Aprendizaje automático no supervisado La analítica se ha convertido en una poderosa herramienta para Detección de anomalías en el panorama actual rico en datos, especialmente con el creciente volumen de datos generados por máquinas. La detección de anomalías en el flujo ofrece información en tiempo real sobre anomalías en los datos, lo que permite una respuesta proactiva. Amazon OpenSearch sin servidor se centra en ofrecer escalabilidad y gestión perfectas de cargas de trabajo de búsqueda; Ingestión de Amazon OpenSearch complementa esto proporcionando una solución sólida para la detección de anomalías en datos indexados.
En esta publicación, proporcionamos una solución que utiliza OpenSearch Ingestion que le permite realizar detección de anomalías en flujo dentro de su propio entorno de AWS.
Detección de anomalías en el flujo con OpenSearch Ingestion
OpenSearch Ingestion hace que el proceso de detección de anomalías en el flujo sea sencillo y a menor costo. La detección de anomalías en el flujo le ayuda a ahorrar en indexación y evita la necesidad de grandes recursos para manejar big data. Permite a las organizaciones aplicar los recursos adecuados en el momento adecuado, gestionar grandes cantidades de datos de manera eficiente y ahorrar dinero. El uso de reenviadores de pares y procesadores agregados puede hacer que las cosas sean más complejas y costosas; OpenSearch Ingestion reduce estos problemas.
Veamos un caso de uso que muestra una configuración YAML de OpenSearch Ingestion para la detección de anomalías en el flujo.
Resumen de la solución
En este ejemplo, analizamos la configuración de OpenSearch Ingestion utilizando un detector de anomalías de bosques cortados aleatoriamente para monitorear los recuentos de registros en un período de 5 minutos. También indexamos los registros sin procesar para proporcionar una demostración completa del flujo de datos entrantes. Si su caso de uso requiere el análisis de registros sin procesar, puede agilizar el proceso omitiendo la canalización inicial y centrándose directamente en la detección de anomalías en el flujo, indexando solo las anomalías identificadas.
El siguiente diagrama ilustra la arquitectura de nuestra solución.
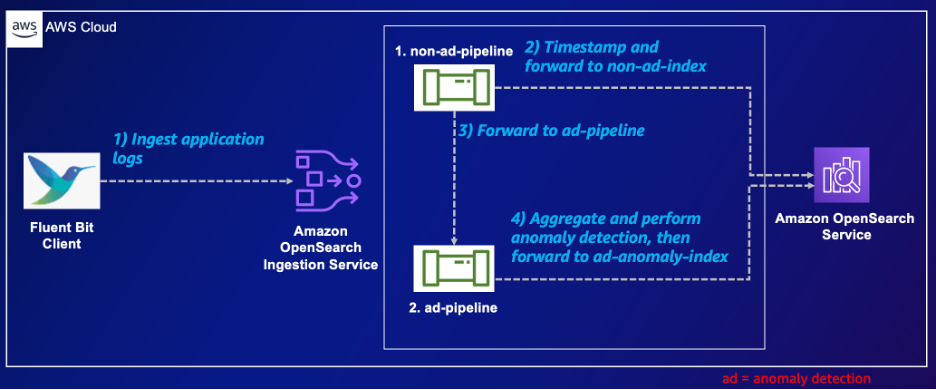
La configuración describe dos canales de ingesta de OpenSearch. El primero, sin canalización de anuncios, ingiere datos HTTP, les marca la hora y los reenvía tanto a la canalización de anuncios como a un índice de OpenSearch, sin índice de anuncios. El segundo, el canal de anuncios, recibe estos datos, realiza una agregación basada en la identificación dentro de un período de 5 minutos y realiza la detección de anomalías. Los resultados se almacenan en el índice ad-anomaly-index. Esta configuración muestra el procesamiento de datos, la detección de anomalías y el almacenamiento dentro del servicio OpenSearch, lo que mejora las capacidades de análisis.
Implementar la solución
Complete los siguientes pasos para configurar la solución:
- Crear un rol de canalización.
- crear una colección.
- Crear una canalización en el que especifica la función de canalización.
La canalización asume esta función para firmar solicitudes al punto final de la colección OpenSearch Serverless. Especifique los valores de las claves dentro de la siguiente configuración de canalización:
-
sts_role_arn, especifique el nombre de recurso de Amazon (ARN) de la función de canalización que creó. -
hosts, especifique el punto final de la colección que creó. - Set
serverlessa la verdad
Para obtener una guía detallada sobre los parámetros requeridos y las limitaciones, consulte Complementos y opciones compatibles para canalizaciones de ingesta de Amazon OpenSearch.
- Después de actualizar la configuración, confirme la validez de la configuración de su canalización eligiendo Validar canalización.
Una validación exitosa mostrará un mensaje que indica "La validación de la configuración de la tubería fue exitosa”. como se muestra en la siguiente captura de pantalla.

Si la validación falla, consulte Solución de problemas del servicio Amazon OpenSearch para solución de problemas y orientación.
Estimación de costos para la ingestión de OpenSearch
Sólo se le cobrará por el número de Ingestión de unidades informáticas de OpenSearch (OCU de ingestión) que se asignan a una canalización, independientemente de si hay datos fluyendo a través de la canalización. OpenSearch Ingestion se adapta inmediatamente a sus cargas de trabajo al aumentar o reducir la capacidad de la canalización según el uso. Para obtener una descripción general de los gastos, consulte Ingestión de Amazon OpenSearch.
La siguiente tabla muestra los costos mensuales aproximados según los rendimientos y las necesidades informáticas específicos. Supongamos que la operación se produce de 8:00 a. m. a 8:00 p. m. de lunes a viernes, con un costo de $0.24 por OCU por hora.
La fórmula sería: Costo total/mes = Requisito de OCU * Precio de OCU * Horas/día * Días/mes.
| rendimiento | Computación requerida (OCU) | Costo total/mes (USD) |
| 1 Gbps | 10 | 576 |
| 10 Gbps | 100 | 5760 |
| 50 Gbps | 500 | 28800 |
| 100 Gbps | 1000 | 57600 |
| 500 Gbps | 5000 | 288000 |
Limpiar
Cuando haya terminado de usar la solución, elimine los recursos que creó, incluida la función de canalización, la canalización y la colección.
Resumen
Con OpenSearch Ingestion, puede explorar la detección de anomalías en el flujo con OpenSearch Service. El caso de uso de esta publicación demuestra cómo OpenSearch Ingestion simplifica el proceso y logra más con menos recursos. Muestra la capacidad del servicio para analizar tasas de registro, generar notificaciones de anomalías y potenciar una respuesta proactiva a las anomalías. Con OpenSearch Ingestion, puede mejorar la eficiencia operativa y mejorar las capacidades de gestión de riesgos en tiempo real.
Deje cualquier idea y pregunta en los comentarios.
Acerca de los autores
 Rupesh Tiwari, un arquitecto de soluciones de AWS, se especializa en la modernización de aplicaciones con un enfoque en análisis de datos, OpenSearch e IA generativa. Es conocido por crear soluciones escalables y seguras que aprovechan la tecnología de la nube para obtener resultados comerciales transformadores, y también dedica tiempo a la participación de la comunidad y al intercambio de experiencias.
Rupesh Tiwari, un arquitecto de soluciones de AWS, se especializa en la modernización de aplicaciones con un enfoque en análisis de datos, OpenSearch e IA generativa. Es conocido por crear soluciones escalables y seguras que aprovechan la tecnología de la nube para obtener resultados comerciales transformadores, y también dedica tiempo a la participación de la comunidad y al intercambio de experiencias.
 Muthu Pitchaimani es un especialista en búsquedas de Amazon OpenSearch Service. Construye aplicaciones y soluciones de búsqueda a gran escala. Muthu está interesado en los temas de redes y seguridad, y tiene su sede en Austin, Texas.
Muthu Pitchaimani es un especialista en búsquedas de Amazon OpenSearch Service. Construye aplicaciones y soluciones de búsqueda a gran escala. Muthu está interesado en los temas de redes y seguridad, y tiene su sede en Austin, Texas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/in-stream-anomaly-detection-with-amazon-opensearch-ingestion-and-amazon-opensearch-serverless/

