¿Qué es RAG?
Aquí está la definición simple de 30 segundos. Seguirá una inmersión más profunda.
RAG (Generación Aumentada de Recuperación) es la palabra más popular en GenAI en este momento, más jerga para confundir a los no iniciados.
RAG significa generación aumentada de recuperación. Simplemente significa que puede aplicar y RECUPERAR conocimientos frente al LLM, para AUMENTAR su mensaje de LLM y su respuesta. De esta manera, puede ayudar a proporcionar barreras de seguridad (más jerga) contra respuestas desactualizadas e implementar su almacén de conocimiento empresarial (privado) con seguridad.
¿Cuál es el problema que resuelve RAG?
Los modelos de lenguaje grandes – o modelos básicos (sí, hay una diferencia. Los modelos básicos incluyen modelos de lenguaje pero también otros tipos de modelos, por ejemplo, imágenes) están “preentrenados”, lo que algunos describen bellamente como loros estocásticos. Piense “preentrenados” en GPT, el modelo que impulsa ChatGPT – GPT significa “Transformador generativo preentrenado”. Preentrenado significa entrenamiento estático en un momento dado. Es por eso que cuando le preguntas al modelo "¿a qué precio se cotiza la Acción X?", no lo sabrá porque la información es demasiado nueva y, peor aún, puede que no sepa lo que no sabe, por lo que en el peor de los casos tendrá alucinaciones. Ahora, estoy exagerando un punto: ChatGPT le dirá que no conoce el precio más reciente; está capacitado para saber que la información que se solicita es demasiado inmediata y le indicará que busque otra manera. Sin embargo, el punto es que, filosóficamente hablando, los LLM no tienen límites epistemológicos. Hay muchos casos en los que no saben lo que no saben. RAG puede permitirle ajustar sus límites a los límites faltantes del LLM.
En cuanto a la jerga en torno a las interfaces humanas/tecnológicas y la conciencia, encuentro que "almacén de conocimientos" es un término particularmente interesante que se utiliza cada vez más en las conversaciones sobre GenAI. Básicamente significa una base de datos técnica o un almacén de vectores, muy probablemente una “base de datos de vectores”, pero observe cómo el término intenta llevar la humanidad (conocimiento, conocimiento en un almacén, como esos almacenes sobre los que lee en las novelas de terror de Stephen King) a un construcción técnica automatizada. Marketing y semántica subjetiva en pocas palabras.
¿Dónde está esa inmersión más profunda que prometiste?
Aquí hay un diagrama de RAG.
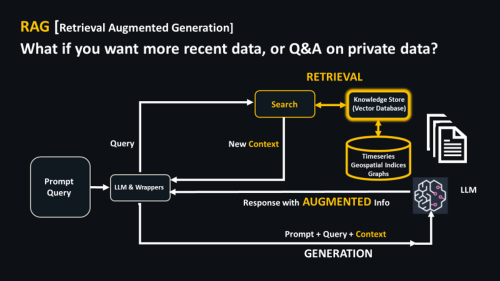
Observe el proceso secuencial, de arriba a abajo, en el diagrama. Hay dos partes clave.
- RECUPERACIÓN: Coloque un almacén de conocimiento con búsqueda (algún tipo de base de datos o almacén de vectores) frente al LLM. Cuando realiza una consulta, la base de datos vectorial ayuda a determinar si tiene información relevante, digamos información financiera actualizada que el LLM probablemente no tendrá.
- Esto informa un mensaje que AUMENTOS información adicional de VectorDB/Knowledge Store, esa parte de su empresa o la nueva información que el LLM no conoce. Junto con el "conocimiento" del LLM, contenido integral
GENERACION se devuelve.
¿Porqué ahora?
Y esa secuenciación explica en cierto modo por qué tanto revuelo. El término RAG se originó aproximadamente en 2020, creo que en
este artículo de Lewis et al. Sin embargo, hasta hace unos tres meses no formaba parte del léxico, ciertamente como lo es hoy. Mi panel de Google AdWords muestra un aumento del 900% en los últimos 3 meses y del 9900% en 3 años. Lo que probablemente sea el instigador son un par de herramientas clave en los círculos de desarrolladores de GenAI, a saber, la muy popular LangChain y los emergentes LlamaIndex. Para aquellos de ustedes con experiencia en software, piensen en estos como VS Code para GenAI. Con LangChain en particular, el nombre del producto explica el "por qué ahora", específicamente la "Cadena" de LangChain (mientras Lang = Idioma). Dada la naturaleza secuencial en forma de cadena de RAG descrita anteriormente, RAG encaja perfectamente en las herramientas del desarrollador.
¿Dónde se implementará RAG y cómo se implementará?
Como se describe, supera algunas limitaciones bastante fundamentales de los LLM y los modelos básicos, por lo que tiene una aplicabilidad bastante ubicua. Sin embargo, ya está teniendo impacto en las industrias:
- impulsado por el tiempo y en tiempo real: piense en los mercados de capitales
- regulados, porque no pueden salir mal y necesitan controles de respuesta, usaré la palabra “barandillas” para procesos empresariales en gran medida de cara al público y que impactan en riesgos. Piense en servicios legales, aplicaciones gubernamentales (el Departamento de Defensa de EE. UU. ya ha elaborado documentos y presentaciones), posiblemente atención médica.
- que requieren conocimiento empresarial (actualizado al minuto); en realidad, eso es prácticamente cualquier cosa excepto pensar en el comercio minorista y el comercio electrónico, por ejemplo.
En cualquier lugar donde se juntan los tres requisitos, piense en la división de servicios legales que ejecuta contratos actualizados al minuto en una industria de servicios financieros regulada, y ese es su punto ideal.
Aquí también es donde, según me dicen fuentes acreditadas, ya están activas las implementaciones de infraestructuras RAG, el resumen de contratos, el resumen de informes y las actividades de chatbot relacionadas. He argumentado en otros lugares a favor
Casos de uso “dorados”
esta página y cómo implementarlos de manera robusta y pegajosa esta página. Estos casos de uso de oro generalmente combinan IA generativa e IA discriminativa; en este último sentido, "discriminativa" significa la IA que se ha utilizado durante años, por ejemplo, el aprendizaje automático que determina la calificación de su tarjeta de crédito y que identifica cuando su proveedor de crédito lo llama con una sospecha. sobre el uso fraudulento de su tarjeta. En mi experiencia, esas llamadas telefónicas fraudulentas suelen ser las que recibe un sábado o domingo por la mañana cuando viaja al extranjero a algún lugar nuevo. Se está trabajando en estos casos de uso de oro y pronto llegarán a algún lugar cerca de usted, el primero simplemente con interfaces de chat sobre problemas tradicionales y de manera más avanzada con análisis incrementales implementados a través de ambos tipos de IA.
¿Qué herramientas necesito para RAG?
RAG es la nueva razón principal para implementar una base de datos vectorial, un almacén de conocimiento con capacidad de búsqueda en forma vectorial. Los vectores han existido durante años, tanto vectores matemáticos (medidas de distancia) como vectores como conjuntos de números (piense en una serie temporal diaria de una acción). Por búsqueda, piense en esos métodos de búsqueda de fuerza bruta que ha utilizado durante años, cuando busca en Google, por ejemplo. Los algoritmos de búsqueda se popularizaron gracias a
Biblioteca Apache Lucene, comúnmente implementado en herramientas como Elasticsearch y Solr, y están encontrando
una nueva vida junto con las bases de datos vectoriales o almacenes de vectores.
Utilizo el término almacenes de vectores porque, en algunos casos, no es necesario que sea una base de datos de vectores. Los vectores se pueden almacenar en cualquier lenguaje de programación matemática de alto nivel aplicable que maneje la memoria y pueda implementar la búsqueda relativamente bien (mejor, dirían algunos). Eso incluye Python/NumPy/Pandas, Julia, MATLAB, q o R, por ejemplo. Estuve en una llamada la semana pasada donde alguien aludió a su tienda de vectores Pandas casera, no una aplicación a escala industrial sino algo para iniciar un proyecto antes de migrar a una base de datos vectorial.
He estado esperando escuchar sobre Python durante algún tiempo y estar seguro de que GenAI es Pythonic (consulte el enlace LangChain arriba, por ejemplo). Los proveedores y partidarios de la programación numérica han guardado silencio cortésmente, mientras que todos los proveedores de datos han gritado a los cuatro vientos “somos una base de datos vectorial”. Rockset, en su Conferencia Index la semana pasada, anunció que ahora eran una base de datos vectorial y, junto con Rockset, el grupo de bases de datos multimodales (Datastax (Cassandra), KDB.AI, las bases de datos de gráficos, Redis Labs) ahora está comenzando a superar en número a la nueva base de datos vectorial especializada. niños: Qdrant, Pinecone, Weaviate. Para mí, la forma en que MathWorks, JuliaHub y Anaconda aborden este mercado podría definir la próxima generación de esta industria. Es mucho más fácil comenzar, al menos con una herramienta matemática multipropósito compatible con vectores que todo científico de datos conoce, y luego migrar a una potente base de datos vectorial completa.
¿RAG merece tanta publicidad?
La mayoría de las personas con las que hablo también, incluso aquellos que suelen ser escépticos con la jerga, entienden RAG. Es una forma sencilla y estándar de obtener control empresarial y actualizado al minuto de las indicaciones del modelo básico. Sospecho que no desaparecerá pronto.
Sin embargo, he empezado a ver casos en los que las empresas de Silicon Valley utilizaron la frase "reducir a RAG" o "reducir los problemas de aprendizaje automático a un problema de búsqueda". Es casi demasiado tentador arrojar cualquier cosa en un proceso de búsqueda GenAI del modelo RAG/base, pero hay casos en los que la IA tradicional funciona mejor. La blogósfera no habla de esto, pero vi a líderes de 3 líderes de alta tecnología de Silicon Valley discutir esto la semana pasada. Donde Silicon Valley discute en el circuito, los líderes bancarios discuten en privado, lejos de ojos y oídos curiosos como los míos. Es una de las razones por las que la IA discriminativa, a la que me referí antes, es importante. Las infraestructuras que aplican ambos servirán para más casos de uso que aquellas que implementan RAG de fuerza bruta. El aprendizaje automático tradicional aún no ha terminado, ni mucho menos.
También escuché el argumento de que las empresas más grandes mantendrán sus propios LLM y modelos de base para solucionar el problema de la empresa, el tiempo y la privacidad. por lo que el modelaje y la formación aún no han terminado. Resulta que esta es la razón por la que Databricks compró Mosaic. El trabajo de AWS con Bedrock y los modelos básicos de código abierto también es interesante. Al parecer, los científicos de datos podrán mantener parte del trabajo que los mantenía ocupados antes de que BigCorp entrenara los modelos más grandes para nosotros. En otras palabras, algunas partes del esfuerzo de RAG pueden ser reemplazadas por el desarrollo de modelos en las empresas más grandes, pero sospecho que esto será sólo un retroceso parcial.
Finalmente, RAG también tiene límites. Los desafíos comunes incluyen:
- tener una búsqueda de similitud eficaz,
- la capacidad de agregar/eliminar documentos
- Garantizar la veracidad y actualidad (o novedad) de los datos.
- incorporar tipos de datos clave de manera óptima, series de tiempo, información de gráficos dirigidos (relacionales), por ejemplo (aquellos de nosotros en ecosistemas de gráficos y series de tiempo vectorizados somos positivos; es una oportunidad)
Pero también están surgiendo nuevos desafíos, predominantemente en torno al rendimiento y la computación. Por ejemplo:
- fragmentar documentos antes de ingresarlos a bases de datos vectoriales (donde se necesitan documentos)
- devolver trozos adecuadamente "diversos" (aliviando el problema estocástico del loro)
- ejecutar consultas secuenciales, encadenar
- las funciones de incorporación pueden cambiar; ¿Cómo se gestionan los cambios sin volver a incorporar todas las entradas?
- El
Impactos ambientales (y geopolíticos) sobre, bueno, todo lo que tiene que ver con requisitos informáticos asombrosamente masivos.
En conclusión
RAG, como gran parte de la cháchara tecnológica de GenAI, es jerga. Sin embargo, muestra de manera sensata y clara cómo se puede agregar un nivel de control, también conocido como
recuperar información útil, para aumentar y
generar Indicaciones y resultados del modelo LLM/Foundation. Los ecosistemas y las herramientas se están desarrollando y evolucionando rápidamente en torno a la nomenclatura.
Sin embargo, todavía es temprano. ¿Cuál será el término de moda dentro de tres meses?
Sospecho que veremos una corriente de conciencia ambiental en la industria a medida que se hagan realidad los impactos de la computación y el consumo de modelos grandes, y posiblemente uno o dos conflictos internacionales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.finextra.com/blogposting/25150/from-rag-to-riches-in-a-genai-world-some-jargon-explainers-amp-current-trends?utm_medium=rssfinextra&utm_source=finextrablogs

