Introducción
Imagine un aeropuerto bullicioso con vuelos despegando y aterrizando cada minuto. Así como los controladores de tráfico aéreo priorizan los vuelos según la urgencia, los montones nos ayudan a gestionar y procesar datos según criterios específicos, garantizando que los datos más "urgentes" o "importantes" estén siempre accesibles en la parte superior.
En esta guía, nos embarcaremos en un viaje para comprender montones de cosas desde cero. Empezaremos por desmitificar qué son los montones y sus propiedades inherentes. A partir de ahí, nos sumergiremos en la implementación de montones de Python, el
heapqmódulo y explore su rico conjunto de funcionalidades. Entonces, si alguna vez se ha preguntado cómo administrar eficientemente un conjunto dinámico de datos donde con frecuencia se necesita el elemento de mayor (o menor) prioridad, está de enhorabuena.
¿Qué es un montón?
Lo primero que querrás entender antes de sumergirte en el uso de montones es que es un montón. Un montón se destaca en el mundo de las estructuras de datos como una potencia basada en árboles, particularmente hábil en mantener el orden y la jerarquía. Si bien puede parecer un árbol binario para el ojo inexperto, los matices en su estructura y las reglas que lo rigen lo distinguen claramente.
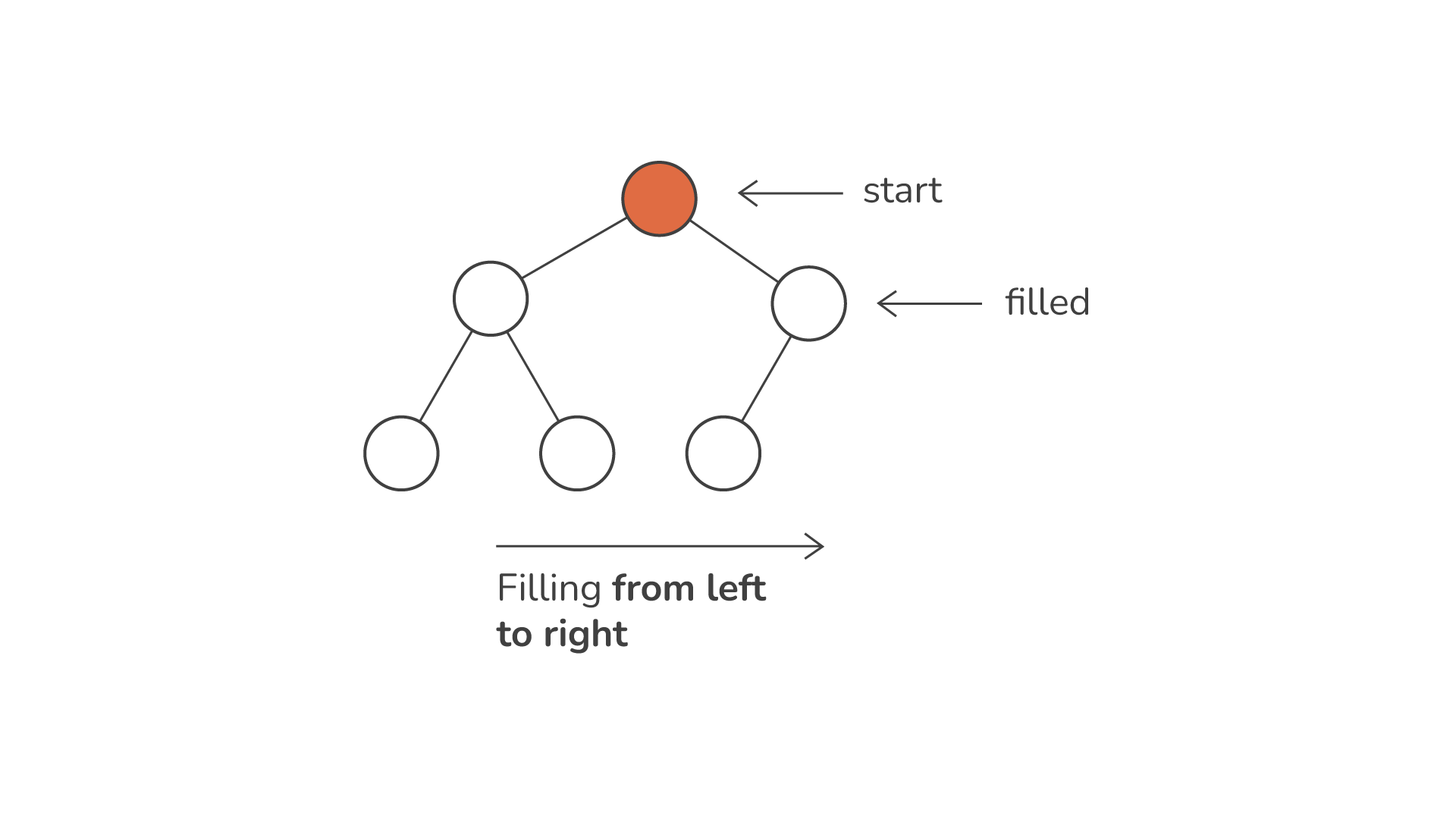
Una de las características que definen a un montón es su naturaleza como árbol binario completo. Esto significa que todos los niveles del árbol, excepto quizás el último, están completamente llenos. Dentro de este último nivel, los nodos se pueblan de izquierda a derecha. Dicha estructura garantiza que los montones se puedan representar y manipular de manera eficiente mediante matrices o listas, donde la posición de cada elemento en la matriz refleja su ubicación en el árbol.
La verdadera esencia de un montón, sin embargo, reside en su pedido. En una montón máximo, el valor de cualquier nodo supera o iguala los valores de sus hijos, posicionando el elemento más grande justo en la raíz. Por otra parte, un min montón opera según el principio opuesto: el valor de cualquier nodo es menor o igual que los valores de sus hijos, lo que garantiza que el elemento más pequeño se encuentre en la raíz.
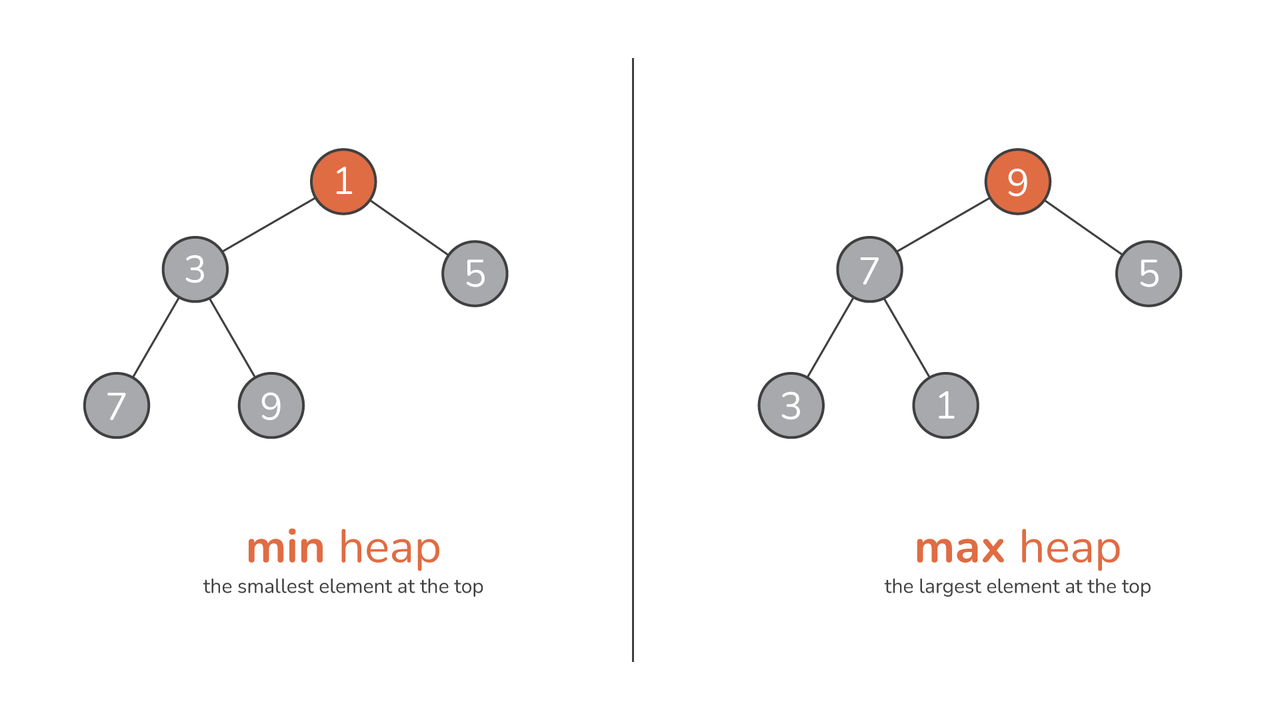
Consejo: Puedes visualizar un montón como un pirámide de números. Para un montón máximo, a medida que asciende desde la base hasta el pico, los números aumentan, culminando en el valor máximo en el pináculo. Por el contrario, un montón mínimo comienza con el valor mínimo en su punto máximo, y los números aumentan a medida que avanza hacia abajo.
A medida que avancemos, profundizaremos en cómo estas propiedades inherentes de los montones permiten operaciones eficientes y cómo Python heapq El módulo integra perfectamente montones en nuestros esfuerzos de codificación.
Características y propiedades de los montones.
Los montones, con su estructura única y principios de ordenación, presentan un conjunto de características y propiedades distintas que los hacen invaluables en diversos escenarios computacionales.
En primer lugar, los montones son inherentemente eficiente. Su estructura basada en árbol, específicamente el formato de árbol binario completo, garantiza que operaciones como la inserción y extracción de elementos prioritarios (máximo o mínimo) se puedan realizar en tiempo logarítmico, normalmente O (log n). Esta eficiencia es una gran ayuda para los algoritmos y aplicaciones que requieren acceso frecuente a elementos prioritarios.
Otra propiedad notable de los montones es su eficiencia de la memoria. Dado que los montones se pueden representar mediante matrices o listas sin la necesidad de punteros explícitos a nodos secundarios o principales, ahorran espacio. La posición de cada elemento en la matriz corresponde a su ubicación en el árbol, lo que permite un recorrido y manipulación predecibles y sencillos.
La propiedad de ordenamiento de los montones, ya sea como montón máximo o mínimo, garantiza que la raíz siempre contiene el elemento de mayor prioridad. Este orden consistente es lo que permite un acceso rápido al elemento de máxima prioridad sin tener que buscar en toda la estructura.
Además, hay montones versátil. Si bien los montones binarios (donde cada padre tiene como máximo dos hijos) son los más comunes, se puede generalizar que los montones tengan más de dos hijos, lo que se conoce como montones d-arios. Esta flexibilidad permite realizar ajustes en función de casos de uso específicos y requisitos de rendimiento.
Por último, hay montones autoajustable. Cada vez que se agregan o eliminan elementos, la estructura se reorganiza para mantener sus propiedades. Este equilibrio dinámico garantiza que el montón permanezca optimizado para sus operaciones principales en todo momento.
Consejo: Estas propiedades hicieron que la estructura de datos del montón fuera una buena opción para un algoritmo de clasificación eficiente: la clasificación del montón. Para obtener más información sobre la clasificación del montón en Python, lea nuestro "Clasificación de montón en Python" .
A medida que profundicemos en la implementación y las aplicaciones prácticas de Python, el verdadero potencial de los montones se revelará ante nosotros.
Tipos de montones
No todos los montones son iguales. Dependiendo de su orden y propiedades estructurales, los montones se pueden clasificar en diferentes tipos, cada uno con su propio conjunto de aplicaciones y ventajas. Las dos categorías principales son montón máximo y min montón.
La característica más distintiva de un montón máximo es que el valor de cualquier nodo dado es mayor o igual a los valores de sus hijos. Esto garantiza que el elemento más grande del montón siempre resida en la raíz. Esta estructura es particularmente útil cuando es necesario acceder con frecuencia al elemento máximo, como en ciertas implementaciones de cola de prioridad.
La contraparte del montón máximo, un min montón asegura que el valor de cualquier nodo dado sea menor o igual a los valores de sus hijos. Esto posiciona el elemento más pequeño del montón en la raíz. Los montones mínimos son invaluables en escenarios donde el menor elemento es de suma importancia, como en los algoritmos que se ocupan del procesamiento de datos en tiempo real.
Más allá de estas categorías primarias, los montones también se pueden distinguir según su factor de ramificación:
Si bien los montones binarios son los más comunes, y cada padre tiene como máximo dos hijos, el concepto de montones se puede extender a nodos que tengan más de dos hijos. en un montón d-ario, cada nodo tiene como máximo d niños. Esta variación se puede optimizar para escenarios específicos, como disminuir la altura del árbol para acelerar ciertas operaciones.
Montón binomial es un conjunto de árboles binomiales que se definen de forma recursiva. Los montones binomiales se utilizan en implementaciones de colas prioritarias y ofrecen operaciones de fusión eficientes.
El nombre de la famosa secuencia de Fibonacci, el Montón de Fibonacci ofrece tiempos de ejecución mejor amortizados para muchas operaciones en comparación con los montones binarios o binomiales. Son particularmente útiles en algoritmos de optimización de redes.
Implementación del montón de Python: el montónq Módulo
Python ofrece un módulo integrado para operaciones de montón: el heapq módulo. Este módulo proporciona una colección de funciones relacionadas con el montón que permiten a los desarrolladores transformar listas en montones y realizar diversas operaciones de montón sin la necesidad de una implementación personalizada. Profundicemos en los matices de este módulo y cómo le brinda el poder de los montones.
El proyecto heapq El módulo no proporciona un tipo de datos de montón distinto. En cambio, ofrece funciones que funcionan en listas normales de Python, transformándolas y tratándolas como montones binarios.
Este enfoque ahorra memoria y se integra perfectamente con las estructuras de datos existentes de Python.
Eso significa que los montones se representan como listas in heapq. La belleza de esta representación es su simplicidad: el sistema de índice de listas basado en cero sirve como un árbol binario implícito. Para cualquier elemento dado en la posición i, es:
- El niño izquierdo está en posición
2*i + 1 - El niño derecho está en posición
2*i + 2 - El nodo principal está en posición
(i-1)//2
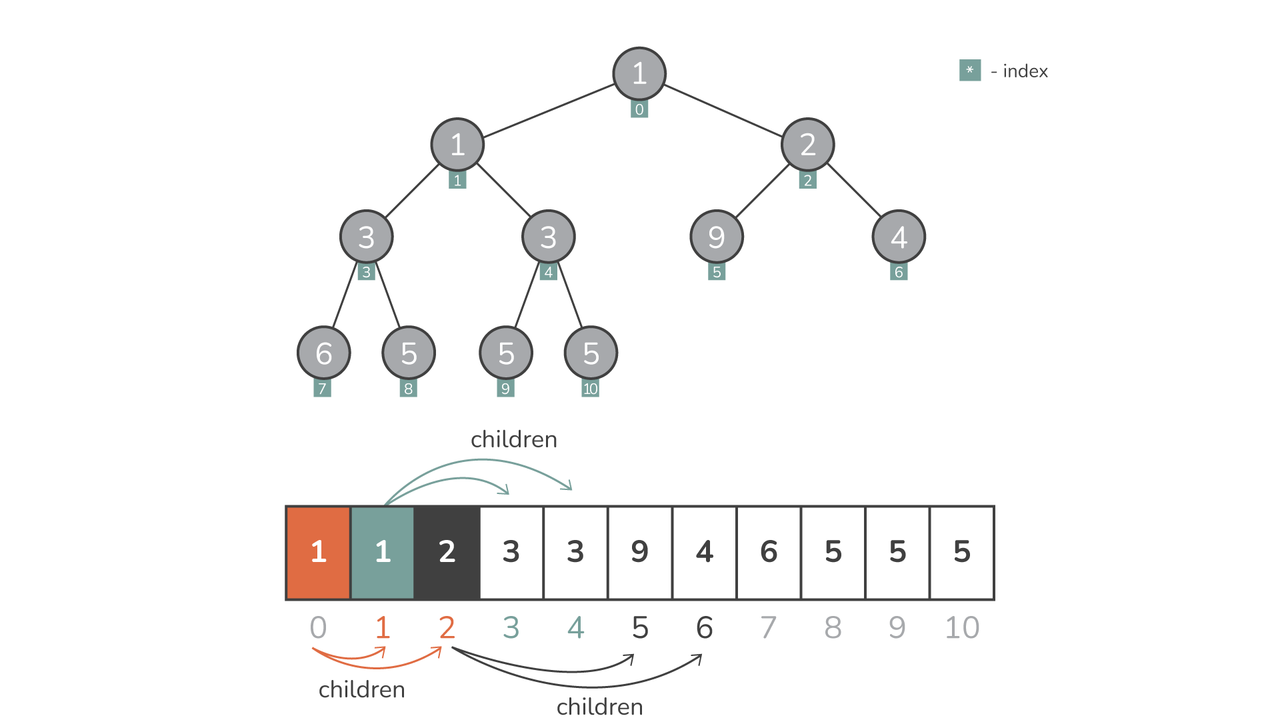
Esta estructura implícita garantiza que no haya necesidad de una representación de árbol binario basada en nodos separada, lo que hace que las operaciones sean sencillas y el uso de memoria sea mínimo.
Complejidad espacial: Los montones normalmente se implementan como árboles binarios, pero no requieren el almacenamiento de punteros explícitos para los nodos secundarios. Esto los hace eficientes en términos de espacio con una complejidad espacial de O (n) para almacenar n elementos.
Es esencial señalar que el heapq módulo crea montones mínimos por defecto. Esto significa que el elemento más pequeño siempre está en la raíz (o en la primera posición de la lista). Si necesita un montón máximo, tendría que invertir el orden multiplicando los elementos por -1 o utilice una función de comparación personalizada.
Python heapq El módulo proporciona un conjunto de funciones que permiten a los desarrolladores realizar varias operaciones de montón en listas.
Nota: Para utilizar el heapq módulo en su aplicación, deberá importarlo usando un simple import heapq.
En las siguientes secciones, profundizaremos en cada una de estas operaciones fundamentales, explorando sus mecánicas y casos de uso.
Cómo transformar una lista en un montón
El proyecto heapify() La función es el punto de partida para muchas tareas relacionadas con el montón. Toma un iterable (normalmente una lista) y reorganiza sus elementos en el lugar para satisfacer las propiedades de un montón mínimo:
Consulte nuestra guía práctica y práctica para aprender Git, con las mejores prácticas, los estándares aceptados por la industria y la hoja de trucos incluida. Deja de buscar en Google los comandos de Git y, de hecho, aprenden ella!
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
heapq.heapify(data)
print(data)
Esto generará una lista reordenada que representa un montón mínimo válido:
[1, 1, 2, 3, 3, 9, 4, 6, 5, 5, 5]
Complejidad del tiempo: Convertir una lista desordenada en un montón usando el heapify la función es una O (n) operación. Esto podría parecer contradictorio, como cabría esperar. O (nlogn), pero debido a las propiedades de la estructura del árbol, se puede lograr en tiempo lineal.
Cómo agregar un elemento al montón
El proyecto heappush() La función le permite insertar un nuevo elemento en el montón mientras mantiene las propiedades del montón:
import heapq heap = []
heapq.heappush(heap, 5)
heapq.heappush(heap, 3)
heapq.heappush(heap, 7)
print(heap)
Al ejecutar el código, obtendrá una lista de elementos que mantienen la propiedad del montón mínimo:
[3, 5, 7]
Complejidad del tiempo: La operación de inserción en un montón, que implica colocar un nuevo elemento en el montón manteniendo la propiedad del montón, tiene una complejidad temporal de O (logn). Esto se debe a que, en el peor de los casos, el elemento podría tener que viajar desde la hoja hasta la raíz.
Cómo eliminar y devolver el elemento más pequeño del montón
El proyecto heappop() La función extrae y devuelve el elemento más pequeño del montón (la raíz en un montón mínimo). Después de la eliminación, garantiza que la lista siga siendo un montón válido:
import heapq heap = [1, 3, 5, 7, 9]
print(heapq.heappop(heap))
print(heap)
Nota: El proyecto heappop() es invaluable en algoritmos que requieren procesar elementos en orden ascendente, como el algoritmo Heap Sort, o al implementar colas de prioridad donde las tareas se ejecutan en función de su urgencia.
Esto generará el elemento más pequeño y la lista restante:
1
[3, 7, 5, 9]
Aquí, 1 es el elemento más pequeño de la heap, y la lista restante ha mantenido la propiedad del montón, incluso después de que eliminamos 1.
Complejidad del tiempo: Eliminar el elemento raíz (que es el más pequeño en un montón mínimo o el más grande en un montón máximo) y reorganizar el montón también requiere O (logn) en las transacciones.
Cómo empujar un artículo nuevo y hacer estallar el artículo más pequeño
El proyecto heappushpop() La función es una operación combinada que empuja un nuevo elemento al montón y luego extrae y devuelve el elemento más pequeño del montón:
import heapq heap = [3, 5, 7, 9]
print(heapq.heappushpop(heap, 4)) print(heap)
Esto dará salida 3, el elemento más pequeño, e imprima el nuevo heap lista que ahora incluye 4 manteniendo la propiedad del montón:
3
[4, 5, 7, 9]
Nota: Usando el heappushpop() La función es más eficiente que realizar operaciones de empujar un nuevo elemento y hacer estallar el más pequeño por separado.
Cómo reemplazar el artículo más pequeño e insertar un artículo nuevo
El proyecto heapreplace() La función extrae el elemento más pequeño y empuja un nuevo elemento al montón, todo en una operación eficiente:
import heapq heap = [1, 5, 7, 9]
print(heapq.heapreplace(heap, 4))
print(heap)
Esto imprime 1, el elemento más pequeño, y la lista ahora incluye 4 y mantiene la propiedad del montón:
1
[4, 5, 7, 9]
Note: heapreplace() es beneficioso en escenarios de transmisión en línea donde desea reemplazar el elemento más pequeño actual con un nuevo valor, como en operaciones de ventana móvil o tareas de procesamiento de datos en tiempo real.
Encontrar múltiples extremos en el montón de Python
nlargest(n, iterable[, key]) y nsmallest(n, iterable[, key]) Las funciones están diseñadas para recuperar múltiples elementos más grandes o más pequeños de un iterable. Pueden ser más eficientes que ordenar todo el iterable cuando solo se necesitan unos pocos valores extremos. Por ejemplo, digamos que tiene la siguiente lista y desea encontrar tres valores más pequeños y tres más grandes en la lista:
data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
Aquí, nlargest() y nsmallest() Las funciones pueden resultar útiles:
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
print(heapq.nlargest(3, data)) print(heapq.nsmallest(3, data)) Esto le dará dos listas: una contiene los tres valores más grandes y la otra contiene los tres valores más pequeños del data lista:
[9, 6, 5]
[1, 1, 2]
Cómo construir su montón personalizado
Mientras que Python heapq El módulo proporciona un conjunto sólido de herramientas para trabajar con montones, hay escenarios en los que el comportamiento de montón mínimo predeterminado puede no ser suficiente. Ya sea que esté buscando implementar un montón máximo o necesite un montón que funcione en función de funciones de comparación personalizadas, crear un montón personalizado puede ser la respuesta. Exploremos cómo adaptar los montones a necesidades específicas.
Implementando un Max Heap usando heapq
De forma predeterminada, heapq crea montones mínimos. Sin embargo, con un truco simple, puedes usarlo para implementar un montón máximo. La idea es invertir el orden de los elementos multiplicándolos por -1 antes de agregarlos al montón:
import heapq class MaxHeap: def __init__(self): self.heap = [] def push(self, val): heapq.heappush(self.heap, -val) def pop(self): return -heapq.heappop(self.heap) def peek(self): return -self.heap[0]
Con este enfoque, el número más grande (en términos de valor absoluto) se convierte en el más pequeño, lo que permite heapq funciones para mantener una estructura de montón máxima.
Montones con funciones de comparación personalizadas
A veces, es posible que necesites un montón que no solo se compare según el orden natural de los elementos. Por ejemplo, si trabaja con objetos complejos o tiene criterios de clasificación específicos, una función de comparación personalizada se vuelve esencial.
Para lograr esto, puede envolver elementos en una clase auxiliar que anule los operadores de comparación:
import heapq class CustomElement: def __init__(self, obj, comparator): self.obj = obj self.comparator = comparator def __lt__(self, other): return self.comparator(self.obj, other.obj) def custom_heappush(heap, obj, comparator=lambda x, y: x < y): heapq.heappush(heap, CustomElement(obj, comparator)) def custom_heappop(heap): return heapq.heappop(heap).obj
Con esta configuración, puede definir cualquier función de comparación personalizada y usarla con el montón.
Conclusión
Los montones ofrecen un rendimiento predecible para muchas operaciones, lo que los convierte en una opción confiable para tareas basadas en prioridades. Sin embargo, es esencial considerar los requisitos y características específicos de la aplicación en cuestión. En algunos casos, modificar la implementación del montón o incluso optar por estructuras de datos alternativas podría generar un mejor rendimiento en el mundo real.
Los montones, como hemos visto, son más que una simple estructura de datos. Representan una confluencia de eficiencia, estructura y adaptabilidad. Desde sus propiedades fundamentales hasta su implementación en Python heapq módulo, los montones ofrecen una solución sólida a una gran cantidad de desafíos computacionales, especialmente aquellos centrados en la prioridad.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://stackabuse.com/guide-to-heaps-in-python/

