Introducción
Identificar la siguiente palabra es la tarea de la predicción de la siguiente palabra, también conocida como modelado del lenguaje. Uno de los PNLLas tareas de referencia de es el modelado del lenguaje. En su forma más básica, implica elegir la palabra que sigue a una cadena de palabras que es más probable que ocurra. En muchos campos diferentes, el modelado del lenguaje tiene una amplia variedad de aplicaciones.
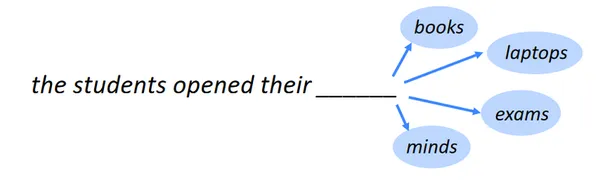
Objetivo de aprendizaje
- Reconocer las ideas y principios subyacentes detrás de los numerosos modelos utilizados en el análisis estadístico, el aprendizaje automático y la ciencia de datos.
- Aprenda a crear modelos predictivos, incluidos regresión, clasificación, agrupamiento, etc., para generar predicciones y tipos precisos basados en datos.
- Comprenda los principios de sobreajuste y ajuste insuficiente, y aprenda a evaluar el rendimiento del modelo utilizando medidas como exactitud, precisión, recuperación, etc.
- Aprenda a preprocesar datos e identificar las características pertinentes para el modelado.
- Aprenda a ajustar los hiperparámetros y optimizar los modelos mediante la búsqueda en cuadrícula y la validación cruzada.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Aplicaciones del modelado del lenguaje
Aquí hay algunas aplicaciones notables del modelado del lenguaje:
Recomendación de texto de teclado móvil
Una función en los teclados de los teléfonos inteligentes llamada recomendación de texto del teclado móvil, o texto predictivo o sugerencias automáticas, sugiere palabras o frases mientras escribe. Busca hacer que la escritura sea más rápida y menos propensa a errores y ofrecer recomendaciones más precisas y contextualmente apropiadas.
Lea también Creación de un sistema de recomendación basado en contenido
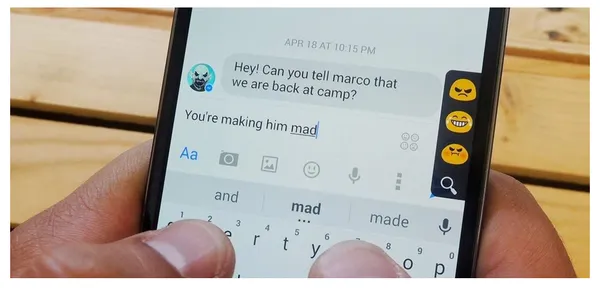
Autocompletado de búsqueda de Google
Cada vez que usamos un motor de búsqueda como Google para buscar algo, recibimos muchas ideas y, a medida que agregamos frases, las recomendaciones crecen mejor y más relevantes para nuestra búsqueda actual. ¿Cómo sucederá entonces?

La tecnología de procesamiento de lenguaje natural (NLP) lo hace factible. Aquí, emplearemos el procesamiento del lenguaje natural (NLP) para crear un modelo de predicción utilizando un modelo LSTM (memoria a largo plazo) bidireccional para predecir las palabras restantes de la oración.
Más información: ¿Qué es LSTM? Introducción a la memoria a largo plazo
Importar bibliotecas y paquetes necesarios
Lo mejor sería importar las bibliotecas y los paquetes necesarios para construir un modelo de predicción de la siguiente palabra mediante un LSTM bidireccional. A continuación se muestra una muestra de las bibliotecas que generalmente necesitará:
import pandas as pd
import os
import numpy as np import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import AdamInformación del conjunto de datos
Comprender las características y los atributos del conjunto de datos con el que está tratando requiere conocimiento. Los siguientes siete artículos de publicaciones medianas, seleccionados al azar y publicados en 2019, están incluidos en este conjunto de datos:
- Hacia la ciencia de datos
- Colectivo UX
- La puesta en marcha
- La Cooperativa de Escritura
- Inversor impulsado por datos
- Mejores humanos
- Mejor marketing
Enlace del conjunto de datos: https://www.kaggle.com/code/ysthehurricane/next-word-prediction-bi-lstm-tutorial-easy-way/input
medium_data = pd.read_csv('../input/medium-articles-dataset/medium_data.csv')
medium_data.head()
Aquí tenemos diez campos diferentes y 6508 registros, pero solo usaremos el campo de título para predecir la siguiente palabra.
print("Number of records: ", medium_data.shape[0])
print("Number of fields: ", medium_data.shape[1])
Al revisar y comprender la información del conjunto de datos, puede elegir los procedimientos de preprocesamiento, el modelo y las métricas de evaluación para su próximo desafío de predicción de palabras.
Mostrar títulos de varios artículos y preprocesarlos
Echemos un vistazo a algunos títulos de muestra para ilustrar la preparación de títulos de artículos:
medium_data['title']
Eliminación de caracteres y palabras no deseadas en los títulos
El preprocesamiento de datos de texto para tareas de predicción a veces incluye la eliminación de letras y frases no deseadas de los títulos. Las letras y palabras no deseadas pueden contaminar los datos con ruido y agregar una complejidad innecesaria, lo que reduce el rendimiento y la precisión del modelo.
- Caracteres no deseados:
- Puntuación: Debe eliminar los signos de admiración, interrogación, comas y otros signos de puntuación. Por lo general, puede descartarlos de manera segura porque generalmente no ayudan con la tarea de predicción.
- Caracteres especiales: Elimine los símbolos no alfanuméricos, como los signos de dólar, los símbolos @, las etiquetas y otros caracteres especiales, que no son necesarios para el trabajo de predicción.
- Etiquetas HTML: Si los títulos tienen marcas o etiquetas HTML, elimínelas con las herramientas o bibliotecas adecuadas para extraer el texto.
- Palabras no deseadas:
- Para las palabras: Elimine las palabras vacías comunes como "un", "un", "el", "es", "en" y otras palabras frecuentes que no tienen un significado significativo o poder predictivo.
- Palabras irrelevantes: Identifique y elimine palabras específicas que no sean relevantes para la tarea o el dominio de predicción. Por ejemplo, si está prediciendo géneros de películas, es posible que palabras como "película" o "película" no proporcionen información útil.
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace(u'xa0',u' '))
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace('u200a',' '))
Tokenization
Tokenization divide el texto en tokens, palabras, subpalabras o caracteres y luego asigna una identificación o índice único a cada token, creando un índice de palabras o vocabulario.
El proceso de tokenización implica los siguientes pasos:
Preprocesamiento de texto: Preprocesa el texto eliminando la puntuación, cambiándolo a minúsculas y ocupándote de cualquier tarea en particular o necesidades específicas del dominio.
Tokenización: Dividir el texto preprocesado en tokens separados mediante reglas o métodos predeterminados. Las expresiones regulares, la separación por espacios en blanco y el empleo de tokenizadores especializados son técnicas comunes de tokenización.
Aumentar el vocabulario Puede hacer un diccionario, también llamado índice de palabras, asignando a cada token una ID o índice único. En este proceso, cada ticket se asigna al valor de índice correspondiente.
tokenizer = Tokenizer(oov_token='<oov>') # For those words which are not found in word_index
tokenizer.fit_on_texts(medium_data['title'])
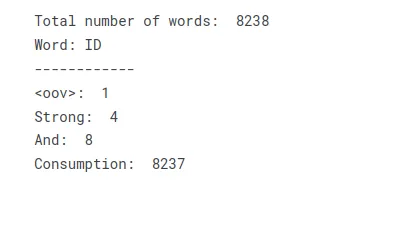
total_words = len(tokenizer.word_index) + 1 print("Total number of words: ", total_words)
print("Word: ID")
print("------------")
print("<oov>: ", tokenizer.word_index['<oov>'])
print("Strong: ", tokenizer.word_index['strong'])
print("And: ", tokenizer.word_index['and'])
print("Consumption: ", tokenizer.word_index['consumption'])Al transformar el texto en un vocabulario o índice de palabras, puede crear una tabla de búsqueda que represente el texto como una colección de índices numéricos. Cada palabra única en el texto recibe un valor de índice correspondiente, lo que permite un mayor procesamiento o operaciones de modelado que requieren entrada numérica.
Títulos Texto en Secuencias y Modelo Make N_gram.
Estas etapas se pueden usar para construir un modelo de n-grama para una predicción precisa basada en secuencias de títulos:
- Convertir títulos en secuencias: Use un tokenizador para convertir cada título en una cadena de tokens o separe manualmente cada ficha en sus palabras constituyentes. Asigne a cada palabra del léxico un índice numérico distinto.
- Generar n-gramas: A partir de las secuencias, haz n-gramas. Una ejecución continua de tokens de n títulos se denomina n-grama.
- Cuente la frecuencia: Determine la frecuencia con la que aparece cada n-grama en el conjunto de datos.
- Construya el modelo de n-gramas: Cree el modelo de n-grama utilizando las frecuencias de n-grama. El modelo realiza un seguimiento de la probabilidad de cada ficha dadas las n-1 fichas anteriores. Esto se puede mostrar como una tabla de búsqueda o un diccionario.
- Predecir la siguiente palabra: El próximo token esperado en una secuencia de n-1 token puede identificarse utilizando el modelo de n-grama. Para hacer esto, es necesario encontrar la probabilidad en el algoritmo y seleccionar un token con la mayor probabilidad.
Más información: ¿Qué son los N-gramas y cómo implementarlos en Python?
Puede usar estas etapas para construir un modelo de n-grama que utilice las secuencias de los títulos para predecir la siguiente palabra o token. Basado en los datos de entrenamiento, este método puede producir predicciones precisas ya que captura las relaciones estadísticas y las tendencias en el uso del idioma de los títulos.

input_sequences = []
for line in medium_data['title']: token_list = tokenizer.texts_to_sequences([line])[0] #print(token_list) for i in range(1, len(token_list)): n_gram_sequence = token_list[:i+1] input_sequences.append(n_gram_sequence) # print(input_sequences)
print("Total input sequences: ", len(input_sequences))
Haga que todos los títulos tengan la misma longitud mediante el uso de relleno
Puede usar relleno para asegurarse de que cada título tenga el mismo tamaño siguiendo estos pasos:
- Encuentre el título más largo en su conjunto de datos comparando todos los demás títulos.
- Repita este proceso para cada título, comparando la longitud de cada uno con el límite general.
- Cuando un título es demasiado corto, debe extenderse usando un token o carácter de relleno específico.
- Para cada título de su conjunto de datos, vuelva a realizar el procedimiento de relleno.
El relleno garantizará que todos los títulos tengan la misma longitud y brindará consistencia para el procesamiento posterior o el entrenamiento del modelo.
# pad sequences max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
input_sequences[1]
Preparar entidades y etiquetas
En el escenario dado, si consideramos el último elemento de cada secuencia de entrada como la etiqueta, podemos realizar una codificación one-hot en los títulos para representarlos como vectores correspondientes al número total de palabras únicas.
# create features and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words) print(xs[5])
print(labels[5])
print(ys[5][14])
La arquitectura de la red neuronal bidireccional LSTM
Redes neuronales recurrentes (RNN) con memoria a largo plazo (LSTM) puede recopilar y almacenar información en secuencias extensas. Las redes LSTM utilizan celdas de memoria especializadas y técnicas de activación para superar las limitaciones de los RNN regulares, que con frecuencia luchan con el problema del gradiente de fuga y tienen problemas para mantener la dependencia a largo plazo.
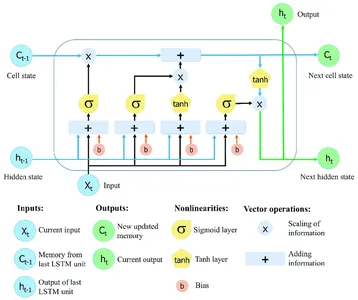
La característica crítica de las redes LSTM es el estado de la celda, que sirve como una unidad de memoria que puede almacenar información a lo largo del tiempo. El estado de la celda está protegido y controlado por tres puertas principales: la puerta de olvido, la puerta de entrada y la puerta de salida. Estas puertas regulan el flujo de información hacia, desde y dentro de la celda LSTM, lo que permite que la red recuerde u olvide información en diferentes pasos de tiempo de forma selectiva.
Más información: Memoria a corto plazo | Arquitectura de LSTM
LSTM bidireccional
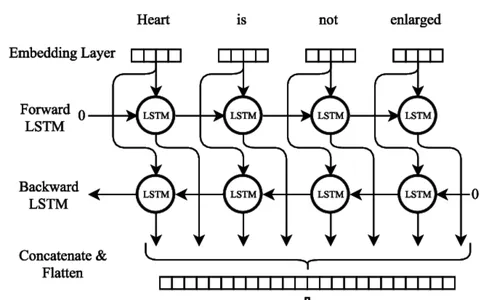
Entrenamiento del modelo de red neuronal Bi-LSTM
Se deben seguir numerosos procedimientos cruciales al entrenar un modelo de red neuronal bidireccional LSTM (Bi-LSTM). El primer paso es compilar un conjunto de datos de entrenamiento con las secuencias de entrada y salida correspondientes, indicando la siguiente palabra. Los datos de texto deben preprocesarse dividiéndolos en líneas separadas, eliminando la puntuación y cambiando el caso a minúsculas.
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
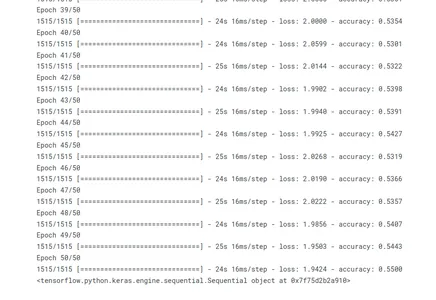
history = model.fit(xs, ys, epochs=50, verbose=1)
#print model.summary()
print(model)
Al llamar al método fit(), se entrena el modelo. Los datos de entrenamiento consisten en secuencias de entrada (xs) y secuencias de salida coincidentes (ys). El modelo procede a través de 50 iteraciones, pasando por todo el conjunto de entrenamiento. Durante el proceso de entrenamiento, se muestra el progreso del entrenamiento (verbose=1).
Precisión y pérdida del modelo de trazado
Graficar la precisión y la pérdida de un modelo a lo largo del entrenamiento ofrece información detallada sobre qué tan bien se desempeña y cómo va el entrenamiento. El error o disparidad entre los valores anticipados y reales se denomina pérdida. Mientras que el porcentaje de predicciones precisas generadas por el modelo se conoce como precisión.
import matplotlib.pyplot as plt def plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show() plot_graphs(history, 'accuracy')
plot_graphs(history, 'loss')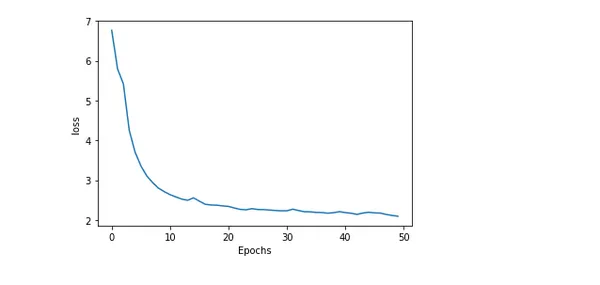
Predecir la siguiente palabra del título
Un desafío fascinante en el procesamiento del lenguaje natural es adivinar la siguiente palabra en un título. Los modelos pueden proponer la conversación más probable al buscar patrones y correlaciones en los datos de texto. Este poder predictivo hace que aplicaciones como los sistemas de sugerencia de texto y el autocompletado sean posibles. Los enfoques sofisticados como RNN y arquitecturas basadas en transformadores aumentan la precisión y capturan las relaciones contextuales.
seed_text = "implementation of"
next_words = 2 for _ in range(next_words): token_list = tokenizer.texts_to_sequences([seed_text])[0] token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre') predicted = model.predict_classes(token_list, verbose=0) output_word = "" for word, index in tokenizer.word_index.items(): if index == predicted: output_word = word break seed_text += " " + output_word
print(seed_text)
Conclusión
En conclusión, entrenar un modelo para predecir la siguiente palabra en una cadena de palabras es el emocionante desafío de procesamiento del lenguaje natural conocido como predicción de la siguiente palabra usando un LSTM bidireccional. Aquí está la conclusión resumida en viñetas:
- La potente arquitectura de aprendizaje profundo BI-LSTM para el procesamiento secuencial de datos puede capturar relaciones de largo alcance y contexto de frases.
- Para preparar datos de texto sin procesar para el entrenamiento BI-LSTM, la preparación de datos es esencial. Esto incluye tokenización, generación de vocabulario y vectorización de texto.
- Crear una función de pérdida, construir el modelo usando un optimizador, ajustarlo a datos preprocesados y evaluar su rendimiento en conjuntos de validación son los pasos para entrenar el modelo BI-LSTM.
- La predicción de la siguiente palabra BI-LSTM requiere una combinación de conocimiento teórico y experimentación práctica para dominar.
- Los algoritmos de autocompletado, creación de idiomas y sugerencias de texto son ejemplos de aplicaciones de modelos de predicción de la siguiente palabra.
Las aplicaciones para la predicción de la siguiente palabra incluyen chatbots, traducción automática y finalización de texto. Puede crear modelos de predicción de la siguiente palabra más precisos y sensibles al contexto con más investigación y mejoras.
Preguntas frecuentes
R. La predicción de la siguiente palabra es una tarea de PNL en la que un modelo predice la palabra más probable para seguir una secuencia de palabras o contexto determinado. Su objetivo es generar sugerencias coherentes y contextualmente relevantes para la siguiente palabra en función de los patrones y las relaciones aprendidas de los datos de entrenamiento.
R. La predicción de la siguiente palabra suele utilizar redes neuronales recurrentes (RNN) y sus variantes, como la memoria a corto plazo (LSTM) y la unidad recurrente cerrada (GRU). Además, modelos como las arquitecturas basadas en transformadores, como los modelos GPT (Generative Pre-trained Transformer), también han mostrado avances significativos en esta tarea.
R. Por lo general, al preparar datos de entrenamiento para la predicción de la siguiente palabra, divide el texto en secuencias de palabras y crea pares de entrada y salida. La salida correspondiente representa la siguiente palabra en el texto para cada secuencia de entrada. El preprocesamiento del texto implica eliminar la puntuación, convertir las palabras a minúsculas y tokenizar el texto en palabras individuales.
R. Puede evaluar el rendimiento de un modelo de predicción de la siguiente palabra mediante métricas de evaluación como la perplejidad, la precisión o la precisión de las k principales. La perplejidad mide qué tan bien el modelo predice la siguiente palabra dado el contexto. Las métricas de precisión comparan la palabra predicha con la verdad básica, mientras que la precisión top-k considera la predicción del modelo dentro de los comentarios más probables top-k.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/07/next-word-prediction-with-bidirectional-lstm/

