Introducción
¡Estoy seguro de que la mayoría de ustedes habrá oído hablar de ChatGPT y lo habrá probado para responder a sus preguntas! ¿Alguna vez se preguntó qué sucede debajo del capó? Está impulsado por un modelo de lenguaje grande GPT-3 desarrollado por Open AI. Estos grandes modelos lingüísticos, a menudo denominados LLM, han desbloqueado muchas posibilidades en Procesamiento natural del lenguaje.
¿Qué son los modelos de lenguaje grande?
Los modelos LLM están entrenados en cantidades masivas de datos de texto, lo que les permite comprender el lenguaje humano con significado y contexto. Anteriormente, la mayoría de los modelos se entrenaron con el enfoque supervisado, en el que alimentamos las características de entrada y las etiquetas correspondientes. A diferencia de esto, los LLM se capacitan a través del aprendizaje no supervisado, donde reciben enormes cantidades de datos de texto sin etiquetas ni instrucciones. Por lo tanto, los LLM aprenden el significado y las relaciones entre las palabras de un idioma de manera eficiente. Se pueden usar para una amplia variedad de tareas, como la generación de texto, la respuesta a preguntas, la traducción de un idioma a otro y mucho más.
Como guinda del pastel, estos grandes modelos de lenguaje se pueden ajustar en su conjunto de datos personalizado para tareas específicas del dominio. En este artículo, hablaré sobre la necesidad de ajustes, los diferentes LLM disponibles y también mostraré un ejemplo.
Comprender el ajuste fino de LLM
Supongamos que dirige una comunidad de apoyo para la diabetes y desea establecer una línea de ayuda en línea para responder preguntas. Un LLM precapacitado está capacitado de manera más general y no podría proporcionar las mejores respuestas para preguntas específicas del dominio y comprender los términos médicos y las siglas. Esto se puede solucionar con un ajuste fino.
¿Qué entendemos por ajuste fino? Para decir en breve, Traslados
aprendizaje! Los modelos de lenguaje grande se entrenan en grandes conjuntos de datos que utilizan muchos recursos y tienen millones de parámetros. Las representaciones y los patrones de lenguaje aprendidos por LLM durante la capacitación previa se transfieren a su tarea actual. En términos técnicos, inicializamos un modelo con los pesos previamente entrenados y luego lo entrenamos en nuestros datos específicos de la tarea para alcanzar más pesos optimizados para la tarea para los parámetros. También puede realizar cambios en la arquitectura del modelo y modificar las capas según sus necesidades.
¿Por qué debería afinar los modelos?
- Ahorre tiempo y recursos: La puesta a punto puede ayudarlo a reducir el tiempo de capacitación y los recursos necesarios en comparación con la capacitación desde cero.
- Requisitos de datos reducidos: Si desea entrenar un modelo desde cero, necesitaría grandes cantidades de datos etiquetados que a menudo no están disponibles para individuos y pequeñas empresas. El ajuste fino puede ayudarlo a lograr un buen rendimiento incluso con una cantidad menor de datos.
- Personaliza según tus necesidades: Es posible que el LLM preentrenado no capte la terminología y las abreviaturas específicas de su dominio. Por ejemplo, un LLM normal no reconocería que "Tipo 1" y "Tipo 2" significan los tipos de diabetes, mientras que uno perfeccionado sí puede.
- Habilite el aprendizaje continuo: Digamos que ajustamos nuestro modelo en datos de información de diabetes y lo implementamos. ¿Qué pasa si hay un nuevo plan de dieta o tratamiento disponible que desea incluir? Puede usar los pesos de su modelo previamente ajustado y ajustarlo para incluir sus nuevos datos. Esto puede ayudar a las organizaciones a mantener sus modelos actualizados de manera eficiente.
Elegir un modelo LLM de código abierto
El siguiente paso sería elegir un modelo de lenguaje grande para su tarea. ¿Cuáles son tus opciones? Los modelos de lenguaje grande de última generación disponibles actualmente incluyen GPT-3, Bloom, BERT, T5 y XLNet. Entre estos, GPT-3 (Transformadores preentrenados generativos) ha mostrado el mejor rendimiento, ya que está entrenado en 175 mil millones de parámetros y puede manejar diversas tareas de NLU. Sin embargo, solo se puede acceder al ajuste fino de GPT-3 a través de una suscripción paga y es relativamente más costoso que otras opciones.
Por otro lado, BERT es un modelo de lenguaje grande de código abierto y se puede ajustar de forma gratuita. BERTI significa Transformadores bidireccionales de codificador y decodificador. BERT hace un excelente trabajo al comprender las representaciones de palabras contextuales.
¿Cómo eliges?
Si su tarea está más orientada a la generación de texto, los modelos GPT-3 (pago) o GPT-2 (código abierto) serían una mejor opción. Si su tarea se incluye en la clasificación de texto, la respuesta a preguntas o el reconocimiento de entidades, puede optar por BERT. Para mi caso de Respuesta a preguntas sobre diabetes, estaría procediendo con el modelo BERT.
Preparación y preprocesamiento de su conjunto de datos
Este es el paso más crucial del ajuste fino, ya que el formato de los datos varía según el modelo y la tarea. Para este caso, he creado un documento de texto de muestra con información sobre diabetes que he obtenido del Instituto Nacional de Salud. página web del NDN Collective . Puede utilizar sus propios datos.
Para afinar BERT en la tarea de Preguntas y Respuestas, se recomienda convertir sus datos al formato SQuAD. SQuAD es un conjunto de datos de respuesta a preguntas de Stanford y este formato se adopta ampliamente para entrenar modelos de PNL para tareas de respuesta a preguntas. Los datos deben estar en formato JSON, donde cada campo consta de:
context: La oración o párrafo con texto a partir del cual el modelo buscará la respuesta a la preguntaquestion: La consulta que queremos que responda el BERT. Debería enmarcar estas preguntas en función de cómo el usuario final interactuaría con el modelo de control de calidad.answers: debe proporcionar la respuesta deseada en este campo. Hay dos subcomponentes debajo de esto,textyanswer_start.texttendrá la cadena de respuesta. Mientras que,answer_startdenota el índice, desde donde comienza la respuesta en el párrafo de contexto.
Como puede imaginar, tomaría mucho tiempo crear estos datos para su documento si lo hiciera manualmente. No te preocupes, te mostraré cómo hacerlo fácilmente con la herramienta de anotación Haystack.
¿Cómo crear datos en formato SQuAD con Haystack?
Con la herramienta de anotación Haystack, puede crear rápidamente un conjunto de datos etiquetados para tareas de respuesta a preguntas. Puede acceder a la herramienta creando una cuenta en su página web. Cree un nuevo proyecto y cargue su documento. Puede verlo en la pestaña "Documentos", vaya a "Acciones" y puede ver la opción para crear sus preguntas. Puede escribir su pregunta y resaltar la respuesta en el documento, Haystack encontrará automáticamente el índice inicial de la misma. He mostrado cómo lo hice en mi documento en la imagen de abajo.
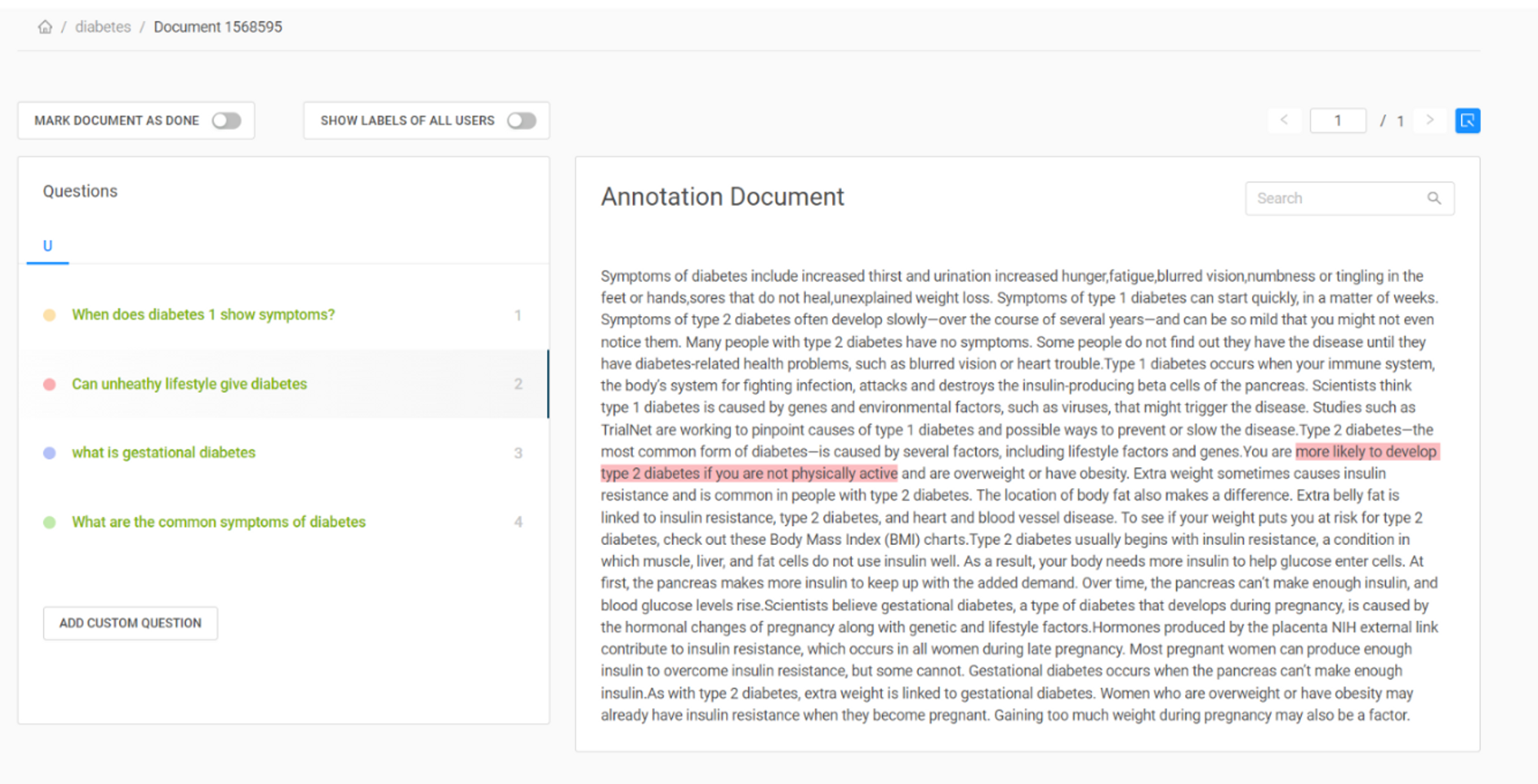
Fig. 1: Creación de un conjunto de datos etiquetados para preguntas y respuestas con Haystack
Cuando haya terminado de crear suficientes pares de preguntas y respuestas para el ajuste fino, debería poder ver un resumen de ellos como se muestra a continuación. En la pestaña "Exportar etiquetas", puede encontrar múltiples opciones para el formato en el que desea exportar. Elegimos el formato de escuadrón para nuestro caso. Si necesita más ayuda para usar la herramienta, puede consultar su documentación. Ahora tenemos nuestro archivo JSON que contiene los pares de control de calidad para realizar ajustes.
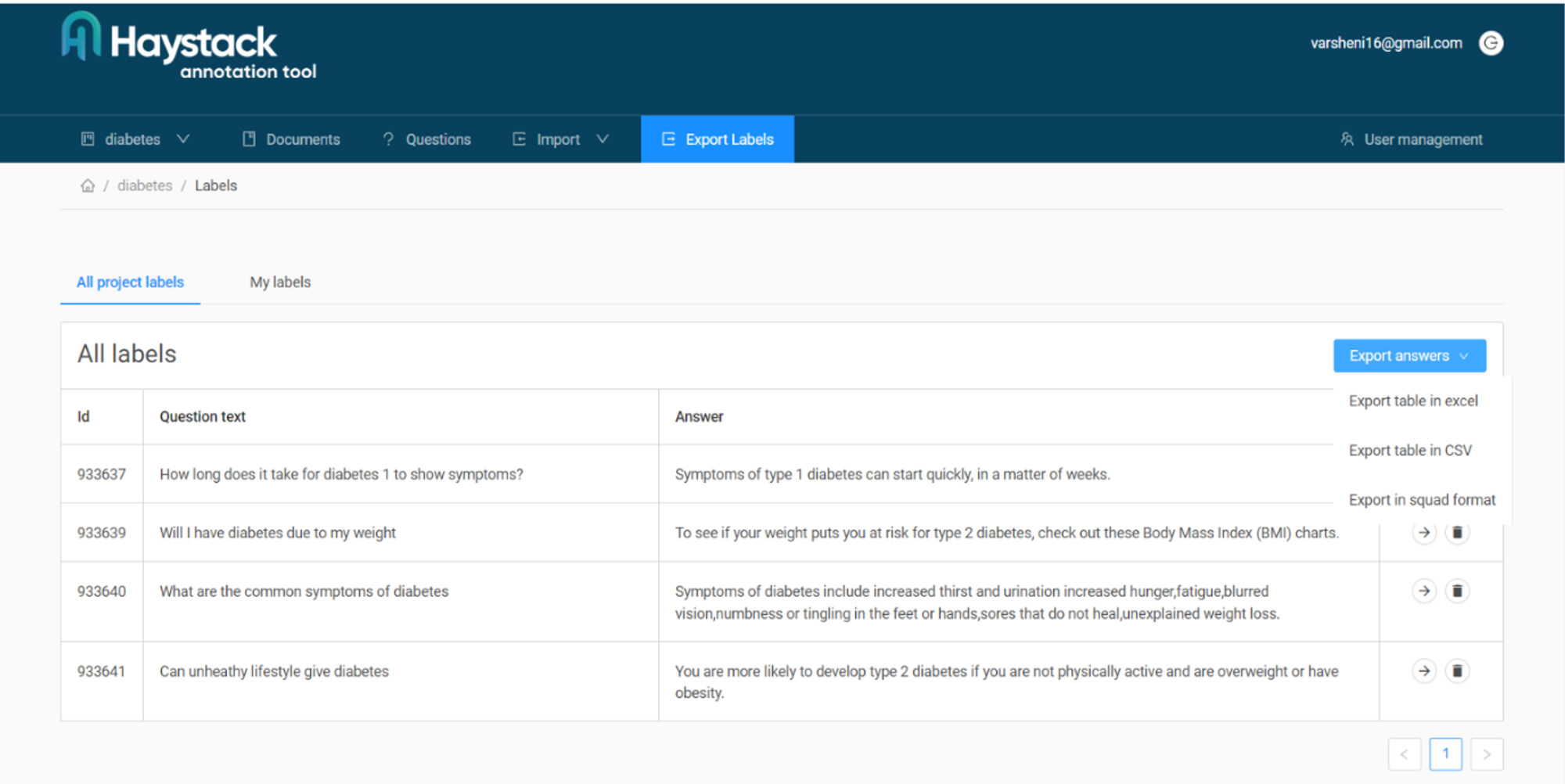
¿Cómo afinar?
Python ofrece muchos paquetes de código abierto que puede usar para realizar ajustes. Usé el paquete Pytorch y Transformers para mi caso. Comience importando los módulos del paquete usando pip, el administrador de paquetes. El transformers biblioteca proporciona un BERTTokenizer, que es específicamente para tokenizar entradas al modelo BERT.
!pip install torch
!pip install transformers import json
import torch
from transformers import BertTokenizer, BertForQuestionAnswering
from torch.utils.data import DataLoader, Dataset
Definición de conjuntos de datos personalizados para carga y preprocesamiento
El siguiente paso es cargar y preprocesar los datos. Puedes usar el Dataset clase de pytorch utils.data módulo para definir una clase personalizada para su conjunto de datos. He creado una clase de conjunto de datos personalizada diabetes como puede ver en el siguiente fragmento de código. El init es responsable de inicializar las variables. El file_path es un argumento que ingresará la ruta de su archivo de entrenamiento JSON y se usará para inicializar data. Inicializamos el BertTokenizer también aquí.
A continuación, definimos un load_data() función. Esta función leerá el archivo JSON en un objeto de datos JSON y extraerá el contexto, la pregunta, las respuestas y su índice. Agrega los campos extraídos en una lista y la devuelve.
La getitem utiliza el tokenizador BERT para codificar la pregunta y el contexto en tensores de entrada que son input_ids y attention_mask. encode_plus tokenizará el texto y agregará tokens especiales (como [CLS] y [SEP]). Tenga en cuenta que usamos el squeeze() método para eliminar cualquier dimensión singleton antes de ingresar a BERT. Finalmente, devuelve los tensores de entrada procesados.
class diabetes(Dataset): def __init__(self, file_path): self.data = self.load_data(file_path) self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') def load_data(self, file_path): with open(file_path, 'r') as f: data = json.load(f) paragraphs = data['data'][0]['paragraphs'] extracted_data = [] for paragraph in paragraphs: context = paragraph['context'] for qa in paragraph['qas']: question = qa['question'] answer = qa['answers'][0]['text'] start_pos = qa['answers'][0]['answer_start'] extracted_data.append({ 'context': context, 'question': question, 'answer': answer, 'start_pos': start_pos, }) return extracted_data def __len__(self): return len(self.data) def __getitem__(self, index): example = self.data[index] question = example['question'] context = example['context'] answer = example['answer'] inputs = self.tokenizer.encode_plus(question, context, add_special_tokens=True, padding='max_length', max_length=512, truncation=True, return_tensors='pt') input_ids = inputs['input_ids'].squeeze() attention_mask = inputs['attention_mask'].squeeze() start_pos = torch.tensor(example['start_pos']) return input_ids, attention_mask, start_pos, end_pos
Una vez que lo defina, puede continuar y crear una instancia de esta clase pasando el file_path argumento a ello.
file_path = 'diabetes.json'
dataset = diabetes(file_path)
Entrenando el modelo
estaré usando el BertForQuestionAnswering modelo, ya que es el más adecuado para las tareas de control de calidad. Puede inicializar los pesos preentrenados del bert-base-uncased modelo llamando al from_pretrained función en el modelo. También debe elegir la función de pérdida de evaluación y el optimizador que usaría para el entrenamiento.
Consulte nuestra guía práctica y práctica para aprender Git, con las mejores prácticas, los estándares aceptados por la industria y la hoja de trucos incluida. Deja de buscar en Google los comandos de Git y, de hecho, aprenden ella!
Estoy usando un optimizador Adam y una función de pérdida de entropía cruzada. Puedes usar la clase Pytorch DataLoader para cargar datos en diferentes lotes y también mezclarlos para evitar cualquier sesgo.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
model.to(device) optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
loss_fn = torch.nn.CrossEntropyLoss()
batch_size = 8
num_epochs = 50 data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
Una vez que se define el cargador de datos, puede continuar y escribir el ciclo de entrenamiento final. Durante cada iteración, cada lote obtenido de la data_loader contiene batch_size número de ejemplos, en los que se realiza la propagación hacia adelante y hacia atrás. El código intenta encontrar el mejor conjunto de pesos para los parámetros, en el que la pérdida sería mínima.
for epoch in range(num_epochs): model.train() total_loss = 0 for batch in data_loader: input_ids = batch[0].to(device) attention_mask = batch[1].to(device) start_positions = batch[2].to(device) optimizer.zero_grad() outputs = model(input_ids, attention_mask=attention_mask, start_positions=start_positions) loss = outputs.loss loss.backward() optimizer.step() total_loss += loss.item() avg_loss = total_loss / len(data_loader) print(f"Epoch {epoch+1}/{num_epochs} - Average Loss: {avg_loss:.4f}")
¡Esto completa su ajuste fino! Puede probar el modelo configurándolo en model.eval(). También puede ajustar la tasa de aprendizaje y el número de parámetros de épocas para obtener los mejores resultados en sus datos.
Mejores consejos y prácticas
Aquí hay algunos puntos a tener en cuenta al ajustar cualquier modelo de lenguaje grande en datos personalizados:
- Su conjunto de datos debe representar el dominio de destino o la tarea en la que desea que se destaque el modelo de lenguaje. Fácil y los datos bien estructurados son esenciales.
- Asegúrese de tener suficientes ejemplos de entrenamiento en sus datos para que el modelo aprenda patrones. De lo contrario, el modelo podría memorizar los ejemplos y sobreajustarse, sin la capacidad de generalizar a ejemplos invisibles.
- Elija un modelo previamente entrenado que haya sido entrenado en un corpus que sea relevante para su tarea en cuestión. Para la respuesta a preguntas, elegimos un modelo preentrenado que está entrenado en el conjunto de datos de Respuesta a preguntas de Stanford. Similar a esto, hay diferentes modelos disponibles para tareas como análisis de sentimientos, generación de texto, resumen, clasificación de texto y más.
- Intente Acumulación de gradiente si tiene una memoria de GPU limitada. En este método, en lugar de actualizar los pesos del modelo después de cada lote, los gradientes se acumulan en varios minilotes antes de realizar una actualización.
- Si se enfrenta al problema de un sobreajuste durante el ajuste fino, utilice regularización tecnicas Algunos métodos comúnmente utilizados incluyen agregar capas de abandono a la arquitectura del modelo, implementar el decaimiento de peso y la normalización de capas.
Conclusión
Los modelos de lenguaje grandes pueden ayudarlo a automatizar muchas tareas de manera rápida y eficiente. Los LLM de ajuste fino lo ayudan a aprovechar el poder del aprendizaje de transferencia y personalizarlo para su dominio particular. El ajuste fino puede ser esencial si su conjunto de datos pertenece a dominios como médicos, un nicho técnico, conjuntos de datos financieros y más.
En este artículo usamos BERT porque es de código abierto y funciona bien para uso personal. Si está trabajando en un proyecto a gran escala, puede optar por LLM más potentes, como GPT3, u otras alternativas de código abierto. Recuerde, el ajuste fino de los modelos de lenguaje grande puede ser computacionalmente costoso y llevar mucho tiempo. Asegúrese de tener suficientes recursos computacionales, incluidas GPU o TPU según la escala.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://stackabuse.com/guide-to-fine-tuning-open-source-llms-on-custom-data/

