Flujo de trabajo administrado por Amazon para Apache Airflow (Amazon MWAA) es un servicio administrado que le permite utilizar una versión familiar Flujo de aire Apache entorno con escalabilidad, disponibilidad y seguridad mejoradas para mejorar y escalar los flujos de trabajo de su negocio sin la carga operativa de administrar la infraestructura subyacente. En flujo de aire, Gráficos acíclicos dirigidos (DAG) se definen como código Python. DAG dinámicos se refiere a la capacidad de generar DAG sobre la marcha durante el tiempo de ejecución, generalmente en función de algunas condiciones, configuraciones o parámetros externos. Los DAG dinámicos le ayudan a crear, programar y ejecutar tareas dentro de un DAG en función de datos y configuraciones que pueden cambiar con el tiempo.
Hay varias formas de introducir dinamismo en los DAG de Airflow (generación dinámica de DAG) utilizando variables de entorno y archivos externos. Uno de los enfoques es utilizar el Fábrica DAG Método de archivo de configuración basado en YAML. Esta biblioteca tiene como objetivo facilitar la creación y configuración de nuevos DAG mediante el uso de parámetros declarativos en YAML. Permite personalizaciones predeterminadas y es de código abierto, lo que simplifica la creación y personalización de nuevas funcionalidades.
En esta publicación, exploramos el proceso de creación de DAG dinámicos con archivos YAML, utilizando el Fábrica DAG biblioteca. Los DAG dinámicos ofrecen varios beneficios:
- Reutilización de código mejorada – Al estructurar DAG a través de archivos YAML, promovemos componentes reutilizables, lo que reduce la redundancia en las definiciones de su flujo de trabajo.
- Mantenimiento simplificado – La generación de DAG basada en YAML simplifica el proceso de modificación y actualización de los flujos de trabajo, lo que garantiza procedimientos de mantenimiento más fluidos.
- Parametrización flexible – Con YAML, puede parametrizar las configuraciones de DAG, lo que facilita ajustes dinámicos a los flujos de trabajo en función de los distintos requisitos.
- Eficiencia mejorada del programador – Los DAG dinámicos permiten una programación más eficiente, optimizando la asignación de recursos y mejorando las ejecuciones generales del flujo de trabajo.
- Escalabilidad mejorada – Los DAG basados en YAML permiten ejecuciones paralelas, lo que permite flujos de trabajo escalables capaces de manejar mayores cargas de trabajo de manera eficiente.
Al aprovechar el poder de los archivos YAML y la biblioteca DAG Factory, desarrollamos un enfoque versátil para crear y administrar DAG, lo que le permite crear canales de datos sólidos, escalables y mantenibles.
Resumen de la solución
En esta publicación, usaremos un archivo DAG de ejemplo diseñado para procesar un conjunto de datos de COVID-19. El proceso de flujo de trabajo implica procesar un conjunto de datos de código abierto ofrecido por OMS-COVID-19-Global. Después de instalar el Fábrica DAG Paquete Python, creamos un archivo YAML que tiene definiciones de varias tareas. Procesamos el recuento de muertes específico del país pasando Country como variable, lo que crea GCI individuales basados en países.
El siguiente diagrama ilustra la solución general junto con los flujos de datos dentro de bloques lógicos.

Requisitos previos
Para este tutorial, debe tener los siguientes requisitos previos:
Además, complete los siguientes pasos (ejecute la instalación en un Región de AWS donde Amazon MWAA está disponible):
- Crear una Entorno Amazon MWAA (si aún no tienes uno). Si es la primera vez que utiliza Amazon MWAA, consulte Presentamos los flujos de trabajo administrados de Amazon para Apache Airflow (MWAA).
Asegúrese de que el Gestión de identidades y accesos de AWS El usuario o rol (IAM) utilizado para configurar el entorno tiene políticas de IAM adjuntas para los siguientes permisos:
Las políticas de acceso mencionadas aquí son solo para el ejemplo de esta publicación. En un entorno de producción, proporcione solo los permisos granulares necesarios ejerciendo principios de mínimo privilegio.
- Cree un nombre de depósito de Amazon S3 único (dentro de una cuenta) mientras crea su entorno de Amazon MWAA y cree carpetas llamadas
dagsyrequirements.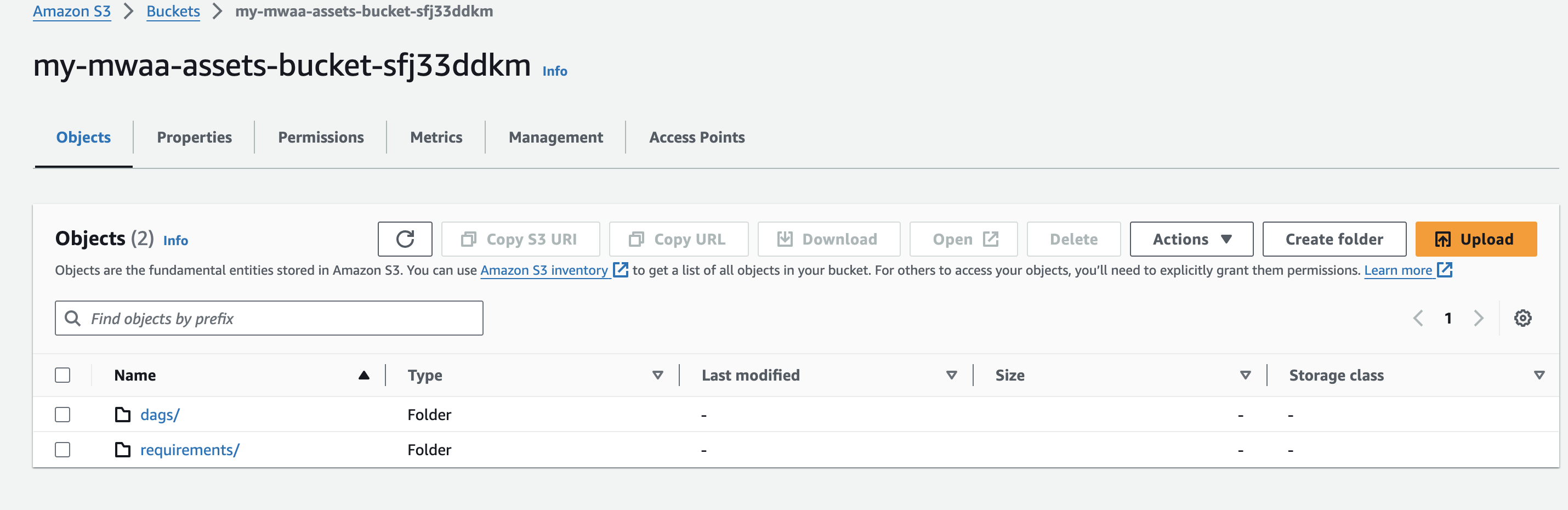
- Crea y sube un
requirements.txtarchivo con el siguiente contenido alrequirementscarpeta. Reemplazar{environment-version}con el número de versión de su entorno, y{Python-version}con la versión de Python que sea compatible con su entorno:
Pandas es necesario solo para el caso de uso de ejemplo descrito en esta publicación, y dag-factory es el único complemento requerido. Se recomienda comprobar la compatibilidad de la última versión de dag-factory con Amazon MWAA. El boto y psycopg2-binary Las bibliotecas se incluyen con la instalación básica de Apache Airflow v2 y no es necesario especificarlas en su requirements.txt archivo.
- Descargue nuestra OMS-COVID-19-archivo de datos globales a su máquina local y cárguelo en el
dagsprefijo de su depósito S3.
Asegúrese de apuntar a la última versión del depósito AWS S3 de su requirements.txt archivo para que se realice la instalación del paquete adicional. Normalmente, esto debería tardar entre 15 y 20 minutos, según la configuración de su entorno.
Validar los DAG
Cuando su entorno Amazon MWAA se muestra como Disponible en la consola de Amazon MWAA, navegue hasta la interfaz de usuario de Airflow eligiendo Abrir la interfaz de usuario de flujo de aire junto a tu entorno.

Verifique los DAG existentes navegando a la pestaña DAG.
Configura tus DAG
Complete los siguientes pasos:
- Crea archivos vacíos llamados
dynamic_dags.yml,example_dag_factory.pyyprocess_s3_data.pyen su máquina local - Editar el
process_s3_data.pyarchivo y guárdelo con el siguiente contenido del código, luego vuelva a cargar el archivo en el depósito de Amazon S3dagscarpeta. Estamos haciendo un procesamiento de datos básico en el código:- Leer el archivo desde una ubicación de Amazon S3
- Renombrar el
Country_codecolumna según corresponda al país. - Filtrar datos por el país dado.
- Escriba los datos finales procesados en formato CSV y cárguelos nuevamente al prefijo S3.
- Editar el
dynamic_dags.ymly guárdelo con el siguiente contenido del código, luego cargue el archivo nuevamente en eldagscarpeta. Estamos uniendo varios DAG según el país de la siguiente manera:- Defina los argumentos predeterminados que se pasan a todos los DAG.
- Cree una definición de DAG para países individuales pasando
op_args - Mapear el
process_s3_datafuncionar conpython_callable_name. - Uso Operador Python para procesar datos de archivos csv almacenados en el depósito de Amazon S3.
- hemos establecido
schedule_intervalcomo 10 minutos, pero siéntase libre de ajustar este valor según sea necesario.
- Editar el archivo
example_dag_factory.pyy guárdelo con el siguiente contenido del código, luego cargue el archivo nuevamente endagscarpeta. El código limpia los DAG existentes y generaclean_dags()método y la creación de nuevos DAG utilizando elgenerate_dags()método delDagFactoryejemplo.
- Después de cargar los archivos, regrese a la consola de Airflow UI y navegue hasta la pestaña DAG, donde encontrará nuevos DAG.
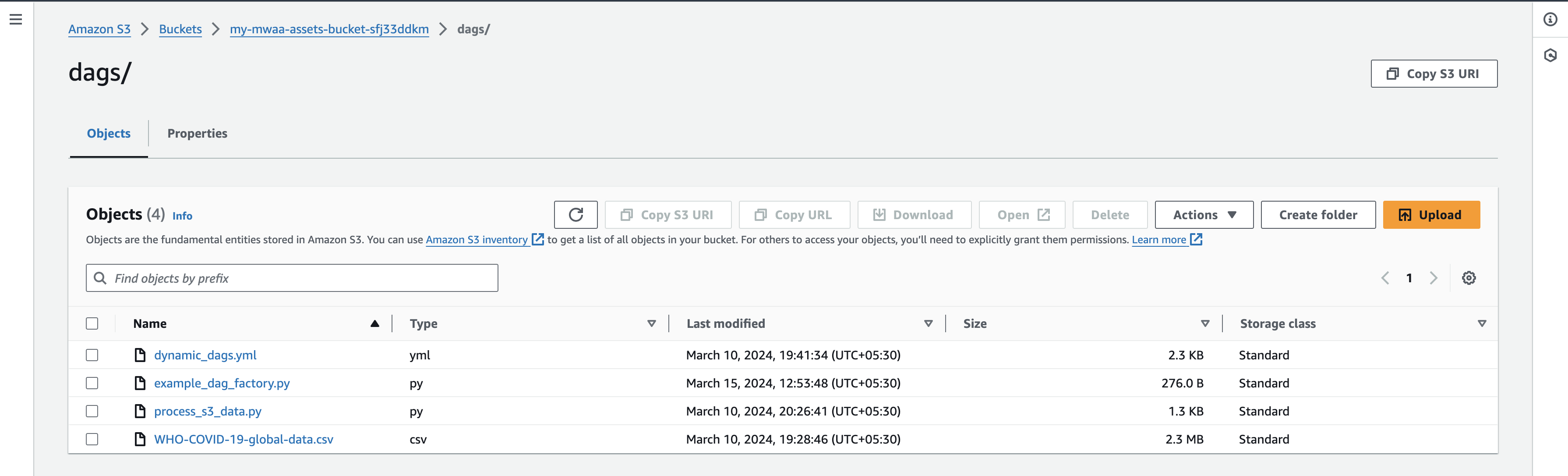
- Una vez que cargue los archivos, regrese a la consola de Airflow UI y en la pestaña DAG encontrará nuevos DAG que aparecen como se muestra a continuación:

Puede habilitar DAG activándolos y probándolos individualmente. Tras la activación, un archivo CSV adicional llamado count_death_{COUNTRY_CODE}.csv se genera en la carpeta dags.
Limpiar
Es posible que existan costos asociados con el uso de los diversos servicios de AWS que se analizan en esta publicación. Para evitar incurrir en cargos futuros, elimine el entorno de Amazon MWAA después de haber completado las tareas descritas en esta publicación y vacíe y elimine el depósito S3.
Conclusión
En esta publicación de blog demostramos cómo usar el fábrica-dag Biblioteca para crear DAG dinámicos. Los DAG dinámicos se caracterizan por su capacidad de generar resultados con cada análisis del archivo DAG en función de las configuraciones. Considere el uso de DAG dinámicos en los siguientes escenarios:
- Automatizar la migración de un sistema heredado a Airflow, donde la flexibilidad en la generación de DAG es crucial
- Situaciones en las que solo cambia un parámetro entre diferentes DAG, lo que agiliza el proceso de gestión del flujo de trabajo
- Gestionar DAG que dependen de la estructura en evolución de un sistema fuente, proporcionando adaptabilidad a los cambios.
- Establecer prácticas estandarizadas para los DAG en todo su equipo u organización mediante la creación de estos planos, promoviendo la coherencia y la eficiencia.
- Adoptar declaraciones basadas en YAML en lugar de codificación Python compleja, simplificando los procesos de configuración y mantenimiento de DAG
- Crear flujos de trabajo basados en datos que se adapten y evolucionen en función de las entradas de datos, lo que permite una automatización eficiente.
Al incorporar DAG dinámicos en su flujo de trabajo, puede mejorar la automatización, la adaptabilidad y la estandarización y, en última instancia, mejorar la eficiencia y eficacia de la gestión de su canal de datos.
Para obtener más información sobre Amazon MWAA DAG Factory, visite Taller de Amazon MWAA para análisis: DAG Factory. Para obtener detalles adicionales y ejemplos de código en Amazon MWAA, visite el Guía del usuario de Amazon MWAA y del Ejemplos de Amazon MWAA GitHub repositorio.
Acerca de los autores
 Jayesh Shinde es arquitecto sénior de aplicaciones en AWS ProServe India. Se especializa en la creación de diversas soluciones centradas en la nube utilizando prácticas modernas de desarrollo de software como sin servidor, DevOps y análisis.
Jayesh Shinde es arquitecto sénior de aplicaciones en AWS ProServe India. Se especializa en la creación de diversas soluciones centradas en la nube utilizando prácticas modernas de desarrollo de software como sin servidor, DevOps y análisis.
 Harshd Yeola Es arquitecto sénior de la nube en AWS ProServe India y ayuda a los clientes a migrar y modernizar su infraestructura a AWS. Se especializa en la creación de DevSecOps e infraestructura escalable utilizando contenedores, AIOP y herramientas y servicios para desarrolladores de AWS.
Harshd Yeola Es arquitecto sénior de la nube en AWS ProServe India y ayuda a los clientes a migrar y modernizar su infraestructura a AWS. Se especializa en la creación de DevSecOps e infraestructura escalable utilizando contenedores, AIOP y herramientas y servicios para desarrolladores de AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/dynamic-dag-generation-with-yaml-and-dag-factory-in-amazon-mwaa/

