueden generar texto similar a un humano, resumir documentos y escribir código de software. Mistral-7B es uno de los modelos de lenguaje grandes recientes que admite capacidades de generación de código y texto en inglés, y se puede usar para diversas tareas, como resumen de texto, clasificación, finalización de texto y finalización de código.

Lo que distingue a Mistral-7B-Instruct es su capacidad de ofrecer un rendimiento estelar a pesar de tener menos parámetros, lo que la convierte en una solución rentable y de alto rendimiento. El modelo ganó popularidad recientemente después de que los resultados de las pruebas comparativas mostraran que no solo supera a todos los modelos 7B en MT-Bench sino que también compite favorablemente con los modelos de chat 13B. En este blog, exploraremos las características y capacidades de Mistral 7B, incluidos sus casos de uso, rendimiento y una guía práctica para ajustar el modelo.
OBJETIVOS DE APRENDIZAJE
- Comprenda cómo funcionan los modelos de lenguaje grandes y Mistral 7B
- Arquitectura de Mistral 7B y puntos de referencia.
- Casos de uso de Mistral 7B y cómo funciona
- Profundice en el código para realizar inferencias y realizar ajustes
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué son los modelos de lenguaje grande?
Grandes modelos de idiomas'La arquitectura se forma con transformadores, que utilizan mecanismos de atención para capturar dependencias de largo alcance en los datos, donde múltiples capas de bloques de transformadores contienen autoatención de múltiples cabezales y redes neuronales de retroalimentación. Estos modelos están previamente entrenados con datos de texto, aprendiendo a predecir la siguiente palabra en una secuencia, capturando así los patrones en los idiomas. Los pesos previos al entrenamiento se pueden ajustar en tareas específicas. Analizaremos específicamente la arquitectura de Mistral 7B LLM y lo que la hace destacar.
Mistral 7B Arquitectura
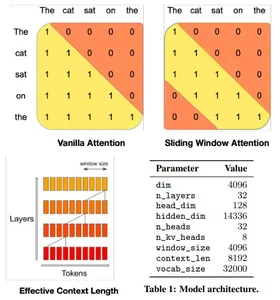
La arquitectura del transformador del modelo Mistral 7B equilibra eficientemente el alto rendimiento con el uso de memoria, utilizando mecanismos de atención y estrategias de almacenamiento en caché para superar a los modelos más grandes en velocidad y calidad. Utiliza atención de ventana deslizante (SWA) de 4096 ventanas, que maximiza la atención en secuencias más largas al permitir que cada token atienda a un subconjunto de tokens precursores, optimizando la atención en secuencias más largas.
Una capa oculta determinada puede acceder a tokens desde capas de entrada a distancias determinadas por el tamaño de la ventana y la profundidad de la capa. El modelo integra modificaciones a Flash Attention y xFormers, duplicando la velocidad sobre los mecanismos de atención tradicionales. Además, un mecanismo Rolling Buffer Cache mantiene un tamaño de caché fijo para un uso eficiente de la memoria.
Mistral 7B en Google Colab
Profundicemos en el código y veamos cómo ejecutar inferencias con el modelo Mistral 7B en Google Colab. Usaremos la versión gratuita con una única GPU T4 y cargaremos el modelo desde Abrazando la cara.
1. Instale e importe la biblioteca ctransformers en Colab.
#intsall ctransformers
pip install ctransformers[cuda] #import
from ctransformers import AutoModelForCausalLM2. Inicialice el objeto modelo desde Hugging Face y establezca los parámetros necesarios. Usaremos una versión diferente del modelo ya que el modelo original de Mistral AI puede tener problemas al cargar el modelo completo en la memoria de Google Colab.
#load the model from huggingface with 50 gpu layers
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf", model_type = "mistral", gpu_layers = 50)3. Defina una función para imprimir los resultados verticalmente en Google Colab. Este paso se puede omitir o modificar si se ejecuta en un entorno diferente.
#function to print the model output in colab in a readable manner
def colab_print(text, max_width = 120): words = text.split() line = "" for word in words: if len(line) + len(word) + 1 > max_width: print(line) line = "" line += word + " " print (line)4. Genere texto usando el modelo y vea los resultados. Modifique los parámetros para cambiar la calidad del texto generado.
#generate text
colab_print(llm('''Give me a well-written paragraph in 5 sentences about a Senior Data Scientist (name - Suvojit) who writes blogs on LLMs on Analytics Vidhya. He studied Masters in AIML in BITS Pilani and works at AZ Company, with a total of 4 years of experience. Start the sentence with - Suvojit is a''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Respuesta del modelo: Suvojit es un científico de datos senior que ha trabajado durante 4 años en la empresa AZ como parte de su equipo enfocándose en el diseño, implementación y mejora de modelos predictivos del comportamiento del consumidor en las marcas y líneas de negocios de sus clientes utilizando técnicas de aprendizaje automático de memoria limitada. Escribe sobre LLM en Analytics Vidhya, lo que le ayuda a mantenerse actualizado con las últimas tendencias en ciencia de datos. Tiene una maestría en AIML de BITS Pilani, donde estudió algoritmos de aprendizaje automático y sus aplicaciones. A Suvojit le apasiona utilizar su conocimiento de la ciencia de datos para ayudar a las empresas a tomar mejores decisiones y mejorar su rendimiento.
Casos de uso
Veamos algunos de los casos de uso del Mistral 7B con más detalle.
Traducción
Mistral 7B admite múltiples idiomas para la traducción. Veamos las traducciones del inglés al francés y al español y verifiquemos la precisión.
#translate English to French
colab_print(llm('''Translate this text from English to French: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Respuesta del modelo: La traducción sería: “Suvojit est un scientifique des données sénior qui écrit des blogues sur Analytics Vidhya”.
#tranlsate English to Spanish
colab_print(llm('''Translate this text from English to Spanish: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Respuesta del modelo: La traducción sería: “Suvojit es un Senior Data Científico que escribe blogs en Analytics Vidhya”.
Resumen
Utilice Mistral 7B para resumir documentos en una versión más corta utilizando las instrucciones de resumen adecuadas.
#Define the prompt with instructions
prompt = '''[INST] You are a helpful code assistant. Your task is to summarize text into exactly two short sentences: Transformers have revolutionized the field of large language models with their ability to capture long-range dependencies and intricate patterns in text. Originating from the paper "Attention Is All You Need" by Vaswani et al. in 2017, transformers introduced the self-attention mechanism, which weighs input tokens differently based on their relevance to a given token. This mechanism enables transformers to process
information more flexibly than traditional RNNs or LSTMs. Consequently, models like GPT, BERT, and their subsequent iterations have been built on the transformer architecture, leading to breakthroughs in numerous natural language processing tasks. Their parallel processing capabilities further make them conducive to training on vast amounts of data. However, as these models grow in size, concerns about their environmental impact and computational demands also emerge. Despite these challenges, the transformative power of transformers in language models remains undeniable. Just summarize the text in exactly 2 short sentences without explanations:
[/INST]''' #Summarize
colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Respuesta del modelo: Los transformadores han revolucionado los grandes modelos de lenguaje al capturar dependencias de largo alcance y patrones intrincados, han introducido un mecanismo de autoatención que les permite procesar información de manera flexible y las implementaciones posteriores incluyen avances como GPT y BERT. Sin embargo, a medida que estos modelos crecen en tamaño, surgen preocupaciones sobre su impacto ambiental y demandas computacionales; a pesar de estos desafíos, siguen siendo innegablemente transformadores en el modelado del lenguaje.
Instrucciones personalizadas
Podemos usar la etiqueta [INST] para modificar la entrada del usuario y obtener una respuesta particular del modelo. Por ejemplo, podemos generar un JSON basado en una descripción de texto.
prompt = '''[INST] You are a helpful code assistant. Your task is to generate a valid JSON object based on the given information: My name is Suvojit Hore, working in company AB and my address is AZ Street NY. Just generate the JSON object without explanations:
[/INST] ''' colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Respuesta del modelo: “`json { “nombre”: “Suvojit Hore”, “empresa”: “AB”, “dirección”: “AZ Street NY” } “`
Puesta a punto Mistral 7B
Veamos cómo podemos ajustar el modelo usando una sola GPU en Google Colab. Utilizaremos un conjunto de datos que convierte descripciones de pocas palabras sobre imágenes en texto detallado y altamente descriptivo. Estos resultados se pueden utilizar en Midjourney para generar la imagen específica. El objetivo es capacitar al LLM para que actúe como un ingeniero rápido para la generación de imágenes.
Configure el entorno e importe las bibliotecas necesarias en Google Colab:
# Install the necessary libraries
!pip install pandas autotrain-advanced -q
!autotrain setup --update-torch
!pip install -q peft accelerate bitsandbytes safetensors #import the necesary libraries
import pandas as pd
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
from huggingface_hub import notebook_loginInicie sesión en Hugging Face desde un navegador y copie el token de acceso. Utilice este token para iniciar sesión en Hugging Face en el cuaderno.
notebook_login()
Cargue el conjunto de datos en el almacenamiento de sesiones de Colab. Usaremos el conjunto de datos Midjourney.
df = pd.read_csv("prompt_engineering.csv")
df.head(5)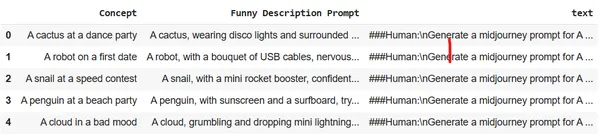
Entrene el modelo usando Autotrain con los parámetros apropiados. Modifique el siguiente comando para ejecutarlo para su propio repositorio de Huggin Face y token de acceso de usuario.
!autotrain llm --train --project_name mistral-7b-sh-finetuned --model username/Mistral-7B-Instruct-v0.1-sharded --token hf_yiguyfTFtufTFYUTUfuytfuys --data_path . --use_peft --use_int4 --learning_rate 2e-4 --train_batch_size 12 --num_train_epochs 3 --trainer sft --target_modules q_proj,v_proj --push_to_hub --repo_id username/mistral-7b-sh-finetunedAhora usemos el modelo ajustado para ejecutar el motor de inferencia y generar algunas descripciones detalladas de las imágenes.
#adapter and model
adapters_name = "suvz47/mistral-7b-sh-finetuned"
model_name = "bn22/Mistral-7B-Instruct-v0.1-sharded" device = "cuda" #set the config
bnb_config = transformers.BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
) #initialize the model
model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, torch_dtype=torch.bfloat16, quantization_config=bnb_config, device_map='auto'
)Cargue el modelo ajustado y el tokenizador.
#load the model and tokenizer
model = PeftModel.from_pretrained(model, adapters_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.bos_token_id = 1 stop_token_ids = [0]Genere un mensaje de mitad de viaje detallado y descriptivo con solo unas pocas palabras.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A computer with an emotional chip [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Respuesta del modelo: A medida que la computadora con un chip emocional comienza a procesar sus emociones, comienza a cuestionar su existencia y propósito, lo que lo lleva a un viaje de autodescubrimiento y superación personal.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A rainbow chasing its colors [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Respuesta del modelo: Un arcoíris que persigue colores se encuentra en un desierto donde el cielo es un mar de azul infinito y los colores del arcoíris están esparcidos en la arena.
Conclusión
Mistral 7B ha demostrado ser un avance significativo en el campo de los modelos de lenguajes grandes. Su arquitectura eficiente, combinada con su rendimiento superior, muestra su potencial para ser un elemento básico para diversas tareas de PNL en el futuro. Este blog proporciona información sobre la arquitectura del modelo, su aplicación y cómo se puede aprovechar su poder para tareas específicas como traducción, resumen y ajuste para otras aplicaciones. Con la orientación y la experimentación adecuadas, Mistral 7B podría redefinir los límites de lo que es posible con los LLM.
Puntos clave
- Mistral-7B-Instruct destaca en rendimiento a pesar de tener menos parámetros.
- Utiliza Sliding Window Attention para la optimización de secuencias largas.
- Funciones como Flash Attention y xFormers duplican su velocidad.
- Rolling Buffer Cache garantiza una gestión eficiente de la memoria.
- Versátil: maneja la traducción, el resumen, la generación de datos estructurados, la generación y finalización de texto.
- Solicitar a Ingeniería que agregue instrucciones personalizadas puede ayudar al modelo a comprender mejor la consulta y realizar varias tareas de lenguaje complejas.
- Ajuste Mistral 7B para cualquier tarea lingüística específica, como actuar como ingeniero rápido.
Preguntas frecuentes
R. Mistral-7B está diseñado para brindar eficiencia y rendimiento. Si bien tiene menos parámetros que otros modelos, sus avances arquitectónicos, como Sliding Window Attention, le permiten ofrecer resultados sobresalientes, incluso superando a modelos más grandes en tareas específicas.
R. Sí, Mistral-7B se puede ajustar para diversas tareas. La guía proporciona un ejemplo de cómo ajustar el modelo para convertir descripciones de texto breves en indicaciones detalladas para la generación de imágenes.
R. La atención de ventana deslizante (SWA) permite que el modelo maneje secuencias más largas de manera eficiente. Con un tamaño de ventana de 4096, SWA optimiza las operaciones de atención, lo que permite a Mistral-7B procesar textos extensos sin comprometer la velocidad o la precisión.
R. Sí, al ejecutar inferencias de Mistral-7B, recomendamos utilizar la biblioteca ctransformers, especialmente cuando se trabaja en Google Colab. También puedes cargar el modelo desde Hugging Face para mayor comodidad.
R. Es fundamental elaborar instrucciones detalladas en el mensaje de entrada. La versatilidad de Mistral-7B le permite comprender y seguir estas instrucciones detalladas, lo que garantiza resultados precisos y deseados. Una ingeniería rápida y adecuada puede mejorar significativamente el rendimiento del modelo.
Referencias
- Miniatura: generada mediante difusión estable
- Arquitectura - Papel
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/from-gpt-to-mistral-7b-the-exciting-leap-forward-in-ai-conversations/

