Introducción
Preguntas y respuestas sobre datos personalizados es uno de los casos de uso más buscados de modelos de lenguaje grandes. Las habilidades conversacionales humanas de los LLM combinadas con métodos de recuperación de vectores hacen que sea mucho más fácil extraer respuestas de documentos grandes. Con algunas variaciones, podemos crear sistemas para interactuar con cualquier dato (estructurado, no estructurado y semiestructurado) almacenado como incrustaciones en una base de datos vectorial. Este método de aumentar los LLM con datos recuperados en función de puntuaciones de similitud entre la incrustación de consultas y la incrustación de documentos se llama RAG o Generación Aumentada de Recuperación. Este método puede facilitar muchas cosas, como leer artículos de arXiv.
Si te gustan la IA y la informática, debes haber escuchado "arXiv" al menos una vez. arXiv es un repositorio de acceso abierto para preimpresiones y posimpresiones electrónicas. Alberga artículos verificados pero no revisados por pares sobre diversos temas, como aprendizaje automático, inteligencia artificial, matemáticas, física, estadística, electrónica, etc. arXiv ha desempeñado un papel fundamental en el impulso de la investigación abierta en inteligencia artificial y ciencias duras. Sin embargo, leer artículos de investigación suele ser arduo y requiere mucho tiempo. Entonces, ¿podemos mejorar esto un poco usando un chatbot RAG que nos permita extraer contenido relevante del documento y obtener respuestas?
En este artículo, crearemos un chatbot RAG para artículos aXiv utilizando una herramienta de código abierto llamada Haystack.

OBJETIVOS DE APRENDIZAJE
- ¿Entiendes qué es Haystack? Y sus componentes para crear aplicaciones basadas en LLM.
- Cree un componente para recuperar documentos Arxiv utilizando la biblioteca "arxiv".
- Aprenda a crear canales de indexación y consultas con nodos Haystack.
- Aprenda a crear una interfaz de chat con Gradio, coordinar canales para recuperar documentos de un almacén de vectores y generar respuestas de un LLM.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué es Haystack?
Haystack es un marco de PNL todo en uno de código abierto para crear aplicaciones escalables basadas en LLM. Haystack proporciona un enfoque altamente modular y personalizable para crear aplicaciones de PNL listas para producción, como búsqueda semántica, respuesta a preguntas, RAG, etc. Se basa en el concepto de canalizaciones y nodos; Las canalizaciones proporcionan un enfoque muy simplificado para organizar nodos para crear aplicaciones de PNL eficientes.
- Nodes: Los nodos son los componentes fundamentales de Haystack. Un nodo logra una sola cosa, como preprocesar documentos, recuperarlos de almacenes de vectores, generar respuestas de LLM, etc.
- Tubería: La canalización ayuda a conectar un nodo con otro para construir una cadena de nodos. Esto facilita la creación de aplicaciones con Haystack.
Haystack también tiene soporte listo para usar para las principales tiendas de vectores, como Weaviate, Milvus, Elastic Search, Qdrant, etc. Consulte el repositorio público de Haystack para obtener más información: https://github.com/deepset-ai/haystack.
Entonces, en este artículo, usaremos Haystack para crear un chatbot de preguntas y respuestas para artículos de Arxiv con una interfaz Gradio.
Gradio
Gradio es una solución de código abierto de Huggingface para configurar y compartir una demostración de cualquier aplicación de aprendizaje automático. Está impulsado por Fastapi en el backend y esbelto para los componentes frontales. Nos permite escribir aplicaciones web personalizables con Python. Ideal para crear y compartir aplicaciones de demostración para modelos de aprendizaje automático o pruebas de conceptos. Para obtener más información, visite el sitio oficial de Gradio. GitHub. Para explorar más sobre la creación de aplicaciones con Gradio, consulte este artículo, "Construyamos Chat GPT con Gradio."
Construyendo el chatbot
Antes de crear la aplicación, describamos brevemente el flujo de trabajo. Comienza cuando un usuario proporciona la identificación del documento Arxiv y termina recibiendo respuestas a las consultas. Entonces, aquí hay un flujo de trabajo simple de nuestro chatbot Arxiv.
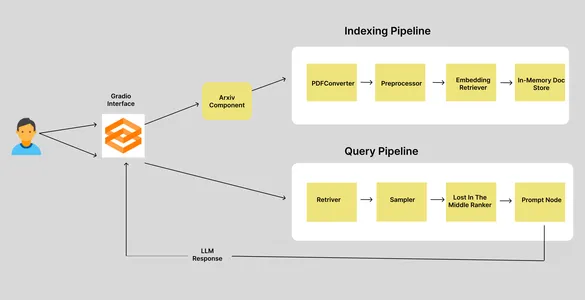
Tenemos dos canales: el canal de indexación y el canal de consulta. Cuando un usuario ingresa el ID de un artículo de Arxiv, va al componente Arxiv, que recupera y descarga el documento correspondiente en un directorio específico y activa el proceso de indexación. El proceso de indexación consta de cuatro nodos, cada uno de los cuales es responsable de realizar una única tarea. Entonces, veamos qué hacen estos nodos.
Canal de indexación
En un Haystack Pipeline, la salida del nodo anterior se utilizará como entrada del nodo actual. En un proceso de indexación, la entrada inicial es la ruta al documento.
- PDFToTextConverter: La biblioteca Arxiv nos permite descargar artículos en formato PDF. Pero necesitamos los datos del texto. Entonces, este nodo extrae los textos del PDF.
- Preprocesador: los datos extraídos deben limpiarse y procesarse antes de almacenarlos en la base de datos vectorial. Este nodo es responsable de limpiar y fragmentar textos.
- EmbeddingRetriver: este nodo define el almacén de vectores donde se deben almacenar los datos y el modelo de incrustación utilizado para obtener incrustaciones.
- InMemoryDocumentStore: este es el almacén de vectores donde se almacenan las incrustaciones. En este caso, hemos utilizado el almacén de documentos en memoria predeterminado de Haystacks. Pero también puedes utilizar otras tiendas de vectores, como Qdrant, Weaviate, Elastic Search, Milvus, etc.
Canalización de consultas
La canalización de consultas se activa cuando el usuario envía consultas. La canalización de consultas recupera "k" documentos más cercanos a las incrustaciones de consultas del almacén de vectores y genera una respuesta LLM. También tenemos cuatro nodos aquí.
- Recuperador: recupera el documento "k" más cercano a las incrustaciones de consulta del almacén de vectores.
- Sampler: filtre documentos según la probabilidad acumulada de las puntuaciones de similitud entre la consulta y los documentos utilizando el muestreo p superior.
- LostInTheMiddleRanker: este algoritmo reordena los documentos extraídos. Coloca los documentos más relevantes al principio o al final del contexto.
- PromptNode: PromptNode es responsable de generar respuestas a las consultas desde el contexto proporcionado al LLM.
Entonces, se trataba del flujo de trabajo de nuestro chatbot Arxiv. Ahora, profundicemos en la parte de codificación.
Configurar el entorno de desarrollo
Antes de instalar cualquier dependencia, cree un entorno virtual. Puede utilizar Venv y Poetry para crear un entorno virtual.
python -m venv my-env-name source bin/activateAhora, instale las siguientes dependencias de desarrollo. Para descargar artículos de Arxiv, necesitamos tener instalada la biblioteca Arxiv.
farm-haystack
arxiv
gradio
Ahora importaremos las bibliotecas.
import arxiv
import os
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes import ( EmbeddingRetriever, PreProcessor, PDFToTextConverter, PromptNode, PromptTemplate, TopPSampler )
from haystack.nodes.ranker import LostInTheMiddleRanker
from haystack.pipelines import Pipeline
import gradio as grConstruyendo el componente Arxiv
Este componente será responsable de descargar y almacenar archivos PDF Arxiv. Entonces. así es como definimos el componente.
class ArxivComponent: """ This component is responsible for retrieving arXiv articles based on an arXiv ID. """ def run(self, arxiv_id: str = None): """ Retrieves and stores an arXiv article for the given arXiv ID. Args: arxiv_id (str): ArXiv ID of the article to be retrieved. """ # Set the directory path where arXiv articles will be stored dir: str = DIR # Create an instance of the arXiv client arxiv_client = arxiv.Client() # Check if an arXiv ID is provided; if not, raise an error if arxiv_id is None: raise ValueError("Please provide the arXiv ID of the article to be retrieved.") # Search for the arXiv article using the provided arXiv ID search = arxiv.Search(id_list=[arxiv_id]) response = arxiv_client.results(search) paper = next(response) # Get the first result title = paper.title # Extract the title of the article # Check if the specified directory exists if os.path.isdir(dir): # Check if the PDF file for the article already exists if os.path.isfile(dir + "/" + title + ".pdf"): return {"file_path": [dir + "/" + title + ".pdf"]} else: # If the directory does not exist, create it os.mkdir(dir) # Attempt to download the PDF for the arXiv article try: paper.download_pdf(dirpath=dir, filename=title + ".pdf") return {"file_path": [dir + "/" + title + ".pdf"]} except: # If there's an error during the download, raise a ConnectionError raise ConnectionError(message=f"Error occurred while downloading PDF for arXiv article with ID: {arxiv_id}")
El componente anterior inicializa un cliente Arxiv, luego recupera el artículo de Arxiv asociado con el ID y verifica si ya se ha descargado; devuelve la ruta del PDF o lo descarga al directorio.
Construyendo el proceso de indexación
Ahora, definiremos el proceso de indexación para procesar y almacenar documentos en nuestra base de datos vectorial.
document_store = InMemoryDocumentStore()
embedding_retriever = EmbeddingRetriever( document_store=document_store, embedding_model="sentence-transformers/All-MiniLM-L6-V2", model_format="sentence_transformers", top_k=10 )
def indexing_pipeline(file_path: str = None): pdf_converter = PDFToTextConverter() preprocessor = PreProcessor(split_by="word", split_length=250, split_overlap=30) indexing_pipeline = Pipeline() indexing_pipeline.add_node( component=pdf_converter, name="PDFConverter", inputs=["File"] ) indexing_pipeline.add_node( component=preprocessor, name="PreProcessor", inputs=["PDFConverter"] ) indexing_pipeline.add_node( component=embedding_retriever, name="EmbeddingRetriever", inputs=["PreProcessor"] ) indexing_pipeline.add_node( component=document_store, name="InMemoryDocumentStore", inputs=["EmbeddingRetriever"] ) indexing_pipeline.run(file_paths=file_path)Primero, definimos nuestro almacén de documentos en memoria y luego el recuperador de incrustación. En el recuperador de incrustación, especificamos el almacén de documentos, los modelos de incrustación y la cantidad de documentos que se recuperarán.
También hemos definido los cuatro nodos que comentamos anteriormente. pdf_converter convierte PDF a texto, el preprocesador limpia y crea fragmentos de texto, embedding_retriever realiza incrustaciones de documentos e InMemoryDocumentStore almacena incrustaciones de vectores. El método de ejecución con la ruta del archivo activa la canalización y cada nodo se ejecuta en el orden en que se han definido. También puede observar cómo cada nodo utiliza las salidas de los nodos anteriores como entradas.
Construyendo el canal de consultas
La canalización de consultas también consta de cuatro nodos. Este es responsable de incrustar el texto consultado, encontrar documentos similares en almacenes de vectores y, finalmente, generar respuestas de LLM.
def query_pipeline(query: str = None): if not query: raise gr.Error("Please provide a query.") prompt_text = """
Synthesize a comprehensive answer from the provided paragraphs of an Arxiv article and the given question.n
Focus on the question and avoid unnecessary information in your answer.n
nn Paragraphs: {join(documents)} nn Question: {query} nn Answer: """ prompt_node = PromptNode( "gpt-3.5-turbo", default_prompt_template=PromptTemplate(prompt_text), api_key="api-key", max_length=768, model_kwargs={"stream": False}, ) query_pipeline = Pipeline() query_pipeline.add_node( component = embedding_retriever, name = "Retriever", inputs=["Query"] ) query_pipeline.add_node( component=TopPSampler( top_p=0.90), name="Sampler", inputs=["Retriever"] ) query_pipeline.add_node( component=LostInTheMiddleRanker(1024), name="LostInTheMiddleRanker", inputs=["Sampler"] ) query_pipeline.add_node( component=prompt_node, name="Prompt", inputs=["LostInTheMiddleRanker"] ) pipeline_obj = query_pipeline.run(query = query) return pipeline_obj["results"]embedding_retriever recupera "k" documentos similares del almacén de vectores. El Sampler es responsable de muestrear los documentos. LostInTheMiddleRanker clasifica los documentos al principio o al final del contexto según su relevancia. Finalmente, el símbolo_nodo, donde el LLM es "gpt-3.5-turbo". También agregamos una plantilla de mensajes para agregar más contexto a la conversación. El método de ejecución devuelve un objeto de canalización, un diccionario.
Este fue nuestro backend. Ahora, diseñamos la interfaz.
Interfaz de radio
Tiene una clase de Bloques para crear una interfaz web personalizable. Entonces, para este proyecto, necesitamos un cuadro de texto que tome el ID de Arxiv como entrada del usuario, una interfaz de chat y un cuadro de texto que tome las consultas de los usuarios. Así es como podemos hacerlo.
with gr.Blocks() as demo: with gr.Row(): with gr.Column(scale=60): text_box = gr.Textbox(placeholder="Input Arxiv ID", interactive=True).style(container=False) with gr.Column(scale=40): submit_id_btn = gr.Button(value="Submit") with gr.Row(): chatbot = gr.Chatbot(value=[]).style(height=600) with gr.Row(): with gr.Column(scale=70): query = gr.Textbox(placeholder = "Enter query string", interactive=True).style(container=False)Ejecute el comando gradio app.py en su línea de comando y visite la URL del host local que se muestra.
Ahora, necesitamos definir los eventos desencadenantes.
submit_id_btn.click( fn = embed_arxiv, inputs=[text_box], outputs=[text_box], )
query.submit( fn=add_text, inputs=[chatbot, query], outputs=[chatbot, ], queue=False ).success( fn=get_response, inputs = [chatbot, query], outputs = [chatbot,] )
demo.queue()
demo.launch()Para que los eventos funcionen, necesitamos definir las funciones mencionadas en cada evento. Haga clic en submit_iid_btn, envíe la entrada del cuadro de texto como parámetro a la función embed_arxiv. Esta función coordinará la búsqueda y el almacenamiento del PDF de Arxiv en el almacén de vectores.
arxiv_obj = ArxivComponent()
def embed_arxiv(arxiv_id: str): """ Args: arxiv_id: Arxiv ID of the article to be retrieved. """ global FILE_PATH dir: str = DIR file_path: str = None if not arxiv_id: raise gr.Error("Provide an Arxiv ID") file_path_dict = arxiv_obj.run(arxiv_id) file_path = file_path_dict["file_path"] FILE_PATH = file_path indexing_pipeline(file_path=file_path) return"Successfully embedded the file"Definimos un objeto ArxivComponent y la función embed_arxiv. Ejecuta el método "ejecutar" y utiliza la ruta del archivo devuelto como parámetro para el canal de indexación.
Ahora, pasamos al evento de envío con la función add_text como parámetro. Este es responsable de representar el chat en la interfaz de chat.
def add_text(history, text: str): if not text: raise gr.Error('enter text') history = history + [(text,'')] return historyAhora, definimos la función get_response, que recupera y transmite respuestas de LLM en la interfaz de chat.
def get_response(history, query: str): if not query: gr.Error("Please provide a query.") response = query_pipeline(query=query) for text in response[0]: history[-1][1] += text yield history, ""Esta función toma la cadena de consulta y la pasa al Query Pipeline para obtener una respuesta. Finalmente, iteramos sobre la cadena de respuesta y la devolvemos al chatbot.
Poniendolo todo junto.
# Create an instance of the ArxivComponent class
arxiv_obj = ArxivComponent() def embed_arxiv(arxiv_id: str): """ Retrieves and embeds an arXiv article for the given arXiv ID. Args: arxiv_id (str): ArXiv ID of the article to be retrieved. """ # Access the global FILE_PATH variable global FILE_PATH # Set the directory where arXiv articles are stored dir: str = DIR # Initialize file_path to None file_path: str = None # Check if arXiv ID is provided if not arxiv_id: raise gr.Error("Provide an Arxiv ID") # Call the ArxivComponent's run method to retrieve and store the arXiv article file_path_dict = arxiv_obj.run(arxiv_id) # Extract the file path from the dictionary file_path = file_path_dict["file_path"] # Update the global FILE_PATH variable FILE_PATH = file_path # Call the indexing_pipeline function to process the downloaded article indexing_pipeline(file_path=file_path) return "Successfully embedded the file" def get_response(history, query: str): if not query: gr.Error("Please provide a query.") # Call the query_pipeline function to process the user's query response = query_pipeline(query=query) # Append the response to the chat history for text in response[0]: history[-1][1] += text yield history def add_text(history, text: str): if not text: raise gr.Error('Enter text') # Add user-provided text to the chat history history = history + [(text, '')] return history # Create a Gradio interface using Blocks
with gr.Blocks() as demo: with gr.Row(): with gr.Column(scale=60): # Text input for Arxiv ID text_box = gr.Textbox(placeholder="Input Arxiv ID", interactive=True).style(container=False) with gr.Column(scale=40): # Button to submit Arxiv ID submit_id_btn = gr.Button(value="Submit") with gr.Row(): # Chatbot interface chatbot = gr.Chatbot(value=[]).style(height=600) with gr.Row(): with gr.Column(scale=70): # Text input for user queries query = gr.Textbox(placeholder="Enter query string", interactive=True).style(container=False) # Define the actions for button click and query submission submit_id_btn.click( fn=embed_arxiv, inputs=[text_box], outputs=[text_box], ) query.submit( fn=add_text, inputs=[chatbot, query], outputs=[chatbot, ], queue=False ).success( fn=get_response, inputs=[chatbot, query], outputs=[chatbot,] ) # Queue and launch the interface
demo.queue()
demo.launch()
Ejecute la aplicación usando el comando gradio app.py y visite la URL para interactuar con Arxic Chatbot.
Así se verá.
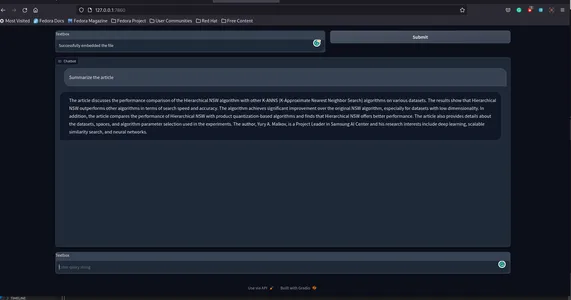
Aquí está el repositorio GitHub de la aplicación. sunilkumardash9/chat-arxiv.
Posibles mejoras
Hemos creado con éxito una aplicación sencilla para chatear con cualquier documento Arxiv, pero se pueden realizar algunas mejoras.
- Tienda de vectores independiente: En lugar de utilizar el almacén de vectores ya preparado, puede utilizar almacenes de vectores independientes disponibles con Haystack, como Weaviate, Milvus, etc. Esto no sólo le dará más flexibilidad sino también importantes mejoras de rendimiento.
- Citaciones: Podemos agregar certeza a las respuestas del LLM agregando citas adecuadas.
- más características: En lugar de solo una interfaz de chat, podemos agregar funciones para representar páginas de PDF utilizadas como fuentes para las respuestas de LLM. Mira este artículo, “Cree un ChatGPT para archivos PDF con Langchain", y el Repositorio GitHub para una aplicación similar.
- Frontend: Una interfaz mejor y más interactiva sería mucho mejor.
Conclusión
Entonces, se trataba de crear una aplicación de chat para los artículos de Arxiv. Esta aplicación no se limita sólo a Arxiv. También podemos extender esto a otros sitios, como PubMed. Con algunas modificaciones, también podemos utilizar una arquitectura similar para chatear con cualquier sitio web. Entonces, en este artículo, pasamos de crear un componente Arxiv para descargar documentos de Arxiv, incrustarlos usando canalizaciones de pajar y finalmente obtener respuestas del LLM.
Puntos clave
- Haystack es una solución de código abierto para crear aplicaciones de PNL escalables y listas para producción.
- Haystack proporciona un enfoque altamente modular para crear aplicaciones del mundo real. Proporciona nodos y canalizaciones para agilizar la recuperación de información, el preprocesamiento de datos, la integración y la generación de respuestas.
- Es una biblioteca de código abierto de Huggingface para crear rápidamente prototipos de cualquier aplicación. Proporciona una manera sencilla de compartir modelos de ML con cualquier persona.
- Utilice un flujo de trabajo similar para crear aplicaciones de chat para otros sitios, como PubMed.
Preguntas frecuentes
A. Cree chatbots de IA personalizados utilizando marcos de PNL modernos como Haystack, Llama Index y Langchain.
R. Los chatbots de respuesta a preguntas están diseñados específicamente utilizando métodos de PNL de vanguardia para responder preguntas sobre datos personalizados, como archivos PDF, hojas de cálculo, CSV, etc.
R. Haystack es un marco de PNL de código abierto para crear aplicaciones basadas en LLM, como agentes de inteligencia artificial, control de calidad, RAG, etc.
A. Arxiv es un repositorio de acceso abierto para publicar artículos de investigación en varias categorías, incluidas, entre otras, matemáticas, informática, física, estadística, etc.
R. Los chatbots de IA emplean tecnologías de procesamiento del lenguaje natural de vanguardia para ofrecer capacidades de conversación similares a las humanas.
R. Cree un chatbot de forma gratuita utilizando marcos de código abierto como Langchain, haystack, etc. Pero hacer inferencias desde LLM, como get-3.5, cuesta dinero.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/mastering-arxiv-searches-a-diy-guide-to-building-a-qa-chatbot-with-haystack/

