En una arquitectura de datos moderna, el análisis unificado le permite acceder a los datos que necesita, ya sea que estén almacenados en un lago de datos o en un almacén de datos. En particular, hemos observado un número creciente de clientes que combinan e integran sus datos en un Desplazamiento al rojo de Amazon almacén de datos para analizar grandes cantidades de datos a escala y ejecutar consultas complejas para lograr sus objetivos comerciales.
Uno de los casos de uso más comunes para la preparación de datos en Amazon Redshift es ingerir y transformar datos de diferentes almacenes de datos en un almacén de datos de Amazon Redshift. Esto se logra comúnmente a través de Pegamento AWS, que es un servicio de integración de datos escalable y sin servidor que facilita descubrir, preparar, mover e integrar datos de múltiples fuentes. AWS Glue proporciona una arquitectura extensible que permite a los usuarios diferentes casos de uso de procesamiento de datos y funciona bien con Amazon Redshift. En AWS re:Invent 2022, anunciamos la compatibilidad con la nueva integración de Amazon Redshift con Apache Spark disponible en AWS Glue 4.0, que proporciona capacidades mejoradas de ETL (extracción, transformación y carga) y ELT con un rendimiento mejorado.
Hoy, nos complace anunciar capacidades de creación de trabajos visuales nuevas y mejoradas para los flujos de trabajo ETL y ELT de Amazon Redshift en el editor visual de AWS Glue Studio. La nueva experiencia de creación le brinda la posibilidad de:
- Comience más rápido con Amazon Redshift navegando directamente por los esquemas y tablas de Amazon Redshift desde la interfaz visual de AWS Glue Studio
- Autoría flexible mediante la compatibilidad nativa con SQL de Amazon Redshift como fuente o acciones previas y posteriores personalizadas
- Simplifique las operaciones comunes de carga de datos en Amazon Redshift a través de la nueva compatibilidad con los comandos INSERT, TRUNCATE, DROP y MERGE
Con estas mejoras, puede usar transformaciones y conectores existentes en AWS Glue Studio para crear rápidamente canalizaciones de datos para Amazon Redshift. Los usuarios sin código pueden completar tareas integrales utilizando solo la interfaz visual, los usuarios de SQL pueden reutilizar su Amazon Redshift SQL existente dentro de AWS Glue y todos los usuarios pueden ajustar su lógica con acciones personalizadas en el editor visual.
En esta publicación, exploramos la nueva interfaz de usuario optimizada y profundizamos en cómo usar estas capacidades. Para demostrar estas nuevas capacidades, mostramos lo siguiente:
- Pasar una instrucción SQL JOIN personalizada a Amazon Redshift
- Uso de los resultados para aplicar una transformación visual de AWS Glue Studio
- Realizar un ANEXO en los resultados para cargarlos en una tabla de destino
Configurar recursos con AWS CloudFormation
Para demostrar la experiencia del editor visual de AWS Glue Studio con Amazon Redshift, proporcionamos un Formación en la nube de AWS plantilla para que pueda configurar recursos de referencia rápidamente. El plantilla crea los siguientes recursos para usted:
- Una VPC de Amazon, subredes, tablas de rutas, una puerta de enlace de Internet y puertas de enlace NAT
- Un clúster de Amazon Redshift
- An Gestión de identidades y accesos de AWS (IAM) rol asociado con el clúster de Amazon Redshift
- Un rol de IAM para ejecutar el trabajo de AWS Glue
- An Servicio de almacenamiento simple de Amazon (Amazon S3) depósito que se utilizará como ubicación temporal para Amazon Redshift ETL
- An Director de secretos de AWS secreto que almacena el nombre de usuario y la contraseña para el clúster de Amazon Redshift
Tenga en cuenta que al momento de escribir esta publicación, Amazon Redshift MERGE está en versión preliminar y el clúster creado es un clúster de versión preliminar.
Para iniciar la pila de CloudFormation, complete los siguientes pasos:
- En la consola de AWS CloudFormation, elija Crear pila y luego elige Con nuevos recursos (estándar).

- Fuente de la plantilla, seleccione Subir un archivo de plantilla, y cargue el proporcionado plantilla.
- Elige Siguiente.
- Ingrese un nombre para la pila de CloudFormation, luego elija Siguiente.

- Reconozca que esta pila podría crear recursos de IAM para usted, luego elija Enviar.
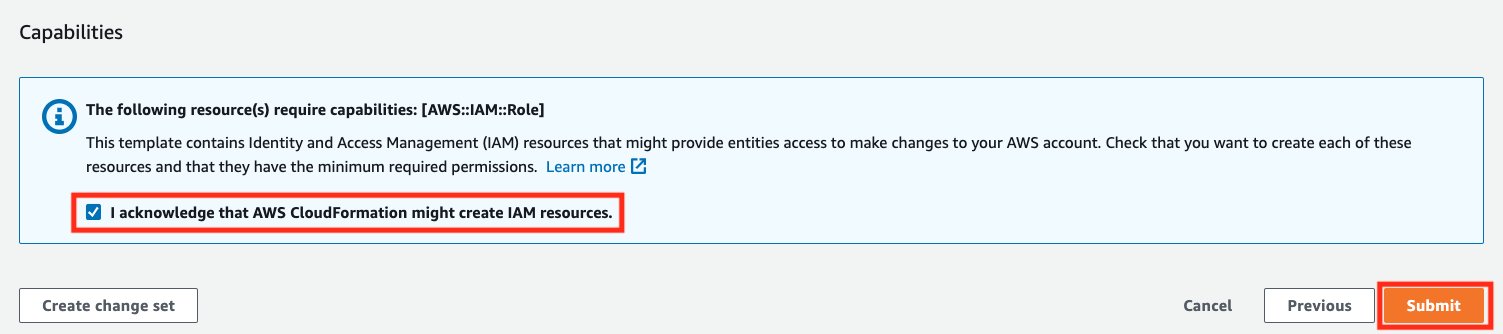
- Después de crear correctamente la pila de CloudFormation, siga los pasos mencionados en https://docs.aws.amazon.com/redshift/latest/gsg/rs-gsg-create-sample-db.html para cargar datos de tickit de muestra en el Redshift Cluster creado
Exploración de las lecturas de Amazon Redshift
En esta sección, repasaremos la nueva funcionalidad de lectura en el editor visual de AWS Glue Studio y demostraremos cómo podemos ejecutar una instrucción SQL personalizada a través de la nueva interfaz de usuario.
- En la consola de AWS Glue, elija Empleos de ETL en el panel de navegación.

- Seleccione Visual con un lienzo en blanco, porque estamos creando un trabajo desde cero, luego elija Crear.

- En el lienzo en blanco, elija el signo más para agregar un nodo de Amazon Redshift del tipo Fuente.

Cuando cierre el selector de nodos, debería ver un nodo de origen de Amazon Redshift en el lienzo junto con las propiedades del origen de datos.

Puede elegir entre dos métodos para acceder a sus datos de Amazon Redshift:
- Conexión directa de datos – Este nuevo método te permite establecer una conexión con tus fuentes de Amazon Redshift sin necesidad de catalogarlas
- Pegar tablas de catálogo de datos – Este método requiere que ya haya rastreado o generado sus tablas de Amazon Redshift en el catálogo de datos de AWS Glue
Para esta publicación, usamos el Conexión directa de datos .
- Tipo de acceso al corrimiento al rojo, Haga click en el botón Conexión directa de datos.
- Conexión de corrimiento al rojo, elija su conexión AWS Glue
redshift-demo-blog-connectioncreado en la pila de CloudFormation.
Especificar la conexión configura automáticamente todos los detalles relacionados con la red junto con el nombre de la base de datos a la que desea conectarse.
Luego, la interfaz de usuario presenta una opción sobre cómo le gustaría acceder a los datos desde la base de datos del clúster de Amazon Redshift seleccionado:
- Elija una sola mesa – Esta opción le permite seleccionar un solo esquema y una sola tabla de su base de datos. Puede navegar a través de todos sus esquemas y tablas disponibles directamente desde el propio editor visual de AWS Glue Studio, lo que facilita mucho la elección de su tabla de origen.

- Introduce una consulta personalizada – Si desea realizar su ETL en un subconjunto de datos de sus tablas de Amazon Redshift, puede crear una consulta de Amazon Redshift desde la interfaz de usuario de AWS Glue Studio. Esta consulta se pasará al clúster de Amazon Redshift conectado y el resultado de la consulta devuelto estará disponible en transformaciones posteriores en AWS Glue Studio.
A los efectos de esta publicación, escribimos nuestra propia consulta personalizada que une los datos del archivo precargado event mesa y venue mesa.
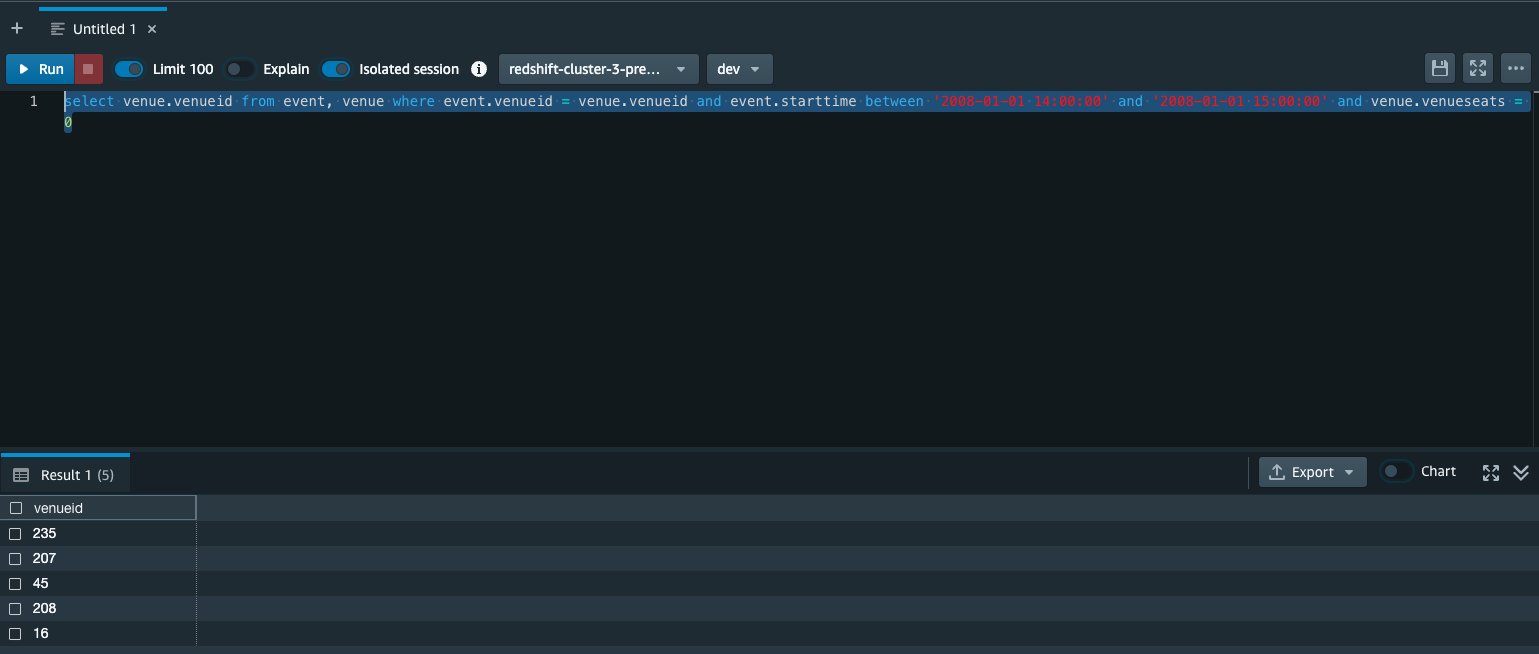
- Seleccione Introduce una consulta personalizada e ingrese la siguiente consulta en el editor de consultas:
La intención de esta consulta es recopilar la venueid de ubicaciones que han tenido un evento entre 2008-01-01 14:00:00 y 2008-01-01 15:00:00 y han tenido venueseats = 0. Si ejecutamos una consulta similar desde el Editor de consultas de Amazon Redshift, podemos ver que en realidad hay cinco lugares de este tipo dentro de ese período de tiempo. Deseamos volver a fusionar estos datos en Amazon Redshift sin incluir estas filas.
- Elige Inferir esquema, que permite que el editor visual de AWS Glue Studio comprenda el esquema de las columnas devueltas de su consulta.

Puedes ver el esquema en la esquema de salida .
- under Rendimiento y seguridad, Para Directorio provisional de S3, elija la ubicación del directorio temporal de S3 creada por la pila de CloudFormation ( Desplazamiento al rojoS3TempPath ).
- Rol de IAM, elija el rol de IAM especificado por Desplazamiento al rojoIamRoleARN en la pila de CloudFormation.

Ahora vamos a agregar una transformación para eliminar filas duplicadas de nuestro resultado de combinación. Esto garantizará que la operación MERGE en los siguientes pasos no tenga claves en conflicto al realizar la operación.
- Elija el Eliminar duplicados nodo para ver las propiedades del nodo.

- En Transformar pestaña, para Soltar duplicados, seleccione Hacer coincidir claves específicas.
- Teclas para unir filas, escoger
venueid.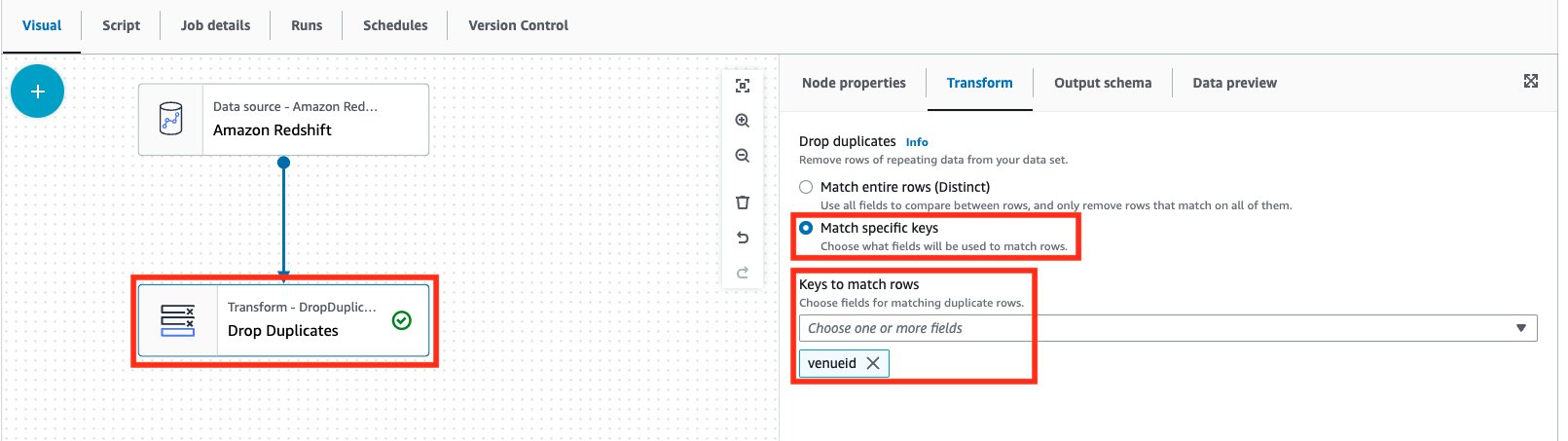
En esta sección, definimos los pasos para leer el resultado de una consulta JOIN personalizada. Luego eliminamos los registros duplicados del valor devuelto. En la siguiente sección, exploramos la ruta de escritura en el mismo trabajo.
Exploración de las escrituras de Amazon Redshift
Ahora repasamos las mejoras para escribir en Amazon Redshift como destino. Esta sección repasa todas las opciones simplificadas para escribir en Amazon Redshift, pero destaca las nuevas capacidades MERGE de Amazon Redshift para los fines de esta publicación.
La operador COMBINAR ofrece una gran flexibilidad para fusionar filas de forma condicional desde un origen en una tabla de destino. MERGE es poderoso porque simplifica las operaciones que tradicionalmente solo se podían lograr mediante el uso de múltiples declaraciones de inserción, actualización o eliminación por separado. Dentro de AWS Glue Studio, particularmente con la opción MERGE personalizada, puede definir una condición de coincidencia más compleja para manejar la búsqueda de registros para actualizar.
- Desde la página de lienzo del trabajo utilizado en la sección anterior, seleccione Desplazamiento al rojo de Amazon para agregar un nodo Amazon Redshift de tipo Target.

Cuando cierre el selector, debería ver su nodo de destino de Amazon Redshift agregado en el lienzo de Amazon Glue Studio, junto con las opciones posibles.
- Tipo de acceso al corrimiento al rojo, selecciona Conexión directa de datos.
Similar al nodo fuente de Amazon Redshift, el Conexión directa de datos El método le permite escribir directamente en sus tablas de Amazon Redshift sin necesidad de catalogarlas en el catálogo de datos de AWS Glue.
- Conexión de corrimiento al rojo, elija su conexión de AWS Glue
redshift-demo-blog-connectioncreado en la pila de CloudFormation.
- Esquema, escoger público.

- Mesa, elegir la lugar de encuentro table como la tabla de Amazon Redshift de destino donde almacenaremos los datos combinados.
- Elige COMBINAR datos en la tabla de destino.
Esta selección proporciona al usuario dos opciones:
- Elige teclas y acciones sencillas – Esta es una versión fácil de usar de la operación MERGE. Simplemente especifique las claves coincidentes y elija qué sucede con las filas que coinciden con la clave (actualícelas o elimínelas) o no tienen ninguna coincidencia (insértelas).
- Ingrese la declaración MERGE personalizada – Esta opción proporciona la mayor flexibilidad. Puede ingresar su propia lógica personalizada para MERGE.
Para esta publicación, usamos el método de acciones simples para realizar una operación MERGE.
- Manejo de datos y tabla de destino, seleccione COMBINAR datos en la tabla de destinoY seleccione Elige teclas y acciones sencillas.
- Claves coincidentes, seleccione
venueid.
Este campo se convertirá en nuestra condición MERGE para verificar claves
- cuando se empareja, Haga click en el botón Eliminar registro en la tabla
- cuando no coincide, seleccione Insertar datos de origen como una nueva fila en la tabla

Con estas selecciones, configuramos el trabajo de AWS Glue para ejecutar una instrucción MERGE en Amazon Redshift mientras insertamos nuestros datos. Además, para realizar esta operación MERGE, usamos como clave (puede seleccionar varias claves). Si hay una coincidencia de clave con el registro de la tabla de destino, eliminamos ese registro. De lo contrario, insertamos el registro en la tabla de destino.
- Navegue hasta la Detalles del trabajo .
- Nombre, introduzca un nombre para el trabajo.
- Para el menú desplegable Rol de IAM, seleccione el Desplazamiento al rojoIamRole rol que se creó a través de la plantilla de CloudFormation.
- Elige Guardar.

- Elige Ejecutar y esperar a que termine el trabajo.
Puede seguir su progreso en el Ron .
- Una vez que la ejecución alcance un estado correcto, vuelva al editor de consultas de Amazon Redshift.
- Vuelva a ejecutar la misma consulta para descubrir que esas filas se han eliminado de acuerdo con nuestras especificaciones MERGE.

En esta sección, configuramos un nodo de destino de Amazon Redshift para escribir una instrucción MERGE para actualizar condicionalmente los registros en nuestra tabla de destino de Amazon Redshift. Luego guardamos y ejecutamos el trabajo de AWS Glue y vimos el efecto de la instrucción MERGE en nuestra tabla de Amazon Redshift de destino.
Otras opciones de escritura disponibles
Además de MERGE, el nodo de destino de Amazon Redshift del editor visual de AWS Glue Studio también admite otras operaciones comunes:
- ADJUNTAR – Agregar a su tabla de destino realiza una inserción en la tabla seleccionada sin actualizar ninguno de los registros existentes (si hay duplicados, se conservarán ambos registros). En los casos en los que desee actualizar las filas existentes además de agregar nuevas filas (a menudo referido a una operación UPSERT), puede seleccionar la opción También actualice los registros existentes en la tabla de destino opción. Tenga en cuenta que tanto APPEND only como UPSERT (APPEND with UPDATE) son un subconjunto más simple de la funcionalidad MERGE discutida anteriormente.
- TRUNCAR – La opción TRUNCATE borra todos los datos de la tabla existente pero conserva todo el esquema de la tabla existente, seguido de un ANEXO de todos los datos nuevos a la tabla vacía. Esta opción se usa a menudo cuando es necesario actualizar el conjunto de datos completo y los servicios o herramientas posteriores dependen de que el esquema de la tabla sea coherente. Por ejemplo, cada noche una tabla de Amazon Redshift debe actualizarse completamente con la información más reciente del cliente que será consumida por un Amazon QuickSight panel. En este caso, el desarrollador de ETL elegiría TRUNCATE para garantizar que los datos se actualicen por completo, pero se garantiza que el esquema de la tabla no cambie.
- DROP – Esta opción se usa cuando es necesario actualizar el conjunto de datos completo y los servicios o herramientas posteriores que dependen del esquema o los sistemas pueden manejar posibles cambios de esquema sin romperse.
Cómo se manejan las operaciones de escritura en el backend
El conector Amazon Redshift admite dos parámetros llamados preactions y postactions. Estos parámetros le permiten ejecutar instrucciones SQL que se pasarán al almacén de datos de Amazon Redshift antes y después de que Spark lleve a cabo la operación de escritura real.
En Guión pestaña en la página de AWS Glue Studio, podemos ver qué declaraciones SQL se están ejecutando.

Use una implementación personalizada para escribir datos en Amazon Redshift
En caso de que los ajustes preestablecidos proporcionados requieran más personalización, o su caso de uso requiera implementaciones más avanzadas para escribir en Amazon Redshift, AWS Glue Studio también le permite seleccionar libremente qué acciones previas y posteriores se pueden ejecutar al escribir en Amazon Redshift.
Para mostrar un ejemplo, creamos un Uso compartido de datos de Amazon Redshift como una acción previa, luego realice la limpieza del mismo recurso compartido de datos como una acción posterior a través de AWS Glue Studio.
NOTA: Esta sección no se ejecuta como parte del blog anterior y se proporciona como ejemplo.
- Elija el nodo de destino de datos de Amazon Redshift.
- En Propiedades de destino de datos pestaña, expanda el Parámetros de corrimiento al rojo personalizados .
- Para los parámetros, agregue lo siguiente:
- Parámetro:
preactionscon valorBEGIN; CREATE DATASHARE ds1; END - Parámetro:
postactionscon valorBEGIN; DROP DATASHARE ds1; END
- Parámetro:

Como puede ver, podemos especificar varias declaraciones de Amazon Redshift como parte tanto del preactions y postactions parámetros Recuerde que estas declaraciones anularán cualquier acción previa o posterior existente con sus acciones especificadas (como puede ver en el siguiente código generado).

Limpiar
Para evitar costos adicionales, asegúrese de eliminar los recursos y archivos innecesarios:
- Vacíe y elimine el contenido del depósito temporal de S3
- Si implementó la pila de CloudFormation de muestra, elimine la pila de CloudFormation a través de la consola de AWS CloudFormation. Asegurate que vaciar el balde S3 antes de eliminar el depósito.
Conclusión
En esta publicación, repasamos las nuevas opciones visuales de AWS Glue Studio para realizar lecturas y escrituras desde Amazon Redshift. También vimos la simplicidad con la que puede explorar sus tablas de Amazon Redshift directamente desde la interfaz de usuario del editor visual de AWS Glue Studio y cómo ejecutar sus propias declaraciones SQL personalizadas en sus fuentes de Amazon Redshift. Luego exploramos cómo realizar tareas simples de carga de ETL contra Amazon Redshift con solo unos pocos clics, y mostramos la nueva declaración MERGE de Amazon Redshift.
Para profundizar en las nuevas integraciones de Amazon Redshift para el editor visual de AWS Glue Studio, consulte Conexión a Redshift en AWS Glue Studio.
Acerca de los autores
 Aniket Jiddigoudar es Arquitecto de Big Data en el equipo de AWS Glue. Trabaja con los clientes para ayudarlos a mejorar sus cargas de trabajo de big data. En su tiempo libre, le gusta probar comida nueva, jugar videojuegos y hacer kickboxing.
Aniket Jiddigoudar es Arquitecto de Big Data en el equipo de AWS Glue. Trabaja con los clientes para ayudarlos a mejorar sus cargas de trabajo de big data. En su tiempo libre, le gusta probar comida nueva, jugar videojuegos y hacer kickboxing.
 sean ma es gerente principal de productos en el equipo de AWS Glue. Tiene un historial de más de 18 años de innovación y entrega de productos empresariales que desbloquean el poder de los datos para los usuarios. Fuera del trabajo, Sean disfruta del buceo y el fútbol americano universitario.
sean ma es gerente principal de productos en el equipo de AWS Glue. Tiene un historial de más de 18 años de innovación y entrega de productos empresariales que desbloquean el poder de los datos para los usuarios. Fuera del trabajo, Sean disfruta del buceo y el fútbol americano universitario.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/exploring-new-etl-and-elt-capabilities-for-amazon-redshift-from-the-aws-glue-studio-visual-editor/

