Imagen del autor
Hay muchos cursos y recursos disponibles sobre aprendizaje automático y ciencia de datos, pero muy pocos sobre ingeniería de datos. Esto plantea algunas preguntas. ¿Es un campo difícil? ¿Ofrece salarios bajos? ¿No se considera tan emocionante como otros roles tecnológicos? Sin embargo, la realidad es que muchas empresas buscan activamente talentos en ingeniería de datos y ofrecen salarios sustanciales, que a veces superan los 200,000 dólares. Los ingenieros de datos desempeñan un papel crucial como arquitectos de plataformas de datos, diseñando y construyendo los sistemas fundamentales que permiten a los científicos de datos y a los expertos en aprendizaje automático funcionar de forma eficaz.
Para abordar esta brecha en la industria, DataTalkClub ha introducido un bootcamp transformador y gratuito”,Ingeniería de datos Zoomcamp“. Este curso está diseñado para capacitar a principiantes o profesionales que buscan cambiar de carrera, con habilidades esenciales y experiencia práctica en ingeniería de datos.
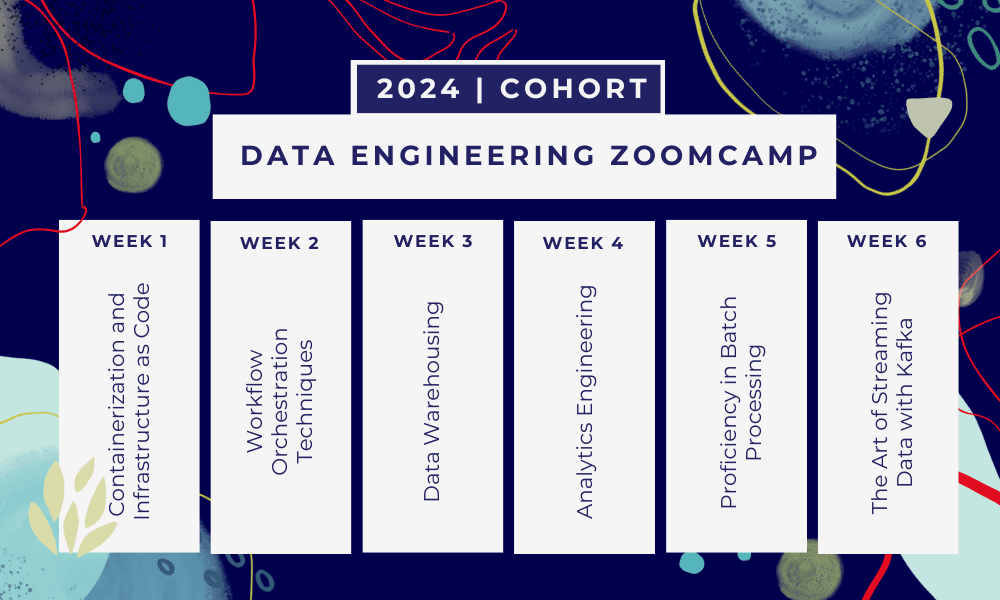
Esto es una campamento de entrenamiento de 6 semanas donde aprenderás a través de múltiples cursos, materiales de lectura, talleres y proyectos. Al final de cada módulo, se le asignará tarea para practicar lo que ha aprendido.
- Semana 1: Introducción a GCP, Docker, Postgres, Terraform y configuración del entorno.
- Semana 2: Orquestación del flujo de trabajo con Mage.
- Semana 3: Almacenamiento de datos con BigQuery y aprendizaje automático con BigQuery.
- Semana 4: Ingeniero analítico con dbt, Google Data Studio y Metabase.
- Semana 5: Procesamiento por lotes con Spark.
- Semana 6: Transmitiendo con Kafka.
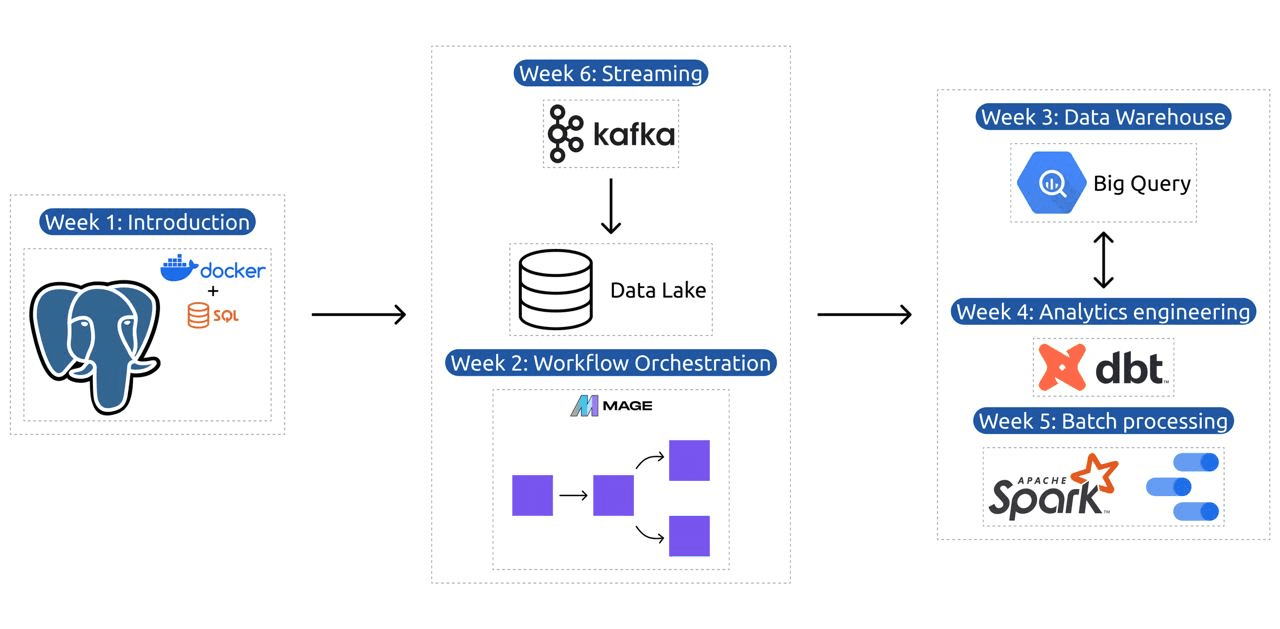
Imagen de DataTalksClub/ingeniería de datos-zoomcamp
El plan de estudios contiene 6 módulos, 2 talleres y un proyecto que cubre todo lo necesario para convertirse en un ingeniero de datos profesional.
Módulo 1: Dominar la contenedorización y la infraestructura como código
En este módulo, aprenderá sobre Docker y Postgres, comenzando con los conceptos básicos y avanzando a través de tutoriales detallados sobre la creación de canalizaciones de datos, la ejecución de Postgres con Docker y más.
El módulo también cubre herramientas esenciales como pgAdmin, Docker-compose y temas de actualización de SQL, con contenido opcional sobre redes Docker y un recorrido especial para usuarios de Linux del subsistema de Windows. Al final, el curso le presenta GCP y Terraform, brindándole una comprensión integral de la contenedorización y la infraestructura como código, esencial para los entornos modernos basados en la nube.
Módulo 2: Técnicas de orquestación del flujo de trabajo
El módulo ofrece una exploración en profundidad de Mage, un innovador marco híbrido de código abierto para la transformación e integración de datos. Este módulo comienza con los conceptos básicos de la orquestación del flujo de trabajo y continúa con ejercicios prácticos con Mage, incluida su configuración a través de Docker y la creación de canalizaciones ETL desde API a Postgres y Google Cloud Storage (GCS), y luego a BigQuery.
La combinación de videos, recursos y tareas prácticas del módulo garantiza una experiencia de aprendizaje integral, equipando a los estudiantes con las habilidades para administrar flujos de trabajo de datos sofisticados utilizando Mage.
Taller 1: Estrategias de ingesta de datos
En el primer taller, dominará la creación de canales de ingesta de datos eficientes. El taller se centra en habilidades esenciales como extraer datos de API y archivos, normalizar y cargar datos y técnicas de carga incremental. Después de completar este taller, podrá crear canales de datos eficientes como un ingeniero de datos senior.
Módulo 3: Almacenamiento de datos
El módulo es una exploración en profundidad del almacenamiento y análisis de datos, centrándose en el almacenamiento de datos mediante BigQuery. Cubre conceptos clave como la partición y la agrupación en clústeres, y profundiza en las mejores prácticas de BigQuery. El módulo avanza hacia temas avanzados, en particular la integración de Machine Learning (ML) con BigQuery, destaca el uso de SQL para ML y proporciona recursos sobre ajuste de hiperparámetros, preprocesamiento de funciones e implementación de modelos.
Módulo 4: Ingeniería Analítica
El módulo de ingeniería analítica se enfoca en construir un proyecto usando dbt (Data Build Tool) con un almacén de datos existente, ya sea BigQuery o PostgreSQL.
El módulo cubre la configuración de dbt tanto en entornos locales como en la nube, presentando conceptos de ingeniería analítica, ETL vs ELT y modelado de datos. También cubre funciones avanzadas de dbt, como modelos incrementales, etiquetas, ganchos e instantáneas.
Al final, el módulo presenta técnicas para visualizar datos transformados utilizando herramientas como Google Data Studio y Metabase, y proporciona recursos para la resolución de problemas y la carga eficiente de datos.
Módulo 5: Competencia en el procesamiento por lotes
Este módulo cubre el procesamiento por lotes utilizando Apache Spark, comenzando con introducciones al procesamiento por lotes y Spark, junto con instrucciones de instalación para Windows, Linux y MacOS.
Incluye explorar Spark SQL y DataFrames, preparar datos, realizar operaciones SQL y comprender los aspectos internos de Spark. Finalmente, concluye ejecutando Spark en la nube e integrando Spark con BigQuery.
Módulo 6: El arte de transmitir datos con Kafka
El módulo comienza con una introducción a los conceptos de procesamiento de flujo, seguida de una exploración en profundidad de Kafka, incluidos sus fundamentos, la integración con Confluent Cloud y aplicaciones prácticas que involucran a productores y consumidores.
El módulo también cubre la configuración y las transmisiones de Kafka, abordando temas como uniones de transmisiones, pruebas, ventanas y el uso de Kafka ksqldb & Connect. Además, extiende su enfoque a entornos Python y JVM, presentando ejemplos de Faust para procesamiento de flujo de Python, Pyspark – Structured Streaming y Scala para Kafka Streams.
Taller 2: Procesamiento de flujos con SQL
Aprenderá a procesar y administrar datos de transmisión con RisingWave, que proporciona una solución rentable con una experiencia de estilo PostgreSQL para potenciar sus aplicaciones de procesamiento de transmisiones.
Proyecto: Aplicación de ingeniería de datos del mundo real
El objetivo de este proyecto es implementar todos los conceptos que hemos aprendido en este curso para construir una canalización de datos de un extremo a otro. Creará un panel que consta de dos mosaicos seleccionando un conjunto de datos, creando una canalización para procesar los datos y almacenándolos en un lago de datos, construyendo una canalización para transferir los datos procesados desde el lago de datos a un almacén de datos, transformando los datos en el almacén de datos y prepararlos para el tablero, y finalmente construir un tablero para presentar los datos visualmente.
Detalles de la cohorte 2024
- Registración: Regístrate
- Fecha de inicio: 15 de enero de 2024, a las 17:00 CET
- Aprendizaje a su propio ritmo con apoyo guiado
- Carpeta de cohorte con tareas y plazos
- Formulario Comunidad de Slack para el aprendizaje entre pares
Requisitos previos
- Habilidades básicas de codificación y línea de comandos.
- Fundación en SQL
- Python: beneficioso pero no obligatorio
Instructores expertos liderando su viaje
- Ankush Khanna
- Victoria Pérez Mola
- Aleksey Grigorev
- mate palmer
- Luis Oliveira
- Michael zapatero
Únase a nuestra cohorte de 2024 y comience a aprender con una increíble comunidad de ingeniería de datos. Con capacitación dirigida por expertos, experiencia práctica y un plan de estudios adaptado a las necesidades de la industria, este bootcamp no solo lo equipa con las habilidades necesarias sino que también lo posiciona a la vanguardia de una carrera profesional lucrativa y muy demandada. ¡Inscríbete hoy y transforma tus aspiraciones en realidad!
Abid Ali Awan (@ 1abidaliawan) es un profesional científico de datos certificado al que le encanta crear modelos de aprendizaje automático. Actualmente, se está enfocando en la creación de contenido y escribiendo blogs técnicos sobre aprendizaje automático y tecnologías de ciencia de datos. Abid tiene una Maestría en Gestión de Tecnología y una licenciatura en Ingeniería de Telecomunicaciones. Su visión es construir un producto de IA utilizando una red neuronal gráfica para estudiantes que luchan contra enfermedades mentales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer

