Recientemente introdujimos una nueva capacidad en el SDK de Amazon SageMaker Python que permite a los científicos de datos ejecutar su código de aprendizaje automático (ML) creado en su entorno de desarrollo integrado (IDE) y cuadernos preferidos junto con las dependencias de tiempo de ejecución asociadas como Amazon SageMaker trabajos de entrenamiento con cambios mínimos de código en la experimentación realizada localmente. Los científicos de datos suelen llevar a cabo varias iteraciones de experimentación en el procesamiento de datos y modelos de entrenamiento mientras trabajan en cualquier problema de ML. Quieren ejecutar este código ML y llevar a cabo la experimentación con facilidad de uso y cambios de código mínimos. Capacitación de modelos de Amazon SageMaker ayuda a los científicos de datos a ejecutar trabajos de capacitación a gran escala totalmente administrados en la infraestructura informática de AWS. SageMaker Training también ayuda a los científicos de datos con herramientas avanzadas como Depurador de Amazon SageMaker y Profiler para depurar y analizar sus trabajos de capacitación a gran escala.
Para los clientes con presupuestos pequeños, equipos pequeños y plazos ajustados, cada nuevo concepto y línea de código reescrito para ejecutarse en SageMaker los hace menos productivos para sus tareas principales, es decir, el procesamiento de datos y la capacitación de modelos de aprendizaje automático. Quieren escribir código una vez en el marco de su elección y poder pasar sin problemas de ejecutar código en sus notebooks o laptops a ejecutar código a escala utilizando las capacidades de SageMaker.
Con esta nueva capacidad de SageMaker Python SDK, los científicos de datos pueden incorporar su código ML a la plataforma de capacitación de SageMaker en unos minutos. Solo necesita agregar una sola línea de código a su código ML, y SageMaker comprende de manera inteligente su código junto con los conjuntos de datos y la configuración del entorno del espacio de trabajo y lo ejecuta como un trabajo de capacitación de SageMaker. Luego puede aprovechar las capacidades clave de la plataforma de capacitación de SageMaker, como la capacidad de escalar trabajos fácilmente y otras herramientas asociadas como Debugger y Profiler. En esta versión, puede ejecutar su código de Python de aprendizaje automático (ML) local como un trabajo de entrenamiento de Amazon SageMaker de un solo nodo o varios trabajos paralelos. Los trabajos de entrenamiento distribuidos (en varios nodos) no son compatibles con las funciones remotas.
En esta publicación, le mostramos cómo usar esta nueva capacidad para ejecutar código ML local como un trabajo de capacitación de SageMaker.
Resumen de la solución
Ahora puede ejecutar su código ML escrito en su IDE o notebook como un trabajo de capacitación de SageMaker al anotar la función, que actúa como un punto de entrada a la base de código del usuario, con un decorador simple. Tras la invocación, esta capacidad toma automáticamente una instantánea de todas las variables asociadas, funciones, paquetes, variables de entorno y otros requisitos de tiempo de ejecución de su código ML, los serializa y los envía como un trabajo de capacitación de SageMaker. Se integra con el recientemente anunciado Característica SageMaker Python SDK para establecer valores predeterminados para parámetros. Esta capacidad simplifica las construcciones de SageMaker que necesita aprender para poder ejecutar código mediante SageMaker Training. Los científicos de datos pueden escribir, depurar e iterar su código en cualquier IDE preferido (como Estudio Amazon SageMaker, cuadernos, VS Code o PyCharm). Cuando esté listo, puede anotar su función de Python con el @remote decorador y ejecútelo como un trabajo de SageMaker a escala.
Esta capacidad toma objetos Python de código abierto familiares como argumentos y salidas. Además, no es necesario que comprenda la administración del ciclo de vida del contenedor y simplemente puede ejecutar sus cargas de trabajo en diferentes contextos informáticos (como un IDE local, Studio o trabajos de capacitación) con gastos generales de configuración mínimos. Para ejecutar cualquier código local como un trabajo de capacitación de SageMaker, esta capacidad deduce las configuraciones necesarias para ejecutar trabajos, como el Gestión de identidades y accesos de AWS (IAM), clave de cifrado y configuración de red, desde la configuración de Studio o IDE (que puede ser la ajustes por defecto) y los pasa a la plataforma por defecto. Tiene la flexibilidad de personalizar su tiempo de ejecución en la infraestructura administrada de SageMaker mediante la configuración inferida o anularlos en el nivel de SDK pasándolos como argumentos al decorador.
Esta nueva capacidad de SageMaker Python SDK transforma su código ML en un entorno de espacio de trabajo existente y cualquier código de procesamiento de datos y conjuntos de datos asociados en un trabajo de capacitación de SageMaker. Esta capacidad busca código ML envuelto dentro de un @remote decorador y lo traduce automáticamente a un trabajo que se ejecuta en Studio o en un IDE local como PyCharm.
En las siguientes secciones, explicamos las características de esta nueva capacidad y cómo iniciar funciones de Python como trabajos de capacitación de SageMaker.
Requisitos previos
Para usar esta nueva capacidad del SDK de Python de SageMaker y ejecutar el código asociado con esta publicación, necesita los siguientes requisitos previos:
- Una cuenta de AWS que contendrá todos sus recursos de AWS
- Un rol de IAM para acceder a SageMaker
- Acceso a Studio o una instancia de notebook de SageMaker o un IDE como PyCharm
Utilice el SDK de las libretas Studio y SageMaker
Puede usar esta capacidad desde Studio iniciando un cuaderno y envolviendo su código con un @remote decorador dentro del cuaderno. Primero necesita importar la función remota usando el siguiente código:
from sagemaker.remote_function import remoteCuando utilice la función de decorador, esta función interpretará automáticamente la función de su código y la ejecutará como un trabajo de capacitación de SageMaker.
También puede usar esta capacidad desde una instancia de notebook de SageMaker. Primero debe iniciar una instancia de notebook, abrir Jupyter o Jupyter Lab en ella e iniciar una notebook. Luego importe la función remota como se muestra en el código anterior y envuelva su código con el @remote decorador. Incluimos un ejemplo de cómo usar la función de decorador y la configuración asociada más adelante en esta publicación.
Utilice el SDK de su entorno local
También puede usar esta capacidad desde su IDE local. Como requisito previo, debe tener la Interfaz de línea de comandos de AWS (AWS CLI), SageMaker Python SDK y AWS SDK para Python (Boto3) instalado en su entorno local. Debe importar estas bibliotecas en su código, configurar la sesión de SageMaker, especificar la configuración y decorar su función con el @remote decorador. En el siguiente código de ejemplo, ejecutamos una función de división simple como un trabajo de capacitación de SageMaker:
import boto3
import sagemaker
from sagemaker.remote_function import remote sm_session = sagemaker.Session(boto_session=boto3.session.Session(region_name="us-west-2"))
settings = dict(
sagemaker_session=sm_session,
role=<IAM_ROLE_NAME>
instance_type="ml.m5.xlarge",
)
@remote(**settings)
def divide(x, y):
return x / y
if __name__ == "__main__":
print(divide(2, 3.0))Podemos usar una metodología similar para ejecutar funciones avanzadas como trabajos de entrenamiento, como se muestra en la siguiente sección.
Inicie funciones de Python como trabajos de SageMaker
La nueva característica SageMaker Python SDK le permite ejecutar funciones de Python como Empleos de Capacitación de SageMaker. Cualquier código de Python, código de entrenamiento de ML desarrollado por científicos de datos usando sus IDE locales preferidos (PyCharm, VS Code), cuadernos de SageMaker o cuadernos de Studio se puede iniciar como un trabajo de SageMaker administrado.
En las cargas de trabajo de ML que utilizan esta capacidad, los conjuntos de datos asociados, las dependencias y las configuraciones del entorno del espacio de trabajo se serializan mediante el código de ML y se ejecutan como un trabajo de SageMaker de forma sincrónica y asincrónica.
Puede agregar un @remote anotación de decorador a cualquier código de Python, incluida una función de capacitación o procesamiento de ML local para iniciarlo como un trabajo de capacitación de SageMaker administrado, y así aprovechar las ventajas de escala, rendimiento y costo de SageMaker. Esto se puede lograr con cambios mínimos en el código agregando un decorador al código de la función de Python. La invocación a la función decorada se ejecuta sincrónicamente y la ejecución de la función espera hasta que finaliza el trabajo de SageMaker.
En el siguiente ejemplo, usamos el @remote decorador para iniciar trabajos de SageMaker en modo decorador utilizando una instancia ml.m5.large. SageMaker usa trabajos de entrenamiento para iniciar esta función como un trabajo administrado.
from sagemaker.remote_function import remote
from numpy as np @remote(instance_type="ml.m5.large")
def matrix_multiply(a, b): return np.matmul(a, b) a = np.array([[1, 0], [0, 1]])
b = np.array([1, 2]) assert matrix_multiply(a, b) == np.array([1,2])También puede usar el modo decorador para iniciar trabajos de SageMaker, paquetes de Python y dependencias. Puede incluir variables de entorno como VPC, subredes y grupos de seguridad para iniciar trabajos de capacitación de SageMaker en el environment.yml archivo. Esto permite a los ingenieros y administradores de ML configurar estas variables de entorno para que los científicos de datos puedan centrarse en la creación de modelos de ML e iterar más rápido. Ver el siguiente código:
from sagemaker.remote_function import remote @remote(instance_type="ml.g4dn.xlarge",dependencies = "./environment.yml")
def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
... <TRUCNATED>
return os.path.join(s3_output_path, model_dir), eval_resultPuedes usar RemoteExecutor para iniciar funciones de Python como trabajos de SageMaker de forma asincrónica. El ejecutor sondea de forma asíncrona los trabajos de SageMaker Training para actualizar el estado del trabajo. El RemoteExecutor La clase es una implementación de la Ejecutor.de.futuros.concurrentes, que se utiliza para enviar trabajos de formación de SageMaker de forma asincrónica. Ver el siguiente código:
from sagemaker.remote_function import RemoteExecutor def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
...<TRUNCATED>
return os.path.join(s3_output_path, model_dir), eval_result with RemoteExecutor(instance_type="ml.g4dn.xlarge", dependencies = './requirements.txt') as e:
future = e.submit(train_hf_model, train_input_path,test_input_path,s3_output_path,
epochs, train_batch_size, eval_batch_size,warmup_steps,learning_rate)Personalizar el entorno de tiempo de ejecución
Modo decorador y RemoteExecutor le permiten definir y personalizar los entornos de tiempo de ejecución para el trabajo de SageMaker. Las dependencias del tiempo de ejecución, incluidos los paquetes de Python y las variables de entorno para los trabajos de SageMaker, se pueden especificar para personalizar el tiempo de ejecución. Para ejecutar el código local de Python como trabajos administrados por SageMaker, el paquete de Python y las dependencias deben estar disponibles para SageMaker. Los ingenieros de aprendizaje automático o los administradores de ciencia de datos pueden configurar configuraciones de red y seguridad, como VPC, subredes y grupos de seguridad para trabajos de SageMaker, de modo que los científicos de datos puedan usar estas configuraciones administradas de forma centralizada al iniciar trabajos de SageMaker. Puedes usar un requirements.txt Archivo o un Conda environment.yaml archivo.
Cuando las dependencias se definen con requirements.txt, los paquetes se instalarán mediante pip en el tiempo de ejecución del trabajo. Si la imagen utilizada para ejecutar el trabajo viene con entornos Conda, los paquetes se instalarán en el entorno Conda declarado para uso en trabajos. El siguiente código muestra un ejemplo. requirements.txt archivo:
datasets
transformers
torch
scikit-learn
s3fs==0.4.2
sagemaker>=2.148.0Puedes pasar tu Conda environment.yaml para crear el entorno de Conda en el que le gustaría que se ejecutara su código durante el trabajo de entrenamiento. Si la imagen utilizada para ejecutar el trabajo declara un entorno Conda para ejecutar el código, actualizaremos el entorno Conda declarado con la especificación dada. El siguiente código es un ejemplo de un Conda environment.yaml archivo:
name: sagemaker_example
channels: - conda-forge
dependencies: - python=3.10 - pandas - pip: - sagemakerAlternativamente, puede configurar dependencies=”auto_capture” para permitir que SageMaker Python SDK capture las dependencias instaladas en el entorno Conda activo. Debe tener un entorno Conda activo para auto_capture trabajar. Tenga en cuenta que hay requisitos previos para auto_capture trabajar; le recomendamos que pase sus dependencias como un requirement.txt or Conda environment.yml archivo como se describe en la sección anterior.
Para más detalles, consulte Ejecute su código local como un trabajo de capacitación de SageMaker.
Configuraciones para trabajos de SageMaker
Los ajustes relacionados con la infraestructura se pueden descargar en un archivo de configuración que los usuarios administradores pueden ayudar a configurar. Solo necesita configurarlo una vez. La configuración de la infraestructura cubre la configuración de la red, los roles de IAM, Servicio de almacenamiento simple de Amazon (Amazon S3) carpeta para entrada, datos de salida y etiquetas. Referirse a Configuración y uso de valores predeterminados con SageMaker Python SDK para más información.
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: path/to/requirements.txt
EnvironmentVariables: {"EnvVarKey": "EnvVarValue"}
ImageUri: 366666666666.dkr.ecr.us-west-2.amazonaws.com/my-image:latest
InstanceType: ml.m5.large
RoleArn: arn:aws:iam::366666666666:role/MyRole
S3KmsKeyId: somekmskeyid
S3RootUri: s3://my-bucket/my-project
SecurityGroupIds:
- sg123
Subnets:
- subnet-1234
Tags:
- {"Key": "someTagKey", "Value": "someTagValue"}
VolumeKmsKeyId: somekmskeyidImplementación
Los modelos de aprendizaje profundo como PyTorch o TensorFlow también se pueden ejecutar dentro de Studio ejecutando el código como un trabajo de entrenamiento dentro del cuaderno. Para mostrar esta capacidad en Studio, puede clonar este repositorio en su Studio y ejecutar el cuaderno ubicado en el GitHub repositorio.
Este ejemplo demuestra un caso de uso de clasificación de texto binario de extremo a extremo. Estamos utilizando la biblioteca de conjuntos de datos y transformadores Hugging Face para ajustar un transformador previamente entrenado en la clasificación de texto binario. En particular, el modelo pre-entrenado se ajustará usando el Conjunto de datos de IMDb.
Cuando clone el repositorio, debe ubicar los siguientes archivos:
- configuración.yaml – La mayoría de los argumentos del decorador se pueden descargar en el archivo de configuración para separar la configuración relacionada con la infraestructura del código base.
- abrazandolacara.ipynb – Esto contiene el código para entrenar un modelo HuggingFace previamente entrenado, que se ajustará utilizando el conjunto de datos de IMDB
- requerimientos.txt – Este archivo contiene todas las dependencias para ejecutar la función que se usará en este cuaderno para ejecutar el código y ejecutar el entrenamiento de forma remota en una instancia de GPU como un trabajo de entrenamiento.
Cuando abra el cuaderno, se le pedirá que configure el entorno del cuaderno. Puede seleccionar la imagen Data Science 3.0 con el kernel de Python 3 y ml.m5.large como el tipo de instancia de inicio rápido para ejecutar el código del cuaderno. Este tipo de instancia es significativamente más rápido en la puesta en marcha de un entorno.
El trabajo de entrenamiento se ejecutará en una instancia ml.g4dn.xlarge como se define en el config.yaml archivo:
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
# role arn is not required if in SageMaker Notebook instance or SageMaker Studio
# Uncomment the following line and replace with the right execution role if in a local IDE
# RoleArn: <IAM_ROLE_ARN>
InstanceType: ml.g4dn.xlarge
Dependencies: ./requirements.txtLa requirements.txt Las dependencias de archivo para ejecutar la función para entrenar el modelo Hugging Face incluyen lo siguiente:
datasets
transformers
torch
scikit-learn
# lock s3fs to this specific version as more recent ones introduce dependency on aiobotocore, which is not compatible with botocore
s3fs==0.4.2
sagemaker>=2.148.0,<3El cuaderno Hugging Face muestra cómo ejecutar la capacitación de forma remota a través del @remote función, que se ejecuta de forma síncrona. Por lo tanto, la ejecución de la función para entrenar el modelo esperará hasta que se complete el trabajo de entrenamiento de SageMaker. El entrenamiento se ejecutará de forma remota con una instancia de GPU en la que el tipo de instancia se define en el archivo de configuración anterior.
Después de ejecutar el trabajo de entrenamiento, puede ejecutar el resto de las celdas en el cuaderno para inspeccionar las métricas de evaluación y clasificar el texto en nuestro modelo entrenado.
También puede ver el estado del trabajo de capacitación que se activó de forma remota en la instancia de GPU en el panel de control de SageMaker volviendo a la consola de SageMaker.
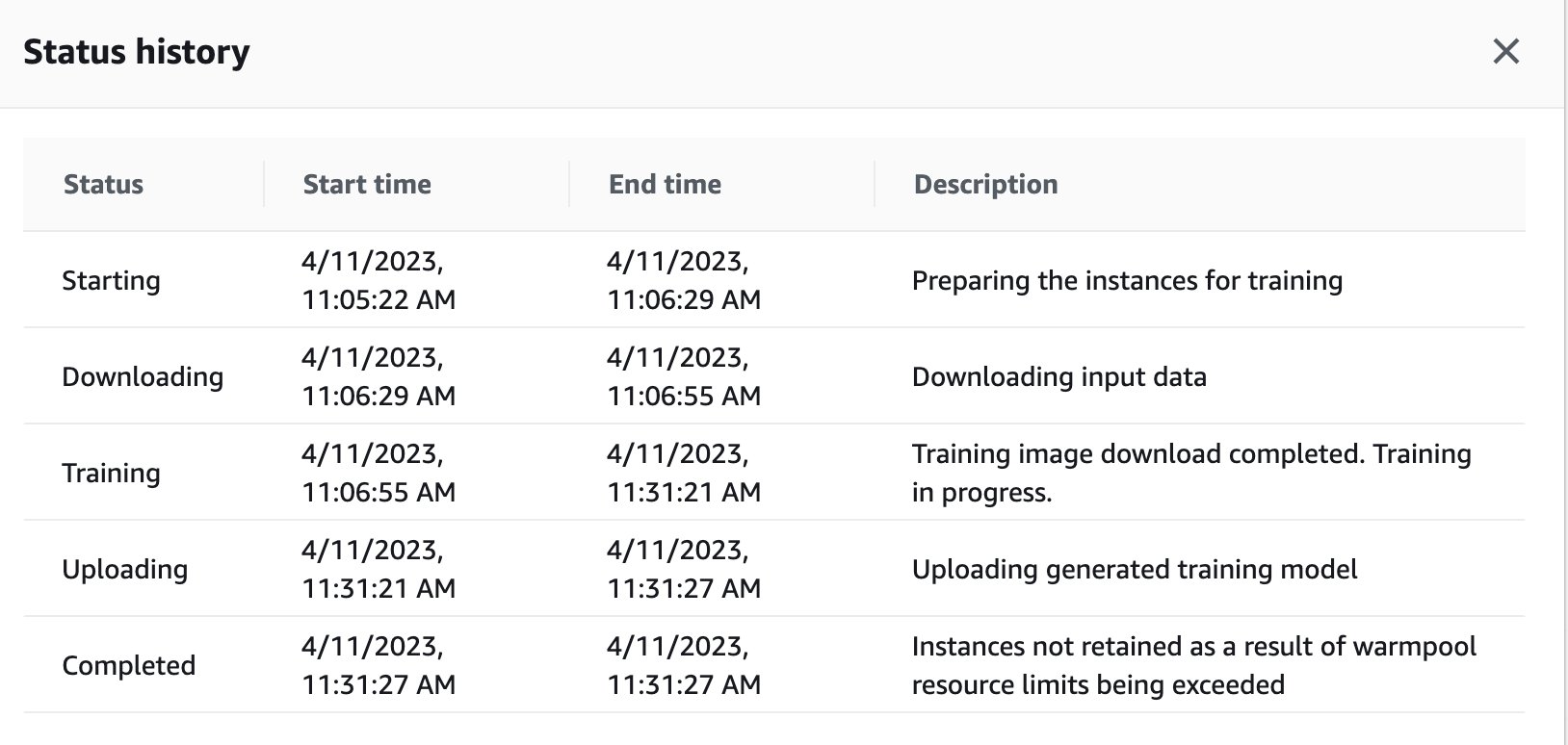
Tan pronto como se completa el trabajo de entrenamiento, continúa ejecutando las instrucciones en el cuaderno para su evaluación y clasificación. Se pueden entrenar y ejecutar trabajos similares a través de la función de ejecución remota integrada en los portátiles de Studio para llevar a cabo las ejecuciones de forma asincrónica.
Integración con experimentos de SageMaker dentro de una función @remote
Puede pasar el nombre de su experimento, el nombre de la ejecución y otros parámetros a su función remota para crear una ejecución de experimentos de SageMaker. El siguiente ejemplo de código importa el nombre del experimento, el nombre de la ejecución y los parámetros para registrar cada ejecución:
from sagemaker.remote_function import remote
from sagemaker.experiments.run import Run
# Define your remote function
@remote
def train(value_1, value_2, exp_name, run_name):
...
...
#Creates the experiment
with Run( experiment_name=exp_name, run_name=run_name, sagemaker_session=sagemaker_session
) as run:
...
...
#Define values for the parameters to log
run.log_parameter("param_1", value_1)
run.log_parameter("param_2", value_2)
...
...
#Define metrics to log
run.log_metric("metric_a", 0.5)
run.log_metric("metric_b", 0.1) # Invoke your remote function
train(1.0, 2.0, "my-exp-name", "my-run-name") En el ejemplo anterior, los parámetros p1 y p2 se registran con el tiempo dentro de un ciclo de entrenamiento. Los parámetros comunes pueden incluir el tamaño del lote o las épocas. En el ejemplo, las métricas A y B se registran para una ejecución en el tiempo dentro de un ciclo de entrenamiento. Las métricas comunes pueden incluir precisión o pérdida. Para más información, ver Crear un experimento de Amazon SageMaker.
Conclusión
En esta publicación, presentamos una nueva capacidad SDK de SageMaker Python que permite a los científicos de datos ejecutar su código ML en su IDE preferido como trabajos de capacitación de SageMaker. Discutimos los requisitos previos necesarios para usar esta capacidad junto con sus características. También mostramos cómo usar esta capacidad en Studio, instancias de notebooks de SageMaker y su IDE local. Además, proporcionamos ejemplos de código de muestra para demostrar cómo usar esta capacidad. Como siguiente paso, recomendamos probar esta capacidad en su IDE o SageMaker siguiendo las ejemplos de código referenciado en esta publicación.
Acerca de los autores
 Dipankar Patro es ingeniero de desarrollo de software en AWS SageMaker, innovando y creando soluciones MLOps para ayudar a los clientes a adoptar soluciones AI/ML a escala. Tiene una maestría en Ciencias de la Computación y sus áreas de interés son la Seguridad Informática, los Sistemas Distribuidos y AI/ML.
Dipankar Patro es ingeniero de desarrollo de software en AWS SageMaker, innovando y creando soluciones MLOps para ayudar a los clientes a adoptar soluciones AI/ML a escala. Tiene una maestría en Ciencias de la Computación y sus áreas de interés son la Seguridad Informática, los Sistemas Distribuidos y AI/ML.
 Farooq Sabir es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Tiene un doctorado y una maestría en ingeniería eléctrica de la Universidad de Texas en Austin y una maestría en informática del Instituto de Tecnología de Georgia. Tiene más de 15 años de experiencia laboral y también le gusta enseñar y asesorar a estudiantes universitarios. En AWS, ayuda a los clientes a formular y resolver sus problemas comerciales en ciencia de datos, aprendizaje automático, visión artificial, inteligencia artificial, optimización numérica y dominios relacionados. Con sede en Dallas, Texas, a él y a su familia les encanta viajar y hacer viajes largos por carretera.
Farooq Sabir es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Tiene un doctorado y una maestría en ingeniería eléctrica de la Universidad de Texas en Austin y una maestría en informática del Instituto de Tecnología de Georgia. Tiene más de 15 años de experiencia laboral y también le gusta enseñar y asesorar a estudiantes universitarios. En AWS, ayuda a los clientes a formular y resolver sus problemas comerciales en ciencia de datos, aprendizaje automático, visión artificial, inteligencia artificial, optimización numérica y dominios relacionados. Con sede en Dallas, Texas, a él y a su familia les encanta viajar y hacer viajes largos por carretera.
 manoj ravi es gerente sénior de productos de Amazon SageMaker. Le apasiona crear productos de inteligencia artificial de próxima generación y trabaja en software y herramientas para facilitar el aprendizaje automático a gran escala para los clientes. Tiene un MBA de Haas School of Business y una Maestría en Gestión de Sistemas de Información de la Universidad Carnegie Mellon. En su tiempo libre, a Manoj le gusta jugar al tenis y dedicarse a la fotografía de paisajes.
manoj ravi es gerente sénior de productos de Amazon SageMaker. Le apasiona crear productos de inteligencia artificial de próxima generación y trabaja en software y herramientas para facilitar el aprendizaje automático a gran escala para los clientes. Tiene un MBA de Haas School of Business y una Maestría en Gestión de Sistemas de Información de la Universidad Carnegie Mellon. En su tiempo libre, a Manoj le gusta jugar al tenis y dedicarse a la fotografía de paisajes.
 Shikhar Kwatra es un arquitecto de soluciones especializado en inteligencia artificial y aprendizaje automático en Amazon Web Services, que trabaja con un integrador de sistemas global líder. Se ha ganado el título de uno de los maestros inventores indios más jóvenes con más de 500 patentes en los dominios de IA/ML e IoT. Shikhar ayuda en la arquitectura, la creación y el mantenimiento de entornos de nube escalables y rentables para la organización, y apoya al socio de GSI en la creación de soluciones industriales estratégicas en AWS. Shikhar disfruta tocar la guitarra, componer música y practicar la atención plena en su tiempo libre.
Shikhar Kwatra es un arquitecto de soluciones especializado en inteligencia artificial y aprendizaje automático en Amazon Web Services, que trabaja con un integrador de sistemas global líder. Se ha ganado el título de uno de los maestros inventores indios más jóvenes con más de 500 patentes en los dominios de IA/ML e IoT. Shikhar ayuda en la arquitectura, la creación y el mantenimiento de entornos de nube escalables y rentables para la organización, y apoya al socio de GSI en la creación de soluciones industriales estratégicas en AWS. Shikhar disfruta tocar la guitarra, componer música y practicar la atención plena en su tiempo libre.
 Vikram Elango es Arquitecto de soluciones especialista en inteligencia artificial/aprendizaje automático sénior en AWS, con sede en Virginia, EE. UU. Actualmente se centra en IA generativa, LLM, ingeniería rápida, optimización de inferencia de modelos grandes y escalado de ML en todas las empresas. Vikram ayuda a los clientes de la industria financiera y de seguros con diseño y liderazgo intelectual para crear e implementar aplicaciones de aprendizaje automático a escala. En su tiempo libre, le gusta viajar, hacer caminatas, cocinar y acampar.
Vikram Elango es Arquitecto de soluciones especialista en inteligencia artificial/aprendizaje automático sénior en AWS, con sede en Virginia, EE. UU. Actualmente se centra en IA generativa, LLM, ingeniería rápida, optimización de inferencia de modelos grandes y escalado de ML en todas las empresas. Vikram ayuda a los clientes de la industria financiera y de seguros con diseño y liderazgo intelectual para crear e implementar aplicaciones de aprendizaje automático a escala. En su tiempo libre, le gusta viajar, hacer caminatas, cocinar y acampar.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/run-your-local-machine-learning-code-as-amazon-sagemaker-training-jobs-with-minimal-code-changes/

