Atenea amazónica ahora permite que los analistas de datos y los ingenieros de datos disfruten de la experiencia sin servidor, interactiva y fácil de usar de Athena con Apache Spark además de SQL. Ahora puede usar el poder expresivo de Python y crear aplicaciones interactivas de Apache Spark con una experiencia de cuaderno simplificada en la consola de Athena o a través de las API de Athena. Para aplicaciones Spark interactivas, puede pasar menos tiempo esperando y ser más productivo porque Athena comienza a ejecutar aplicaciones instantáneamente en menos de un segundo. Y como Athena no tiene servidor y está completamente administrado, los analistas pueden ejecutar sus cargas de trabajo sin preocuparse por la infraestructura subyacente.
Fecha lagos son un mecanismo común para almacenar y analizar datos porque permiten a las empresas administrar múltiples tipos de datos de una amplia variedad de fuentes y almacenar estos datos, estructurados y no estructurados, en un repositorio centralizado. Apache Spark es un popular sistema de procesamiento distribuido de código abierto optimizado para cargas de trabajo de análisis rápido contra datos de cualquier tamaño. A menudo se usa para explorar lagos de datos para obtener información. Para realizar exploraciones de datos interactivas en el lago de datos, ahora puede usar el motor Apache Spark instantáneo, interactivo y completamente administrado en Athena. Le permite ser más productivo y comenzar rápidamente, sin perder casi tiempo configurando la infraestructura y las configuraciones de Spark.
En esta publicación, mostramos cómo puede usar Athena para Apache Spark para explorar y obtener información de su lago de datos alojado en Servicio de almacenamiento simple de Amazon (Amazon S3).
Resumen de la solución
Mostramos la lectura y exploración de conjuntos de datos CSV y Parquet para realizar análisis interactivos utilizando Athena para Apache Spark y el poder expresivo de Python. También realizamos análisis visuales utilizando las bibliotecas de Python preinstaladas. Para ejecutar este análisis, usamos el editor de cuadernos integrado en Athena.
Para el propósito de esta publicación, usamos el Resumen del día de la superficie global de la NOAA conjunto de datos público de la Registro de Datos Abiertos en AWS, que consta de resúmenes meteorológicos diarios de varias estaciones meteorológicas de la NOAA. El conjunto de datos está principalmente en formato CSV de texto sin formato. Hemos transformado la totalidad y los subconjuntos del conjunto de datos CSV en formato Parquet para nuestra demostración.
Antes de ejecutar la demostración, queremos presentar los siguientes conceptos relacionados con Athena para Spark:
- Talleres – Cuando abre un bloc de notas en Athena, se inicia automáticamente una nueva sesión. Las sesiones realizan un seguimiento de las variables y el estado de los cuadernos.
- Cálculos – Ejecutar una celda en un cuaderno significa ejecutar un cálculo en la sesión actual. Mientras se ejecuta una sesión, los cálculos usan y modifican el estado que se mantiene para el cuaderno.
Para más detalles, consulte Sesión y Cálculos.
Requisitos previos
Para esta demostración, necesita los siguientes requisitos previos:
- Una cuenta de AWS con acceso a la Consola de administración de AWS
- Permisos de Athena en el grupo de trabajo
DemoAthenaSparkWorkgroup, que creas como parte de esta demostración - Gestión de identidades y accesos de AWS (IAM) permisos para crear, leer y actualizar la función y las políticas de IAM creadas como parte de la demostración
- Permisos de Amazon S3 para crear un depósito S3 y leer la ubicación del depósito
La siguiente política otorga estos permisos. Adjúntelo al rol de IAM o al usuario que utiliza para iniciar sesión en la consola. Asegúrese de proporcionar su ID de cuenta de AWS y la región en la que está ejecutando la demostración.
Crea tu grupo de trabajo de Athena
Creamos un nuevo grupo de trabajo de Athena con Spark como motor. Complete los siguientes pasos:
- En la consola de Athena, elija Grupos de trabajo en el panel de navegación.
- Elige Crear grupo de trabajo.
- Nombre del grupo de trabajo, introduzca
DemoAthenaSparkWorkgroup.
Asegúrese de ingresar el nombre exacto porque los permisos de IAM anteriores se limitan al grupo de trabajo con este nombre. - Motor de análisis, escoger Apache Spark.
- Configuraciones adicionales, seleccione Usar valores predeterminados.
Los valores predeterminados incluyen la creación de un rol de IAM con los permisos necesarios para ejecutar cálculos de Spark en Athena y un depósito de S3 para almacenar los resultados de los cálculos. También establece la administración de claves de cifrado del cuaderno (que creamos más adelante) en un Servicio de administración de claves de AWS (AWS KMS) clave propiedad de Athena. - Opcionalmente, agregue etiquetas a su grupo de trabajo.
- Elige Crear grupo de trabajo.
Modificar el rol de IAM
La creación del grupo de trabajo crea un nuevo rol de IAM. Elija el grupo de trabajo recién creado, luego el valor bajo ARN de rol para ser redirigido a la consola de IAM.

Agregue el siguiente permiso como una política en línea al rol de IAM creado anteriormente. Esto permite que el rol lea los conjuntos de datos de S3. Para obtener instrucciones, consulte la sección Para incorporar una política en línea para un usuario o rol (consola) in Adición de permisos de identidad de IAM (consola).
Configura tu cuaderno
Para ejecutar el análisis en Spark en Athena, necesitamos un cuaderno. Complete los siguientes pasos para crear uno:
- En la consola de Athena, elija Editor de cuadernos.
- Elija el grupo de trabajo recién creado
DemoAthenaSparkWorkgroupen el menú desplegable. - Elige Crear cuaderno.
- Proporcione un nombre de cuaderno, por ejemplo
AthenaSparkBlog. - Mantenga los parámetros de sesión predeterminados.
- Elige Crear.
Su computadora portátil ahora debería estar cargada, lo que significa que puede comenzar a ejecutar el código Spark. Debería ver la siguiente captura de pantalla.

Explore el conjunto de datos
Ahora que hemos creado el grupo de trabajo y el cuaderno, comencemos a explorar el Resumen del día de la superficie global de la NOAA conjunto de datos Los conjuntos de datos utilizados en esta publicación se almacenan en las siguientes ubicaciones:
- Datos CSV para el año 2022 –
s3://noaa-gsod-pds/2022/ - Datos de parquet para el año 2021 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2021/ - Datos de parquet para el año 2020 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/ - Todo el conjunto de datos en formato Parquet (hasta octubre de 2022) –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/historical/
En el resto de esta publicación, mostramos fragmentos de código de PySpark. Copie el código e ingréselo en la celda del cuaderno. Prensa Shift + Enter para ejecutar el código como un cálculo. Alternativamente, puede elegir Ejecutar. Agregue más celdas para ejecutar fragmentos de código posteriores.
Comenzamos leyendo el conjunto de datos CSV para el año 2022 e imprimimos su esquema para comprender las columnas contenidas en el conjunto de datos. Ejecute el siguiente código en la celda del cuaderno:

Obtenemos el siguiente resultado.

Pudimos enviar el código anterior como un cálculo al instante usando el cuaderno.
Sigamos explorando el conjunto de datos. Mirando las columnas en el esquema, estamos interesados en obtener una vista previa de los datos para los siguientes atributos en 2022:
- TEMP - Temperatura media
- WDSP – Velocidad media del viento
- RÁFAGA – Ráfaga de viento máxima
- MAX - Temperatura máxima
- MIN - Temperatura mínima
- Nombre - Nombre de estación
Ejecute el siguiente código:
Obtenemos el siguiente resultado.

Ahora tenemos una idea de cómo se ve el conjunto de datos. A continuación, realicemos un análisis para encontrar la temperatura máxima registrada para el aeropuerto de Seattle-Tacoma en 2022. Ejecute el siguiente código:
Obtenemos el siguiente resultado.

A continuación, queremos encontrar la temperatura máxima registrada para cada mes de 2022. Para ello, utilizamos la función Spark SQL de Athena. Primero, necesitamos crear una vista temporal en el year_22_csv marco de datos. Ejecute el siguiente código:
Para ejecutar nuestra consulta Spark SQL, usamos magia %%sql:
Obtenemos el siguiente resultado.

El resultado de la consulta anterior produce el mes en forma numérica. Para hacerlo más legible, vamos a convertir los números de los meses en nombres de meses. Para esto, usamos un función definida por el usuario (UDF) y regístrelo para usarlo en las consultas de Spark SQL durante el resto de la sesión del cuaderno. Ejecute el siguiente código para crear y registrar la UDF:
Volvemos a ejecutar la consulta para encontrar la temperatura máxima registrada para cada mes de 2022 pero con el month_name_udf UDF que acabamos de crear. Además, esta vez ordenamos los resultados según el valor de temperatura máxima. Ver el siguiente código:
El siguiente resultado muestra los nombres de los meses.
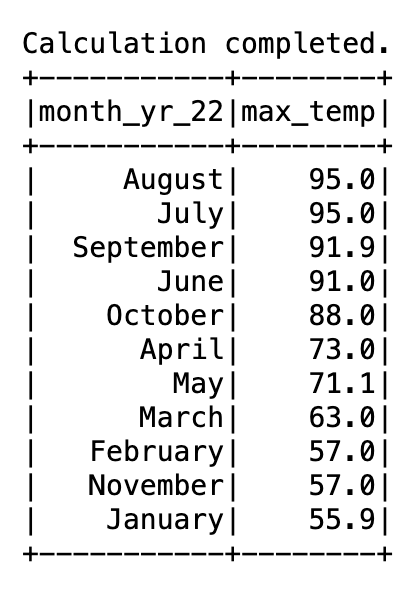
Hasta ahora, hemos realizado exploraciones interactivas para el año 2022 del conjunto de datos del Resumen del día de la superficie global de la NOAA. Digamos que queremos comparar los valores de temperatura con los 2 años anteriores. Comparamos la temperatura máxima en 2020, 2021 y 2022. Como recordatorio, el conjunto de datos para 2022 está en formato CSV y para 2020 y 2021, los conjuntos de datos están en formato Parquet.
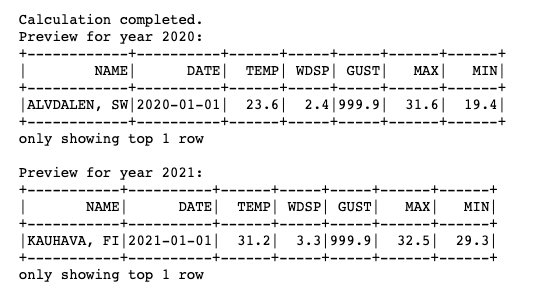
Para continuar con el análisis, leemos los conjuntos de datos de Parquet de 2020 y 2021 en el marco de datos y creamos vistas temporales en los respectivos marcos de datos. Ejecute el siguiente código:
Obtenemos el siguiente resultado.
Para comparar la temperatura máxima registrada para cada mes en 2020, 2021 y 2022, realizamos una operación conjunta en las tres vistas creadas hasta ahora a partir de sus respectivos marcos de datos. Además, reutilizamos el month_name_udf UDF para convertir el número de mes en nombre de mes. Ejecute el siguiente código:
Obtenemos el siguiente resultado.

Hasta ahora, hemos leído conjuntos de datos CSV y Parquet, ejecutado análisis en los conjuntos de datos individuales y realizado operaciones de unión y agregación en ellos para obtener información al instante en un modo interactivo. A continuación, mostramos cómo puede usar las bibliotecas preinstaladas como Seaborn, Matplotlib y Pandas for Spark en Athena para generar un análisis visual. Para obtener la lista completa de bibliotecas de Python preinstaladas, consulte Lista de bibliotecas de Python preinstaladas.
Trazamos un análisis visual para comparar los valores de temperatura máxima registrados para cada mes en 2020, 2021 y 2022. Ejecute el siguiente código, que crea un marco de datos de Spark a partir de la consulta SQL, lo convierte en un marco de datos de Pandas y usa Seaborn y Matplotlib para trazar:
El siguiente gráfico muestra nuestra salida.

A continuación, trazamos un mapa de calor que muestra la tendencia de la temperatura máxima para cada mes en todos los años del conjunto de datos. Para ello, hemos convertido todo el conjunto de datos CSV (hasta octubre de 2022) a formato Parquet y lo hemos almacenado en s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/historical/.
Ejecute el siguiente código para trazar el mapa de calor:
Obtenemos el siguiente resultado.

A partir de las macetas, podemos ver que la tendencia ha sido casi similar a lo largo de los años, donde la temperatura sube durante los meses de verano y baja a medida que se acerca el invierno en el área del aeropuerto de Seattle-Tacoma. Puede continuar explorando más los conjuntos de datos, ejecutando más análisis y trazando más imágenes para tener una idea de la experiencia interactiva e instantánea que ofrece Athena para Apache Spark.
Limpiar recursos
Cuando haya terminado con la demostración, asegúrese de eliminar el depósito S3 que creó para almacenar los cálculos del grupo de trabajo para evitar costos de almacenamiento. Además, puede eliminar el grupo de trabajo, lo que también elimina el cuaderno.
Conclusión
En esta publicación, vimos cómo puede usar la experiencia interactiva y sin servidor de Athena para Spark como motor para ejecutar cálculos al instante. Solo necesita crear un grupo de trabajo y un cuaderno para comenzar a ejecutar el código Spark. Exploramos conjuntos de datos almacenados en diferentes formatos en un lago de datos S3 y ejecutamos análisis interactivos para obtener varios conocimientos. Además, realizamos análisis visuales trazando gráficos utilizando las bibliotecas preinstaladas. Para obtener más información sobre Spark en Athena, consulte Uso de Apache Spark en Amazon Athena.
Acerca de los autores
 Patik Shah es Arquitecto sénior de Big Data en Amazon Athena. Se unió a AWS en 2015 y se ha centrado en el espacio de análisis de big data desde entonces, ayudando a los clientes a crear soluciones sólidas y escalables mediante los servicios de análisis de AWS.
Patik Shah es Arquitecto sénior de Big Data en Amazon Athena. Se unió a AWS en 2015 y se ha centrado en el espacio de análisis de big data desde entonces, ayudando a los clientes a crear soluciones sólidas y escalables mediante los servicios de análisis de AWS.
 Raj Devnath es gerente sénior de productos en AWS y trabaja en Amazon Athena. Le apasiona crear productos que aman a los clientes y ayudar a los clientes a extraer valor de sus datos. Su experiencia es en la entrega de soluciones para múltiples mercados finales, como finanzas, comercio minorista, edificios inteligentes, automatización del hogar y sistemas de comunicación de datos.
Raj Devnath es gerente sénior de productos en AWS y trabaja en Amazon Athena. Le apasiona crear productos que aman a los clientes y ayudar a los clientes a extraer valor de sus datos. Su experiencia es en la entrega de soluciones para múltiples mercados finales, como finanzas, comercio minorista, edificios inteligentes, automatización del hogar y sistemas de comunicación de datos.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/explore-your-data-lake-using-amazon-athena-for-apache-spark/

