Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Con la creciente cultura y tendencias de las redes sociales, la cantidad de datos producidos diariamente está aumentando drásticamente. Para manejar esta enorme cantidad de datos de manera eficiente, Teradata se está convirtiendo en un activo para las empresas. Teradata está gobernando, tiene un gran volumen de datos que necesita un procesamiento rápido.
Teradata puede realizar potentes funciones OLAP (Programación analítica en línea) y procesar los datos en paralelo. Teradata proporciona mejor rendimiento y escalabilidad de base de datos lineal que Oracle o cualquier otra estructura de datos DBMS.
¿Qué es Teradata?
Teradata Corporation, una empresa estadounidense de TI, desarrolló un software capaz de desarrollar aplicaciones de almacenamiento de datos a gran escala llamado software Teradata. Es un sistema de gestión de bases de datos relacionales (RDBMS) de código abierto que utiliza el concepto de paralelismo (servicios masivamente paralelos) y ofrece soporte para múltiples operaciones de almacenamiento de datos.
Teradata es compatible con varios servidores de plataformas como Unix/Linux/Windows y, al mismo tiempo, garantiza la compatibilidad con varios entornos de clientes. Es un RDBMS muy eficiente y económico.
Arquitectura Teradata
La arquitectura Teradata es una arquitectura de procesamiento paralelo masivo (MPP) diseñada para manejar grandes volúmenes de datos con extrema facilidad. Comprende tres componentes importantes: motor de análisis (PE), BYNET y procesadores de módulo de acceso (AMP). ¡Vamos a elaborar cada componente de la arquitectura de Teradata para comprender su funcionamiento!
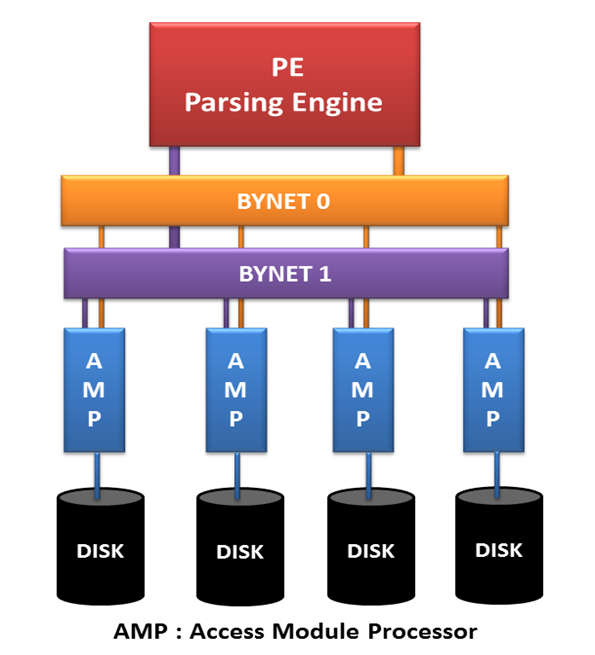
Imagen:- https://tdexperts.wordpress.com/2016/04/14/teradata-architecture/
A. Motor de análisis: Parsing Engine se considera el componente base de Teradata, que analiza las consultas recibidas de los clientes y prepara el plan de ejecución. Se encarga de optimizar y enviar solicitudes al usuario y gestionar las sesiones para los mismos. Algunas de las responsabilidades importantes del motor de análisis se enumeran a continuación:
-
Acepta las consultas SQL enviadas por el cliente y realiza un análisis para verificar los errores sintácticos sobre ellas.
-
Comprueba si los objetos disponibles en la consulta son relevantes o no.
-
Se encarga de comprobar si el usuario está autenticado frente a los objetos presentes en la consulta o no.
-
Crea un plan de ejecución eficiente para la consulta y lo envía a BYNET (una capa de paso de mensajes).
-
Finalmente, recibe la salida de los procesadores del módulo de acceso y la envía de regreso al cliente.
B.BYNET: BYNET es una capa de red en Teradata que actúa como un canal de comunicación entre el motor de análisis y AMP. Los siguientes pasos definen el funcionamiento de BYNET:
-
La capa de paso de mensajes acepta el plan de ejecución del motor de análisis (PE) y lo entrega a AMP.
-
Luego, obtiene la salida procesada generada por los AMP, y su trabajo es transferirla nuevamente al motor de análisis.
-
Para mantener una disponibilidad adecuada, hay dos BYNET disponibles, a saber, BYNET 0 y BYNET 1. En caso de falla del BYNET principal, un BYNET secundario garantiza el funcionamiento adecuado sin demora.
C. Procesadores del módulo de acceso (AMP): Los AMP son los procesadores virtuales de Teradata que almacenan los registros en sus discos. Los siguientes pasos definen el funcionamiento de AMP:
-
Acepta los datos y el plan de ejecución del motor de análisis y realiza la conversión requerida asociada con la generación de resultados como clasificación, agregación, filtrado, etc.
-
AMP administra la parte de la base de datos y distribuye los registros de la tabla de manera uniforme para el almacenamiento de datos.
-
También realiza la gestión de bloqueos y espacios.
Según la función principal, la arquitectura de Teradata se reconoce de dos formas:
-
Arquitectura de almacenamiento
-
Arquitectura de recuperación
Arquitectura de almacenamiento Teradata
Cada vez que el cliente genera una consulta para insertar registros, el motor de análisis envía los registros a BYNET. Tan pronto como BYNET recibe los registros, recupera las filas requeridas y las envía al AMP de destino para su inserción. Ahora, AMP tiene sus discos disponibles para el almacenamiento de registros, por lo que mantiene esas filas en los discos y funciona como una unidad de almacenamiento.
Arquitectura de recuperación de Teradata
Cada vez que el sistema Teradata recibe una solicitud de un cliente para la recuperación de datos, el motor de análisis reenvía una solicitud a BYNET. Luego, el trabajo de BYNET es reenviar la solicitud de recuperación a los AMP apropiados. Ahora, el trabajo de los AMP es realizar la búsqueda de registros en paralelo desde todos sus discos y reenviar los registros encontrados a BYNET, que a su vez los envía al cliente con la ayuda del Parsing Engine.
Diferencia entre Teradata y Hadoop
Arquitectura
Hadoop:- El tipo de arquitectura que sigue Hadoop es la Arquitectura Master-Slave, en la que el clúster está formado por un solo nodo Master y varios nodos Slave. La arquitectura de Hadoop se compone de los siguientes componentes:
-
HDFS: HDFS significa Hadoop Distributed File System, que es la unidad de almacenamiento de la arquitectura Hadoop.
-
YARN: YARN significa Otro Negociador de Recursos. Actúa como administrador de recursos y asigna los recursos disponibles en el sistema.
-
MapReduce: MapReduce actúa como el agente que divide el trabajo y recopila la salida.
Teradata:- Teradata sigue la arquitectura de nada compartido basada en un sistema de procesamiento paralelo masivo (MPP). Teradata es un único almacén de datos que puede recibir varias solicitudes simultáneas o paralelas de varias aplicaciones cliente. Teradata comprende varios elementos como BYNET, motor de análisis (PE), AMP (procesadores de módulos de acceso) y múltiples nodos.
Tecnología
Hadoop: - Es una plataforma de tecnología Big Data de código abierto desarrollada y mantenida por Apache Software Foundation, que se utiliza para almacenar y procesar cantidades masivas de datos y sus aplicaciones en clústeres escalables de hardware básico que es relativamente económico. Es un marco originalmente escrito en Java y utilizó el concepto de MapReduce y GFS (Google File System) de Google. Es una forma optimizada de resolver los desafíos de Big Data que involucra datos que son demasiado diversos y que cambian rápidamente para las tecnologías convencionales.
Teradata: - Teradata es un almacén de datos empresarial activo que admite múltiples usuarios simultáneos de varias plataformas de clientes. Es un sistema de gestión de base de datos relacional de código abierto (RDBMS) que puede ejecutarse en Unix o Windows. Proporciona un arquitecto paralelo para un rendimiento eficiente y actúa como una solución de almacenamiento de datos inigualable.
Tipo de datos
Hadoop: - Hadoop es una solución muy conocida para muchas empresas basadas en datos y la razón es bastante simple: puede procesar y manejar diversos tipos de datos. Puede extraer fácilmente el valor total de todos los datos disponibles. Puede manejar cientos de terabytes de datos de forma económica e independientemente del tipo de datos. Puede procesar datos estructurados, semiestructurados e incluso no estructurados utilizando múltiples herramientas de código abierto. Hadoop es mejor en el manejo de una variedad de datos que Teradata porque Teradata no está diseñado para manejar datos no estructurados inesperados.
Teradata: - Teradata es una solución de almacenamiento de datos relacional simple, y la palabra "relacional" en sí es suficiente para indicar que es la más adecuada para datos estructurados. No puede almacenar ni procesar datos semiestructurados o no estructurados, ya que sus capacidades son para manejar grandes cantidades de datos estructurados disponibles en formato tabular. Proporciona escalabilidad con un rendimiento excepcional y puede escalar desde 100 gigabytes hasta más de 100 petabytes de datos en un solo sistema.
Manipulación de datos en Teradata
Teradata admite la manipulación de datos y nos permite insertar, eliminar y actualizar registros mediante consultas SQL simples.
A. Insertar registros
Cada vez que creamos una tabla RDBMS, la primera tarea es poner siempre algunos datos dentro de la tabla, para hacerlo podemos usar la declaración "INSERT INTO".
Sintaxis:-
Insertar en
(columna1, columna2, columna3,…) VALORES (v1, v2, v3…);
Ejemplo:-
INSERTAR EN Empl (Eid, FName, LName, DOB, DOJ,Dept) VALORES ('E111', 'John', 'Kelvin', '10-11-1986', '25-12-2001',04);
B. Actualizar registros
Para actualizar cualquier registro existente en la tabla, podemos usar la declaración "UPDATE...SET".
Sintaxis:-
ACTUALIZAR
SET = [CONDICIÓN DONDE];
Ejemplo:-
UPDATE Empl SET Dept = 01 DONDE Eid = 'E111';
C. Eliminar registros
Para eliminar cualquier registro existente en la tabla, podemos usar la instrucción “DELETE…FROM”.
Sintaxis:-
BORRAR DE
[DONDE condición];
Ejemplo:-
ELIMINAR DESDE Empl DONDE Eid = 'E111';
Conclusión
Teradata es una tecnología muy confiable utilizada por muchos gigantes para procesar sus datos estructurados muy críticos almacenados en formato tabular. Utiliza un motor de almacenamiento de datos en tiempo real que puede responder a necesidades comerciales complejas y en constante cambio. Teradata es famoso por ofrecer escalabilidad, alto rendimiento y capacidades analíticas. Los puntos clave extraídos de este blog son:
1. ¿Qué implica Teradata?
2. Discutimos los dos tipos de arquitectura de Teradata, incluida la arquitectura de almacenamiento y recuperación.
3. También echamos un vistazo a los componentes de Teradata que contienen BYNET, AMP y Parsing Engine.
4. También discutimos la diferencia exacta entre Teradata y Hadoop según la arquitectura, la tecnología y el tipo de datos. Aquí, discutimos cómo Teradata es más beneficioso para los datos estructurados a largo plazo de las multinacionales.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/11/understanding-the-concepts-of-teradata/

