Muchas organizaciones, pequeñas y grandes, están trabajando para migrar y modernizar sus cargas de trabajo de análisis en Amazon Web Services (AWS). Hay muchas razones para que los clientes migren a AWS, pero una de las principales es la capacidad de utilizar servicios totalmente administrados en lugar de dedicar tiempo a mantener la infraestructura, aplicar parches, monitorear, realizar copias de seguridad y más. Los equipos de liderazgo y desarrollo pueden dedicar más tiempo a optimizar las soluciones actuales e incluso a experimentar con nuevos casos de uso, en lugar de mantener la infraestructura actual.
Con la capacidad de avanzar rápidamente en AWS, también debe ser responsable de los datos que recibe y procesa a medida que continúa escalando. Estas responsabilidades incluyen cumplir con las leyes y regulaciones de privacidad de datos y no almacenar ni exponer datos confidenciales como información de identificación personal (PII) o información de salud protegida (PHI) de fuentes ascendentes.
En esta publicación, analizamos una arquitectura de alto nivel y un caso de uso específico que demuestra cómo puede continuar escalando la plataforma de datos de su organización sin necesidad de dedicar grandes cantidades de tiempo de desarrollo para abordar los problemas de privacidad de los datos. Usamos Pegamento AWS para detectar, enmascarar y redactar datos de PII antes de cargarlos en Servicio Amazon OpenSearch.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución de alto nivel. Hemos definido todas las capas y componentes de nuestro diseño de acuerdo con el Lente de análisis de datos del marco de buena arquitectura de AWS.
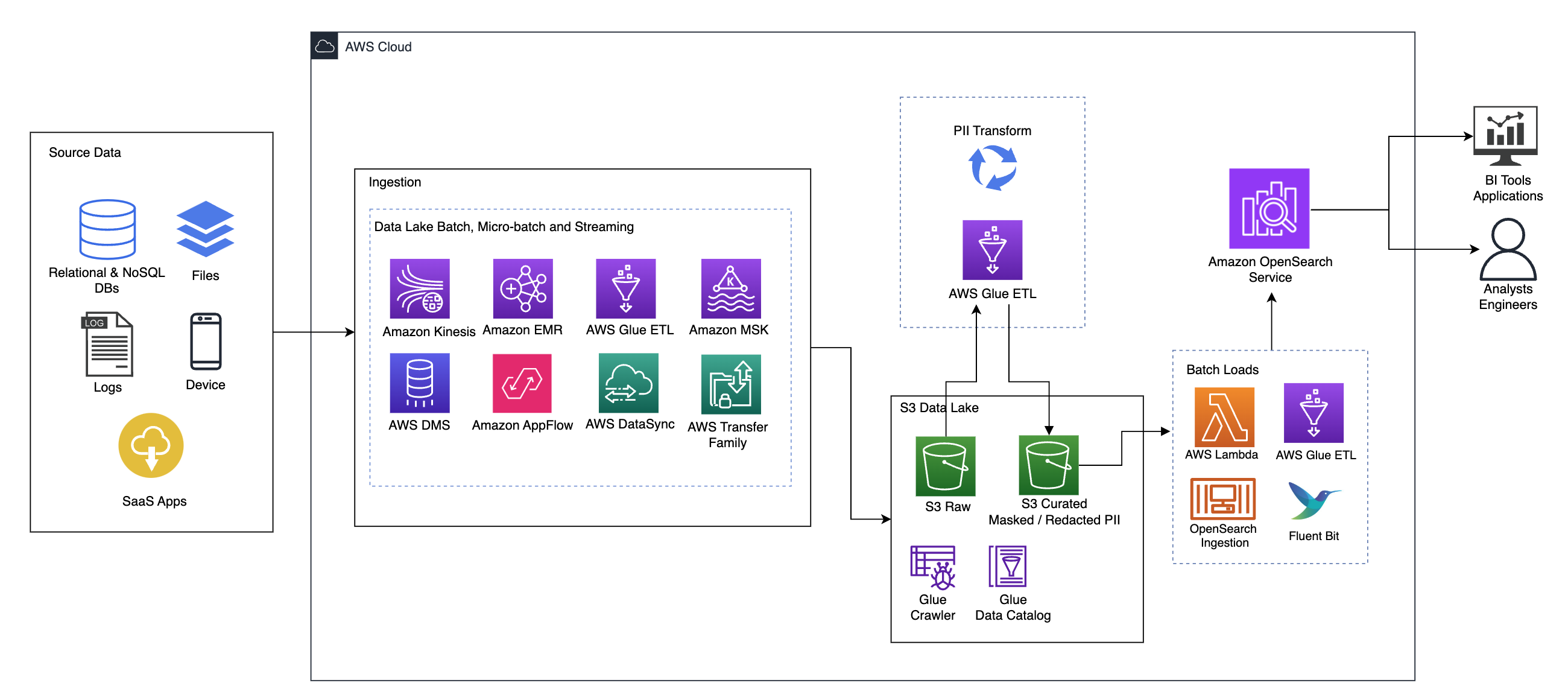
La arquitectura se compone de varios componentes:
Datos fuente
Los datos pueden provenir de decenas a cientos de fuentes, incluidas bases de datos, transferencias de archivos, registros, aplicaciones de software como servicio (SaaS) y más. Es posible que las organizaciones no siempre tengan control sobre qué datos llegan a través de estos canales y a sus aplicaciones y almacenamiento posteriores.
Ingestión: lago de datos por lotes, microlotes y streaming
Muchas organizaciones introducen sus datos de origen en su lago de datos de varias maneras, incluidos trabajos por lotes, microlotes y de transmisión. Por ejemplo, EMR de Amazon, Pegamento AWSy Servicio de migración de bases de datos de AWS (AWS DMS) se pueden utilizar para realizar operaciones por lotes o de transmisión que se hunden en un lago de datos en Servicio de almacenamiento simple de Amazon (Amazon S3). Flujo de aplicaciones de Amazon se puede utilizar para transferir datos desde diferentes aplicaciones SaaS a un lago de datos. Sincronización de datos de AWS y Familia de transferencias de AWS puede ayudar a mover archivos hacia y desde un lago de datos a través de varios protocolos diferentes. Kinesis amazónica y Amazon MSK también tienen capacidades para transmitir datos directamente a un lago de datos en Amazon S3.
Lago de datos S3
El uso de Amazon S3 para su lago de datos está en línea con la estrategia de datos moderna. Proporciona almacenamiento de bajo costo sin sacrificar el rendimiento, la confiabilidad o la disponibilidad. Con este enfoque, puede incorporar computación a sus datos según sea necesario y pagar solo por la capacidad que necesita para ejecutarse.
En esta arquitectura, los datos sin procesar pueden provenir de una variedad de fuentes (internas y externas), que pueden contener datos confidenciales.
Utilizando los rastreadores de AWS Glue, podemos descubrir y catalogar los datos, lo que creará los esquemas de tablas para nosotros y, en última instancia, simplificará el uso de AWS Glue ETL con la transformación PII para detectar, enmascarar o redactar cualquier dato confidencial que pueda haber llegado. en el lago de datos.
Contexto empresarial y conjuntos de datos
Para demostrar el valor de nuestro enfoque, imaginemos que usted es parte de un equipo de ingeniería de datos para una organización de servicios financieros. Sus requisitos son detectar y enmascarar datos confidenciales a medida que se incorporan al entorno de nube de su organización. Los datos serán consumidos por procesos analíticos posteriores. En el futuro, sus usuarios podrán buscar de forma segura transacciones de pago históricas basadas en flujos de datos recopilados de los sistemas bancarios internos. Los resultados de búsqueda de equipos operativos, clientes y aplicaciones de interfaz deben estar enmascarados en campos confidenciales.
La siguiente tabla muestra la estructura de datos utilizada para la solución. Para mayor claridad, hemos asignado nombres de columnas sin formato a seleccionados. Notará que varios campos dentro de este esquema se consideran datos confidenciales, como nombre, apellido, número de Seguro Social (SSN), dirección, número de tarjeta de crédito, número de teléfono, correo electrónico y dirección IPv4.
| Nombre de columna sin formato | Nombre de columna seleccionada | Tipo de Propiedad |
| c0 | nombre de pila | cadena |
| c1 | apellido | cadena |
| c2 | ssn | cadena |
| c3 | dirección | cadena |
| c4 | código postal | cadena |
| c5 | país | cadena |
| c6 | sitio_de_compra | cadena |
| c7 | Número de Tarjeta de Crédito | cadena |
| c8 | proveedor_de_tarjeta_de_crédito | cadena |
| c9 | moneda | cadena |
| c10 | valor de la compra | entero |
| c11 | Fecha de Transacción | datos |
| c12 | número de teléfono | cadena |
| c13 | cadena | |
| c14 | ipv4 | cadena |
Caso de uso: detección por lotes de PII antes de cargar en el servicio OpenSearch
Los clientes que implementan la siguiente arquitectura han creado su lago de datos en Amazon S3 para ejecutar diferentes tipos de análisis a escala. Esta solución es adecuada para clientes que no requieren la ingesta en tiempo real del servicio OpenSearch y planean utilizar herramientas de integración de datos que se ejecutan según una programación o se activan a través de eventos.
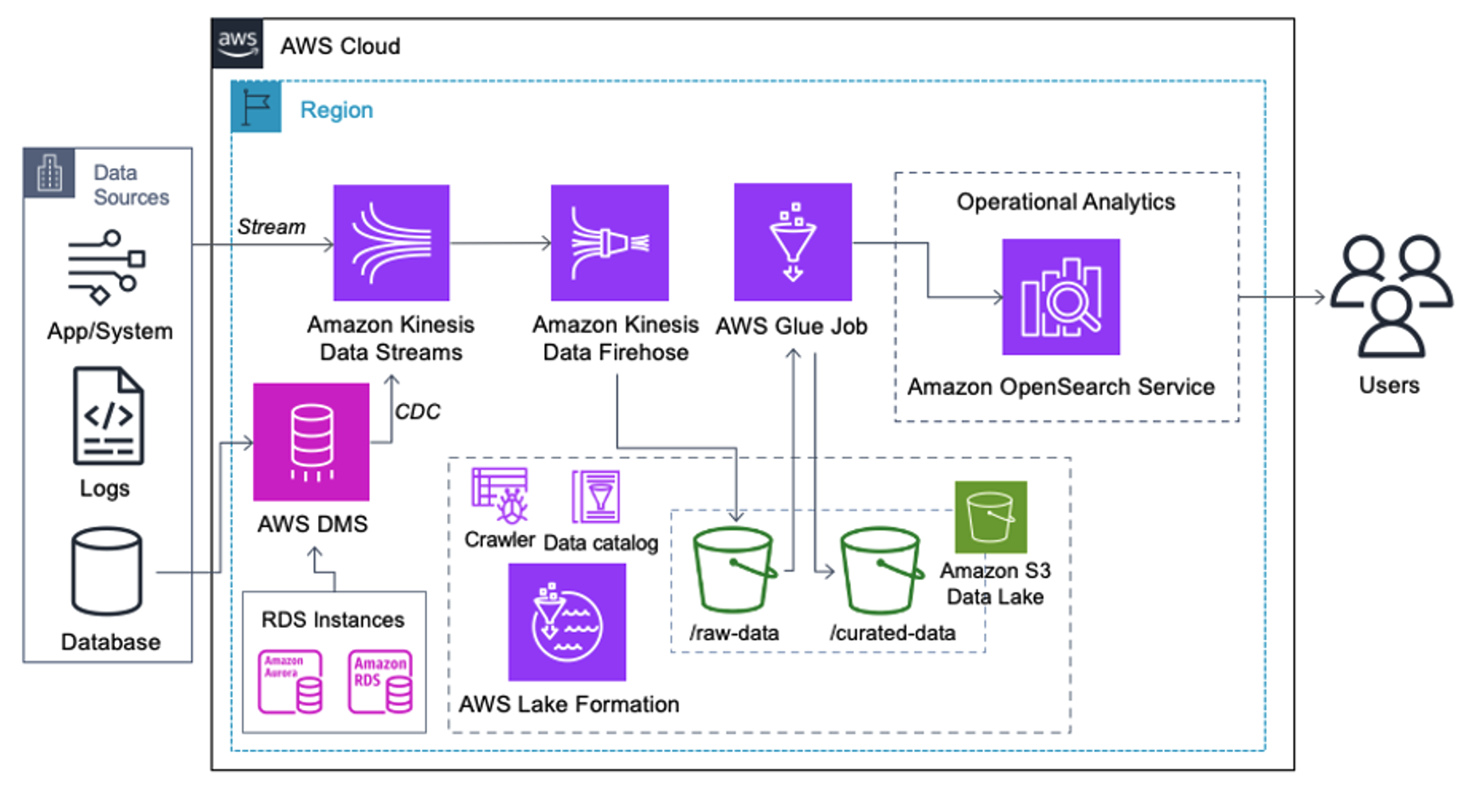
Antes de que los registros de datos lleguen a Amazon S3, implementamos una capa de ingesta para llevar todos los flujos de datos de manera confiable y segura al lago de datos. Kinesis Data Streams se implementa como una capa de ingesta para la ingesta acelerada de flujos de datos estructurados y semiestructurados. Ejemplos de estos son cambios en bases de datos relacionales, aplicaciones, registros del sistema o secuencias de clics. Para casos de uso de captura de datos modificados (CDC), puede utilizar Kinesis Data Streams como destino para AWS DMS. Las aplicaciones o sistemas que generan flujos que contienen datos confidenciales se envían al flujo de datos de Kinesis a través de uno de los tres métodos admitidos: Amazon Kinesis Agent, AWS SDK para Java o Kinesis Producer Library. Como último paso, Manguera de bomberos de datos de Amazon Kinesis nos ayuda a cargar de manera confiable lotes de datos casi en tiempo real en nuestro destino del lago de datos S3.
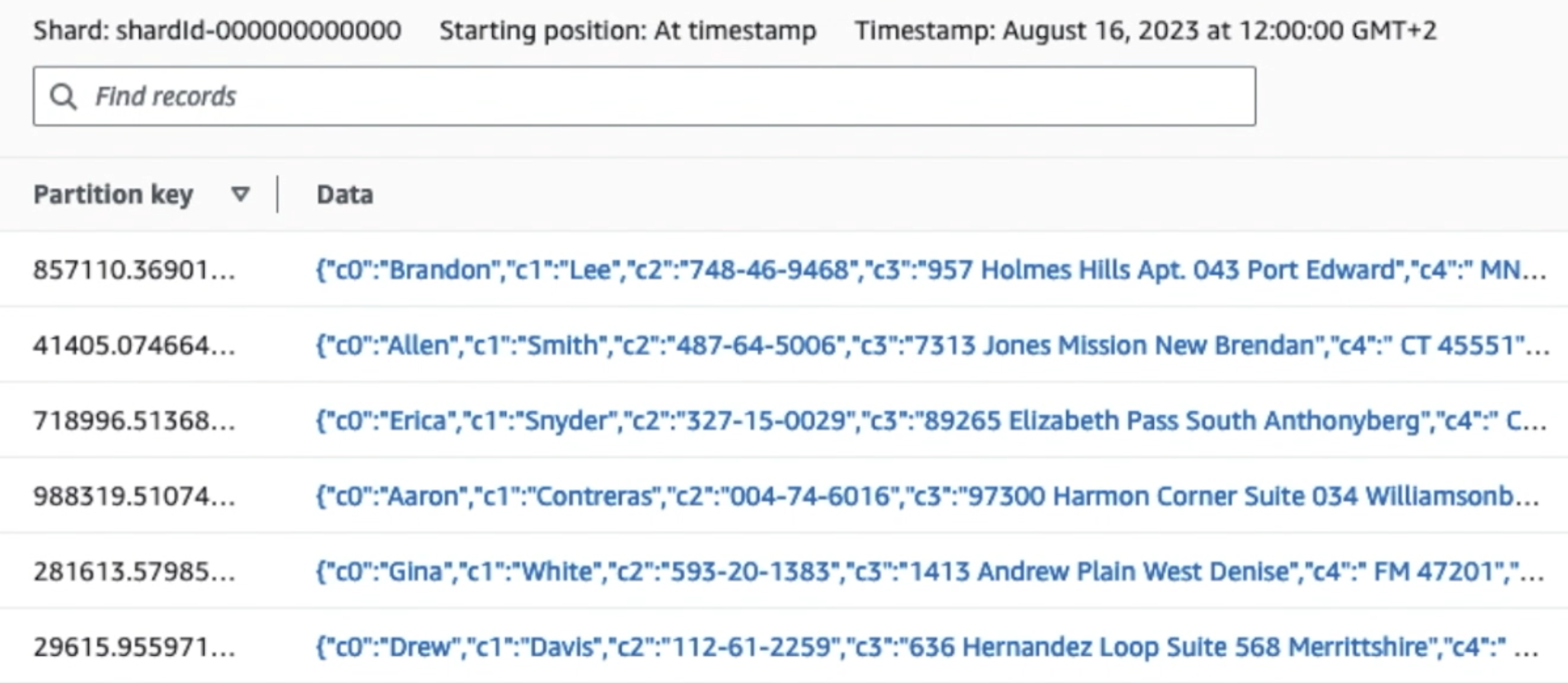
La siguiente captura de pantalla muestra cómo fluyen los datos a través de Kinesis Data Streams a través del Visor de datos y recupera datos de muestra que llegan al prefijo S3 sin formato. Para esta arquitectura, seguimos el ciclo de vida de los datos para los prefijos S3 como se recomienda en Fundación del lago de datos.
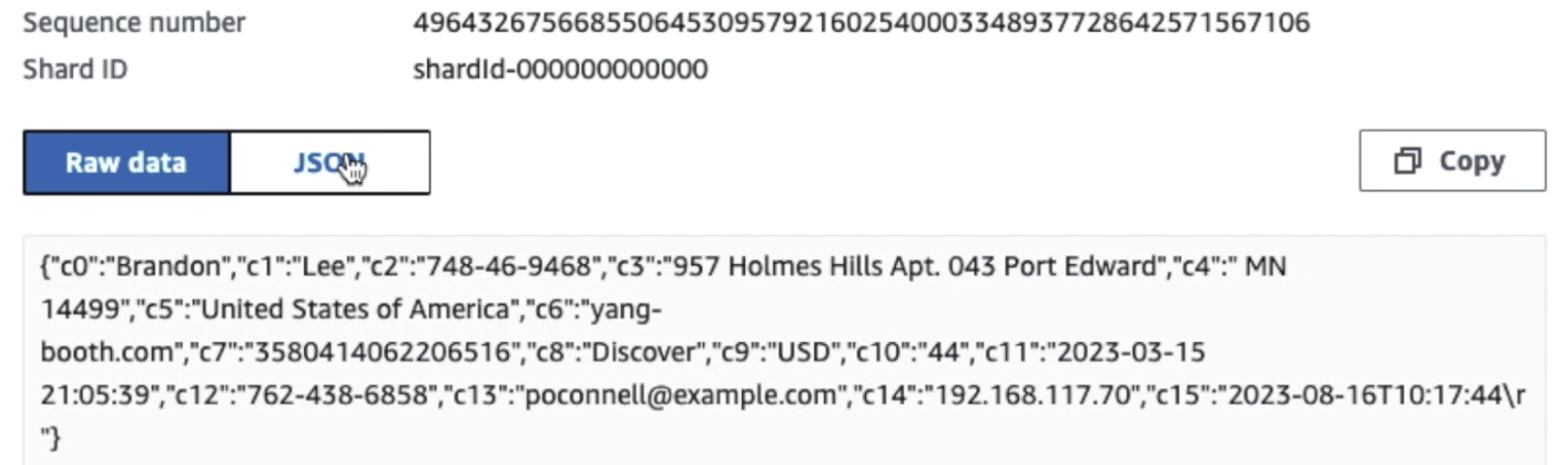
Como puede ver en los detalles del primer registro en la siguiente captura de pantalla, la carga útil JSON sigue el mismo esquema que en la sección anterior. Puede ver los datos no redactados fluyendo hacia el flujo de datos de Kinesis, que se ofuscarán más adelante en etapas posteriores.
Una vez que los datos se recopilan e incorporan en Kinesis Data Streams y se entregan al depósito de S3 mediante Kinesis Data Firehose, la capa de procesamiento de la arquitectura toma el control. Utilizamos la transformación PII de AWS Glue para automatizar la detección y el enmascaramiento de datos confidenciales en nuestra canalización. Como se muestra en el siguiente diagrama de flujo de trabajo, adoptamos un enfoque ETL visual y sin código para implementar nuestro trabajo de transformación en AWS Glue Studio.
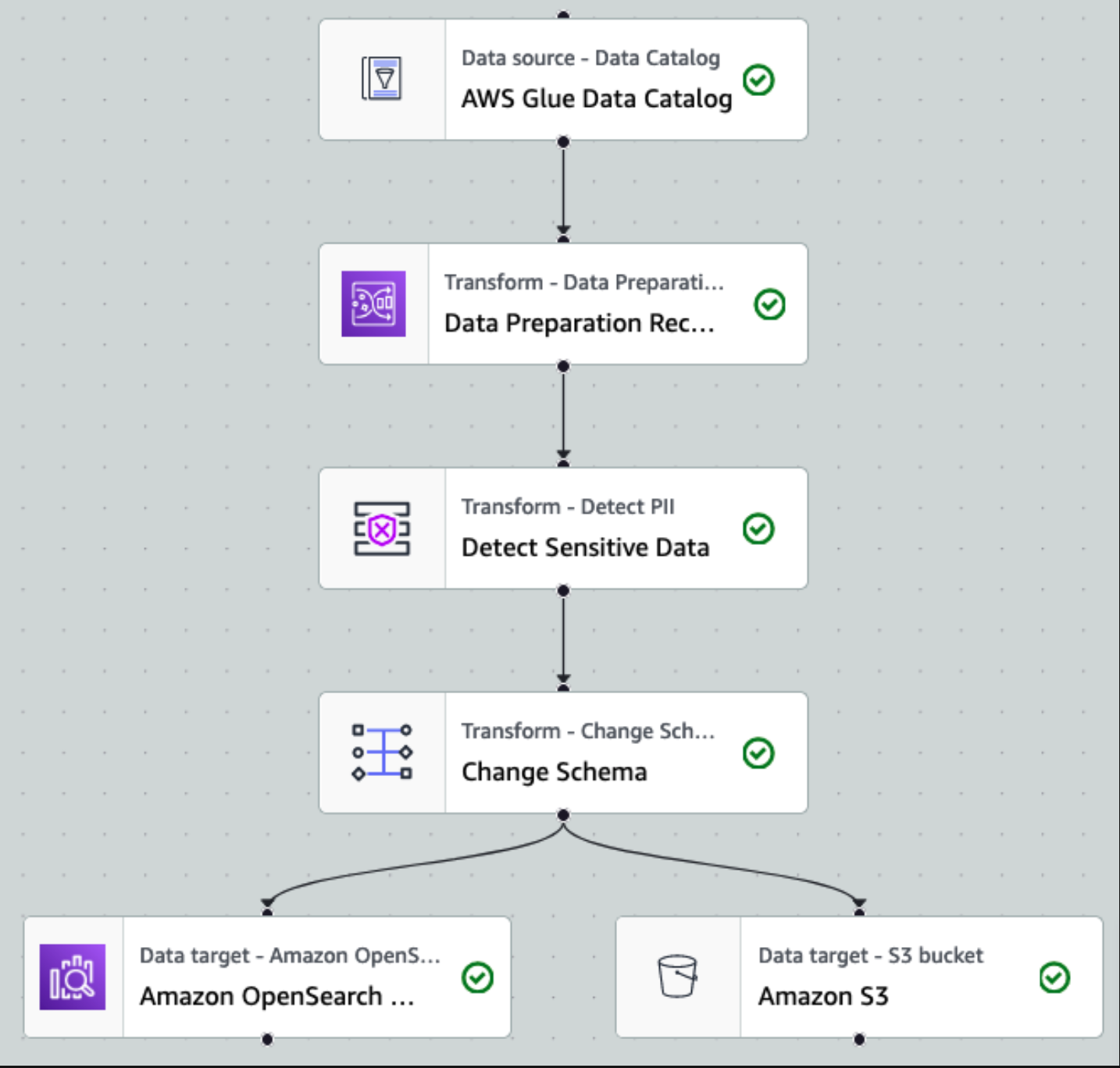
Primero, accedemos a la tabla del catálogo de datos de origen sin formato desde el pii_data_db base de datos. La tabla tiene la estructura del esquema presentado en la sección anterior. Para realizar un seguimiento de los datos procesados sin procesar, utilizamos marcadores de trabajo.

Usamos la Recetas de AWS Glue DataBrew en el trabajo ETL visual de AWS Glue Studio Se espera transformar dos atributos de fecha para que sean compatibles con OpenSearch. formatos. Esto nos permite tener una experiencia completa sin código.

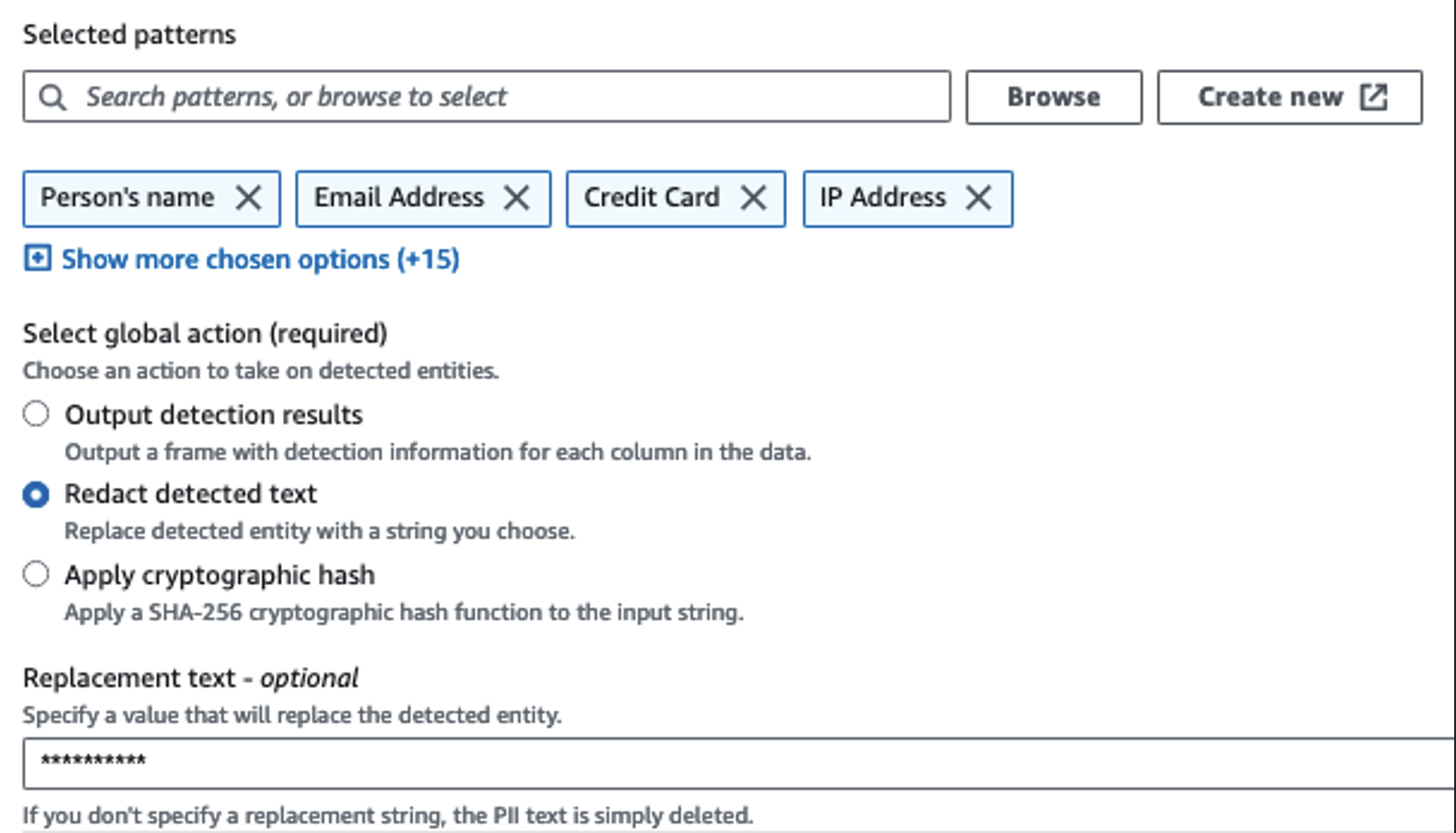
Usamos la acción Detectar PII para identificar columnas confidenciales. Dejamos que AWS Glue determine esto en función de los patrones seleccionados, el umbral de detección y la porción de muestra de filas del conjunto de datos. En nuestro ejemplo, utilizamos patrones que se aplican específicamente a los Estados Unidos (como los SSN) y es posible que no detecten datos confidenciales de otros países. Puede buscar categorías y ubicaciones disponibles aplicables a su caso de uso o utilizar expresiones regulares (regex) en AWS Glue para crear entidades de detección para datos confidenciales de otros países.
Es importante seleccionar el método de muestreo correcto que ofrece AWS Glue. En este ejemplo, se sabe que los datos que provienen de la secuencia tienen datos confidenciales en cada fila, por lo que no es necesario muestrear el 100 % de las filas del conjunto de datos. Si tiene un requisito en el que no se permiten datos confidenciales en fuentes posteriores, considere muestrear el 100 % de los datos para los patrones que eligió, o escanee todo el conjunto de datos y actúe en cada celda individual para garantizar que se detecten todos los datos confidenciales. El beneficio que obtiene del muestreo es la reducción de costos porque no tiene que escanear tantos datos.

La acción Detectar PII le permite seleccionar una cadena predeterminada al enmascarar datos confidenciales. En nuestro ejemplo, usamos la cadena **********.
Usamos la operación de aplicación de mapeo para cambiar el nombre y eliminar columnas innecesarias como ingestion_year, ingestion_monthy ingestion_day. Este paso también nos permite cambiar el tipo de datos de una de las columnas (purchase_value) de cadena a número entero.

A partir de este momento, el trabajo se divide en dos destinos de salida: OpenSearch Service y Amazon S3.
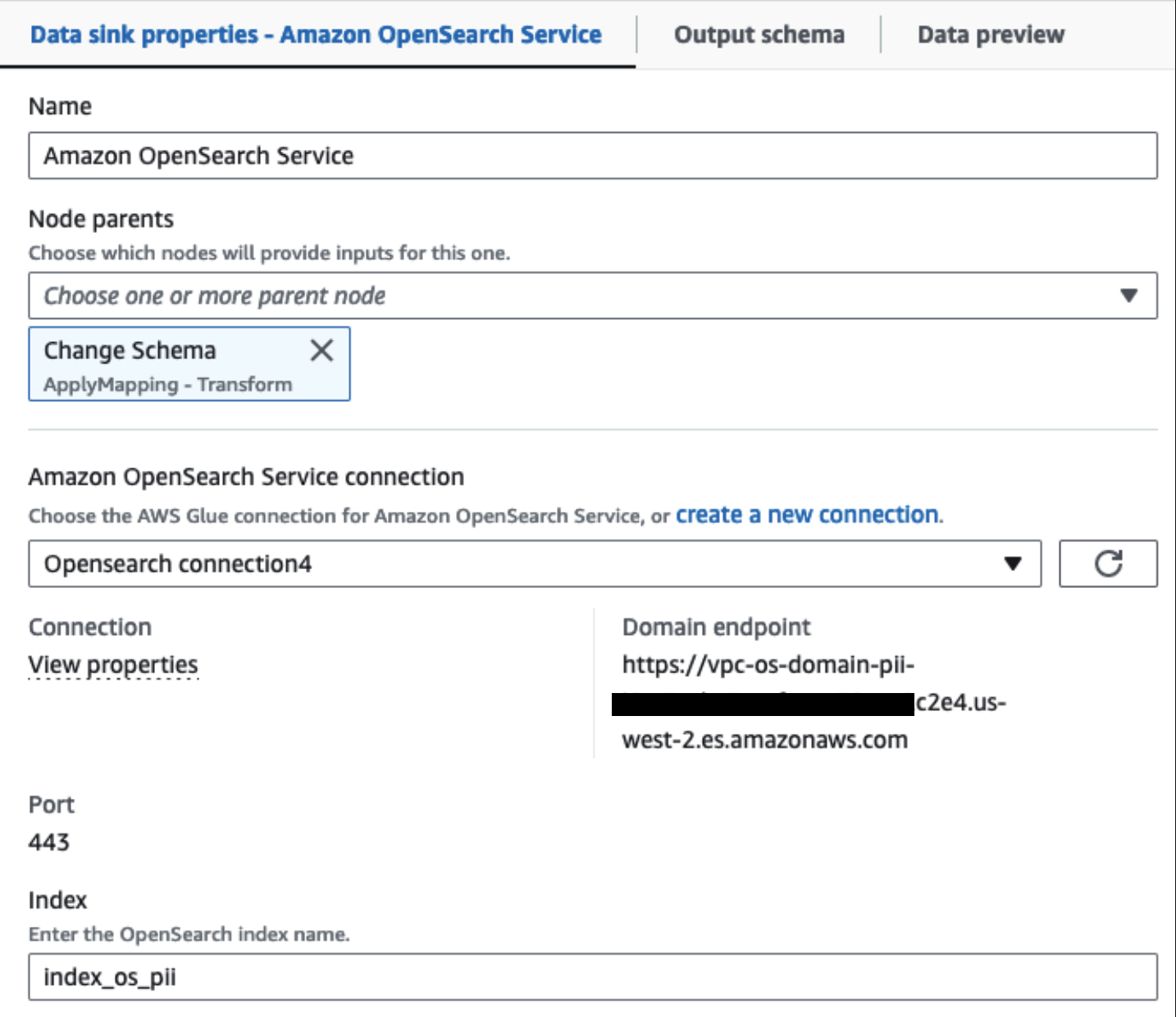
Nuestro clúster de servicio OpenSearch aprovisionado está conectado a través de Conector integrado OpenSearch para Glue. Especificamos el índice OpenSearch en el que nos gustaría escribir y el conector maneja las credenciales, el dominio y el puerto. En la captura de pantalla siguiente, escribimos en el índice especificado index_os_pii.
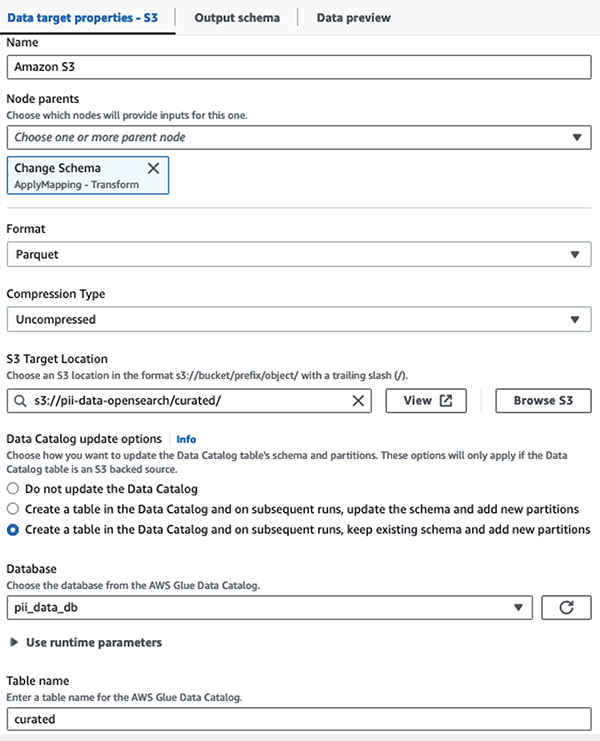
Almacenamos el conjunto de datos enmascarado en el prefijo S3 seleccionado. Allí, tenemos datos normalizados para un caso de uso específico y un consumo seguro por parte de científicos de datos o para necesidades de informes ad hoc.
Para una gobernanza unificada, control de acceso y pistas de auditoría de todos los conjuntos de datos y tablas del catálogo de datos, puede utilizar Formación del lago AWS. Esto le ayuda a restringir el acceso a las tablas del catálogo de datos de AWS Glue y a los datos subyacentes solo a aquellos usuarios y roles a quienes se les han otorgado los permisos necesarios para hacerlo.
Una vez que el trabajo por lotes se ejecute correctamente, puede utilizar el servicio OpenSearch para ejecutar consultas o informes de búsqueda. Como se muestra en la siguiente captura de pantalla, la canalización enmascaró campos confidenciales automáticamente sin esfuerzos de desarrollo de código.

Puede identificar tendencias a partir de los datos operativos, como la cantidad de transacciones por día filtradas por proveedor de tarjeta de crédito, como se muestra en la captura de pantalla anterior. También puede determinar las ubicaciones y dominios donde los usuarios realizan compras. El transaction_date El atributo nos ayuda a ver estas tendencias a lo largo del tiempo. La siguiente captura de pantalla muestra un registro con toda la información de la transacción redactada adecuadamente.
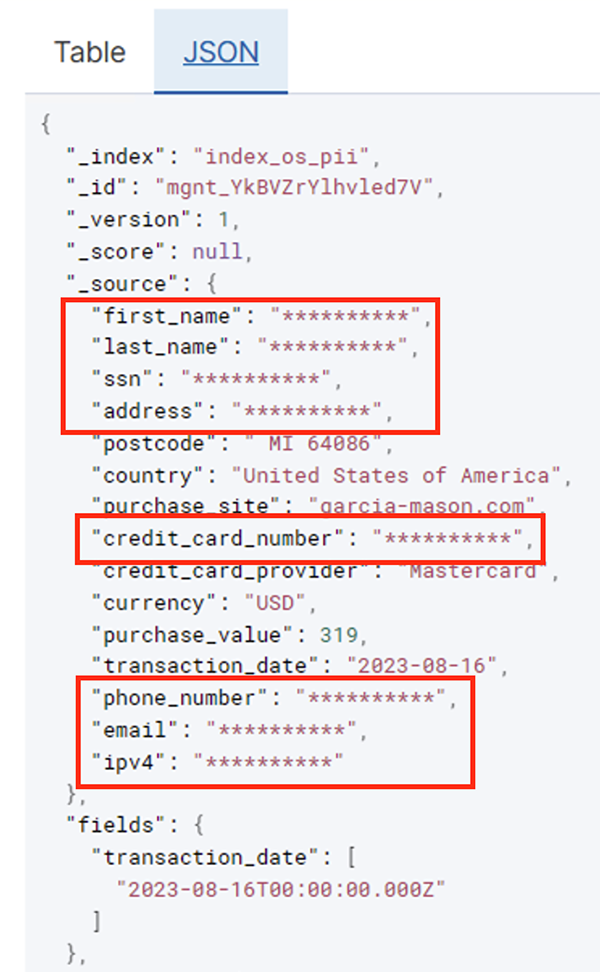
Para conocer métodos alternativos sobre cómo cargar datos en Amazon OpenSearch, consulte Cargando datos de transmisión en Amazon OpenSearch Service.
Además, los datos confidenciales también se pueden descubrir y enmascarar utilizando otras soluciones de AWS. Por ejemplo, podrías usar Amazonas Macie para detectar datos confidenciales dentro de un depósito S3 y luego usar Amazon Comprehend para redactar los datos confidenciales que se detectaron. Para obtener más información, consulte Técnicas comunes para detectar datos PHI y PII utilizando los servicios de AWS.
Conclusión
Esta publicación analizó la importancia de manejar datos confidenciales dentro de su entorno y varios métodos y arquitecturas para seguir cumpliendo y al mismo tiempo permitir que su organización escale rápidamente. Ahora debería comprender bien cómo detectar, enmascarar o redactar y cargar sus datos en Amazon OpenSearch Service.
Sobre los autores
 Michael Hamilton es un arquitecto senior de soluciones de análisis que se centra en ayudar a los clientes empresariales a modernizar y simplificar sus cargas de trabajo de análisis en AWS. Le gusta andar en bicicleta de montaña y pasar tiempo con su esposa y sus tres hijos cuando no está trabajando.
Michael Hamilton es un arquitecto senior de soluciones de análisis que se centra en ayudar a los clientes empresariales a modernizar y simplificar sus cargas de trabajo de análisis en AWS. Le gusta andar en bicicleta de montaña y pasar tiempo con su esposa y sus tres hijos cuando no está trabajando.
 daniel rodo es un arquitecto de soluciones senior de AWS que brinda soporte a clientes en los Países Bajos. Su pasión es diseñar soluciones de análisis y datos simples y ayudar a los clientes a pasar a arquitecturas de datos modernas. Fuera del trabajo, le gusta jugar tenis y andar en bicicleta.
daniel rodo es un arquitecto de soluciones senior de AWS que brinda soporte a clientes en los Países Bajos. Su pasión es diseñar soluciones de análisis y datos simples y ayudar a los clientes a pasar a arquitecturas de datos modernas. Fuera del trabajo, le gusta jugar tenis y andar en bicicleta.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/

