A medida que los clientes aceleran sus migraciones a la nube y transforman sus negocios, algunos se encuentran en situaciones en las que tienen que gestionar las operaciones de TI en un entorno multinube. Por ejemplo, es posible que haya adquirido una empresa que ya operaba en un proveedor de nube diferente, o puede que tenga una carga de trabajo que genera valor a partir de capacidades únicas proporcionadas por AWS. Otro ejemplo son los proveedores de software independientes (ISV) que ofrecen sus productos y servicios en diferentes plataformas en la nube para beneficiar a sus clientes finales. O una organización puede estar operando en una región donde no hay un proveedor de nube principal disponible y, para cumplir con los requisitos de soberanía o residencia de datos, puede utilizar un proveedor de nube secundario.
En estos escenarios, a medida que comienza a adoptar la IA generativa, los grandes modelos de lenguaje (LLM) y las tecnologías de aprendizaje automático (ML) como parte central de su negocio, es posible que esté buscando opciones para aprovecharlas. IA y aprendizaje automático de AWS capacidades fuera de AWS en un entorno multinube. Por ejemplo, es posible que desee utilizar Amazon SageMaker para construir y entrenar un modelo de ML, o usar Inicio rápido de Amazon SageMaker para implementar modelos de aprendizaje automático básicos prediseñados o de terceros, que puede implementar con solo hacer clic en unos pocos botones. O quizás quieras aprovechar lecho rocoso del amazonas para crear y escalar aplicaciones de IA generativa, o puede aprovechar Servicios de IA previamente entrenados de AWS, que no requieren que usted aprenda habilidades de aprendizaje automático. AWS brinda soporte para escenarios en los que las organizaciones desean traer su propio modelo a Amazon SageMaker or en Amazon SageMaker Canvas para realizar predicciones.
En esta publicación, demostramos una de las muchas opciones que tiene para aprovechar el conjunto más amplio y profundo de capacidades de IA/ML de AWS en un entorno multinube. Mostramos cómo se puede crear y entrenar un modelo de aprendizaje automático en AWS e implementar el modelo en otra plataforma. Entrenamos el modelo usando Amazon SageMaker, almacenamos los artefactos del modelo en Servicio de almacenamiento simple de Amazon (Amazon S3) e implementar y ejecutar el modelo en Azure. Este enfoque es beneficioso si utiliza los servicios de AWS para ML para su conjunto más completo de características, pero necesita ejecutar su modelo en otro proveedor de nube en una de las situaciones que hemos analizado.
Conceptos clave
Estudio Amazon SageMaker es un entorno de desarrollo integrado (IDE) basado en web para el aprendizaje automático. SageMaker Studio permite a los científicos de datos, ingenieros de ML y a los ingenieros de datos preparar datos, crear, entrenar e implementar modelos de ML en una interfaz web. Con SageMaker Studio, puede acceder a herramientas diseñadas específicamente para cada etapa del ciclo de vida del desarrollo de ML, desde la preparación de datos hasta la creación, el entrenamiento y la implementación de sus modelos de ML, mejorando la productividad del equipo de ciencia de datos hasta diez veces. Cuadernos SageMaker Studio son cuadernos colaborativos de inicio rápido que se integran con herramientas de aprendizaje automático diseñadas específicamente en SageMaker y otros servicios de AWS.
SageMaker es un servicio integral de ML que permite a los analistas de negocios, científicos de datos e ingenieros de MLOps crear, entrenar e implementar modelos de ML para cualquier caso de uso, independientemente de su experiencia en ML.
AWS proporciona Contenedores de aprendizaje profundo (DLC) para marcos de aprendizaje automático populares como PyTorch, TensorFlow y Apache MXNet, que puede usar con SageMaker para entrenamiento e inferencia. Los DLC están disponibles como imágenes de Docker en Registro de contenedores elásticos de Amazon (Amazon ECR). Las imágenes de Docker están preinstaladas y probadas con las últimas versiones de marcos de aprendizaje profundo populares, así como con otras dependencias necesarias para el entrenamiento y la inferencia. Para obtener una lista completa de las imágenes de Docker prediseñadas administradas por SageMaker, consulte Rutas de registro de Docker y código de ejemplo. Amazon ECR admite el escaneo de seguridad y está integrado con Inspectora de Amazonas servicio de gestión de vulnerabilidades para cumplir con los requisitos de seguridad de cumplimiento de imágenes de su organización y para automatizar el escaneo de evaluación de vulnerabilidades. Las organizaciones también pueden utilizar tren de AWS y Inferencia de AWS para obtener una mejor relación precio-rendimiento para ejecutar trabajos de capacitación o inferencia de ML.
Resumen de la solución
En esta sección, describimos cómo construir y entrenar un modelo usando SageMaker e implementar el modelo en Azure Functions. Usamos un cuaderno de SageMaker Studio para construir, entrenar e implementar el modelo. Entrenamos el modelo en SageMaker usando una imagen de Docker prediseñada para PyTorch. Aunque en este caso estamos implementando el modelo entrenado en Azure, podría usar el mismo enfoque para implementar el modelo en otras plataformas, como las locales u otras plataformas en la nube.
Cuando creamos un trabajo de entrenamiento, SageMaker lanza las instancias informáticas de ML y utiliza nuestro código de entrenamiento y el conjunto de datos de entrenamiento para entrenar el modelo. Guarda los artefactos del modelo resultante y otros resultados en un depósito de S3 que especificamos como entrada para el trabajo de entrenamiento. Cuando se completa el entrenamiento del modelo, utilizamos el Intercambio de redes neuronales abiertas (ONNX) biblioteca de tiempo de ejecución para exportar el modelo PyTorch como modelo ONNX.
Finalmente, implementamos el modelo ONNX junto con un código de inferencia personalizado escrito en Python en Azure Functions mediante la CLI de Azure. ONNX admite la mayoría de los Marcos y herramientas de aprendizaje automático comúnmente utilizados.. Una cosa a tener en cuenta es que convertir un modelo de ML a ONNX es útil si desea utilizar un marco de implementación de destino diferente, como PyTorch a TensorFlow. Si está utilizando el mismo marco tanto en el origen como en el destino, no necesita convertir el modelo al formato ONNX.
El siguiente diagrama ilustra la arquitectura de este enfoque.
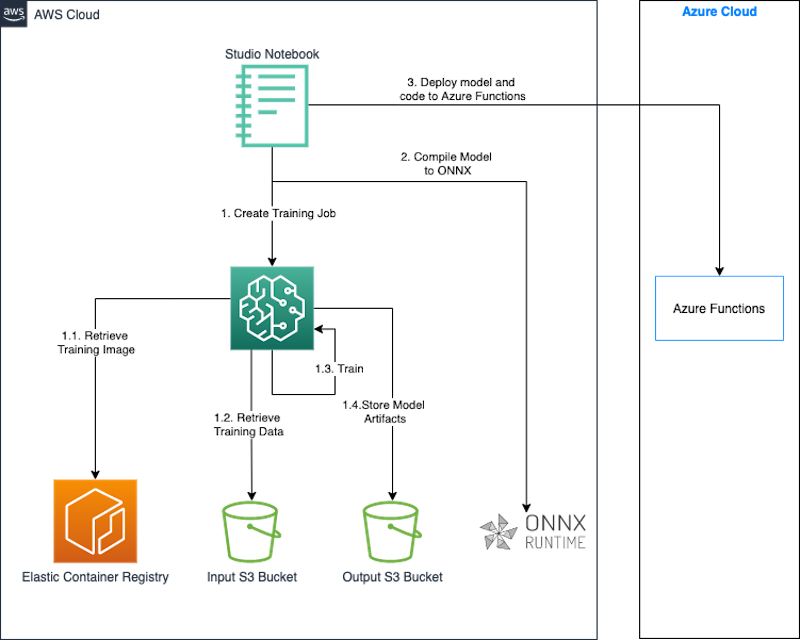
Usamos un cuaderno SageMaker Studio junto con el SDK de SageMaker Python para construir y entrenar nuestro modelo. El SDK de SageMaker Python es una biblioteca de código abierto para entrenar e implementar modelos de aprendizaje automático en SageMaker. Para obtener más detalles, consulte Crear o abrir un cuaderno de Amazon SageMaker Studio.
Los fragmentos de código de las siguientes secciones se probaron en el entorno del cuaderno SageMaker Studio utilizando la imagen Data Science 3.0 y el kernel Python 3.0.
En esta solución, demostramos los siguientes pasos:
- Entrene un modelo PyTorch.
- Exporte el modelo PyTorch como modelo ONNX.
- Empaquete el modelo y el código de inferencia.
- Implemente el modelo en Azure Functions.
Requisitos previos
Debe tener los siguientes requisitos previos:
- Una cuenta de AWS.
- Un dominio de SageMaker y un usuario de SageMaker Studio. Para obtener instrucciones para crearlos, consulte Incorporación al dominio de Amazon SageMaker mediante la configuración rápida.
- La CLI de Azure.
- Acceso a Azure y credenciales para una entidad de servicio que tenga permisos para crear y administrar Azure Functions.
Entrenar un modelo con PyTorch
En esta sección, detallamos los pasos para entrenar un modelo PyTorch.
Instalar dependencias
Instale las bibliotecas para llevar a cabo los pasos necesarios para el entrenamiento y la implementación del modelo:
pip install torchvision onnx onnxruntimeCompletar la configuración inicial
Comenzamos importando el AWS SDK para Python (Boto3) y del SDK de SageMaker Python. Como parte de la configuración, definimos lo siguiente:
- Un objeto de sesión que proporciona métodos convenientes dentro del contexto de SageMaker y de nuestra propia cuenta.
- Un ARN de rol de SageMaker utilizado para delegar permisos al servicio de capacitación y alojamiento. Necesitamos esto para que estos servicios puedan acceder a los depósitos de S3 donde se almacenan nuestros datos y modelo. Para obtener instrucciones sobre cómo crear un rol que satisfaga sus necesidades comerciales, consulte Funciones de SageMaker. Para esta publicación, utilizamos la misma función de ejecución que nuestra instancia de cuaderno de Studio. Obtenemos este rol llamando
sagemaker.get_execution_role(). - La región predeterminada donde se ejecutará nuestro trabajo de capacitación.
- El depósito predeterminado y el prefijo que usamos para almacenar la salida del modelo.
Ver el siguiente código:
import sagemaker
import boto3
import os execution_role = sagemaker.get_execution_role()
region = boto3.Session().region_name
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = "sagemaker/mnist-pytorch"Crear el conjunto de datos de entrenamiento
Usamos el conjunto de datos disponible en el depósito público. sagemaker-example-files-prod-{region}. El conjunto de datos contiene los siguientes archivos:
- imágenes-de-tren-idx3-ubyte.gz – Contiene imágenes del conjunto de entrenamiento.
- etiquetas-de-tren-idx1-ubyte.gz – Contiene etiquetas de conjuntos de entrenamiento
- t10k-imagenes-idx3-ubyte.gz – Contiene imágenes del conjunto de prueba.
- t10k-etiquetas-idx1-ubyte.gz – Contiene etiquetas de equipos de prueba
Usamos latorchvision.datasets módulo para descargar los datos del depósito público localmente antes de cargarlos en nuestro depósito de datos de entrenamiento. Pasamos esta ubicación del depósito como entrada para el trabajo de capacitación de SageMaker. Nuestro script de entrenamiento utiliza esta ubicación para descargar y preparar los datos de entrenamiento y luego entrenar el modelo. Vea el siguiente código:
MNIST.mirrors = [ f"https://sagemaker-example-files-prod-{region}.s3.amazonaws.com/datasets/image/MNIST/"
] MNIST( "data", download=True, transform=transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))] ),
)
Crear el guión de entrenamiento
Con SageMaker, puedes traer tu propio modelo usando modo script. Con el modo de secuencia de comandos, puede utilizar los contenedores prediseñados de SageMaker y proporcionar su propia secuencia de comandos de entrenamiento, que tiene la definición del modelo, junto con las bibliotecas y dependencias personalizadas. El SDK de SageMaker Python pasa nuestro script como un entry_point al contenedor, que carga y ejecuta la función de tren desde el script proporcionado para entrenar nuestro modelo.
Cuando se completa la capacitación, SageMaker guarda el resultado del modelo en el depósito de S3 que proporcionamos como parámetro para el trabajo de capacitación.
Nuestro código de formación está adaptado del siguiente Script de ejemplo de PyTorch. El siguiente extracto del código muestra la definición del modelo y la función del tren:
# define network class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output# train def train(args, model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: breakEntrenar a la modelo
Ahora que hemos configurado nuestro entorno y creado nuestro conjunto de datos de entrada y nuestro script de entrenamiento personalizado, podemos comenzar el entrenamiento del modelo usando SageMaker. Usamos el estimador PyTorch en el SDK de Python de SageMaker para iniciar un trabajo de capacitación en SageMaker. Pasamos los parámetros requeridos al estimador y llamamos al método de ajuste. Cuando llamamos ajuste al estimador de PyTorch, SageMaker inicia un trabajo de entrenamiento usando nuestro script como código de entrenamiento:
from sagemaker.pytorch import PyTorch output_location = f"s3://{bucket}/{prefix}/output"
print(f"training artifacts will be uploaded to: {output_location}") hyperparameters={ "batch-size": 100, "epochs": 1, "lr": 0.1, "gamma": 0.9, "log-interval": 100
} instance_type = "ml.c4.xlarge"
estimator = PyTorch( entry_point="train.py", source_dir="code", # directory of your training script role=execution_role, framework_version="1.13", py_version="py39", instance_type=instance_type, instance_count=1, volume_size=250, output_path=output_location, hyperparameters=hyperparameters
) estimator.fit(inputs = { 'training': f"{inputs}", 'testing': f"{inputs}"
})Exportar el modelo entrenado como modelo ONNX
Una vez completada la capacitación y guardado nuestro modelo en la ubicación predefinida en Amazon S3, exportamos el modelo a un modelo ONNX utilizando el tiempo de ejecución de ONNX.
Incluimos el código para exportar nuestro modelo a ONNX en nuestro script de capacitación para ejecutarlo una vez completada la capacitación.
PyTorch exporta el modelo a ONNX ejecutando el modelo usando nuestra entrada y registrando un rastro de los operadores utilizados para calcular la salida. Usamos una entrada aleatoria del tipo correcto con PyTorch torch.onnx.export función para exportar el modelo a ONNX. También especificamos la primera dimensión en nuestra entrada como dinámica para que nuestro modelo acepte una variable. batch_size de entradas durante la inferencia.
def export_to_onnx(model, model_dir, device): logger.info("Exporting the model to onnx.") dummy_input = torch.randn(1, 1, 28, 28).to(device) input_names = [ "input_0" ] output_names = [ "output_0" ] path = os.path.join(model_dir, 'mnist-pytorch.onnx') torch.onnx.export(model, dummy_input, path, verbose=True, input_names=input_names, output_names=output_names, dynamic_axes={'input_0' : {0 : 'batch_size'}, # variable length axes 'output_0' : {0 : 'batch_size'}})ONNX es un formato estándar abierto para modelos de aprendizaje profundo que permite la interoperabilidad entre marcos de aprendizaje profundo como PyTorch, Microsoft Cognitive Toolkit (CNTK) y más. Esto significa que puede utilizar cualquiera de estos marcos para entrenar el modelo y posteriormente exportar los modelos previamente entrenados en formato ONNX. Al exportar el modelo a ONNX, obtiene el beneficio de una selección más amplia de dispositivos y plataformas de implementación.
Descargue y extraiga los artefactos del modelo.
SageMaker copió el modelo ONNX que guardó nuestro script de capacitación en Amazon S3 en la ubicación de salida que especificamos cuando iniciamos el trabajo de capacitación. Los artefactos del modelo se almacenan como un archivo comprimido llamado model.tar.gz. Descargamos este archivo a un directorio local en nuestra instancia del cuaderno Studio y extraemos los artefactos del modelo, es decir, el modelo ONNX.
import tarfile local_model_file = 'model.tar.gz'
model_bucket,model_key = estimator.model_data.split('/',2)[-1].split('/',1)
s3 = boto3.client("s3")
s3.download_file(model_bucket,model_key,local_model_file) model_tar = tarfile.open(local_model_file)
model_file_name = model_tar.next().name
model_tar.extractall('.')
model_tar.close()Validar el modelo ONNX
El modelo ONNX se exporta a un archivo llamado mnist-pytorch.onnx por nuestro guión de entrenamiento. Después de haber descargado y extraído este archivo, opcionalmente podemos validar el modelo ONNX usando el onnx.checker módulo. los check_model La función de este módulo comprueba la coherencia de un modelo. Se genera una excepción si la prueba falla.
import onnx onnx_model = onnx.load("mnist-pytorch.onnx")
onnx.checker.check_model(onnx_model)Empaquetar el modelo y el código de inferencia.
Para esta publicación, utilizamos la implementación .zip para Azure Functions. En este método, empaquetamos nuestro modelo, el código que lo acompaña y la configuración de Azure Functions en un archivo .zip y lo publicamos en Azure Functions. El siguiente código muestra la estructura de directorios de nuestro paquete de implementación:
mnist-onnx├── function_app.py├── model│ └── mnist-pytorch.onnx└── requirements.txt
Listar dependencias
Enumeramos las dependencias de nuestro código de inferencia en el requirements.txt archivo en la raíz de nuestro paquete. Este archivo se utiliza para crear el entorno de Azure Functions cuando publicamos el paquete.
azure-functionsnumpyonnxruntime
Escribir código de inferencia
Usamos Python para escribir el siguiente código de inferencia, usando la biblioteca ONNX Runtime para cargar nuestro modelo y ejecutar la inferencia. Esto indica a la aplicación Azure Functions que haga que el punto final esté disponible en el /classify camino relativo.
import logging
import azure.functions as func
import numpy as np
import os
import onnxruntime as ort
import json app = func.FunctionApp() def preprocess(input_data_json): # convert the JSON data into the tensor input return np.array(input_data_json['data']).astype('float32') def run_model(model_path, req_body): session = ort.InferenceSession(model_path) input_data = preprocess(req_body) logging.info(f"Input Data shape is {input_data.shape}.") input_name = session.get_inputs()[0].name # get the id of the first input of the model try: result = session.run([], {input_name: input_data}) except (RuntimeError) as e: print("Shape={0} and error={1}".format(input_data.shape, e)) return result[0] def get_model_path(): d=os.path.dirname(os.path.abspath(__file__)) return os.path.join(d , './model/mnist-pytorch.onnx') @app.function_name(name="mnist_classify")
@app.route(route="classify", auth_level=func.AuthLevel.ANONYMOUS)
def main(req: func.HttpRequest) -> func.HttpResponse: logging.info('Python HTTP trigger function processed a request.') # Get the img value from the post. try: req_body = req.get_json() except ValueError: pass if req_body: # run model result = run_model(get_model_path(), req_body) # map output to integer and return result string. digits = np.argmax(result, axis=1) logging.info(type(digits)) return func.HttpResponse(json.dumps({"digits": np.array(digits).tolist()})) else: return func.HttpResponse( "This HTTP triggered function successfully.", status_code=200 )Implementar el modelo en Azure Functions
Ahora que tenemos el código empaquetado en el formato .zip requerido, estamos listos para publicarlo en Azure Functions. Lo hacemos utilizando la CLI de Azure, una utilidad de línea de comandos para crear y administrar recursos de Azure. Instale la CLI de Azure con el siguiente código:
!pip install -q azure-cliLuego complete los siguientes pasos:
- Inicie sesión en Azure:
!az login - Configure los parámetros de creación de recursos:
import random random_suffix = str(random.randint(10000,99999)) resource_group_name = f"multicloud-{random_suffix}-rg" storage_account_name = f"multicloud{random_suffix}" location = "ukwest" sku_storage = "Standard_LRS" functions_version = "4" python_version = "3.9" function_app = f"multicloud-mnist-{random_suffix}" - Utilice los siguientes comandos para crear la aplicación Azure Functions junto con los recursos necesarios:
!az group create --name {resource_group_name} --location {location} !az storage account create --name {storage_account_name} --resource-group {resource_group_name} --location {location} --sku {sku_storage} !az functionapp create --name {function_app} --resource-group {resource_group_name} --storage-account {storage_account_name} --consumption-plan-location "{location}" --os-type Linux --runtime python --runtime-version {python_version} --functions-version {functions_version} - Configure Azure Functions para que cuando implementemos el paquete de Functions, el
requirements.txtEl archivo se utiliza para construir las dependencias de nuestra aplicación:!az functionapp config appsettings set --name {function_app} --resource-group {resource_group_name} --settings @./functionapp/settings.json - Configure la aplicación Functions para ejecutar el modelo Python v2 y realizar una compilación del código que recibe después de la implementación de .zip:
{ "AzureWebJobsFeatureFlags": "EnableWorkerIndexing", "SCM_DO_BUILD_DURING_DEPLOYMENT": true } - Una vez que tengamos el grupo de recursos, el contenedor de almacenamiento y la aplicación de Functions con la configuración correcta, publique el código en la aplicación de Functions:
!az functionapp deployment source config-zip -g {resource_group_name} -n {function_app} --src {function_archive} --build-remote true
Prueba el modelo
Hemos implementado el modelo ML en Azure Functions como un desencadenador HTTP, lo que significa que podemos usar la URL de la aplicación Functions para enviar una solicitud HTTP a la función para invocarla y ejecutar el modelo.
Para preparar la entrada, descargue los archivos de imágenes de prueba del depósito de archivos de ejemplo de SageMaker y prepare un conjunto de muestras en el formato requerido por el modelo:
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt transform=transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
) test_dataset = datasets.MNIST(root='../data', download=True, train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=True) test_features, test_labels = next(iter(test_loader))Utilice la biblioteca de solicitudes para enviar una solicitud de publicación al punto final de inferencia con las entradas de muestra. El punto final de inferencia toma el formato que se muestra en el siguiente código:
import requests, json def to_numpy(tensor): return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy() url = f"https://{function_app}.azurewebsites.net/api/classify"
response = requests.post(url, json.dumps({"data":to_numpy(test_features).tolist()}) )
predictions = json.loads(response.text)['digits']Limpiar
Cuando haya terminado de probar el modelo, elimine el grupo de recursos junto con los recursos contenidos, incluido el contenedor de almacenamiento y la aplicación Functions:
!az group delete --name {resource_group_name} --yesAdemás, se recomienda cerrar los recursos inactivos dentro de SageMaker Studio para reducir costos. Para obtener más información, consulte Ahorre costos al cerrar automáticamente los recursos inactivos dentro de Amazon SageMaker Studio.
Conclusión
En esta publicación, mostramos cómo se puede crear y entrenar un modelo de aprendizaje automático con SageMaker e implementarlo en otro proveedor de nube. En la solución, utilizamos una computadora portátil SageMaker Studio, pero para cargas de trabajo de producción, recomendamos usar MLOps para crear flujos de trabajo de capacitación repetibles para acelerar el desarrollo y la implementación del modelo.
Esta publicación no mostró todas las formas posibles de implementar y ejecutar un modelo en un entorno multinube. Por ejemplo, también puede empaquetar su modelo en una imagen de contenedor junto con código de inferencia y bibliotecas de dependencia para ejecutar el modelo como una aplicación en contenedores en cualquier plataforma. Para obtener más información sobre este enfoque, consulte Implemente aplicaciones de contenedores en un entorno multinube mediante Amazon CodeCatalyst. La intención de la publicación es mostrar cómo las organizaciones pueden utilizar las capacidades de IA/ML de AWS en un entorno multinube.
Sobre los autores
 Raja Vaidyanathan es arquitecto de soluciones en AWS y brinda soporte a clientes de servicios financieros globales. Raja trabaja con los clientes para diseñar soluciones a problemas complejos con un impacto positivo a largo plazo en sus negocios. Es un sólido profesional de ingeniería capacitado en estrategia de TI, gestión de datos empresariales y arquitectura de aplicaciones, con intereses particulares en análisis y aprendizaje automático.
Raja Vaidyanathan es arquitecto de soluciones en AWS y brinda soporte a clientes de servicios financieros globales. Raja trabaja con los clientes para diseñar soluciones a problemas complejos con un impacto positivo a largo plazo en sus negocios. Es un sólido profesional de ingeniería capacitado en estrategia de TI, gestión de datos empresariales y arquitectura de aplicaciones, con intereses particulares en análisis y aprendizaje automático.
 Amandeep Bajwa es arquitecto senior de soluciones en AWS que brinda soporte a empresas de servicios financieros. Ayuda a las organizaciones a lograr sus resultados comerciales identificando la estrategia de transformación de la nube adecuada en función de las tendencias de la industria y las prioridades organizacionales. Algunas de las áreas en las que Amandeep consulta son migración a la nube, estrategia de nube (incluidas la híbrida y la multinube), transformación digital, datos y análisis, y tecnología en general.
Amandeep Bajwa es arquitecto senior de soluciones en AWS que brinda soporte a empresas de servicios financieros. Ayuda a las organizaciones a lograr sus resultados comerciales identificando la estrategia de transformación de la nube adecuada en función de las tendencias de la industria y las prioridades organizacionales. Algunas de las áreas en las que Amandeep consulta son migración a la nube, estrategia de nube (incluidas la híbrida y la multinube), transformación digital, datos y análisis, y tecnología en general.
 Prema Iyer es gerente técnico senior de cuentas de AWS Enterprise Support. Trabaja con clientes externos en una variedad de proyectos, ayudándolos a mejorar el valor de sus soluciones cuando utilizan AWS.
Prema Iyer es gerente técnico senior de cuentas de AWS Enterprise Support. Trabaja con clientes externos en una variedad de proyectos, ayudándolos a mejorar el valor de sus soluciones cuando utilizan AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/train-and-deploy-ml-models-in-a-multicloud-environment-using-amazon-sagemaker/

