Con el crecimiento exponencial de los datos, las empresas manejan enormes volúmenes y una amplia variedad de datos, incluida la información de identificación personal (PII). PII es un término legal relacionado con información que puede identificar, contactar o localizar a una sola persona. Identificar y proteger datos confidenciales a escala se ha vuelto cada vez más complejo, costoso y requiere mucho tiempo. Las organizaciones deben cumplir con los requisitos regulatorios, de cumplimiento y de privacidad de datos, como RGPD y CCPAy es importante identificar y proteger la PII para mantener el cumplimiento. Debe identificar datos confidenciales, incluida la PII, como nombre, número de seguro social (SSN), dirección, correo electrónico, licencia de conducir y más. Incluso después de la identificación, resulta engorroso implementar la redacción, el enmascaramiento o el cifrado de datos confidenciales a escala.
Muchas empresas identifican y etiquetan la PII mediante métodos manuales, que consumen mucho tiempo y son propensos a errores. Reseñas de sus bases de datos, almacenes de datos y lagos de datos, dejando así sus datos confidenciales desprotegidos y vulnerables a sanciones regulatorias e incidentes de violación.
En esta publicación, proporcionamos una solución automatizada para detectar datos PII en Desplazamiento al rojo de Amazon usando Pegamento AWS.
Resumen de la solución
Con esta solución, detectamos PII en los datos de nuestro almacén de datos de Redshift para poder tomar y proteger los datos. Utilizamos los siguientes servicios:
- Desplazamiento al rojo de Amazon es un servicio de almacenamiento de datos en la nube que utiliza SQL para analizar datos estructurados y semiestructurados en almacenes de datos, bases de datos operativas y lagos de datos, utilizando hardware y aprendizaje automático (ML) diseñados por AWS para ofrecer la mejor relación precio/rendimiento a cualquier escala. Para nuestra solución, utilizamos Amazon Redshift para almacenar los datos.
- Pegamento AWS es un servicio de integración de datos sin servidor que facilita el descubrimiento, la preparación y la combinación de datos para análisis, aprendizaje automático y desarrollo de aplicaciones. Utilizamos AWS Glue para descubrir los datos de PII almacenados en Amazon Redshift.
- Servicios de almacenamiento simples de Amazon (Amazon S3) es un servicio de almacenamiento que ofrece escalabilidad, disponibilidad de datos, seguridad y rendimiento líderes en la industria.
El siguiente diagrama ilustra la arquitectura de nuestra solución.
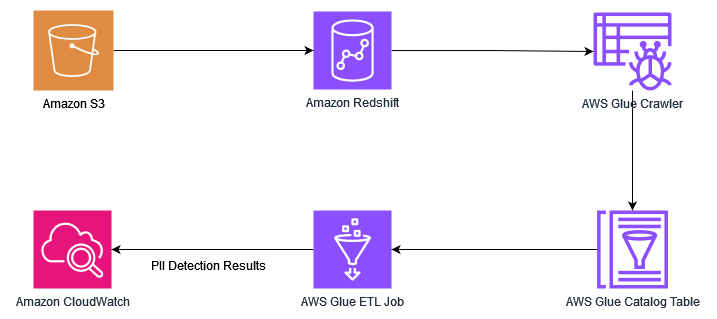
La solución incluye los siguientes pasos de alto nivel:
- Configurar la infraestructura utilizando un Formación en la nube de AWS plantilla.
- Cargue datos desde Amazon S3 al almacén de datos de Redshift.
- Ejecute un rastreador de AWS Glue para completar el catálogo de datos de AWS Glue con tablas.
- Ejecute un trabajo de AWS Glue para detectar los datos de PII.
- Analizar la salida usando Reloj en la nube de Amazon.
Requisitos previos
Los recursos creados en esta publicación suponen que existe una VPC junto con una subred privada y ambos identificadores. Esto garantiza que no cambiemos sustancialmente la VPC y la configuración de la subred. Por lo tanto, queremos configurar nuestros puntos finales de VPC según la VPC y la subred en la que elegimos exponerlos.
Antes de comenzar, cree los siguientes recursos como requisitos previos:
- Una VPC existente
- Una subred privada en esa VPC
- Un punto final S3 de puerta de enlace de VPC
- Un punto final de puerta de enlace de VPC STS
Configurar la infraestructura con AWS CloudFormation
Para crear su infraestructura con una plantilla de CloudFormation, complete los siguientes pasos:
- Abra la consola de AWS CloudFormation en su cuenta de AWS.
- Elige Pila de lanzamiento:

- Elige Siguiente.
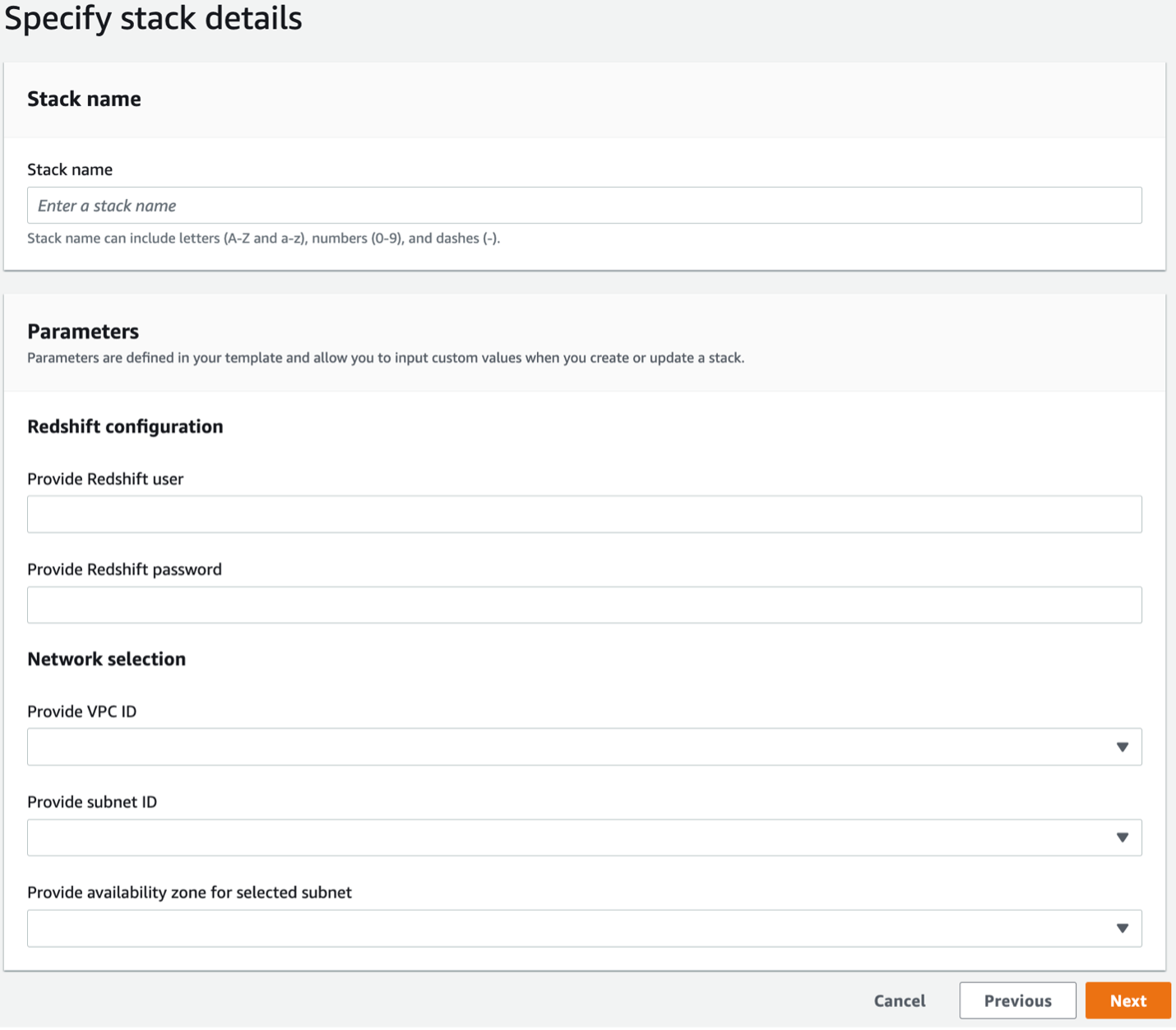
- Provee la siguiente informacion:
- Nombre de pila
- Nombre de usuario de Amazon Redshift
- Contraseña de Amazon Redshift
- ID de VPC
- ID de subred
- Zonas de disponibilidad para el ID de subred
- Elige Siguiente.
- En la página siguiente, elija Siguiente.
- Revise los detalles y seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM.
- Elige Crear pila.
- Tenga en cuenta los valores de
S3BucketNameyRedshiftRoleArnen la pila Salidas .
Cargue datos desde Amazon S3 al almacén de datos de Redshift
Con la Comando COPY, podemos cargar datos de archivos ubicados en uno o más depósitos de S3. Usamos la cláusula FROM para indicar cómo el comando COPY ubica los archivos en Amazon S3. Puede proporcionar la ruta del objeto a los archivos de datos como parte de la cláusula FROM o puede proporcionar la ubicación de un archivo de manifiesto que contenga una lista de rutas de objetos de S3. COPY de Amazon S3 utiliza una conexión HTTPS.
Para esta publicación, utilizamos un ejemplo de salud personal. datos. Cargue los datos con los siguientes pasos:
- En la consola de Amazon S3, navegue hasta el depósito de S3 creado a partir de la plantilla de CloudFormation y verifique el conjunto de datos.
- Conéctese al almacén de datos de Redshift utilizando el Editor de consultas v2 estableciendo una conexión con la base de datos que crea utilizando la pila de CloudFormation junto con el nombre de usuario y la contraseña.
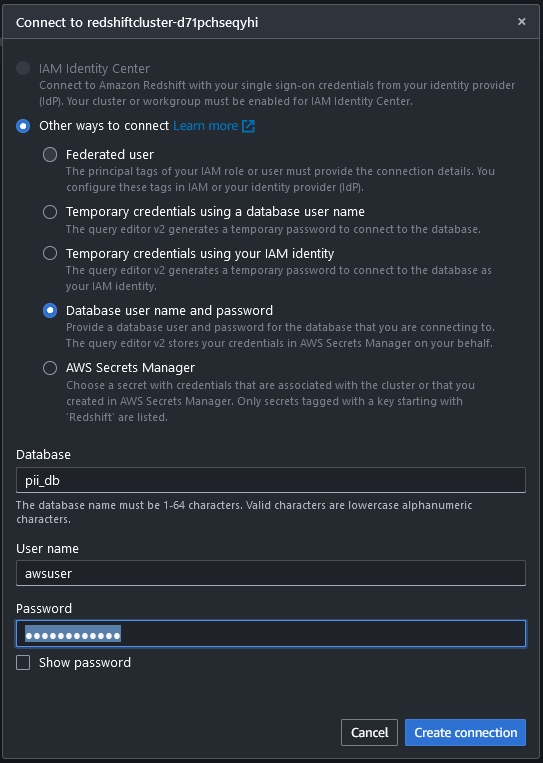
Una vez conectado, puede utilizar los siguientes comandos para crear la tabla en el almacén de datos de Redshift y copiar los datos.
- Cree una tabla con la siguiente consulta:
- Cargue los datos del depósito S3:
Proporcione valores para los siguientes marcadores de posición:
- Desplazamiento al rojoRoleArn – Localice el ARN en la pila de CloudFormation. Salidas de la pestaña.
- Nombre del depósito S3 – Reemplazar con el nombre del depósito de la pila de CloudFormation
- región de aws – Cambie a la región donde implementó la plantilla de CloudFormation
- Para verificar que los datos se cargaron, ejecute el siguiente comando:

Ejecute un rastreador de AWS Glue para completar el catálogo de datos con tablas
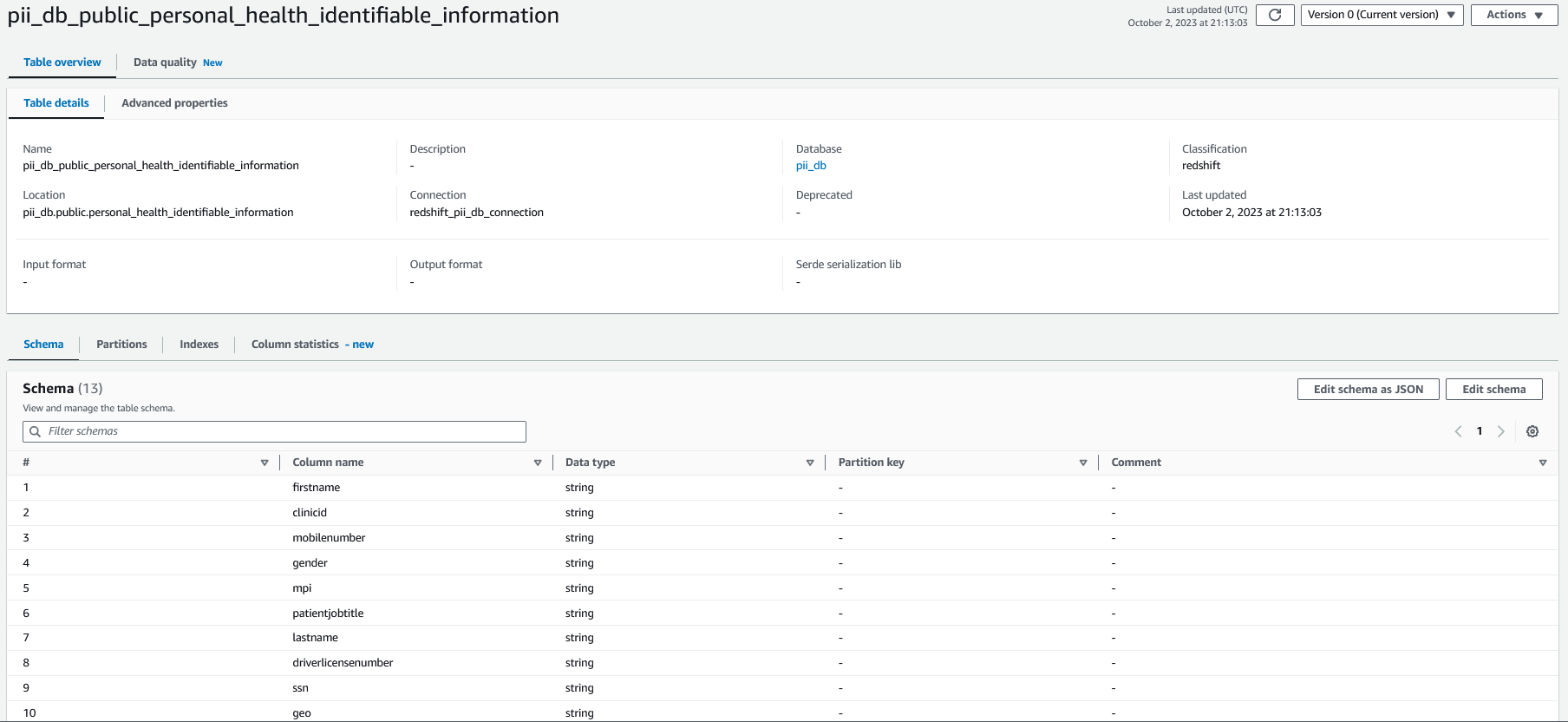
En la consola de AWS Glue, seleccione el rastreador que implementó como parte de la pila de CloudFormation con el nombre crawler_pii_db, A continuación, elija Ejecutar rastreador.

Cuando se completa el rastreador, las tablas de la base de datos con el nombre pii_db se completan en el catálogo de datos de AWS Glue y el esquema de la tabla se parece a la siguiente captura de pantalla.
Ejecute un trabajo de AWS Glue para detectar datos PII y enmascarar las columnas correspondientes en Amazon Redshift
En la consola de AWS Glue, elija Empleos ETL en el panel de navegación y ubique el trabajo detect-pii-data para comprender su configuración. Las propiedades básicas y avanzadas se configuran mediante la plantilla de CloudFormation.
Las propiedades básicas son las siguientes:
- Tipo de Propiedad - Chispa - chispear
- Versión con pegamento – Pegamento 4.0
- Idioma - Python
Para fines de demostración, la opción de marcadores de trabajos está deshabilitada, junto con la función de escala automática.

También configuramos propiedades avanzadas respecto a conexiones y parámetros de trabajo.
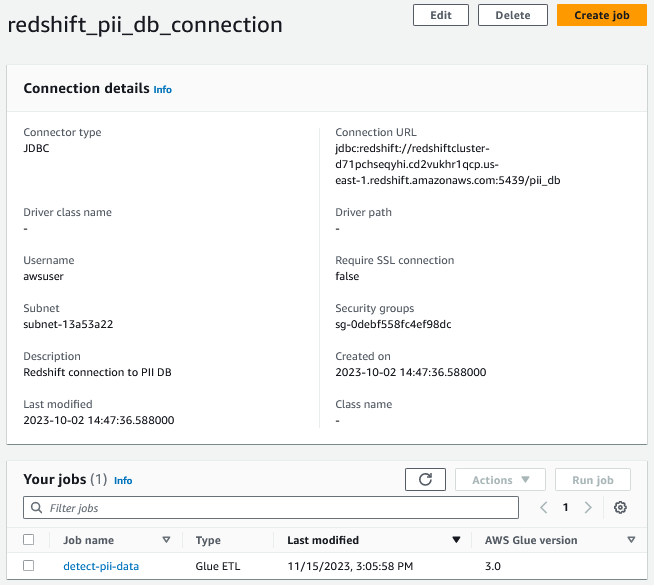
Para acceder a los datos que residen en Amazon Redshift, creamos una conexión de AWS Glue que utiliza la conexión JDBC.
También proporcionamos parámetros personalizados como pares clave-valor. Para esta publicación, dividimos la PII en cinco categorías de detección diferentes:
- universal –
PERSON_NAME,EMAIL,CREDIT_CARD - hipaa –
PERSON_NAME,PHONE_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT,USA_DRIVING_LICENSE,USA_HCPCS_CODE,USA_NATIONAL_DRUG_CODE,USA_NATIONAL_PROVIDER_IDENTIFIER,USA_DEA_NUMBER,USA_HEALTH_INSURANCE_CLAIM_NUMBER,USA_MEDICARE_BENEFICIARY_IDENTIFIER - red –
IP_ADDRESS,MAC_ADDRESS - Estados Unidos –
PHONE_NUMBER,USA_PASSPORT_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT - personalizado – Coordenadas
Si está probando esta solución desde otros países, puede especificar los campos de PII personalizados utilizando la categoría personalizada, porque esta solución se crea en función de las regiones de EE. UU.
Para fines de demostración, utilizamos una sola tabla y la pasamos como el siguiente parámetro:
--table_name: table_namePara esta publicación, nombramos la tabla. personal_health_identifiable_information.

Puede personalizar estos parámetros según el caso de uso empresarial individual.
Ejecute el trabajo y espere a que Success de estado.
El trabajo tiene dos objetivos. El primer objetivo es identificar columnas relacionadas con datos PII en la tabla Redshift y producir una lista de estos nombres de columnas. El segundo objetivo es ofuscar los datos en esas columnas específicas de la tabla de destino. Como parte del segundo objetivo, lee los datos de la tabla, aplica una función de enmascaramiento definida por el usuario a esas columnas específicas y actualiza los datos en la tabla de destino utilizando una tabla provisional Redshift (stage_personal_health_identifiable_information) para las inserciones.
Alternativamente, también puede utilizar el enmascaramiento de datos dinámico (DDM) en Amazon Redshift para proteger los datos confidenciales en su almacén de datos.
Analizar el resultado usando CloudWatch
Cuando se complete el trabajo, revisemos los registros de CloudWatch para comprender cómo se ejecutó el trabajo de AWS Glue. Podemos navegar a los registros de CloudWatch eligiendo Registros de salida en la página de detalles del trabajo en la consola de AWS Glue.

El trabajo identificó cada columna que contiene datos PII, incluidos los campos personalizados pasados mediante los campos de detección de datos confidenciales del trabajo de AWS Glue.

Limpiar
Para limpiar la infraestructura y evitar cargos adicionales, complete los siguientes pasos:
- Vacíe los cubos S3.
- Elimine los puntos finales que creó.
- Elimine la pila de CloudFormation a través de la consola de AWS CloudFormation para eliminar los recursos restantes.

Conclusión
Con esta solución, puede escanear automáticamente los datos ubicados en los clústeres de Redshift mediante un trabajo de AWS Glue, identificar PII y tomar las acciones necesarias. Esto podría ayudar a su organización con funciones de seguridad, cumplimiento, gobernanza y protección de datos, que contribuyen a la seguridad y la gobernanza de los datos.
Acerca de los autores
 Manikanta Gona es ingeniero de datos y ML en AWS Professional Services. Se unió a AWS en 2021 con más de 6 años de experiencia en TI. En AWS, se centra en las implementaciones de lagos de datos y las cargas de trabajo analíticas y de búsqueda mediante Amazon OpenSearch Service. En su tiempo libre, le encanta la jardinería, hacer caminatas y andar en bicicleta con su esposo.
Manikanta Gona es ingeniero de datos y ML en AWS Professional Services. Se unió a AWS en 2021 con más de 6 años de experiencia en TI. En AWS, se centra en las implementaciones de lagos de datos y las cargas de trabajo analíticas y de búsqueda mediante Amazon OpenSearch Service. En su tiempo libre, le encanta la jardinería, hacer caminatas y andar en bicicleta con su esposo.
 Denis Novikov es arquitecto sénior de lago de datos en el equipo de servicios profesionales de Amazon Web Services. Está especializado en el diseño e implementación de sistemas de Analytics, Data Management y Big Data para clientes empresariales.
Denis Novikov es arquitecto sénior de lago de datos en el equipo de servicios profesionales de Amazon Web Services. Está especializado en el diseño e implementación de sistemas de Analytics, Data Management y Big Data para clientes empresariales.
 Anjan Mukherjee es un arquitecto de lago de datos en AWS, especializado en soluciones de análisis y big data. Ayuda a los clientes a crear aplicaciones escalables, confiables, seguras y de alto rendimiento en la plataforma AWS.
Anjan Mukherjee es un arquitecto de lago de datos en AWS, especializado en soluciones de análisis y big data. Ayuda a los clientes a crear aplicaciones escalables, confiables, seguras y de alto rendimiento en la plataforma AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/automatically-detect-personally-identifiable-information-in-amazon-redshift-using-aws-glue/

