Con el uso de computación en la nube, big data y herramientas de aprendizaje automático (ML) como Atenea amazónica or Amazon SageMaker ahora están disponibles y son utilizables por cualquier persona sin mucho esfuerzo en su creación y mantenimiento. Las empresas industriales recurren cada vez más al análisis de datos y a la toma de decisiones basada en datos para aumentar la eficiencia de los recursos en toda su cartera, desde las operaciones hasta la realización de mantenimiento predictivo o la planificación.
Debido a la velocidad del cambio en TI, los clientes de las industrias tradicionales se enfrentan a un dilema en cuanto a habilidades. Por un lado, los analistas y expertos en el campo tienen un conocimiento muy profundo de los datos en cuestión y su interpretación, pero a menudo carecen de exposición a herramientas de ciencia de datos y lenguajes de programación de alto nivel como Python. Por otro lado, los expertos en ciencia de datos a menudo carecen de la experiencia para interpretar el contenido de los datos de la máquina y filtrarlo según lo relevante. Este dilema obstaculiza la creación de modelos eficientes que utilicen datos para generar conocimientos relevantes para el negocio.
Lienzo de Amazon SageMaker aborda este dilema proporcionando a los expertos en el dominio una interfaz sin código para crear análisis potentes y modelos de aprendizaje automático, como pronósticos, clasificación o modelos de regresión. También le permite implementar y compartir estos modelos con especialistas de ML y MLOps después de su creación.
En esta publicación, le mostramos cómo usar SageMaker Canvas para curar y seleccionar las características correctas en sus datos y luego entrenar un modelo de predicción para la detección de anomalías, utilizando la funcionalidad sin código de SageMaker Canvas para ajustar el modelo.
Detección de anomalías para la industria manufacturera
En el momento de escribir este artículo, SageMaker Canvas se centra en casos de uso empresarial típicos, como previsión, regresión y clasificación. En esta publicación, demostramos cómo estas capacidades también pueden ayudar a detectar puntos de datos anormales complejos. Este caso de uso es relevante, por ejemplo, para identificar fallos de funcionamiento u operaciones inusuales de máquinas industriales.
La detección de anomalías es importante en el ámbito industrial, porque las máquinas (desde trenes hasta turbinas) normalmente son muy confiables, con tiempos entre fallas que abarcan años. La mayoría de los datos de estas máquinas, como las lecturas de los sensores de temperatura o los mensajes de estado, describen el funcionamiento normal y tienen un valor limitado para la toma de decisiones. Los ingenieros buscan datos anormales cuando investigan las causas fundamentales de una falla o como indicadores de advertencia para fallas futuras, y los gerentes de desempeño examinan los datos anormales para identificar posibles mejoras. Por lo tanto, el primer paso típico para avanzar hacia una toma de decisiones basada en datos se basa en encontrar datos relevantes (anormales).
En esta publicación, utilizamos SageMaker Canvas para curar y seleccionar las características correctas en los datos y luego entrenar un modelo de predicción para la detección de anomalías, utilizando la funcionalidad sin código de SageMaker Canvas para ajustar el modelo. Luego implementamos el modelo como un punto final de SageMaker.
Resumen de la solución
Para nuestro caso de uso de detección de anomalías, entrenamos un modelo de predicción para predecir un rasgo característico para el funcionamiento normal de una máquina, como la temperatura del motor indicada en un automóvil, a partir de características que influyen, como la velocidad y el par reciente aplicado en el automóvil. . Para la detección de anomalías en una nueva muestra de mediciones, comparamos las predicciones del modelo para el rasgo característico con las observaciones proporcionadas.
Para el ejemplo del motor de un automóvil, un experto en el campo obtiene mediciones de la temperatura normal del motor, el par reciente del motor, la temperatura ambiente y otros posibles factores de influencia. Estos le permiten entrenar un modelo para predecir la temperatura a partir de otras características. Luego podemos usar el modelo para predecir la temperatura del motor de forma regular. Cuando la temperatura prevista para esos datos es similar a la temperatura observada en esos datos, el motor está funcionando normalmente; una discrepancia indicará una anomalía, como un fallo del sistema de refrigeración o un defecto en el motor.
El siguiente diagrama ilustra la arquitectura de la solución.
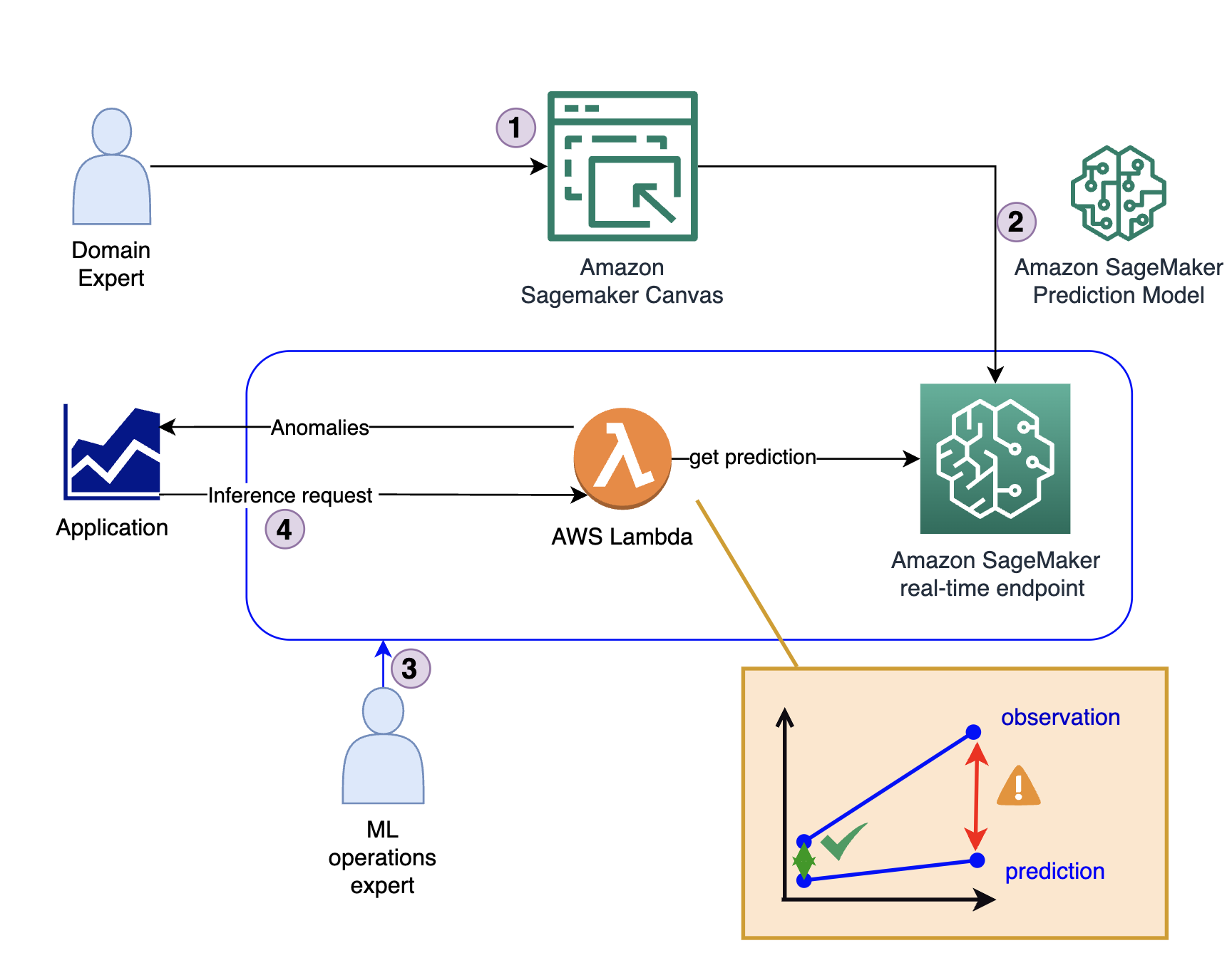
La solución consta de cuatro pasos clave:
- El experto en el dominio crea el modelo inicial, incluido el análisis de datos y la curación de funciones utilizando SageMaker Canvas.
- El experto en el dominio comparte el modelo a través del Registro de modelos de Amazon SageMaker o lo implementa directamente como un punto final en tiempo real.
- Un experto en MLOps crea la infraestructura de inferencia y el código que traduce el resultado del modelo de una predicción a un indicador de anomalía. Este código normalmente se ejecuta dentro de un AWS Lambda función.
- Cuando una aplicación requiere la detección de una anomalía, llama a la función Lambda, que utiliza el modelo para la inferencia y proporciona la respuesta (ya sea que sea una anomalía o no).
Requisitos previos
Para seguir esta publicación, debe cumplir con los siguientes requisitos previos:
Crea el modelo usando SageMaker
El proceso de creación del modelo sigue los pasos estándar para crear un modelo de regresión en SageMaker Canvas. Para obtener más información, consulte Introducción al uso de Amazon SageMaker Canvas.
Primero, el experto en el dominio carga datos relevantes en SageMaker Canvas, como una serie temporal de mediciones. Para esta publicación, utilizamos un archivo CSV que contiene las medidas (generadas sintéticamente) de un motor eléctrico. Para más detalles, consulte Importar datos en Canvas. Los datos de muestra utilizados están disponibles para descargar como archivo CSV.
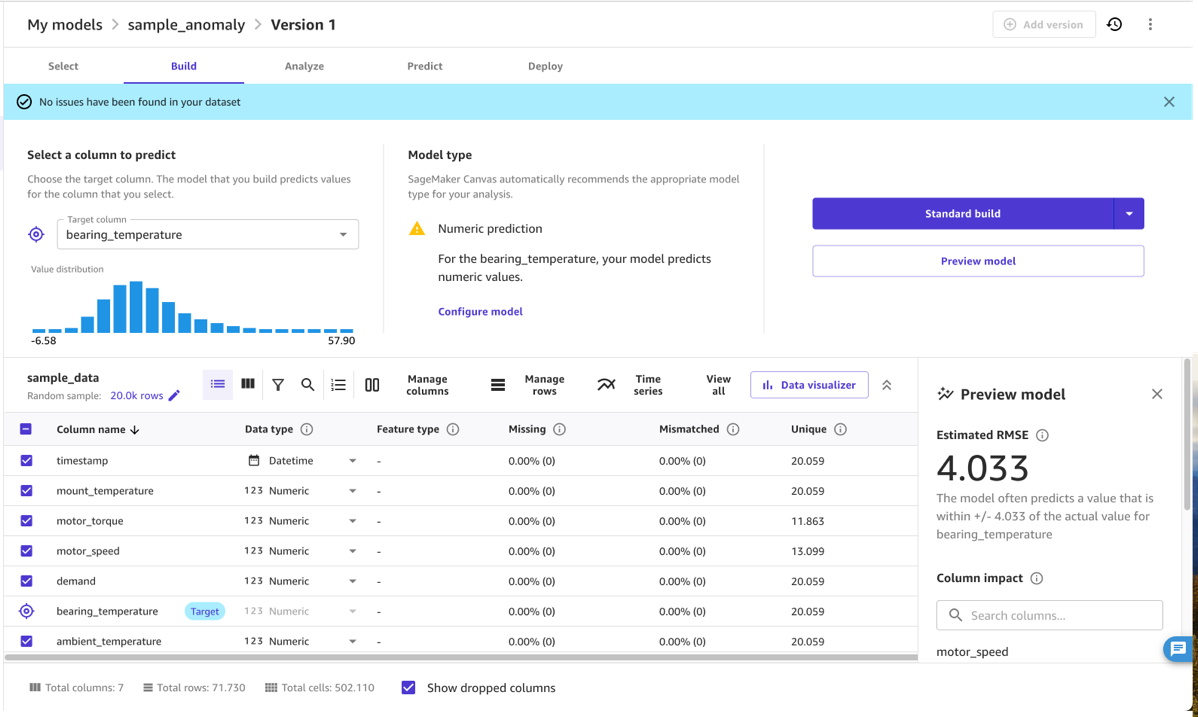
Cura los datos con SageMaker Canvas
Una vez cargados los datos, el experto en el dominio puede utilizar SageMaker Canvas para seleccionar los datos utilizados en el modelo final. Para ello, el experto selecciona aquellas columnas que contienen medidas características del problema en cuestión. Más precisamente, el experto selecciona columnas que están relacionadas entre sí, por ejemplo, mediante una relación física como una curva de presión-temperatura, y donde un cambio en esa relación es una anomalía relevante para su caso de uso. El modelo de detección de anomalías aprenderá la relación normal entre las columnas seleccionadas e indicará cuando los datos no se ajusten a ella, como una temperatura anormalmente alta del motor dada la carga actual en el motor.
En la práctica, el experto en el dominio necesita seleccionar un conjunto de columnas de entrada adecuadas y una columna de destino. Las entradas suelen ser una colección de cantidades (numéricas o categóricas) que determinan el comportamiento de una máquina, desde la configuración de demanda hasta la carga, la velocidad o la temperatura ambiente. La salida suele ser una cantidad numérica que indica el rendimiento de la operación de la máquina, como una temperatura que mide la disipación de energía u otra métrica de rendimiento que cambia cuando la máquina funciona en condiciones subóptimas.
Para ilustrar el concepto de qué cantidades seleccionar para entrada y salida, consideremos algunos ejemplos:
- Para equipos rotativos, como el modelo que construimos en esta publicación, las entradas típicas son la velocidad de rotación, el par (actual e histórico) y la temperatura ambiente, y los objetivos son las temperaturas resultantes del rodamiento o del motor que indican buenas condiciones operativas de las rotaciones.
- Para una turbina eólica, las entradas típicas son la historia actual y reciente de la velocidad del viento y los ajustes de las palas del rotor, y la cantidad objetivo es la potencia producida o la velocidad de rotación.
- Para un proceso químico, los insumos típicos son el porcentaje de diferentes ingredientes y la temperatura ambiente, y los objetivos son el calor producido o la viscosidad del producto final.
- Para equipos en movimiento, como puertas corredizas, las entradas típicas son la entrada de energía a los motores y el valor objetivo es la velocidad o el tiempo de finalización del movimiento.
- Para un sistema HVAC, las entradas típicas son la diferencia de temperatura alcanzada y los ajustes de carga, y la cantidad objetivo es el consumo de energía medido.
En última instancia, las entradas y objetivos correctos para un equipo determinado dependerán del caso de uso y del comportamiento anómalo a detectar, y son mejor conocidos por un experto en el dominio que esté familiarizado con las complejidades del conjunto de datos específico.
En la mayoría de los casos, seleccionar insumos adecuados y cantidades objetivo significa seleccionar solo las columnas correctas y marcar la columna objetivo (para este ejemplo, bearing_temperature). Sin embargo, un experto en el dominio también puede utilizar las funciones sin código de SageMaker Canvas para transformar columnas y refinar o agregar los datos. Por ejemplo, puede extraer o filtrar fechas o marcas de tiempo específicas de los datos que no sean relevantes. SageMaker Canvas admite este proceso, mostrando estadísticas sobre las cantidades seleccionadas, lo que le permite comprender si una cantidad tiene valores atípicos y una dispersión que pueda afectar los resultados del modelo.
Entrenar, ajustar y evaluar el modelo.
Una vez que el experto en el dominio haya seleccionado las columnas adecuadas en el conjunto de datos, puede entrenar el modelo para conocer la relación entre las entradas y las salidas. Más precisamente, el modelo aprenderá a predecir el valor objetivo seleccionado a partir de las entradas.
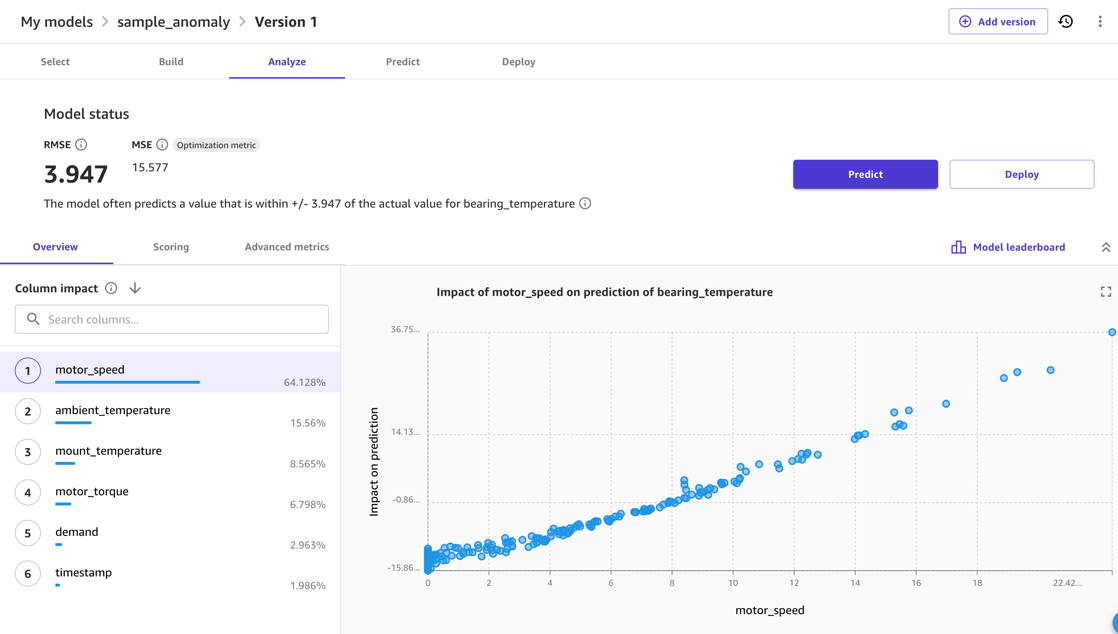
Normalmente, puedes utilizar SageMaker Canvas Vista previa del modelo opción. Esto proporciona una indicación rápida de la calidad esperada del modelo y le permite investigar el efecto que tienen las diferentes entradas en la métrica de salida. Por ejemplo, en la siguiente captura de pantalla, el modelo es el más afectado por el motor_speed y ambient_temperature métricas al predecir bearing_temperature. Esto es sensato, porque estas temperaturas están estrechamente relacionadas. Al mismo tiempo, es probable que esto afecte a la fricción adicional u otras formas de pérdida de energía.
Para la calidad del modelo, el RMSE del modelo es un indicador de qué tan bien el modelo pudo aprender el comportamiento normal en los datos de entrenamiento y reproducir las relaciones entre las medidas de entrada y salida. Por ejemplo, en el siguiente modelo, el modelo debería poder predecir la respuesta correcta. motor_bearing temperatura dentro de 3.67 grados Celsius, por lo que podemos considerar una desviación de la temperatura real de la predicción de un modelo que sea mayor que, por ejemplo, 7.4 grados como una anomalía. Sin embargo, el umbral real que utilizaría dependerá de la sensibilidad requerida en el escenario de implementación.
Finalmente, una vez finalizada la evaluación y el ajuste del modelo, puede comenzar el entrenamiento completo del modelo que creará el modelo que se utilizará para la inferencia.
Implementar el modelo
Aunque SageMaker Canvas puede usar un modelo para inferencia, la implementación productiva para la detección de anomalías requiere implementar el modelo fuera de SageMaker Canvas. Más precisamente, necesitamos implementar el modelo como punto final.
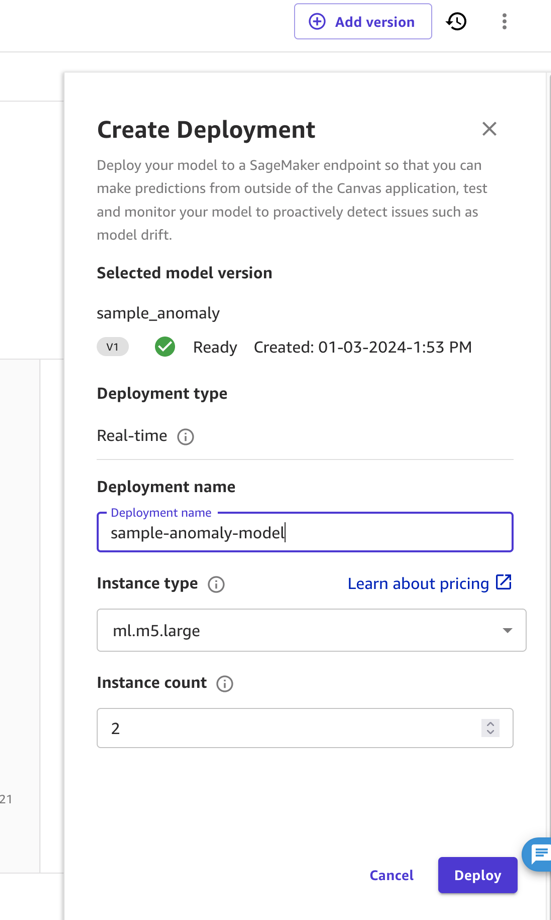
En esta publicación y para simplificar, implementamos el modelo como un punto final directamente desde SageMaker Canvas. Para obtener instrucciones, consulte Implemente sus modelos en un punto final. Asegúrese de tomar nota del nombre de la implementación y considere el precio del tipo de instancia en la que implementa (para esta publicación, usamos ml.m5.large). Luego, SageMaker Canvas creará un punto final del modelo al que se puede llamar para obtener predicciones.
En entornos industriales, un modelo debe someterse a pruebas exhaustivas antes de poder implementarse. Para ello, el experto en el dominio no lo implementará, sino que compartirá el modelo con el Registro de modelos de SageMaker. Aquí, un experto en operaciones de MLOps puede hacerse cargo. Normalmente, ese experto probará el punto final del modelo, evaluará el tamaño del equipo informático necesario para la aplicación de destino y determinará la implementación más rentable, como la implementación para inferencia sin servidor o inferencia por lotes. Estos pasos normalmente están automatizados (por ejemplo, usando Tuberías de Amazon Sagemaker o de SDK de Amazon).

Utilice el modelo para la detección de anomalías.
En el paso anterior, creamos una implementación de modelo en SageMaker Canvas, llamada canvas-sample-anomaly-model. Podemos usarlo para obtener predicciones de un bearing_temperature valor basado en las otras columnas del conjunto de datos. Ahora queremos utilizar este punto final para detectar anomalías.
Para identificar datos anómalos, nuestro modelo utilizará el punto final del modelo de predicción para obtener el valor esperado de la métrica objetivo y luego comparará el valor predicho con el valor real en los datos. El valor previsto indica el valor esperado para nuestra métrica objetivo según los datos de entrenamiento. Por lo tanto, la diferencia de este valor es una métrica de la anormalidad de los datos reales observados. Podemos usar el siguiente código:
El código anterior realiza las siguientes acciones:
- Los datos de entrada se filtran hasta las características correctas (función "
input_transformer"). - El punto final del modelo SageMaker se invoca con los datos filtrados (función “
do_inference“), donde manejamos el formato de entrada y salida de acuerdo con el código de muestra proporcionado al abrir la página de detalles de nuestra implementación en SageMaker Canvas. - El resultado de la invocación se une a los datos de entrada originales y la diferencia se almacena en la columna de error (función “
output_transform").
Encuentre anomalías y evalúe eventos anómalos
En una configuración típica, el código para obtener anomalías se ejecuta en una función Lambda. La función Lambda se puede llamar desde una aplicación o Puerta de enlace API de Amazon. La función principal devuelve una puntuación de anomalía para cada fila de los datos de entrada; en este caso, una serie temporal de una puntuación de anomalía.
Para realizar pruebas, también podemos ejecutar el código en un cuaderno de SageMaker. Los siguientes gráficos muestran las entradas y salidas de nuestro modelo cuando se utilizan los datos de muestra. Los picos en la desviación entre los valores previstos y reales (puntuación de anomalía, que se muestra en el gráfico inferior) indican anomalías. Por ejemplo, en el gráfico podemos ver tres picos distintos en los que la puntuación de anomalía (diferencia entre la temperatura esperada y la real) supera los 7 grados Celsius: el primero después de un largo tiempo de inactividad, el segundo con una fuerte caída de bearing_temperature, y el último donde bearing_temperature es alto en comparación con motor_speed.
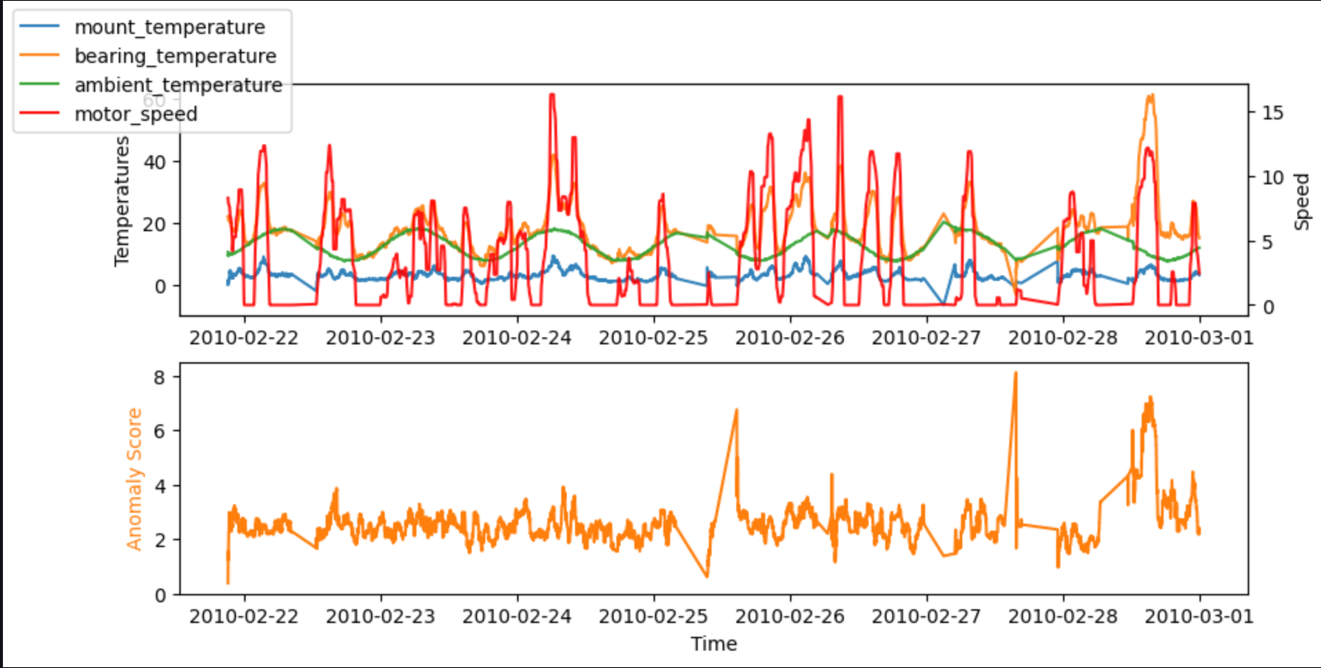
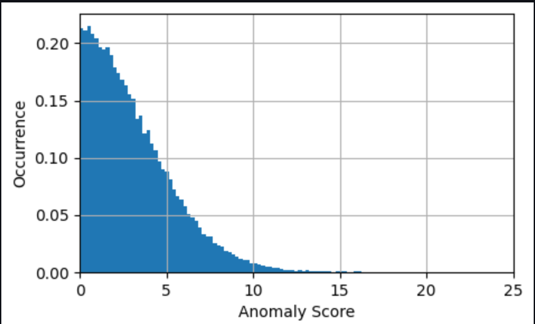
En muchos casos, conocer la serie temporal de la puntuación de anomalía ya es suficiente; puede configurar un umbral para saber cuándo advertir de una anomalía importante en función de la necesidad de sensibilidad del modelo. La puntuación actual indica entonces que una máquina tiene un estado anormal que necesita investigación. Por ejemplo, para nuestro modelo, el valor absoluto de la puntuación de anomalía se distribuye como se muestra en el siguiente gráfico. Esto confirma que la mayoría de las puntuaciones de anomalía están por debajo de los (2xRMS=)8 grados encontrados durante el entrenamiento del modelo como error típico. El gráfico puede ayudarle a elegir un umbral manualmente, de modo que el porcentaje correcto de las muestras evaluadas se marque como anomalías.
Si el resultado deseado son eventos de anomalías, entonces las puntuaciones de anomalía proporcionadas por el modelo requieren refinamiento para que sean relevantes para el uso empresarial. Para ello, el experto en ML normalmente agregará posprocesamiento para eliminar ruido o picos grandes en la puntuación de anomalía, como agregar una media móvil. Además, el experto normalmente evaluará la puntuación de anomalía mediante una lógica similar a plantear una Reloj en la nube de Amazon alarma, como la supervisión del incumplimiento de un umbral durante un período de tiempo específico. Para obtener más información sobre cómo configurar alarmas, consulte Uso de alarmas de Amazon CloudWatch. La ejecución de estas evaluaciones en la función Lambda le permite enviar advertencias, por ejemplo, publicando una advertencia en un Servicio de notificación simple de Amazon (Amazon SNS).
Limpiar
Una vez que haya terminado de usar esta solución, debe limpiar para evitar costos innecesarios:
- En SageMaker Canvas, busque la implementación del punto final de su modelo y elimínela.
- Cierre sesión en SageMaker Canvas para evitar cargos por su funcionamiento inactivo.
Resumen
En esta publicación, mostramos cómo un experto en un dominio puede evaluar los datos de entrada y crear un modelo de aprendizaje automático utilizando SageMaker Canvas sin la necesidad de escribir código. Luego mostramos cómo usar este modelo para realizar la detección de anomalías en tiempo real usando SageMaker y Lambda a través de un flujo de trabajo simple. Esta combinación permite a los expertos en el dominio utilizar sus conocimientos para crear potentes modelos de aprendizaje automático sin capacitación adicional en ciencia de datos, y permite a los expertos de MLOps utilizar estos modelos y ponerlos a disposición para inferencias de manera flexible y eficiente.
Hay un nivel gratuito de 2 meses disponible para SageMaker Canvas y luego solo paga por lo que usa. Comience a experimentar hoy y agregue ML para aprovechar al máximo sus datos.
Acerca del autor.
 Helge Aufderheide es un entusiasta de hacer que los datos sean utilizables en el mundo real con un fuerte enfoque en la automatización, el análisis y el aprendizaje automático en aplicaciones industriales, como la fabricación y la movilidad.
Helge Aufderheide es un entusiasta de hacer que los datos sean utilizables en el mundo real con un fuerte enfoque en la automatización, el análisis y el aprendizaje automático en aplicaciones industriales, como la fabricación y la movilidad.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/detect-anomalies-in-manufacturing-data-using-amazon-sagemaker-canvas/

